《深度剖析CPython解释器》31. Python 和 C / C++ 联合编程
楔子
Python 和 C / C++ 混合编程已经屡见不鲜了,那为什么要将这两种语言结合起来呢?或者说,这两种语言混合起来能给为我们带来什么好处呢?首先,Python 和 C / C++ 联合,无非两种情况。
1. C / C++ 为主导的项目中引入 Python;2. Python 为主导的项目中引入 C / C++;
首先是第一种情况,因为 C / C++ 是编译型语言,而它们的编译调试的成本是很大的。如果用 C / C++ 开发一个大型项目的话,比如游戏引擎,这个时候代码的修改、调试是无可避免的。而对于编译型语言来说,你对代码做任何一点改动都需要重新编译,而这个耗时是比较长的,所以这样算下来成本会非常高。这个时候一个比较不错的做法是,将那些跟性能无关的内容开放给脚本,可以是 Lua 脚本、也可以是 Python 脚本,而脚本语言不需要编译,我们可以随时修改,这样可以减少编译调试的成本。还有就是引入了 Python 脚本之后,我们可以把 C / C++ 做的更加模块化,由 Python 将 C / C++ 各个部分联合起来,这样可以降低 C / C++ 代码的耦合度,从而加强可重用性。
然后是第二种情况,Python 项目中引入 C / C++。我们知道 Python 的效率不是很高,如果你希望 Python 能够具有更高的性能,那么可以把一些和性能相关的逻辑使用 C / C++ 进行重写。此外,Python 有大量的第三方库,特别是诸如 Numpy、Pandas、Scipy 等等和科学计算密切相关的库,底层都是基于 C / C++ 的。再比如机器学习,底层核心算法都是基于 C / C++ 编写的,然后在业务层暴露给 Python 去调用,因此对于一些需要高性能的领域,Python 是必须要引入 C / C++ 的。此外 Python 还有一个最让人诟病的问题,就是由于 GIL 的限制导致 Python 无法有效利用多核,而引入 C / C++ 可以绕过 GIL 的限制。
此外有一个项目叫做 Cython,从名字你就能看出来这是将 Python 和 C / C++ 结合在了一起,之所以把它们结合在一起,很明显,因为这两者不是对立的,而是互补的。Python 是高阶语言、动态、易于学习,并且灵活。但是这些优秀的特性是需要付出代价的,因为 Python 的动态性、以及它是解释型语言,导致其运行效率比静态编译型语言慢了好几个数量级。而 C / C++ 是非常古老的静态编译型语言,并且至今也被广泛使用。从时间来算的话,其编译器已有将近半个世纪的历史,在性能上做了足够的优化。而 Cython 的出现,就是为了让你编写的代码具有 C / C++ 的高效率的同时,还能有 Python 的开发速度。
而笔者本人是主 Python 的,所以我们只会介绍第二种,也就是 Python 项目中引入 C / C++。而在 Python 中引入 C / C++,也涉及两种情况。第一种是,Python 通过 ctypes 模块直接调用 C / C++ 编写好的动态链接库,此时不会涉及任何的 Python / C API,只是单纯的通过 ctypes 模块将 Python 中的数据转成 C 中的数据传递给函数进行调用,调用完之后再将返回值转成 Python 中的数据。因此这种方式它和 Python 底层提供的 Python / C API 无关,和 Python 的版本也无关,因此会很方便。但很明显这种方式是有局限性的,至于局限性在哪儿,我们后面慢慢聊,因此还有一种选择是通过 C / C++ 为 Python 编写扩展模块的方式,来在 Python 中引入 C / C++,比如 OpenCV。
无论是 ctypes 调用动态链接库,还是 C / C++ 为 Python 编写扩展模块,我们都会介绍。
环境准备
首先是 Python 的安装,估计这应该不用我说了,我这里使用的 Python 版本是 3.8.7。
然后重点是 C / C++ 编译器的安装,我这里使用的是 64 位的 Windows 10 操作系统,所以我们需要手动安装相应的编译环境。可以下载一个 gcc,然后配置到环境变量中,就可以使用了。
或者安装 Visual Studio,我的 Visual Studio 版本是 2017,在命令行中可以通过 cl 命令进行编译。
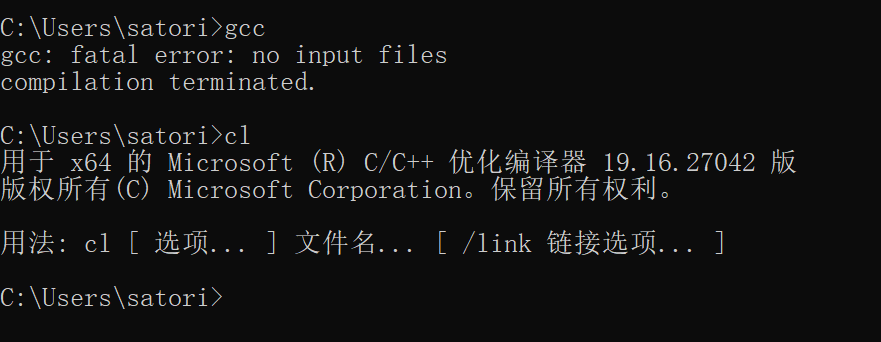
当然这两种命令的使用方式都是类似的,或者你也可以使用 Linux,比如 CentOS,基本上自带 gcc。当然 Linux 的话,环境什么的比较简单,这里就不再废话了。重点是如果你是在 Windows 上使用 Visual Studio 的话,在命令行中输入命令 cl,很可能会提示你命令找不到;再或者编译的时候,会提示你 fatal error 不包括路径集等等。出现以上问题的话,说明你的环境变量没有配置正确,下面来说一下环境变量的配置。再次强调,我操作系统是 64 位 Windows 10,Visual Studio 版本是 2017,相信大部分人应该我是一样的,如果完全一样的话,那么路径啥的应该也是一致的,当然最好还是检查一下。
首先在 path 中添加如下几个路径:
C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Tools\MSVC\14.16.27023\bin\Hostx64\x64C:\Program Files (x86)\Windows Kits\10\bin\10.0.17763.0\x64C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\Common7\IDE

然后,新建一个环境变量。
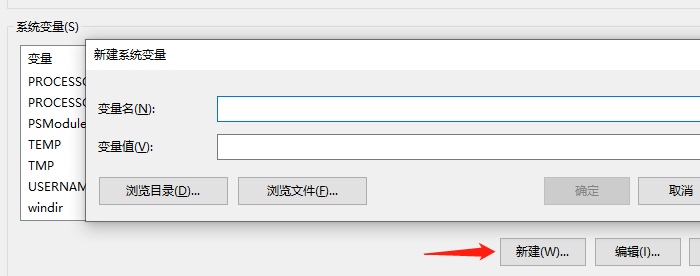
变量名为 LIB,变量值为以下路径,由于是写在一行,所以路径之间需要使用分号进行隔开。
C:\Program Files (x86)\Windows Kits\10\Lib\10.0.17763.0\um\x64C:\Program Files (x86)\Windows Kits\10\Lib\10.0.17763.0\ucrt\x64C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Tools\MSVC\14.16.27023\lib\x64
最后,还是新建一个环境变量,变量名为 INCLUDE,变量值为以下路径:
C:\Program Files (x86)\Windows Kits\10\Include\10.0.17763.0\ucrtC:\Program Files (x86)\Windows Kits\10\Lib\10.0.17763.0\umC:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Tools\MSVC\14.16.27023\include
以上就是 Windows 系统中配置 Visual Studio 2017 环境变量的整个过程,配置完毕之后重启命令行之后就可以使用了。注意:以上是我当前机器的路径,如果你的配置和我不一样,记得仔细检查。
不过个人更习惯使用 gcc,因此后面我们会使用 gcc 进行编译。
Python ctypes 模块调用 C / C++ 动态链接库
通过 ctypes 模块(Python 自带的)调用 C / C++ 动态库,也算是 Python 和 C / C++ 联合编程的一种方案,而且是最简单的一种方案。因为它只对你的操作系统有要求,比如 Windows 上编译的动态库是 .dll 文件,Linux 上编译的动态库是 .so 文件,只要操作系统一致,那么任何提供了 ctypes 模块的 Python 解释器都可以调用。这种方式的使用场景是 Python 和 C / C++ 不需要做太多的交互,比如嵌入式设备,可能只是简单调用底层驱动提供的某个接口而已。
再比如我们使用 C / C++ 写了一个高性能的算法,然后通过 Python 的 ctypes 模块进行调用也是可以的,但我们之前说使用 ctypes 具有相应的局限性,这个局限性就是 C / C++ 提供的接口不能太复杂。因为 ctypes 提供的交互能力还是比较有限的,最明显的问题就是不同语言数据类型不同,一些复杂的交互方式还是比较难做到的,还有多线程的控制问题等等。
举个小栗子
首先我们来举个栗子,演示一下。
int f(){
return 123;
}
这是个简单到不能再简单的 C 函数,然后我们来编译成动态库。
编译方式: gcc -o .dll文件或者.so文件 -shared c或者c++源文件
如果你用的是 Visual Studio,那么把 gcc 换成 cl 即可。我当前的源文件叫做 main.c,我们编译成 main.dll,那么命令就需要这么写:gcc -o main.dll -shared main.c。
编译成功之后,我们通过 ctypes 来进行调用。
import ctypes
# 使用 ctypes 很简单,直接import进来,然后使用 ctypes.CDLL 这个类来加载动态链接库
# 或者是用 ctypes.cdll.LoadLibrary("./main.dll")
lib = ctypes.CDLL(r"./main.dll") # 加载之后就得到了动态链接库对象
# 我们可以直接通过 . 的方式去调用里面的函数了,会发现成功打印
print(lib.f()) # 123
# 但是为了确定是否存在这个函数,我们一般会使用反射去获取
# 因为如果函数不存在通过 . 的方式调用会抛异常的
func = getattr(lib, "f", None)
if func:
print(func) # <_FuncPtr object at 0x0000029F75F315F0>
func() # hello world
# 不存在 f2 这个函数,所以得到的结果为 None
func1 = getattr(lib, "f2", None)
print(func1) # None
所以使用ctypes去调用动态链接库非常方便,过程很简单:
1. 通过 ctypes.CDLL 去加载动态库,另外注意的是:dll 或者 so 文件的路径最好是绝对路径,即便不是也要表明层级。比如我们这里的 py 文件和 dll 文件是在同一个目录下,但是我们加载的时候不可以写 main.dll,这样会报错找不到,我们需要写成 ./main.dll2. 加载动态链接库之后会返回一个对象,我们上面起名为 lib,这个 lib 就是得到的动态链接库了3. 然后可以直接通过 lib 调用里面的函数,但是一般我们会使用反射的方式来获取,因为不知道函数到底存不存在,如果不存在直接调用会抛出异常,如果存在这个函数我们才会调用。
Linux 和 Mac 也是一样的,这里不演示了,只不过编译之后的名字不一样。Linux 系统是 .so,Mac 系统是 .dylib。
此外我们也可以在 C 中进行打印,举个栗子:
#include <stdio.h>
void f(){
printf("hello world");
}
然后编译,进行调用。
import ctypes
lib = ctypes.CDLL(r"./main.dll") # 加载之后就得到了动态链接库对象
lib.f() # hello world
另外,Python 的 ctypes 调用的都是 C 语言函数,如果你用的 C++ 编译器,那么会编译成 C++ 中的函数。我们知道 C 语言的函数不支持重载,说白了就是不可以定义两个同名的函数,而 C++ 的函数是支持重载的,只要参数类型不一致即可,然后调用的时候会根据传递的参数调用对应的函数。所以当我们使用 C++ 编译器的时候,需要通过 extern "C" 将函数包起来,这样 C++ 编译器在编译的时候会将其编译成 C 的函数。
#include <stdio.h>
// 注意: 我们不能直接通过 extern "C" {} 将函数包起来, 因为这不符合 C 的语法, extern 在 C 中是用来声明一个外部变量的
// 所以我们应该使用宏替换的方式, 如果是 C++ 编译器的话, 那么编译的时候 #ifdef __cplusplus 是会通过的, 因为 __cplusplus 是一个预定义的宏
// 如果是 C 编译器, 那么 #ifdef __cplusplus 不会通过
#ifdef __cplusplus
extern "C" {
#endif
void f() {
printf("hello world\n");
}
#ifdef __cplusplus
}
#endif
当然我们在介绍 ctypes 使用的 gcc 都是 C 编译器,会编译成 C 的函数,所以后面 extern "C" 的逻辑就不加了。
我们以上就演示了,如何通过 Python 的 ctypes 模块来调用 C / C++ 动态库,但显然目前还是远远不够的。比如说:
double f() {
return 3.14;
}
然后我们调用的时候,会得到什么结果呢?来试一下:
import ctypes
lib = ctypes.CDLL(r"./main.dll") # 加载之后就得到了动态链接库对象
print(lib.f()) # 1374389535
我们看到得到一个不符合预期的结果,我们暂且不纠结它是怎么来的,现在的问题是它返回的为什么不是 3.14 呢?原因是 ctypes 在解析的时候默认是按照整型来解析的,但很明显我们 C 函数返回是浮点型,因此我们在调用之前需要显式的指定其返回值。
不过在这之前,我们需要先来看看 Python 类型和 C 类型之间的转换关系。
Python 类型与 C 语言类型之间的转换
我们说可以使用 ctypes 调用动态链接库,主要是调用动态链接库中使用C编写好的函数,但这些函数肯定都是需要参数的,还有返回值,不然编写动态链接库有啥用呢。那么问题来了,不同的语言变量类型不同,所以 Python 能够直接往 C 编写的函数中传参吗?显然不行,因此 ctypes 提供了大量的类,帮我们将 Python 中的类型转成 C 语言中的类型。
我们说了,Python 中类型不能直接往 C 语言的函数中传递(整型是个例外),而 ctypes 可以帮助我们将 Python 的类型转成 C 类型。而常见的类型分为以下几种:数值、字符、指针。
数值类型转换
C 语言的数值类型分为如下:
int:整型unsigned int:无符号整型short:短整型unsigned short:无符号短整型long:长整形unsigned long:无符号长整形long long:64位机器上等同于 longunsigned long long:等同于 unsigned longfloat:单精度浮点型double:双精度浮点型long double:看成是 double 即可_Bool:布尔类型ssize_t:等同于 long 或者 long longsize_t:等同于 unsigned long 或者 unsigned long long

下面来演示一下:
import ctypes
# 下面都是 ctypes 中提供的类,将 Python 中的对象传进去,就可以转换为 C 语言能够识别的类型
print(ctypes.c_int(1)) # c_long(1)
print(ctypes.c_uint(1)) # c_ulong(1)
print(ctypes.c_short(1)) # c_short(1)
print(ctypes.c_ushort(1)) # c_ushort(1)
print(ctypes.c_long(1)) # c_long(1)
print(ctypes.c_ulong(1)) # c_ulong(1)
# c_longlong 等价于 c_long,c_ulonglong 等价于c_ulong
print(ctypes.c_longlong(1)) # c_longlong(1)
print(ctypes.c_ulonglong(1)) # c_ulonglong(1)
print(ctypes.c_float(1.1)) # c_float(1.100000023841858)
print(ctypes.c_double(1.1)) # c_double(1.1)
# 在64位机器上,c_longdouble等于c_double
print(ctypes.c_longdouble(1.1)) # c_double(1.1)
print(ctypes.c_bool(True)) # c_bool(True)
# 相当于c_longlong和c_ulonglong
print(ctypes.c_ssize_t(10)) # c_longlong(10)
print(ctypes.c_size_t(10)) # c_ulonglong(10)
字符类型转换、指针类型转换
C 语言的字符类型分为如下:
char:一个 ascii 字符或者 -128~127 的整型wchar:一个 unicode 字符unsigned char:一个 ascii 字符或者 0~255 的一个整型
C 语言的指针类型分为如下:
char *:字符指针wchar_t *:字符指针void *:空指针

import ctypes
# 必须传递一个字节(里面是 ascii 字符),或者一个 int,来代表 C 里面的字符
print(ctypes.c_char(b"a")) # c_char(b'a')
print(ctypes.c_char(97)) # c_char(b'a')
# 传递一个 unicode 字符,当然 ascii 字符也是可以的,并且不是字节形式
print(ctypes.c_wchar("憨")) # c_wchar('憨')
# 和 c_char 类似,但是 c_char 既可以传入单个字节、也可以传整型,而这里的 c_byte 则要求必须传递整型。
print(ctypes.c_byte(97)) # c_byte(97)
print(ctypes.c_ubyte(97)) # c_ubyte(97)
# c_char_p 就是 c 里面字符数组了,其实我们可以把它看成是 Python 中的 bytes 对象
# char *s = "hello world";
# 那么这里面也要传递一个 bytes 类型的字符串,返回一个地址
print(ctypes.c_char_p(b"hello world")) # c_char_p(2082736374464)
# 直接传递一个字符串,同样返回一个地址
print(ctypes.c_wchar_p("憨八嘎~")) # c_wchar_p(2884583039392)
# ctypes.c_void_p后面演示
常见的类型就是上面这些,至于其他的类型,比如整型指针、数组、结构体、回调函数等等,ctypes 也是支持的,我们后面会介绍。
参数传递
下面我们来看看如何传递参数。
#include <stdio.h>
void test(int a, float f, char *s)
{
printf("a = %d, b = %.2f, s = %s\n", a, f, s);
}
这是一个很简单的 C 文件,然后编译成 dll 之后,让 Python 去调用,这里我们编译之后的文件名叫做还叫做 main.dll。
from ctypes import *
lib = CDLL(r"./main.dll") # 加载之后就得到了动态链接库对象
try:
lib.test(1, 1.2, b"hello world")
except Exception as e:
print(e) # argument 2: <class 'TypeError'>: Don't know how to convert parameter 2
# 我们看到一个问题,那就是报错了,告诉我们不知道如何转化第二个参数
# 正如我们之前说的,整型是会自动转化的,但是浮点型是不会自动转化的
# 因此我们需要使用 ctypes 来包装一下,当然还有整型,即便整型会自动转,我们还是建议手动转化一下
# 这里传入 c_int(1) 和 1 都是一样的,但是建议传入 c_int(1)
lib.test(c_int(1), c_float(1.2), c_char_p(b"hello world")) # a = 1, b = 1.20, s = hello world
我们看到完美的打印出来了,我们再来试试布尔类型。
#include <stdio.h>
void test(_Bool flag)
{
//布尔类型本质上是一个int
printf("a = %d\n", flag);
}
import ctypes
from ctypes import *
lib = ctypes.CDLL("./main.dll")
lib.test(c_bool(True)) # a = 1
lib.test(c_bool(False)) # a = 0
# 可以看到 True 被解释成了 1,False 被解释成了 0
# 我们说整型会自动转化,而布尔类型继承自整型所以布尔类型也可以直接传递
lib.test(True) # a = 1
lib.test(False) # a = 0
然后再来看看字符和字符数组的传递:
#include <stdio.h>
#include <string.h>
void test(int age, char *gender)
{
if (age >= 18)
{
if (strcmp(gender, "female") == 0)
{
printf("age >= 18, gender is female\n");
}
else
{
printf("age >= 18, gender is male\n");
}
}
else
{
if (strcmp(gender, "female") == 0)
{
printf("age < 18, gender is female\n");
}
else
{
printf("age < 18, gender is main\n");
}
}
}
from ctypes import *
lib = CDLL("./main.dll")
lib.test(c_int(20), c_char_p(b"female")) # age >= 18, gender is female
lib.test(c_int(20), c_char_p(b"male")) # age >= 18, gender is male
lib.test(c_int(14), c_char_p(b"female")) # age < 18, gender is female
lib.test(c_int(14), c_char_p(b"male")) # age < 18, gender is main
# 我们看到 C 中的字符数组,我们直接通过 c_char_p 来传递即可
# 至于单个字符,使用 c_char 即可
同理我们也可以打印宽字符,逻辑是类似的。
传递可变的字符串
我们知道 C 中不存在字符串这个概念,Python 中的字符串在 C 中也是通过字符数组来实现的,我们通过 ctypes 像 C 函数传递一个字符串的时候,在 C 中是可以被修改的。
#include <stdio.h>
void test(char *s)
{
s[0] = 'S';
printf("%s", s);
}
from ctypes import *
lib = CDLL("./main.dll")
lib.test(c_char_p(b"satori")) # Satori
我们看到小写的字符串,第一个字符变成了大写,但即便能修改我们也不建议这么做,因为 bytes 对象在 Python 中是不能更改的,所以在 C 中也不应该更改。当然不是说不让修改,而是应该换一种方式。如果是需要修改的话,那么不要使用 c_char_p 的方式来传递,而是建议通过 create_string_buffer 来给 C 语言传递可以修改字符的空间。
from ctypes import *
# 传入一个 int,表示创建一个具有固定大小的字符缓存,这里是 10 个
s = create_string_buffer(10)
# 直接打印就是一个对象
print(s) # <ctypes.c_char_Array_10 object at 0x000001E2E07667C0>
# 也可以调用 value 方法打印它的值,可以看到什么都没有
print(s.value) # b''
# 并且它还有一个 raw 方法,表示 C 语言中的字符数组,由于长度为 10,并且没有内容,所以全部是 \x00,就是C语言中的 \0
print(s.raw) # b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
# 还可以查看长度
print(len(s)) # 10
# 其它类型也是一样的
v = c_int(1)
# 我们看到 c_int(1) 它的类型就是 ctypes.c_long
print(type(v)) # <class 'ctypes.c_long'>
# 当然你把 c_int,c_long,c_longlong 这些花里胡哨的都当成是整型就完事了
# 此外我们还能够拿到它的值,调用 value 方法
print(v.value, type(v.value)) # 1 <class 'int'>
v = c_char(b"a")
print(type(v)) # <class 'ctypes.c_char'>
print(v.value, type(v.value)) # b'a' <class 'bytes'>
v = c_char_p(b"hello world")
print(type(v)) # <class 'ctypes.c_char_p'>
print(v.value, type(v.value)) # b'hello world' <class 'bytes'>
v = c_wchar_p("夏色祭")
print(type(v)) # <class 'ctypes.c_wchar_p'>
print(v.value, type(v.value)) # 夏色祭 <class 'str'>
# 因此 ctypes 中的对象调用 value 即可得到 Python 中的对象
当然 create_string_buffer 如果只传一个 int,那么表示创建对应长度的字符缓存。除此之外,还可以指定字节串,此时的字符缓存大小和指定的字节串大小是一致的:
from ctypes import *
# 此时我们直接创建了一个字符缓存
s = create_string_buffer(b"hello")
print(s) # <ctypes.c_char_Array_6 object at 0x0000021944E467C0>
print(s.value) # b'hello'
# 我们知道在 C 中,字符数组是以 \0 作为结束标记的,所以结尾会有一个 \0,因为 raw 表示 C 中原始的字符数组
print(s.raw) # b'hello\x00'
# 长度为 6,b"hello" 五个字符再加上 \0 一共 6 个
print(len(s))
当然 create_string_buffer 还可以在指定字节串的同时,指定空间大小。
from ctypes import *
# 此时我们直接创建了一个字符缓存,如果不指定容量,那么默认和对应的字符数组大小一致
# 但是我们还可以同时指定容量,记得容量要比前面的字节串的长度要大。
s = create_string_buffer(b"hello", 10)
print(s) # <ctypes.c_char_Array_10 object at 0x0000019361C067C0>
print(s.value) # b'hello'
# 长度为 10,剩余的 5 个显然是 \0
print(s.raw) # b'hello\x00\x00\x00\x00\x00'
print(len(s)) # 10
下面我们来看看如何使用 create_string_buffer 来传递:
#include <stdio.h>
int test(char *s)
{
//变量的形式依旧是char *s
//下面的操作就是相当于把字符数组的索引为5到11的部分换成" satori"
s[5] = ' ';
s[6] = 's';
s[7] = 'a';
s[8] = 't';
s[9] = 'o';
s[10] = 'r';
s[11] = 'i';
printf("s = %s\n", s);
}
from ctypes import *
lib = CDLL("./main.dll")
s = create_string_buffer(b"hello", 20)
lib.test(s) # s = hello satori
此时就成功地修改了,我们这里的 b"hello" 占五个字节,下一个正好是索引为 5 的地方,然后把索引为 5 到 11 的部分换成对应的字符。但是需要注意的是,一定要小心 \0,我们知道 C 语言中一旦遇到了 \0 就表示这个字符数组结束了。
from ctypes import *
lib = CDLL("./main.dll")
# 这里把"hello"换成"hell",看看会发生什么
s = create_string_buffer(b"hell", 20)
