《深度剖析CPython解释器》27. Python内存管理与垃圾回收(第一部分):深度剖析Python内存管理架构、内存池的实现原理
楔子
内存管理,对于Python这样的动态语言来说是非常重要的一部分,它在很大程度上决定了Python的执行效率,因为Python在运行中会创建和销毁大量的对象,这些都涉及内存的管理,因此精湛的内存管理技术是确保内存使用效率的关键。
此外,我们知道Python还是一门提供了垃圾回收机制(GC, garbage collection)的语言,可以将开发者从繁琐的手动维护内存的工作中解放出来。
那么下面我们就来分析一下Python中的内存管理和垃圾回收。
内存管理架构
首先Python的内存管理机制是分层次的,我们可以看成是有6层:-2、-1、0、1、2、3。
- 最底层,也就是-2和-1层是由操作系统提供的内存管理接口,因为计算机硬件资源由操作系统负责管理,内存资源也不例外,应用程序通过系统调用向操作系统申请内存。注意:这一层Python是无权干预的。
- 第0层,C的库函数会将系统调用封装成通用的内存分配器,也就是我们所熟悉的malloc系列函数。注意:这一层Python同样无法干预。
- 第1、2、3层,由于Python解释器实现并负责维护。
所以我们看到Python的内存管理实际上封装了C的malloc,C的malloc则是封装了系统调用。
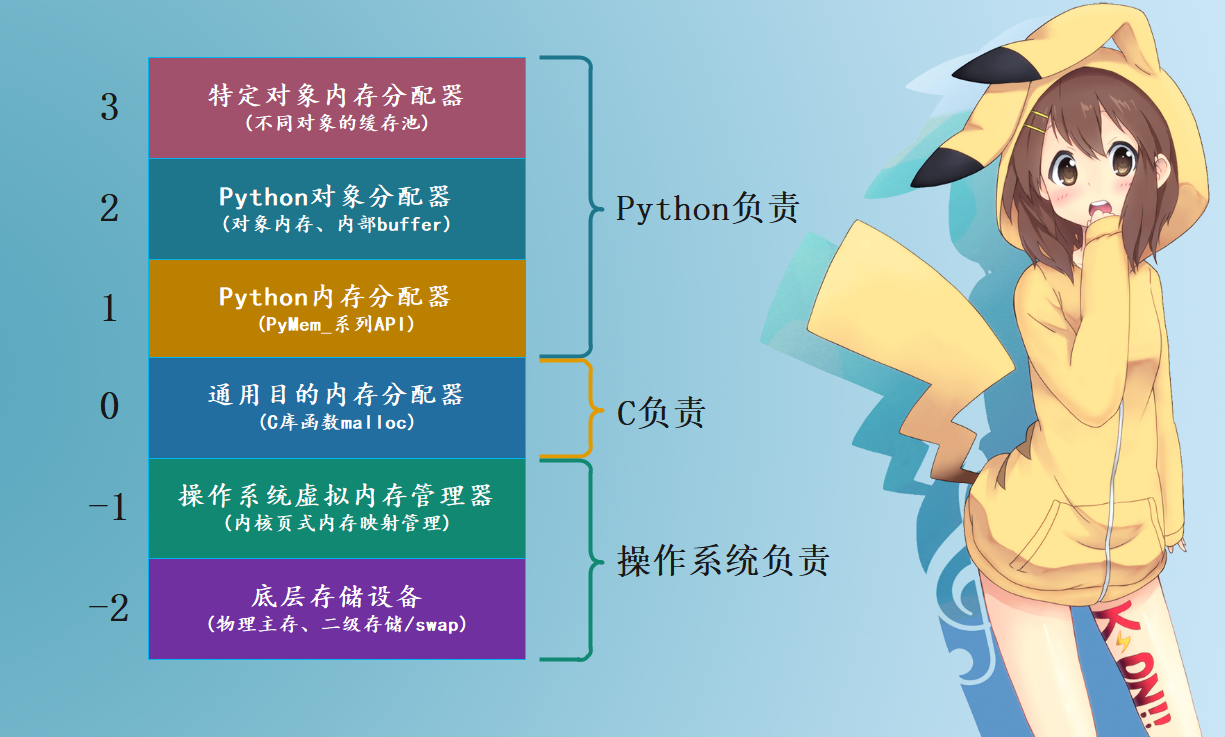
我们自下而上来简单说一下,首先操作系统内部是一个基于页表的虚拟内存管理器(第-1层),以"页(page)"为单位管理内存,而CPU内存管理单元(MMU)在这个过程中发挥重要作用。虚拟内存管理器下方则是底层存储设备(第-2层),直接管理物理内存以及磁盘等二级存储设备。
所以最后的两层是操作系统的领域,过于底层,不在我们的涉及范围内,简单了解就好。有兴趣的话,可以网上查阅相关资料,看看操作系统是如何管理内存的。
C库函数实现的"通用目的内存分配器"是一个重要的分水岭,即内存管理层次中的第0层。此层之上是应用程序自己的内存管理,之下则是隐藏在冰山中的操作系统的内存管理。
第1、2、3层则是Python自己的内存管理,总共分为3层,作用如下:
第1层:基于第0层的"通用目的内存分配器"包装而成。
这一层并没有在第0层上加入太多的动作,其目的仅仅是为Python提供一层统一的raw memory的管理接口。这么做的原因就是虽然不同的操作系统都提供了ANSI C标准 所定义的内存管理接口,但是对于某些特殊情况不同操作系统有不同的行为。比如调用malloc(0),有的操作系统会返回NULL,表示申请失败,但是有的操作系统则会返回一个貌似正常的指针, 但是这个指针指向的内存并不是有效的。为了最广泛的可移植性,Python必须保证相同的语义一定代表着相同的运行时行为,为了处理这些与平台相关的内存分配行为,Python必须要在C的内存分配接口之上再提供一层包装。
在Python中,第一层的实现就是一组以PyMem_为前缀的函数簇,下面来看一下。
//Include/pymem.h
PyAPI_FUNC(void *) PyMem_Malloc(size_t size);
PyAPI_FUNC(void *) PyMem_Realloc(void *ptr, size_t new_size);
PyAPI_FUNC(void) PyMem_Free(void *ptr);
//Objects/obmalloc.c
void *
PyMem_Malloc(size_t size)
{
/* see PyMem_RawMalloc() */
if (size > (size_t)PY_SSIZE_T_MAX)
return NULL;
return _PyMem.malloc(_PyMem.ctx, size);
}
void *
PyMem_Realloc(void *ptr, size_t new_size)
{
/* see PyMem_RawMalloc() */
if (new_size > (size_t)PY_SSIZE_T_MAX)
return NULL;
return _PyMem.realloc(_PyMem.ctx, ptr, new_size);
}
void
PyMem_Free(void *ptr)
{
_PyMem.free(_PyMem.ctx, ptr);
}
我们看到在第一层,Python提供了类似于类似于C中malloc、realloc、free的语义。并且我们发现,比如 PyMem_Malloc ,如果申请的内存大小超过了 PY_SSIZE_T_MAX 直接返回NULL,并且还调用了 _PyMem.malloc ,这和C中的malloc几乎没啥区别,但是会对特殊值进行一些处理。到目前为止,仅仅是分配了raw memory而已。当然在第一层,Python还提供了面向对象中类型的内存分配器。
//Include/pymem.h
#define PyMem_New(type, n) \
( ((size_t)(n) > PY_SSIZE_T_MAX / sizeof(type)) ? NULL : \
( (type *) PyMem_Malloc((n) * sizeof(type)) ) )
#define PyMem_NEW(type, n) \
( ((size_t)(n) > PY_SSIZE_T_MAX / sizeof(type)) ? NULL : \
( (type *) PyMem_MALLOC((n) * sizeof(type)) ) )
#define PyMem_Resize(p, type, n) \
( (p) = ((size_t)(n) > PY_SSIZE_T_MAX / sizeof(type)) ? NULL : \
(type *) PyMem_Realloc((p), (n) * sizeof(type)) )
#define PyMem_RESIZE(p, type, n) \
( (p) = ((size_t)(n) > PY_SSIZE_T_MAX / sizeof(type)) ? NULL : \
(type *) PyMem_REALLOC((p), (n) * sizeof(type)) )
#define PyMem_Del PyMem_Free
#define PyMem_DEL PyMem_FREE
很明显,在 PyMem_Malloc 中需要程序员自行提供所申请的空间大小。然而在 PyMem_New 中,只需要提供类型和数量,Python会自动侦测其所需的内存空间大小。
第2层:在第1层提供的通用 PyMem_ 接口基础上,实现统一的对象内存分配(object.tp_alloc)
第1层所提供的内存管理接口的功能是非常有限的,如果创建一个PyLongObject对象,还需要做很多额外的工作,比如设置对象的类型参数、初始化对象的引用计数值等等。因此为了简化Python自身的开发,Python在比第1层更高的抽象层次上提供了第2层内存管理接口。在这一层,是一组以PyObject_为前缀的函数簇,主要提供了创建Python对象的接口。这一套函数簇又被称为Pymalloc机制,因此在第2层的内存管理机制上,Python对于一些内建对象构建了更高抽象层次的内存管理策略。
第3层:为特定对象服务
这一层主要是用于对象的缓存机制,比如:小整数对象池,浮点数缓存池等等。
所以Python中GC是隐藏在哪一层呢?不用想,肯定是第二层,也是在Python的内存管理中发挥巨大作用的一层,我们后面也会基于第二层进行剖析。
小块空间的内存池
为什么要引入内存池
在Python中,很多时候申请的内存都是小块的内存,这些小块的内存在申请后很快又被释放,并且这些内存的申请并不是为了创建对象,所以并没有对象一级的内存池机制。这就意味着Python在运行期间需要大量地执行底层的malloc和free操作,导致操作系统在用户态和内核态之间进行切换,这将严重影响Python的效率。所以为了提高执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放,这就是之前说的Pymalloc机制,并且提供了pymalloc_alloc,pymalloc_realloc,pymalloc_free三个接口。
而整个小块内存的内存池可以视为一个层次结构,从下至上分别是:block、pool、arena。当然内存池只是一个概念上的东西,表示Python对整个小块内存分配和释放行为的内存管理机制。
block
在最底层,block是一个确定大小的内存块。而Python中,有很多种block,不同种类的block都有不同的内存大小,这个内存大小的值被称之为size class。为了在当前主流的32位平台和64位平台都能获得最佳性能,所有的block的长度都是8字节对齐的。
//Objects/obmalloc.c
#define ALIGNMENT 8 /* must be 2^N */
#define ALIGNMENT_SHIFT 3
但是问题来了,Python为什么要有这么多种类的block呢?为了更好理解这一点,我们需要了解"内存碎片化"这个概念。
