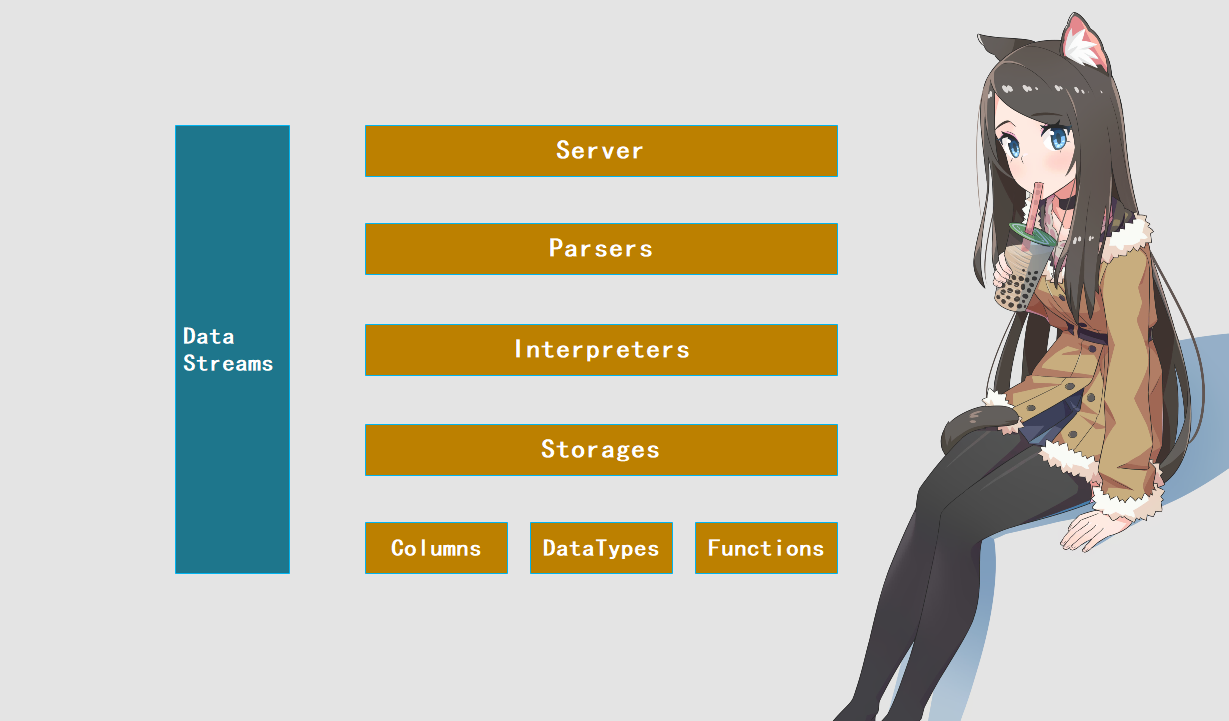
ClickHouse 的架构设计、安装方式以及连接工具
ClickHouse 的架构设计
下面我们来聊一聊 ClickHouse 底层设计中的一些概念,这些概念可以帮助我们了解 ClickHouse。
当然这些东西后面会慢慢说。
Column 与 Field
Column 和 Field 是 ClickHouse 中最基础的映射单元,作为一款百分百的列式存储数据库,ClickHouse 按列存储数据,内存中的一个列就用一个 Column 对象表示。Column 对象分为接口和实现两个部分,在 IColumn 接口对象中,定义了对数据进行各种关系运算的方法,例如插入数据的 insertRangeFrom 方法和 insertFrom 方法,用于分页的 cut,以及用于数据过滤的 filter 方法等等。而这些方法的具体实现对象则根据数据类型的不同,由不同的对象实现,例如:ColumnString、ColumnArray 和 ColumnTuple 等等。在大部分场景中,ClickHouse 都会以整列的方式操作数据,但凡事也有例外,如果需要操作单个具体的值(也就是单列中的一行数据),则需要使用 Field 对象。Field 对象代表一个单值,与 Column 对象的泛化设计思路不同,Field 对象使用了聚合的设计模式。在 Field 对象内部聚合 Null、UInt64、String 和 Array 等 13 种数据类型及相应的处理逻辑,说白了就是这些值的类型虽然不同,但它们都是 Field 对象,因为这些类型的数据的处理逻辑都在 Field 对象里面。
Column 对象是数据表中的一列,Field 对象相当于一个单元格。
DataType
数据的序列化和反序列化工作由 DataType 负责,IDataType 接口定义了许多正反序列化的方法,它们成对出现,例如 serializeBinary 和 deserializeBinary、serializeTextJSON 和 deserializeTextJSON 等等,涵盖了常用的二进制、文本、JSON、XML、CSV 和 Protobuf 等多种格式类型。IDataType 也使用了泛化的设计模式,具体方法的实现逻辑由对应数据类型的实例对象来承载,例如 DataTypeString、DataTypeArray 以及 DataTypeTuple 等等。
接口内部定义相应的方法,具体的数据类负责实现。如果某个类实现了接口内部定义的所有方法,那么这个类就实现了这个接口,其实例对象就可以赋值给接口,通过接口来调用内部的方法。当然调用的方法必须是接口内部已经声明的,如果除了接口内部定义的方法之外,该类还定义了其它的方法,那么这些其它的方法就不能通过接口调用了。
那么接口设计有什么好处呢?首先最直观的一个好处就是实现了多态,因为不管是什么类,只要它实现了接口定义的方法,那么其实例对象就可以赋值给接口,即:一个接口,多种实现。
另外 DataType 虽然负责序列化相关工作,但它并不直接负责数据的读取,而是从 Column 对象或 Field 对象中读取。在 DataType 的实现类中,聚合了相应数据类型的 Column 对象和 Field 对象。例如 DataTypeString 会引用字符串类型的 ColumnString,而 DataTypeArray 则会引用数组类型的 ColumnArray,以此类推。
Block 和 Block流
ClickHouse 内部的数据操作是面向 Block 对象进行的,并且采用了流的形式,虽然 Column 对象和 Field 对象组成了数据的基本映射单元,但对应到实际操作,它们还少了一些必要的信息,比如数据的类型和列的名称。于是 ClickHouse 设计了 Block 对象,Block 对象可以看成是数据表的子集,Block 对象的本质是由数据对象、数据类型和列名称组成的三元组,即 Column、DataType、列名称字符串。Column 提供了数据的读取能力,而 DataType 知道如何正反序列化,所以 Block 对象在这些对象的基础上实现了进一步的抽象和封装,从而简化了整个使用的过程,仅通过 Block 对象就能完成一系列的数据操作。只不过在具体的实现过程中,Block 并没有直接聚合 Column 和 DataType 对象,而是通过 ColumnWithAndName 对象进行间接引用。