lib.test(s) # s = hell
# 我们看到这里只打印了"hell",这是为什么?
# 我们看一下这个s
print(s.raw) # b'hell\x00 satori\x00\x00\x00\x00\x00\x00\x00\x00'
# 我们看到这个 create_string_buffer 返回的对象是可变的,在将 s 传进去之后被修改了
# 如果没有传递的话,我们知道它是长这样的。
"""
b'hell\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
hell的后面全部是C语言中的 \0
修改之后变成了这样
b'hell\x00 satori\x00\x00\x00\x00\x00\x00\x00\x00'
我们看到确实是把索引为5到11(包含11)的部分变成了" satori"
但是我们知道 C 语言中扫描字符数组的时候一旦遇到了 \0,就表示结束了,而hell后面就是 \0,
因为即便后面还有内容也不会输出了,所以直接就只打印了 hell
"""
另外除了 create_string_buffer 之外,还有一个 create_unicode_buffer,针对于 wchar_t *,用法和 create_string_buffer 类似。
调用操作系统的库函数
我们知道 Python 解释器本质上就是使用 C 语言写出来的一个软件,那么操作系统呢?操作系统本质上它也是一个软件,不管是 Windows、Linux 还是 MacOS 都自带了大量的共享库,那么我们就可以使用 Python 去调用。
from ctypes import *
import sys
import platform
# 判断当前的操作系统平台。
# Windows 平台返回 "Windows",Linux 平台返回 "Linux",MacOS 平台返回 "Darwin"
system = platform.system()
# 不同的平台共享库不同
if system == "Windows":
lib = cdll.msvcrt
elif system == "Linux":
lib = CDLL("libc.so.6")
elif system == "Darwin":
lib = CDLL("libc.dylib")
else:
print("不支持的平台,程序结束")
sys.exit(0)
# 调用对应的函数,比如 printf,注意里面需要传入字节
lib.printf(b"my name is %s, age is %d\n", b"van", 37) # my name is van, age is 37
# 如果包含汉字就不能使用 b"" 这种形式了,因为这种形式只适用于 ascii 字符,我们需要手动 encode 成 utf-8
lib.printf("姓名: %s, 年龄: %d\n".encode("utf-8"), "古明地觉".encode("utf-8"), 17) # 姓名: 古明地觉, 年龄: 17
我们上面是在 Windows 上调用的,这段代码即便拿到 Linux 和 MacOS 上也可以正常执行。
当然这里面还支持其他的函数,我们这里以 Windows 为例:
from ctypes import *
libc = cdll.msvcrt
# 创建一个大小为 10 的buffer
s = create_string_buffer(10)
# strcpy 表示将字符串进行拷贝
libc.strcpy(s, c_char_p(b"hello satori"))
# 由于 buffer 只有10个字节大小,所以无法完全拷贝
print(s.value) # b'hello sato'
# 创建 unicode buffer
s = create_unicode_buffer(10)
libc.strcpy(s, c_wchar_p("我也觉得很变态啊"))
print(s.value) # 我也觉得很变态啊
# 比如 puts 函数
libc.puts(b"hello world") # hello world
对于 Windows 来说,我们还可以调用一些其它的函数,但是不再是通过 cdll.msvcrt 这种方式了。在 Windows 上面有一个 user32 这么个东西,我们来看一下:
from ctypes import *
# 我们通过 cdll.user32 本质上还是加载了 Windows 上的一个共享库
# 这个库给我们提供了很多方便的功能
win = cdll.user32
# 比如查看屏幕的分辨率
print(win.GetSystemMetrics(0)) # 1920
print(win.GetSystemMetrics(1)) # 1080
我们还可以用它来打开 MessageBoxA:
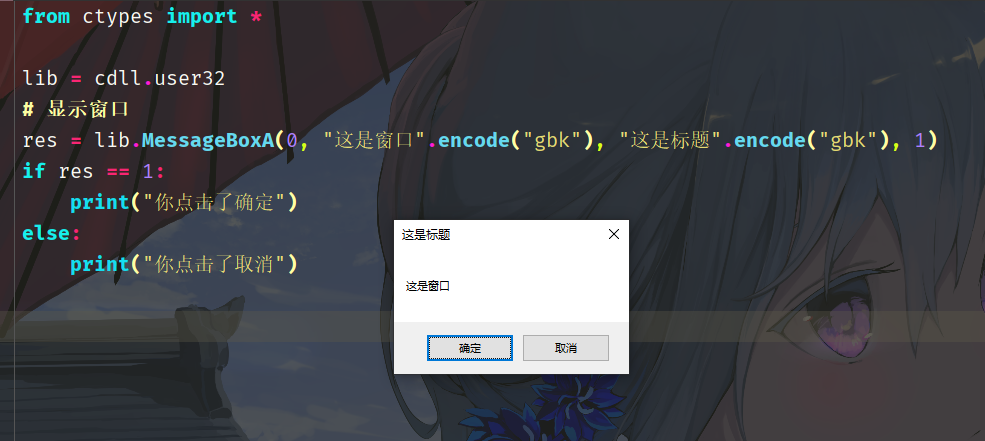
可以看到我们通过 cdll.user32 就可以很轻松地调用 Windows 的 api,具体有哪些 api 可以去网上查找,搜索 win32 api 即可。
除了 ctypes,还有几个专门用来操作 win32 服务的模块,win32gui、win32con、win32api、win32com、win32process。直接 pip install pywin32 即可,或者 pip install pypiwin32。
显示窗体和隐藏窗体
import win32gui
import win32con
# 首先查找窗体,这里查找 qq。需要传入 窗口类名 窗口标题名,至于这个怎么获取可以使用 spy 工具查看
qq = win32gui.FindWindow("TXGuifoundation", "QQ")
# 然后让窗体显示出来
win32gui.ShowWindow(qq, win32con.SW_SHOW)
# 还可以隐藏
win32gui.ShowWindow(qq, win32con.SW_HIDE)
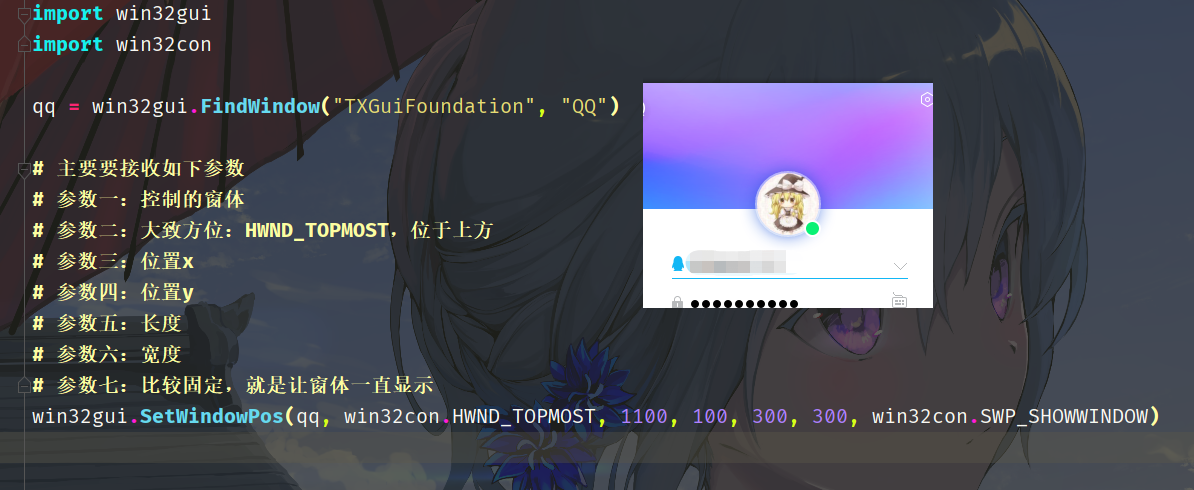
控制窗体的位置和大小
import win32gui
import win32con
qq = win32gui.FindWindow("TXGuiFoundation", "QQ")
# 主要要接收如下参数
# 参数一:控制的窗体
# 参数二:大致方位:HWND_TOPMOST,位于上方
# 参数三:位置x
# 参数四:位置y
# 参数五:长度
# 参数六:宽度
# 参数七:比较固定,就是让窗体一直显示
win32gui.SetWindowPos(qq, win32con.HWND_TOPMOST, 100, 100, 300, 300, win32con.SWP_SHOWWINDOW)
那么我们还可以让窗体满屏幕乱跑:
import win32gui
import win32con
import random
qqWin = win32gui.FindWindow("TXGuiFoundation", "QQ")
# 将位置变成随机数
while True:
x = random.randint(1, 1920)
y = random.randint(1, 1080)
win32gui.SetWindowPos(qqWin, win32con.HWND_TOPMOST, x, y, 300, 300, win32con.SWP_SHOWWINDOW)
语音播放
import win32com.client
# 直接调用操作系统的语音接口
speaker = win32com.client.Dispatch("SAPI.SpVoice")
# 输入你想要说的话,前提是操作系统语音助手要认识。一般中文和英文是没有问题的
speaker.Speak("他能秒我,他能秒杀我?他要是能把我秒了,我当场······")
Python 中 win32 模块的 api 非常多,几乎可以操作整个 Windows 提供的服务,win32 模块就是相当于把 Windows 服务封装成了一个一个的接口。不过这些服务、或者调用这些服务具体都能干些什么,可以自己去研究,这里就到此为止了。
ctypes 获取返回值
我们前面已经看到了,通过 ctypes 向动态链接库中的函数传参时是没有问题的,但是我们如何拿到返回值呢?我们之前都是使用 printf 直接打印的,但是这样显然不行,我们肯定是要拿到返回值去做一些别的事情的。那么我们在 C 函数中直接 return 不就可以啦,还记得之前演示的返回浮点型的例子吗?我们明明返回了 3.14,但得到的确是一大长串整数,所以我们需要在调用函数之前告诉 ctypes 返回值的类型。
int test1(int a, int b)
{
int c;
c = a + b;
return c;
}
void test2()
{
}
from ctypes import *
lib = CDLL("./main.dll")
print(lib.test1(25, 33)) # 58
print(lib.test2()) # -883932787
我们看到对于 test1 的结果是正常的,但是对于 test2 来说即便返回的是 void,在 Python 中依旧会得到一个整型,因为默认都会按照整型进行解析,但这个结果肯定是不正确的。不过对于整型来说,是完全没有问题的。
正如我们传递参数一样,需要使用 ctypes 转化一下,那么在获取返回值的时候,也需要提前使用 ctypes 指定一下返回值到底是什么类型,只有这样才能拿到动态链接库中函数的正确的返回值。
#include <wchar.h>
char * test1()
{
char *s = "hello satori";
return s;
}
wchar_t * test2()
{
// 遇到 wchar_t 的时候,一定要导入 wchar.h 头文件
wchar_t *s = L"憨八嘎";
return s;
}
from ctypes import *
lib = CDLL("./main.dll")
# 不出所料,我们在动态链接库中返回的是一个字符数组的首地址,我们希望拿到指向的字符串
# 然而 Python 拿到的仍是一个整型,而且一看感觉这像是一个地址。如果是地址的话那么从理论上讲是对的,返回地址、获取地址
print(lib.test1()) # 1788100608
# 但我们希望的是获取地址指向的字符数组,所以我们需要指定一下返回的类型
# 指定为 c_char_p,告诉 ctypes 你在解析的时候将 test1 的返回值按照 c_char_p 进行解析
lib.test1.restype = c_char_p
# 此时就没有问题了
print(lib.test1()) # b'hello satori'
# 同理对于 unicode 也是一样的,如果不指定类型,得到的依旧是一个整型
lib.test2.restype = c_wchar_p
print(lib.test2()) # 憨八嘎
因此我们就将 Python 中的类型和 C 语言中的类型通过 ctypes 关联起来了,我们传参的时候需要转化,同理获取返回值的时候也要使用 ctypes 来声明一下类型。因为默认 Python 调用动态链接库的函数返回的都是整型,至于返回的整型的值到底是什么?从哪里来的?我们不需要关心,你可以理解为地址、或者某块内存的脏数据,但是不管怎么样,结果肯定是不正确的(如果函数返回的就是整形除外)。因此我们需要提前声明一下返回值的类型。声明方式:
lib.CFunction.restype = ctypes类型
我们说 lib 就是 ctypes 调用 dll 或者 so 得到的动态链接库,而里面的函数就相当于是一个个的 CFunction,然后设置内部的 restype(返回值类型),就可以得到正确的返回值了。另外即便返回值设置的不对,比如:test1 返回一个 char *,但是我们将类型设置为 c_float,调用的时候也不会报错而且得到的也是一个 float,但是这个结果肯定是不对的。
from ctypes import *
lib = CDLL("./main.dll")
lib.test1.restype = c_char_p
print(lib.test1()) # b'hello satori'
# 设置为 c_float
lib.test1.restype = c_float
# 获取了不知道从哪里来的脏数据
print(lib.test1()) # 2.5420596244190436e+20
# 另外 ctypes 调用还有一个特点
lib.test2.restype = c_wchar_p
print(lib.test2(123, c_float(1.35), c_wchar_p("呼呼呼"))) # 憨八嘎
# 我们看到 test2 是不需要参数的,如果我们传了那么就会忽略掉,依旧能得到正常的返回值
# 但是不要这么做,因为没准就出问题了,所以还是该传几个参数就传几个参数
下面我们来看看浮点类型的返回值怎么获取,当然方法和上面是一样的。
#include <math.h>
float test1(int a, int b)
{
float c;
c = sqrt(a * a + b * b);
return c;
}
from ctypes import *
lib = CDLL("./main.dll")
# 得到的结果是一个整型,默认都是整型。
# 我们不知道这个整型是从哪里来的,就把它理解为地址吧,但是不管咋样,结果肯定是不对的
print(lib.test1(3, 4)) # 1084227584
# 我们需要指定返回值的类型,告诉 ctypes 返回的是一个 float
lib.test1.restype = c_float
# 此时结果就是对的
print(lib.test1(3, 4)) # 5.0
# 如果指定为 double 呢?
lib.test1.restype = c_double
# 得到的结果也有问题,总之类型一定要匹配
print(lib.test1(3, 4)) # 5.356796015e-315
# 至于 int 就不用说了,因为默认就是 int。所以和第一个结果是一样的
lib.test1.restype = c_int
print(lib.test1(3, 4)) # 1084227584
所以类型一定要匹配,该是什么类型就是什么类型。即便动态链接库中返回的是 float,我们在 Python 中通过 ctypes 也要指定为 float,而不是指定为 double,尽管都是浮点数并且 double 的精度还更高,但是结果依旧不是正确的。至于整型就不需要关心了,但即便如此,int、long 也建议不要混用,而且传参的时候最好也进行转化。

ctypes 给动态链接库中的函数传递指针
我们使用 ctypes 可以创建一个字符数组并且拿到首地址,但是对于整型、浮点型我们怎么创建指针呢?下面就来揭晓。另外,一旦涉及到指针操作的时候就要小心了,因为这往往是比较危险的,所以 Python 把指针给隐藏掉了,当然不是说没有指针,肯定是有指针的。只不过操作指针的权限没有暴露给程序员,能够操作指针的只有对应的解释器。
ctypes.byref 和 ctypes.pointer 创建指针
from ctypes import *
v = c_int(123)
# 我们知道可以通过 value 属性获取相应的值
print(v.value)
# 但是我们还可以修改
v.value = 456
print(v) # c_long(456)
s = create_string_buffer(b"hello")
s[3] = b'>'
print(s.value) # b'hel>o'
# 如何创建指针呢?通过 byref 和 pointer
v2 = c_int(123)
print(byref(v2)) # <cparam 'P' (000001D9DCF86888)>
print(pointer(v2)) # <__main__.LP_c_long object at 0x000001D9DCF868C0>
我们看到 byref 和 pointer 都可以创建指针,那么这两者有什么区别呢?byref 返回的指针相当于右值,而 pointer 返回的指针相当于左值。举个栗子:
// 以整型的指针为例:
int num = 123;
int *p = &num
对于上面的例子,如果是 byref,那么结果相当于 &num,拿到的就是一个具体的值。如果是 pointer,那么结果相当于 p。这两者在传递的时候是没有区别的,只是对于 pointer 来说,它返回的是一个左值,我们是可以继续拿来做文章的。
from ctypes import *
n = c_int(123)
# 拿到变量 n 的指针
p1 = byref(n)
p2 = pointer(n)
# pointer 返回的是左值,我们可以继续做文章,比如继续获取指针,此时获取的就是 p2 的指针
print(byref(p2)) # <cparam 'P' (0000023953796888)>
# 但是 p1 不行,因为 byref 返回的是一个右值
try:
print(byref(p1))
except Exception as e:
print(e) # byref() argument must be a ctypes instance, not 'CArgObject'
因此两者的区别就在这里,但是还是那句话,我们在传递的时候是无所谓的,传递哪一个都可以。
传递指针
我们知道了可以通过 ctypes.byref、ctypes.pointer 的方式传递指针,但是如果函数返回的也是指针呢?我们知道除了返回 int 之外,都要指定返回值类型,那么指针如何指定呢?答案是通过 ctypes.POINTER。
// 接收两个 float *,返回一个 float *
float *test1(float *a, float *b)
{
// 因为返回指针,所以为了避免被销毁,我们使用 static 静态声明
static float c;
c = *a + *b;
return &c;
}
from ctypes import *
lib = CDLL("./main.dll")
# 声明一下,返回的类型是一个 POINTER(c_float),也就是 float 的指针类型
lib.test1.restype = POINTER(c_float)
# 别忘了传递指针,因为函数接收的是指针,两种传递方式都可以
res = lib.test1(byref(c_float(3.14)), pointer(c_float(5.21)))
print(res) # <__main__.LP_c_float object at 0x000001FFF1F468C0>
print(type(res)) # <class '__main__.LP_c_float'>
# 这个 res 是 ctypes 类型,和 pointer(c_float(5.21)) 的类型是一样的,都是 <class '__main__.LP_c_float'>
# 我们调用 contents 即可拿到 ctypes 中的值,那么显然在此基础上再调用 value 就能拿到 Python 中的值
print(res.contents) # c_float(8.350000381469727)
print(res.contents.value) # 8.350000381469727
因此我们看到了如果返回的是指针类型可以使用 POINTER(类型) 来声明,也就是说 POINTER 是用来声明指针类型的,而 byref、pointer 则是用来获取指针的。
声明类型
我们知道可以事先声明返回值的类型,这样才能拿到正确的返回值。而我们传递的时候,直接传递正确的类型即可,但是其实也是可以事先声明的。
from ctypes import *
lib = CDLL("./main.dll")
# 通过 argtypes,我们可以事先指定需要传入两个 float 的指针类型,注意:要指定为一个元组,即便是一个参数也要是元组
lib.test1.argtypes = (POINTER(c_float), POINTER(c_float))
lib.test1.restype = POINTER(c_float)
# 但是和 restype 不同,argtypes 实际上是可以不要的
# 因为返回的默认是一个整型,我们才需要通过 restype 事先声明返回值的类型,这是有必要的
# 但是对于 argtypes 来说,我们传参的时候已经直接指定类型了,所以 argtypes 即便没有也是可以的
# 所以 argtypes 的作用就类似于其他静态语言中的类型声明,先把类型定好,如果你传的类型不对,直接给你报错
try:
# 这里第二个参数传c_int
res = lib.test1(byref(c_float(3.21)), c_int(123))
except Exception as e:
# 所以直接就给你报错了
print(e) # argument 2: <class 'TypeError'>: expected LP_c_float instance instead of c_long
# 此时正确执行
res1 = lib.test1(byref(c_float(3.21)), byref(c_float(666)))
print(res1.contents.value) # 669.2100219726562

传递数组
下面我们来看看如何使用 ctypes 传递数组,这里我们只讲传递,不讲返回。因为 C 语言返回数组给 Python 实际上会存在很多问题,比如:返回的数组的内存由谁来管理,不用了之后空间由谁来释放,事实上 ctypes 内部对于返回数组支持的也不是很好。因此我们一般不会向 Python 返回一个 C 语言中的数组,因为 C 语言中的数组传递给 Python 涉及到效率的问题,Python 中的列表传递直接传递一个引用即可,但是 C 语言中的数组过来肯定是要拷贝一份的,所以这里我们只讲 Python 如何通过 ctypes 给动态链接库传递数组,不再介绍动态链接库如何返回数组给 Python。
from ctypes import *
# 创建一个数组,假设叫 [1, 2, 3, 4, 5]
a5 = (c_int * 5)(1, 2, 3, 4, 5)
print(a5) # <__main__.c_long_Array_5 object at 0x00000162428968C0>
# 上面这种方式就得到了一个数组
# 当然下面的方式也是可以的
a5 = (c_int * 5)(*range(1, 6))
print(a5) # <__main__.c_long_Array_5 object at 0x0000016242896940>
下面演示一下:
// 字符数组默认是以 \0 作为结束的,我们可以通过 strlen 来计算长度。
// 但是对于整型的数组来说我们不知道有多长
// 因此有两种声明参数的方式,一种是 int a[n],指定数组的长度
// 另一种是通过指定 int *a 的同时,再指定一个参数 int size,调用函数的时候告诉函数这个数组有多长
int test1(int a[5])
{
// 可能有人会问了,难道不能通过 sizeof 计算吗?答案是不能,无论是 int *a 还是 int a[n]
// 数组作为函数的参数时会退化为指针,我们调用的时候,传递的都是指针,指针在 64 位机器上默认占 8 个字节。
// 所以int a[] = {...}这种形式,如果直接在当前函数中计算的话,那么 sizeof(a) 就是数组里面所有元素的总大小,因为a是一个数组名
// 但是当把 a 传递给一个函数的时候,那么等价于将 a 的首地址拷贝一份传过去,此时在新的函数中再计算 sizeof(a) 的时候就是一个指针的大小
//至于 int *a 这种声明方式,不管在什么地方,sizeof(a) 都是一个指针的大小
int i;
int sum = 0;
a[3] = 10;
a[4] = 20;
for (i = 0;i < 5; i++){
sum += a[i];
}
return sum;
}
from ctypes import *
lib = CDLL("./main.dll")
# 创建 5 个元素的数组,但是只给3个元素
arr = (c_int * 5)(1, 2, 3)
# 在动态链接库中,设置剩余两个元素
# 所以如果没问题的话,结果应该是 1 + 2 + 3 + 10 + 20
print(lib.test1(arr)) # 36
传递结构体
有了前面的数据结构还不够,我们还要看看结构体是如何传递的,有了结构体的传递,我们就能发挥更强大的功能。那么我们来看看如何使用 ctypes 定义一个结构体:
