《深度剖析CPython解释器》11. 深入Python虚拟机,探索虚拟机执行字节码的奥秘
楔子
这一次我们就来剖析Python运行字节码的原理,我们知道Python虚拟机是Python的核心,在源代码被编译成PyCodeObject对象时,就将由Python虚拟机接手整个工作。Python虚拟机会从PyCodeObject中读取字节码,并在当前的上下文中执行,直到所有的字节码都被执行完毕。
Python虚拟机的执行环境
Python的虚拟机实际上是在模拟操作系统运行可执行文件的过程,我们先来看看在一台普通的x86的机器上,可执行文件是以什么方式运行的。在这里主要关注运行时栈的栈帧,如图所示:
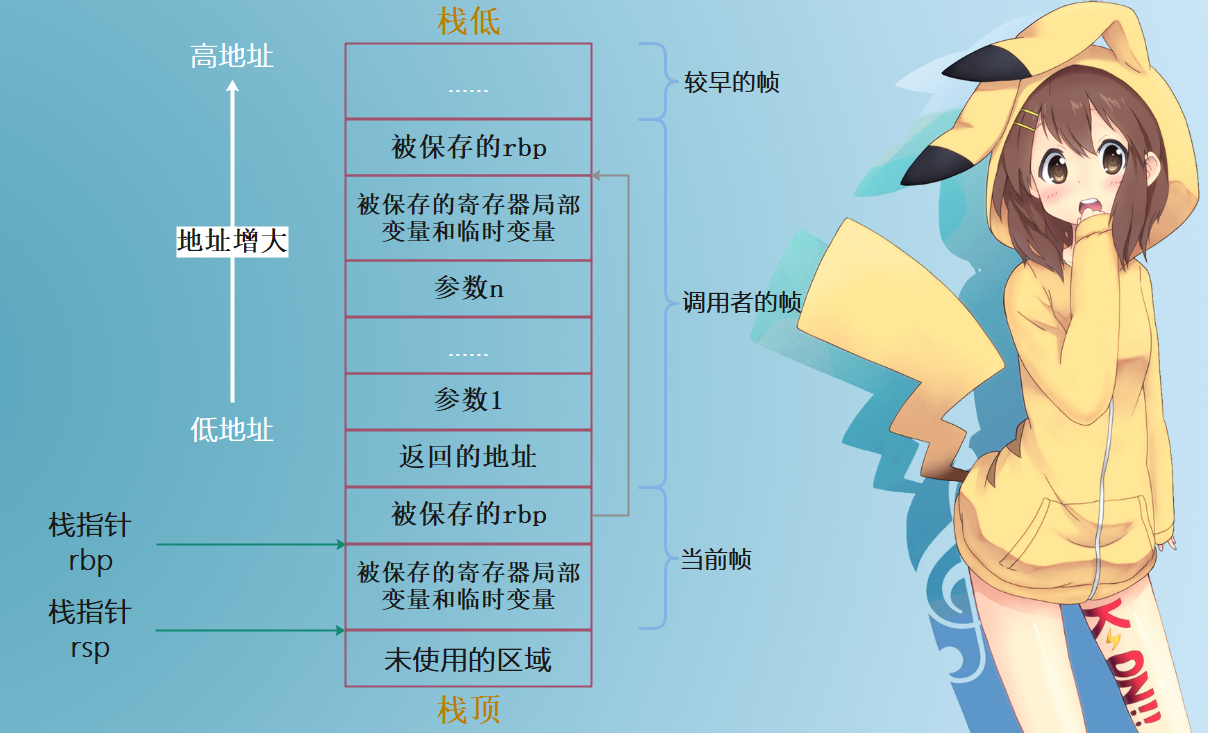
x86体系处理器通过栈维护调用关系,每次函数调用时就在栈上分配一个帧用于保存调用上下文以及临时存储。CPU中有两个关键寄存器,rsp指向当前栈顶,rbp指向当前栈帧。每次调用函数时,调用者(Caller)负责准备参数、保存返回地址,并跳转到被调用函数中执行代码;作为被调用者(Callee),函数先将当前rbp寄存器压入栈(保存调用者栈帧位置),并将rbp设为当前栈顶(保存当前新栈帧的位置)。由此,rbp寄存器与每个栈帧中保存调用者栈帧地址一起完美地维护了函数调用关系链。
我们以Python中的代码为例:
def f(a, b):
return a + b
def g():
return f()
g()
当程序进入到函数 f 中执行时,那么显然调用者的帧就是函数 g 的栈帧,而当前帧则是 f 的栈帧。
解释一下:栈是先入后出的数据结构,从栈顶到栈底地址是增大的。对于一个函数而言,其所有对局部变量的操作都在自己的栈帧中完成,而调用函数的时候则会为调用的函数创建新的栈帧。
在上图中,我们看到运行时栈的地址是从高地址向低地址延伸的。当在函数 g 中调用函数 f 的时候,系统就会在地址空间中,于 g 的栈帧之后创建 f 的栈帧。当然在函数调用的时候,系统会保存上一个栈帧的栈指针(rsp)和帧指针(rbp)。当函数的调用完成时,系统就又会把rsp和rbp的值恢复为创建 f 栈帧之前的值,这样程序的流程就又回到了 g 函数中,当然程序的运行空间则也又回到了函数g的栈帧中,这就是可执行文件在x86机器上的运行原理。
而上一章我们说Python源代码经过编译之后,所有字节码指令以及其他静态信息都存储在PyCodeObject当中,那么是不是意味着Python虚拟机就在PyCodeObject对象上进行所有的动作呢?其实不能给出唯一的答案,因为尽管PyCodeObject包含了关键的字节码指令以及静态信息,但是有一个东西,是没有包含、也不可能包含的,就是程序运行的动态信息--执行环境。
var = "satori"
def f():
var = 666
print(var)
f()
print(var)
首先代码当中出现了两个print(var),它们的字节码指令是相同的,但是执行的效果却显然是不同的,这样的结果正是执行环境的不同所产生的。因为环境的不同,var的值也是不同的。因此同一个符号在不同环境中对应不同的类型、不同的值,必须在运行时进行动态地捕捉和维护,这些信息是不可能在PyCodeObject对象中被静态的存储的。
所以我们还需要执行环境,这里的执行环境和我们下面将要说的名字空间比较类似(名字空间暂时就简单地理解为作用域即可)。但是名字空间仅仅是执行环境的一部分,除了名字空间,在执行环境中,还包含了其他的一些信息。
因此对于上面代码,我们可以大致描述一下流程:
当python在执行第一条语句时,已经创建了一个执行环境,假设叫做A所有的字节码都会在这个环境中执行,Python可以从这个环境中获取变量的值,也可以修改。当发生函数调用的时候,Python会在执行环境A中调用函数f的字节码指令,会在执行环境A之外重新创建一个执行环境B在环境B中也有一个名字为var的对象,但是由于环境的不同,var也不同。两个人都叫小明,但一个是北京的、一个是上海的,所以这两者没什么关系一旦当函数f的字节码指令执行完毕,会将当前f的栈帧销毁(也可以保留下来),再回到调用者的栈帧中来。就像是递归一样,每当调用函数就会创建一个栈帧,一层一层创建,一层一层返回。
所以Python在运行时的时候,并不是在PyCodeObject对象上执行操作的,而是我们一直在说的栈帧对象(PyFrameObject),从名字也能看出来,这个栈帧也是一个对象。
Python源码中的PyFrameObject
对于Python而言,PyFrameObject可不仅仅只是类似于x86机器上看到的那个简简单单的栈帧,Python中的PyFrameObject实际上包含了更多的信息。
typedef struct _frame {
PyObject_VAR_HEAD /* 可变对象的头部信息 */
struct _frame *f_back; /* 上一级栈帧, 也就是调用者的栈帧 */
PyCodeObject *f_code; /* PyCodeObject对象, 通过栈帧对象的f_code可以获取对应的PyCodeObject对象 */
PyObject *f_builtins; /* builtin命名空间,一个PyDictObject对象 */
PyObject *f_globals; /* global命名空间,一个PyDictObject对象 */
PyObject *f_locals; /* local命名空间,一个PyDictObject对象 */
PyObject **f_valuestack; /* 运行时的栈底位置 */
PyObject **f_stacktop; /* 运行时的栈顶位置 */
PyObject *f_trace; /* 回溯函数,打印异常栈 */
char f_trace_lines; /* 是否触发每一行的回溯事件 */
char f_trace_opcodes; /* 是否触发每一个操作码的回溯事件 */
PyObject *f_gen; /* 是否是生成器 */
int f_lasti; /* 上一条指令在f_code中的偏移量 */
int f_lineno; /* 当前字节码对应的源代码行 */
int f_iblock; /* 当前指令在栈f_blockstack中的索引 */
char f_executing; /* 当前栈帧是否仍在执行 */
PyTryBlock f_blockstack[CO_MAXBLOCKS]; /* 用于try和loop代码块 */
PyObject *f_localsplus[1]; /* 动态内存,维护局部变量+cell对象集合+free对象集合+运行时栈所需要的空间 */
} PyFrameObject;
因此我们看到,Python会根据PyCodeObject对象来创建一个栈帧对象(或者直接说栈帧也行),也就是PyFrameObject对象,虚拟机实际上是在PyFrameObject对象上执行操作的。每一个PyFrameObject都会维护一个PyCodeObject,换句话说,每一个PyCodeObject都会隶属于一个PyFrameObject。并且从f_back中可以看出,在Python的实际执行过程中,会产生很多PyFrameObject对象,而这些对象会被链接起来,形成一条执行环境链表,这正是x86机器上栈帧之间关系的模拟。在x86机器上,栈帧间通过rsp和rbp指针建立了联系,使得新栈帧在结束之后能够顺利的返回到旧栈帧中,而Python则是利用f_back来完成这个动作。
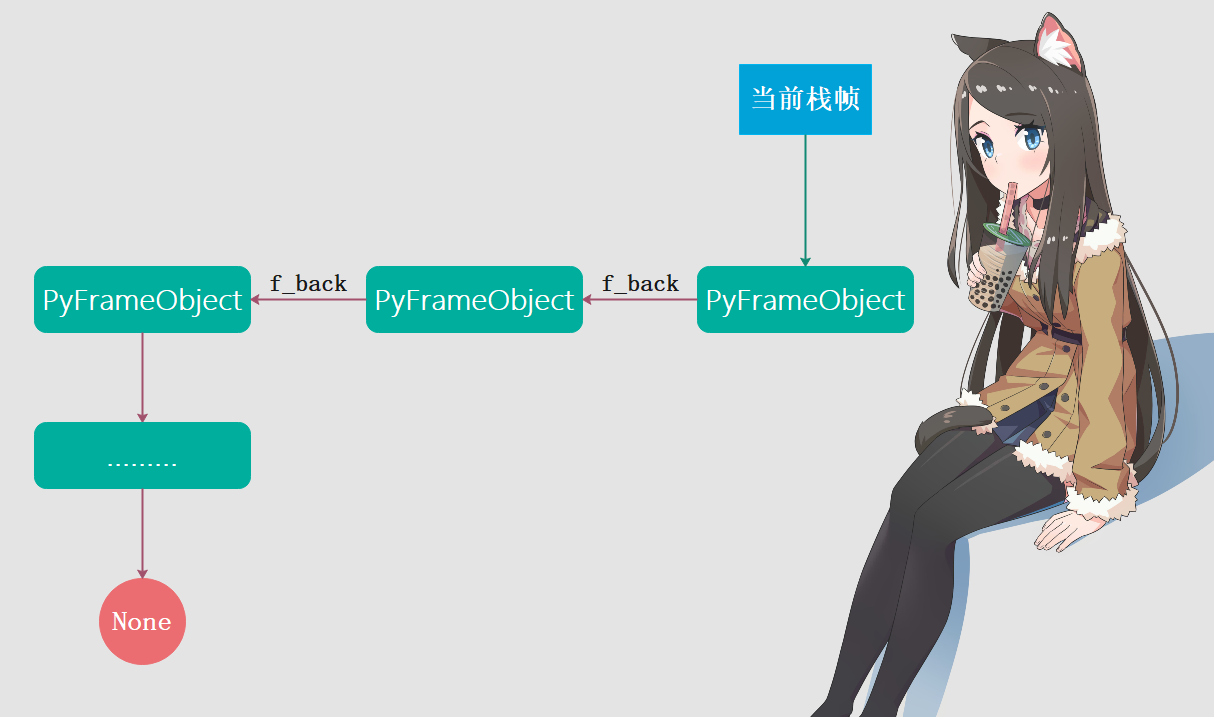
里面f_code成员是一个指针,指向相应的PyCodeObject对象,而接下来的f_builtins、f_globals、f_locals是三个独立的名字空间,在这里我们看到了名字空间和执行环境(即栈帧)之间的关系。名字空间实际上是维护这变量名和变量值的PyDictObject对象,所以在这三个PyDictObject对象中分别维护了各自name和value的对应关系。
在PyFrameObject的开头,有一个PyObject_VAR_HEAD,表示栈帧是一个变长对象,即每一次创建PyFrameObject对象大小可能是不一样的,那么变动在什么地方呢?首先每一个PyFrameObject对象都维护了一个PyCodeObject对象,而每一个PyCodeObject对象都会对应一个代码块(code block)。在编译一段代码块的时候,会计算这段代码块执行时所需要的栈空间的大小,这个栈空间大小存储在PyCodeObject对象的co_stacksize中。而不同的代码块所需要的栈空间是不同的,因此PyFrameObject的开头要有一个PyObject_VAR_HEAD对象。最后其实PyFrameObject里面的内存空间分为两部分,一部分是编译代码块需要的空间,另一部分是计算所需要的空间,我们也称之为"运行时栈"。
注意:x86机器上执行时的运行时栈不止包含了计算
(还有别的)所需要的内存空间,但PyFrameObject对象的运行时栈则只包含计算所需要的内存空间,这一点务必注意。
在python中访问PyFrameObject对象
在Python中获取栈帧,我们可以使用inspect模块。
import inspect
def f():
# 返回当前所在的栈帧, 这个函数实际上是调用了sys._getframe(1)
return inspect.currentframe()