有了 Block 对象的这一层封装之后,对 Block 流的设计就是水到渠成的事情了,流操作有两组顶层接口:IBlockInputStream 负责数据的读取和关键运算,IBlockOutputStream 负责将数据输出到下一环节。Block 流也是用了泛化的设计模式,对数据的各种操作都会转换成其中一种流的实现。所以 IBlockInputStream 也是一个接口,内部定义了读取数据的若干个 read 虚方法,而具体的实现逻辑则交给它的实现类来填充,IBlockOutputStream 同理。
总共有 60 多个类实现了 IBlockInputStream 接口,它们覆盖了 ClickHouse 数据摄取的方方面面。这些实现类大致可以分为三类:第一类用于处理数据定义的 DDL 操作,例如 DDLQueryStatusInputStream 等;第二类用于处理数据关系运算的相关操作,例如 LimitBlockInputStream、JoinBlockInputStream、AggregatingBlockInputStream等;第三类则是与引擎呼应,每一种引擎都拥有与之对应的 BlockInputStream 实现,例如 MergeTreeBaseSelectBlockInputStream(MergeTree 引擎)、TinyLogBlockInputStream(TinyLog 引擎)以及 KafkaBlockInputStream(Kafka 引擎)等。
IBlockOutputStream 的设计也与 IBlockInputStream 如出一辙,IBlockOutputStream 接口同样定义了若干写入数据的 write 虚方法。但它的实现类比起 IBlockInputStream 要少很多,一共只有 20 多种,这些实现类基本用于引擎的相关处理,负责将数据写入下一环节或者最终目的地,例如:MergeTreeBlockOutputStream、TinyLogBlockOutputStream 以及 StorageFileBlockOutputStream 等。
Table
在数据表的底层设计中并没有所谓的 Table 对象,它是直接使用 IStroge 接口指代数据表,表的引擎是 ClickHouse 的一个显著特征,不同的表的引擎由不同的子类实现。例如:IStorageSystemOneBlock(系统表)、StorageMergeTree(合并树引擎)和 StorageTinyLog(日志表引擎)等。IStorage 接口定义了 DDL(如 ALTER、RENAME、OPTIMIZE 和 DROP 等)、read 和 write 方法,它们分别负责数据的定义、查询与写入。在数据查询时,IStorage 负责根据 AST 查询语句的指示要求,返回指定列的原始数据。后续对数据的进一步加工、计算和过滤则会统一交由 Interpreter 解释器对象处理。对 Table 发起的一次操作通常都会经历这样的过程,接收 AST 查询语句、根据 AST 返回指定列的数据,之后再将数据交给 Interpreter 做进一步处理。
Parser 和 Interpreter
Parser 和 Interpreter 是非常重要的两组接口:Parser 分析器负责创建 AST 对象;而 Interpreter 解释器对象则负责解释 AST,并进一步创建查询的执行管道,它们与 IStorage 一起,串联起了整个数据查询的过程。