from ctypes import *
# 对于这样一个结构体应该如何定义呢?
"""
struct Girl {
char *name; // 姓名
int age; // 年龄
char *gender; //性别
int class; //班级
};
"""
# 定义一个类,必须继承自 ctypes.Structure
class Girl(Structure):
# 创建一个 _fields_ 变量,必须是这个名字,注意开始和结尾都只有一个下划线
# 然后就可以写结构体的字段了,具体怎么写估计一看就清晰了
_fields_ = [
("name", c_char_p),
("age", c_int),
("gender", c_char_p),
("class", c_int)
]
我们向 C 中传递一个结构体,然后再返回:
struct Girl {
char *name;
int age;
char *gender;
int class;
};
//接收一个结构体,返回一个结构体
struct Girl test1(struct Girl g){
g.name = "古明地觉";
g.age = 17;
g.gender = "female";
g.class = 2;
return g;
}
from ctypes import *
lib = CDLL("./main.dll")
class Girl(Structure):
_fields_ = [
("name", c_char_p),
("age", c_int),
("gender", c_char_p),
("class", c_int)
]
# 此时返回值类型就是一个 Girl 类型,另外我们这里的类型和 C 中结构体的名字不一样也是可以的
lib.test1.restype = Girl
# 传入一个实例,拿到返回值
g = Girl()
res = lib.test1(g)
print(res, type(res)) # <__main__.Girl object at 0x0000015423A06840> <class '__main__.Girl'>
print(res.name, str(res.name, encoding="utf-8")) # b'\xe5\x8f\xa4\xe6\x98\x8e\xe5\x9c\xb0\xe8\xa7\x89' 古明地觉
print(res.age) # 17
print(res.gender) # b'female'
print(getattr(res, "class")) # 2
如果是结构体指针呢?
struct Girl {
char *name;
int age;
char *gender;
int class;
};
// 接收一个指针,返回一个指针
struct Girl *test1(struct Girl *g){
g -> name = "mashiro";
g -> age = 17;
g -> gender = "female";
g -> class = 2;
return g;
}
from ctypes import *
lib = CDLL("./main.dll")
class Girl(Structure):
_fields_ = [
("name", c_char_p),
("age", c_int),
("gender", c_char_p),
("class", c_int)
]
# 此时指定为 Girl 类型的指针
lib.test1.restype = POINTER(Girl)
# 传入一个实例,拿到返回值
# 但返回的是指针,我们还需要手动调用一个 contents 才可以拿到对应的值。
g = Girl()
res = lib.test1(byref(g))
print(str(res.contents.name, encoding="utf-8")) # mashiro
print(res.contents.age) # 16
print(res.contents.gender) # b'female'
print(getattr(res.contents, "class")) # 3
# 另外我们不仅可以通过返回的 res 去调用,还可以通过 g 来调用,因为我们传递的是 g 的指针
# 修改指针指向的内存就相当于修改g,所以我们通过g来调用也是可以的
print(str(g.name, encoding="utf-8")) # mashiro
因此对于结构体来说,我们先创建一个结构体(Girl)实例 g,如果动态链接库的函数中接收的是结构体,那么直接把 g 传进去等价于将 g 拷贝了一份,此时函数中进行任何修改都不会影响原来的 g。但如果函数中接收的是结构体指针,我们传入 byref(g) 相当于把 g 的指针拷贝了一份,在函数中修改是会影响 g 的。而返回的 res 也是一个指针,所以我们除了通过 res.contents 来获取结构体中的值之外,还可以通过 g 来获取。再举个栗子对比一下:
struct Num {
int x;
int y;
};
struct Num test1(struct Num n){
n.x += 1;
n.y += 1;
return n;
}
struct Num *test2(struct Num *n){
n->x += 1;
n->y += 1;
return n;
}
from ctypes import *
lib = CDLL("./main.dll")
class Num(Structure):
_fields_ = [
("x", c_int),
("y", c_int),
]
# 我们在创建的时候是可以传递参数的
num = Num(x=1, y=2)
print(num.x, num.y) # 1 2
lib.test1.restype = Num
res = lib.test1(num)
# 我们看到通过 res 得到的结果是修改之后的值
# 但是对于 num 来说没有变
print(res.x, res.y) # 2 3
print(num.x, num.y) # 1 2
"""
因为我们将 num 传进去之后,相当于将 num 拷贝了一份。
函数里面的结构体和这里的 num 尽管长得一样,但是没有任何关系
所以 res 获取的结果是自增之后的结果,但是 num 还是之前的 num
"""
# 我们来试试传递指针,将 byref(num) 再传进去
lib.test2.restype = POINTER(Num)
res = lib.test2(byref(num))
print(num.x, num.y) # 2 3
"""
我们看到将指针传进去之后,相当于把 num 的指针拷贝了一份。
然后在函数中修改,相当于修改指针指向的内存,所以是会影响外面的 num 的
而动态链接库的函数中返回的是参数中的结构体指针,而我们传递的 byref(num) 也是这里的num的指针
尽管传递指针的时候也是拷贝了一份,两个指针本身来说虽然也没有任何联系,但是它们存储的地址是一样的
那么通过 res.contents 获取到的内容就相当于是这里的 num
因此此时我们通过 res.contents 获取和通过 num 来获取都是一样的。
"""
print(res.contents.x, res.contents.y) # 2 3
# 另外还需要注意的一点就是:如果传递的是指针,一定要先创建一个变量
# 比如这里,一定是:先要 num = Num(),然后再 byref(num),不可以直接就 byref(Num())
# 原因很简单,因为 Num() 这种形式在创建完 Num 实例之后就销毁了,因为没有变量保存它,那么此时再修改指针指向的内存就会有问题,因为内存的值已经被回收了
# 如果不是指针,那么可以直接传递 Num(),因为拷贝了一份
所以在这里,C 中返回一个指针是没有问题的,因为它指向的对象是我们在 Python 中创建的,Python 会管理它。

回调函数
在看回调函数之前,我们先看看如何把一个函数赋值给一个变量。准确的说,是让一个指针指向一个函数,这个指针叫做函数指针。通常我们说的指针变量是指向一个整型、字符型或数组等等,而函数指针是指向函数。
#include <stdio.h>
int add(int a, int b){
int c;
c = a + b;
return c;
}
int main() {
// 创建一个指针变量 p,让 add 等于 p
// 我们看到就类似声明函数一样,指定返回值类型和变量类型即可
// 但是注意的是,中间一定是 *p,不是 p,因为这是一个函数指针,所以要有 *
int (*p)(int, int) = add;
printf("1 + 3 = %d\n", p(1, 3)); //1 + 3 = 4
return 0;
}
除此之外我们还以使用 typedef。
#include <stdio.h>
int add(int a, int b){
int c;
c = a + b;
return c;
}
// 相当于创建了一个类型,名字叫做 func,这个 func 表示的是一个函数指针类型
typedef int (*func)(int, int);
int main() {
// 声明一个 func 类型的函数指针 p,等于 add
func p = add;
printf("2 + 3 = %d\n", p(2, 3)); // 2 + 3 = 5
return 0;
}
下面来看看如何使用回调函数,说白了就是把一个函数指针作为函数的参数。
#include <stdio.h>
char *evaluate(int score){
if (score < 60 && score >= 0){
return "bad";
}else if (score < 80){
return "not bad";
}else if (score < 90){
return "good";
}else if (score <=100){
return "excellent";
}else {
return "无效的成绩";
}
}
//接收一个整型和一个函数指针,指针指向的函数接收一个整型返回一个 char *
char *execute1(int score, char *(*f)(int)){
return f(score);
}
//除了上面那种方式,我们还可以跟之前一样通过 typedef
typedef char *(*func)(int);
// 这样声明也是可以的。
char *execute2(int score, func f){
return f(score);
}
int main(int argc, char const *argv[]) {
printf("%s\n", execute1(88, evaluate)); // good
printf("%s\n", execute2(70, evaluate)); // not bad
}
我们知道了在 C 中传入一个函数,那么在 Python 中如何定义一个 C 语言可以识别的函数呢?毫无疑问,类似于结构体,我们肯定是要先定义一个 Python 的函数,然后再把 Python 的函数转化成 C 语言可以识别的函数。
int add(int a, int b, int (*f)(int *, int *)){
return f(&a, &b);
}
我们就以这个函数为例,add 函数返回一个 int,接收两个 int,和一个函数指针,那么我们如何在 Python 中定义这样的函数并传递呢?
from ctypes import *
lib = CDLL("./main.dll")
# 动态链接库中的函数接收的函数的参数是两个 int *,所以我们这里的 a 和 b 也是一个 pointer
def add(a, b):
return a.contents.value + b.contents.value
# 此时我们把 C 中的函数用 Python 表达了,但是这样肯定是不可能直接传递的,能传就见鬼了
# 那我们要如何转化呢?
# 可以通过 ctypes 里面的函数 CFUNCTYPE 转化一下,这个函数接收任意个参数
# 但是第一个参数是函数的返回值类型,然后函数的参数写在后面,有多少写多少。
# 比如这里的函数返回一个 int,接收两个 int *,所以就是
t = CFUNCTYPE(c_int, POINTER(c_int), POINTER(c_int))
# 如果函数不需要返回值,那么写一个 None 即可
# 然后得到一个类型 t,此时的类型 t 就等同于 C 中的 typedef int (*t)(int*, int*);
# 将我们的函数传进去,就得到了 C 语言可以识别的函数 func
func = t(add)
# 然后调用,别忘了定义返回值类型,当然这里是 int 就无所谓了
lib.add.restype = c_int
print(lib.add(88, 96, func))
print(lib.add(59, 55, func))
print(lib.add(94, 105, func))
"""
184
114
199
"""

以上便是 ctypes 的基本用法,但其实我们可以通过 ctypes 玩出更高级的花样,甚至可以串改内部的解释器。ctypes 内部提供了一个属性叫 pythonapi,它实际上就是加载了 Python 安装目录里面的 python38.dll。有兴趣可以自己去了解一下,需要你了解底层的 Python / C API,当然我们也很少这么做。对于 ctypes 调用 C 库而言,我们目前算是介绍完了。
使用 C / C++ 为 Python 开发扩展模块
我们上面介绍 ctypes,我们说这种方式它不涉及任何的 Python / C API,但是它只能做一些简单的交互。而如果是编写扩展模块的话,那么它是可以被 Python 解释器识别的,也就是说我们可以通过 import 的方式进行导入。
关于扩展模块,这里不得不再提一下 Cython,使用 Python / C API 编写扩展不是一件轻松的事情,其实还是 C 语言本身比较底层吧。而 Cython 则是帮我们解决了这一点,Cython 代码和 Python 高度相似,而 cython 编译器会自动帮助我们将 Cython 代码翻译成C代码,所以Cython本质上也是使用了 Python / C API。只不过它让我们不需要直接面对C,只要我们编写 Cython 代码即可,会自动帮我们转成 C 的代码。
所以随着 Cython 的出现,现在使用 Python / C API 编写扩展算是越来越少了,不过话虽如此,使用 Python / C API 编写可以极大的帮助我们熟悉 Python 的底层。
那么废话不多说,直接开始吧。
编写扩展模块的基本骨架
首先使用 C / C++ 为 Python 编写扩展的话,是需要遵循一定套路的,而这个套路很固定。那么下面就来介绍一下整个流程:
Python 的扩展模块是需要被 import 进来的,那么它必然要有一个入口。
// 这个 xxx 非常重要,这个是你最终生成的扩展模块的名字,前面的 PyInit 是写死的
PyInit_xxx(void) // 模块初始化入口
有了入口之后,我们还需要创建模块,创建模块使用下面这个函数。
PyModule_Create // 创建模块
创建模块,那么总要有模块信息吧。
PyModuleDef // 模块信息
那么模块信息里面都可以包含哪些信息呢?模块名算吧,模块里面有哪些函数算吧。
PyMethodDef // 模块函数信息, 一个数组, 因为一个模块可以包含多个函数
而一个 Python 中的函数底层会对应一个结构体,这个结构体里面保存了 Python 函数的元信息,并且还保存了一个指向 C 函数的指针,这是显然的。
我们通过一个例子来说明以下吧,这样会更好理解一些,具体细节在编写代码的时候再补充。
def f1():
return 123
def f2(a):
return a + 1
以上是非常简单的一个模块,里面只有两个简单的函数,但是我们知道当被导入时它就是一个 PyModuleObject 对象。里面除了我们定义的两个函数之外还有其它的属性,显然这是 Python 解释器在背后帮助我们完成的,具体流程也是我们上面说的那几步(省略了亿点点细节)。
那么我们如何使用 C 来进行编写呢?下面来操作一下。
/*
编写 Python 扩展模块,需要引入 Python.h 这个头文件
该头文件在 Python 安装目录的 include 目录下,我们必须要导入它
当然这个头文件里面还导入了很多其它的头文件,我们也可以直接拿来用
*/
#include "Python.h"
/*
编写我们之前的两个函数 f1 和 f2,必须返回 PyObject *
函数里面至少要接收一个 PyObject *self,而这个参数我们是不需要管的,当然不叫 self 也是可以的
显然跟方法里面的 self 是一个道理,所以对于 Python 调用者而言,f1 是一个不需要接收参数的函数
*/
static PyObject *
f1(PyObject *self) {
return PyLong_FromLong(123);
}
static PyObject *
f2(PyObject *self, PyObject *a) {
long x;
// 转成 C 中的 long,进行相加,然后再转成 Python 的 int; 或者调用 PyNumber_Add() 也可以
x = PyLong_AsLong(a);
PyObject *result = PyLong_FromLong(x + 1);
return result;
}
// 但是注意:虽然我们定义了 f1 和 f2,但是它们是 C 中的函数,不是 Python 的
// Python 中的函数在 C 中对应的是一个结构体,里面会有函数指针,指向这里的 f1 和 f2
// 但除了函数指针,还有其它的信息
/*
定义一个结构体数组,结构体类型为 PyMethodDef,显然这个 PyMethodDef 就是 Python 中的函数
PyMethodDef 里面有四个成员,分别是:函数名、函数指针(需要转成PyCFunction)、函数参数标识、函数的doc
关于 PyMethodDef 我们后面会单独说
*/
static PyMethodDef methods[] = {
{
"f1",
(PyCFunction) f1,
METH_NOARGS, // 后面单独说
"this is a function named f1"
},
{"f2", (PyCFunction) f2, METH_O, "this is a function named f2"},
// 结尾要有一个 {NULL, NULL, 0, NULL} 充当哨兵
{NULL, NULL, 0, NULL}
};
/*
我们编写的 py 文件,解释器会自动把它变成一个模块,但是这里我们需要手动定义
下面定义一个 PyModuleDef 类型的结构体,它就是我们的模块信息
*/
static PyModuleDef module = {
// 头部信息,PyModuleDef_Base m_base,正如所有对象都有 PyObject 这个结构体一样
// 而 Python.h 中提供了一个宏,#define PyModuleDef_HEAD_INIT PyModuleDef_Base m_base; 我们可以使用 PyModuleDef_HEAD_INIT 来代替
PyModuleDef_HEAD_INIT,
"kagura_nana", // 模块的名字
"this is a module named kagura_nana", // 模块的doc,没有的话直接写成NULL即可
-1, // 模块的独立空间,这个不需要关心,直接写成 -1 即可
methods, // 上面的 PyMethodDef 结构数组,必须写在这里,不然我们没法使用定义的函数
// 下面直接写4个NULL即可
NULL, NULL, NULL, NULL
};
// 以上便是 PyModuleDef 结构体实例的创建过程,至于里面的一些细节我们后面说
// 到目前为止,前置工作就做完了,下面还差两步
/*
扩展库入口函数,这是一个宏,Python 的源代码我们知道是使用 C 来编写的
但是编译的时候为了支持 C++ 的编译器也能编译,于是需要通过 extern "C" 定义函数
然后这样 C++ 编译器在编译的的时候就会按照 C 的标准来编译函数,这个宏就是干这件事情的,主要和 Python 中的函数保持一致
*/
PyMODINIT_FUNC
/*
模块初始化入口,注意:模块名叫 kagura_nana,那么下面就必须要写成 PyInit_kagura_nana
*/
PyInit_kagura_nana(void)
{
// 将 PyModuleDef 结构体实例的指针传递进去,然后返回得到 Python 中的模块
return PyModule_Create(&module);
}
整体逻辑还是非常简单的,过程如下:
include "Python.h",这个是必须的定义我们函数,具体定义什么函数、里面写什么代码完全取决于你的业务定义一个PyMethodDef结构体数组定义一个PyModuleDef结构体定义模块初始化入口,然后返回模块对象
那么如何将这个 C 文件变成扩展模块呢?显然要经过编译,而 Python 提供了 distutils 标准库,可以非常轻松地帮我们把 C 文件编译成扩展模块。
from distutils.core import *
setup(
# 打包之后会有一个 egg_info,表示该模块的元信息信息,name 就表示打包之后的 egg 文件名
# 显然和模块名是一致的
name="kagura_nana",
version="1.11", # 版本号
author="古明地盆",
author_email="66666@东方地灵殿.com",
# 关键来了,这里面接收一个类 Extension,类里面传入两个参数
# 第一个参数是我们的模块名,必须和 PyInit_xxx 中的 xxx 保持一致,否则报错
# 第二个参数是一个列表,表示用到了哪些 C 文件,因为扩展模块对应的 C 文件不一定只有一个,我们这里的 C 文件还叫 main.c
ext_modules=[Extension("kagura_nana", ["main.c"])]
)
当前的 py 文件名叫做 1.py,我们在控制台中直接输入 python 1.py install 即可。注意:在介绍 ctypes 我用的是 gcc,但这里默认是使用 Visual Studio 2017 进行编译的。
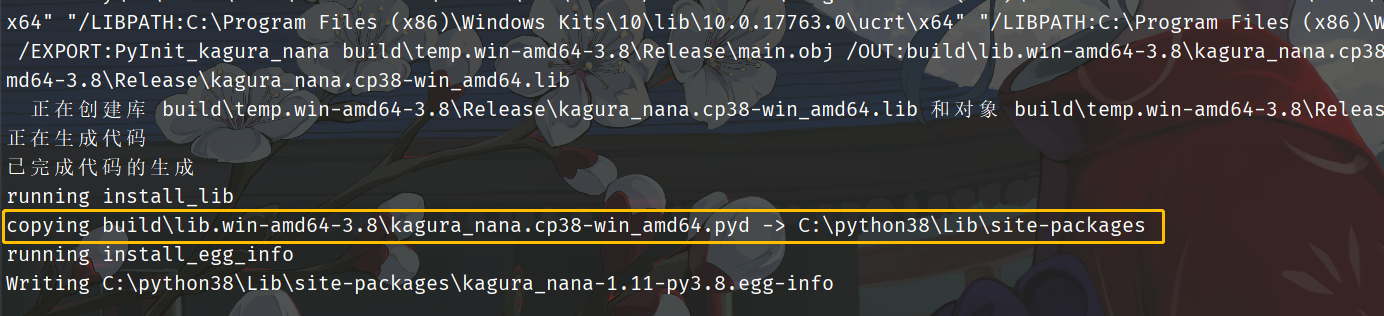
我们看到对应的 pyd 已经生成了,在你当前目录会有一个 build目录,然后 build 目录中 lib 开头的目录里面便存放了编译好的 pyd文件,并且还自动帮我们拷贝到了 site-packages 目录中。

我们看到了 kagura_nana.cp38-win_amd64.pyd 文件,中间的部分表示解释器的版本,所以编写扩展模块的方式虽然可定制性更高,但它除了操作系统之外,还需要特定的解释器版本。因为中间是 cp38,所以只能 Python3.8 版本的解释器才可以导入它。然后还有一个 egg-info,它是我们编写的模块的元信息,我们打开看看。
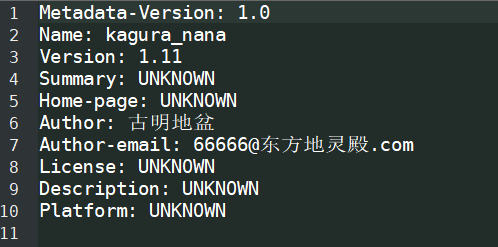
有几个我们没有写,所以是 UNKNOW,当然这都不重要,重要的是我们能不能调用,试一试吧。
import kagura_nana
print(kagura_nana) # <module 'kagura_nana' from 'C:\\python38\\lib\\site-packages\\kagura_nana.cp38-win_amd64.pyd'>
print(kagura_nana.f1()) # 123
print(kagura_nana.f2(123)) # 124
可以看到调用是没有任何问题的,最后再看一个神奇的东西,我们知道在 pycharm 这样的智能编辑器中,通过 Ctrl 加左键可以调到指定模块的指定位置。
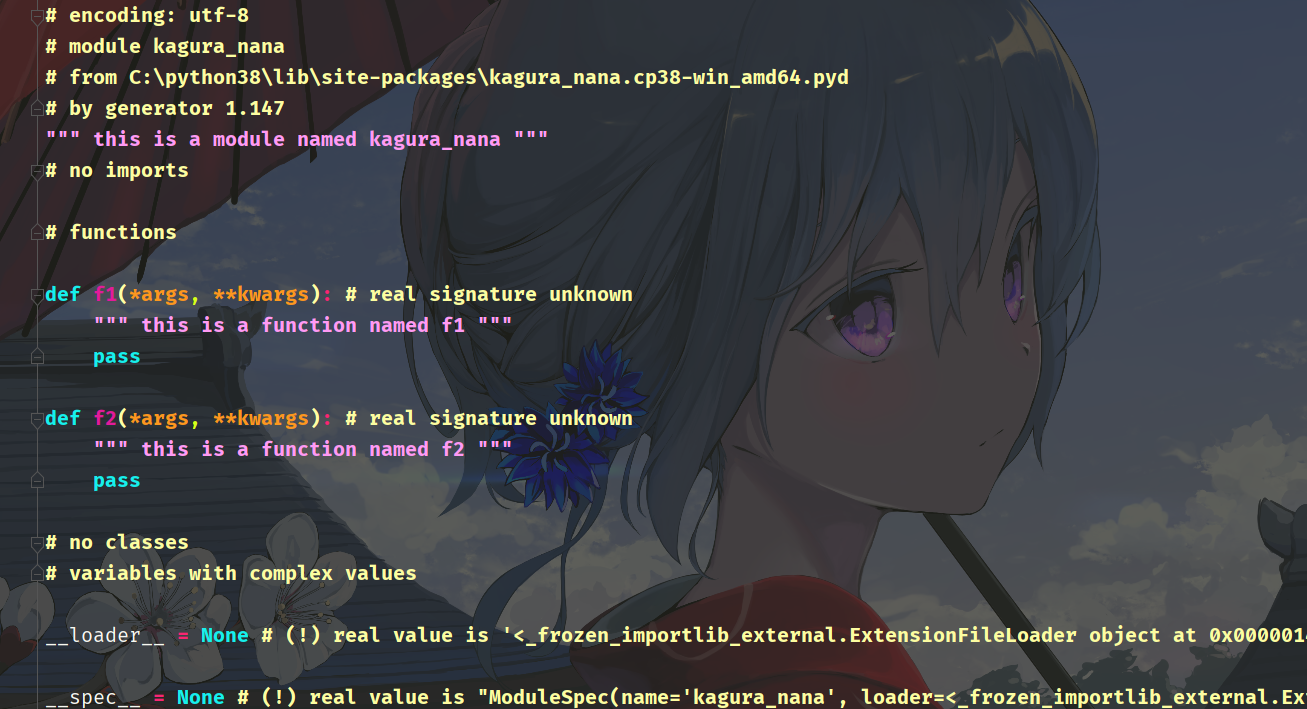
神奇的一幕出现了,我们点击进去居然还能跳转,其实我们在编译成扩展模块移动到 site-packages 之后,pycharm 会进行检测、然后将其抽象成一个普通的 py 文件,方便你查看。我们看到模块注释、函数的注释跟我们在 C 文件中指定的一样。但是注意:该文件只是 pycharm 方便你查看函数注释等信息而专门做的一个抽象,事实上你把这个文件删掉也是没有关系的。
因此我们可以再总结一下整体流程:
第一步:include "Python.h",必须要引入这个头文件,这个头文件中还引入了 C 中的一些头文件,具体都引入了哪些库我们可以查阅。当然如果不确定但又懒得看,我们还可以手动再引入一次,反正 include 同一个头文件只会引入一次。
第二步:理论上这不是第二步,但是按照编写代码顺序我们就认为它是第二步吧,对,就是按照我们上面写的代码从上往下撸。这一步你需要编写函数,这个函数就是 C 语言中定义的函数,这个函数返回一个 PyObject * ,至少要接收一个PyObject *,我们一般叫它 self,这第一个参数你可以看成是必须的,无论我们传不传其他参数,这个参数是必需要有的。所以如果只有这一个参数,那么我们就认为这个函数不接收参数,因为我们在调用的时候没有传递。
