17. Redis哨兵模式
楔子
之前我们了解了 Redis 主从节点集群模式,在这个模式下,如果从节点发生故障了,客户端可以继续向主节点或其他从节点发送请求,进行相关的操作。但如果是主节点发生故障了,那么显然会直接影响到从节点的同步,因为从节点没有相应的主节点可以进行数据复制操作了。
而且,如果客户端发送的都是读操作请求,那还可以由从节点继续提供服务,这在纯读的业务场景下还能被接受。但是一旦有写操作请求,那么按照主从节点模式下的读写分离要求,需要由主节点来完成写操作,而主节点挂掉了,那么显然就没有实例可以来服务客户端了,如下图所示:
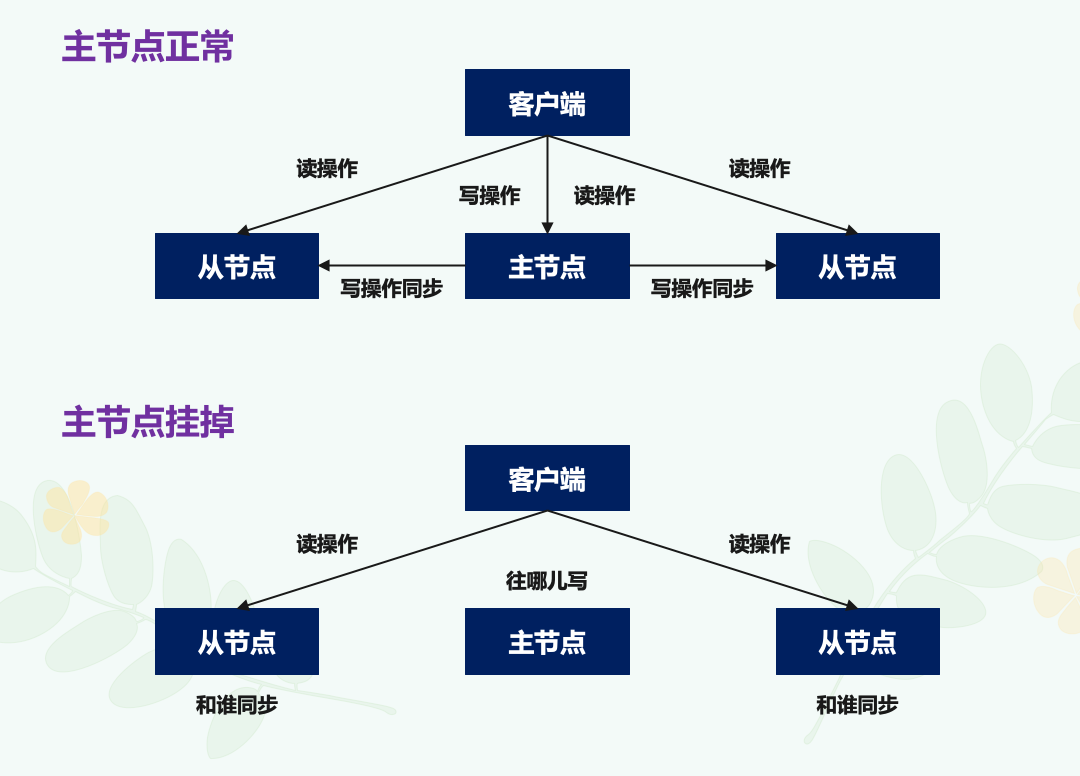
无论是写服务中断,还是从节点无法进行数据同步,都是不能接受的。所以如果主节点挂了,我们就需要设置一个新的主节点,比如说把一个从节点切换为主节点,但这就涉及到三个问题:
1. 主节点真的挂了吗?;2. 该选择哪个从节点作为新主节点?;3. 怎么把新主节点的相关信息通知给从节点和客户端呢?;
首先最笨的解决办法就是 "人工智能",手动选择一个节点作为主节点,然后将剩余节点设置为该节点的从节点,然后进行数据同步。虽然这是一种解决问题的方式,但很明显,这如果是发生在晚上或者从服务器节点很多的情况下,对于人工来说想要立即实现恢复的难度会很大,所以我们需要一个工具来把手动的过程变成自动的,让 Redis 拥有自动容灾恢复(failover)的能力。
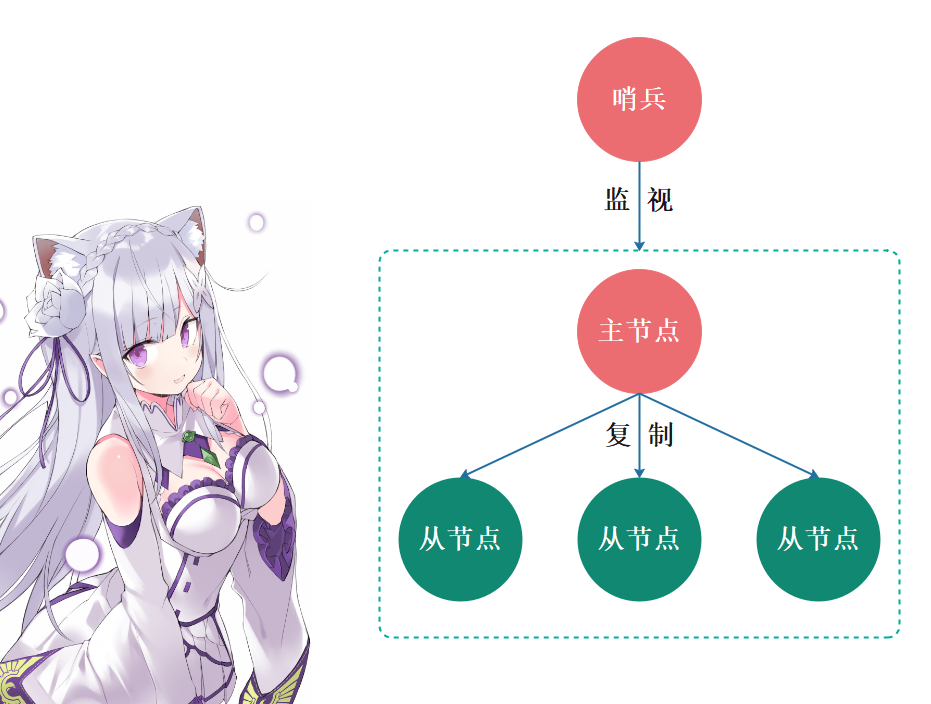
而该工具就是 Redis 提供的哨兵机制,哨兵可以监控整个 Redis 集群,并在主节点挂了之后,自动在剩余的从节点中选择一个成为新的主节点,然后将其余的从节点作为新选出的主节点的从节点。因此该机制有效解决了上面的三个问题。
下面我们就来了解一下哨兵机制。
哨兵机制基本流程
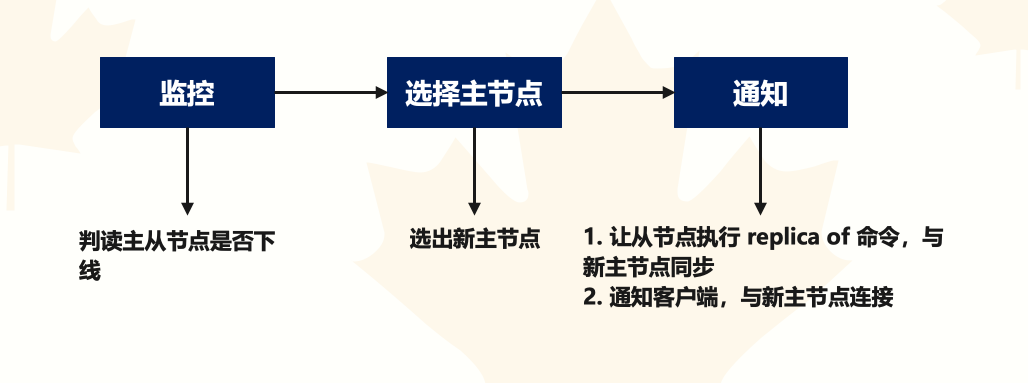
哨兵其实就是一个运行在特殊模式下的 Redis 进程,主从节点实例运行的同时,它也在运行。哨兵主要负责的就是三个任务:监控、选择主节点、通知。
- 监控:指哨兵进程在运行时,会周期性地给所有的主从节点发送 PING 命令,检测它们是否仍然在线运行。如果从节点没有在规定时间内响应哨兵的 PING 命令,哨兵就会把它标记为 "下线状态";同样,如果主节点也没有在规定时间内响应哨兵的 PING 命令,哨兵就会判定主节点下线,然后开始自动选择新的主节点。
- 选择主节点:主节点挂了以后,哨兵就需要从很多个从节点里,按照一定的规则选择一个从节点实例,把它作为新的主节点。这一步完成后,现在的集群里就有了新的主节点。
- 通知:在执行通知任务时,哨兵会把新主节点的连接信息发给其他从节点,让它们执行 replicaof 命令,和新主节点建立连接,并进行数据复制。同时,哨兵会把新主节点的连接信息通知给客户端,让它们把请求操作发到新主节点上。
所以我们看到哨兵所做的事情非常简单,如果没有哨兵,我们手工的话也是会采用这种做法,只不过哨兵将这一切自动化了。
在这三个任务中,通知任务相对来说比较简单,哨兵只需要把新主节点信息发给从节点和客户端,让它们和新主节点建立连接就行,并不涉及决策的逻辑。但是在监控和选择主节点这两个任务中则不一样,哨兵需要做出两个决策:
1. 在监控任务中,哨兵需要判断主节点是否处于下线状态;2. 在选择主节点任务中,哨兵也要决定选择哪个从节点实例作为主节点;
接下来,我们就先说说如何判断主节点的下线状态。
首先我们需要知道的是,哨兵对主节点的下线判断有 "主观下线" 和 "客观下线" 两种,但问题是为什么会存在两种判断呢?它们的区别和联系是什么呢?