Parser 分析器可以将一条 SQL 语句以递归下降的方法解析成 AST(抽象语法树),不同的 SQL 语句会交给不同的 Parser 实现类来解析。例如,有负责解析 DDL 查询语句的 ParserRenameQuery、ParserDropQuery 和 ParserAlterQuery 解析器,还有负责解析 INSERT 语句的 ParserInsertQuery 解析器,还有负责 SELECT 语句的 ParserSelectQuery 等等。所以尽管 SQL 语句最终都会被解析成 AST,但不同的 SQL 语句会交给不同的 Parser 实现类进行解析
Interpreter 解释器的作用域就像 Service 服务器一样,起到串联整个查询过程的作用,它会根据解释器的类型,聚合它所需要的资源。首先它会解析 AST 对象,然后执行 "业务逻辑"(例如分支判断、设置参数、调用接口等);最终返回 IBlock 对象,以线程的形式建立起一个查询执行管道。
Functions 与 Aggregate Functions
ClickHouse 主要提供两类函数:普通函数和聚合函数,普通函数由 IFunction 接口定义,拥有数十种函数实现,例如 FunctionFormatDataTime、FunctionSubstring 等。除了一些常见的函数(诸如四则运算、日期转换)之外,也不乏一些非常使用的函数,例如网址提取函数、IP 地址脱敏函数等。普通函数是没有状态的,函数效果作用于每行数据之上。当然,在函数具体执行的过程中,并不会一行一行的运算,而是采用向量化执行的方式直接作用于一整列数据。
聚合函数由 IAggregateFunction 接口定义,相比无状态的普通函数,聚合函数是有状态的。以 COUNT 聚合函数为例,其 AggregateFunctionCount 的状态使用整型UInt64记录。聚合函数的状态支持序列化和反序列化,所以能够在分布式节点直接进行传输,以实现增量计算。
Cluster 与 Replication
ClickHouse 的集群由分片(Shard)组成,而每个分片又通过副本(Replica)组成,这种分层的概念,在一些流行的分布式系统中非常普遍。例如,在 Elasticsearch 中,一个索引由分片和副本组成,副本可以看做是一种特殊的分片,如果一个索引由 5 个分片组成,副本的基数是 1,那么这个索引一共会拥有 10 个分片(每 1 个分片对应 1 个副本)。
而如果你使用同样的方式来理解 ClickHouse 的分片,那么很可能会栽一个跟头,ClickHouse 的某些设计总是显得独树一帜,而集群与分片便是其中之一。这里有几个与众不同的特性:
1. ClickHouse 的一个节点只能有 1 个分片,也就是说如果要实现 1 分片、1 副本,则至少需要两个服务节点2. 分片只是一个逻辑概念,其物理承载还是要由副本来承担的
我们来看一下 ClickHouse 的集群配置,这里将会在后面详细说,目前先看看有个印象即可。
<ch_cluster>
<shard>
<replica>
<host>47.94.174.89</host>
<port>9000</port>
</replica>
</shard>
</ch_cluster>
如果从字面含义上来理解的话,可以认为是自定义集群 ch_cluster 拥有一个 shard(分片)和一个replica(副本),且该副本由 47.94.174.89 服务节点承载。
但是从本质上来理解的话,1 分片、1 副本的配置在 ClickHouse 中只有 1 个物理副本,所以它的正确语义应该是 1 分片、0 副本。分片更像是逻辑层的分组,在物理存储层面则统一使用副本来代表 "分片和副本"。所以如果想真正表示 1 分片、1 副本语义的配置,应该改为 1 个分片和 2 个副本,配置可以改为如下:
<ch_cluster>
<shard>
<replica>
<host>47.94.174.89</host>
<port>9000</port>
</replica>
<replica>
<host>47.93.39.238</host>
<port>9000</port>
</replica>
</shard>
</ch_cluster>