frame = f()
print(frame) # <frame at 0x000001FE3D6E69F0, file 'D:/satori/1.py', line 6, code f>
print(type(frame)) # <class 'frame'>
我们看到栈帧的类型是<class 'frame'>,正如PyCodeObject对象的类型是<class 'code'>一样。还是那句话,这两个类Python解释器没有暴露给我们,所以不可以直接使用。同理,还有Python的函数,类型是<class 'function'>;模块,类型是<class 'module'>,这些Python解释器都没有给我们提供,如果直接使用的话,那么frame、code、function、module只是几个没有定义的变量罢了,这些类我们只能通过这种间接的方式获取。
下面我们就来获取一下栈帧的成员属性
import inspect
def f():
name = "夏色祭"
age = -1
return inspect.currentframe()
def g():
name = "神乐mea"
age = 38
return f()
# 当我们调用函数g的时候, 也会触发函数f的调用
# 而一旦f执行完毕, 那么f对应的栈帧就被全局变量frame保存起来了
frame = g()
print(frame) # <frame at 0x00000194046863C0, file 'D:/satori/1.py', line 8, code f>
# 获取上一级栈帧, 即调用者的栈帧, 显然是g的栈帧
print(frame.f_back) # <frame at 0x00000161C79169F0, file 'D:/satori/1.py', line 14, code g>
# 模块也是有栈帧的, 我们后面会单独说
print(frame.f_back.f_back) # <frame at 0x00000174CE997840, file 'D:/satori/1.py', line 25, code <module>>
# 显然最外层就是模块了, 模块对应的上一级栈帧是None
print(frame.f_back.f_back.f_back) # None
# 获取PyCodeObject对象
print(frame.f_code) # <code object f at 0x00000215D560D450, file "D:/satori/1.py", line 4>
print(frame.f_code.co_name) # f
# 获取f_locals, 即栈帧内部的local名字空间
print(frame.f_locals) # {'name': '夏色祭', 'age': -1}
print(frame.f_back.f_locals) # {'name': '神乐mea', 'age': 38}
"""
另外我们看到函数运行完毕之后里面的局部变量居然还能获取
原因就是栈帧没被销毁, 因为它被返回了, 而且被外部变量接收了
同理:该栈帧的上一级栈帧也不能被销毁, 因为当前栈帧的f_back指向它了, 引用计数不为0, 所以要保留
"""
# 获取栈帧对应的行号
print(frame.f_lineno) # 8
print(frame.f_back.f_lineno) # 14
"""
行号为8的位置是: return inspect.currentframe()
行号为14的位置是: return f()
"""
通过栈帧我们可以获取很多的属性,我们后面还会慢慢说。
此外,异常处理也可以获取到栈帧。
def foo():
try:
1 / 0
except ZeroDivisionError:
import sys
# exc_info返回一个三元组,分别是异常的类型、值、以及traceback
exc_type, exc_value, exc_tb = sys.exc_info()
print(exc_type) # <class 'ZeroDivisionError'>
print(exc_value) # division by zer
print(exc_tb) # <traceback object at 0x00000135CEFDF6C0>
# 调用exc_tb.tb_frame即可拿到异常对应的栈帧
# 另外这个exc_tb也可以通过except ZeroDivisionError as e; e.__traceback__的方式获取
print(exc_tb.tb_frame.f_back) # <frame at 0x00000260C1297840, file 'D:/satori/1.py', line 17, code <module>>
# 因为foo是在模块级别、也就是最外层调用的,所以tb_frame是当前函数的栈帧、那么tb_frame.f_back就是整个模块对应的栈帧
# 那么再上一级的话, 栈帧就是None了
print(exc_tb.tb_frame.f_back.f_back) # None
foo()
名字、作用域、名字空间
我们在PyFrameObject里面看到了3个独立的名字空间:f_locals、f_globals、f_builtins。名字空间对于Python来说是一个非常重要的概念,整个Python虚拟机运行的机制和名字空间有着非常紧密的联系。并且在Python中,与命名空间这个概念紧密联系着的还有"名字"、"作用域"这些概念,下面就来剖析这些概念是如何实现的。
Python中的变量只是一个名字
很早的时候我们就说过,Python中的变量在底层一个泛型指针PyObject *,而在Python的层面上来说,变量只是一个名字、或者说符号,用于和对象进行绑定的。变量的定义本质上就是建立名字和对象之间的约束关系,所以a = 1这个赋值语句本质上就是将符号a和1对应的PyLongObject绑定起来,让我们通过a可以找到对应的PyLongObject。
除了变量赋值,函数定义、类定义也相当于定义变量,或者说完成名字和对象之间的绑定。
def foo(): pass
class A(): pass
定义一个函数也相当于定义一个变量,会先根据函数体创建一个函数对象,然后将名字foo和函数对象绑定起来,所以函数名和函数体之间是分离的,同理类也是如此。
再有导入一个模块,也相当于定义一个变量。
import os
import os,相当于将名字os和模块对象绑定起来,通过os可以访问模块里面的属性。或者import numpy as np当中的as语句也相当于定义一个变量,将名字np和对应的模块对象绑定起来,以后就可以通过np这个名字去访问模块内部的属性了。
另外,当我们导入一个模块的时候,解释器是这么做的。比如:import os等价于os = __import__("os"),可以看到本质上还是一个赋值语句。
作用域和名字空间
我们说赋值语句、函数定义、类定义、模块导入,本质上只是完成了名字和对象之间的绑定。而从概念上讲,我们实际上得到了一个name和obj这样的映射关系,通过name获取对应的obj,而它们的容身之所就是名字空间。而名字空间是通过PyDictObject对象实现的,这对于映射来说简直再适合不过了,所以字典在Python底层也是被大量使用的,因此是经过高度优化的。
但是一个模块内部,名字还存在可见性的问题,比如:
a = 1
def foo():
a = 2
print(a) # 2
foo()
print(a) # 1
我们看到同一个变量名,打印的确实不同的值,说明指向了不同的对象。换句话说这两个变量是在不同的名字空间中被创建的,我们知道名字空间本质上是一个字典,如果两者是在同一个名字空间,那么由于字典的key的不重复性,那么当我进行a=2的时候,会把字典里面key为'a'的value给更新掉,但是在外面还是打印为1,这说明,两者所在的不是同一个名字空间。在不同的名字空间,打印的也就自然不是同一个a。
因此对于一个模块而言,内部是可能存在多个名字空间的,每一个名字空间都与一个作用域相对应。作用域就可以理解为一段程序的正文区域,在这个区域里面定义的变量是有作用的,然而一旦出了这个区域,就无效了。
对于作用域这个概念,至关重要的是要记住它仅仅是由源程序的文本所决定的。在Python中,一个变量在某个位置是否起作用,是由其在文本位置是否唯一决定的。因此,Python是具有静态作用域(词法作用域)的,而名字空间则是作用域的动态体现。一个由程序文本定义的作用域在Python运行时就会转化为一个名字空间、即一个PyDictObject对象。也就是说,在函数执行时,会为创建一个名字空间,这一点在以后剖析函数时会详细介绍。
我们之前说Python在对Python源代码进行编译的时候,对于代码中的每一个block,都会创建一个PyCodeObject与之对应。而当进入一个新的名字空间、或者说作用域时,我们就算是进入了一个新的block了。相信此刻你已经明白了,而且根据我们使用Python的经验,显然函数、类都是一个新的block,当Python运行的时候会它们创建各自的名字空间。
所以名字空间是名字、或者变量的上下文环境,名字的含义取决于命名空间。更具体的说,一个变量名对应的变量值什么,在Python中是不确定的,需要名字空间来决定。
位于同一个作用域中的代码可以直接访问作用域中出现的名字,即所谓的"直接访问",也就是不需要通过属性引用的访问修饰符:.。
class A:
a = 1
class B:
b = 2
print(A.a) # 1
print(b) # 2
比如:B里面想访问A里面的内容,比如通过A.属性的方式,表示通过A来获取A里面的属性。但是访问B的内容就不需要了,因为都是在同一个作用域,所以直接访问即可。
访问名字这样的行为被称为名字引用,名字引用的规则决定了Python程序的行为。
a = 1
def foo():
a = 2
print(a) # 2
foo()
print(a) # 1
还是对于上面的代码,如果我们把函数里面的a=2给删掉,那么显然作用域里面已经没有a这个变量的,那么再执行程序会有什么后果呢?从Python层面来看,显然是会寻找外部的a。因此我们可以得到如下结论:
作用域是层层嵌套的,显然是这样,毕竟python虚拟机操作的是PyFrameObject对象,而PyFrameObject对象也是嵌套的,当然还有PyCodeObject内层的作用域是可以访问外层作用域的外层作用域无法访问内层作用域,尽管我们没有试,但是想都不用想,如果把外层的a=1给去掉,那么最后面的print(a)铁定报错。因为外部的作用域算是属于顶层了(先不考虑builtin)查找元素会依次从当前作用域向外查找,也就是查找元素对应的作用域是按照从小往大、从里往外的方向前进的,到了最外层还没有,就真没有了(先不考虑builtin)
LGB规则
我们说函数、类是有自己的作用域的,但是模块对应的源文件本身也有相应的作用域。比如:
# a.py
name = "夏色祭"
age = -1
def foo():
return 123
class A:
pass
由于这个文件本身也有自己的作用域(显然是global作用域),所以Python解释器在运行a.py这个文件的时候,也会为其创建一个名字空间,而显然这个名字空间就是global名字空间。它里面的变量是全局的,或者说是模块级别的,在当前的文件内可以直接访问。
而函数也会有一个作用域,这个作用域称为local作用域(对应local名字空间);同时Python自身还定义了一个最顶层的作用域,也就是builtin作用域(比如:dir、range、open都是builtin里面的)。这三个作用域在python2.2之前就存在了,所以那时候Python的作用域规则被称之为LGB规则:名字引用动作沿着local作用域(local名字空间)、global作用域(global名字空间)、builtin作用域(builtin名字空间)来查找对应的变量。
而获取名字空间,Python也提供了相应的内置函数:
locals函数: 获取当前作用域的local名字空间, local名字空间也称为局部名字空间globals函数: 获取当前作用域的global名字空间, global名字空间也称为全局名字空间
对于global名字空间来说,它对应一个字典,并且这个字典是全局唯一的,全局变量都存储在这里面。
name = "夏色祭"
age = -1
def foo():
name = "神乐mea"
age = 38
print(globals()) # {..., 'name': '夏色祭', 'age': -1, 'foo': <function foo at 0x0000020BF60851F0>}
里面的...表示省略了一部分输出,我们看到创建的全局变量都在里面了。而且foo也是一个变量,它指向一个函数对象,我们说foo也对应一个PyCodeObject。但是在解释到def foo的时候,便会根据这个PyCodeObject对象创建一个PyFunctionObject对象,然后将foo和这个函数对象绑定起来。当我们调用foo的时候,会根据PyFunctionObject对象再创建PyFrameObject对象、然后执行,这些留在介绍函数的时候再细说。总之,我们看到foo也是一个全局变量,全局变量都在global名字空间中。
global名字空间全局唯一,它是程序运行时全局变量和与之绑定的对象的容身之所,你在任何一个地方都可以访问到global名字空间。正如,你在任何一个地方都可以访问相应的全局变量一样。
此外,我们说名字空间是一个字典,变量和变量指向的值会以键值对的形式存在里面。那么换句话说,如果我手动的往这个global名字空间里面添加一个键值对,是不是也等价于定义一个全局变量呢?
globals()["name"] = "夏色祭"
print(name) # 夏色祭
def f1():
def f2():
def f3():
globals()["age"] = -1
return f3
return f2
f1()()()
print(age) # -1
我们看到确实如此,通过往global名字空间里面插入一个键值对完全等价于定义一个全局变量。并且我们看到global名字空间是全局唯一的,你在任何地方调用globals()得到的都是global名字空间,正如你在任意地方都可以访问到全局变量一样。所以即使是在函数中向global名字空间中插入一个键值对,也等价于定义一个全局变量、并和对象绑定起来。
name = "夏色祭"等价于 globals["name"] = "夏色祭"print(name)等价于print(globals["name"])
对于local名字空间来说,它也对应一个字典,显然这个字典是就不是全局唯一的了,每一个作用域都会对应自身的local名字空间。
def f():
name = "夏色祭"
age = -1
return locals()
def g():
name = "神乐mea"
age = 38
return locals()
print(locals() == globals()) # True
print(f()) # {'name': '夏色祭', 'age': -1}
print(g()) # {'name': '神乐mea', 'age': 38}
显然对于模块来讲,它的local名字空间和global名字空间是一样的,也就是说模块对应的PyFrameObject对象里面的f_locals和f_globals指向的是同一个PyDictObject对象。
但是对于函数而言,局部名字空间和全局名字空间就不一样了。而调用locals也是获取自身的局部名字空间,因此不同的函数的local名字空间是不同的,而调用locals函数返回结果显然取决于调用它的位置。但是globals函数的调用结果是一样的,获取的都是global名字空间,这也符合"函数内找不到某个变量的时候会去找全局变量"这一结论。
所以我们说在函数里面查找一个变量,查找不到的话会找全局变量,全局变量再没有会查找内置变量。本质上就是按照自身的local空间、外层的global空间、内置的builtin空间的顺序进行查找。因此local空间会有很多个,因为每一个函数或者类都有自己的局部作用域,这个局部作用域就可以称之为该函数的local空间;但是global空间则全局唯一,因为该字典存储的是全局变量,无论你在什么地方,通过globals拿到的永远全局变量对应的名字空间,向该空间中添加键值对,等价于创建全局变量。
对于builtin命名空间,它也是一个字典。当local空间、global空间都没有的时候,会去builtin空间查找。
name = "夏色祭"
age = -1
def f1():
name = "神乐mea"
# local空间有"name"这个key, 直接从局部名字空间获取
print(name)
# 但是当前的local空间没有"age"这个key, 所以会从global空间查找
# 从这里也能看出为什么函数也能访问到global空间了
# 如果函数内访问不到的话, 那么它怎么能够在局部变量找不到的时候去找全局变量呢
print(age)
# 但是local空间、global空间都没有"int"这个key, 所以要去builtin空间查找了
print(int)
# "xxx"的话, 三个空间都没有, 那么结果只能是NameError了
print(xxx)
f1()
"""
神乐mea
-1
<class 'int'>
...
File "D:/satori/1.py", line 18, in f1
print(xxx)
NameError: name 'xxx' is not defined
"""
问题来了,builtin名字空间如何获取呢?答案是通过builtins模块。
import builtins
# 我们调用int、str、list显然是从内置作用域、也就是builtin命名空间中查找的
# 即使我们只通过list也是可以的, 因为local空间、global空间没有的话, 最终会从builtin空间中查找,
# 但如果是builtins.list, 那么就不兜圈子了, 表示: "builtin空间,就从你这获取了"
print(builtins.list is list) # True
builtins.dict = 123
# 将builtin空间的dict改成123,那么此时获取的dict就是123,因为是从内置作用域中获取的
print(dict + 456) # 579
str = 123
# 如果是str = 123,等价于创建全局变量str = 123,显然影响的是global空间,而查找显然也会先从global空间查找
print(str) # 123
# 但是此时不影响内置作用域
print(builtins.str) # <class 'str'>
这里提一下Python2当中,while 1比while True要快,为什么?