"内存碎片化"是困扰经典内存分配器的一大难题,碎片化导致的结果也是惨重的。看一个典型的内存碎片化例子:
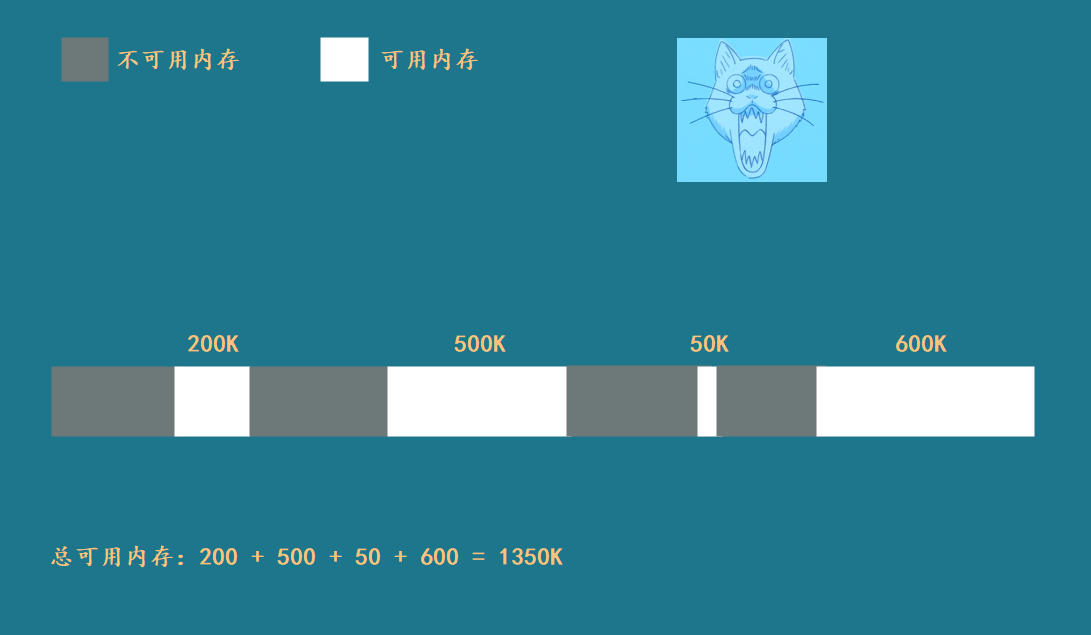
虽然还有1350K的可用内存,但由于分散在一系列不连续的碎片上,因此连675K、总可用内存的一半都分配不出来。
那么如何避免内存碎片化呢?想要解决问题,就必须先分析导致问题的根源。
我们知道,应用程序请求内存尺寸是不确定的,有大有小;释放内存的时机也是不确定的,有先有后。经典内存分配器将不同尺寸的内存混合管理,按照先来后到的顺序分配:

由此可见,将不同尺寸内存块混合管理,将大块内存切分后再次分配的做法是罪魁祸首。
找到了问题的原因,那么解决方案也就自然而然浮出水面了,那就是将内存空间划分成不同区域,独立管理,比如:
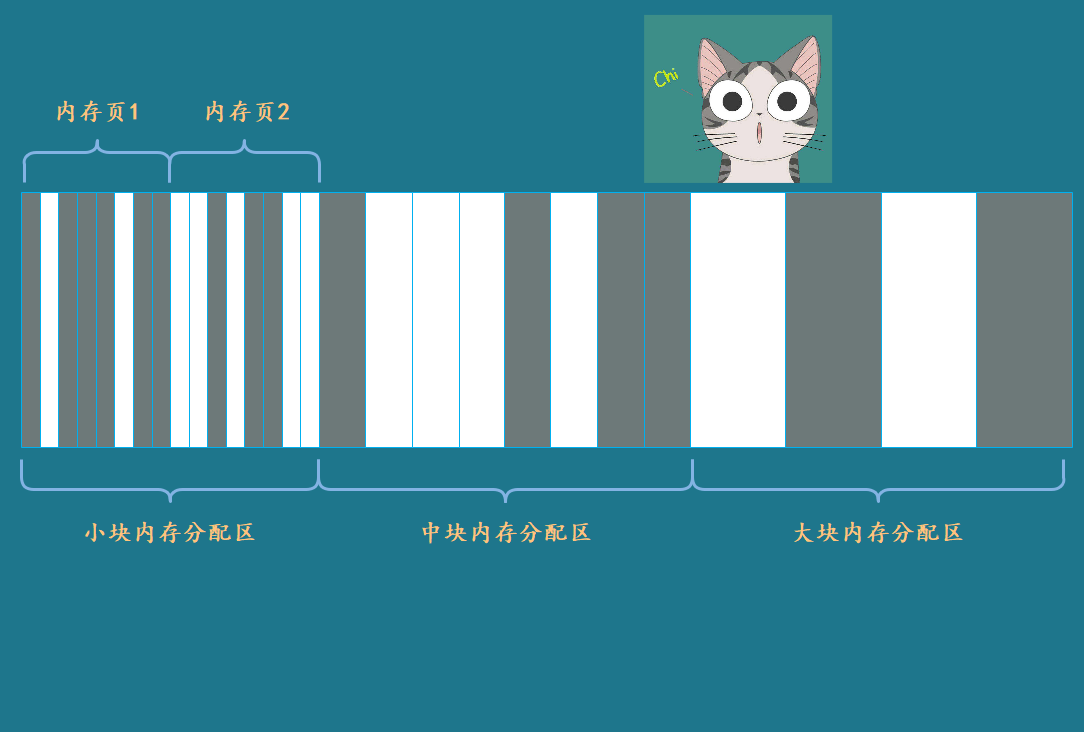
如图,内存被划分成小、中、大三个不同尺寸的区域,区域可由若干内存页组成,每个页都划分为统一规格的内存块。这样一来,小块内存的分配,不会影响大块内存区域,使其碎片化。
不过每个区域的碎片仍无法完全避免,但这些碎片都是可以被重新分配出去的,影响不大。此外,通过优化分配策略,碎片还可被进一步合并。以小块内存为例,新内存优先从内存页1分配,内存页2将慢慢变空,最终将被整体回收。
在 Python 虚拟机内部,每时每刻都有对象创建、销毁,这引发频繁的内存申请、释放动作。这类内存尺寸一般不大,但分配、释放频率非常高,因此 Python 专门设计内存池对此进行优化。
那么,尺寸多大的内存才会动用内存池呢?Python 以 512 字节为上限,小于等于 512 的内存分配才会被内存池接管。所以当申请的内存大小不超过这个上限时, Python 可以使用不同种类的block满足对内存的需求;当申请的内存大小超过了上限, Python 就会将对内存的请求转交给第一层的内存管理机制,即PyMem函数簇来处理。所以这个上限值在 Python 中被设置为 512 ,如果超过了这个值还是要经过操作系统临时申请的。
//Objects/obmalloc.c
#define SMALL_REQUEST_THRESHOLD 512
#define NB_SMALL_SIZE_CLASSES (SMALL_REQUEST_THRESHOLD / ALIGNMENT)
0: 直接调用 malloc 函数1 ~ 512: 由专门的内存池负责分配,内存池以内存尺寸进行划分512以上: 直接调动 malloc 函数
那么,Python 是否为每个尺寸的内存都准备一个独立内存池呢?答案是否定的,原因有几个:
内存规格有 512 种之多,如果内存池分也分 512 种,徒增复杂性内存池种类越多,额外开销越大如果某个尺寸内存只申请一次,将浪费内存页内其他空闲内存
相反,Python 以 8 字节为梯度,将内存块分为:8 字节、16 字节、24 字节,以此类推。总共 64 种block:
* Request in bytes Size of allocated block Size class idx
* ----------------------------------------------------------------
* 1-8 8 0
* 9-16 16 1
* 17-24 24 2
* 25-32 32 3
* 33-40 40 4
* 41-48 48 5
* 49-56 56 6
* 57-64 64 7
* 65-72 72 8
* ... ... ...
* 497-504 504 62
* 505-512 512 63
当然Python也提供了一个宏,来描述"Size of allocated block"和"Size class idx"之间的关系:
#define INDEX2SIZE(I) (((uint)(I) + 1) << ALIGNMENT_SHIFT)
//索引为0的话, 就是1 << 3, 显然结果为8
//索引为1的话, 就是2 << 3, 显然结果为16
//以此类推
因此当我们申请一个 44 字节的内存时, PyObject_Malloc 会从内存池中划分一个 48 字节的block给我们。
但是这样也暴露了一个问题,首先内存池是由多个内存页组成,每个内存页划分为多个内存块(block),这些后面会说。假设我们申请 7 字节的内存,那么毫无疑问会给我们一个 8 字节的块;但是当我们申请 1 字节的时候,分配给我们的还是 8 字节的块,因为最小的块就是 8 字节。
这种做法好处显而易见,前面提到的问题均得到解决。此外这种方式是字对齐的,内存以字对齐的方式可以提高读写速度。字大小从早期硬件的 2 字节、4 字节,慢慢发展到现在的 8 字节,甚至 16 字节。
当然了,有得必有失,内存利用率成了被牺牲的因素,以8字节内存块为例,平均利用率为 (1+8)/2/8*100% ,大约只有 56.25% 。当然对于现在的机器而言,完全是可以容忍的。
另外在 Python 中,block其实也只是一个概念,在 Python 源码中没有与之对应的实体存在。之前我们说对象,对象在源码中有对应的 PyObject ,列表在源码中则有对应的 PyListObject ,但是这里的block仅仅是概念上的东西,我们知道它是具有一定大小的内存,但是它并不与 Python 源码里面的某个东西对应。但是, Python 提供了一个管理block的东西,也就是我们下面要分析的pool。
pool
一组block的集合称为一个pool,换句话说,一个pool管理着一堆具有固定大小的内存块(block)。事实上,pool管理着一大块内存,它有一定的策略,将这块大的内存划分为多个小的内存块。在Python中,一个pool的大小通常是为一个系统内存页,也就是4kb。
//Objects/obmalloc.c
#define SYSTEM_PAGE_SIZE (4 * 1024)
#define SYSTEM_PAGE_SIZE_MASK (SYSTEM_PAGE_SIZE - 1)
#define POOL_SIZE SYSTEM_PAGE_SIZE /* must be 2^N */
#define POOL_SIZE_MASK SYSTEM_PAGE_SIZE_MASK
虽然Python没有为block提供对应的结构,但是提供了和pool相关的结构,我们说Python是将内存页看成由一个个内存块(block)组成的池子(pool),我们来看看pool的结构:
//Objects/obmalloc.c
/* Pool for small blocks. */
struct pool_header {
union { block *_padding;
uint count; } ref; /* 当前pool里面已分配出去的block数量 */
block *freeblock; /* 指向空闲block链表的第一块 */
/* 底层会有多个pool, 多个pool之间也会形成一个链表 */
struct pool_header *nextpool; /* 所以nextpool指向下一个pool */
struct pool_header *prevpool; /* prevpool指向上一个pool */
uint arenaindex; /* 在area里面的索引(area后面会说) */
uint szidx; /* 尺寸类别编号, 如果是2, 那么管理的block的大小就是24 */
uint nextoffset; /* 下一个可用block的内存偏移量 */
uint maxnextoffset; /* 最后一个block距离开始位置的偏移量 */
};
typedef struct pool_header *poolp;
我们刚才说了一个pool的大小在Python中是4KB,但是从当前的这个pool的结构体来看,用鼻子想也知道吃不完4KB(4048字节)的内存,事实上这个结构体只占48字节。所以呀,这个结构体叫做pool_header,它仅仅一个pool的头部,除去这个pool_header,剩下的内存才是维护的所有block的集合所占的内存。
我们注意到,pool_header里面有一个szidx,这就意味着pool里面管理的内存块大小都是一样的。也就是说,一个pool管理的block可以是32字节、也可以是64字节,但是不会出现既有32字节的block、又有64字节的block。每一个pool都和一个size联系在一起,更确切的说都和一个size class index联系在一起,表示pool里面存储的block都是多少字节的。这就是里面的域szidx存在的意义。
我们以16字节(szidx=1)的block为例,看看Python是如何将一块4KB的内存改造成管理16字节block的pool:
//Objects/obmalloc.c
#define POOL_OVERHEAD _Py_SIZE_ROUND_UP(sizeof(struct pool_header), ALIGNMENT)
static void*
pymalloc_alloc(void *ctx, size_t nbytes)
{
block *bp;
poolp pool;
poolp next;
uint size;
//......