以上就是 ClickHouse 的架构设计,这些内容感觉有点枯燥甚至不好理解,下面就来安装 ClickHouse,进入实际操作环节。
ClickHouse 的安装以及连接工具
相较于 Hadoop 生态中的一些系统,ClickHouse 的安装显得尤为简单,因为它自成一体,在单节点的情况下不需要额外的依赖,集群的话后面会说。
ClickHouse 支持运行在主流 64 位 CPU 架构的 Linux 操作系统上,可以通过源码编译、预编译压缩包、Docker 镜像和 RPM 等多种方法进行安装。这里我们着重介绍一下离线 RPM 的安装方法,因为它最常用。
先介绍一下环境,我们使用的操作系统为 CentOS 7,是我在阿里云上的服务器,而 ClickHouse 我们选择 21.7.3.14 版本,一个非常新的版本。
1. 下载 RPM 安装包
用于安装的 RPM 包可以从仓库 https://repo.yandex.ru/clickhouse/rpm/stable/x86_64/ 中进行下载,里面包含了所有版本的 ClickHouse。
我们需要下载以下四个安装包文件:
clickhouse-client-21.7.3.14-2.noarch.rpm
clickhouse-common-static-21.7.3.14-2.x86_64.rpm
clickhouse-common-static-dbg-21.7.3.14-2.x86_64.rpm
clickhouse-server-21.7.3.14-2.noarch.rpm
2. 关闭防火墙并检查环境依赖
首先,考虑到后续的集群部署,通常建议关闭本机的防火墙,在 CentOS 7 中关闭防火墙的方法如下:
# 关闭防火墙
systemctl stop firewalld.service
# 禁用开机启动项
systemctl disable firewalld.service
接着需要验证当前服务器的 CPU 是否支持 SSE 4.2 指令集,因为向量化执行需要用到这项特性:
grep -q sse4_2 /proc/cpuinfo && echo "支持 SSE 4.2 指令集" || echo "不支持 SSE 4.2 指令集"

如果不支持 SSE 指令集,则不能使用上面下载的 RPM 安装包,而是需要使用源码编译的方式安装,当然现在的 CPU 基本上都是支持的。
3. 安装 ClickHouse
我们将上面下载地 RPM 包上传到服务器,然后进行安装。
# 使用通配符,会将当前目录下所有的 rpm 包全部依次安装,非常方便
# 因为我们是安装 ClickHouse,所以该目录除了 ClickHouse 的 rpm 包之外,最好不要有其它的 rpm 包
rpm -ivh ./*.rpm
注意,在安装到 clickhouse-server 的时候会提示你设置密码:
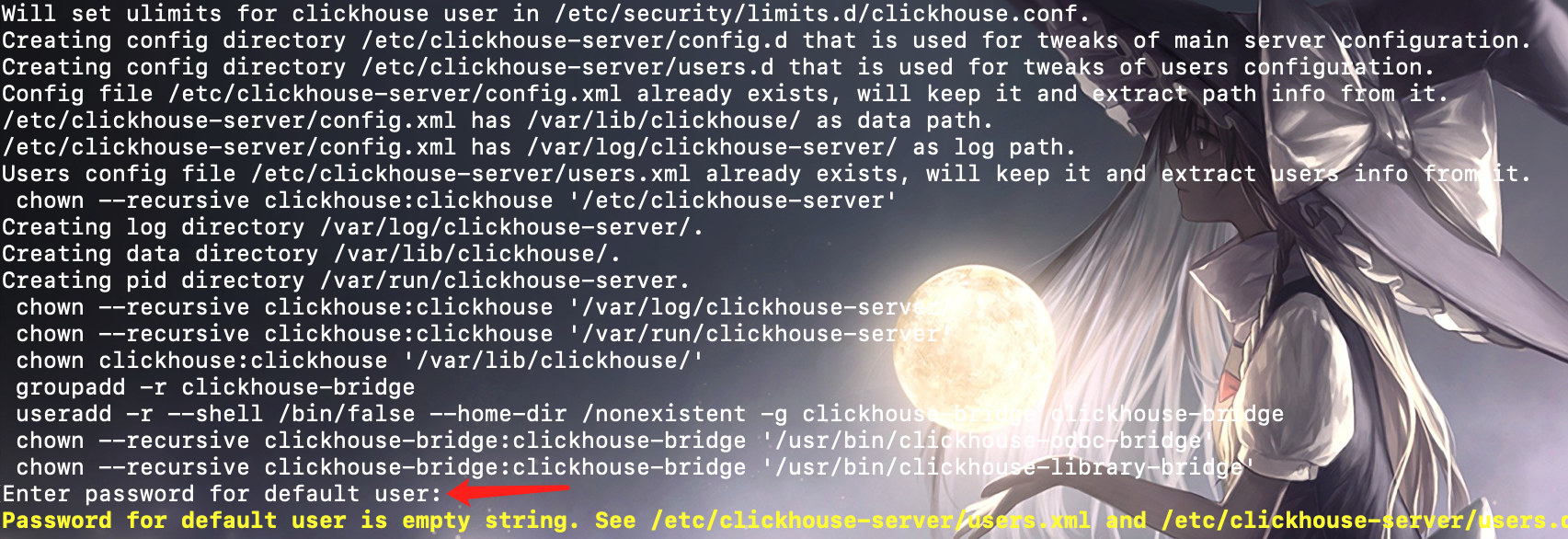
因为 ClickHouse 在安装的时候会有一个默认的 default 用户,这里会提示你给 default 设置密码,因为 ClickHouse 和 MySQL、PostgreSQL 等数据库一样,也具有用户管理权限。老版本默认没有密码,新版本会让你主动设置,这里我们就不设置了,直接回车就好,这样后续在连接的时候就不需要密码了。
最后,如果想卸载 ClickHouse 也很简单,至于以下几步:
yum remove clickhouse-client clickhouse-common-static clickhouse-common-static-dbg clickhouse-server -y
rm -rf /var/lib/clickhouse
rm -rf /etc/clickhouse-*
rm -rf /var/log/clickhouse-server
目录结构
程序在安装的时候会自动构建整套目录结构,接下来分别说明它们的作用。
1) 首先是核心目录部分
/etc/clickhouse-server:服务端的配置文件目录, 包括全局配置 config.xml 和用户配置 users.xml 等。