因为True在Python2中不是关键字,所以它是可以作为变量名的,那么python在执行的时候就要先看local空间和global空间中有没有True这个变量,有的话使用我们定义的,没有的话再使用内置的True,而1是一个常量直接加载就可以。所以while True它多了符号查找这一过程,但是在Python3中两者就等价了,因为True在python3中是一个关键字,所以会直接作为一个常量来加载。
这里再提一下函数的local空间
我们说:globals["name"] = "夏色祭"等价于定义一个全局变量name = "夏色祭",那么如果是在函数里面执行了locals["name"] = "夏色祭",是不是等价于创建局部变量name = "夏色祭"呢?
def f1():
locals()["name "] = "夏色祭"
try:
print(name)
except Exception as e:
print(e)
f1() # name 'name' is not defined
我们说对于全局变量来讲,变量的创建是通过向字典添加键值对的方式实现的。因为全局变量会一直在变,需要使用字典来动态维护。但是对于函数来讲,内部的变量是通过静态方式访问的,因为其局部作用域中存在哪些变量在编译的时候就已经确定了,我们通过PyCodeObject的co_varnames即可获取内部都有哪些变量。
所以虽然我们说查找是按照LGB的方式查找,但是访问函数内部的变量其实是静态访问的,不过完全可以按照LGB的方式理解。
所以名字空间可以说是Python的灵魂,因为它规定了Python变量的作用域,使得Python对变量的查找变得非常清晰。
LEGB规则
我们上面说的LGB是针对Python2.2之前的,那么Python2.2开始,由于引入了嵌套函数,显然最好的方式应该是内层函数找不到应该首先去外层函数找,而不是直接就跑到global空间、也就是全局里面找,那么此时的规则就是LEGB。
a = 1
def foo():
a = 2
def bar():
print(a)
return bar
f = foo()
f()
"""
2
"""
调用f,实际上调用的是bar函数,最终输出的结果是2。如果按照LGB的规则来查找的话。bar函数的作用域没有a、那么应该到全局里面找,打印的应该是1才对。但是我们之前说了,作用域仅仅是由文本决定的,函数bar位于函数foo之内,所以bar函数定义的作用域内嵌与函数foo的作用域之内。换句话说,函数foo的作用域是函数bar的作用域的直接外围作用域,所以首先是从foo作用域里面找,如果没有那么再去全局里面找。而作用域和名字空间是对应的,所以最终打印了2。
因此在执行f = foo()的时候,会执行函数foo中的def bar():语句,这个时候Python会将a=2与函数bar对应的函数对象捆绑在一起,将捆绑之后的结果返回,这个捆绑起来的整体称之为闭包。
所以:闭包 = 内层函数 + 引用的外层作用域
这里显示的规则就是LEGB,其中E成为enclosing,代表直接外围作用域这个概念。
global表达式
有一个很奇怪的问题,最开始学习python的时候,笔者也为此困惑了一段时间,下面我们来看一下。
a = 1
def foo():
print(a)
foo()
"""
1
"""
首先这段代码打印1,这显然是没有问题的,但是下面问题来了。
a = 1
def foo():
print(a)
a = 2
foo()
"""
Traceback (most recent call last):
File "C:/Users/satori/Desktop/love_minami/a.py", line 8, in <module>
foo()
File "C:/Users/satori/Desktop/love_minami/a.py", line 5, in foo
print(a)
UnboundLocalError: local variable 'a' referenced before assignment
"""
这里我仅仅是在print下面,在当前作用域又新建了一个变量a,结果就告诉我局部变量a在赋值之前就被引用了,这是怎么一回事,相信肯定有人为此困惑。
弄明白这个错误的根本就在于要深刻理解两点:
一个赋值语句所定义的变量在这个赋值语句所在的作用域里都是可见的函数中的变量是静态存储、静态访问的, 内部有哪些变量在编译的时候就已经确定
在编译的时候,因为存在a = 2这条语句,所以知道函数中存在一个局部变量a,那么查找的时候就会在局部空间中查找。但是还没来得及赋值,就print(a)了,所以报错:局部变量a在赋值之前就被引用了。但如果没有a = 2这条语句则不会报错,因为知道局部作用域中不存在a这个变量,所以会找全局变量a,从而打印1。
更有趣的东西隐藏在字节码当中,我们可以通过反汇编来查看一下:
import dis
a = 1
def g():
print(a)
dis.dis(g)
"""
7 0 LOAD_GLOBAL 0 (print)
2 LOAD_GLOBAL 1 (a)
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
"""
def f():
print(a)
a = 2
dis.dis(f)
"""
12 0 LOAD_GLOBAL 0 (print)
2 LOAD_FAST 0 (a)
4 CALL_FUNCTION 1
6 POP_TOP
13 8 LOAD_CONST 1 (2)
10 STORE_FAST 0 (a)
12 LOAD_CONST 0 (None)
14 RETURN_VALUE
"""
中间的序号代表字节码的偏移量,我们看第二条,g的字节码是LOAD_GLOBAL,意思是在global名字空间中查找,而f的字节码是LOAD_FAST,表示在local名字空间中查找名字。这说明Python采用了静态作用域策略,在编译的时候就已经知道了名字藏身于何处。
因此上面的例子表明,一旦作用域有了对某个名字的赋值操作,这个名字就会在作用域中可见,就会出现在local名字空间中,换句话说,就遮蔽了外层作用域中相同的名字。
但有时我们想要在函数里面修改全局变量呢?当然Python也为我们精心准备了global关键字,比如函数内部出现了global a,就表示我后面的a是全局的,你要到global名字空间里面找,不要在local空间里面找了
a = 1
def bar():
def foo():
global a
a = 2
return foo
bar()()
print(a) # 2
但是如果外层函数里面也出现了a,我们想找外层函数里面的a而不是全局的a,该怎么办呢?Python同样为我们准备了关键字: nonlocal,但是nonlocal的时候,必须确保自己是内层函数。
a = 1
def bar():
a = 2
def foo():
nonlocal a
a = "xxx"
return foo
bar()()
print(a) # 1
# 外界依旧是1
属性引用与名称引用
属性引用实质上也是一种名称引用,其本质都是到名称空间中去查找一个名称所引用的对象。这个就比较简单了,比如a.xxx,就是到a里面去找xxx,这个规则是不受LEGB作用域限制的,就是到a里面查找,有就是有、没有就是没有。
这个比较简单,但是有一点我们需要注意,那就是我们说属性查找会按照LEGB的规则,但是仅仅限制在自身所在的模块内。举个栗子:
# a.py
print(name)
# b.py
name = "夏色祭"
import a
关于模块的导入我们后面系列中会详细说,总之目前在b.py里面执行的import a,你可以简单认为就是把a.py里面的内容拿过来执行一遍即可,所以这里相当于print(name)。
但是执行b.py的时候会提示变量name没有被定义,可是把a导进来的话,就相当于print(name),而我们上面也定义name这个变量了呀。显然,即使我们把a导入了进来,但是a.py里面的内容依旧是处于一个模块里面。而我们也说了,名称引用虽然是LEGB规则,但是无论如何都无法越过自身的模块的,print(name)是在a.py里面的,而变量name被定义在b.py中,所以是不可能跨过模块a的作用域去访问模块b里面的内容的。
所以模块整体也有一个作用域,就是该模块的全局作用域,每个模块是相互独立的。所以我们发现每个模块之间作用域还是划分的很清晰的,都是相互独立的。
关于模块,我们后续会详细说。总之通过.的方式本质上都是去指定的命名空间中查找对应的属性。
属性空间
我们知道,自定义的类中如果没有__slots__,那么这个类的实例对象都会有一个属性字典。
class Girl:
def __init__(self):
self.name = "夏色祭"
self.age = -1
g = Girl()
print(g.__dict__) # {'name': '夏色祭', 'age': -1}
# 对于查找属性而言, 也是去属性字典中查找
print(g.name, g.__dict__["name"])
# 同理设置属性, 也是更改对应的属性字典
g.__dict__["gender"] = "female"
print(g.gender) # female
当然模块也有属性字典,属性查找方面,本质上和上面的类的实例对象是一致的。
import builtins
print(builtins.str) # <class 'str'>
print(builtins.__dict__["str"]) # <class 'str'>
另外global空间里面是保存了builtin空间的指针的:
# globals()["__builtins__"]直接等价于import builtins
print(globals()["__builtins__"]) # <module 'builtins' (built-in)>
import builtins
print(builtins) # <module 'builtins' (built-in)>
# 但我们说globals函数是在什么地方呢? 显然是在builtin空间中
# 所以
print(globals()["__builtins__"].globals()["__builtins__"].
globals()["__builtins__"].globals()["__builtins__"].
globals()["__builtins__"].globals()["__builtins__"]) # <module 'builtins' (built-in)>
print(globals()["__builtins__"].globals()["__builtins__"].
globals()["__builtins__"].globals()["__builtins__"].