//......
init_pool: //pool指向了一块4KB的内存
next = usedpools[size + size]; /* == prev */
pool->nextpool = next;
pool->prevpool = next;
next->nextpool = pool;
next->prevpool = pool;
pool->ref.count = 1;
//......
//设置pool的size class index
pool->szidx = size;
//一个宏, 将szidx转成内存块的大小, 比如: 0->8, 1->16, 63->512
size = INDEX2SIZE(size);
//跳过用于pool_header的内存,并进行对齐
bp = (block *)pool + POOL_OVERHEAD;
//等价于pool->nextoffset = POOL_OVERHEAD+size+size
pool->nextoffset = POOL_OVERHEAD + (size << 1);
pool->maxnextoffset = POOL_SIZE - size;
pool->freeblock = bp + size;
*(block **)(pool->freeblock) = NULL;
goto success;
}
//.....
success:
assert(bp != NULL);
return (void *)bp;
failed:
return NULL;
}
注意最后的(void *)bp;,它指的就是pool的freeblock域。我们说它指向的是pool中的第一块空闲block、或者说可用block,但是新内存页总是由内存请求触发,所以第一个block一定会被分配出去,因此这里的bp最后指向的只能是第二个、或者第二个之后的内存块。而且从ref.count中我们也可以看出端倪,我们说ref.count记录了当前已经被分配的block的数量,但初始化的时候不是0,而是1。最终改造成pool之后的4kb内存如图所示:

实线箭头是指针,但是虚线箭头则是偏移位置的形象表示。在nextoffset,maxnextoffset中存储的是相对于pool头部的偏移位置。
在了解初始化之后的pool的样子之后,可以来看看Python在申请block时,pool_header中的各个域是怎么变动的。假设我们再申请1块16字节的内存块:
//Objects/obmalloc.c
static void*
pymalloc_alloc(void *ctx, size_t nbytes)
{
//......
if (pool != pool->nextpool) {
//首先pool中已分配的block数自增1
++pool->ref.count;
//这里的freeblock指向的是下一个可用的block的起始地址
bp = pool->freeblock;
assert(bp != NULL);
if ((pool->freeblock = *(block **)bp) != NULL) {
goto success;
}
//因此当再次申请16字节block时,只需要返回freeblock指向的地址就可以了。
//那么很显然,freeblock需要前进,指向下一个可用的block,这个时候nextoffset就现身了
if (pool->nextoffset <= pool->maxnextoffset) {
//当nextoffset小于等于maxoffset时候
//freeblock等于当前block的地址 + nextoffset(下一个可用block的内存偏移量)
//所以freeblock正好指向了下一个可用block的地址
pool->freeblock = (block*)pool +
pool->nextoffset;
//同理,nextoffset也要向前移动一个block的距离
pool->nextoffset += INDEX2SIZE(size);
//依次反复,即可对所有的block进行遍历。而maxnextoffset指明了该pool中最后一个可用的block距离pool开始位置的偏移
//当pool->nextoffset > pool->maxnextoffset就意味着遍历完pool中的所有block了
//再次获取显然就是NULL了
*(block **)(pool->freeblock) = NULL;
goto success;
}
/* Pool is full, unlink from used pools. */
next = pool->nextpool;
pool = pool->prevpool;
next->prevpool = pool;
pool->nextpool = next;
goto success;
}
//......
}
所以当我们再申请1块16字节的内存块时,pool的结构图就变成了这样:
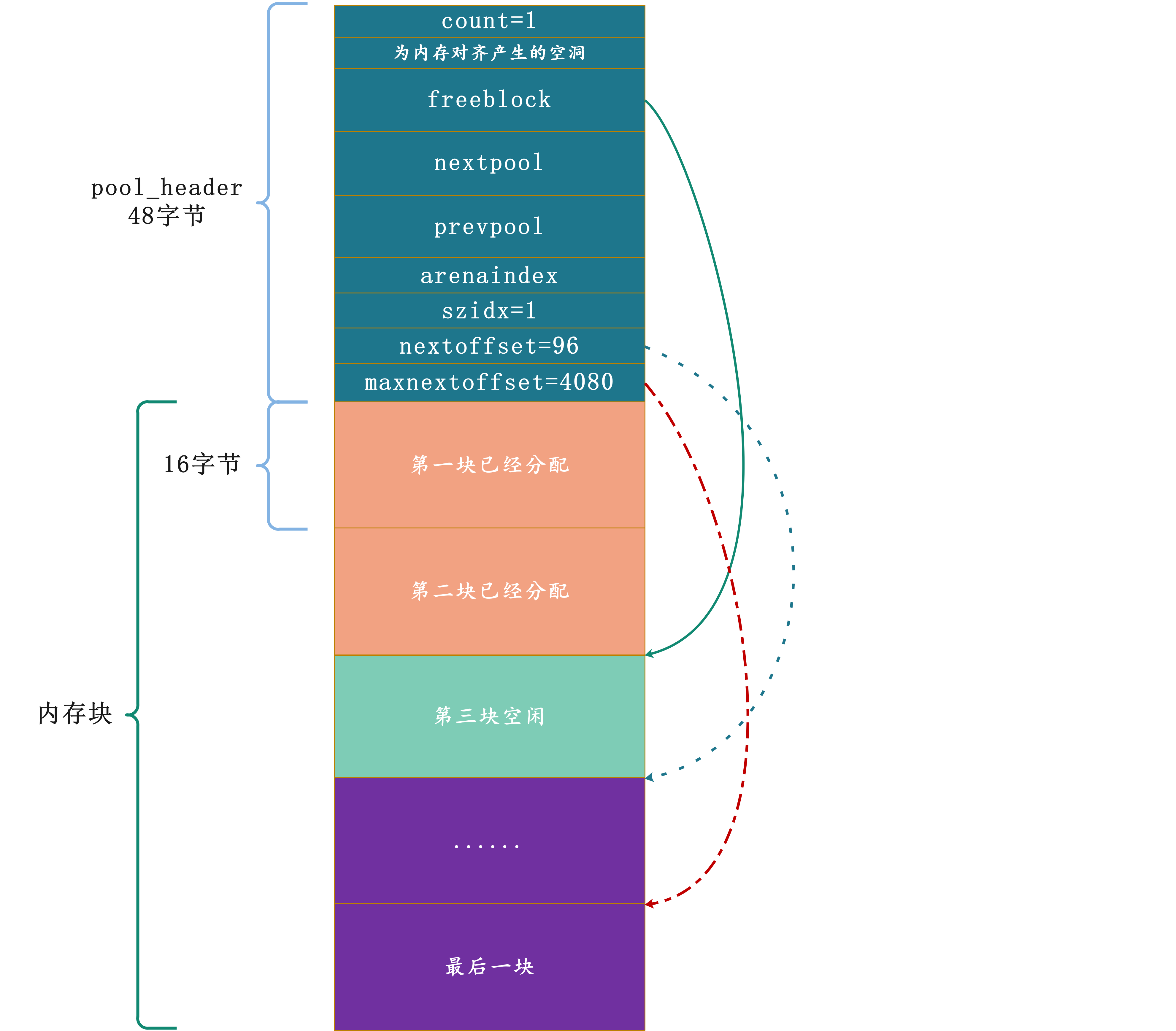
首先freeblock指向了第三块block,仍然是第一块可用block;注意:nextoffset,它表示下一块可用block的偏移量,显然下一块的可用block是第三块,因此48 + 16 * 3 = 96,前进了16字节的偏移量;至于maxnextoffset仍然是4080,它是不变的。
随着内存分配的请求不断发起,空闲的block(内存块)也将不断地分配出去,freeblock不断前进、指向下一个可用内存块,nextoffset也在不断前进、偏移量每次增加内存块的大小,直到所有的空闲内存块被消耗完。
所以,申请、前进、申请、前进,一直重复着相同的动作,整个过程非常自然,也很容易理解。但是我们知道一个pool里面的block都是相同大小的,这就使得一个pool只能满足POOL_SIZE / size次对block的申请,但是这样存在一个问题,举个栗子:
我们知道内存块不可能一直被使用,肯定有释放的那一天。假设我们分配了两个内存块,理论上下一次应该申请第三个内存块,但是某一时刻第一个内存块被释放了,那么下一次申请的时候,Python是申请第一个内存块、还是第三个内存块呢?
显然为了pool的使用效率,最好分配第一个block。因此可以想象,一旦Python运转起来,内存的释放动作将导致pool中出现大量的离散的自由block,Python为了知道哪些block是被使用之后再次被释放的,必须建立一种机制,将这些离散自由的block组合起来,再次使用。这个机制就是所有的自由block链表(freeblock list),这个链表的关键就在pool_header中的那个freeblock身上。
再来回顾一下pool_header的定义:
//Objects/obmalloc.c
/* Pool for small blocks. */
struct pool_header {
union { block *_padding;
uint count; } ref;
block *freeblock; /* 指向空闲block链表的第一块 */
struct pool_header *nextpool;
struct pool_header *prevpool;
uint arenaindex;
uint szidx;
uint nextoffset;
uint maxnextoffset;
};
typedef struct pool_header *poolp;
当pool初始化完后之后,freeblock指向了一个有效的地址,也就是下一个可以分配出去的block的地址。然而奇特的是,当Python设置了freeblock时,还设置了 *freeblock。这个动作看似诡异,然而我们马上就能看到设置 *freeblock的动作正是建立离散自由block链表的关键所在。目前我们看到的freeblock只是在机械地前进前进,因为它在等待一个特殊的时刻,在这个特殊的时刻,你会发现freeblock开始成为一个苏醒的精灵,在这4kb的内存上开始灵活地舞动,这个特殊的时刻就是一个block被释放的时刻。
//Objects/obmalloc.c
//基于地址P获得离P最近的pool的边界地址
#define POOL_ADDR(P) ((poolp)_Py_ALIGN_DOWN((P), POOL_SIZE))
static int
pymalloc_free(void *ctx, void *p)
{
poolp pool;
block *lastfree;
poolp next, prev;
uint size;
assert(p != NULL);
pool = POOL_ADDR(p);
//如果p不再pool里面,直接返回0
if (!address_in_range(p, pool)) {
return 0;
}
//释放,那么ref.count就势必大于0
assert(pool->ref.count > 0); /* else it was empty */
*(block **)p = lastfree = pool->freeblock;
pool->freeblock = (block *)p;
//......