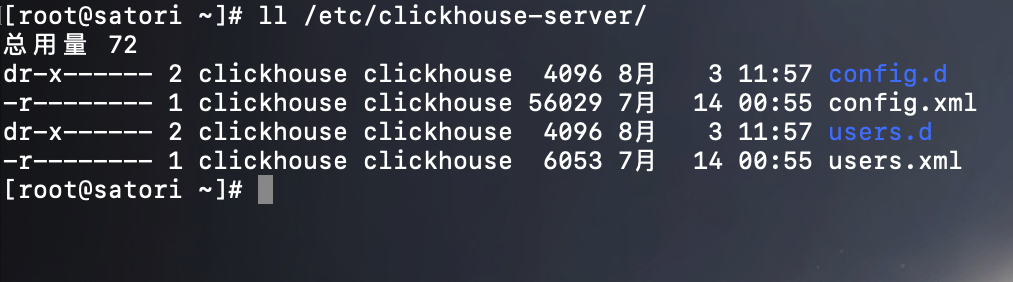
/var/lib/clickhouse:默认的数据存储目录(通常会修改默认存储路径,将数据保存到大容量磁盘挂载的路径),通过 config.xml 进行修改。
/var/log/clickhouse-server:默认保存日志的目录(通常会修改默认存储路径,将日志保存到大容量磁盘挂载的路径),通过 config.xml 进行修改。
2) 接下来是配置文件部分
/etc/security/limits.d/clickhouse.conf:文件句柄数量的配置,默认值如下所示:
[root@satori ~]# cat /etc/security/limits.d/clickhouse.conf
clickhouse soft nofile 262144
clickhouse hard nofile 262144
[root@satori ~]#
该配置也可以通过 config.xml 中的 max_open_files 参数指定。
/etc/cron.d/clickhouse-server:cron 定时任务配置, 用于恢复因异常原因中断的 ClickHouse 服务进程, 其默认的配置如下所示:
[root@satori ~]# cat /etc/cron.d/clickhouse-server
#*/10 * * * * root ((which service > /dev/null 2>&1 && (service clickhouse-server condstart ||:)) || /etc/init.d/clickhouse-server condstart) > /dev/null 2>&1
[root@satori ~]#
可以看到默认情况,每隔 10 秒就会使用 condstart 尝试启动一次 ClickHouse 服务,如果 ClickHouse 服务正在运行,则跳过;如果没有运行,则启动。
3) 最后是在 /usr/bin 目录下的启动文件
ClickHouse 相关的启动文件都位于 /usr/bin 目录下。
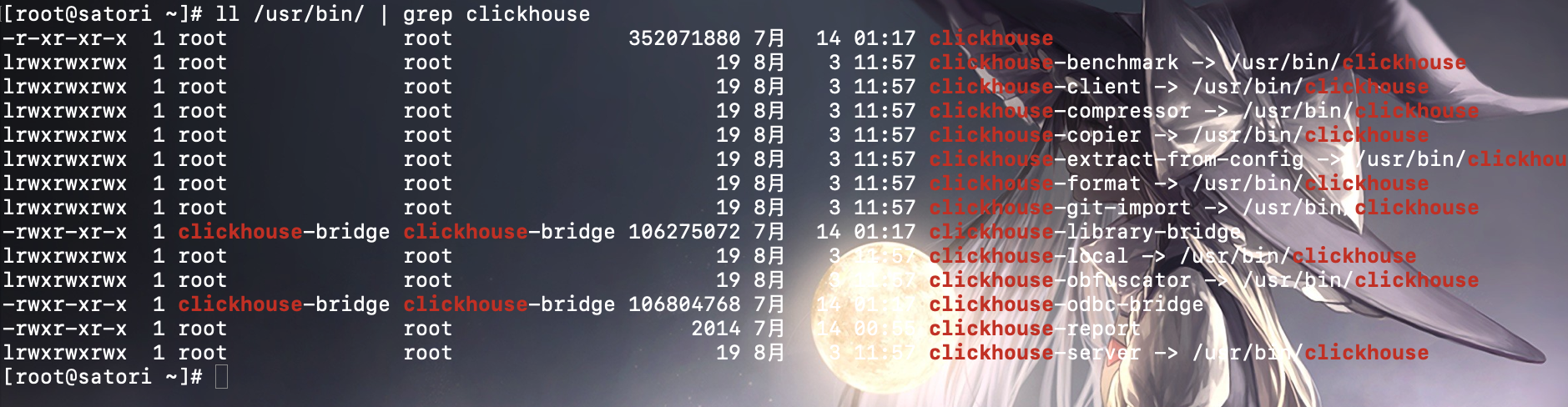
可执行文件数量还是蛮多的,其中四个最常用。
clickhouse: 主程序的可执行文件clickhouse-client: 一个指向 ClickHouse 可执行文件的软连接, 供客户端连接使用clickhouse-server: 一个指向 ClickHouse 可执行文件的软连接, 供服务端启动使用clickhouse-compressor: 内置提供的压缩工具, 可用于数据的正压反解
启动命令
ClickHouse 给我们提供了非常优雅的启动方式。
- 启动 ClickHouse:clickhouse start
- 关闭 ClickHouse:clickhouse stop
- 重启 ClickHouse:clickhouse restart
注意:在安装 ClickHouse 的时候,系统会自动创建一个名为 clickhouse 的用户,启动脚本会基于此用户来启动服务。因此我们需要将 clickhouse 用户具备相关目录的权限,如果不赋权限,ClickHouse 可能会启动失败。
chown clickhouse.clickhouse /var/log/clickhouse-server/ -R
chown clickhouse.clickhouse /var/lib/clickhouse/ -R
# 如果后续你修改了配置文件,改变了 ClickHouse 的数据存储目录,那么也要记得赋给它相应的权限
另外,上面通过 clickhouse start 启动的时候我们没有指定配置文件,没错,通过这种方式启动的话,会自动加载 /etc/clickhouse-server/config.xml。
但如果我们想手动指定配置文件的话,那么需要使用 clickhouse-server。