主观下线和客观下线
先解释下什么是主观下线。
哨兵进程会使用 PING 命令检测它自己和主、从节点的网络连接情况,用来判断实例的状态。如果哨兵发现主、从节点对 PING 命令的响应超时了,那么哨兵就会先把它标记为 "主观下线",而从节点一旦被标记为主观下线,那么就真的下线了,会被踢出集群,因为从节点下线对集群的影响不大,集群的对外服务不会间断;但是,如果检测的是主节点,那么哨兵把它标记为 "主观下线" 之后,还不能贸然将主节点踢出集群、开启主从切换。因为很有可能存在这么一个情况:那就是哨兵误判了,其实主节点并没有故障,如果此时就立刻启动主从切换,后续的选则新主节点和通知操作都会带来额外的计算和通信开销。
注意:一个有效的 PING 响应可以是:+PONG、-LOADING 或者 -MASTERDOWN。如果返回值非以上三种,或者在指定时间内没有响应 PING 命令, 那么哨兵认为服务器返回的回复无效(non-valid)。
为了避免这些不必要的开销,我们要特别注意误判的情况,但首先我们要知道啥叫误判。很简单,就是主节点实际并没有下线,但是哨兵误以为它下线了,而误判一般会发生在集群网络压力较大、网络拥塞,或者是主节点本身压力较大的情况下。
而一旦哨兵判断主节点下线了,就会开始选择新主节点,并让从节点和新主节点进行数据同步,而这个过程本身就会有开销,例如哨兵要花时间选出新主节点,从节点也需要花时间和新主节点同步。而在误判的情况下,主节点本身根本就不需要进行切换的,所以这个过程的开销是没有价值的,正因为这样,我们需要判断是否有误判,以及减少误判。
那怎么减少误判呢?在日常生活中,当我们要对一些重要的事情做判断的时候,经常会和家人或朋友一起商量一下,然后再做决定。哨兵机制也是类似的,它通常会采用多实例组成的集群模式进行部署,这也被称为哨兵集群。引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主节点下线的情况。同时,多个哨兵的网络同时不稳定的概率较小,由它们一起做决策,误判率也能降低。
至于决策的机制我们一会再聊,目前我们只需要先理解哨兵集群在减少误判方面的作用即可。
所以在判断主节点是否下线时,不能只由一个哨兵说了算,只有大多数的哨兵实例,都将主节点标记为 "主观下线",主节点最终才会被标记为 "客观下线",而这个叫法也是表明主节点下线已经成为一个客观事实了,此时才会重新选择新主节点。因此还是很形象的,主观下线指的是某个哨兵自己主观认为下线了,但问题是主节点到底下没下线呢,还需要参考其它哨兵的意见,如果大部分的哨兵都这么认为的话(就是简单的少数服从多数),那么说明主节点下线就已经成为客观事实了,所以会被标记为客观下线、然后重新选举。
我们以一张图为例,下图是一个 Redis 主从集群,有一个主节点、三个从节点,还有三个哨兵实例。
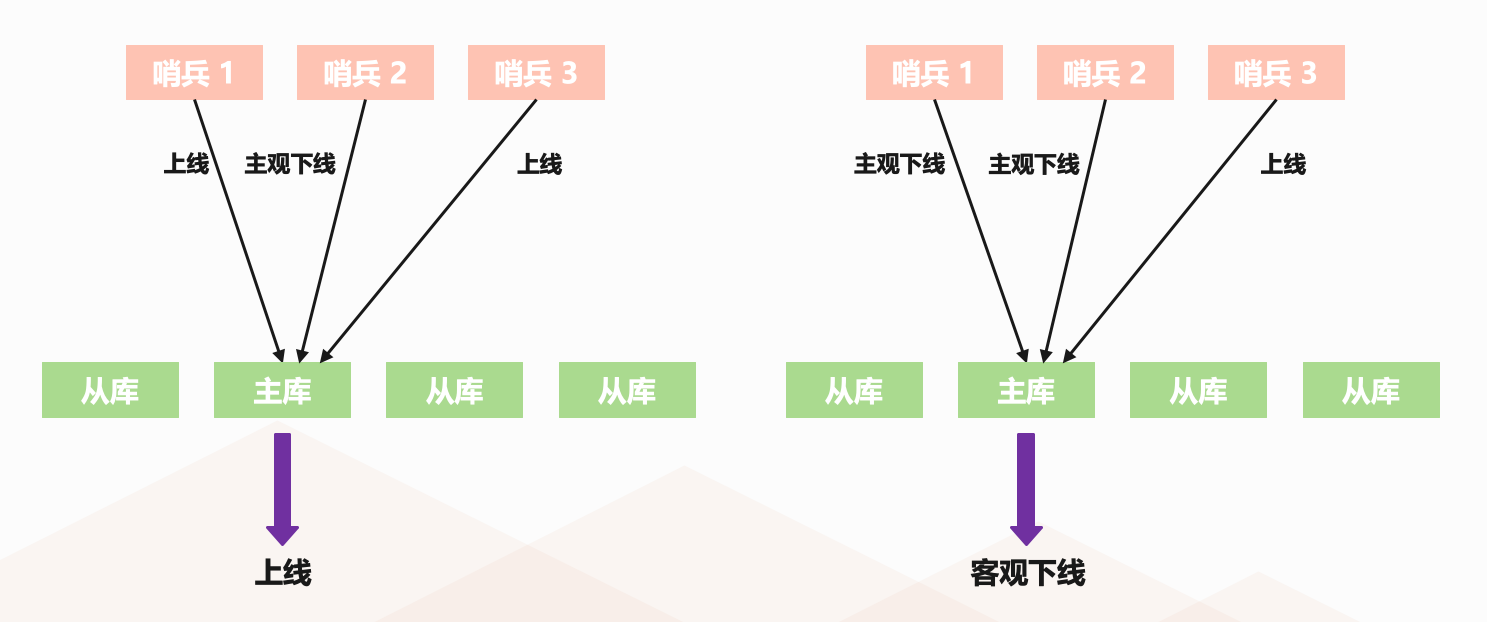
在图片的左边,哨兵 2 判断主节点为 "主观下线",但哨兵 1 和 3 却判定主节点是上线状态,那么此时主节点仍然被判断为处于上线状态。在图片的右边,哨兵 1 和 2 都判断主节点为 "主观下线",那么即使哨兵 3 仍然判断主节点为上线状态,主节点也会被标记为 "客观下线" 。
简单来说,客观下线的标准就是,当有 N 个哨兵实例时,最好要有 N/2 + 1 个实例判断主节点为主观下线,才能最终判定主节点为客观下线。这样一来,就可以减少误判的概率,也能避免误判带来的无谓的主从节点切换。当然,有多少个实例做出主观下线的判断才可以,可以由 Redis 管理员自行设定,也就说客观下线的标准是由我们自己定的,即使设置成有一个哨兵标记为主观下线就进行主从切换也是可以的,只不过误判率会比较高。因此工作中的哨兵数量最好是大于 1 的奇数,然后至少有 N/2 + 1 个哨兵标记主观下线再进行主从切换,当然为了避免误判可以设置的更高一些,比如 2/3 * N + 1,一切都由我们自己设置。