static PyObject *
f1(PyObject *self)
{
}
static PyObject *
f2(PyObject *self)
{
}
static PyObject *
f3(PyObject *self)
{
}
// 假设我们定义了这三个函数吧,三个函数都不接受参数
第三步:定义一个 PyMethodDef 类型的数组,这个数组也是我们后面的 PyModuleDef 对象中的一个参数,这个数组名字叫什么就无所谓了。至于 PyMethodDef,我们可以单独使用 PyMethodDef 创建实例,然后将变量写到数组中,也可以直接在数组中创建。如果是直接在数组中创建的话,那么就不需要再使用 PyMethodDef 定义了,直接在 {} 里面写成员信息即可。
static PyMethodDef module_functions[] = {
{
// 暴露给 Python 的函数名
"f1",
// 函数指针,最好使用 PyCFunction 转一下,可以确保不出问题。
// 如果不转,我自己测试没有问题,但是编译时候会给警告,最好还是按照标准,把指针的类型转换一下
// 转换成 Python 底层识别的 PyCFunction
(PyCFunction) f1,
METH_NOARGS, // 参数类型,至于怎么接收 *args 和 **kwargs 的参数,后面说
"函数f1的注释"
},
{"f2", (PyCFunction)f2, METH_NOARGS, "函数f2的注释"},
{"f3", (PyCFunction)f3, METH_NOARGS, "函数f3的注释"},
//别忘记,下面的 {NULL, NULL, 0, NULL},充当哨兵
{NULL, NULL, 0, NULL}
}
第四步:定义 PyModuleDef 对象,这个变量的名字叫什么也没有要求。
static PyModuleDef m = {
PyModuleDef_HEAD_INIT, // 头部信息
// 模块名,这个是有讲究的,你要编译的扩展模块叫啥,这里就写啥
"kagura_nana",
"模块的注释",
-1, // 模块的空间,这个是给子解释器调用的,我们不需要关心,直接写 -1 即可,表示不使用
module_functions, // 然后是我们上面定义的数组名,里面放了一大堆的 PyMethodDef 结构体实例
// 然后是四个 NULL,因为该结构还有其它成员,但我们不需要使用,所以指定 NULL 即可。当然有的编译器比较智能,你若不指定自动为 NULL
// 但为了规范,我们还是手动写上,因为规范的做法就是给每个成员都赋上值
NULL,
NULL,
NULL,
NULL
}
第五步:写上一个宏,其实把它单独拆分出来,有点小题大做了。
PyMODINIT_FUNC
// 一个宏,主要是保证函数按照 C 的标准,不用在意,写上就行
第六步:创建一个模块的入口函数,我们说编译的扩展模块叫 kagura_nana,那么这个函数名就要这么写。
PyInit_kagura_nana(void)
{
// 会根据上面定义的 PyModuleDef 实例,得到 Python 中的模块
// PyModule_Create 就是用来创建 Python 中的模块的,直接将 PyModuleDef 定义的对象的指针扔进去
// 便可得到 Python 中的模块,然后直接返回即可。
return PyModule_Create(&m);
}
第七步:定义一个py文件,假设叫 xx.py,那么在里面写上如下内容,然后 python xx.py install 即可。
from distutils.core import *
setup(
# 这是生成的 egg 文件名,也是里面的元信息中的 Name
name="kagura_nana",
# 版本号
version="10.22",
# 作者
author="古明地觉",
# 作者邮箱
author_email="东方地灵殿",
# 当然还有其它参数,作为元信息来描述模块,比如 description:模块介绍。
# 有兴趣的话可以看函数的注释,或者根据已有的 egg 文件自己查看
# 下面是扩展模块,Extension("yousa", ["C源文件"])
# 我们说 Extension 里面的第一个参数也必须是你的扩展模块的名字,并且必须要和 PyInit_xxx 以及 PyModuleDef 中的第一个成员保持一致
# 至于第二个参数就是一个列表,你需要用到哪些 C 源文件。
# 而且我们看到这个 Extension 也在一个列表里面,因为我们也可以传入多个 Extension 同时生成多个扩展模块。
# 我们可以写好一个生成一个,你也可以一次性写多个,然后只编译一次。
ext_modules=[Extension("hanser", ["a.c"])]
以上便是编写扩展模块的基本流程,但是里面还有很多细节没有说。
PyMethodDef
首先是 PyMethodDef,我们说它对应的是 Python 中的函数,那么我们肯定要来看看它的定义,藏身于 Include/methodobject.h 中。
struct PyMethodDef {
/* 函数名 */
const char *ml_name;
/* 实现对应逻辑的 C 函数,但是需要转成 PyCFunction 类型,主要是为了更好的处理关键字参数 */
PyCFunction ml_meth;
/* 参数类型
#define METH_VARARGS 0x0001 扩展位置参数,*args
#define METH_KEYWORDS 0x0002 扩展关键字参数,**kwargs
#define METH_NOARGS 0x0004 不需要参数
#define METH_O 0x0008 需要一个参数
#define METH_CLASS 0x0010 被 classmethod 装饰
#define METH_STATIC 0x0020 被 staticmethod 装饰
*/
int ml_flags;
//函数的 __doc__,没有的话传递 NULL
const char *ml_doc;
};
typedef struct PyMethodDef PyMethodDef;
如果不需要参数,那么 ml_flags 传入一个 METH_NOARGS;接收一个参数传入 METH_O;所以我们上面的 f1 对应的 ml_flags 是 METHOD_NOARGS,f2 对应的 ml_flags 是 METH_O。
如果是多个参数,那么直接写成 METH_VARAGRS 即可,也就是通过扩展位置参数的方式,但是这要如何解析呢?比如:有一个函数f3接收3个参数,这在C中要如何实现呢?别急我们后面会说。
引用计数和内存管理
我们在最开始的时候就说过,PyObject 贯穿了我们的始终。我们说这里面存放了引用计数和类型指针,并且 Python 中所有对象底层对应的结构体都嵌套了 PyObject,因此 Python 中的所有对象都有引用计数和类型。并且 Python 的对象在底层,都可以看成是 PyObject 的一个扩展,因此参数、返回值都是 PyObject *,至于具体类型则是通过里面的 ob_type 动态判断。比如:之前使用的 PyLong_FromLong。
PyObject *
PyLong_FromLong(long ival)
{
PyLongObject *v;
// ...
return (PyObject *)v;
}
此外 Python 还专门定义了几个宏,来看一下:
#define Py_REFCNT(ob) (((PyObject*)(ob))->ob_refcnt)
#define Py_TYPE(ob) (((PyObject*)(ob))->ob_type)
#define Py_SIZE(ob) (((PyVarObject*)(ob))->ob_size)
Py_REFCNT:拿到对象的引用计数;Py_TYPE:拿到对象的类型;Py_SIZE:拿到对象的ob_size,也就是变长对象里面的元素个数。除此之外,Python 还提供了两个宏:Py_INCREF 和 Py_DECREF 来用于引用计数的增加和减少。
// 引用计数增加很简单,就是找到 ob_refcnt,然后 ++
#define Py_INCREF(op) ( \
_Py_INC_REFTOTAL _Py_REF_DEBUG_COMMA \
((PyObject *)(op))->ob_refcnt++)
// 但是减少的话,做的事情稍微多一些
// 其实主要就是判断引用计数是否为 0,如果为 0 直接调用 _Py_Dealloc 将对象销毁
// _Py_Dealloc 也是一个宏,会调用对应类型对象的 tp_dealloc,也就是析构方法
#define Py_DECREF(op) \
do { \
PyObject *_py_decref_tmp = (PyObject *)(op); \
if (_Py_DEC_REFTOTAL _Py_REF_DEBUG_COMMA \
--(_py_decref_tmp)->ob_refcnt != 0) \
_Py_CHECK_REFCNT(_py_decref_tmp) \
else \
_Py_Dealloc(_py_decref_tmp); \
} while (0)
当然这些东西我们在系列的最开始的时候就已经说过了,但是接下来我们要引出一个非常关键的地方,就是内存管理。到目前为止我们没有涉及到内存管理的操作,但我们知道 Python 中的对象都是申请在堆区的,这个是不会自动释放的。举个栗子:
static PyObject *
f(PyObject *self)
{
PyObject *s = PyUnicode_FromString("你好呀~~~");
// Py_None 就是 Python 中的 None, 同理还有 Py_True、Py_False,我们后面会继续提
// 这里增加引用计数,至于为什么要增加,我们后面说
Py_INCREF(Py_None);
return Py_None;
}
这个函数不需要参数,如果我们写一个死循环不停的调用这个函数,你会发现内存的占用蹭蹭的往上涨。就是因为这个 PyUnicodeObject 是申请在堆区的,此时内部的引用计数为 1。函数执行完毕变量 s 被销毁了,但是 s 是一个指针,这个指针被销毁了是不假,但是它指向的内存并没有被销毁。
static PyObject *
f(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *s = PyUnicode_FromString("hello~~~");
Py_DECREF(s);
Py_INCREF(Py_None);
return Py_None;
}
因此我们需要手动调用 Py_DECREF 这个宏,来将 s 指向的 PyUnicodeObject 的引用计数减 1,这样引用计数就为 0 了。不过有一个特例,那就是当这个指针作为返回值的时候,我们不需要手动减去引用计数,因为会自动减。
static PyObject *
f(PyObject *self)
{
PyObject *s = PyUnicode_FromString("hello~~~");
// 如果我们把 s 给返回了,那么我们就不需要调用 Py_DECREF 了
// 因为一旦作为返回值,那么会自动减去 1
// 所以此时 C 中的对象是由 Python 来管理的,准确的说应该是作为返回值的指针指向的对象是由 Python 来管理的
return s;
// 所以在返回 Py_None 的时候,我们需要手动将引用计数加 1,因为它作为了返回值。
// 如果你不加 1,那么当你无限调用的时候,总会有那么一刻,Py_None 会被销毁,因为它的引用计数在不断减少
// 但当销毁 Py_None 的时候,会出现 Fatal Python error: deallocating None,解释器异常退出
}
不过这里还存在一个问题,那就是我们在 C 中返回的是 Python 传过来的。
static PyObject *
f(PyObject *self, PyObject *val)
{
//传递过来一个 PyObject *,然后原封不动的返回
return val;
}
显然上面 val 指向的内存不是在 C 中调用 api 创建的,而是 Python 创建然后传递过来的,也就是说这个 val 已经指向了一块合法的内存(和增加 Py_None 引用计数类似)。但是内存中的对象的引用计数是没有变化的,虽说有新的变量(这里的 val)指向它了,但是这个 val 是 C 中的变量不是 Python 中的变量,因此它的引用计数是没有变化的。然后作为返回值返回之后,指向对象的引用计数减一。所以你会发现在 Python 中,创建一个变量,然后传递到 f 中,执行完之后再进行打印就会发生段错误,因为对应的内存已经被回收了。如果能正常打印,说明在 Python 中这个变量的引用计数不为 1,也可能是小整数对象池、或者有多个变量引用,那么就创建一个大整数或者其他的对象多调用几次,因为作为返回值,每次调用引用计数都会减1。
static PyObject *
f(PyObject *self)
{
// 假设创建一个 PyListObject
PyObject *l1 = PyList_New(2);
// 将 l1 赋值给 l2,但是不好意思,这两位老铁指向的 PyListObject 的引用计数还是 1
PyObject *l2 = l1;
Py_INCREF(Py_None);
return Py_None;
}
因此我们说,如果在 C 中创建一个 PyObject 的话,那么它的引用计数会是 1,因为对象被初始化了,引用计数默认是 1。至于传递,无论你在 C 中将创建 PyObject * 赋值给了多少个变量,它们指向的 PyObject 的引用计数都会是 1。因为这些变量是 C 中的变量,不是 Python 中的。
因此我们的问题就很好解释了,我们说当一个 PyObject * 作为返回值的时候,它指向的对象的引用计数会减去 1,那么当 Python 传递过来一个 PyObject * 指针的时候,由于它作为了返回值,因此调用之后会发现引用计数会减少了。因此当你在 Python 中调用扩展函数结束之后,这个变量指向的内存可能就被销毁了。如果你在 Python 传递过来的指针没有作为返回值,那么引用计数是不会发生变化的,但是一旦作为了返回值,引用计数会自动减 1,因此我们需要手动的加 1。
static PyObject *
f(PyObject *self, PyObject *val)
{
Py_INCREF(val);
return val;
}
因此我们可以得出如下结论:
如果在 C 中,创建一个 PyObject *var,并且 var 已经指向了合法的内存,比如调用 PyList_New、PyDict_New 等等 api 返回的 PyObject *,总之就是已经存在了 PyObject。那么如果 var 没有作为返回值,我们必须手动地将 var 指向的对象的引用计数减 1,否则这个对象就会在堆区一直待着不会被回收。可能有人问,如果 PyObject *var2 = var,我将 var 再赋值给一个变量呢?那么只需要对一个变量进行 Py_DECREF 即可,当然对哪个变量都是一样的,因为在 C 中变量的传递不会导致引用计数的增加。
如果 C 中创建的 PyObject * 作为返回值了,那么会自动将指向的对象的引用计数减 1,因此此时该指针指向的内存就由 Python 来管理了,就相当于在 Python 中创建了一个对象,我们不需要关心。
最后关键的一点,如果 C 中返回的指针指向的内存是 Python 中创建好的,假设我们在 Python 中创建了一个对象,然后把指针传递过来了,但是我们说这不会导致引用计数的增加,因为赋值的变量是 C 中的变量。如果 C 中用来接收参数的指针没有作为返回值,那么引用计数在扩展函数调用之前是多少、调用之后还是多少。然而一旦作为了返回值,我们说引用计数会自动减 1,因此假设你在调用扩展函数之前引用计数是 3,那么调用之后你会发现引用计数变成了2。为了防止段错误,一旦作为返回值,我们需要在返回之前手动地将引用计数加1。
C中创建的:不作为返回值,引用计数手动减 1、作为返回值,不处理;Python 中创建传递过来的,不作为返回值,不处理、作为返回值,引用计数手动加 1。
而实现引用计数增加和减少所使用的宏就是 Py_INCREF 和 Py_DECREF,但它们要求传递的 PyObject * 不可以为 NULL。如果可能为 NULL 的话,那么建议使用 Py_XINCREF 和 Py_XDECREF。
参数的解析
我们说,PyMethodDef 内部有一个 ml_flags 属性,表示此函数的参数类型,我们说有如下几种:
1. 不接受参数,METH_NOARGS,对应函数格式如下:
static PyObject *
f(PyObject *self)
{
}
2. 接受一个参数,METH_O,对应函数格式如下:
static PyObject *
f(PyObject *self, PyObject *val)
{
}
3. 接受任意个位置参数,METH_VARARGS,对应函数格式如下:
static PyObject *
f(PyObject *self, PyObject *args)
{
}
4. 接受任意个位置参数和关键字参数,METH_VARARGS | METH_KEYWORDS,对应函数格式如下:
static PyObject *
f(PyObject *self, PyObject *args, PyObject *kwargs)
{
}
第一种和第二种显然都很简单,关键是第三种和第四种要怎么做呢?我们先来看看第三种,解析多个位置参数可以使用一个函数:PyArg_ParseTuple。
解析多个位置参数
函数原型:int PyArg_ParseTuple(PyObject *args, const char *format, ...); 位于 Python/getargs.c 中
所以重点就在 PyArg_ParseTuple 上面,我们注意到里面有一个 format,显然类似于 printf,里面肯定是一些占位符,那么都支持哪些占位符呢?常用的如下:
i:接收一个 Python 中的 int,然后解析成 C 的 intl:接收一个 Python 中的 int,然后将传来的值解析成 C 的 longf:接收一个 Python 中的 float,然后将传来的值解析成 C 的 floatd:接收一个 Python 中的 float,然后将传来的值解析成 C 的 doubles:接收一个 Python 中的 str,然后将传来的值解析成 C 的 char *u:接收一个 Python 中的 str,然后将传来的值解析成 C 的 wchar_t *O:接收一个 Python 中的 object,然后将传来的值解析成 C 的 PyObject *
我们举个栗子:
static PyObject *
f(PyObject *self, PyObject *args)
{
// 目前我们定义了一个 PyObject *args,如果是 METH_O,那么这个 args 就是对应的一个参数
// 如果 METH_VARAGRS,还是只需要定义一个 *args 即可,只不过此时的 *args 是一个 PyTupleObject,我们需要将多个参数解析出来
//假设此时我们这个函数是接收 3 个 int,然后相加
int a, b, c;
/*
下面我们需要使用 PyArg_ParseTuple 进行解析,因为我们接收三个参数
这个函数返回一个整型,如果失败会返回 0,成功返回非 0
*/
if (!PyArg_ParseTuple(args, "iii", &a, &b, &c)){
// 失败我们需要返回 NULL
return NULL;
}
return PyLong_FromLong(a + b + c);
}
我们还是编译一下,当然编译的过程我们就不显示了,跟之前是一样的。并且为了方便,我们的模块名就不改了,但是编译之后的 pyd 文件内容已经变了。不过需要注意的是,我们说编译之后会有一个 build 目录,然后会自动把里面的 pyd 文件拷贝到 site-packages 中,如果你修改了代码,但是模块名没有变的话,那么编译之后的文件名还和原来一样。如果一样的话,那么由于已经存在相同文件了,可能就不会再拷贝了。因此两种做法:要么你把模块名给改了,这样编译会生成新的模块。要么编译之前记得把上一次编译生成的 build 目录先删掉,我们推荐第二种做法,不然 site-packages 目录下会出现一大堆我们自己定义的模块。
然后我们将 ml_flags 改成 METH_VARARGS,来测试一下。
#include "Python.h"
static PyObject *
f(PyObject *self, PyObject *args)
{
int a, b, c;
if (!PyArg_ParseTuple(args, "iii", &a, &b, &c)){
return NULL;
}
return PyLong_FromLong(a + b + c);
}
static PyMethodDef methods[] = {
{
"f",
(PyCFunction) f,
// 这里需要改成 METH_VARAGRS,这个地方很重要,因为它表示了函数的参数类型。如果这个地方不修改的话,Python 在调用函数时会发生段错误
METH_VARARGS,
"this is a function named f"
},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named kagura_nana",
-1,
methods,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void)
{
return PyModule_Create(&module);
}
我们编译成扩展模块之后,来测试一下,但是注意,你在调用的时候 pycharm 可能会感到别扭。

因为在调用函数 f 的是给你飘黄了,原因就是我们上一次在生成 pyd 的时候,里面的函数是 f1 和 f2,并没有 f。而我们 pycharm 会将 pyd 抽象成一个普通的 py 文件让你查看,但同时它也是 pycharm 自动提示的依据。因为上一次 pycharm 已经抽象出来了这个文件,而里面没有 f 这个函数,所以这里会飘黄。但是不用管,因为我们调用的是生成的 pyd 文件,跟 pycharm 抽象出来的 py 文件无关。
import kagura_nana
# 传参不符合,自动给你报错
try:
print(kagura_nana.f())
except TypeError as e:
print(e) # function takes exactly 3 arguments (0 given)
try:
print(kagura_nana.f(123))
except TypeError as e:
print(e) # function takes exactly 3 arguments (1 given)
try:
print(kagura_nana.f(123, "xxx", 123, 123))
except TypeError as e:
print(e) # function takes exactly 3 arguments (4 given)
try:
kagura_nana.f(123, 123.0, 123) # int: 123, long: 123, float: 123.000000, double: 123.000000
except TypeError as e:
print(e) # integer argument expected, got float
print(kagura_nana.f(123, 123, 123)) # 369
怎么样,是不是很简单呢?当然 PyArg_ParseTuple 解析失败,Python 底层自动帮你报错了,告诉你缺了几个参数,或者哪个参数的类型错了。
我们这里是以 i 进行演示的,至于其它的几个占位符也是类似的。当然 O 比较特殊,因为它是转成 PyObject *,所以此时我们是可以传递元组、列表、字典等任意高阶对象的。而我们之前的 ctypes 则是不支持的,还是那句话,因为它没有涉及任何 Python / C API 的调用,显然数据的表达能力有限。
解析成 PyObject *
我们说 PyArg_ParseTuple 中的 i 代表 int、l 代表 long、f 代表 float、d 代表 double、s 代表 char*、u代表 wchar_t *,这些都比较简单。我们重点是 O,其实 O 也不难,无非就是后续的一些 Python / C API 调用罢了。
我们还是以普通的 py 文件为例:
def foo(lst: list):
"""
假设我们传递一个列表, 然后返回一个元组, 并且将里面的元素都设置成元素的类型
:return:
"""
return tuple([type(item) for item in lst])
print(foo([1, 2, "3", {}])) # (<class 'int'>, <class 'int'>, <class 'str'>, <class 'dict'>)
如果使用 C 来编写扩展的话,要怎么做呢?