clickhouse-server --config-file /etc/clickhouse-server/config.xml --daemon
--config-file 负责指定配置文件,这样即使将配置文件放在了别的地方也没有关系,因为我们可以显式地指定它的位置;--daemon 表示后台启动,因为默认是前台启动的。
但是注意:使用 clickhouse-server 启动的话,不能使用 root,需要切换到 clickhouse 用户,所以我们应该这么做。
sudo -u clickhouse clickhouse-server --config-file /etc/clickhouse-server/config.xml --daemon
注意:sudo -u 后面的 clickhouse 指的是名为 clickhouse 的用户,clickhouse start 里面的 clickhouse 指的是 /usr/bin 里面的可执行文件。这里由于我们配置文件就在默认路径下,所以也可以直接使用 clickhouse start 启动,默认加载 /etc/clickhouse-server/config.xml、并且后台启动。至于关闭的话,直接 clickhouse stop 即可。
客户端的访问接口
ClickHouse 服务端的底层访问接口支持 TCP 和 HTTP 两种方式,其中 TCP 拥有更好的性能,其默认监听 9000 端口,主要用于集群间的内部通信及 clickhouse-client 客户端进行连接;而 HTTP 协议则拥有更好的兼容性,可以通过 REST 服务的形式被广泛用于编程语言的客户端,其默认监听 8123 端口。
下面我们来介绍几种连接方式。
使用客户端 clickhouse-client 连接服务端
通过 clickhouse start 将服务启动之后,我们就可以通过客户端进行连接了,通过 clickhouse-client,默认会连接到本机的 9000 端口,并使用 default 用户,如果想单独指定的话可使用如下方式:
clickhouse-client --host 地址 --port 端口 --user 用户 --password 密码
这里我们的服务端默认也是监听 9000 端口,并且 default 用户还没有密码,所以直接输入 clickhouse-client 即可连接上。
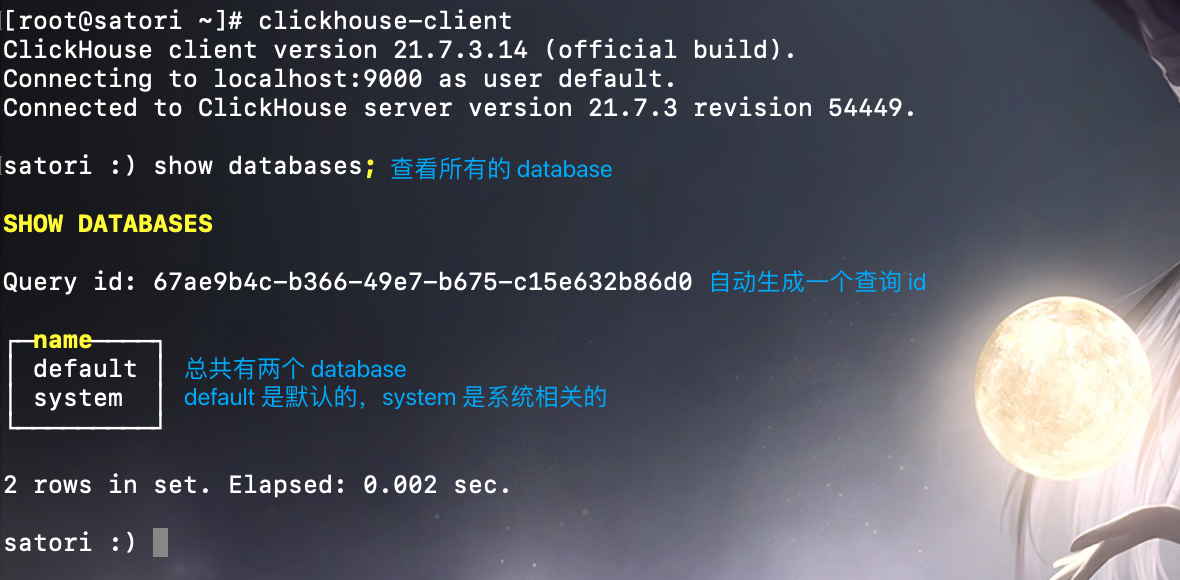
我们看到连接成功,并且也查询成功了,我们需要注意一下图中 show databases 前面的提示内容,很明显它就是我们刚才设置的 FQDN。至此,单节点 ClickHouse 的安装就算完毕了,至于集群的搭建我们后面会说。
插句题外话,如果我们想要更新 ClickHouse,那么直接下载新版的 ClickHouse RPM 包即可,然后进行更新:
rpm -Uvh ./*.rpm
升级的时候,原有的配置均会保留。
然后我们再来聊一下 clickhouse-client,我们上面通过输入 clickhouse-client 进入命令行、然后再执行 SQL 的方式叫做 "交互式执行",一般用于调试、运维、开发和测试等场景。
通过交互式执行的 SQL 语句,相关查询结果会统一记录到 ~/.clickhouse-client-history 文件中,可以作为审计之用。
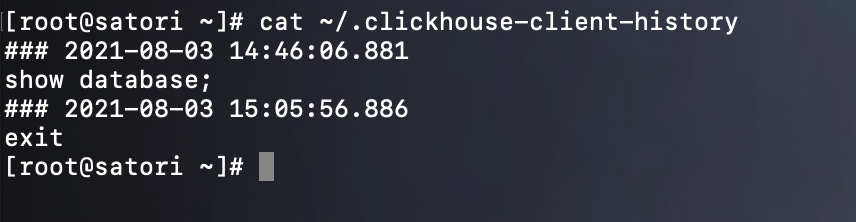
但除了交互式执行之外,还有非交互式执行。非交互式执行主要用于批处理场景,诸如对数据的导入和导出操作,在执行脚本命令时,需要追加 --query 参数指定执行的 SQL 语句。举个栗子:
cat xxx.csv | clickhouse-client --query "INSERT INTO some_table FORMAT CSV"
在导入数据时,它可以接收操作系统的 stdin 标准输入作为写入的数据。所以 cat 命令读取的文件流,将会作为 INSERT 查询的数据输入,而在数据导出时,则可以输出流重定向到文件:
clickhouse-client --query "SELECT * FROM some_table" >> xxx.csv
默认情况下,clickhouse-client 一次只能运行一条 SQL 语句,如果需要执行多次查询,则需要在循环中重复执行,这显然不是一种高效的方式。此时可以追加 --multiquery 参数,它可以支持一次运行多条SQL查询,多条查询之间使用分号分隔,比如:
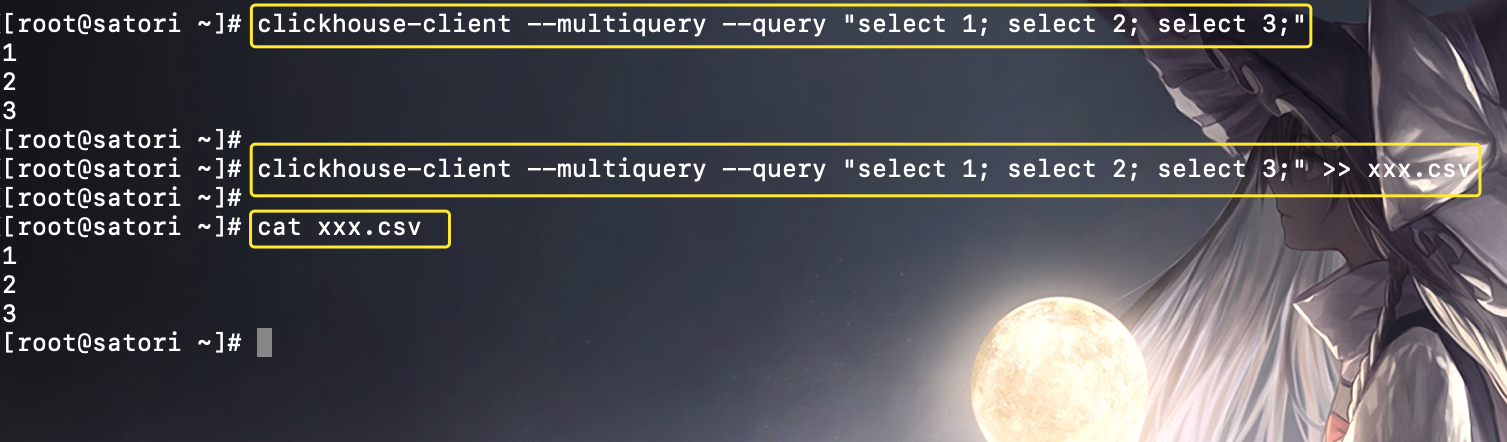
多条 SQL 的查询结果集会依次按照顺序返回。
以上就是 clickhouse-client 的两种运行方式,由于提供了非交互式执行的功能,所以 ClickHouse 的客户端比其它数据库的客户端要强大一些。下面整理一下 clickhouse-client 常用的相关参数:
--host/-h: 指定连接的服务端的地址, 默认是 localhost,如果服务端的地址不是 localhost, 则需要依靠此参数进行指定, 例如 clickhouse-client -h xx.xx.xx.xx--port: 服务端的 TCP 端口, 默认是 9000,如果服务端监听的不是 9000, 则需要此参数指定--user/-u: 登录的用户名, 默认是 default。如果使用非 default 的用户名登录, 则需要使用此参数指定--password: 登录的密码, 默认值为空。如果在用户定义中未设置密码, 则无需填写(比如默认的 default 用户,我们没有设置密码)--database/-d: 登录之后所在的数据库, 默认为 default--query/-q: 只能在非交互式查询时使用, 用于执行指定的 SQL 语句--multiquery/-n: 在非交互式执行时, 允许一次运行多条 SQL 语句, 多条语句之间用分号隔开--time/-t: 在非交互式执行时, 会打印每条 SQL 的执行时间
更多参数可以通过 clickhouse-client --help 查看,数量多到恐怖。
Python 连接 ClickHouse 服务端
首先 ClickHouse 支持使用 JDBC 连接,但我本身不是 JAVA 方向的,所以这里只介绍使用 Python 连接 ClickHouse 的方式。
Python 连接 ClickHouse 的话需要安装一个第三方库,直接 pip install clickhouse-driver 即可。
注意:我们说 HTTP 协议使用的是 8123 端口,但是 Python 这个包比较特殊,它和 clickhouse-client 一样,使用的也是 TCP 协议,也就是说端口需要指定为 9000。
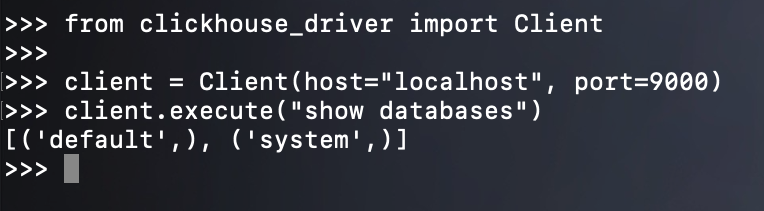
使用 Python 是可以连接的,但是注意:我们这里是在服务器上使用 Python 连接的,如果需要在其它机器上连接的话,那么就不能使用 localhost 了。
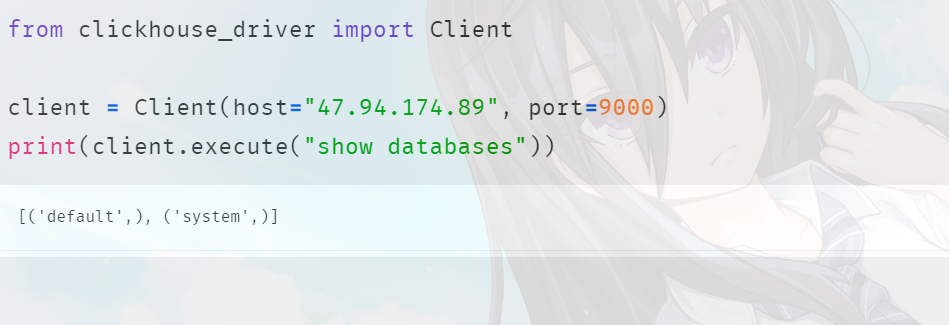
from clickhouse_driver import Client
# 需要指定具体的 ip
client = Client(host="47.94.174.89", port=9000)
print(client.execute("show databases"))
不过此时仍无法在其它节点上访问,因为我们还需要修改一下服务端的配置,vim /etc/clickhouse-server/config.xml:
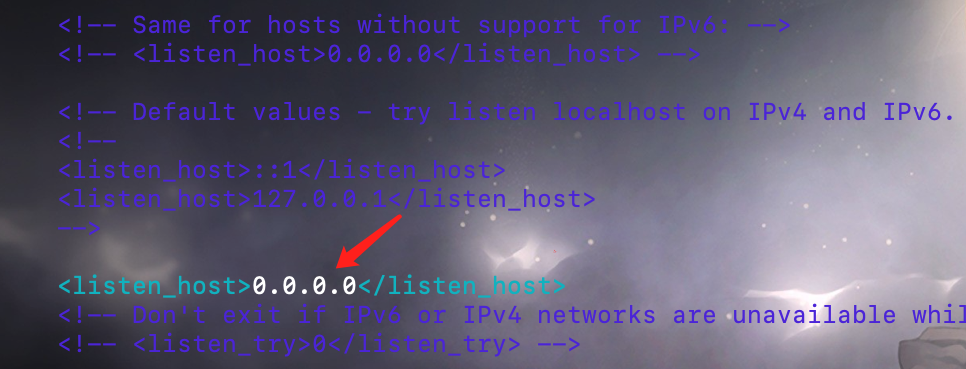
listen_host 这个标签默认是被注释掉的,也就是只监听来自本机的请求。这里我们将注释打开,或者不管注释,直接手动增加一条。
<!-- 改成 0.0.0.0,这样即可接收来自其它机器上的请求 -->
<listen_host>0.0.0.0</listen_host>