这里的 N/2 + 1 或者 2/3 * N + 1 也 被称为 quorum,指的就是上面说的:标记为主观下线、然后进行主从切换所需要的哨兵数量。
好了,到这里我们可以看到,借助于多个哨兵实例的共同判断机制,我们就可以更准确地判断出主节点是否处于下线状态。如果主节点的确下线了,哨兵就要开始下一个决策过程了,即从许多从节点中,选出一个从节点来做新主节点。
如何选定新主节点
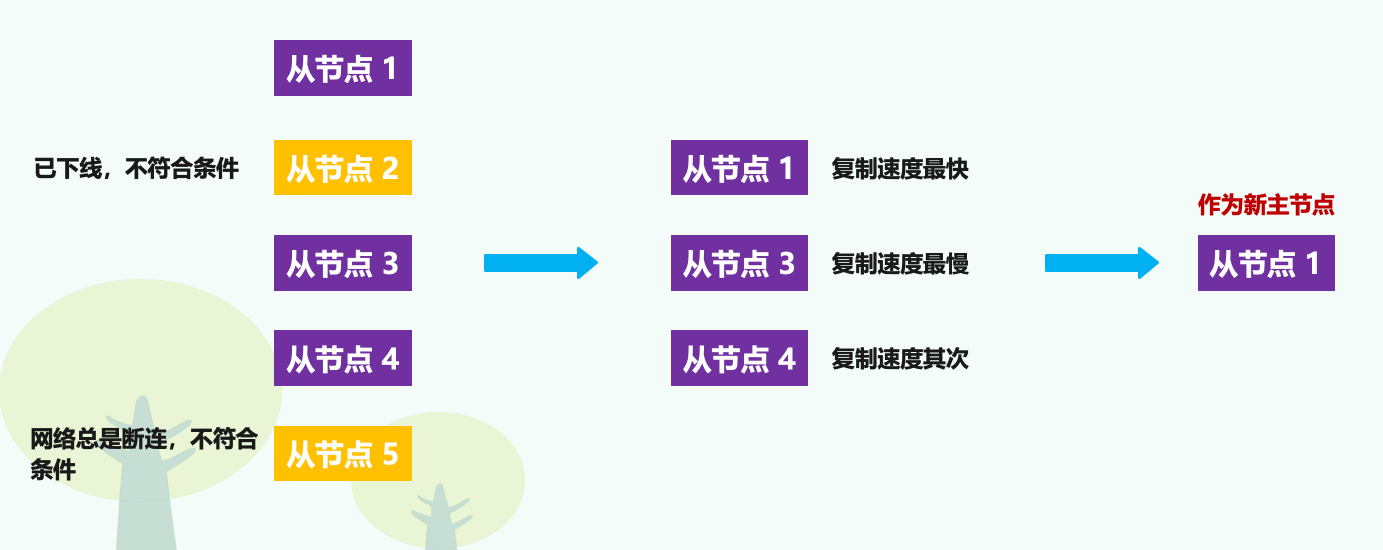
一般来说,哨兵筛选新主节点的过程被称为:筛选 + 打分,简单来说,我们在多个从节点中先按照 "一定" 的筛选条件,把不符合条件的从节点去掉。然后再按照 "一定" 的规则,给剩下的从节点逐个打分,将得分最高的从节点选为新主节点。如下图所示:
在上面的这段话里,有两个加了引号的 "一定",现在,我们要考虑这里的 "一定" 具体是指什么。
首先来看筛选的条件,一般情况下,我们肯定要先保证所选的从节点仍然在线运行。不过在选择主节点时,从节点正常在线只能表示从节点的现状良好,并不代表它就是最适合做主节点的。设想一下,如果在选择主节点时,一个从节点正常运行,我们把它选为新主节点开始使用了。可是,很快它的网络出了故障,此时我们就又得重新选择主节点了,而这显然不是我们期望的结果。
所以在选择主节点时,除了要检查从节点的当前在线状态,还要判断它之前的网络连接状态。如果从节点总是和主节点断连,而且断连次数超出了一定的阈值,我们就有理由相信,这个从节点的网络状况并不是太好,就可以把这个从节点筛掉了。
具体判断方式可以通过配置项 down-after-milliseconds * 10,其中 down-after-milliseconds 是我们认定主从节点断连的最大连接超时时间。如果在 down-after-milliseconds 毫秒内,主从节点都没有通过网络联系上,我们就可以认为主从节点断连了。如果后面的 * 10 则表示发生断连的次数超过了 10 次,就说明这个从节点的网络状况不好,不适合作为新主节点。
好了,这样我们就过滤掉了不适合做主节点的从节点,完成了筛选工作。
接下来就要给剩余的从节点打分了,我们可以分别按照三个规则依次进行三轮打分,这三个规则分别是:从节点优先级、从节点复制进度、从节点 ID 号。只要在某一轮中,有从节点得分最高,那么它就是主节点了,选则主节点的这个过程到此结束。如果没有出现得分最高的从节点,那么就继续进行下一轮。
第一轮:优先级最高的从节点得分高
用户可以通过 slave-priority 或 replica-priority 配置项,给不同的从节点设置不同优先级。比如你有两个从节点,它们的内存大小不一样,你可以手动给内存大的实例设置一个高优先级。在选择主节点时,哨兵会给优先级高的从节点打高分,如果有一个从节点优先级最高,那么它就是新主节点了。如果从节点的优先级都一样,那么哨兵开始第二轮打分。
注:slave-priority 如果设置为 0,那么不会参与打分,而是会被直接过滤掉,因为 slave-priority 为 0 表示该从节点不参与主节点的竞选。
第二轮:和旧主节点同步程度最接近的从节点得分高
这个规则的依据是,如果选择和旧主节点同步最接近的那个从节点作为新主节点,那么,这个新主节点上就有最新的数据。如何判断从节点和旧主节点之间的同步进度呢?