#include "Python.h"
static PyObject *
foo(PyObject *self, PyObject *args)
{
PyObject *lst; // 首先我们这里要接收一个 PyObject *
// 我们要修改 lst,让它指向我们传递的列表, 因此要传递一个二级指针进行修改
if (!PyArg_ParseTuple(args, "O", &lst)){
return NULL;
}
// 计算列表中的元素个数,申请同样大小的元组。
// 其实还可以使用 PyList_Size,底层也是调用了 Py_SIZE,只是 PyList_Size 会进行类型检测,同理还有 PyTuple_Size 等等
Py_ssize_t arg_count = Py_SIZE(lst);
// 申请完毕之后,里面的元素全部是 NULL,然后我们来进行设置
// 但是这里我们故意多申请一个,我们看看 NULL 在 Python 中的表现是什么
PyObject *tpl = PyTuple_New(arg_count + 1);
// 申明类型对象、以及元素
PyObject *type, *val;
for (int i = 0; i < arg_count; i++) {
val = PyList_GetItem(lst, i); // 获取对应元素,赋值给 val
// 获取对应的类型对象,但得到的是 PyTypeObject *,所以需要转成 PyObject *
// 或者你使用 Py_TYPE 这个宏也可以,内部自动帮你转了
type = (PyObject *)val -> ob_type;
//设置到元组中
PyTuple_SetItem(tpl, i, type);
}
return tpl;
}
static PyMethodDef methods[] = {
{
"foo",
(PyCFunction) foo,
// 记得这里写上 METH_VARARGS, 假设我们写的是 METH_NOARGS, 那么即便我们上面定义了参数也是没有意义的
// 调用的时候 Python 会提示你: TypeError: foo() takes no arguments
METH_VARARGS,
NULL
},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named kagura_nana",
-1,
methods,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void)
{
return PyModule_Create(&module);
}
然后使用 Python 测试一下:
import kagura_nana
print(
kagura_nana.foo([1, 2, "3", {}])
) # (<class 'int'>, <class 'int'>, <class 'str'>, <class 'dict'>, <NULL>)
# 我们看到得到结果是一致的,并且我们多申请了一个空间,但是没有设置,所以结尾多了一个 <NULL>
# 但是注意:不要试图通过 kagura_nana.foo([1, 2, "3", {}])[-1] 的方式来获取这个 NULL,会造成段错误
# 因为 Python 操作指针会自动操作指针指向的内存,而 NULL 是一个空指针,指向的内存是非法的
# 另外段错误是一种非常可怕的错误,它造成的结果就是解释器直接就异常退出了。
# 并且这不是异常捕获能解决的问题,异常捕获也是解释器正常运行的前提下。因此申请容器的时候,要保证元数个数相匹配
从这里我们也能看出使用 C 来为 Python 写扩展是一件多么麻烦的事情,因此 Cython 的出现是一个福音。当然我们上面的代码只是演示,没有太大意义,完全可以用 Python 实现。
传递字符串
然后我们再来看看字符串的传递,比较简单,说白了这些都是 Python / C API 的调用。
#include "Python.h"
static PyObject *
f1(PyObject *self, PyObject *args)
{
// 这里我们接受任意个字符串,然后将它们拼接在一起,最后放在列表中返回。
// 由于是任意个,所以无法使用 PyArg_ParseTuple 了
// 因为我们不知道占位符要写几个 O,但我们说 args 是一个元组,那么我们可以按照元组的方式进行解析
Py_ssize_t arg_count = Py_SIZE(args); // 计算元组的长度
PyObject *res = PyUnicode_FromWideChar(L"", 0); // 返回值,因为包含中文,所以是宽字符
for (int i=0; i < arg_count; i++){
// 将 res 和 里面的字符串依次拼接,等价于字符串的加法
res = PyUnicode_Concat(res, PyTuple_GetItem(args, i));
}
// 我们上面这种做法比较笨,直接通过 PyUnicode_Join 直接拼接不香吗?我们目前先这么做,join 的话在下面的 f2 函数中
// 然后创建一个列表,将结果放进去。我们申请列表,容量只需要为 1 即可
PyObject *lst = PyList_New(1);
PyList_SetItem(lst, 0, res);
// 我们说 lst 是在 C 中创建的, 但是它作为了返回值, 所以我们不需要关心它的引用计数, 因为会自动减一
// 那 res 怎么办?它要不要减少引用计数,答案是不需要、也不能,因为它作为了容器的一个元素(这里面有很多细节,我们暂且不表,在后面介绍 PyDictObject 的时候再说)
return lst;
}
static PyObject *
f2(PyObject *self, PyObject *args)
{
// 这里还可以指定连接的字符,这里就直接返回吧
PyObject *res = PyUnicode_Join(PyUnicode_FromWideChar(L"||", 2), args);
return res;
}
static PyMethodDef methods[] = {
{
"f1",
(PyCFunction) f1,
METH_VARARGS,
NULL
},
{
"f2",
(PyCFunction) f2,
METH_VARARGS,
NULL
},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named kagura_nana",
-1,
methods,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void)
{
return PyModule_Create(&module);
}
Python 进行调用,看看结果。
import kagura_nana
print(kagura_nana.f1("哼哼", "嘿嘿", "哈哈")) # ['哼哼嘿嘿哈哈']
print(kagura_nana.f2("哼哼", "嘿嘿", "哈哈")) # 哼哼||嘿嘿||哈哈
我们看到结果是没有问题的,还是蛮有趣的。
类型检查和返回异常
在 Python 中,当我们传递的类型不对时会报错。那么在底层我如何才能检测传递过来的参数是不是想要的类型呢?首先我们想到的是通过 ob_type,假设我们要求 val 是一个 int,那么:
#include "Python.h"
static PyObject *
f1(PyObject *self, PyObject *val)
{
// 获取类型名称, 如果是字符串,那么 tp_name 就是 "str",字典是 "dict"
const char *tp_name = val -> ob_type -> tp_name;
char *res;
if (strcmp(tp_name, "int") == 0) {
res = "success";
} else {
res = "failure";
}
return PyUnicode_FromString(res);
}
static PyMethodDef methods[] = {
{
"f1",
(PyCFunction) f1,
METH_O,
NULL
},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named kagura_nana",
-1,
methods,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void)
{
return PyModule_Create(&module);
}
import kagura_nana
print(kagura_nana.f1(123)) # success
print(kagura_nana.f1("123")) # failure
以上是一种判断方式,但是 Python 底层给我们提供了其它的 API 来进行判断。比如:
判断是否为整型: PyLong_Check判断是否为字符串: PyUnicode_Check判断是否为浮点型: PyFloat_Check判断是否为复数: PyComplex_Check判断是否为元组: PyTuple_Check判断是否为列表: PyList_Check判断是否为字典: PyDict_Check判断是否为集合: PySet_Check判断是否为字节串: PyBytes_Check判断是否为函数: PyFunction_Check判断是否为方法: PyMethod_Check判断是否为实例对象: PyInstance_Check判断是否为类(type的实例对象): PyType_Check判断是否为可迭代对象: PyIter_Check判断是否为数值: PyNumber_Check判断是否为序列(实现 __getitem__ 和 __len__): PySequence_Check判断是否为映射(必须实现 __getitem__、__len__ 和 __iter__): PyMapping_Check判断是否为模块: PyModule_Check
写法非常固定,因此我们上面的判断逻辑就可以进行如下修改:
static PyObject *
f1(PyObject *self, PyObject *val)
{
char *res;
if (PyLong_Check(val)) {
res = "success";
} else {
res = "failure";
}
return PyUnicode_FromString(res);
}
这种写法是不是就简单多了呢?其它部分不需要动,然后你可以自己重新编译、并测试一下,看看结果是不是一样的。
然后问题来了,如果用户传递的参数个数不对,或者类型不对,那么我们应该返回一个 TypeError,或者说返回一个异常。那么在 C 中,要如何设置异常呢?其实设置异常,说白了就是把输出信息打印到 stderr 中,然后直接返回 NULL 即可。
#include "Python.h"
static PyObject *
f1(PyObject *self, PyObject *args)
{
Py_ssize_t arg_count = Py_SIZE(args);
if (arg_count != 3) {
// 这里是我们设置的异常, 其实参数个数不对的话, 我们可以借助于 PyArg_ParseTuple 来帮助我们
// 因为指定的占位符已经表明了参数的个数
PyErr_Format(PyExc_TypeError, ">>>>>> f1() takes 3 positional arguments but %d were given", arg_count);
}
// 然后我们要求第一个参数是整型, 第二个参数是字符串, 第三个参数是列表
PyObject *a, *b, *c;
// 因为参数一定是三个, 否则逻辑不会执行到这里, 因此我们不需要判断了
PyArg_ParseTuple(args, "OOO", &a, &b, &c);
// 检测
if (!PyLong_Check(a)) {
PyErr_Format(PyExc_ValueError, "The 1th argument requires a int, but got %s", Py_TYPE(a) -> tp_name);
}
if (!PyUnicode_Check(b)) {
PyErr_Format(PyExc_ValueError, "The 2th argument requires a str, but got %s", Py_TYPE(b) -> tp_name);
}
if (!PyList_Check(c)) {
PyErr_Format(PyExc_ValueError, "The 3th argument requires a list, but got %s", Py_TYPE(c) -> tp_name);
}
// 检测成功之后, 我们将整数和字符串添加到列表中
PyList_Append(c, a);
PyList_Append(c, b);
// 这里我们将列表给返回, 而它是 Python 传递过来的, 所以一旦返回、引用计数会减一, 因此我们需要手动加一
Py_INCREF(c);
return c;
}
static PyMethodDef methods[] = {
{
"f1",
(PyCFunction) f1,
METH_VARARGS,
NULL
},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named kagura_nana",
-1,
methods,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void)
{
return PyModule_Create(&module);
}
所以逻辑就是像上面那样,通过 PyErr_Format 来设置异常,这个会被 Python 端接收到,但是异常一旦设置,就必须要返回 NULL,否则会出现段错误。但反过来吗,返回 NULL 的话则不一定要设置异常,但如果你不设置,那么 Python 底层会默认帮你设置一个 SystemError,并且异常的 value 信息为:<built-in function f1> returned NULL without setting an error,提示你返回了 NULL 但没有设置 error。因为返回 NULL 表示程序需要终止了,那么就应该把为什么需要终止的理由告诉使用者。
然后我们来测试一下:
import kagura_nana
try:
kagura_nana.f1()
except Exception as e:
print(e) # >>>>>> f1() takes 3 positional arguments but 0 were given
try:
kagura_nana.f1(1, 2, 3, 4)
except Exception as e:
print(e) # >>>>>> f1() takes 3 positional arguments but 4 were given
try:
kagura_nana.f1(1, 2, 3)
except Exception as e:
print(e) # The 2th argument requires a str, but got int
lst = ["xx", "yy"]
print(kagura_nana.f1(123, "123", lst)) # ['xx', 'yy', 123, '123']
print(lst) # ['xx', 'yy', 123, '123']
所表现的一切,都和我们在底层设置的一样。另外我们再来看看这个函数的身份是什么:
import kagura_nana
def foo(): pass
print(kagura_nana.f1) # <built-in function f1>
print(sum) # <built-in function sum>
print(foo) # <function foo at 0x000001F1BAAF61F0>
我们居然实现了一个内置函数,怎么样是不是很神奇呢?因为扩展模块里面的函数和解释器内置的函数本质上都是一样的,所以它们都是 built-in。
返回布尔类型和 None
我们说函数都必须返回一个 PyObject *,如果这个函数没有返回值,那么在 Python 中实际上返回的是一个 None,但是我们不能返回 NULL,None 和 NULL 是两码事。在扩展函数中,如果返回 NULL 就表示这个函数执行的时候,不符合某个逻辑,我们需要终止掉,不能再执行下去了。这是在底层,但是在 Python 的层面,你需要告诉使用者为什么不能执行了,或者说底层的哪一行代码不满足条件,因此这个时候我们会在 return NULL 之前需要手动设置一个异常,这样在 Python 代码中才知道为什么底层函数退出了。当然有时候会自动帮我们设置,比如们说的 PyArg_ParseTuple。
那么在底层如何返回一个 None 呢?既然要返回我们就需要知道它的结构是什么。
# 首先在 Python 中,None 也是有类型的
print(type(None)) # <class 'NoneType'>
这个 NoneType 在底层对应的是 _PyNone_Type,至于 None 在底层对应的结构体是 _Py_NoneStruct,所以我们返回的时候应该返回这个结构体的指针。不过官方不推荐直接使用,而是给我们定义了一个宏,#define Py_None (&_Py_NoneStruct),我们直接返回 Py_None 即可。
不光是 None,我们说还有 True 和 False,True 和 False 对应的结构体是:_Py_FalseStruct,_Py_TrueStruct,它们本质上是 PyLongObject,Python 也不推荐直接返回,也是定义了两个宏。
#define Py_False ((PyObject *) &_Py_FalseStruct)#define Py_True ((PyObject *) &_Py_TrueStruct)
推荐我们使用 Py_False 和 Py_True。
另外:
return Py_None; 等价于 Py_RETURN_NONE;return Py_True; 等价于 Py_RETURN_TRUE;return Py_False; 等价于 Py_RETURN_FALSE;
可以自己测试一下,比如条件满足返回 Py_True,不满足返回 Py_False 等等。
传递关键字参数
我们上面的例子都是通过位置参数实现的,如果我们通过关键字参数传递呢?很明显是会报错的,因为我们参数名叫什么都不知道,所以上面的例子都不支持关键字参数。那么下面我们就来看看关键字参数要如何实现。
传递关键字参数的话,我们是通过 key=value 的方式来实现,那么在 C 中我们如何解析呢?既然支持关键字的方式,那么是不是也可以实现默认参数呢?答案是肯定的,我们知道解析位置参数是通过 PyArg_ParseTuple,而解析关键字参数是通过 PyArg_ParseTupleAndKeywords。
函数原型: int PyArg_ParseTupleAndKeywords(PyObject *args, PyObject *kw, const char *format, char *keywords[], ...)
我们看到相比原来的 PyArg_ParseTuple,多了一个 kw 和一个 char * 类型的数组,具体怎么用我们在编写代码的时候说。
#include "Python.h"
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
// 我们说函数既可以通过位置参数、还可以通过关键字参数传递,那么函数的参数类型就要变成 METH_VARARGS | METH_KEYWORDS
// 参数 args 就是 PyTupleObject 对象, kwargs 就是 PyDictObject 对象
// 假设我们定义了三个参数,name、age、place,这三个参数可以通过位置参数传递、也可以通过关键字参数传递
wchar_t *name;
int age = 17;
wchar_t *gender = L"FEMALE";
// 告诉 Python 解释器参数的名字,注意:里面字符串的顺序就是函数定义的参数顺序
// 这里的字符串就是函数的参数名,上面的是变量名。其实变量名字叫什么无所谓,只是为了一致我们会起相同的名字
char *keys[] = {"name", "age", "gender", NULL};
// 注意结尾要有一个 NULL,否则会报出段错误。
// 解析参数,我们看到 format 中本来应该是 uiu 的,但是中间出现了一个 |
// 这就表示 | 后面的参数是可以不填的,如果不填会使用我们上面给出的默认值
// 因此这里 name 就是必填的,因为它在 | 的前面,而 age 和 gender 可以不填,如果不填就用我们上面给出的默认值
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "u|iu", keys, &name, &age, &gender)){
return NULL;
} // keys 就是函数的所以参数的名字,然后后面把指针传进去,注意顺序要和参数顺序保持一致
wchar_t res[100];
swprintf(res, 100, L"name: %s, age: %d, gender: %s", name, age, gender);
return PyUnicode_FromWideChar(res, wcslen(res));
}
static PyMethodDef methods[] = {
{
"f1",
(PyCFunction) f1,
METH_VARARGS | METH_KEYWORDS, // 注意这里, 因为支持位置参数和关键字参数, 所以是 METH_VARARGS | METH_KEYWORDS
NULL
},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named kagura_nana",
-1,
methods,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void)
{
return PyModule_Create(&module);
}
用 Python 来测试一下。
import kagura_nana
try:
print(kagura_nana.f1())
except Exception as e:
print(e) # function missing required argument 'name' (pos 1)
try:
print(kagura_nana.f1(123))
except Exception as e:
print(e) # argument 1 must be str, not int
print(kagura_nana.f1("古明地觉")) # name: 古明地觉, age: 17, gender: FEMALE
print(kagura_nana.f1("古明地恋", 16)) # name: 古明地恋, age: 16, gender: FEMALE
print(kagura_nana.f1("古明地恋", 16, "女")) # name: 古明地恋, age: 16, gender: 女
我们看到一切都符合我们的预期,而且 PyArg_ParseTuple,和 PyArg_ParseTupleAndKeywords 可以自动帮我们检测参数是否合法,不合法抛出合理的异常。当然你也可以检测参数的个数,或者将参数一个一个获取、用 PyXxx_Check 系列检测函数进行判断,看看是否符合预期,当然这么做就比较麻烦了。
PyArg_ParseTuple 和 PyArg_ParseTupleAndKeywords 里面的占位符还可以接收一些特殊的符号,我们举个栗子。为了更好的说明,我们统一以 PyArg_ParseTupleAndKeywords 为例。
占位符 :
下面的是之前写的 C 代码,我们不做任何改动,来测试一下当参数传递错误时的报错信息。
#include "Python.h"
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
wchar_t *name;
int age = 17;
wchar_t *gender = L"FEMALE";
char *keys[] = {"name", "age", "gender", NULL};
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "u|iu", keys, &name, &age, &gender)){
return NULL;
}
wchar_t res[100];
swprintf(res, 100, L"name: %s, age: %d, gender: %s", name, age, gender);
return PyUnicode_FromWideChar(res,wcslen(res));
}
static PyMethodDef methods[] = {
{
"f1",
(PyCFunction) f1,
METH_VARARGS | METH_KEYWORDS,
NULL
},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named kagura_nana",
-1,
methods,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void)
{
return PyModule_Create(&module);
}
我们用 Python 来测试一下,注意观察报错信息。
import kagura_nana
try:
print(kagura_nana.f1())
except Exception as e:
print(e) # function missing required argument 'name' (pos 1)
try:
print(kagura_nana.f1("古明地觉", xxx=123))
except Exception as e:
print(e) # 'xxx' is an invalid keyword argument for this function
try:
print(kagura_nana.f1("古明地觉", name=123))
except Exception as e:
print(e) # argument for function given by name ('name') and position (1)
报错信息似乎没有什么特别的,但是注意了,我们来做一下改动。
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "u|iu:abcdefg", keys, &name, &age, &gender)){
return NULL;
}
其它地方都不变,我们只在 format 字符串的结尾加上了一个 :abcdefg,然后编译再来测试一下。
import kagura_nana
try:
print(kagura_nana.f1())
except Exception as e:
print(e) # abcdefg() missing required argument 'name' (pos 1)
try:
print(kagura_nana.f1("古明地觉", xxx=123))
except Exception as e:
print(e) # 'xxx' is an invalid keyword argument for abcdefg()
try:
print(kagura_nana.f1("古明地觉", name=123))
except Exception as e:
print(e) # argument for abcdefg() given by name ('name') and position (1)
你看到了什么?没错,默认的报错信息使用的是 function,但我们通过在占位符中指定 :xxx ,可以将 function 变成我们指定的内容 xxx,一般和函数名保持一致。另外需要注意的是,:xxx 要出现在占位符的结尾,并且只能出现一次。如果这样的话会变成什么样子呢?
PyArg_ParseTupleAndKeywords(args, kwargs, "u:aaa|iu:abcdefg", keys, &name, &age, &gender)
显然这变成了只接受一个参数,然后我们将参数不对时、返回报错信息中的 function 换成了 aaa|iu:abcdefg。并且你在传递参数的时候还会报出如下错误:
SystemError: More keyword list entries (3) than format specifiers (1)
因为占位符中相当于只有一个 u,也就是接收一个参数,但是我们后面跟了 &name、&age、&gender。关键字 entry 是 3,占位符是 1,两者不匹配。因此 :xxx 一定要出现在最后面,并且只能出现一次。
另外,即使函数不接收参数我们也是可以这么做的,比如:
#include "Python.h"
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
char *keys[] = {NULL};
// 不接收参数
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "", keys)){
return NULL;
}
Py_INCREF(Py_None);
return Py_None;
}
static PyMethodDef methods[] = {
{
"f1",
(PyCFunction) f1,
METH_VARARGS | METH_KEYWORDS,
NULL
},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named kagura_nana",
-1,
methods,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void)
{
return PyModule_Create(&module);
}
import kagura_nana
try:
print(kagura_nana.f1("xxx"))
except Exception as e:
print(e) # function takes at most 0 arguments (1 given)
然后我们加上 :xxx。
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
char *keys[] = {NULL};
// 这里还可以使用数字
if (!PyArg_ParseTupleAndKeywords(args, kwargs, ":123", keys)){
return NULL;
}
Py_INCREF(Py_None);
return Py_None;
}
import kagura_nana
try:
print(kagura_nana.f1("xxx"))
except Exception as e:
print(e) # 123() takes at most 0 arguments (1 given)
我们看到返回信息也被我们修改了,以上就是 :xxx 的作用。所以目前我们看到了两个特殊符号,一个是 | 用来实现默认参数,一个是这里的 : 用来自定义报错信息中的函数名。
占位符 !