globals()["__builtins__"].globals()["__builtins__"].list("abc")) # ['a', 'b', 'c']
小结
在 Python 中,一个名字(变量)可见范围由 "作用域" 决定,而作用域由语法静态划分,划分规则提炼如下:
.py文件(模块)最外层为全局作用域遇到函数定义,函数体形成子作用域遇到类定义,类定义体形成子作用域名字仅在其作用域以内可见全局作用域对其他所有作用域可见函数作用域对其直接子作用域可见,并且可以传递(闭包)
与"作用域"相对应, Python 在运行时借助 PyDictObject 对象保存作用域中的名字,构成动态的"名字空间" 。这样的名字空间总共有 4 个:
局部名字空间(local): 不同的函数,局部名字空间不同全局名字空间(global): 全局唯一闭包名字空间(enclosing)内建名字空间(builtin)在查找名字时会按照LEGB规则查找, 但是注意: 无法跨越文件本身。就是按照自身文件的LEGB, 如果属性查找都找到builtin空间了, 那么证明这已经是最后的倔强。如果builtin空间再找不到, 那么就只能报错了, 不可能跑到其它文件中找
python虚拟机的运行框架
当Python启动后,首先会进行运行时环境的初始化。注意这里的运行时环境,它和上面说的执行环境是不同的概念。运行时环境是一个全局的概念,而执行时环境是一个栈帧,是一个与某个code block相对应的概念。现在不清楚两者的区别不要紧,后面会详细介绍。关于运行时环境的初始化是一个非常复杂的过程,我们后面将用单独的一章进行剖析,这里就假设初始化动作已经完成,我们已经站在了Python虚拟机的门槛外面,只需要轻轻推动一下第一张骨牌,整个执行过程就像多米诺骨牌一样,一环扣一环地展开。
首先Python虚拟机执行PyCodeObject对象中字节码的代码为Python/ceval.c中,主要函数有两个:PyEval_EvalCodeEx 是通用接口,一般用于函数这样带参数的执行场景; PyEval_EvalCode 是更高层封装,用于模块等无参数的执行场景。
PyObject *
PyEval_EvalCode(PyObject *co, PyObject *globals, PyObject *locals);
PyObject *
PyEval_EvalCodeEx(PyObject *_co, PyObject *globals, PyObject *locals,
PyObject *const *args, int argcount,
PyObject *const *kws, int kwcount,
PyObject *const *defs, int defcount,
PyObject *kwdefs, PyObject *closure);
这两个函数最终调用 _PyEval_EvalCodeWithName 函数,初始化栈帧对象并调用PyEval_EvalFrame 和PyEval_EvalFrameEx函数进行处理。栈帧对象将贯穿代码对象执行的始终,负责维护执行时所需的一切上下文信息。而PyEval_EvalFrame 和PyEval_EvalFrameEx函数最终调用 _PyEval_EvalFrameDefault 函数,虚拟机执行的秘密就藏在这里。
PyObject *
PyEval_EvalFrame(PyFrameObject *f);
PyObject *
PyEval_EvalFrameEx(PyFrameObject *f, int throwflag)
PyObject* _Py_HOT_FUNCTION
_PyEval_EvalFrameDefault(PyFrameObject *f, int throwflag);
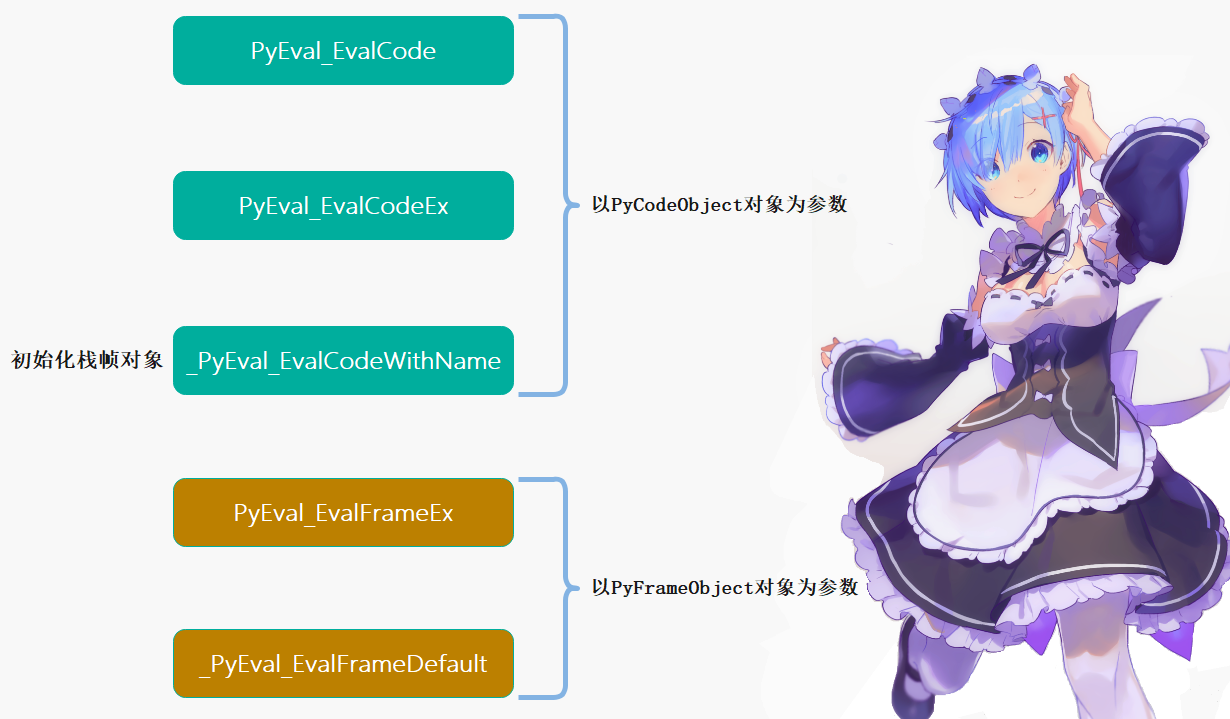
_PyEval_EvalFrameDefault函数是虚拟机运行的核心,这一个函数加上注释大概在3100行左右。可以说代码量非常大,但是逻辑并不难理解。
PyObject* _Py_HOT_FUNCTION
_PyEval_EvalFrameDefault(PyFrameObject *f, int throwflag)
{
/*
该函数首先会初始化一些变量,PyFrameObject对象中的PyCodeObject对象包含的信息不用说,还有一个重要的动作就是初始化堆栈的栈顶指针,使其指向f->f_stacktop
*/
//......
co = f->f_code;
names = co->co_names;
consts = co->co_consts;
fastlocals = f->f_localsplus;
freevars = f->f_localsplus + co->co_nlocals;
next_instr = first_instr;
if (f->f_lasti >= 0) {
assert(f->f_lasti % sizeof(_Py_CODEUNIT) == 0);
next_instr += f->f_lasti / sizeof(_Py_CODEUNIT) + 1;
}
stack_pointer = f->f_stacktop;
assert(stack_pointer != NULL);
f->f_stacktop = NULL;
//......
}
/*
PyFrameObject对象中的f_code就是PyCodeObject对象,而PyCodeObject对象里面的co_code域则保存着字节码指令和字节码指令参数
python执行字节码指令序列的过程就是从头到尾遍历整个co_code、依次执行字节码指令的过程。在Python的虚拟机中,利用三个变量来完成整个遍历过程。
首先co_code本质上是一个PyBytesObject对象,而其中的字符数组才是真正有意义的东西。也就是说整个字节码指令序列就是c中一个普普通通的数组。
因此遍历的过程使用的3个变量都是char *类型的变量
1.first_instr:永远指向字节码指令序列的开始位置
2.next_instr:永远指向下一条待执行的字节码指令的位置
3.f_lasti:指向上一条已经执行过的字节码指令的位置
*/
那么这个一步一步的动作是如何完成的呢?其实就是一个for循环加上一个巨大的switch case结构。
PyObject* _Py_HOT_FUNCTION
_PyEval_EvalFrameDefault(PyFrameObject *f, int throwflag)
{
//......
co = f->f_code;
names = co->co_names;
consts = co->co_consts;