}
在释放block时,神秘的freeblock惊鸿一瞥,显然覆盖在freeblock身上的那层面纱就要被揭开了。我们知道,这是freeblock虽然指向了一个有效的pool里面的地址,但是 *freeblock是为NULL的。假设这时候Python释放的是block 1,那么block 1中的第一个字节的值被设置成了当前freeblock的值,然后freeblock的值被更新了,指向了block 1的首地址。就是这两个步骤,一个block被插入到了离散自由的block链表中。
简单点,说人话就是:原来freeblock指向block 3,现在变成了block 1指向block 3,而freeblock则指向了block 1。
所以pool的结构图变化如下:
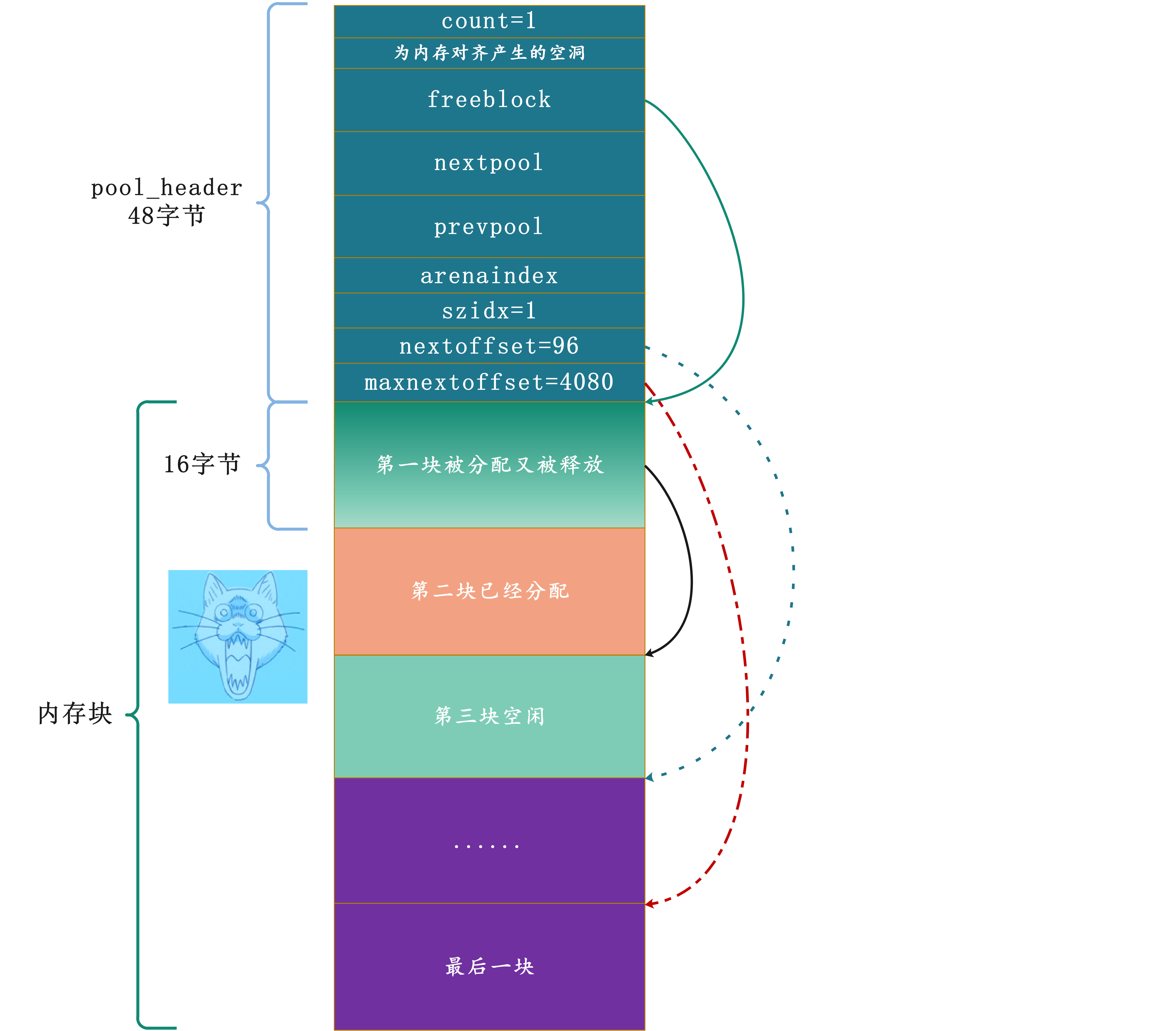
到了这里,这条实现方式非常奇特的block链表被我们挖掘出来了,从freeblock开始,我们可以很容易的以freeblock = *freeblock的方式遍历这条链表,而当发现了*freeblock为NULL时,则表明到达了该链表(可用自由链表)的尾部了,那么下次就需要申请新的block了。
//Objects/obmalloc.c
static void*
pymalloc_alloc(void *ctx, size_t nbytes)
{
if (pool != pool->nextpool) {
++pool->ref.count;
bp = pool->freeblock;
assert(bp != NULL);
//如果这里的条件不为真,表明离散自由链表中已经不存在可用的block了
//如果为真那么代表存在,则会继续分配pool的nextoffset指定的下一块block
if ((pool->freeblock = *(block **)bp) != NULL) {
goto success;
}
//离散自由block链表中不存在,则从pool里面申请新的block
if (pool->nextoffset <= pool->maxnextoffset) {
pool->freeblock = (block*)pool +
pool->nextoffset;
pool->nextoffset += INDEX2SIZE(size);
*(block **)(pool->freeblock) = NULL;
goto success;
}
//......
}
}
因此我们可以得出,一个pool在其声明周期内,可以处于以下三种状态:
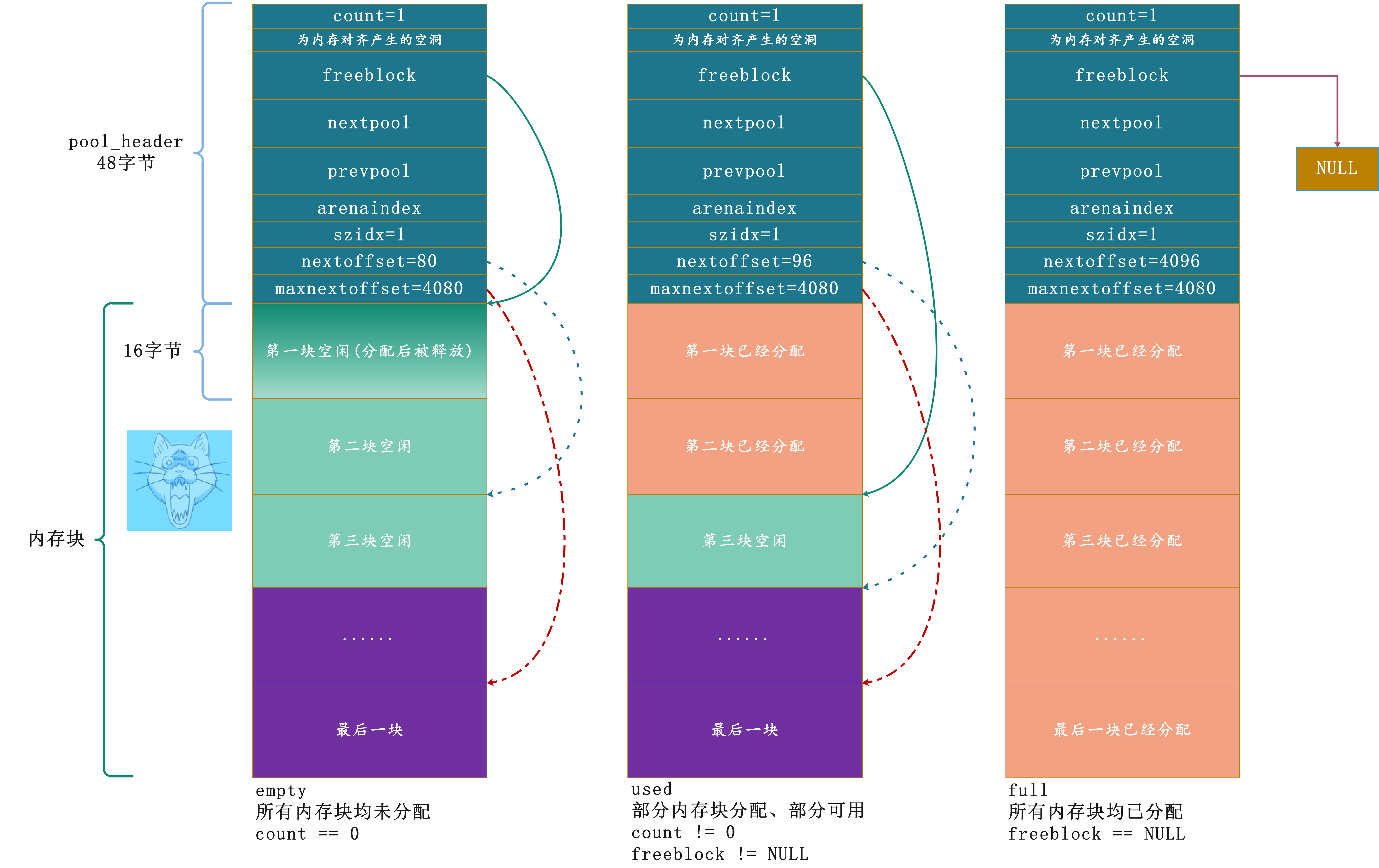
为什么要讨论pool的状态呢?我们在上面的代码中说自由链表中不存在可用的block时,会从pool中申请,但是显然是有条件的。我们看到必须满足:pool->nextoffset <= pool->maxnextoffset才行,但如果连这个条件都不成立了呢?而这个条件不成立显然意味着pool中已经没有可用的block了,因为pool是有大小限制的。所以这个时候想在申请一个block要怎么做?答案很简单,再来一个pool不就好了,然后从新的pool里面申请。
所以block组合起来可以成为一个pool,那么同理多个pool也是可以组合起来的。而多个pool组合起来会得到什么呢,我们说内存池是分层次的,从下至上分别是:block、pool、arena,显然多个pool组合起来,可以得到我们下面要介绍的arena。
arena
在Python中,多个pool聚合的结果就是一个arena。上一节提到,pool的大小默认是4kb,同样每个arena的大小也有一个默认值。#define ARENA_SIZE (256 << 10),显然这个值默认是256KB,也就是ARENA_SIZE / POOL_SIZE = 64个pool的大小。我们来看看arena的底层结构体定义,同样藏身于 Objects/obmalloc.c 中。
struct arena_object {
//arena的地址
uintptr_t address;
//池对齐指针,指向下一个被划分的pool
block* pool_address;
//该arena中可用pool的数量
uint nfreepools;
// 该arena中所有pool的数量
uint ntotalpools;
//我们在介绍pool的时候说过,pool之间也会形成一个链表,而这里freepools指的是第一个可用pool
struct pool_header* freepools;
//从名字上也能看出:nextarena指向下一个arena、prevarena指向上一个arena
//是不是说明arena之间也会组成链表呢?答案不是的,其实多个arena之间组成的是一个数组,至于为什么我们下面说
struct arena_object* nextarena;
struct arena_object* prevarena;
};