之前我们说过主从节点同步时有个命令传播的过程,在这个过程中,主节点会用 master_repl_offset 记录当前的最新写操作在 repl_backlog_buffer 中的位置,而从节点会用 slave_repl_offset 这个值记录当前的复制进度。而我们想要找的从节点,它的 slave_repl_offset 需要最接近 master_repl_offset,如果在所有从节点中,有从节点的 slave_repl_offset 最接近 master_repl_offset,那么它的得分就最高,可以作为新主节点。
就像下图所示,旧主节点的 master_repl_offset 是 1000,从节点 1、2 和 3 的 slave_repl_offset 分别是 950、990 和 900,那么从节点 2 就应该被选为新主节点。
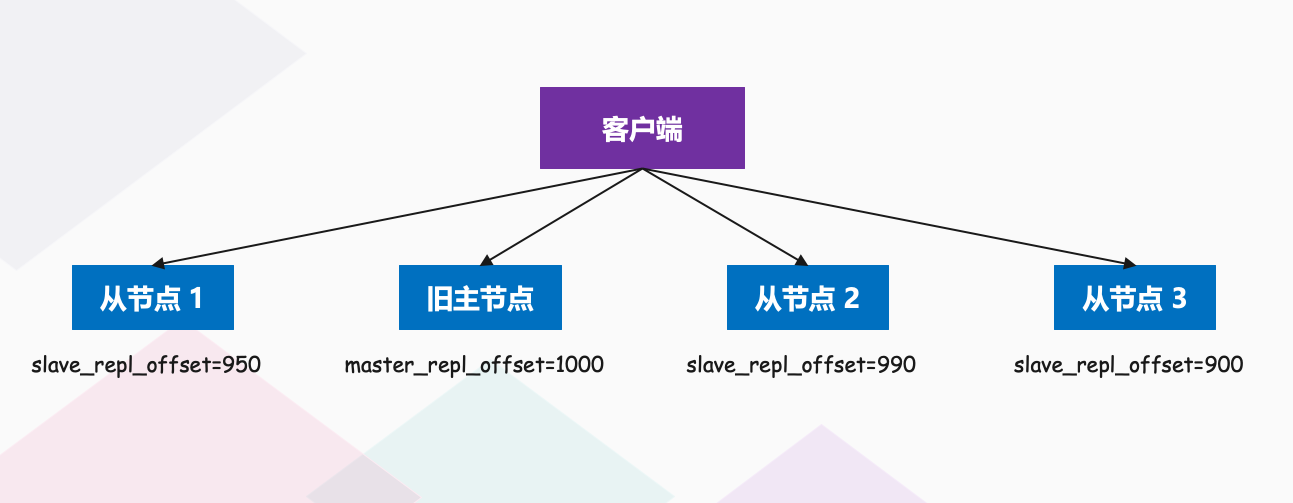
当然,如果有两个从节点的 slave_repl_offset 值大小是一样的(例如,从节点 1 和从节点 2 的 slave_repl_offset 值都是 990),我们就需要给它们进行第三轮打分了。
第三轮:ID 号小的从节点得分高
每个实例都会有一个 ID,这个 ID 就类似于这里的从节点的编号。目前 Redis 在选主节点时,有一个默认的规定:在优先级和复制进度都相同的情况下,ID 号最小的从节点得分最高,会被选为新主节点。所以到这里,新主节点就被选出来了,"选择主节点" 这个过程就完成了,显然用 ID 号来选实属最后没得比了。
流程总结
我们再回顾下这个流程:首先哨兵会按照在线状态、网络状态,筛选过滤掉一部分不符合要求的从节点,然后依次按照优先级、复制进度、ID 号大小再对剩余的从节点进行打分,只要有得分最高的从节点出现,就把它选为新主节点。如果有多个实例拥有相同的最高分,那么就单独拎出来继续比。
以上就是哨兵机制的基本原理,它是实现 Redis 不间断服务的重要保证。具体来说,主从集群的数据同步,是数据可靠的基础保证;而在主节点发生故障时,自动的主从切换是服务不间断的关键支撑。
而 Redis 的哨兵机制自动完成了以下三大功能,从而实现了主从节点的自动切换,可以降低 Redis 集群的运维开销:
监控主节点运行状态,并判断主节点是否客观下线;在主节点客观下线后,选取新主节点;选出新主节点后,通知从节点和客户端;
而为了降低误判率,在实际应用时,哨兵机制通常采用多实例的方式进行部署(组成哨兵集群),多个哨兵实例通过 "少数服从多数" 的原则,来判断主节点是否客观下线。一般来说,我们可以部署三个哨兵,如果有两个哨兵认定主节点主观下线,就可以开始切换过程。当然,如果你希望进一步提升判断准确率,也可以再适当增加哨兵个数,比如说使用五个哨兵。
我们说过,哨兵集群内部的哨兵数量最好是取大于 1 的奇数,例如 3、5、7、9,而 quorum 的配置要根据哨兵的数量来发生变化。例如有 3 个哨兵,那么对应的 quorum 最好是 2,如果有 5 个哨兵,那么 quorum 最好是 3,它表示当有 3 个哨兵都标记主节点主观下线了,那么就可以确定主节点真的下线了。当然还是那句话,具体怎么配都是由我们自己决定的,将 quorum 配置为 N/2 + 1 只是一个参考,你可以设置的多一些。
哨兵集群示意图如下:
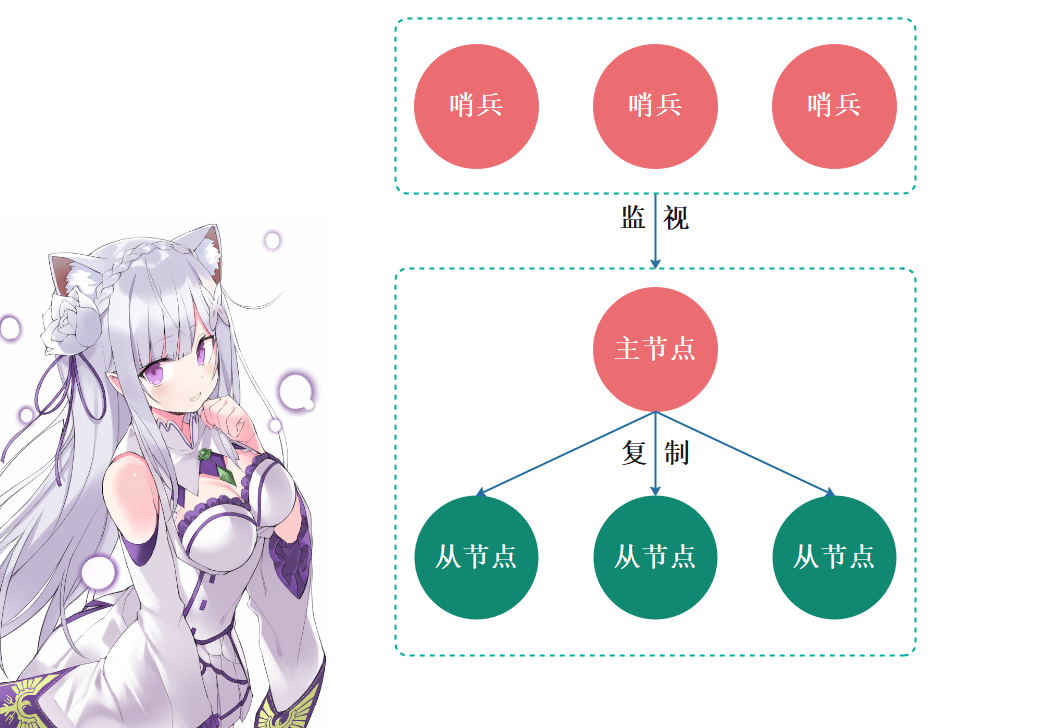
可以看到整体流程还是比较容易的,下面我们就来实际操作一波,搭建一个哨兵集群。
哨兵集群搭建与测试
我们说哨兵就是用来监视的,如果没有哨兵的话,那么当 master 挂了,我们需要找手动找一个从节点执行 slaveof no one 成为 master,然后显式地指定其余的机器来跟随这个新的 master,而哨兵模式则是自动地执行这一个过程,不需要人为参与。所以就是有个哨兵在监控,如果老大挂了,那么就要从小弟当中选出一个新老大。
环境
在我阿里云上有三台服务器,配置如下:
主机名:satori,公网 IP:47.94.174.89,内网 IP:172.24.60.6,2 核心 8GB 内存主机名:matsuri,公网 IP:47.93.39.238,内网 IP:172.28.112.191,2 核心 4GB 内存主机名:aqua,公网 IP:47.93.235.147,内网 IP:172.30.146.243,2 核心 4GB 内存
其中 satori 主机是主节点,matsuri 主机和 aqua 主机是从节点。
sentinel.conf 配置文件
那么如何使用哨兵模式呢?