fastlocals = f->f_localsplus;
freevars = f->f_localsplus + co->co_nlocals;
//......
// 逐条取出字节码来执行
for (;;) {
if (_Py_atomic_load_relaxed(eval_breaker)) {
// 读取下条字节码
// 字节码位于: f->f_code->co_code, 偏移量由 f->f_lasti 决定
opcode = _Py_OPCODE(*next_instr);
//opcode是指令,我们说Python在Include/opcode.h中定义了121个指令
if (opcode == SETUP_FINALLY ||
opcode == SETUP_WITH ||
opcode == BEFORE_ASYNC_WITH ||
opcode == YIELD_FROM) {
goto fast_next_opcode;
}
fast_next_opcode:
//......
//判断该指令属于什么操作,然后执行相应的逻辑
switch (opcode) {
// 加载常量
case LOAD_CONST:
// ....
break;
// 加载名字
case LOAD_NAME:
// ...
break;
// ...
}
}
}
在这个执行架构中,对字节码一步一步的遍历是通过几个宏来实现的:
#define INSTR_OFFSET() \
(sizeof(_Py_CODEUNIT) * (int)(next_instr - first_instr))
#define NEXTOPARG() do { \
_Py_CODEUNIT word = *next_instr; \
opcode = _Py_OPCODE(word); \
oparg = _Py_OPARG(word); \
next_instr++; \
} while (0)
Python的字节码有的是带有参数的,有的是没有参数的,而判断字节码是否带有参数是通过HAS_AGR这个宏来实现的。注意:对于不同的字节码指令,由于存在是否需要指令参数的区别,所以next_instr的位移可以是不同的,但无论如何,next_instr总是指向python下一条要执行的字节码。
Python在获得了一条字节码指令和其需要的参数指令之后,会对字节码利用switch进行判断,根据判断的结果选择不同的case语句,每一条指令都会对应一个case语句。在case语句中,就是Python对字节码指令的实现。所以这个switch语句非常的长,函数总共3000行左右,这个switch就占了2400行,因为指令有121个,比如:LOAD_CONST、LOAD_NAME、YIELD_FROM等等,而每一个指令都要对应一个case语句。
在成功执行完一条字节码指令和其需要的指令参数之后,Python的执行流程会跳转到fast_next_opcode处,或者for循环处。不管如何,Python接下来的动作就是获取下一条字节码指令和指令参数,完成对下一条指令的执行。通过for循环一条一条地遍历co_code中包含的所有字节码指令,然后交给for循环里面的switch语句,如此周而复始,最终完成了对Python程序的执行。
尽管只是简单的分析,但是相信大家也能了解Python执行引擎的大体框架,在Python的执行流程进入了那个巨大的for循环,取出第一条字节码交给里面的switch语句之后,第一张多米诺骨牌就已经被推倒,命运不可阻挡的降临了。一条接一条的字节码像潮水一样涌来,浩浩荡荡,横无际涯。
我们这里通过反编译的方式演示一下
指令分为很多种,我们这里就以简单的顺序执行为例,不涉及任何的跳转指令,看看Python是如何执行字节码的。
pi = 3.14
r = 3
area = pi * r ** 2
对它们反编译之后,得到的字节码指令如下:
1 0 LOAD_CONST 0 (3.14)
2 STORE_NAME 0 (pi)
2 4 LOAD_CONST 1 (3)
6 STORE_NAME 1 (r)
3 8 LOAD_NAME 0 (pi)
10 LOAD_NAME 1 (r)
12 LOAD_CONST 2 (2)
14 BINARY_POWER
16 BINARY_MULTIPLY
18 STORE_NAME 2 (area)
20 LOAD_CONST 3 (None)
22 RETURN_VALUE
第一列是源代码的行号,第二列是指令的偏移量(或者说指令对应的索引),第三列是指令(或者操作码, 它们在宏定义中代表整数),第四列表示指令参数(或者操作数)。
- 0 LOAD_CONST: 表示加载一个常量
(压入"运行时栈"),后面的0 (3.14)表示从常量池中加载索引为0的对象,3.14表示加载的对象是3.14(所以最后面的括号里面的内容实际上起到的是一个提示作用,告诉你加载的对象是什么)。 - 2 STORE_NAME: 表示将LOAD_CONST得到的对象用一个名字存储、或者绑定起来。0 (pi)表示使用符号表
(co_varnames)中索引为0的名字(符号),且名字为"pi"。 - 4 LOAD_CONST和6 STORE_NAME显然和上面是一样的,只不过后面的索引变成了1,表示加载常量池中索引为1的对象、符号表中索引为1的符号
(名字)。另外从这里我们也能看出,一行赋值语句实际上对应两条字节码(加载常量、与名字绑定)。 - 8 LOAD_NAME表示加载符号表中pi对应的值,10 LOAD_NAME表示加载符号表中r对应的值,12 LOAD_CONST表示加载2这个常量
2 (2)表示常量池中索引为2的对象是2。 - 14 BINARY_POWER表示进行幂运算,16 BINARY_MULTIPLY表示进行乘法运算,18 STORE_NAME表示用符号表中索引为2的符号
(area)存储上一步计算的结果,20 LOAD_CONST表示将None加载进来,22 RETURN_VALUE将None返回。虽然它不是在函数里面,但也是有这一步的。
我们通过几张图展示一下上面的过程:
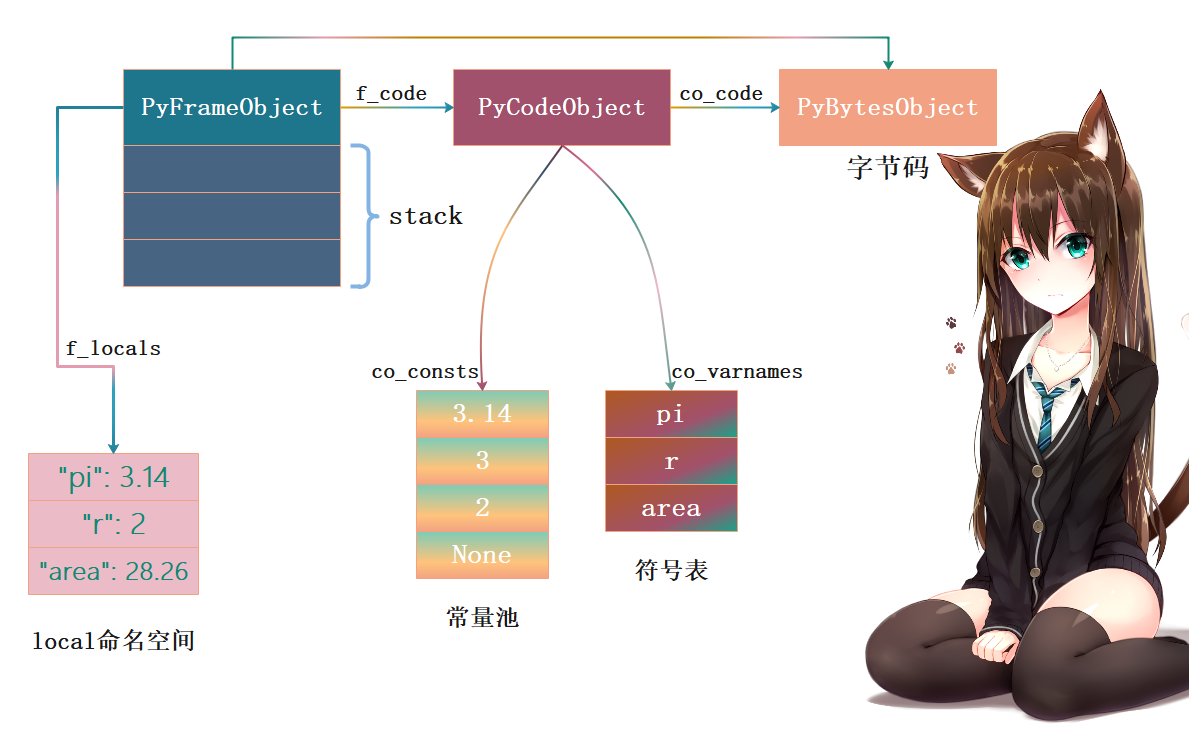
Python 虚拟机刚开始执行时,准备好栈帧对象用于保存执行上下文,关系如下(省略部分信息)。另外,图中有地方画错了,图中的co_varnames应该改成co_names。我们说对于函数来说是通过co_varnames获取符号表(local空间里面局部变量的存储位置,一个静态数组),因为函数有哪些局部变量在编译时已经确定,会静态存储在符号表co_varnames中。但我们这里是对模块进行反编译、不是函数,而模块的符号是全局的,local空间和global空间是同一个,使用字典来维护,所以它的co_varnames是一个空元组。但co_names是可以获取到所有的符号的,因此这里把co_names理解为符号表即可,但我们知道全局变量是存在字典里面的。