一个概念上的arena在Python源码中就对应一个arena_object结构体实例,确切的说,arena_object仅仅是arena的一部分。就像pool_header仅仅是pool的一部分一样,一个完整的pool包括一个pool_header和透过这个pool_header管理的block集合;一个完整的arena也包括一个arena_object和透过这个arena_object管理的pool集合。
"未使用的"的arena和"可用"的arena
在arena_object结构体的定义中,我们看到了nextarena和prevarena这两个东西,这似乎意味着在Python中会有一个或多个arena构成的链表。呃,这种猜测实际上只对了一半,实际上,在Python中确实会存在多个arena_object构成的集合,但是这个集合不够成链表,而是一个数组。数组的首地址由arenas来维护,这个数组就是Python中的通用小块内存的内存池。另一方面,nextarea和prevarena也确实是用来连接arena_object组成链表的,咦,不是已经构成或数组了吗?为啥又要来一个链表。
我们曾说arena是用来管理一组pool的集合的,arena_object的作用看上去和pool_header的作用是一样的。但是实际上,pool_header管理的内存(block所使用)和arena_object管理的内存(pool所使用)有一点细微的差别,pool_header管理的内存pool_header自身是一块连续的内存,但是arena_object与其管理的内存则是分离的:
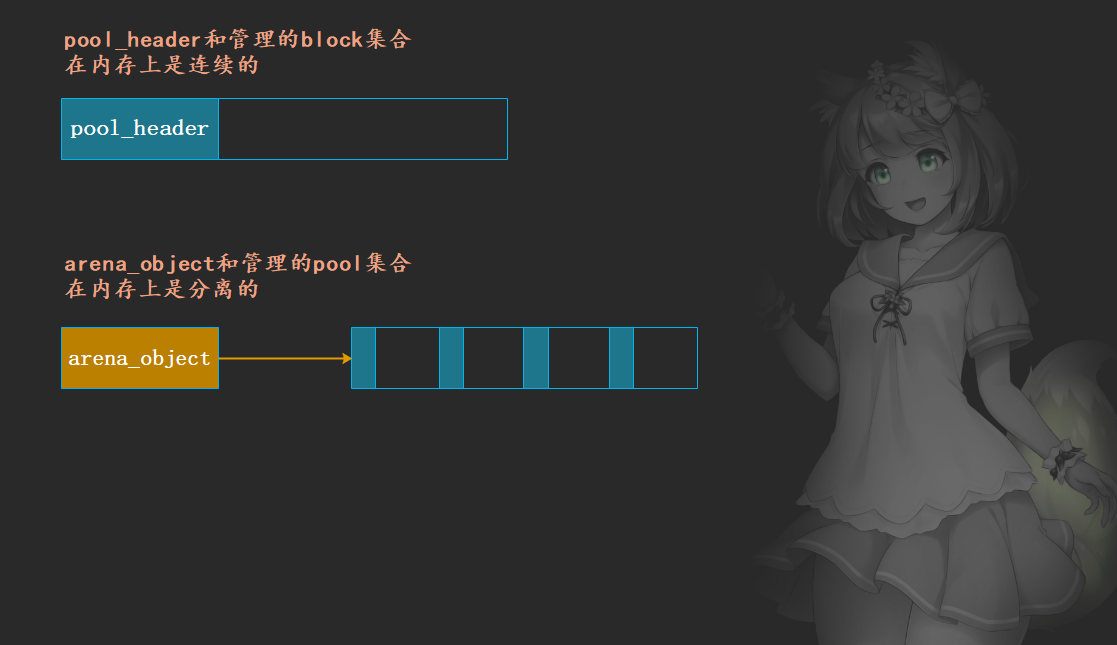
咋一看,貌似没啥区别,不过一个是连着的,一个是分开的。但是这后面隐藏了这样一个事实:当pool_header被申请时,它所管理的内存也一定被申请了;但是当arena_object被申请时,它所管理的pool集合的内存则没有被申请。换句话说,arena_object和pool集合在某一时刻需要建立联系。
当一个arena的arena_object没有与pool集合建立联系的时候,这时的arena就处于"未使用"状态;一旦建立了联系,这时arena就转换到了"可用"状态。对于每一种状态,都有一个arena链表。"未使用"的arena链表表头是unused_arena_objects,多个arena之间通过nextarena连接,并且是一个单向的链表;而"可用的"arena链表表头是usable_arenas,多个arena之间通过nextarena、prevarena连接,是一个双向链表。
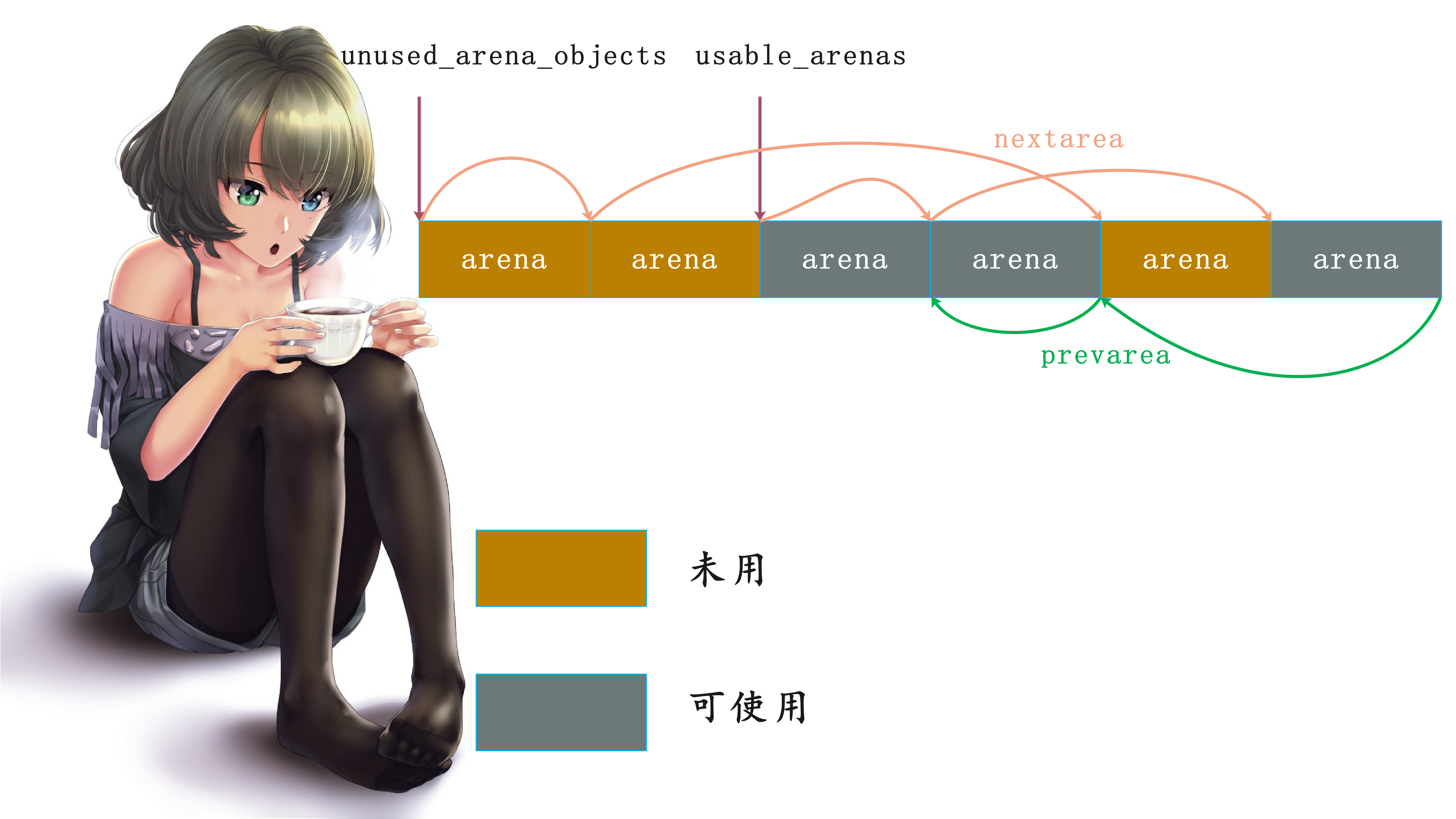
申请arena
在运行期间,Python使用new_arena来创建一个arena,我们来看看它是如何被创建的。
//arenas,多个arena组成的数组的首地址
static struct arena_object* arenas = NULL;
//当arena数组中的所有arena的个数
static uint maxarenas = 0;
//未使用的arena的个数
static struct arena_object* unused_arena_objects = NULL;
//可用的arena的个数
static struct arena_object* usable_arenas = NULL;
//初始化需要申请的arena的个数
#define INITIAL_ARENA_OBJECTS 16
static struct arena_object*
new_arena(void)
{
//arena,一个arena_object结构体对象
struct arena_object* arenaobj;
uint excess; /* number of bytes above pool alignment */
//[1]:判断是否需要扩充"未使用"的arena列表
if (unused_arena_objects == NULL) {
uint i;
uint numarenas;
size_t nbytes;
//[2]:确定本次需要申请的arena_object的个数,并申请内存
numarenas = maxarenas ? maxarenas << 1 : INITIAL_ARENA_OBJECTS;
nbytes = numarenas * sizeof(*arenas);
arenaobj = (struct arena_object *)PyMem_RawRealloc(arenas, nbytes);
if (arenaobj == NULL)
return NULL;
arenas = arenaobj;
//[3]:初始化新申请的arena_object,并将其放入"未使用"arena链表中
for (i = maxarenas; i < numarenas; ++i) {
arenas[i].address = 0; /* mark as unassociated */
arenas[i].nextarena = i < numarenas - 1 ?
