ClickHouse 数据表的增删改
楔子
日常工作中,我们更多地还是对数据表中的数据进行操作,而对于 OLAP 类型的数据库而言,这些操作还都是查询操作。不过查询涉及到的内容非常多,我们会单独展开,这里先看看如何进行增删改。
增
跟绝大部分关系型数据库一样,ClickHouse 使用 INSERT 语句进行数据的插入。并且 INSERT语句支持三种语法范式,三种范式各有不同,可以根据写入的需求灵活运用。
其中,第一种是使用 VALUES 格式的常规语法:
-- 中括号表示里面的内容可以省略
INSERT INTO [db.]table_name [(col1, col2, col3...)] VALUES (val1, val2, val3, ...), (val1, val2, val3, ...), ...
这个和其它关系型数据库没什么两样,就不赘述了。
在使用 VALUES 格式的语法写入数据时,还支持加入表达式或函数,例如:
INSERT INTO partizion_v2 VALUES('matsuri', toString(1+2), now())
第二种是使用指定格式的语法:
INSERT INTO [db.]table_name [(col1, col2, col3...)] FORMAT format_name data_set
ClickHouse 支持多种数据格式,以常用的 CSV 格式写入为例:
INSERT INTO partition_v2 FORMAT CSV \
'mea', 'www.mea.com', '2019-01-01'
'nana', 'www.nana.com', '2019-02-01'
'matsuri', 'www.matsuri.com', '2019-03-01'
第三种是使用 SELECT 子句形式的语法:
INSERT INTO [db.]table_name [(col1, col2, col3...)] SELECT ...
通过 SELECT 子句可将查询结果写入数据表,假设需要将 partition_v1 的数据写入 partition_v2,则可以 使用下面的语句:
INSERT INTO partition_v2 SELECT * FROM partition_v1
当然也可以这么做:
-- 加入表达式也是可以的,比如这里的 now()
INSERT INTO partition_v2 SELECT 'aqua', 'www.aqua.com', now()
虽然 VALUES 和 SELECT 子句的形式都支持声明表达式或函数,但是表达式或函数会带来额外的性能开销,从而导致写入性能下降。所以如果追求极致的写入性能,应该尽量避免使用它们。