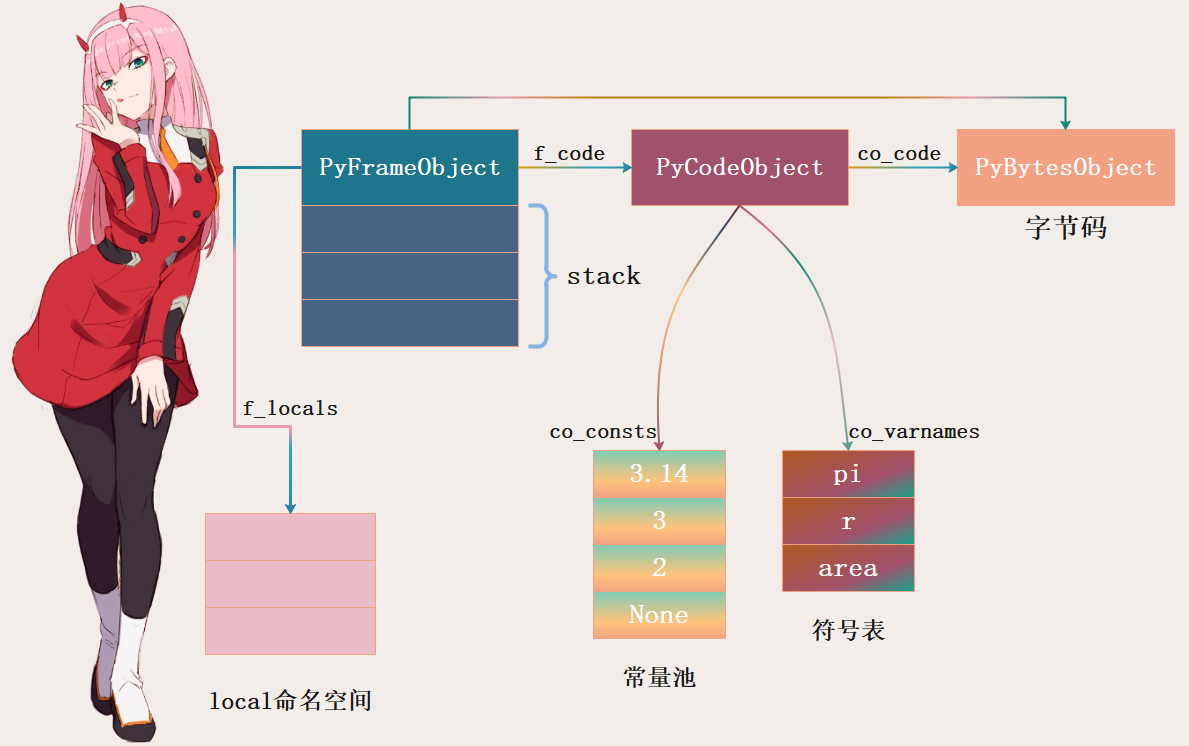
由于 next_instr 初始状态指向字节码开头,虚拟机开始加载第一条字节码指令: 0 LOAD_CONST 0 (3.14) 。字节码分为两部分,分别是 操作码 ( opcode )和 操作数 ( oparg ) 。LOAD_CONST 指令表示将常量加载进运行时栈,常量下标由操作数给出。LOAD_CONST 指令在 _PyEval_EvalFrameDefault 函数 switch 结构的一个 case 分支中实现:
TARGET(LOAD_CONST) {
//通过GETITEM从consts(常量池)中加载索引为oparg的对象(常量)
//所以0 LOAD_CONST 0 (3.14)分别表示:
//字节码指令的偏移量、操作码、对象在常量池中的索引(即这里的oparg)、对象的值(对象的值、或者说常量的值其实是dis模块帮你解析出来的)
PyObject *value = GETITEM(consts, oparg);
//增加引用计数
Py_INCREF(value);
//压入运行时栈, 这个运行时栈是位于栈帧对象尾部, 我们一会儿会说
PUSH(value);
FAST_DISPATCH();
}
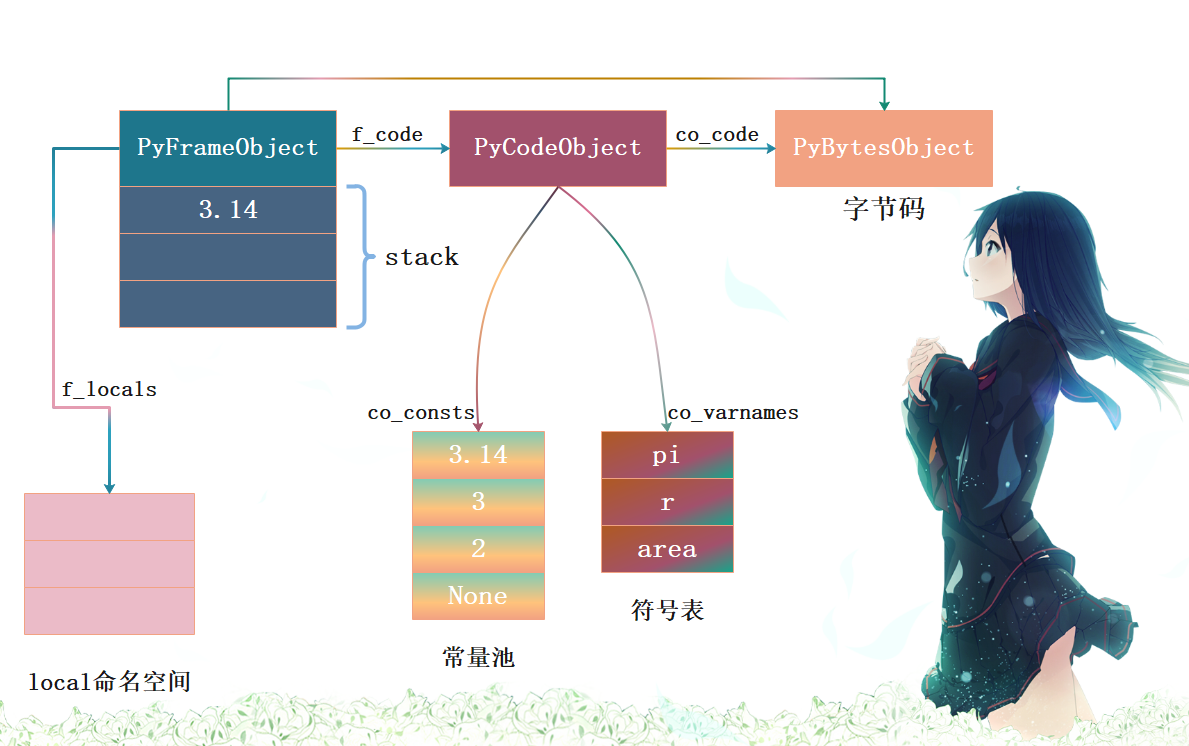
接着虚拟机接着执行 2 STORE_NAME 0 (pi) 指令,从符号表中获取索引为0的符号、即pi,然后将栈顶元素3.14弹出,再把符号"pi"和整数对象3.14绑定起来保存到local名字空间
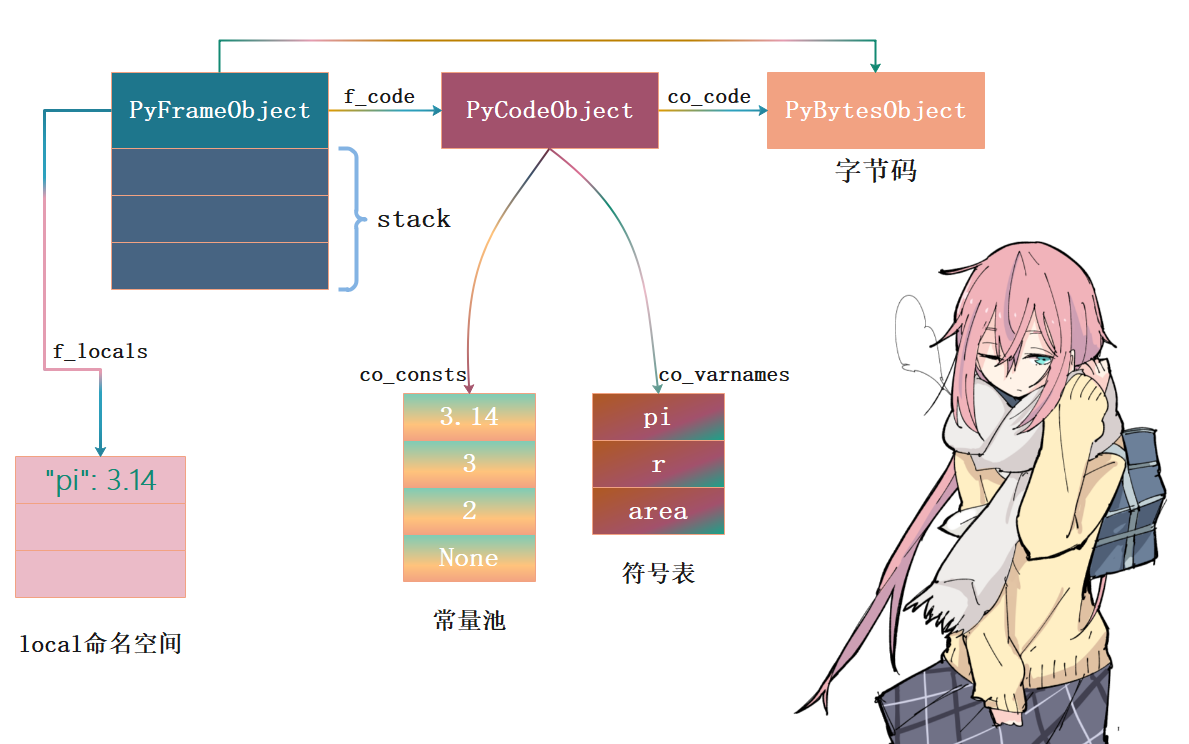
case TARGET(STORE_NAME): {
//从符号表中加载索引为oparg的符号
PyObject *name = GETITEM(names, oparg);
//从栈顶弹出元素
PyObject *v = POP();
//获取名字空间namespace
PyObject *ns = f->f_locals;
int err;
if (ns == NULL) {
//如果没有名字空间则报错, 这个tstate是和线程密切相关的, 我们后面会说
_PyErr_Format(tstate, PyExc_SystemError,
"no locals found when storing %R", name);
Py_DECREF(v);
goto error;
}
//将符号和对象绑定起来放在ns中
if (PyDict_CheckExact(ns))
err = PyDict_SetItem(ns, name, v);
else
err = PyObject_SetItem(ns, name, v);
Py_DECREF(v);
if (err != 0)
goto error;
DISPATCH();
}
你可能会问,变量赋值为啥不直接通过名字空间,而是到临时栈绕一圈?主要原因在于: Python 字节码只有一个操作数,另一个操作数只能通过临时栈给出。 Python 字节码设计思想跟 CPU精简指令集类似,指令尽量简化,复杂指令由多条指令组合完成。
同理,r = 2对应的两条指令也是类似的。
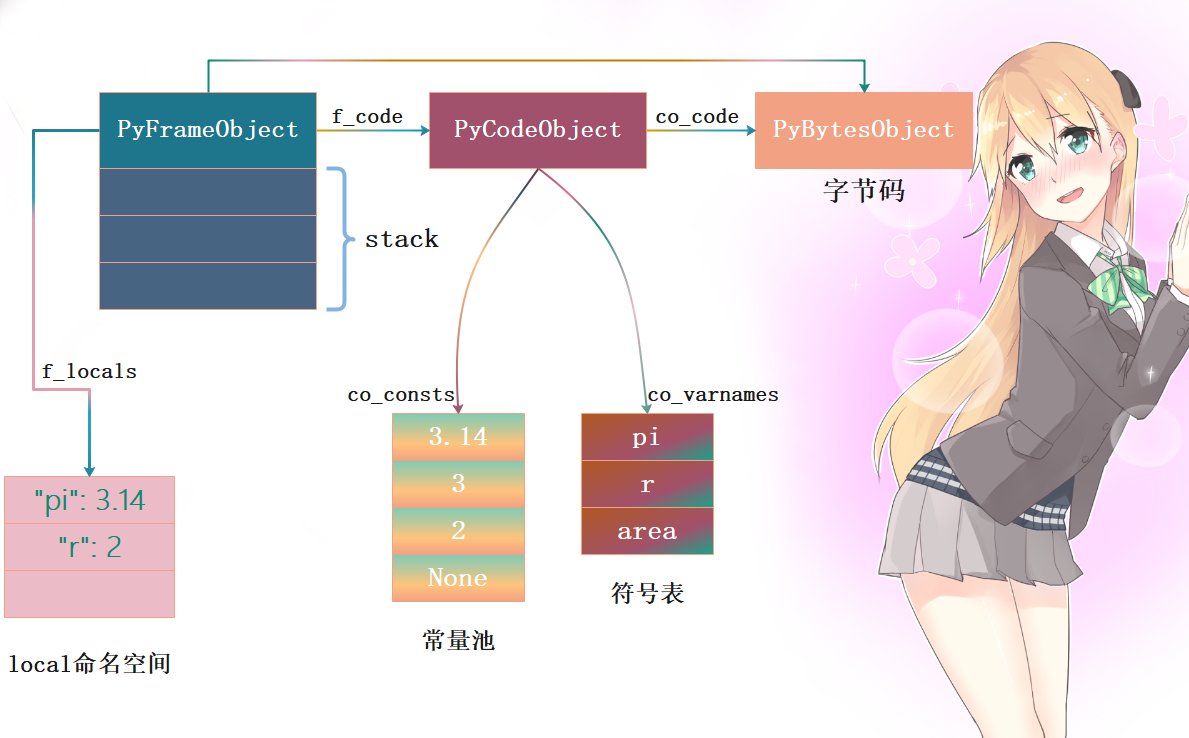
然后8 LOAD_NAME 0 (pi)、10 LOAD_NAME 1 (r)、12 LOAD_CONST 2 (2),表示将符号pi指向的值、符号r指向的值、常量2压入运行时栈。
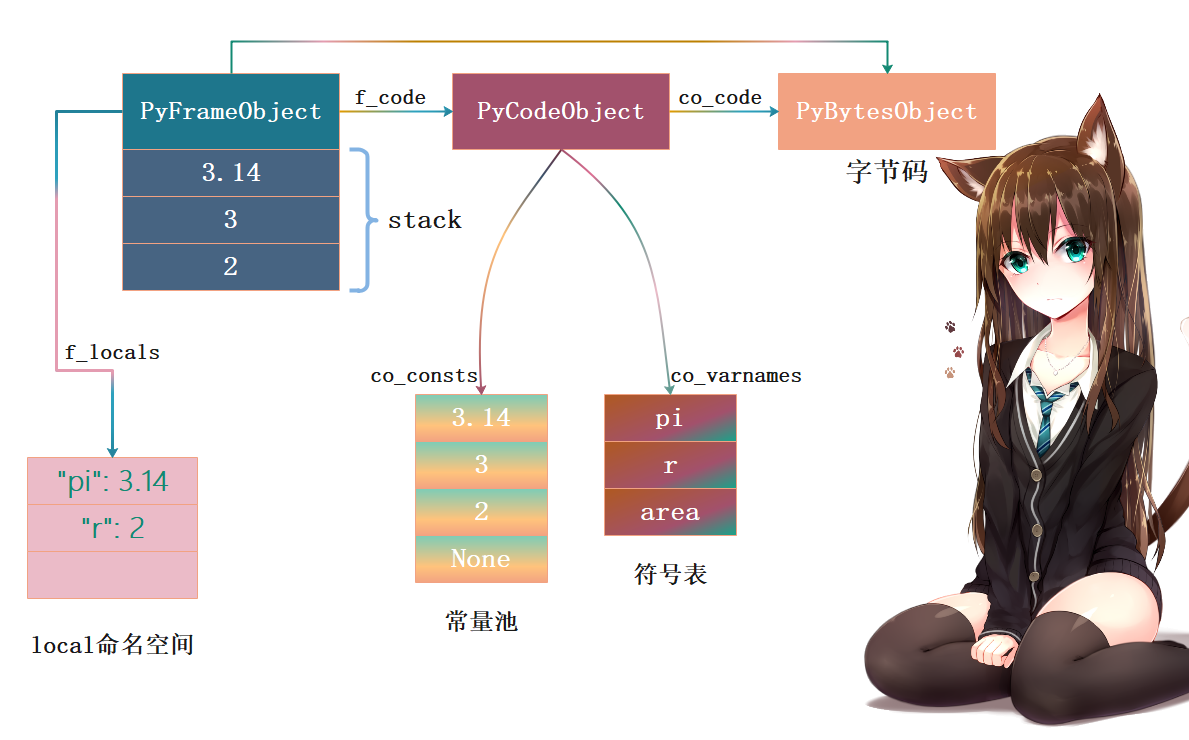
然后14 BINARY_POWER表示进行幂运算,16 BINARY_MULTIPLY表示进行乘法运算。
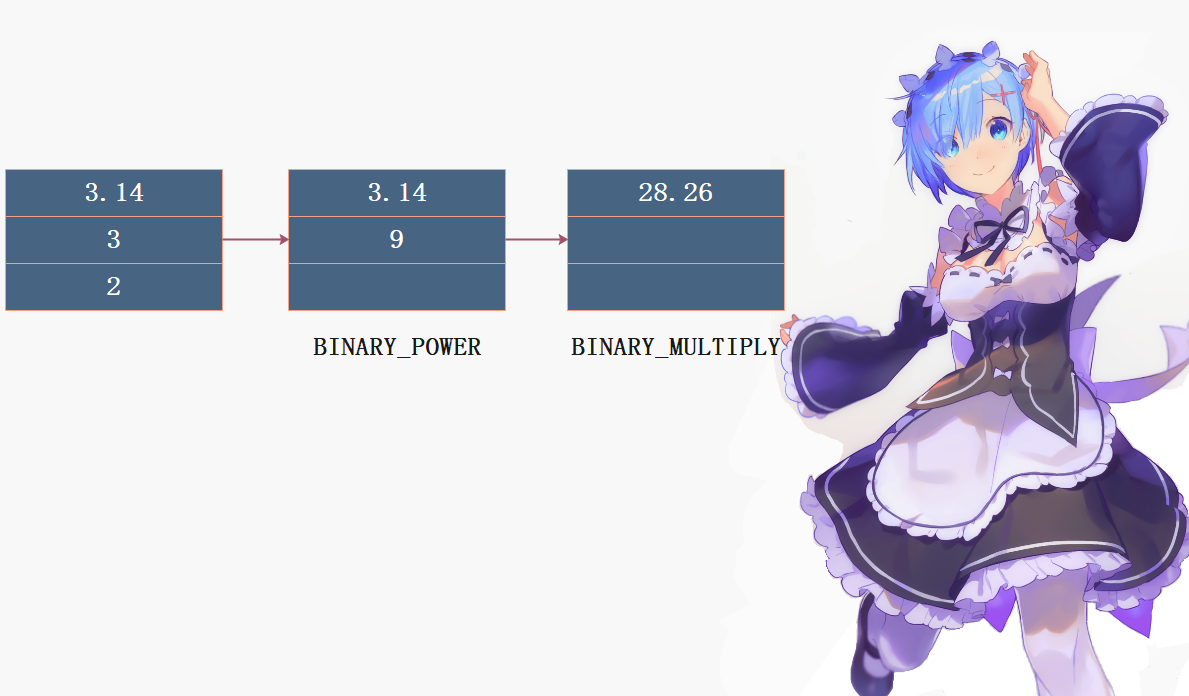
其中, BINARY_POWER 指令会从栈上弹出两个操作数(底数 3 和 指数 2 )进行 幂运算,并将结果 9 压回栈中; BINARY_MULTIPLY 指令则进行乘积运算 ,步骤也是类似的。
case TARGET(BINARY_POWER): {
//从栈顶弹出元素, 这里是指数2
PyObject *exp = POP();
//我们看到这个是TOP, 所以其实它不是弹出底数3, 而是获取底数3, 所以3这个元素依旧在栈里面
PyObject *base = TOP();
//进行幂运算
PyObject *res = PyNumber_Power(base, exp, Py_None);
Py_DECREF(base);
Py_DECREF(exp);
//将幂运算的结果再设置回去, 所以原来的3被计算之后的9给替换掉了
SET_TOP(res);
if (res == NULL)
goto error;
DISPATCH();
}
case TARGET(BINARY_MULTIPLY): {
//同理这里也是弹出元素9
PyObject *right = POP();
//获取元素3.14
PyObject *left = TOP();
//乘法运算
PyObject *res = PyNumber_Multiply(left, right);
Py_DECREF(left);
Py_DECREF(right);
//将运算的结果28.26将原来的3.14给替换掉
SET_TOP(res);
if (res == NULL)
goto error;
DISPATCH();
}
最终执行指令18 STORE_NAME 2 (area),会从符号表中加载索引为2的符号、即area,再将"area"和浮点数28.26绑定起来放到名字空间中。
整体的执行流程便如上面几张图所示,当然字节码指令有很多,我们说它们定义在Include/opcode.h中,有121个。比如:除了LOAD_CONST、STORE_NAME之外,还有LOAD_FAST、LOAD_GLOBAL、STORE_FAST,以及if语句、循环语句所使用的跳转指令,运算使用的指令等等等等,这些在后面的系列中会慢慢遇到。
PyFrameObject中的动态内存空间
上面我们提到了一个运行时栈,我们说加载常量的时候会将常量(对象)从常量池中获取、并压入运行时栈,当计算或者使用变量保存的时候,会将其从栈里面弹出来。那么这个运行时栈所需要的空间都保存在什么地方呢?
PyFrameObject中有这么一个属性f_localsplus(可以回头看一下PyFrameObject的定义),我们说它是动态内存,用于"维护局部变量+cell对象集合+free对象集合+运行时栈所需要的空间",因此可以看出这段内存不仅仅使用来给栈使用的,还有别的对象使用。