首先我们要新建一个文件,这个文件名必须叫做 sentinel.conf,放在哪个目录不重要,但是名字不可以错。不过由于我们的 Redis 是从源码编译安装的,而在 Redis 主目录中就有一个 sentinel.conf,哨兵的所有配置都在里面,类似于 redis.conf 一样,我们直接修改指定的部分即可。
我们把注释删掉,看看里面都有哪些内容吧。
# bind 127.0.0.1 192.168.1.1
# protected-mode no
port 26379
daemonize no
pidfile /var/run/redis-sentinel.pid
logfile ""
# sentinel announce-ip <ip>
# sentinel announce-port <port>
dir /tmp
sentinel monitor mymaster 127.0.0.1 6379 2
# sentinel auth-pass <master-name> <password>
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# requirepass <password>
# sentinel parallel-syncs <master-name> <numreplicas>
sentinel parallel-syncs mymaster 1
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# sentinel notification-script <master-name> <script-path>
# sentinel client-reconfig-script <master-name> <script-path>
sentinel deny-scripts-reconfig yes
配置还是蛮多的,有的被注释掉,有的没被注释掉,我们来分别解释一下里面的含义。
- bind 127.0.0.1 192.168.1.1:bind 表示选择绑定的 IP,默认情况下只能本机访问,而不同节点之间的哨兵显然是需要通信的,我们需要改成 0.0.0.0。
- protected-mode no:是否开启保护模式,默认不开启。同 Redis Server 一样,如果不开启,那么任何节点都可以访问哨兵集群、并且无需密码。当然我们后面为了节点之间自由访问,就不关开启保护模式了,既然不开启,那么 bind 也就无需设置了。
- port 26379:监听的端口,默认是 26379。
- daemonize no:是否后台启动,为了更好的观察输出,我们后面直接前台启动。
- pidfile /var/run/redis-sentinel.pid:如果后台运行,那么 Redis 哨兵需要保存对应的 pid,而默认会写入到 pidfile 中。
- logfile "":日志文件,后台启动的时候日志会写到 logfile 指定的位置,而不指定 logfile,也就是 logfile 为空字符串,那么会写到 /dev/null;但如果前台启动,logfile 为 "",那么会写到标准输出当中。
- sentinel announce-ip <ip>、sentinel announce-port <port>:当哨兵之间无法通过内网 IP 访问时使用。举个栗子,我们购买阿里云服务器之后会有一个内网 IP 和一个外网 IP,内网 IP 就是本机 IP(使用 ifconfig 即可查看),只能在阿里云内的局域网中使用,但是多个节点之间的数据交换是非常快速的(能达到 1G 每秒),并且成本为零;公网 IP 则是负责让别人访问的,服务器上如果部署一个应用,那么外界如果想访问,必须使用公网 IP,然后内部会再通过 NAT 技术将公网 IP 转成内网 IP 进入阿里云局域网,最终找到指定的节点,访问节点上指定的服务。所以,如果多个哨兵部署在内网,并且之间还无法通信的话,那么就必须指定自己的公网 IP 和端口(端口不指定,则会使用上面 port 指定的 26379),让哨兵通过 "非本机 IP(非内网 IP)"、也就是通过公网 IP 从外部访问,而指定方式就是通过这里的两个配置。注意:这个非常重要,后面会用到。
- dir /tmp:每个长时间运行的程序都应该有一个工作区,负责容纳运行时产生的日志文件。但是需要注意,dir 会改变后面指令的相对路径,如果 pidfile 和 logfile 放在 dir 的后面并指定为相对路径,那么相对路径就是 dir 指定的工作区。