我们说占位符 O 表示接收一个 Python 中的对象,但这个对象显然是没有限制的,可以是列表、可以是字典等等。我们之前是通过 Check 的方式进行检测,但是 Python 底层为我们提供更简便的做法,先来看一个常规的例子:
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
char *keys[] = {"val1", "val2", "val3", NULL};
PyObject *val1;
PyObject *val2;
PyObject *val3;
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "OOO", keys, &val1, &val2, &val3)){
return NULL;
}
Py_INCREF(Py_None);
return Py_None;
}
这个例子很简单,就是接收三个 PyObject *,但如果我希望第一个参数的类型是浮点型,第三个参数的类型是字典,这个时候该怎么做呢?此时 ! 就派上用场了。
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
char *keys[] = {"val1", "val2", "val3", NULL};
PyObject *val1;
PyObject *val2;
PyObject *val3;
// 我们希望限制第一个参数和第三个参数的类型, 那么在它们的后面加上 ! 即可
// 但是注意: 一旦加上了 !, 那么 O! 就要对应两个位置(分别是类型和变量, 当然都是指针)
// 我们说, 第一个参数是浮点型, 那么第一个 O! 对应 &PyFloat_Type, &val1
// 第二个参数没有限制, 那么就是 &val2
// 第三个参数是字典, 那么最后一个 O! 对应 &PyDict_Type, &val3
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "O!OO!:my_func", keys,
&PyFloat_Type, &val1, &val2, &PyDict_Type, &val3)){
return NULL;
}
Py_INCREF(Py_None);
return Py_None;
}
然后其它地方不变,我们来编译测试一下。
import kagura_nana
try:
print(kagura_nana.f1(123, 123, "xx"))
except Exception as e:
print(e) # my_func() argument 1 must be float, not int
try:
print(kagura_nana.f1(123.0, 11, "xx"))
except Exception as e:
print(e) # my_func() argument 3 must be dict, not str
这个功能就很方便了,可以让我们更加轻松地限制参数类型。但如果你用过 Cython 的话,你会发现我这里所说的方便实在是不敢恭维。如果你要写扩展,那么我强烈推荐 Cython,而且用 Cython 可以轻松的连接 C / C++。
注意:! 只能跟在 O 的后面。
占位符 &
& 的话,对于我们编写扩展而言用的不是很多,首先 & 和 上面说的 ! 用法类似,并且都只能跟在 O 的后面。O! 的话,我们说会对应一个类型指针和一个 PyObject *(参数就会传递给它),会判断传递的参数的类型是否和指定的类型一致。但 O& 的话,则是对应一个函数(convert)和一个任意类型的指针(address),会执行 convert(object, address),这个 object 就是我们传递过来的参数。我们举个栗子:
void convert(PyObject *object, long *any){
// 将 object 转成 long, 赋值给 *any
*any = PyLong_AsLong(object);
}
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
char *keys[] = {"val1", NULL};
long any = 0;
// 我们传递一个 Python 中的整数(假设为 PyObject *val1), 那么这里就会执行 convert(val1, &any)
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "O&", keys,
convert, &any)){
return NULL;
}
// 执行完毕之后, any 就会被改变, 为了方便我们就直接打印一下吧, 顺便加一个 1
printf("any = %ld\n", any + 1);
Py_INCREF(Py_None);
return Py_None;
}
我们来测试一下:
print(kagura_nana.f1(123))
"""
any = 124
None
"""
效果大概就是这样,个人觉得对于我们编写扩展而言用处不是很大,了解一下即可。
占位符 ;
占位符 ; 和 : 比较类似,但 ; 更加粗暴。至于怎么个粗暴法,看个栗子就一目了然了。
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
char *keys[] = {"val1", NULL};
PyObject *val1;
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "O!;my name is van, i am a artist, a performance artist", keys,
&PyFloat_Type, &val1)){
return NULL;
}
Py_INCREF(Py_None);
return Py_None;
}
然后我们来调用试试,看看会有什么结果:
import kagura_nana
try:
print(kagura_nana.f1())
except Exception as e:
print(e) # function missing required argument 'val1' (pos 1)
try:
print(kagura_nana.f1(123, 123))
except Exception as e:
print(e) # function takes at most 1 argument (2 given)
目前来看的话,似乎一切正常,但是往下看:
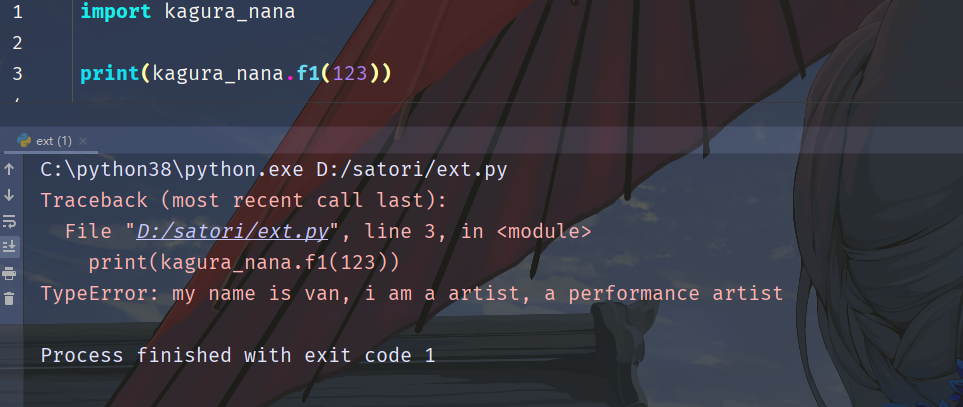
此时把整个报错信息都给修改了,因此这个符号也不是很常用。
注意:
;同样需要放到结尾,并且和:相互排斥,两者不可同时出现。
占位符 $
老规矩,还是先来看一个常规的例子。
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
char *keys[] = {"val1", "val2", "val3", NULL};
PyObject *val1;
PyObject *val2;
PyObject *val3;
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "OOO", keys,
&val1, &val2, &val3)){
return NULL;
}
Py_INCREF(Py_None);
return Py_None;
}
import kagura_nana
print(kagura_nana.f1(123, 123, 123))
print(kagura_nana.f1(123, val2=123, val3=123))
print(kagura_nana.f1(123, 123, val3=123))
print(kagura_nana.f1(val1=123, val2=123, val3=123))
以上都是没有问题的,可以通过位置参数传递、也可以通过关键字参数传递,只要位置参数在关键字参数之前即可。但如果我们希望某个参数只能通过关键字的方式传递呢?
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
char *keys[] = {"val1", "val2", "val3", NULL};
PyObject *val1;
PyObject *val2;
PyObject *val3;
// 指定一个 $, 那么 $ 后面只能通过关键字参数的方式传递
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "OO$O", keys,
&val1, &val2, &val3)){
return NULL;
}
Py_INCREF(Py_None);
return Py_None;
}
重新编译然后测试:
import kagura_nana
print(kagura_nana.f1(123, val2=123, val3=123))
print(kagura_nana.f1(123, 123, val3=123))
print(kagura_nana.f1(val1=123, val2=123, val3=123))
# 以上仍然是正常的, 都会打印 None
# 但是下面不行了, 因为 val3 必须通过关键字参数的方式传递
try:
kagura_nana.f1(123, 123, 123)
except Exception as e:
print(e) # function takes exactly 2 positional arguments (3 given)
# 其实这就等价于如下:
def f1(val1, val2, *, val3):
return None
不过有一点需要注意,目前来说,如果 | 和 $ 同时出现的话,那么 | 必须要在 $ 的前面。所以如果既有仅限关键字参数、又有可选参数,那么仅限关键字参数必须同时也是可选参数,所以 | 要在 $ 的前面。如果我们把 | 写在了 $ 的后面,那么执行会抛异常。
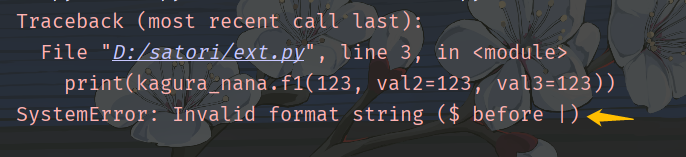
并且,即便仅限关键字参数和默认参数相同,那也应该这么写 OO|$O,而不能这么写 OO$|O。
占位符 #
这个 # 不可以跟在 O 后面,它是跟在 s 或者 u 后面,用来限制长度,有兴趣自己去了解一下。
Py_BuildValue
下面介绍一个非常方便的函数 Py_BuildValue,专门用来对数据进行打包的,返回一个 PyObject *,同样是通过占位符的方式。
Py_BuildValue 的占位符和 PyArg_ParseTuple 里面的占位符是一致的,只不过功能相反。比如:i,PyArg_ParseTuple 是将 Python 中的 int 转成 C 中的 int,而 Py_BuildValue 是将 C 中的 int 打包成 Python 中的 int。所以它们的占位符一致,功能正好相反,并且我们在介绍 PyArg_ParseTuple 的时候只介绍一部分占位符,其实支持的占位符不止我们上面说的那些,下面就来罗列一下。
再重复一次,PyArg_ParseTuple 和 Py_BuildValue 的占位符是一致的,但是功能相反。

我们只接用官方的栗子,因为官方给的栗子非常直观。
Py_BuildValue("") None
Py_BuildValue("i", 123) 123
Py_BuildValue("iii", 123, 456, 789) (123, 456, 789)
Py_BuildValue("s", "hello") 'hello'
Py_BuildValue("y", "hello") b'hello'
Py_BuildValue("ss", "hello", "world") ('hello', 'world')
Py_BuildValue("s#", "hello", 4) 'hell'
Py_BuildValue("y#", "hello", 4) b'hell'
Py_BuildValue("()") ()
Py_BuildValue("(i)", 123) (123,)
Py_BuildValue("(ii)", 123, 456) (123, 456)
Py_BuildValue("(i,i)", 123, 456) (123, 456)
Py_BuildValue("[i,i]", 123, 456) [123, 456]
Py_BuildValue("{s:i,s:i}", "abc", 123, "def", 456) {'abc': 123, 'def': 456}
Py_BuildValue("((ii)(ii)) (ii)", 1, 2, 3, 4, 5, 6) (((1, 2), (3, 4)), (5, 6))
如果是多个符号,自动会变成一个元组。我们来测试一下:
#include "Python.h"
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
PyObject *lst = PyList_New(5);
PyList_SetItem(lst, 0,
Py_BuildValue("i", 123));
PyList_SetItem(lst, 1,
Py_BuildValue("is", 123, "hello matsuri"));
PyList_SetItem(lst, 2,
Py_BuildValue("[i, i]", 123, 321));
PyList_SetItem(lst, 3,
Py_BuildValue("(s)s", "hello", "matsuri"));
PyList_SetItem(lst, 4,
Py_BuildValue("{s: s}", "hello", "matsuri"));
return lst;
}
static PyMethodDef methods[] = {
{
"f1",
(PyCFunction) f1,
METH_VARARGS | METH_KEYWORDS,
NULL
},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named kagura_nana",
-1,
methods,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void)
{
return PyModule_Create(&module);
}
from pprint import pprint
import kagura_nana
pprint(kagura_nana.f1())
"""
[123,
(123, 'hello matsuri'),
[123, 321],
(('hello',), 'matsuri'),
{'hello': 'matsuri'}]
"""
我们看到结果是符合我们的预期的,另外除了 Py_BuildValue 之外,还有一个 PyTuple_Pack,这两者是类似的,只不过后者只接收 PyObject *,举个栗子就很清晰了:
Py_BuildValue("OO", a, b) 等价于 PyTuple_Pack(2, a, b)
这个是固定打包成元组,而且第一个参数是个数,不是 format,因此它不支持通过占位符来指定元素类型,而是只接收 PyObject *。
操作 PyDictObject
Python 中的字典在底层要如何读取、如何设置,这个我们必须要好好地说一说。像整型、浮点型、字符串、元组、列表、集合,它们都比较简单,我们就不详细说了。比如列表:Python 中插入元素是调用 insert,那么底层则是 PyList_Insert;追加元素是 append,那么底层则是 PyList_Append;设置元素是 __setitem__,那么底层则是 PyList_SetItem;同理获取元素是 PyList_GetItem,写法非常具有规范性。所以如果不知道某个 API 的话,可以去查看解释的源码,比如你想查看元组,那么就去 Include/tupleobject.h 中查看:
像这些凡是以 PyAPI 开头的都是可以直接用的,PyAPI_DATA 表示数据,PyAPI_FUNC 表示函数,至于它们的含义是什么,我们可以通过文档查看。在 Python 的安装目录的 Doc 目录下就有,点击通过关键字进行检索即可。当然基本数据类型的一些方法,相信通过函数名即可判断,比如:PyTuple_GetItem,很明显就是通过索引获取元素的。还是那句话,Python 解释器的整个工程,在命名方面都非常有规律。
所以我们的重点是字典的使用,因为字典比较特殊,它里面的键值对的形式,而列表、元组等容器里面的元素是单一独立的。
PyDictObject 的读取
先来介绍内部关于读取的一些 API:
PyDict_Contains(dic, key):判断字典中是否具有某个 keyPyDict_GetItem(dic, key):获取字典中某个 key 对应的 valuePyDict_GetItemString(dic, key):和 PyDict_GetItem 作用相同,但这里的 key 是一个 char *PyDict_Keys(dic):获取所有的 keyPyDict_Values(dic):获取所有的 valuePyDict_Items(dic):获取所有的 key-value
下面我们来操作一波:
#include "Python.h"
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
PyObject *dic;
char *keys[] = {"dic", NULL};
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "O!", keys, &PyDict_Type, &dic)){
return NULL;
}
PyObject *res; // 返回值
// 1. 检查是否包含 "name" 这个 key
PyObject *name = PyUnicode_FromString("name");
if (!PyDict_Contains(dic, name)){
res = PyUnicode_FromString("key `name` does not exists");
} else {
res = PyDict_GetItem(dic, name);
// 注意:这一步很关键,因为我们下面返回了 res,而这个 res 是从 Python 传递过来的字典中获取的
// 因此它的引用计数不会加 1,只是指向了某个已存在的空间,因此返回之前我们需要将引用计数加 1
// 至于 if 里面的 res,因为它是在 C 中创建了新的空间,所以不需要关心
Py_INCREF(res);
}
// 此时我们能直接返回 res 吗? 很明显是不能的,因为我们上面还创建了一个 Python 的字符串 name
// 这是在 C 中创建的,并且也没作为返回值,那么我们就必须要手动将其引用计数减 1
// 因此这种时候更推荐使用 PyDict_GetItemString,它接收一个 C 字符串,函数结束时自动释放
// 但是很明显这个函数局限性比较大
Py_DECREF(name);
return res;
}
static PyMethodDef methods[] = {
{
"f1",
(PyCFunction) f1,
METH_VARARGS | METH_KEYWORDS,
NULL
},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named kagura_nana",
-1,
methods,
NULL, NULL, NULL, NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void)
{
return PyModule_Create(&module);
}
import kagura_nana
try:
print(kagura_nana.f1(""))
except Exception as e:
print(e) # argument 1 must be dict, not str
print(kagura_nana.f1({})) # key `name` does not exists
print(kagura_nana.f1({"name": "古明地觉"})) # 古明地觉
PyDictObject 的遍历
首先我们说可以通过 PyDict_Keys、PyDict_Values、PyDict_Items 来进行遍历,下面演示一下。
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
PyObject *dic;
char *keys[] = {"dic", NULL};
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "O!", keys, &PyDict_Type, &dic)){
return NULL;
}
PyObject *res = PyList_New(3); // 返回值
PyList_SetItem(res, 0, PyDict_Keys(dic));
PyList_SetItem(res, 1, PyDict_Values(dic));
PyList_SetItem(res, 2, PyDict_Items(dic));
return res;
}
import kagura_nana
print(kagura_nana.f1({"name": "satori", "age": 17}))
"""
[['name', 'age'],
['satori', 17],
[('name', 'satori'), ('age', 17)]]
"""
而且我们看到 PyDict_Keys 等函数返回的是列表,这说明创建了一个新的空间,引用计数为 1。但我们没有调用 Py_DECREF,这是因为我们将其放在了一个新的列表中,如果作为某个容器的元素,那么引用计数也应该要增加。但对于 PyListObject、PyTupleObject 而言,通过 PyList_SetItem、PyTuple_SetItem 是不会增加指向对象的引用计数的,所以结果正好抵消,我们不需要对引用计数做任何处理。
但如果我们是通过 PyList_Append 进行追加、或者 PyList_Insert 进行插入的话,那么是会增加引用计数的,这样引用计数就增加了 2,因此我们还需要减去 1。所以这一点比较烦人,因为你光知道何时增加引用计数、何时减少引用计数还是不够的,你还要看某一个操作到底有没有增加、或者减少。就拿我们这里设置元素为例,本来作为容器内的一个元素,理论上是要增加引用计数的,但是结果却没有增加。而添加和插入元素,也是作为容器的一个元素,但是这两个操作却增加了。所以还是推荐 Cython,再度安利一波,写扩展用 Cython 真的非常香。
这里我们将元素都获取出来了,至于遍历也很简单,这里不测试了。
PyDictObject 的设置和删除
PyDict_SetItem(dic, key, value):设置元素PyDict_DelItem(dic, key, value):删除元素PyDict_Clear(dic):清空字典
static PyObject *
f1(PyObject *self, PyObject *args, PyObject *kwargs)
{
PyObject *dic;
char *keys[] = {"dic", NULL};
if (!PyArg_ParseTupleAndKeywords(args, kwargs, "O!", keys, &PyDict_Type, &dic)){
return NULL;
}
// 设置一个 "name": "satori"
PyObject *key = PyUnicode_FromString("name");
PyObject *value = PyUnicode_FromString("satori");
PyDict_SetItem(dic, key, value);
// 因为 key 和 value 是 C 中创建的,首先引用计数为 1
// 然后它们又放到了字典里,对于字典而言,设置元素是会增加引用计数的,所以这里引用计数变成了 2
// 因此我们需要手动将它们的引用计数减去 1,否则这个键值对永远不会被回收。
// 所以最让人烦的就是这个引用计数,非常的讨厌,因为你不知道它到底有没有增加
Py_XDECREF(key);
Py_XDECREF(value);
// 如果有 "age" 这个 key 就将其删掉
key = PyUnicode_FromString("age");
if (PyDict_Contains(dic, key)) {
PyDict_DelItem(dic, key);
}
Py_XDECREF(key); // 同样减少引用计数
Py_INCREF(Py_None);
return Py_None;
}
测试一下:
import kagura_nana
dic = {"name": "mashiro", "age": 17}
kagura_nana.f1(dic)
print(dic) # {'name': 'satori'}
当然还有很多其它 API,可以查看源代码(Include/dictobject.h)自己测试一下。
编写扩展类
我们之前在 C 中编写的都是函数,但光有函数显然是不够的,我们需要实现类。而在 C 中实现的类被称为扩展类,它和 Python 内置的类(int、dict、str等等)是等价的,都属于静态类,直接指向了 C 一级的数据结构。
下面来看看在 C 中如何实现扩展类,首先我们来实现一个最基本的扩展类,也就是只包含一些最关键的部分。然后再添加类参数、方法,以及继承等等。
当然最重要的一点,我们还要解决类的循环引用、以及自定义垃圾回收。像列表、元组、字典等容器,它们也都会发生循环引用。
前面有一点我们没有提,当一个容器(比如列表)引用计数减一的时候,里面的元素(指向的对象)的引用计数是不会发生改变的。只有当一个容器的引用计数为 0 被销毁的时候,在销毁之前会先将内部元素的引用计数都减 1,然后再销毁这个容器。
而循环引用是引用计数机制所面临的最大的痛点,所以 Python 中的 gc 就是来干这个事情的,通过分代技术根据对象的生命周期划分为三个链表,然后通过三色标记模型来找出那些具有循环引用的对象,改变它们的引用计数。所以在 Python 中一个对象是否要被回收,最终还是取决于它的引用计数是否为 0。如果是 Python 代码的话,我们在实现类的时候,解释器会自动帮我们处理这一点,但我们是做类扩展,因此这些东西就必须由我们来考虑了。
编写扩展类前奏曲
我们之前编写了扩展函数,我们说首先要创建一个模块,这里也是一样的,因为类也要在模块里面。编写函数是有套路的,编写类也是一样,我们还是先看看大致的流程,具体细节会在慢慢补充。
首先我们需要了解以下内容:
1. 一个类要有类名、构造函数、析构函数2. 所有的类在底层都是一个 PyTypeObject 实例,而且类也是一个对象3. PyType_Ready 对类进行初始化,主要是进行属性字典的设置4. PyModule_AddObject,将扩展类添加到模块中
那么一个类在底层都有哪些属性呢?很明显,我们说所有的类都是一个 PyTypeObject 实例,那么我们就把这个结构体拷贝出来看一下就知道了。
// 下面我们来介绍一下内部成员都代表什么含义
typedef struct _typeobject {
// 头部信息,PyVarObject ob_base; 里面包含了引用计数、类型、ob_size
// 而创建这个结构体实例的话,Python 提供了一个宏,PyVarObject_HEAD_INIT(type, size)
// 传入类型和大小可以直接创建,至于引用计数则默认为 1
PyObject_VAR_HEAD
// 创建之后的类名
const char *tp_name; /* For printing, in format "<module>.<name>" */
// 大小,用于申请空间的,注意了,这里是两个成员
Py_ssize_t tp_basicsize, tp_itemsize; /* For allocation */
/* Methods to implement standard operations */
// 析构方法__del__,当删除实例对象时会调用这个操作
// typedef void (*destructor)(PyObject *); 函数接收一个PyObject *,没有返回值
destructor tp_dealloc;
// 打印其实例对象是调用的函数