&arenas[i+1] : NULL;
}
/* Update globals. */
unused_arena_objects = &arenas[maxarenas];
maxarenas = numarenas;
}
/* Take the next available arena object off the head of the list. */
//[4]:从"未使用"arena链表中取出一个"未使用"的arena
assert(unused_arena_objects != NULL);
arenaobj = unused_arena_objects;
unused_arena_objects = arenaobj->nextarena;
assert(arenaobj->address == 0);
//[5]:申请arena管理的内存
address = _PyObject_Arena.alloc(_PyObject_Arena.ctx, ARENA_SIZE);
if (address == NULL) {
arenaobj->nextarena = unused_arena_objects;
unused_arena_objects = arenaobj;
return NULL;
}
arenaobj->address = (uintptr_t)address;
//调整个数
++narenas_currently_allocated;
++ntimes_arena_allocated;
if (narenas_currently_allocated > narenas_highwater)
narenas_highwater = narenas_currently_allocated;
//[6]:设置poo集合的相关信息,这是设置为NULL
arenaobj->freepools = NULL;
arenaobj->pool_address = (block*)arenaobj->address;
arenaobj->nfreepools = MAX_POOLS_IN_ARENA;
//将pool的起始地址调整为系统页的边界
excess = (uint)(arenaobj->address & POOL_SIZE_MASK);
if (excess != 0) {
--arenaobj->nfreepools;
arenaobj->pool_address += POOL_SIZE - excess;
}
arenaobj->ntotalpools = arenaobj->nfreepools;
return arenaobj;
}
因此我们可以看到,Python首先会检查当前"未使用"链表中是否还有"未使用"arena,检查的结果将决定后续的动作。
如果在"未使用"链表中还存在未使用的arena,那么Python会从"未使用"arena链表中抽取一个arena,接着调整"未使用"链表,让它和抽取的arena断绝一切联系。然后Python申请了一块256KB大小的内存,将申请的内存地址赋给抽取出来的arena的address。我们已经知道,arena中维护的是pool集合,这块256KB的内存就是pool的容身之处,这时候arena就已经和pool集合建立联系了。这个arena已经具备了成为"可用"内存的条件,该arena和"未使用"arena链表脱离了关系,就等着被"可用"arena链表接收了,不过什么时候接收呢?先别急。
随后,python在代码的[6]处设置了一些arena用于维护pool集合的信息。需要注意的是,Python将申请到的256KB内存进行了处理,主要是放弃了一些内存,并将可使用的内存边界(pool_address)调整到了与系统页对齐。然后通过arenaobj->freepools = NULL;将freepools设置为NULL,这不奇怪,基于对freeblock的了解,我们知道要等到释放一个pool时,这个freepools才会有用。最后我们看到,pool集合占用的256KB内存在进行边界对齐后,实际是交给pool_address来维护了。
回到new_arena中的[1]处,如果unused_arena_objects为NULL,则表明目前系统中已经没有"未使用"arena了,那么Python首先会扩大系统的arena集合(小块内存内存池)。Python在内部通过一个maxarenas的变量维护了存储arena的数组的个数,然后在[2]处将待申请的arena的个数设置为当然arena个数(maxarenas)的2倍。当然首次初始化的时候maxarenas为0,此时为16。
在获得了新的maxarenas后,Python会检查这个新得到的值是否溢出了。如果检查顺利通过,Python就会在[3]处通过realloc扩大arenas指向的内存,并对新申请的arena_object进行设置,特别是那个不起眼的address,要将新申请的address一律设置为0。实际上,这是一个标识arena是出于"未使用"状态还是"可用"状态的重要标记。而一旦arena(arena_object)和pool集合建立了联系,这个address就变成了非0,看代码的[6]处。当然别忘记我们为什么会走到[3]这里,是因为unused_arena_objects == NULL了,而且最后还设置了unused_arena_objects,这样系统中又有了"未使用"的arena了,接下来Python就在[4]处对一个arena进行初始化了。
内存池
通过#define SMALL_REQUEST_THRESHOLD 512我们知道Python内部默认的小块内存与大块内存的分界点为512个字节。也就是说,当申请的内存小于512个字节,pymalloc_alloc会在内存池中申请内存,而当申请的内存超过了512字节,那么pymalloc_alloc将退化为malloc,通过操作系统来申请内存。当然,通过修改Python源代码我们可以改变这个值,从而改变Python的默认内存管理行为。
当申请的内存小于512字节时,Python会使用area所维护的内存空间。那么Python内部对于area的个数是否有限制呢?换句话说,Python对于这个小块空间内存池的大小是否有限制?其实这个决策取决于用户,Python提供了一个编译符号,用于控制是否限制内存池的大小,不过这里不是重点,只需要知道就行。