- sentinel monitor mymaster 127.0.0.1 6379 2:核心配置,原型为 sentinel monitor <master-name> <master-ip> <master-port> <quorum>。其中 master-name 表示给监视的主节点起一个名称,名字随意;master-ip 表示监听的主节点的 IP;master-port 表示监听的主节点的端口;quorum 表示标记主节点客观下线所需的 Sentinel(哨兵) 数量,如果 quorum 设置为 1,则表示只要有一台 Sentinel 标记主节点主观下线,那么就可以标记主节点客观下线了。
- sentinel auth-pass <master-name> <password>:指定 master 节点的密码,用于验证,但是注意:该密码也会适用于从节点。这意味着,如果想让哨兵监视主节点的同时也监视从节点,那么主节点、从节点都必须设置相同的密码。但问题是我们这里没有指定从节点的 IP 啊,答案是不需要指定,哨兵会自动监听连接到主节点的从节点。
- sentinel down-after-milliseconds <master-name> <milliseconds>:我们说哨兵会每隔固定时间就向主节点、从节点发送一个 PING,如果在 down-after-milliseconds 内没有收到回复,那么就会将其标记为主观下线,默认值是 30000、即 30 秒。
- requirepass <password>:类似于 redis-cli -p 6379 一样,我们也可以使用 redis-cli -p 26379 连接到哨兵集群,这里的 requirepass 表示连接时需要指定的密码。
- sentinel parallel-syncs <master-name> <numreplicas>:表示最多可以有多少个从节点同时对新主节点的数据进行同步,显然这个数字越小,所有从节点完成同步的总体所需时间就越长;但越大就意味越多的从节点因为复制数据而无法提供服务,默认为 1,表示每次只有一个从节点进行数据同步。
- sentinel failover-timeout <master-name> <milliseconds>:故障转移(failover)超时时间,默认为 18000、即 180 秒,如果在 failover-timeout 内没有触发任何 failover 操作,那么哨兵会认为此次 failover 失败。
- sentinel notification-script <master-name> <script-path>:可以指定一个路径(脚本文件),在故障转移期间,当一些警告级别的时间发生时,会触发对应路径的脚本,并传递相关的事件参数。
- sentinel client-reconfig-script <master-name> <script-path>:和 notification-script 类似,在故障转移结束后,会触发对应路径的脚本,并向脚本发送故障转移结果的相关参数。
- sentinel deny-scripts-reconfig yes:是否拒绝动态修改 client-reconfig-script 参数。
然后我们修改相应的配置,由于这里我们只是学习,所以就不在之前的配置文件上改了,直接创建一个新的 sentinel.conf,把需要的相关配置写上去即可。
# 非常重要,一定要配置,这里负责指定要监听的主节点
# my_master 表示给主节点起个名字
# 47.94.174.89 表示主节点的 IP
# 6379 表示主节点的 Redis 服务监听的端口
# 1 表示将主节点标记为客观下线的 Sentinel 数量,这里我们设置为 1
sentinel monitor my_master 47.94.174.89 6379 1
# 主节点连接需要密码,但我们说这个密码也适用其它的从节点,因此整个 Redis 集群的密码就必须相同
# 这里我已经将所有的节点的密码都改成了 heihei、重启完毕,并让 matsuri 节点和 aqua 节点继续成为 satori 节点的从节点
sentinel auth-pass my_master heihei
非常重要:我们之前在使用 slaveof 之后,还需要指定 master 密码,当时我们是在命令行中用 config set masterauth 的方式指定的。但是主从切换的时候,会从配置文件中读取 masterauth,因此我们在重启 Redis 服务的时候还需要修改一下配置文件,指定 masterauth,否则后面会无法进行主从切换,哨兵会一直提示:Next failover delay: I will not start a failover before ......