此时 Python 即可在其它节点上访问了,注意:服务器的 9000 端口是要对外开放的,这里我阿里云服务器的 9000、8123 端口都已经对外了。
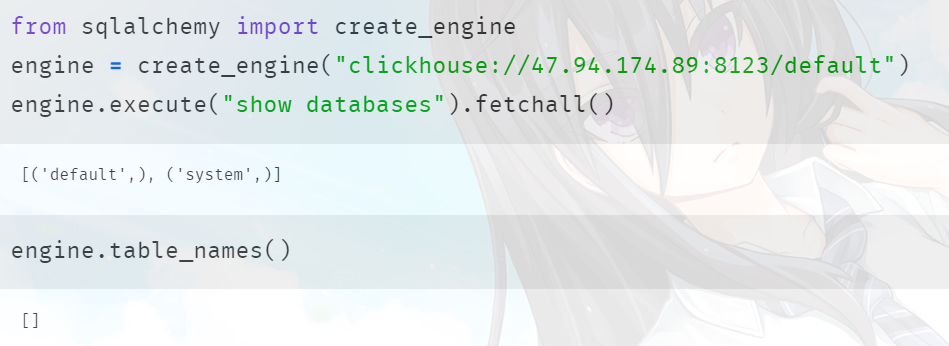
此外我们还可以通过 sqlalchemy 去连接,但是默认情况下 sqlalchemy 找不到对应的 dialect,我们需要再安装一个模块:pip install sqlalchemy_clickhouse,安装之后就可以使用了。
但是有一点需要注意:使用 sqlalchemy_clickhouse 的话,那么连接的端口就不能是 9000 了,而是 8123。更准确的说,需要使用 HTTP 端口。
以上就是 Python 连接 ClickHouse 的两种方式,还是挺容易的。
DataGrip 连接 ClickHouse 服务端
DataGrip 是 JetBrains 公司开发的一个 IDE,专门负责连接数据库,其中也包含了对 ClickHouse 的支持。

点击之后下载相应的驱动,然后输入相关信息即可。
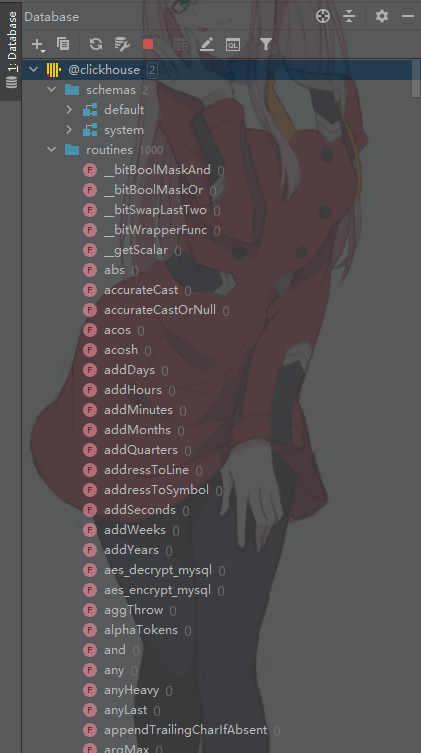
我们看到连接成功,里面还显示了 ClickHouse 支持的内置函数。然后我们执行 SQL 语句测试一下:
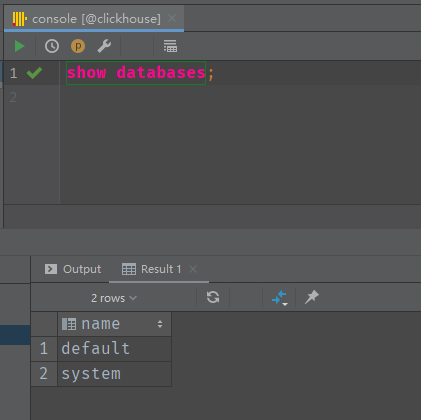
内置的实用工具
我们说 /usr/bin 下面包含了很多关于 ClickHouse 的启动文件,除了之前介绍的四个,这里再介绍两个,分别是 clickhouse-local 和 clickhouse-benchmark。
clickhouse-local
clickhouse-local 可以独立运行大部分的 SQL 查询,不需要依赖任何 ClickHouse 服务端程序,它可以理解为 ClickHouse 服务的单机版内核,是一个轻量级的应用程序。clickhouse-local 只能够使用 File 引擎(或者称之为表引擎),关于引擎后面会展开。它的数据与同机运行的 ClickHouse 服务之间也是完全隔离的,互相并不能访问。
clickhouse-local 是非交互式的,每次执行都需要指定数据来源,例如通过 stdin 标准输入,以 echo 打印作为数据来源:

也可以借助操作系统的命令,实现对系统用户内存用量的查询。
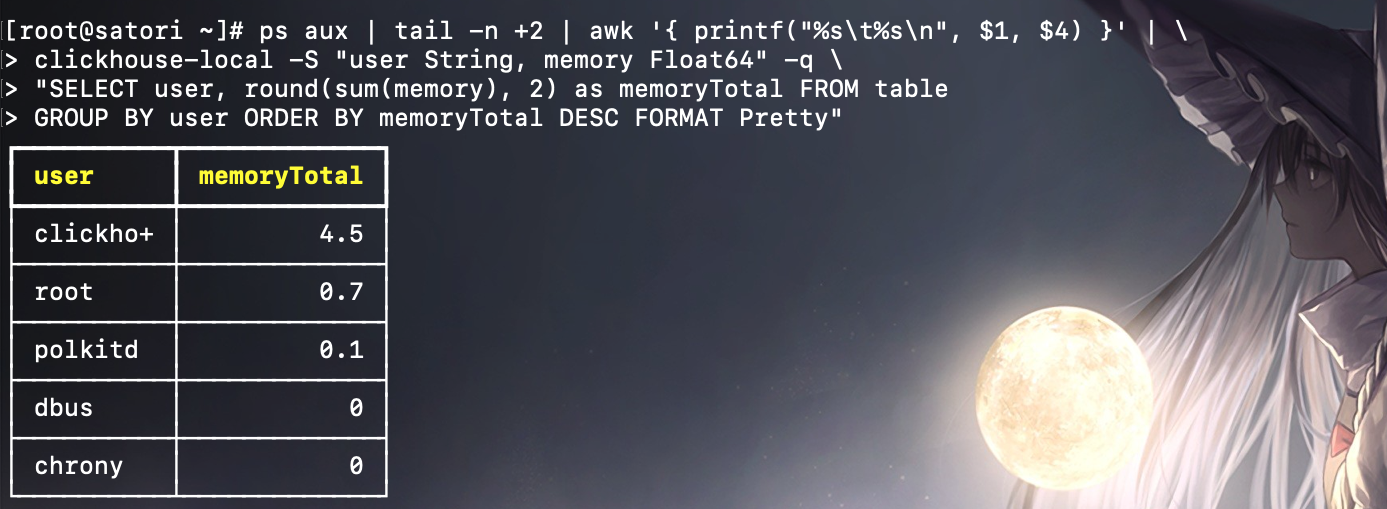
clickhouse-local 的参数用法可以通过 --help 查看,但是个人觉得不是很常用。
clickhouse-benchmark
clickhouse-benchmark 是基准测试的小工具,它可以自动运行 SQL 查询,并生成对应的运行指标报告,例如执行下面的语句启动测试:
echo "SELECT * FROM table" | clickhouse-benchmark -i 5
执行之后,按照指定参数的查询会被执行 5 次。执行完毕之后,会显示包含 QPS、RPS 等指标信息的报告,还会列出各百分位的查询执行时间。
如果想测试多条 SQL,此时就需要将 SQL 写在文件中,然后通过 clickhouse-benchmark -i 5 < 文件路径,将里面的 SQL 按照顺序依次执行。
这里我就不使用具体的数据测试了,有兴趣可以自己尝试一下。
clickhouse-benchmark 的一些核心参数可以通过 --help 查看。
以上我们介绍了基于离线 RPM 包安装 ClickHouse 的整个过程,当然也可以使用其它方式安装,比如:在线安装、或者使用 docker 等等。事实上,这种离线安装的方式也不麻烦,相反个人觉得还很简单。然后还介绍了访问 ClickHouse 的两个接口,TCP 接口和 HTTP 接口,以及如何使用 Python 去访问。那么就来学习 ClickHouse 的具体语法了,首先会从数据定义开始。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号