// typedef int (*printfunc)(PyObject *, FILE *, int); 函数接收一个PyObject *、FILE * 和 int
printfunc tp_print;
// 获取属性,内部的 __getattr__ 方法
// typedef PyObject *(*getattrfunc)(PyObject *, char *);
getattrfunc tp_getattr;
// 设置属性,内部的 __setattr__ 方法
// typedef int (*setattrfunc)(PyObject *, char *, PyObject *);
setattrfunc tp_setattr;
// 在 Python3.5之后才产生的,这个不需要关注。
// 并且在其它类的注释中,这个写的都是tp_reserved
PyAsyncMethods *tp_as_async; /* formerly known as tp_compare (Python 2)
or tp_reserved (Python 3) */
// 内部的 __repr__方法
// typedef PyObject *(*reprfunc)(PyObject *);
reprfunc tp_repr;
// 一个对象作为数值所有拥有的方法
PyNumberMethods *tp_as_number;
// 一个对象作为序列所有拥有的方法
PySequenceMethods *tp_as_sequence;
// 一个对象作为映射所有拥有的方法
PyMappingMethods *tp_as_mapping;
/* More standard operations (here for binary compatibility) */
//内部的 __hash__ 方法
// typedef Py_hash_t (*hashfunc)(PyObject *);
hashfunc tp_hash;
// 内部的 __call__ 方法
// typedef PyObject * (*ternaryfunc)(PyObject *, PyObject *, PyObject *);
ternaryfunc tp_call;
// 内部的 __repr__ 方法
// typedef PyObject *(*reprfunc)(PyObject *);
reprfunc tp_str;
// 获取属性
// typedef PyObject *(*getattrofunc)(PyObject *, PyObject *);
getattrofunc tp_getattro;
// 设置属性
// typedef int (*setattrofunc)(PyObject *, PyObject *, PyObject *);
setattrofunc tp_setattro;
//作为缓存,不需要关心
/*
typedef struct {
getbufferproc bf_getbuffer;
releasebufferproc bf_releasebuffer;
} PyBufferProcs;
*/
PyBufferProcs *tp_as_buffer;
// 这个类的特点,比如:
// Py_TPFLAGS_HEAPTYPE: 是否在堆区申请空间
// Py_TPFLAGS_BASETYPE: 是否允许这个类被其它类继承
// Py_TPFLAGS_IS_ABSTRACT: 是否为抽象类
// Py_TPFLAGS_HAVE_GC: 是否被垃圾回收跟踪
// 这里面有很多,具体可以去 object.h 中查看
// 一般我们设置成 Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE | Py_TPFLAGS_HAVE_GC 即可
unsigned long tp_flags;
// 这个类的注释
const char *tp_doc; /* Documentation string */
//用于检测是否出现循环引用,和下面的tp_clear是一组
/*
class A:
pass
a = A()
a.attr = a
此时就会出现循环引用
*/
// typedef int (*traverseproc)(PyObject *, visitproc, void *);
traverseproc tp_traverse;
// 删除对包含对象的引用
inquiry tp_clear;
// 富比较
// typedef PyObject *(*richcmpfunc) (PyObject *, PyObject *, int);
richcmpfunc tp_richcompare;
// 弱引用,不需要关心
Py_ssize_t tp_weaklistoffset;
// __iter__方法
// typedef PyObject *(*getiterfunc) (PyObject *);
getiterfunc tp_iter;
// __next__方法
// typedef PyObject *(*iternextfunc) (PyObject *);
iternextfunc tp_iternext;
/* Attribute descriptor and subclassing stuff */
// 内部的方法,这个 PyMethodDef 不陌生了吧
struct PyMethodDef *tp_methods;
// 内部的成员
struct PyMemberDef *tp_members;
// 一个结构体,包含了 name、get、set、doc、closure
struct PyGetSetDef *tp_getset;
// 继承的基类
struct _typeobject *tp_base;
// 内部的属性字典
PyObject *tp_dict;
// 描述符,__get__ 方法
// typedef PyObject *(*descrgetfunc) (PyObject *, PyObject *, PyObject *);
descrgetfunc tp_descr_get;
// 描述符,__set__ 方法
// typedef int (*descrsetfunc) (PyObject *, PyObject *, PyObject *);
descrsetfunc tp_descr_set;
// 生成的实例对象是否有属性字典
// 我们上一个例子中的实例对象显然是没有属性字典的,因为我们当时没有设置这个成员
Py_ssize_t tp_dictoffset;
// 初始化函数
// typedef int (*initproc)(PyObject *, PyObject *, PyObject *);
initproc tp_init;
// 为实例对象分配空间的函数
// typedef PyObject *(*allocfunc)(struct _typeobject *, Py_ssize_t);
allocfunc tp_alloc;
// __new__ 方法
// typedef PyObject *(*newfunc)(struct _typeobject *, PyObject *, PyObject *);
newfunc tp_new;
// 我们一般设置到 tp_new 即可,剩下的就不需要管了
// 释放一个实例对象
// typedef void (*freefunc)(void *); 一般会在析构函数中调用
freefunc tp_free; /* Low-level free-memory routine */
// typedef int (*inquiry)(PyObject *); 是否被 gc 跟踪
inquiry tp_is_gc; /* For PyObject_IS_GC */
// 继承哪些类,这里可以指定继承多个类
// 这个还是有必要的,因此这个可以单独设置
PyObject *tp_bases;
//下面的就不需要关心了
PyObject *tp_mro; /* method resolution order */
PyObject *tp_cache;
PyObject *tp_subclasses;
PyObject *tp_weaklist;
destructor tp_del;
unsigned int tp_version_tag;
destructor tp_finalize;
} PyTypeObject;
这里面我们看到有很多成员,如果有些成员我们不需要的话,那么就设置为 0 即可。不过即便设置为 0,但是有些成员我们在调用 PyType_Ready 初始化的时候,也会设置进去。比如 tp_dict,这个我们创建类的时候没有设置,但是这个类是有属性字典的,因为在 PyType_Ready 中设置了;但有的不会,比如 tp_dictoffset,这个我们没有设置,那么类在 PyType_Ready 中也不会设置,因此这个类的实例对象,就真的没有属性字典了。再比如 tp_free,我们也没有设置,但是是可以调用的,原因你懂的。
虽然里面的成员非常多,但是我们在实现的时候不一定每一个成员都要设置。如果只需要指定某几个成员的话,那么我们可以先创建一个 PyTypeObject 实例,然后针对指定的属性进行设置即可。
下面我们来编写一个简单的扩展类,具体细节在代码中体现。
#include "Python.h"
// 这一步是直接定义一个类,它就是我们在 Python 中使用的类,这里采用 C++,因此我们编译时的文件要从 main.c 改成 main.cpp
class MyClass {
public:
PyObject_HEAD // 公共的头部信息
};
/*
或者你直接使用结构体的方式也是可以的,这样源文件还叫 main.c 不需要修改
typedef struct {
PyObject_HEAD // 头部信息
} MyClass;
*/
// 这里我们实现 Python 中的 __new__ 方法,这个 __new__ 方法接收哪些参数来着
// 一个类本身,以及 __init__ 中的参数,我们一般会这样写 def __new__(cls, *args, **kwargs):
// 所以这里的第一个参数就不再是 PyObject *了,而是 PyTypeObject *
static PyObject *
MyClass_new(PyTypeObject *cls, PyObject *args, PyObject *kw)
{
// 我们说 Python 中的 __new__ 方法默认都干了哪些事来着
// 为创建的实例对象开辟一份空间,然后会将这份空间的指针返回回去交给 self
// 当然交给 __init__ 的还有其它参数,这些参数是 __init__ 需要使用的,__new__ 方法不需要关心
// 但是毕竟要先经过 __new__ 方法,所以 __new__ 方法中要有参数位能够接收
// 最终 __new__ 会将自身返回的 self 连同其它参数组合起来一块交给 __init__
// 所以 __init__ 中 self 我们不需要关心,我们只需要传递 self 后面的参数即可,因为在 __new__ 会自动传递self
// 另外多提一嘴:我们使用实例对象调用方法的时候,会自动传递 self,你有没有想过它为什么会自动传递呢?
// 其实这个在底层是使用了描述符,至于底层是怎么实现的,我们在之前已经说过了
// 所以我们这里要为 self 分配一个空间,self 也是一个指针,但是它已经有了明确的类型,所以我们需要转化一下
// 当然这里不叫 self 也是可以的,只是我们按照官方的约定,不会引起歧义
// 分配空间是通过调用 PyTypeObject 的 tp_alloc 方法,传入一个 PyTypeObject *,以及大小,这里是固定的所以是 0
MyClass *self = (MyClass *)cls -> tp_alloc(cls, 0); // 此时就由 Python 管理了
// 记得返回 self,转成 PyObject *,当然我们这里是 __new__ 方法的默认实现,你也可以做一些其它的事情来控制一下类的实例化行为
return (PyObject *)self;
}
// 构造函数接收三个 PyObject *, 但它返回的是一个 int, 0 表示成功、-1 表示失败
static int
MyClass_init(PyObject *self, PyObject *args, PyObject *kw)
{
// 假设这个构造函数接收三个参数:name,age,gender
char *name;
int age;
char *gender;
char *keys[] = {"name", "age", "gender", NULL};
if (!PyArg_ParseTupleAndKeywords(args, kw, "sis", keys, &name, &age, &gender)){
// 这里失败了不能返回 NULL,而是返回 -1,__init__ 比较特殊
return -1;
}
//至于如何设置到 self 当中,我们后面演示,这里先打印一下
printf("name = %s, age = %d, gender = %s\n", name, age, gender);
// 我们说结果为 0 返回成功,结果为 -1 返回失败,所以走到这里的话应该返回 0
return 0;
}
// 析构函数, 返回值是 void,关于这些函数的参数和返回值的定义可以查看上面介绍的 PyTypeObject 结构体
void
MyClass_del(PyObject *self)
{
// 打印一句话吧
printf("call __del__\n");
// 拿到类型,调用 tp_free 释放,这个是释放实例对象所占空间的。所以 tp_alloc 是申请、tp_dealloc 是释放
Py_TYPE(self) -> tp_free(self);
}
static PyModuleDef module = {
PyModuleDef_HEAD_INIT, // 头部信息
"kagura_nana", // 模块名
"this is a module named hanser", // 模块注释
-1, // 模块空间
0, // 这里是 PyMethodDef 数组,但是我们这里没有 PyMethodDef,所以就是 0,也就是我们这里面没有定义函数
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void) {
// 创建类的这些过程,我们也可以单独写,我们这里第一次演示就直接写在模块初始化函数里面了
// 实例化一个 PyTypeObject,但是这里面的属性非常多,我们通过直接赋值的方式需要写一大堆,所以先定义,然后设置指定的属性
static PyTypeObject cls;
// 我们知道 PyTypeObject 结构体的第一个参数就是 PyVarObject ob_base;
// 需要引用计数(初始为1)、类型 &PyType_Type、ob_size(不可变,写上0即可)
PyVarObject ob_base = {1, &PyType_Type, 0};
cls.ob_base = ob_base; // 类的公共头部
// 这里是类名,但是这个 MyClass 是 Python 中打印的时候显示的名字,或者说调用 __name__ 显示的名字
// 假设我们上面的是 MyClass1,那么在 Python 中你就需要使用 MyClass1 来实例化
// 但是使用 type 查看的时候显示的 MyClass,因为类名叫 MyClass,但是很明显这两者应该是一致的
cls.tp_name = "MyClass";
cls.tp_basicsize = sizeof(MyClass); // 类的空间大小
cls.tp_itemsize = 0; // 设置为 0
// 设置类的 __new__ 方法、__init__ 方法、__del__ 方法
cls.tp_new = MyClass_new;
cls.tp_init = MyClass_init;
cls.tp_dealloc = MyClass_del;
// 初始化类,调用 PyType_Ready,而且 Python 内部的类在创建完成之后也会调用这个方法进行初始化,它会对创建类进行一些属性的设置
// 记得传入指针进去
if (PyType_Ready(&cls) < 0){
// 如果结果小于0,说明设置失败
return NULL;
}
// 这个是我们自己创建的类,所以需要手动增加引用计数
Py_XINCREF(&cls);
// 加入到模块中,这个不需要在创建 PyModuleDef 的时候指定,而是可以单独添加
// 我们需要先把模块创建出来,然后通过 PyModule_AddObject 将类添加进去
PyObject *m = PyModule_Create(&module);
// 传入 创建的模块的指针 m、类名(这个类名要和我们上面设置的 tp_name 保持一致)、以及由 PyTypeObject * 转化得到的 PyObject *
// 另外多提一嘴,这里的 m、和 cls 以及上面 module 都只是 C 中的变量,具体的模块名和类名是 kagura_nana 和 MyClass
PyModule_AddObject(m, "MyClass", (PyObject *)&cls);
return m; // 将模块对象返回
}
然后是用于编译的 py 文件:
from distutils.core import *
setup(
name="kagura_nana",
version="1.11",
author="古明地盆",
author_email="66666@东方地灵殿.com",
# 这里改成 main.cpp
ext_modules=[Extension("kagura_nana", ["main.cpp"])],
)
注意:之前使用的都是自己住的地方的台式机,里面装了相应的环境,因为机器性能比较好。但是春节本人回家了,现在使用的是自己的笔记本,而笔记本里面没有装 Visual Studio 等环境,因此接下来环境会选择我阿里云上的 CentOS。
编译的方式跟之前一样,只不过需要先执行一下 yum install gcc-c++,否则编译时会抛出:
gcc: error trying to exec 'cc1plus': execvp: No such file or directory
如果你已经装了,那么是没有问题的,但也建议执行确认一下。下面操作一波:
>>> import kagura_nana
>>> kagura_nana
<module 'kagura_nana' from '/usr/local/lib64/python3.6/site-packages/kagura_nana.cpython-36m-x86_64-linux-gnu.so'>
>>> try:
... # 然后实例化一个类
... # 我们说这个类的构造函数中接收三个参数,我们先不传递,看看会有什么表现
... self = kagura_nana.MyClass()
... except Exception as e:
... print(e)
...
call __del__
Required argument 'name' (pos 1) not found
尽管实例化失败,但是这个对象在 __new__ 方法中被创建了,所以依旧会调用 __del__。然后我们传递参数,但是我们在构造函数中只是打印,并没有设置到 self 中。
>>> self = kagura_nana.MyClass("mashiro", 16, "female")
name = mashiro, age = 16, gender = female
>>> self.name
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'MyClass' object has no attribute 'name'
我们看到调用失败了,因为我们没有设置到 self 中,然后再看看析构函数。
>>> del self
call __del__
>>>
成功调用,然后里面的 printf 也成功执行。
给实例对象添加属性
整体流程我们大致了解了,下面看看如何给实例对象添加属性。我们说 PyTypeObject 里面有一个 tp_members 属性,很明显它就是用来指定实例对象的属性的。
#include "Python.h"
#include "structmember.h" // 添加成员需要导入这个头文件
class MyClass {
public:
PyObject_HEAD
// 添加成员,这里面的参数要和 __init__ 中的参数保持一致,你可以把 name、age、gender 看成是要通过 self. 的方式来设置的属性
// 假设这里面没有 gender,那么即使 Python 中传了 gender 这个参数、并且解析出来了
// 但是你仍然没办法设置,所以实例化的对象依旧无法访问
PyObject *name;
PyObject *age;
PyObject *gender;
};
/*
// 你仍然可以使用结构体的方式定义
typedef struct{
PyObject_HEAD
PyObject *name;
PyObject *age;
PyObject *gender;
}MyClass;
*/
static PyObject *
MyClass_new(PyTypeObject *cls, PyObject *args, PyObject *kw)
{
MyClass *self = (MyClass *)cls -> tp_alloc(cls, 0);
return (PyObject *)self;
}
static int
MyClass_init(PyObject *self, PyObject *args, PyObject *kw)
{
// 这里不使用 C 的类型了,使用 PyObject *,参数和原来一样
PyObject *name;
PyObject *age = NULL;
PyObject *gender = NULL;
// 注意:上面申明的三个 PyObject * 变量叫什么名字其实是没有所谓的,重点是 MyClass 和 下面 keys
// keys 里面的字符串就是 __init__ 中的参数名,MyClass 中的变量则是实例对象的属性名
// 假设把 MyClass 这个类中的 name 改成 NAME,那么最终的形式就等价于 self.NAME = name
char *keys[] = {"name", "age", "gender", NULL};
if (!PyArg_ParseTupleAndKeywords(args, kw, "O!|O!O!", keys, &PyUnicode_Type, &name,
&PyLong_Type, &age, &PyUnicode_Type, &gender)){
return -1;
}
// 注意: 有一个很关键的点,在 __init__ 函数调用结束之后,name、age、gender 的引用计数会减一
// 而它们又是从 Python 传递过来的,所以为了保证不出现悬空指针,我们必须要将引用计数手动加 1
Py_XINCREF(name);
// 而 age 和 gender 是可以不传的,我们需要给一个默认值。
// 当传递了 age,那么增加引用计数;没有传递 age,我们自己创建一个,由于是创建,引用计数初始为 1,所以此时就无需增加了。gender 也是同理
if (age) Py_XINCREF(age); else age = PyLong_FromLong(17);
if (gender) Py_XINCREF(gender); else gender = PyUnicode_FromWideChar(L"萌妹子", 3);
// 这里就是设置 __init__ 属性的,将解析出来的参数设置到 __init__ 中
// 注意 PyObject * 要转成 MyClass *,并且考虑优先级,我们需要使用括号括起来
((MyClass *)self) -> name = name;
((MyClass *)self) -> age = age;
((MyClass *)self) -> gender = gender;
// 此时我们的构造函数就设置完成了
return 0;
}
void
MyClass_del(PyObject *self)
{
// 同样的问题,当对象在销毁的时候,实例对象的成员的引用计数是不是也要减去 1 呢
Py_XDECREF(((MyClass *)self) -> name);
Py_XDECREF(((MyClass *)self) -> age);
Py_XDECREF(((MyClass *)self) -> gender);
Py_TYPE(self) -> tp_free(self);
}
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named hanser",
-1,
0,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void) {
static PyTypeObject cls;
PyVarObject ob_base = {1, &PyType_Type, 0};
cls.ob_base = ob_base;
cls.tp_name = "MyClass";
cls.tp_basicsize = sizeof(MyClass);
cls.tp_itemsize = 0;
cls.tp_new = MyClass_new;
cls.tp_init = MyClass_init;
cls.tp_dealloc = MyClass_del;
// 添加成员,这是一个 PyMemberDef 类型的数组,然后显然要把数组名放到类的 tp_members 中
// PyNumberDef 结构体有以下成员:name type offset flags doc
static PyMemberDef members[] = {
//这些成员具体值是什么?我们需要在 MyClass_init 中设置
{
"name", // 成员名
T_OBJECT_EX, // 类型,关于类型我们一会儿介绍
// 接收结构体对象和一个成员
// 获取对应值的偏移地址,由于 Python 中的类是动态变化的,所以 C 只能通过偏移的地址来找到对应的成员,offsetof 是一个宏
// 而这里面的 name 就是我们定义的 MyClass 里面的 name,所以如果 MyClass 里面不设置,那么这里会报错
offsetof(MyClass, name),
0, // 变量的读取类型,设置为 0 表示可读写,设置为 1 表示只读
"this is a name" //成员说明
},
// 这里将 age 设置为只读
{"age", T_OBJECT_EX, offsetof(MyClass, age), 1, "this is a age"},
{"gender", T_OBJECT_EX, offsetof(MyClass, gender), 0, "this is a gender"},
{NULL} // 结尾有一个{NULL}
};
// 设置成员,这一步很关键,否则之前的相当于白做
cls.tp_members = members;
if (PyType_Ready(&cls) < 0){
return NULL;
}
Py_XINCREF(&cls);
PyObject *m = PyModule_Create(&module);
PyModule_AddObject(m, "MyClass", (PyObject *)&cls);
return m;
}
我们来测试一下:
>>> import kagura_nana
>>> self = kagura_nana.MyClass("古明地觉")
>>> self.name, self.age, self.gender
('古明地觉', 17, '萌妹子')
>>>
>>> self = kagura_nana.MyClass("古明地恋", 16, "美少女")
>>> self.name, self.age, self.gender
('古明地恋', 16, '美少女')
>>>
>>> self.name, self.gender = "koishi", "びしょうじょ"
>>> self.name, self.age, self.gender
('koishi', 16, 'びしょうじょ')
>>>
>>> # 我们看到一些都没有问题,但接下来重点来了
...