然后我们就可以通过 redis-sentinel <sentinel.conf 文件路径> 进行启动了,当然这里我们是前台启动的,工作中要改成后台启动。
我们先在 satori 节点、也就是主节点上启动,看看输出:
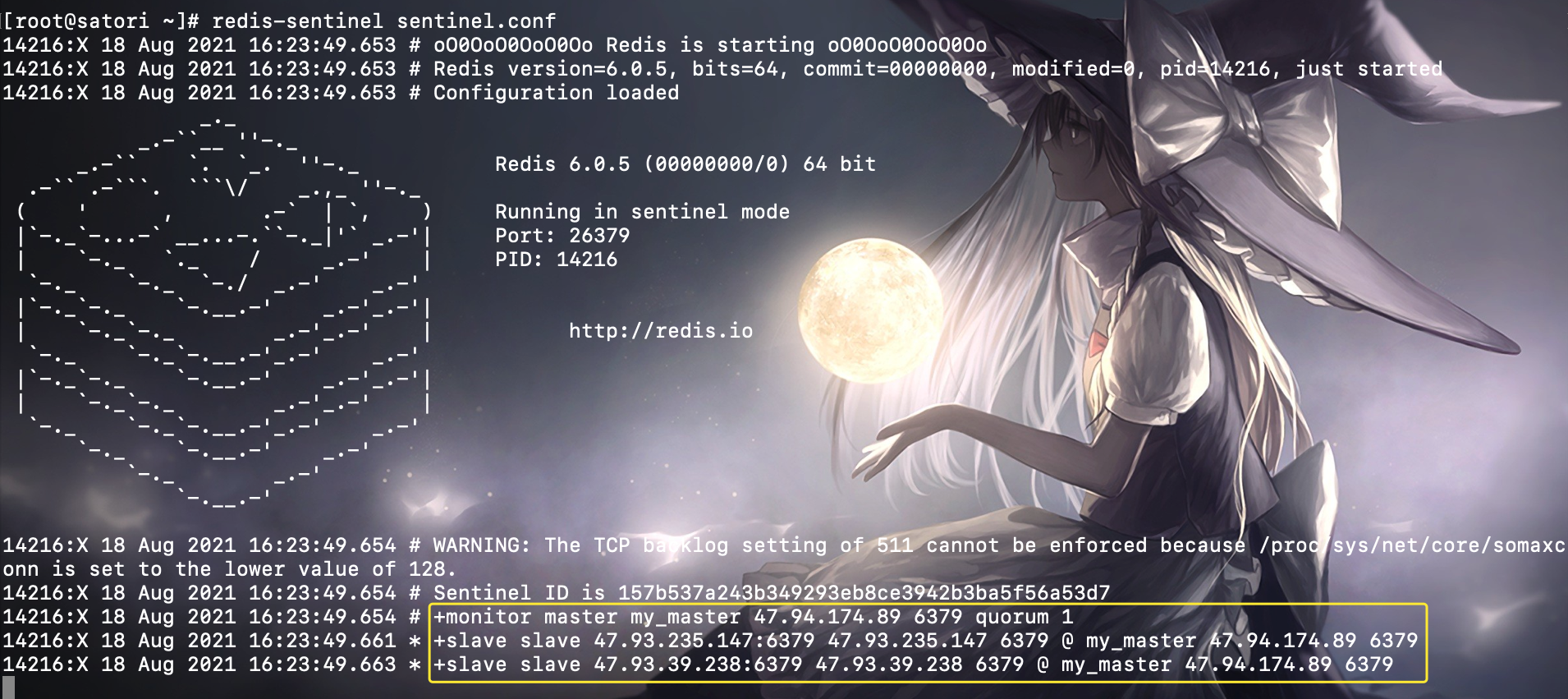
此时我们就启动了一个哨兵,注意黄色框框里面的内容,+monitor 表示成功监听主节点,+slave 表示成功监听从节点。所以我们看到监听的主节点的 IP 为 47.94.174.89,master name 为 my_master,并且我们在 sentinel.conf 中只配置了主节点的信息,但是会自动监听连接到主节点上的从节点。
上面我们演示了单个哨兵的启动,但生产环境我们不会只启动一个哨兵,因为如果只有一个哨兵,那当它不幸宕机的话,就不能提供自动容灾的服务了,不符合我们高可用的宗旨,所以我们会在不同的物理机上启动多个哨兵来组成哨兵集群,来保证 Redis 服务的高可用。因此我们在 aqua 节点和 matsuri 节点上也分别启动一个哨兵,所以当前就是 "一主二从三哨兵",satori 是主节点,matsuri、aqua 是从节点,并且每个节点上都运行一个哨兵。因此我们这里是每个节点上即部署了 Redis 服务,还部署了哨兵,不过工作中一般都会分开,但我这里只有三台服务器,所以只能既当爹又当妈了。
而启动哨兵集群的方法很简单,和上面启动单台的方式一样,我们只需要让多个哨兵监听到同一个主服务器节点,那么多个哨兵就会自动发现彼此,并组成一个哨兵集群(至于背后的原理我们一会再说)。
那么下面我们就来启动第二个哨兵试一下,在 matsuri 节点上启动,并且配置和之前一样,不需要做任何改动:
sentinel monitor my_master 47.94.174.89 6379 1
sentinel auth-pass my_master heihei
然后你会发现在哨兵的窗口(satori 节点)中多了一条输出,该输出告诉我们增加了一个哨兵。
+sentinel sentinel 668a7b1b90811840d70a0ef949250f93e37ae0c1 172.28.112.191 26379 @ my_master 47.94.174.89 6379
注意:里面的 172.28.112.191 指的是 matsuri 节点的内网 IP,注意这里的内网 IP,这是一个坑。总之目前的输出告诉我们 matsuri 节点上的哨兵加入进来了,和 satori 上的节点一起监视 master 节点。
虽然看起来很顺利,然而没一会儿就出现问题了:

左侧输出的有时间信息,我们看到 30 秒后 satori 节点上输出信息提示我们 matsuri 节点上的哨兵下线了;同理,如果查看 matsuri 节点上的输出的话,也会发现这么一条:
+sdown sentinel 157b537a243b349293eb8ce3942b3ba5f56a53d7 172.24.60.6 26379 @ my_master 47.94.174.89 6379
172.24.60.6 指的是 satori 节点的内网 IP,所以提示我们 satori 节点上的哨兵下线了。
在阿里云上部署多个哨兵的坑
为啥会出现这个状况呢?原因就是哨兵之间进行通信的时候使用的是内网 IP,而 satori 节点和 matsuri 节点不在同一个内网中,所以就出现了这个问题。另外,虽然 satori 节点和 matsuri 节点不在一个内网中,但 matsuri 节点和 auqa 节点时处于一个内网中的,我们在 aqua 节点上再启动一个哨兵,然后观察一下输出。
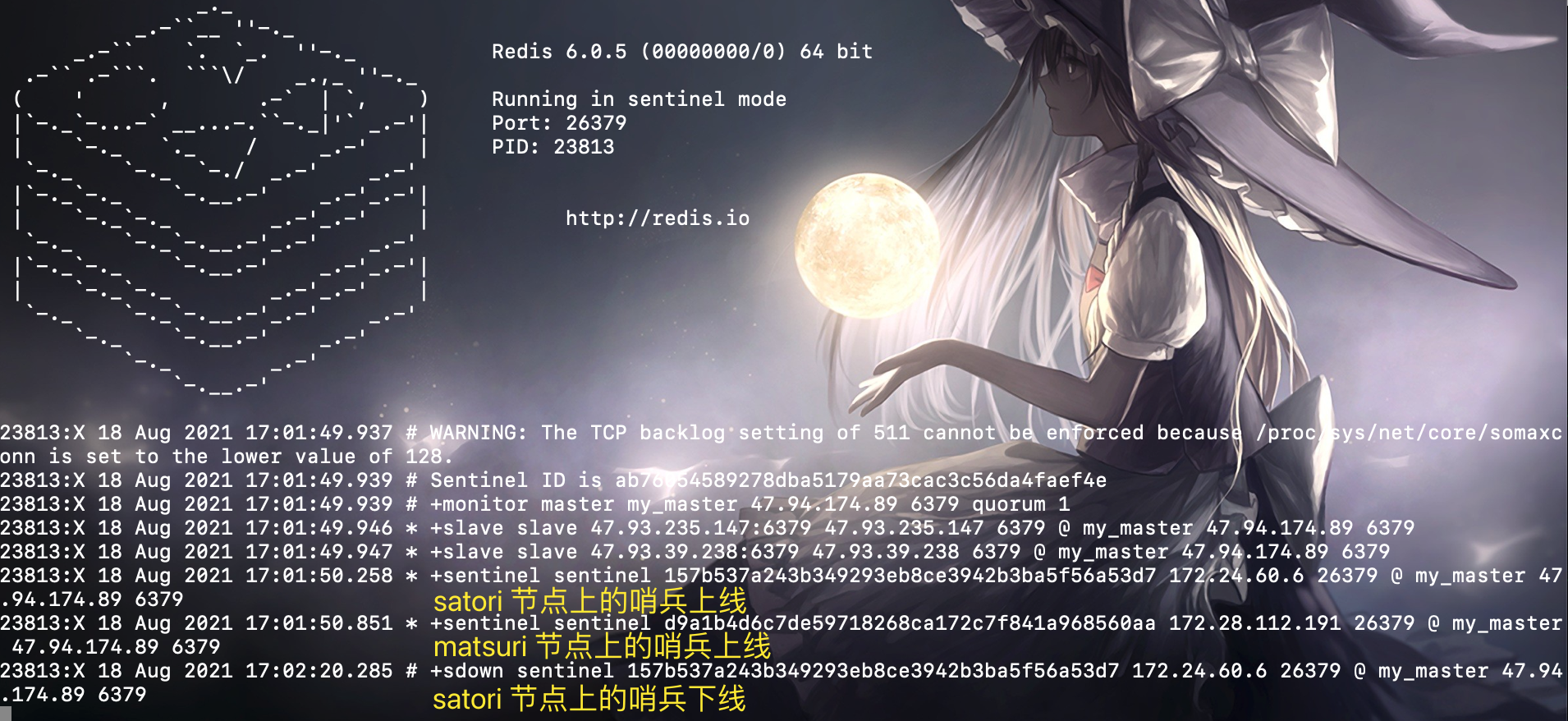
我们看到 satori 节点上哨兵下线了,但 matsuri 节点上的哨兵没有下线,原因就是通过内网 IP 连接话,aqua 是连不上 satori 节点的,只能连接 matsuri 节点。当然我们这里说的下线,是某个哨兵因为网络问题连接不上另一个哨兵而错误地认为下线,但实际上 satori 节点上的哨兵运行的好好的。
那么怎么解决这个问题呢?两种办法,第一种是让 satori 节点和 matsuri 节点、aqua 节点之间进行内网互通即可,不过这里我们不使用这种方法,而是使用第二种。第二种办法是通过配置 sentinel announce-ip 进行设置,我们说当节点之间无法通过内网访问时,只需要将这个配置指定为公网 IP 即可。所以先暂停哨兵集群,然后重新修改我们的配置文件:
sentinel monitor my_master 47.94.174.89 6379 1