尽管我们在前面花了不少篇幅介绍arena,同时也看到arena是Python小块内存池的最上层结构,其实所有arena的集合就是小块内存池。然而在实际的使用中,Python并不直接与arenas和arena数组打交道。当Python申请内存时,最基本的操作单元并不是arena,而是pool。估计到这里懵了,别急,慢慢来。
举个例子,当我们申请一个28字节的内存时,Python内部会在内存池寻找一块能够满足需求的pool,从中取出一个block返回,而不会去寻找arena。这实际上是由pool和arena的属性决定的,在Python中,pool是一个有size概念的内存管理抽象体,一个pool中的block总是有确定的大小,这个pool总是和某个size class index对应,还记得pool_header中的那个szidx么?而arena是没有size概念的内存管理抽象体。这就意味着,同一个arena在某个时刻,其内部的pool集合管理的可能都是相同字节的block,比如:32字节;而到了另一个时刻,由于系统需要,这个arena可能被重新划分,其中的pool集合管理的block可能变成是64字节了,甚至pool集合中一半的pool管理的是32字节block,另一半管理64字节block。这就决定了在进行内存分配和销毁时,所有的动作都是在pool上完成的。
所以一个arena,并不要求pool集合中所有pool管理的block必须一样;可以有管理16字节block的pool,也可以有管理32字节block的pool,等等。
当然内存池中的pool不仅仅是一个有size概念的内存管理抽象体,更进一步的,它还是一个有状态的内存管理抽象体。正如我们之前说的,一个pool在Python运行的任何一个时刻,总是处于以下三种状态中的一种:
empty状态:pool中所有的block都未被使用used状态:pool中至少有一个block已经被使用,并且至少有一个block未被使用full状态:pool中所有的block都已经被使用,这种状态的pool在arena中,但是不在arena的freepools链表中。
而且pool处于不同的状态,也会得到Python不同的对待:
如果pool完全空闲,那么Python会将它占用的内存页归还给操作系统、或者缓存起来,后续需要重新分配时直接拿来用。如果pool完全用满,Python就无需关注它了,直接丢在一边。如果pool只是部分使用,说明它还有内存块未分配,Python会将它们以双向链表的形式组织起来;
可用pool链表
由于used状态的pool只是部分使用,内部还有内存块未分配,将它们组织起来可供后续分配。Python通过pool_header中的nextpool和prevpool指针,将它们连成一个双向循环链表。
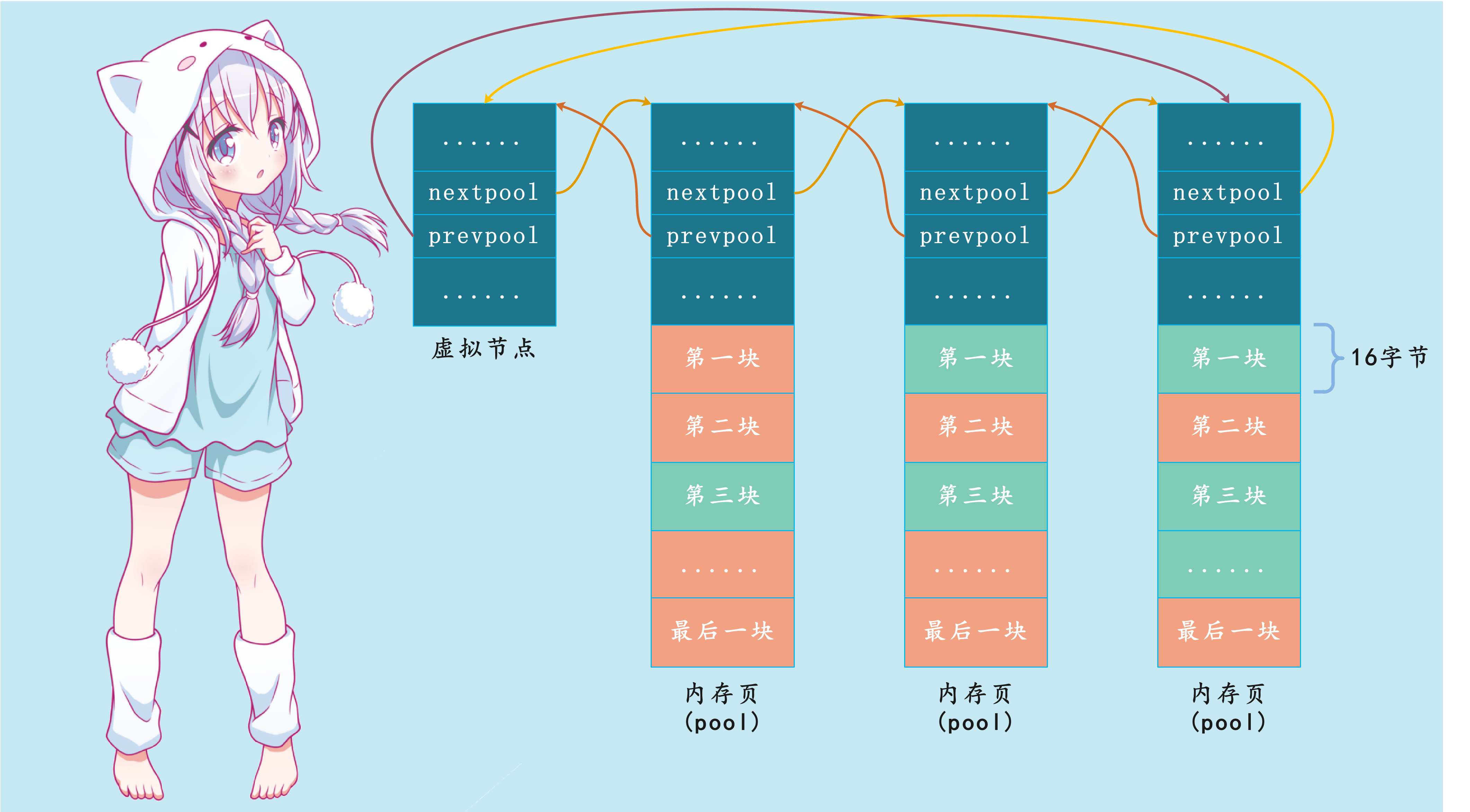
注意到,同个可用pool链表中的内存块大小规格都是一样的,我们还以16字节为例。另外,为了简化链表处理逻辑,Python引入了一个虚拟节点,这是一个常见的C语言链表实现技巧。一个空的pool链表是这样的,判断条件是:pool -> nextpool == pool:

虚拟节点只参与链表维护,并不实际管理内存块。因为无需为虚拟节点分配一个完整的4k内存页,64字节pool_header结构体足以。然而实际上Python作者们更抠,只分配刚好足够nextpool和prevpool指针用的内存,手法非常精妙,后续会体现。
Python优先从链表的第一个pool中分配内存块,如果pool的可用内存块用完了,就将其从可用pool链表中剔除。
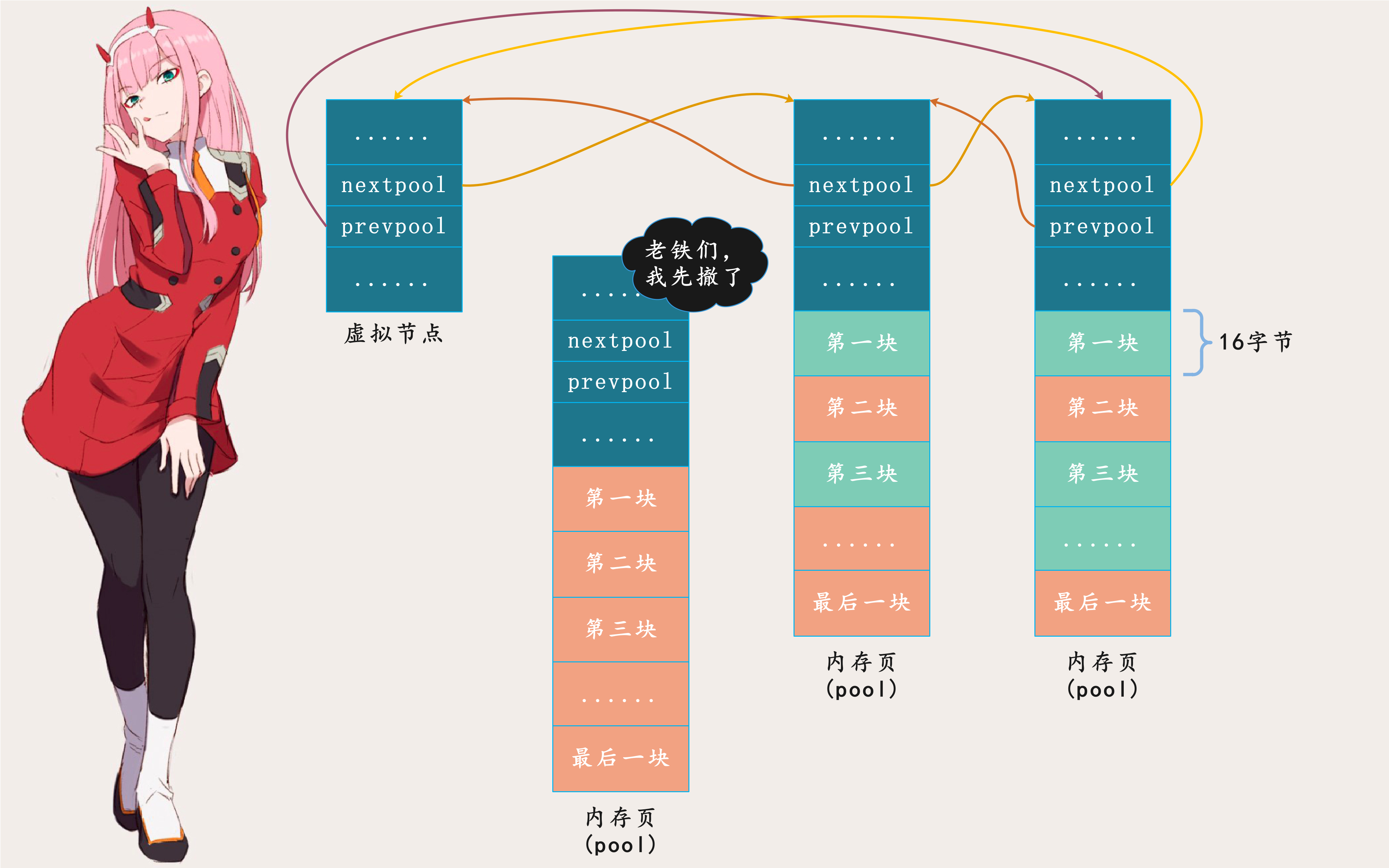
当一个内存块(block)被回收,Python根据块地址计算得到距离该块最近的pool边界地址,计算方式就是我们上面说的那个宏:POOL_ADDR,将块(block)地址对齐为内存页(pool)尺寸的整数倍,便得到pool地址。
得到pool地址后,Python将空闲内存块插入到空闲内存块链表的头部,如果pool状态是由full变成used,那么Python还会将它插回到可用pool链表的头部。

插入到可用pool链表头部是为了保证较满的pool在链表的前面,以便优先使用。位于尾部的pool被使用的概率很低,随着时间的推移,更多的内存块被释放出来,慢慢变空。因此可用pool链表很明显头重脚轻,靠前的pool比较慢,靠后的pool比较空。
当一个pool中所有的内存块(block)都被释放,状态就变成了empty,那么Python就会将它移除可用pool链表,内存页可能直接归还给操作系统,或者缓存起来备用:
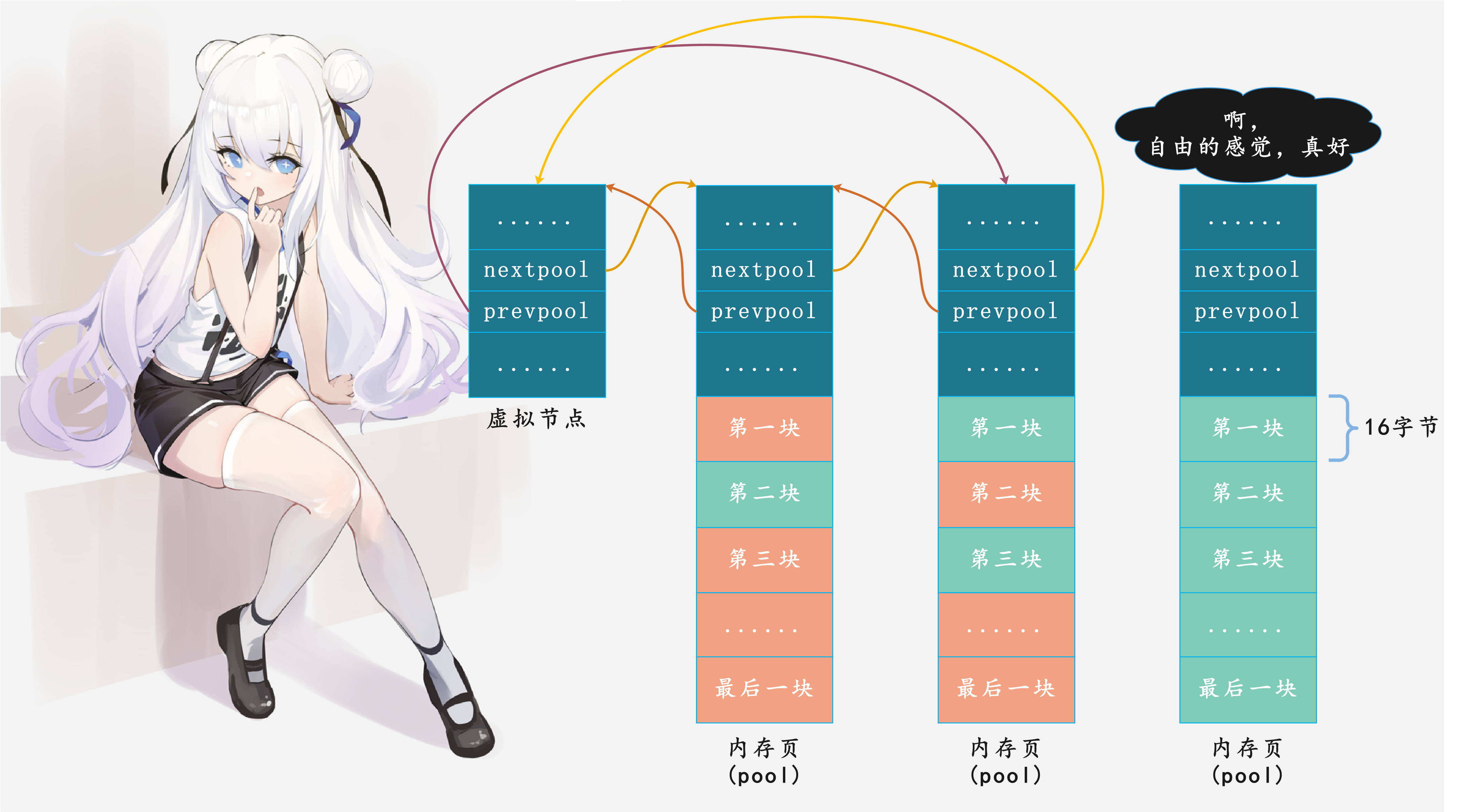
实际上,pool链表任一节点均有机会完全空闲下来,这由概率决定,尾部节点概率最高。
可用pool链表数组
Python内存池管理内存块,按照尺寸分门别类进行。因此每种规格都需要维护一个独立可执行的可用pool链表,以8直接为梯度,那么会有64中pool链表。
那么如何组织这么多pool链表呢?最直接的办法就是分配一个长度为64的虚拟节点数组,这个虚拟节点数组就是我们上面提到过的usedpools。Python内部维护的usedpools数组是一个非常巧妙的实现,该数组维护着所有的处于used状态的pool。当申请内存时,Python就会通过usedpools寻找到一个可用的pool(处于used状态),从中分配一个block。因此我们想,一定有一个usedpools相关联的机制,完成从申请的内存的大小到size class index之间的转换,否则Python就无法找到最合适的pool了。这种机制和usedpools的结构有着密切的关系,而usedpools也藏身于 Objects/obmalloc.c 中。但是我们暂时先不看它的结构,因为还缺少一个东西,我们后面会说。
然后如果程序请求 5 字节,Python 将分配 8 字节内存块,通过数组第 0 个虚拟节点即可找到 8 字节 pool 链表;如果程序请求 56 字节,Python 将分配 64 字节内存块,则需要从数组第 7 个虚拟节点出发;其他以此类推。
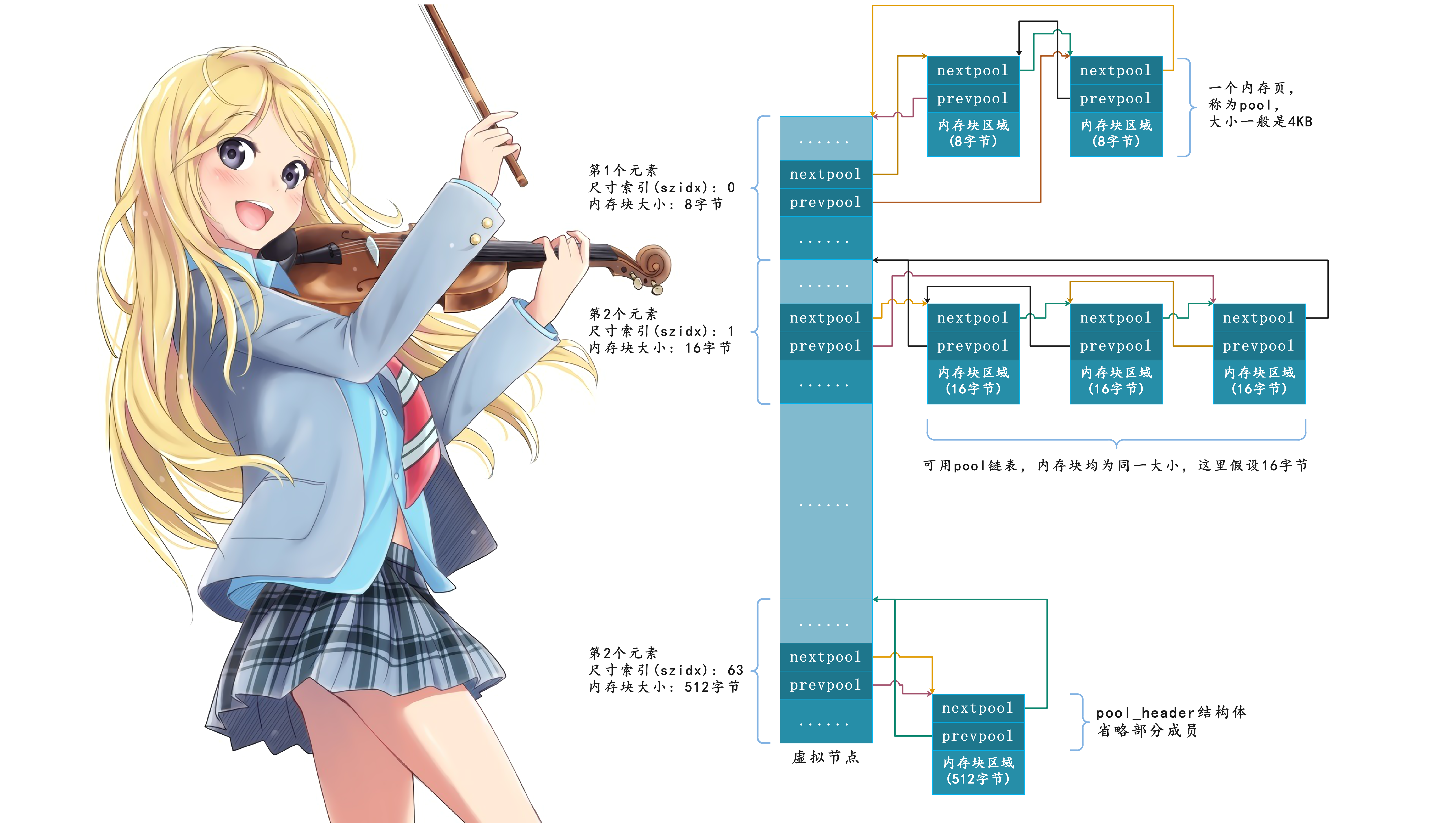
那么,虚拟节点数组需要占用多少内存呢?很好计算:48 * 64 = 3072字节,也就是3KB的内存,0.75个内存页。
话说3KB的内存,你们觉得多吗?对于现在的机器来说,3KB可以忽略不计吧。但是高级程序猿对内存的精打细算,完全堪比、甚至凌驾于菜市场买菜的大妈,所以Python的作者从中还扣掉了三分之二。相当于只给虚拟机节点原来的三分之一、也就是1KB的内存,那么这是如何做到的呢?