PyFrameObject*
PyFrame_New(PyThreadState *tstate, PyCodeObject *code,
PyObject *globals, PyObject *locals)
{
//本质上调用了_PyFrame_New_NoTrack
PyFrameObject *f = _PyFrame_New_NoTrack(tstate, code, globals, locals);
if (f)
_PyObject_GC_TRACK(f);
return f;
}
PyFrameObject* _Py_HOT_FUNCTION
_PyFrame_New_NoTrack(PyThreadState *tstate, PyCodeObject *code,
PyObject *globals, PyObject *locals)
{
//上一级的栈帧, PyThreadState指的是线程对象
PyFrameObject *back = tstate->frame;
//当前的栈帧
PyFrameObject *f;
//builtin
PyObject *builtins;
/*
...
...
...
...
*/
else {
Py_ssize_t extras, ncells, nfrees;
ncells = PyTuple_GET_SIZE(code->co_cellvars);
nfrees = PyTuple_GET_SIZE(code->co_freevars);
//这四部分便构成了PyFrameObject维护的动态内存区,其大小由extras确定
extras = code->co_stacksize + code->co_nlocals + ncells +
nfrees;
/*
...
...
...
...
*/
f->f_code = code;
//计算初始化运行时,栈的栈顶,所以没有加上stacksize
extras = code->co_nlocals + ncells + nfrees;
//f_valuestack维护运行时栈的栈底
f->f_valuestack = f->f_localsplus + extras;
for (i=0; i<extras; i++)
f->f_localsplus[i] = NULL;
f->f_locals = NULL;
f->f_trace = NULL;
}
//f_stacktopk维护运行时栈的栈顶
f->f_stacktop = f->f_valuestack;
f->f_builtins = builtins;
Py_XINCREF(back);
f->f_back = back;
Py_INCREF(code);
Py_INCREF(globals);
f->f_globals = globals;
/* Most functions have CO_NEWLOCALS and CO_OPTIMIZED set. */
if ((code->co_flags & (CO_NEWLOCALS | CO_OPTIMIZED)) ==
(CO_NEWLOCALS | CO_OPTIMIZED))
; /* f_locals = NULL; will be set by PyFrame_FastToLocals() */
else if (code->co_flags & CO_NEWLOCALS) {
locals = PyDict_New();
if (locals == NULL) {
Py_DECREF(f);
return NULL;
}
f->f_locals = locals;
}
else {
if (locals == NULL)
locals = globals;
Py_INCREF(locals);
f->f_locals = locals;
}
//设置一些其他属性,返回返回该栈帧
f->f_lasti = -1;
f->f_lineno = code->co_firstlineno;
f->f_iblock = 0;
f->f_executing = 0;
f->f_gen = NULL;
f->f_trace_opcodes = 0;
f->f_trace_lines = 1;
return f;
}
可以看到,在创建PyFrameObject对象时,额外申请的"运行时栈"对应的空间并不完全是给运行时栈使用的,有一部分是给"PyCodeObject对象中存储的那些局部变量"、"co_freevars"、"co_cellvars"(co_freevars、co_cellvars是与闭包有关的内容,后面章节会剖析)使用的,而剩下的才是给真正运行时栈使用的。
并且这段连续的空间是由四部分组成,并且顺序是"局部变量"、"Cell对象"、"Free对象"、"运行时栈"。
小结
这次我们深入了 Python 虚拟机源码,研究虚拟机执行字节码的全过程。虚拟机在执行PyCodeObject对象里面的字节码之前,需要先根据PyCodeObject对象创建栈帧对象 ( PyFrameObject ),用于维护运行时的上下文信息。然后在PyFrameObject的基础上,执行字节码。
PyFrameObject 关键信息包括:
f_locals: 局部名字空间f_globals: 全局名字空间f_builtins: 内建名字空间f_code: PyCodeObject对象f_lasti: 上条已执行指令的编号, 或者说偏移量、索引都可以f_back: 该栈帧的上一级栈帧、即调用者栈帧f_localsplus: 局部变量 + co_freevars + co_cellvars + 运行时栈, 这四部分需要的空间
栈帧对象通过 f_back 串成一个"栈帧调用链",与 CPU 栈帧调用链有异曲同工之妙。我们还借助 inspect 模块成功取得栈帧对象(底层是通过sys模块),并在此基础上输出整个函数调用链。
Python虚拟机的代码量不小,但是核心并不难理解,主要是_PyEval_EvalFrameDefault里面的一个巨大的for循环,准确的说for循环里面的那个巨型switch语句。其中的switch语句,case了每一个操作指令,当出现什么指令就执行什么操作。
另外我们提到运行时环境,这个运行时环境非常复杂,因为Python启动是要创建一个主进程、在进程内创建一个主线程的。所以还涉及到了进程和线程的初始化,在后面的系列中我们会详细说,包括GIL的问题。这里我们就先假设运行时环境已经初始化好了,我们直接关注虚拟机执行字节码的流程即可。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号