在前面曾介绍过,ClickHouse 内部所有的数据操作都是面向 Block 数据块的,所以 INSERT 查询最终会将数据转换为 Block 数据块。也正因为如此,INSERT 语句在单个数据块的写入过程中是具有原子性的。在默认情况下,每个数据块最多可以写入 1048576 条数据(由 max_insert_block_size 参数控制)。也就是说,如果一条 INSERT 语句写入的数据行数少于 max_insert_block_size,那么这批数据的写入是具有原子性的,要么全部成功,要么全部失败。但是需要注意的是,只有在 ClickHouse 服务端处理数据的时候才具有这种原子写入的特性,例如使用 HTTP 接口,因为 max_insert_block_size 参数在使用 CLI 命令行或者 INSERT SELECT 子句写入时是不生效的。
删除与修改
ClickHouse 提供了 DELETE 和 UPDATE 的能力,这类操作被称为 Mutation 查询,它可以看作 ALTER 语句的变种。虽然 Mutation 能最终实现修改和删除,但不能完全以通常意义上的 UPDATE 和 DELETE 来理解,我们必须清醒地认识到它的不同。首先,Mutation 语句是一种 "很重" 的操作,更适用于批量数据的修改和删除;其次,它不支持事务,一旦语句被提交执行,就会立刻对现有数据造成影响,无法回滚;最后,Mutation 语句的执行是一个异步的后台过程,语句被提交之后就会立即返回。所以这并不代表具体逻辑已经执行完毕,它的具体执行进度需要通过 system.mutations 系统表查询。
DELETE 语句的完整语法如下所示:
ALTER TABLE [db_name.]table_name DELETE WHERE filter_expr
数据删除的范围由 WHERE 查询子句决定。例如,执行下面语句可以删除 partition_v2 表内所有 ID 等于 'xxx' 的数据:
ALTER TABLE partition_v2 DELETE WHERE ID ='xxx'
如果数据很少的话,那么 DELETE 操作给人的感觉和常用的 OLTP 数据库无异,但我们心中应该要明白这是一个异步的后台执行动作。
下面我们来实际删除数据,就以 partition_v1 为例吧,先来看看对应目录(/var/lib/clickhouse/data/default/partition_v1)里面的内容:
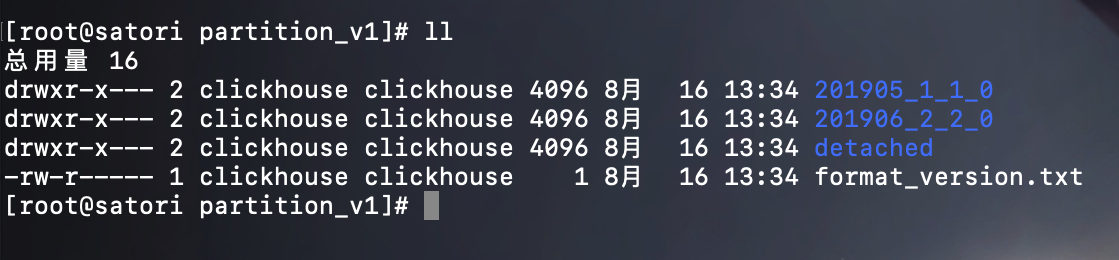
执行该语句:ALTER TABLE partition_v1 DELETE WHERE ID ='xxx' 进行数据删除,执行完之后再看一下目录结构:
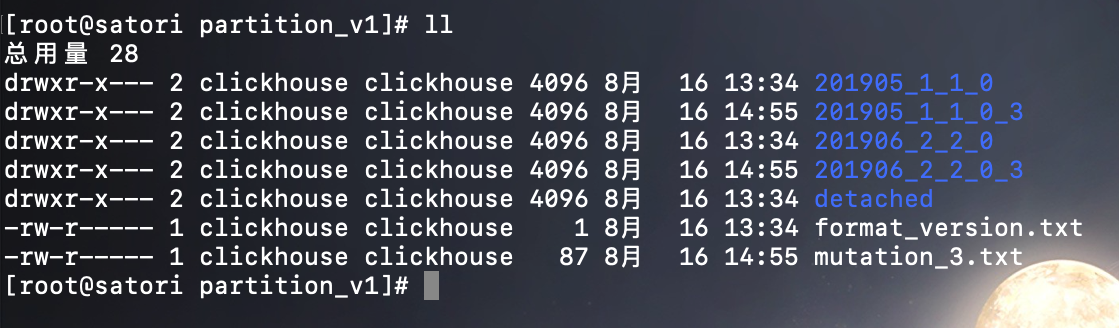
可以发现,在执行了 DELETE 操作后数据目录发生了一些变化,每一个原有的数据目录都额外增加了一个同名目录,并且在末尾处增加了 _3 后缀。此外,目录下还多了一个名为 mutation_3.txt 文件,里面的内容如下:
[root@satori partition_v1]# cat mutation_3.txt
format version: 1
create time: 2021-08-16 14:55:41
commands: DELETE WHERE ID = \'xxx\'
[root@satori partition_v1]#
原来 mutation3.txt 是一个日志文件,它完整地记录了这次 DELETE 操作的执行语句和时间,而文件名的后缀 _3 与新增目录的后缀对应。那么后缀的数字从何而来呢?继续查询 system.mutations 系统表,一探究竟:
SELECT database, table, mutation_id, block_numbers.number as num, is_done FROM system .mutations
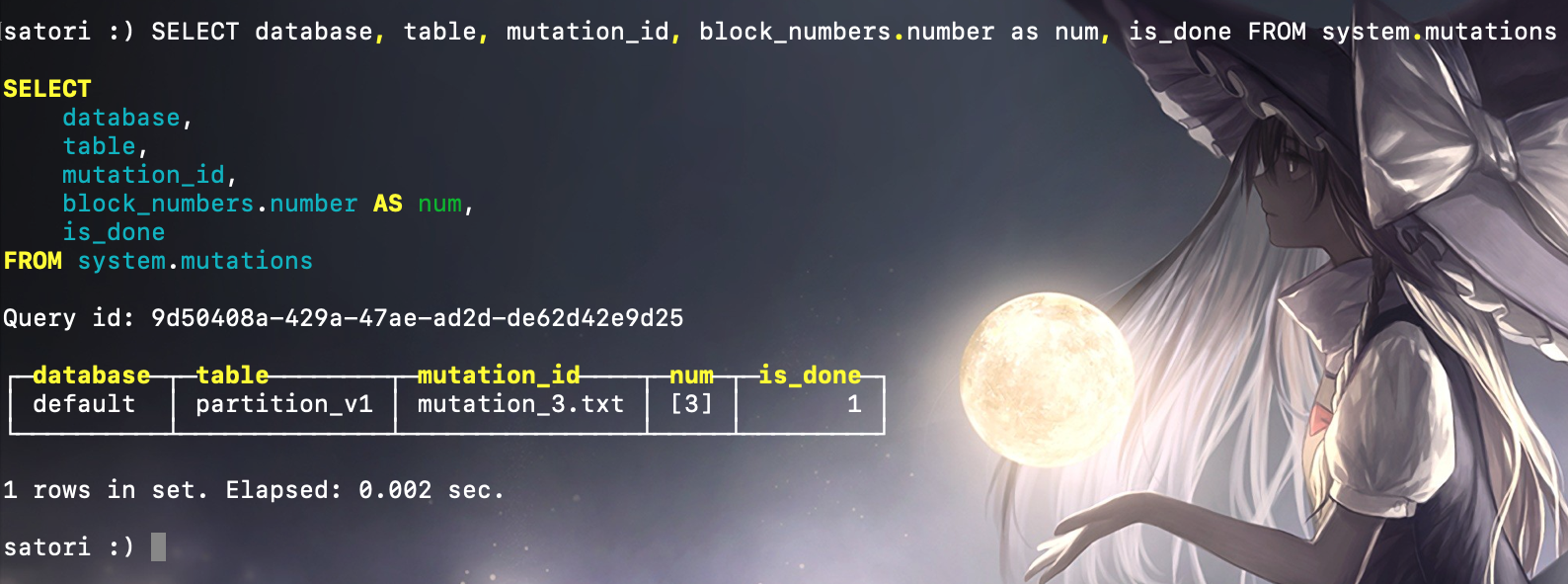
至此,整个 Mutation 操作的逻辑就比较清晰了。每执行一条 ALTER DELETE 语句,都会在 mutations 系统表中生成一条对应的执行计划,当 is_done 等于 1 时表示执行完毕。与此同时,在数据表的根目录下,会以 mutation_id 作为名字生成与之对应的日志文件用于记录相关信息。而数据删除的过程是以数据表的每个分区目录为单位,将所有目录重写为新的目录,新目录的命名规则是在原有名称上加上 system.mutations.block_numbers.number。数据在重写的过程中会将需要删除的数据去掉,旧的数据目录并不会立即删除,而是会被标记成非激活状态(active 为 0)。等到 MergeTree 引擎的下一次合并动作触发时,这些非激活目录才会被真正从物理意义上删除。
数据修改除了需要指定具体的要更新的列字段之外,整个逻辑与数据删除别无二致,它的完整语法如下所示:
ALTER TABLE [db_name.]table_name UPDATE column1 = expr1 [, ...] WHERE filter_expr
UPDATE 支持在一条语句中同时定义多个修改字段,但是分区键和主键不能作为修改字段。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号