事实上我们在前面已经埋下伏笔了,虚拟节点只参与维护链表结构,并不管了内存页。因此虚拟节点其实只使用pool_header结构体中参与链表维护的nextpool和prevpool两个指针字段。

为避免浅蓝色部分内存浪费,Python 作者们将虚拟节点想象成一个个卡片,将深蓝色部分首尾相接,最终转换成一个纯指针数组。
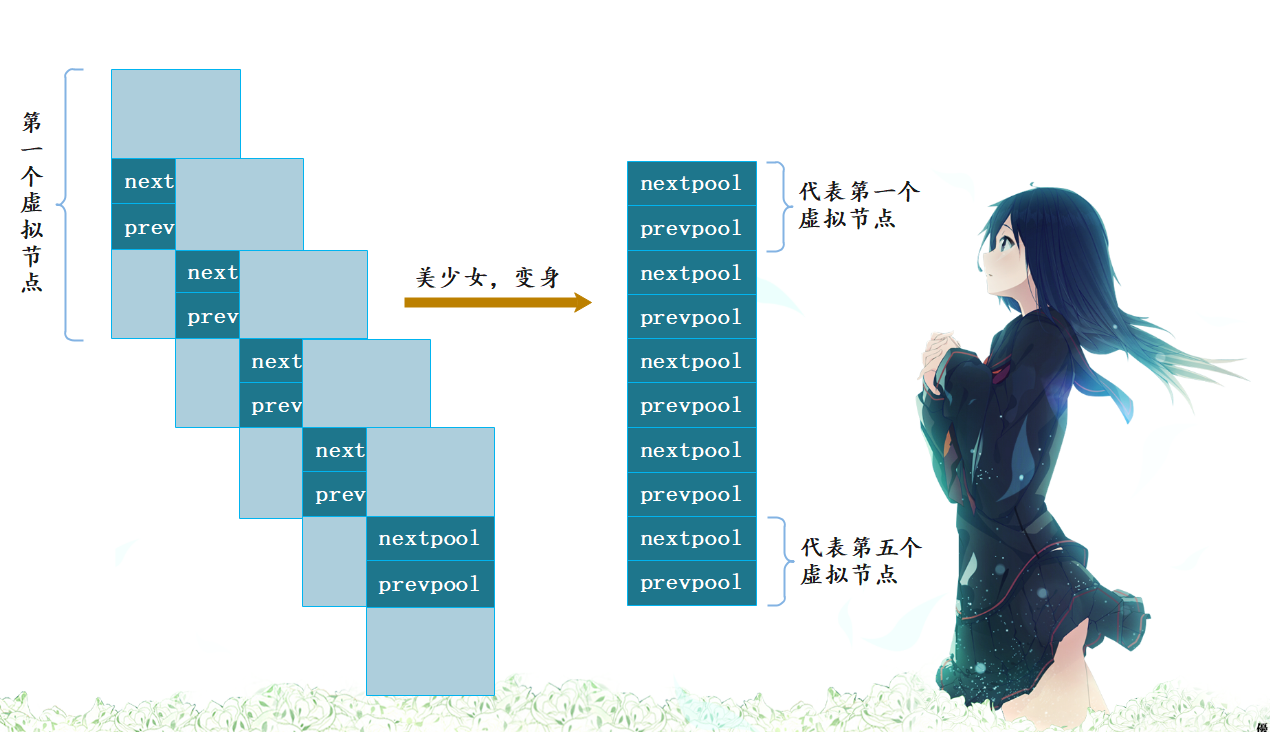
而这个纯指针数组就是在 Objects/obmalloc.c 中定义的 usedpools ,每个虚拟节点对应数组里面的两个指针。所以之前我们说先不看 usedpools 的结构体定义,就是因为直接看的话绝对会一脸懵,因为不知道数组里面存的是啥,但是现在我们知道了数组里面存的就是一堆指针:
typedef uint8_t block;
#define PTA(x) ((poolp )((uint8_t *)&(usedpools[2*(x)]) - 2*sizeof(block *)))
#define PT(x) PTA(x), PTA(x)
//NB_SMALL_SIZE_CLASSES之前好像出现过,但是不用说也知道这表示当前配置下有多少个不同size的块
//在我当前的机器就是512/8=64个,对应的size class index就是从0到63
#define NB_SMALL_SIZE_CLASSES (SMALL_REQUEST_THRESHOLD / ALIGNMENT)
static poolp usedpools[2 * ((NB_SMALL_SIZE_CLASSES + 7) / 8) * 8] = {
PT(0), PT(1), PT(2), PT(3), PT(4), PT(5), PT(6), PT(7)
#if NB_SMALL_SIZE_CLASSES > 8
, PT(8), PT(9), PT(10), PT(11), PT(12), PT(13), PT(14), PT(15)
#if NB_SMALL_SIZE_CLASSES > 16
, PT(16), PT(17), PT(18), PT(19), PT(20), PT(21), PT(22), PT(23)
#if NB_SMALL_SIZE_CLASSES > 24
, PT(24), PT(25), PT(26), PT(27), PT(28), PT(29), PT(30), PT(31)
#if NB_SMALL_SIZE_CLASSES > 32
, PT(32), PT(33), PT(34), PT(35), PT(36), PT(37), PT(38), PT(39)
#if NB_SMALL_SIZE_CLASSES > 40
, PT(40), PT(41), PT(42), PT(43), PT(44), PT(45), PT(46), PT(47)
#if NB_SMALL_SIZE_CLASSES > 48
, PT(48), PT(49), PT(50), PT(51), PT(52), PT(53), PT(54), PT(55)
#if NB_SMALL_SIZE_CLASSES > 56
, PT(56), PT(57), PT(58), PT(59), PT(60), PT(61), PT(62), PT(63)
#if NB_SMALL_SIZE_CLASSES > 64
#error "NB_SMALL_SIZE_CLASSES should be less than 64"
#endif /* NB_SMALL_SIZE_CLASSES > 64 */
#endif /* NB_SMALL_SIZE_CLASSES > 56 */
#endif /* NB_SMALL_SIZE_CLASSES > 48 */
#endif /* NB_SMALL_SIZE_CLASSES > 40 */
#endif /* NB_SMALL_SIZE_CLASSES > 32 */
#endif /* NB_SMALL_SIZE_CLASSES > 24 */
#endif /* NB_SMALL_SIZE_CLASSES > 16 */
#endif /* NB_SMALL_SIZE_CLASSES > 8 */
};
然后将对应的两个指针的前后空间都想象成是自己的,这样就能够得到一个虚无缥缈、但又非常完整的pool_header结构体。尽管它们前后的空间不是自己的,但是不妨碍精神层面上YY一下,不过由于我们不会访问除了nextpool和prevpool指针之外的其它字段,所以虽然有内存越界,但也无伤大雅。
以一个代表空链表的虚拟节点为例,nextpool 和 prevpool 指针均指向 pool_header 自己。虽然实际上 nextpool 和 prevpool 都指向了数组中的其他虚拟节点,但逻辑上可以想象成指向当前的 pool_header 结构体:
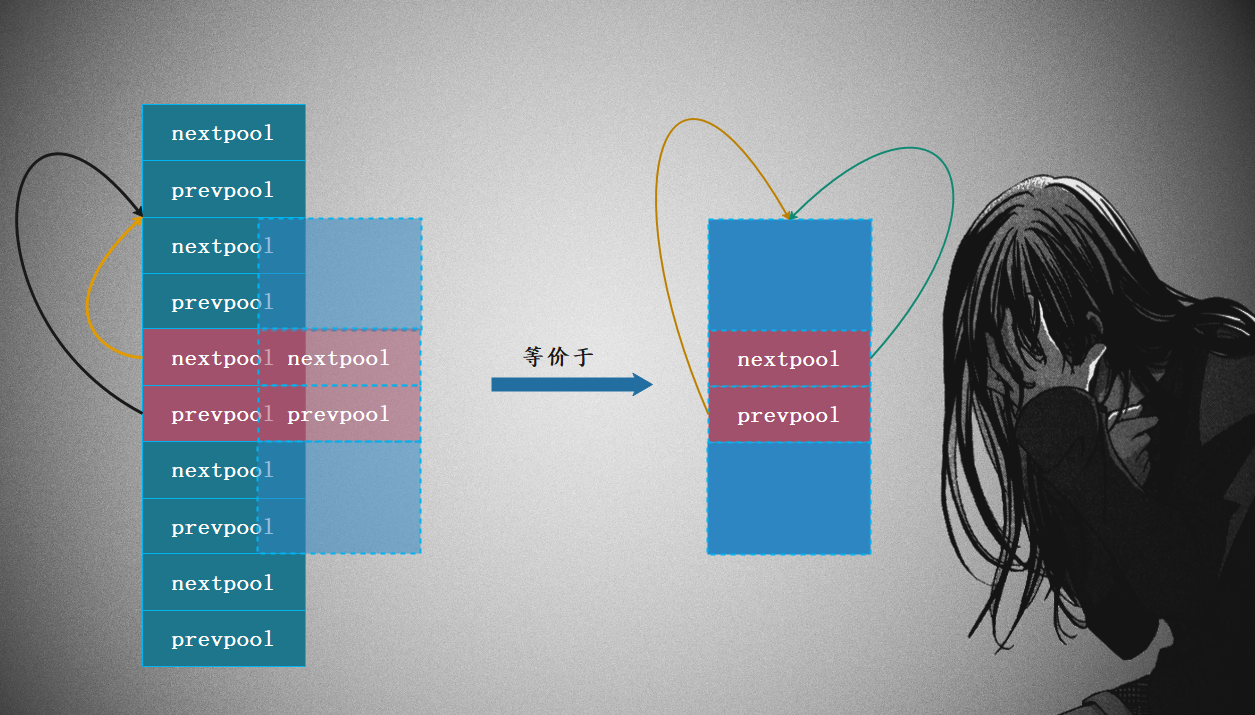
经过这番优化,数组只需要 16 * 64 = 1024 字节的内存空间即可,也就是1KB,所以节省了三分之二。然而为了节省这三分之二的内存,代码变得难以理解。当然Python诞生的那个年代,内存还是比较精贵的,所以秉承着能省则省的策略,然后这个优良传统一直保持到了现在。
小结
对于一个用C开发的庞大的软件(python是一门高级语言,但是执行对应代码的解释器则可以看成是c的一个软件),其中的内存管理可谓是最复杂、最繁琐的地方了。不同尺度的内存会有不同的抽象,这些抽象在各种情况下会组成各式各样的链表,非常复杂。但是我们还是有可能从一个整体的尺度上把握整个内存池,尽管不同的链表变幻无常,但我们只需记住,所有的内存都在arenas(或者说那个存放多个arena的数组)的掌握之中 。
更详细的内容可以自己进入 Objects/obmalloc.c 中查看对应源码,主要看两个函数:
pymalloc_alloc: 负责内存分配pymalloc_free: 负责内存释放
关于内存管理和内存池我们就说到这里,下一篇介绍Python中的垃圾回收。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号