>>> self.age = 16
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: readonly attribute
>>>
一切正常,并且我们看到 age 是只读的,因为我们在 PyMemberDef 中将其设置为只读,我们来看一下这个结构体。该结构体的定义藏身于 Include/structmember.h 中。
typedef struct PyMemberDef {
const char *name; // 实例属性的名字, 比如我们上面的 name、age、gender
int type; // 实例属性的类型, 这一点很关键, 支持的类型我们一会说
Py_ssize_t offset; // 实例属性的偏移量,通过 offsetof(TYPE, MEMBER) 这个宏来获取
int flags; // 设置为 0 表示可读可写, 设置为 1 表示只读
const char *doc; // 属性说明
} PyMemberDef;
然后我们重点看一下里面的 type 成员,它表示属性的类型,支持如下选项:
#define T_SHORT 0#define T_INT 1#define T_LONG 2#define T_FLOAT 3#define T_DOUBLE 4#define T_STRING 5#define T_OBJECT 6#define T_CHAR 7#define T_BYTE 8#define T_UBYTE 9#define T_USHORT 10#define T_UINT 11#define T_ULONG 12#define T_STRING_INPLACE 13#define T_BOOL 14#define T_OBJECT_EX 16#define T_LONGLONG 17#define T_ULONGLONG 18#define T_PYSSIZET 19#define T_NONE 20
我们的类(MyClass)中的成员应该是 PyObject *,但是用来接收参数的变量可以不是,只不过在设置实例属性的时候需要再转成 PyObject *,如果接收的就是 PyObject *,那么就不需要再转了。而上面这些描述的就是参数的类型,所以我们一般用 T_OBJECT_EX 即可,但是还有一个 T_OBJECT,这两者的区别是前者如果接收的是 NULL(没有接收到值),那么会引发一个 AttributeError。
到目前为止,我们应该感受到使用 C/C++ 来写扩展是一件多么痛苦的事情,特别是引用计数,一搞不好就出现内存泄漏或者悬空指针。因此,关键来了,再次安利一波 Cython。
除了 __init__、__new__、__del__ 之外,你还可以添加其它的方法,比如 tp_call、tp_getset 等等。
给类添加成员
一个类里面可以定义很多的函数,那么这在 C 中是如何实现的呢?很简单,和模块中定义函数是一致的。
#include "Python.h"
#include "structmember.h" // 添加成员需要导入这个头文件
class MyClass {
public:
PyObject_HEAD
// 添加成员,这里面的参数要和 __init__ 中的参数保持一致,你可以把 name、age、gender 看成是要通过 self. 的方式来设置的属性
// 假设这里面没有 gender,那么即使 Python 中传了 gender 这个参数、并且解析出来了
// 但是你仍然没办法设置,所以实例化的对象依旧无法访问
PyObject *name;
PyObject *age;
PyObject *gender;
};
static PyObject *
MyClass_new(PyTypeObject *cls, PyObject *args, PyObject *kw)
{
MyClass *self = (MyClass *)cls -> tp_alloc(cls, 0);
return (PyObject *)self;
}
static int
MyClass_init(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *name;
PyObject *age = NULL;
PyObject *gender = NULL;
char *keys[] = {"name", "age", "gender", NULL};
if (!PyArg_ParseTupleAndKeywords(args, kw, "O!|O!O!", keys, &PyUnicode_Type, &name,
&PyLong_Type, &age, &PyUnicode_Type, &gender)){
return -1;
}
Py_XINCREF(name);
if (age) Py_XINCREF(age); else age = PyLong_FromLong(17);
if (gender) Py_XINCREF(gender); else gender = PyUnicode_FromWideChar(L"萌妹子", 3);
((MyClass *)self) -> name = name;
((MyClass *)self) -> age = age;
((MyClass *)self) -> gender = gender;
return 0;
}
void
MyClass_del(PyObject *self)
{
Py_XDECREF(((MyClass *)self) -> name);
Py_XDECREF(((MyClass *)self) -> age);
Py_XDECREF(((MyClass *)self) -> gender);
Py_TYPE(self) -> tp_free(self);
}
// 下面来给类添加成员函数啦,添加方法跟之前的创建函数是一样的
static PyObject *
age_incr_1(PyObject *self, PyObject *args, PyObject *kw)
{
((MyClass *)self) -> age = PyNumber_Add(((MyClass *)self) -> age, PyLong_FromLong(1));
return Py_None;
}
//构建 PyMethodDef[], 方法和之前创建函数是一样的,但是这是类的方法,记得添加到类的 tp_methods 成员中
static PyMethodDef MyClass_methods[] = {
{"age_incr_1", (PyCFunction)age_incr_1, METH_VARARGS | METH_KEYWORDS, "method age_incr_1"},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named hanser",
-1,
0,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void) {
static PyTypeObject cls;
PyVarObject ob_base = {1, &PyType_Type, 0};
cls.ob_base = ob_base;
cls.tp_name = "MyClass";
cls.tp_basicsize = sizeof(MyClass);
cls.tp_itemsize = 0;
cls.tp_new = MyClass_new;
cls.tp_init = MyClass_init;
cls.tp_dealloc = MyClass_del;
static PyMemberDef members[] = {
{
"name",
T_OBJECT_EX,
offsetof(MyClass, name),
0,
"this is a name"
},
{"age", T_OBJECT_EX, offsetof(MyClass, age), 0, "this is a age"},
{"gender", T_OBJECT_EX, offsetof(MyClass, gender), 0, "this is a gender"},
{NULL}
};
cls.tp_members = members;
// 设置方法
cls.tp_methods = MyClass_methods;
if (PyType_Ready(&cls) < 0){
return NULL;
}
Py_XINCREF(&cls);
PyObject *m = PyModule_Create(&module);
PyModule_AddObject(m, "MyClass", (PyObject *)&cls);
return m;
}
我们看到几乎没有任何区别,那么下面就来测试一下:
>>> import kagura_nana
>>> self = kagura_nana.MyClass("古明地恋", 16, "美少女")
>>> self.age_incr_1()
>>> self.age
17
>>>
循环引用造成的内存泄漏
我们说 Python 的引用计数有一个重大缺陷,那就是它无法解决循环引用。
while True:
my = MyClass("古明地觉")
my.name = my
如果你执行上面这段代码的话,那么你会发现内存不断飙升,很明显我们上面在 C 中定义的类是没有考虑循环引用的,因为它没有被 GC 跟踪。
我们看到由于内存使用量不断增加,最后被操作系统强制 kill 掉了,主要就在于我们没有解决循环引用,导致实例对象不断被创建、但却没有被回收(引用计数最大的缺陷)。如果想要解决循环引用的话,那么就需要 Python 中的 GC 出马,而使用 GC 的前提是这个类的实例对象要被 GC 跟踪,因此我们还需要指定 tp_flags。除此之外,我们还要指定 tp_traverse(判断内部成员是否被循环引用)和 tp_clear(清理)两个函数,至于具体细节编写代码时有所体现。最后我们上面的那个类也是不允许被继承的,如果想被继承,同样需要指定 tp_flags。
>>> import kagura_nana
>>> class A(kagura_nana.MyClass):
... pass
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: type 'MyClass' is not an acceptable base type
>>>
我们看到 MyClass 不是一个可以被继承的类,那么下面我们来进行修改。
#include "Python.h"
#include "structmember.h"
class MyClass {
public:
PyObject_HEAD
PyObject *name;
PyObject *age;
PyObject *gender;
};
static PyObject *
MyClass_new(PyTypeObject *cls, PyObject *args, PyObject *kw)
{
MyClass *self = (MyClass *)cls -> tp_alloc(cls, 0);
return (PyObject *)self;
}
static int
MyClass_init(PyObject *self, PyObject *args, PyObject *kw)
{
PyObject *name;
PyObject *age = NULL;
PyObject *gender = NULL;
char *keys[] = {"name", "age", "gender", NULL};
if (!PyArg_ParseTupleAndKeywords(args, kw, "O!|O!O!", keys, &PyUnicode_Type, &name,
&PyLong_Type, &age, &PyUnicode_Type, &gender)){
return -1;
}
Py_XINCREF(name);
if (age) Py_XINCREF(age); else age = PyLong_FromLong(17);
if (gender) Py_XINCREF(gender); else gender = PyUnicode_FromWideChar(L"萌妹子", 3);
((MyClass *)self) -> name = name;
((MyClass *)self) -> age = age;
((MyClass *)self) -> gender = gender;
return 0;
}
static PyObject *
age_incr_1(PyObject *self, PyObject *args, PyObject *kw)
{
((MyClass *)self) -> age = PyNumber_Add(((MyClass *)self) -> age, PyLong_FromLong(1));
return Py_None;
}
static PyMethodDef MyClass_methods[] = {
{"age_incr_1", (PyCFunction)age_incr_1, METH_VARARGS | METH_KEYWORDS, "method age_incr_1"},
{NULL, NULL, 0, NULL}
};
// 判断是否被循环引用,参数和返回的值的定义还是参考源码,这里面的参数名要固定
static int MyClass_traverse(MyClass *self, visitproc visit, void *arg){
// 底层帮你提供了一个宏
Py_VISIT(self -> name);
Py_VISIT(self -> age);
Py_VISIT(self -> gender);
return 0;
}
// 清理
static int MyClass_clear(MyClass *self){
Py_CLEAR(self -> name);
Py_CLEAR(self -> age);
Py_CLEAR(self -> gender);
return 0;
}
void
MyClass_del(PyObject *self)
{
// 我们在 MyClass_clear 中使用了 Py_CLEAR,那么这里减少引用计数的逻辑就不需要了,直接调用 MyClass_clear 即可
MyClass_clear((MyClass *) self);
// 我们说 Python 会跟踪创建的对象,如果被回收了,那么应该从链表中移除
PyObject_GC_UnTrack(self);
Py_TYPE(self) -> tp_free(self);
}
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named hanser",
-1,
0,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void) {
static PyTypeObject cls;
PyVarObject ob_base = {1, &PyType_Type, 0};
cls.ob_base = ob_base;
cls.tp_name = "MyClass";
cls.tp_basicsize = sizeof(MyClass);
cls.tp_itemsize = 0;
cls.tp_new = MyClass_new;
cls.tp_init = MyClass_init;
cls.tp_dealloc = MyClass_del;
static PyMemberDef members[] = {
{
"name",
T_OBJECT_EX,
offsetof(MyClass, name),
0,
"this is a name"
},
{"age", T_OBJECT_EX, offsetof(MyClass, age), 0, "this is a age"},
{"gender", T_OBJECT_EX, offsetof(MyClass, gender), 0, "this is a gender"},
{NULL}
};
cls.tp_members = members;
cls.tp_methods = MyClass_methods;
// 解决循环引用造成的内存泄漏,通过 Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE | Py_TPFLAGS_HAVE_GC 开启垃圾回收,同时允许该类被继承
cls.tp_flags = Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE | Py_TPFLAGS_HAVE_GC;
// 设置 tp_traverse 和 tp_clear
cls.tp_traverse = (traverseproc) MyClass_traverse;
cls.tp_clear = (inquiry) MyClass_clear;
// 如果想指定继承的类的话,那么通过 tp_bases 指定即可,这里不再说了
if (PyType_Ready(&cls) < 0){
return NULL;
}
Py_XINCREF(&cls);
PyObject *m = PyModule_Create(&module);
PyModule_AddObject(m, "MyClass", (PyObject *)&cls);
return m;
}
下面我们来继续测试一下,看看有没有问题:
可以看到,此时类可以被继承了,并且也没有出现循环引用导致的内存泄漏。
真的想说,用 C 写扩展实在是太不容易了,很明显这还只是非常简单的,因为目前这个类基本没啥方法。如果加上描述符、自定义迭代器,或者我们再多写几个方法。方法之间互相调用,导入模块(目前还没有说)等等,绝对是让人头皮发麻的事情,所以写扩展我一般只用 Cython。
全局解释器锁
我们使用 C / C++ 写扩展除了增加效率之外,最大的特点就是能够释放掉 GIL,关于 GIL 也是一个老生常谈的问题。我在前面系列已经说过,这里不再赘述了。
那么问题来了,在 C 中如何获取 GIL 呢?
// 首先 Python 中的线程是对 C 线程的一个封装,同时还会对应一个 PyThreadState(线程状态) 对象,用来对线程状态进行描述
// 而如果要使用 Python / C API 的话,那么就不能是 C 中的线程,而是 Python 中的线程
Py_GILState_STATE gstate;
// 所以 Python 为了简便而提供了一个函数 PyGILState_Ensure,在 C 中创建了一个线程,那么调用这个函数后,C 线程就会被封装成 Python 中的线程
// 不然的话,我们要写好多代码。这一步会对 Python 中线程进行初始化创建一个 PyThreadState 对象,同时获取 GIL
//
gstate = PyGILState_Ensure();
// 做一些其它操作,注意:一旦使用 Python / C API,那么必须要获取到 GIL
call_some_function();
// 释放掉 GIL
PyGILState_Release(gstate);
一旦在 C 中获取到 GIL,那么 Python 的其它线程都必须处于等待状态,并且当调用扩展模块中的函数时,解释器是没有权利迫使当前线程释放 GIL 的,因为调用的是 C 的代码,Python 解释器能控制的只有 Python 的字节码这一层。所以在一些操作执行结束后,必须要主动释放 GIL,否则 Python 的其它线程永远不会得到被调度的机会。
但有时我们做的是一些纯 C / C++ 操作,不需要和 Python 进行交互,这个时候希望告诉 Python 解释器,其它的线程该执行执行,不用等我,这个时候怎么做呢?首先Python 底层给我们提供了两个宏:Py_BEGIN_ALLOW_THREADS 和 Py_END_ALLOW_THREADS。
// 将当前线程状态给保存下来,然后其它线程就可以继续执行了,从名字上也能看出,开始允许多个线程并行执行
#define Py_BEGIN_ALLOW_THREADS { \
PyThreadState *_save; \
_save = PyEval_SaveThread();
// 恢复线程状态,回到解释器的 GIL 调用中
#define Py_END_ALLOW_THREADS PyEval_RestoreThread(_save); \
}
从宏定义中我们可以看出,这两个宏是需要成对出现的,当然你也可以使用更细的 API 自己控制。总之:当释放 GIL 的时候,一定不要和 Python 进行交互,或者说不能有任何 Python / C API 的调用。
#include "Python.h"
#include <pthread.h>
// 子线程调用的函数, 要求接受一个 void *、返回一个 void*
void* test(void *lst) {
// 对于扩展而言,我们是通过 Python 调用里面的函数,所以调用它的是 Python 中的线程
// 但这是我们使用 pthread 创建的子线程进行调用,不是 Python 中的,因此它不能和 Python 有任何的交互
// 而我们是需要和 Python 交互的,这里面的参数 lst 就是由 PyObject * 转化得到的,因此我们需要封装成 Python 中的线程
PyGILState_STATE gstate;
gstate = PyGILState_Ensure();
// 这里面和 Python 进行交互
PyObject *lst1 = (PyObject *) lst;
// 我们往里面添加设置几个元素
PyObject *item = PyLong_FromLong(123);
PyList_Append(lst1, item);
// 注意:以上引用计数变成了 2,我们需要再减去 1
Py_XDECREF(item);
item = PyUnicode_FromString("hello matsuri");
PyList_Append(lst1, item);
Py_XDECREF(item);
// 假设我们以上 Python 的逻辑就调用完了,那么我们是不是要将 GIL 给释放掉呢?否则其它线程永远没有机会得到调度
// 干脆我们就不释放了,看看效果吧
return NULL;
}
static PyObject* test_gil(PyObject *self, PyObject *args){
// 假设我们接受一个 list
PyObject *lst = NULL;
if (!PyArg_ParseTuple(args, "O!", &PyList_Type, &lst)){
return NULL;
}
// 创建线程 id
pthread_t tid;
// 创建一个线程
int res = pthread_create(&tid, NULL, test, (void *)lst);
if (res != 0) {
printf("pthread_create error: error_code = %d\n", res);
}
return Py_None;
}
static PyMethodDef methods[] = {
{"test_gil", (PyCFunction) test_gil, METH_VARARGS, "this is a function named test_gil"},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named hanser",
-1,
methods,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void) {
PyObject *m = PyModule_Create(&module);
return m;
}
我们来测试一下:
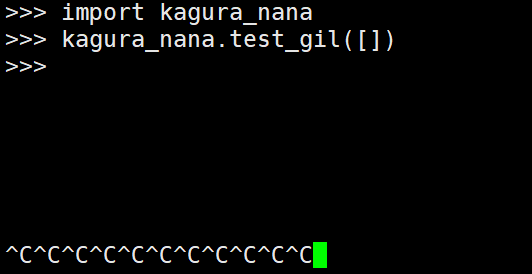
我们看了程序就无法执行了,因为 Python 只能利用单核,我们在 C 中开启了子线程,然后创建对应的 Python 线程。此时就有两个 Python 线程,只不过一个是主线程,另一个是在 C 中创建的子线程,然后这个子线程通过 Python / C API 获取了 GIL,但是用完了不释放,这就导致了主线程永远得不到机会执行。当然也无法接收 Ctrl + C 命令,因此我们需要新启一个终端 kill 掉它。
#include "Python.h"
#include <pthread.h>
void* test(void *lst) {
PyGILState_STATE gstate;
gstate = PyGILState_Ensure();
PyObject *lst1 = (PyObject *) lst;
PyObject *item = PyLong_FromLong(123);
PyList_Append(lst1, item);
Py_XDECREF(item);
item = PyUnicode_FromString("hello matsuri");
PyList_Append(lst1, item);
Py_XDECREF(item);
// 这里将 GIL 释放掉
PyGILState_Release(gstate);
// 然后下面就不可以再有任何 Python / C API 的出现了
return NULL;
}
static PyObject* test_gil(PyObject *self, PyObject *args){
PyObject *lst = NULL;
if (!PyArg_ParseTuple(args, "O!", &PyList_Type, &lst)){
return NULL;
}
pthread_t tid;
int res = pthread_create(&tid, NULL, test, (void *)lst);
if (res != 0) {
printf("pthread_create error: error_code = %d\n", res);
}
return Py_None;
}
static PyMethodDef methods[] = {
{"test_gil", (PyCFunction) test_gil, METH_VARARGS, "this is a function named test_gil"},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named hanser",
-1,
methods,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void) {
PyObject *m = PyModule_Create(&module);
return m;
}
然后我们再来测试一下:
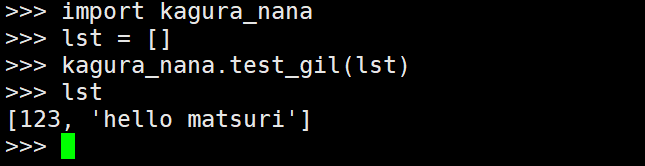
我们看到此时就没有任何问题了,当 C 中的线程将 GIL 给释放掉之后,此时它和 Python 线程就没有关系了,它就是 C 的线程。那么下面可以写纯 C / C++ 代码,此时可以实现并行执行。但是能不用多线程就不用多线程,因为多线程出现 bug 之后难以调试。
另外我们目前是在 C 中创建的 Python 线程,但是很明显这需要你对 C 的多线程理解有一定要求。那么我也可以不在 C 中创建,而是在 Python 中创建子线程去调用。
#include "Python.h"
static PyObject* test_gil(PyObject *self, PyObject *args){
PyObject *lst = NULL;
if (!PyArg_ParseTuple(args, "O!", &PyList_Type, &lst)){
return NULL;
}
// 此时该函数要被 Python 的子线程进行调用,但是很明显默认还是受到 GIL 的限制的
Py_BEGIN_ALLOW_THREADS // 释放掉 GIL,此时调用该函数的 Python 线程将不再受到解释器的制约,从而实现并行执行
// 但是很明显,这里面不可以有任何的 Python / C API 调用
long a;
while (1) a ++; // 不停的对 a 进行自增,显然程序会一直卡在这里
Py_END_ALLOW_THREADS // 获取 GIL,此时会回到解释器的线程调度中
// 下面就可以包含 Python 逻辑了,如果再遇到纯 C / C++ 逻辑,那么就再通过这两个宏继续实现并行
// 当然为了演示,我们上面是个死循环
return Py_None;
}
static PyMethodDef methods[] = {
{"test_gil", (PyCFunction) test_gil, METH_VARARGS, "this is a function named test_gil"},
{NULL, NULL, 0, NULL}
};
static PyModuleDef module = {
PyModuleDef_HEAD_INIT,
"kagura_nana",
"this is a module named hanser",
-1,
methods,
NULL,
NULL,
NULL,
NULL
};
PyMODINIT_FUNC
PyInit_kagura_nana(void) {
PyObject *m = PyModule_Create(&module);
return m;
}
然后我们在 Python 中创建子线程去调用:
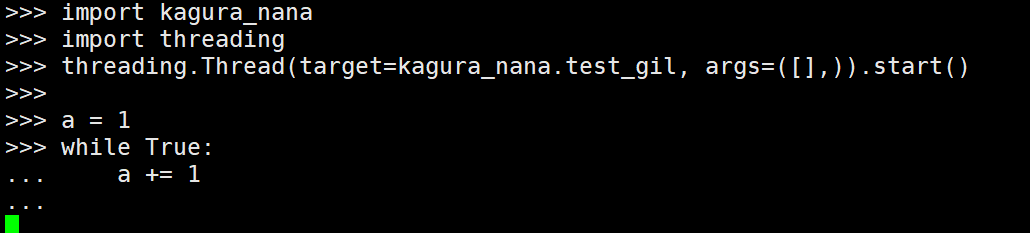
我们开启了一个子线程,去调用扩展模块中的函数,然后主线程也写了一个死循环。下面看一下 CPU 的使用率:
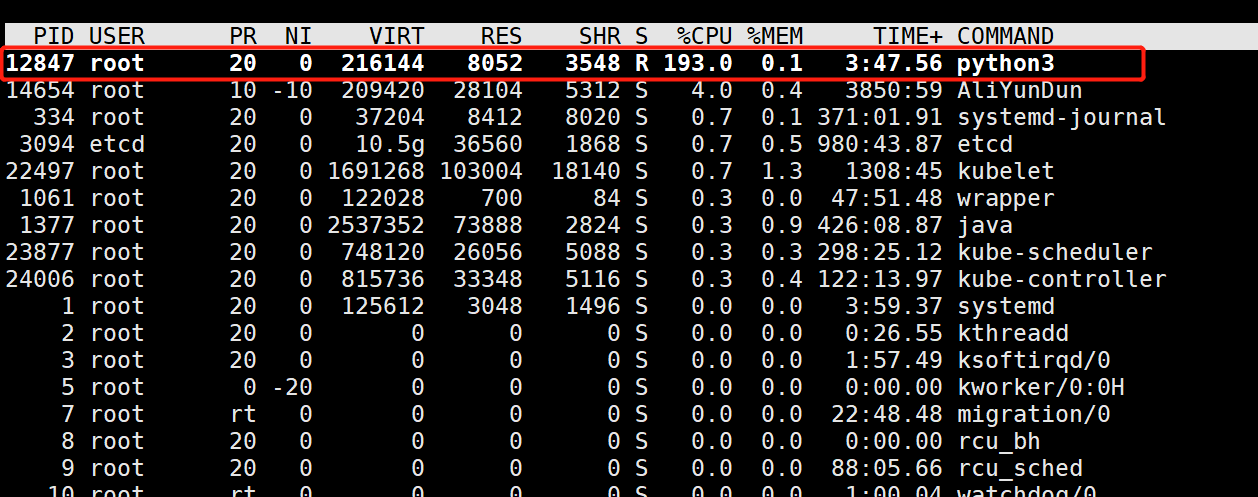
我们看到成功利用了多核,此时我们就通过编写扩展的方式来绕过了解释器中 GIL 的限制。
所以对于一些 C / C++ 逻辑,它们不需要和 Python 进行所谓的交互,那么我们就可以把 GIL 释放掉。因为 GIL 本来就是为了保护 Python 中的对象的,为了内存管理,CPython 的开发人员为了直接在解释器上面加上了一把超级大锁,但是当我们不需要和 Python 对象进行交互的时候,就可以把 GIL 给释放掉。
GIL 是字节码级别互斥锁,当线程执行字节码的时候,如果自身已经获取到 GIL ,那么会判断是否有释放的 GIL 的请求(gil_drop_request):有则释放、将 CPU 使用权交给其它线程,没有则直接执行字节码;如果自身没有获取到 GIL,那么会先判断 GIL 是否被别的线程获取,若被别的线程获取就一直申请、没有则拿到 GIL 执行字节码。
总结
这一次我们聊了聊 Python 和 C/C++ 联合编程,我们可以在 Python 中引入 C/C++,也可以在 C/C++ 中引入 Python,甚至还可以定制 Python 解释器。只不过笔者是主 Python 的,因此在 C/C++ 中引入 Python 就不说了。
Python 引入 C/C++ 主要是通过编写扩展的方式,这真的是一件痛苦的事情,需要你对 Python / C API 有很深的了解,最后仍然安利一波 Cython。
这应该是我有史以来写过的最长的文章了。

如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号