sentinel auth-pass my_master heihei
# satori 节点指定为 47.94.174.89
# matsuri 节点指定为 47.93.39.238
# aqua 节点指定为 47.93.235.147
sentinel announce-ip <ip>
# 这里不需要指定 announce-port,不指定的话,默认使用上面 port 26379
在哨兵集群启动之后,sentinel.conf 会被自动刷新,因为哨兵集群会往里面里面写入内容(记录哨兵集群的状态)。这里我们直接里面的内容删除即可,然后将修改后配置贴到里面去。
此时再来重新启动,查看各节点的输出:

显然指定完 announce-ip 之后就正常了,并且此时显示的就是公网 IP 了。
然后我们来执行一些写操作测试一下,由于为了观察输出,我们是前台启动的哨兵,因此只能再开启三个终端。

显然此时一切正常,在主节点上写数据也能同步到从节点中,然而天有不测风云,这个时候 satori 节点(主节点)挂掉了(我们手动将其关闭):
[root@satori ~]# ps -ef | grep redis-server
root 14194 1 0 16:18 ? 00:00:23 redis-server 0.0.0.0:6379
root 14475 14449 0 20:00 pts/1 00:00:00 grep --color=auto redis-server
[root@satori ~]# kill -9 14194
[root@satori ~]# ps -ef | grep redis-server
root 14478 14449 0 20:00 pts/1 00:00:00 grep --color=auto redis-server
[root@satori ~]#
当主节点挂掉之后,哨兵在 PING 的时候就会得不到返回,知道主节点已经下线,就会从剩余的从节点中选出一个作为新主节点,如图所示:
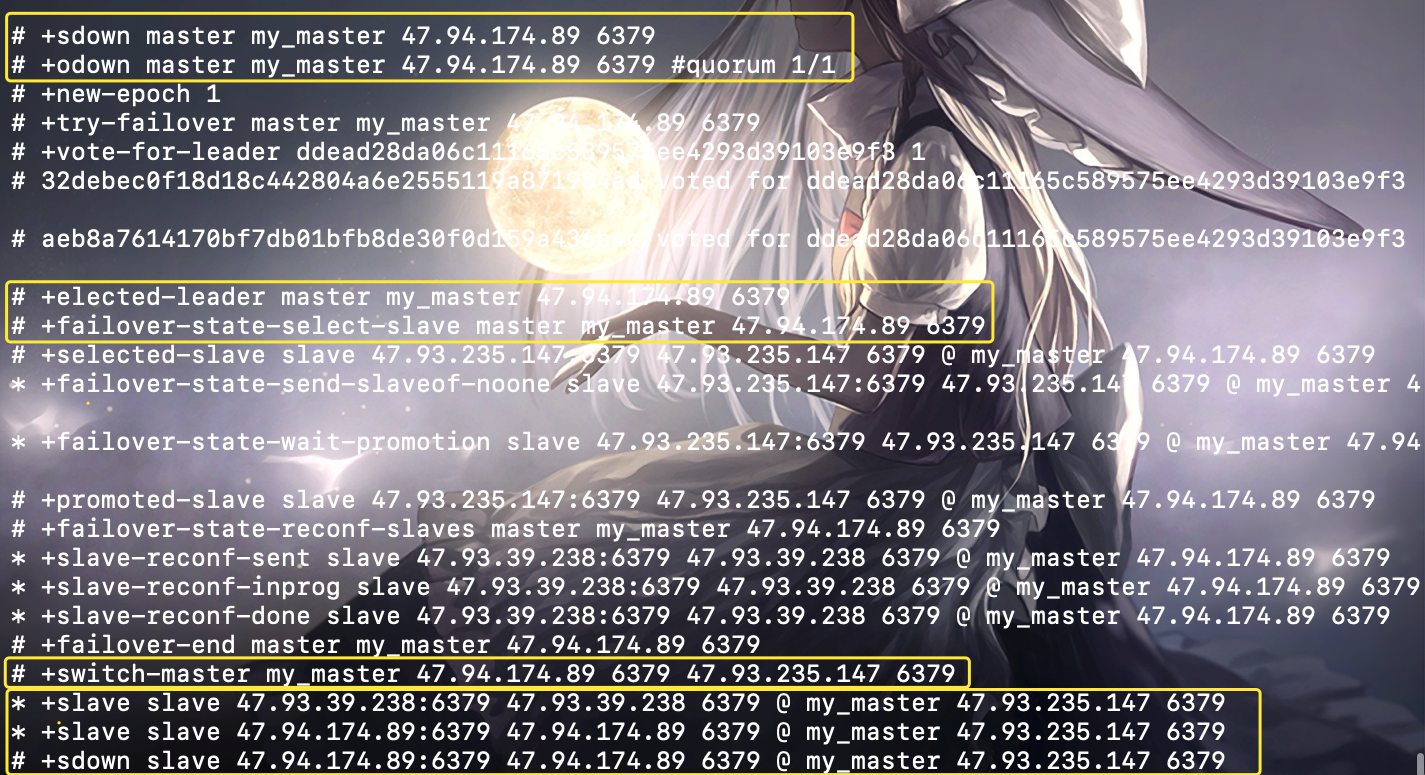
我们看到当主节点退出时会被标记为主观下线(+sdown),但是我们的 quorum 配置的是 1,所以会立即变成客观下线(+odown)。然后就进行新主节点选举(选举规则我们上面说的很详细了)、故障转移等等。而最终选择完新的主节点(+switch-master),这里新的主节点是 aqua 节点,之后再将其余的 "旧的主节点的从节点" 变成 "新的主节点的从节点"(+slave)。但是 satori 已经挂掉了,所以将其设置为 aqua 的从节点之后就直接主观下线了。
此时 aqua 节点时主节点,我们在上面写几个 key:
127.0.0.1:6379> set name gin
OK
127.0.0.1:6379> set age 29
OK
127.0.0.1:6379> role
1) "master"
2) (integer) 177541
3) 1) 1) "47.93.39.238"
2) "6379"
3) "177541"
127.0.0.1:6379>
显示从节点是 matsuri 节点,而在 matsuri 节点肯定能获取 aqua 节点上设置的 name 和 age,这里就不试了。因为有一个更重要的问题,我们说 master 挂了,会选择新的 master,但是如果之前那个挂掉的 master 又回来了,这个时候会是什么情况呢?很简单,其实上面的图中已经给出答案了,因为在选择 aqua 节点作为新主节点的时候,就已经将 satori 节点作为它的从节点了。所以尽管你之前是 master,但是你挂掉了,风水轮流转,即便你回来也只能当 slave。
# satori 节点
127.0.0.1:6379> role
1) "slave"
2) "47.93.235.147"
3) (integer) 6379
4) "connected"
5) (integer) 228771
127.0.0.1:6379>
127.0.0.1:6379> get name
"gin"
127.0.0.1:6379> get age
"29"
127.0.0.1:6379>
结果和我们分析的一样,如果再查看 aqua 节点的话,会发现它的 slave 数量变成了 2。

以上就是整个哨兵集群的搭建与测试环节,整个过程还是不难的。我们说,使用哨兵的目的是将主从切换自动化,而多个哨兵组成集群则是为了降低误判率,但这样又会面临新的挑战,比如:
哨兵集群中有实例挂了,怎么办,会影响主节点状态判断和选则新主节点吗?哨兵集群多数实例达成共识,判断出主节点客观下线后,由哪个实例来执行主从切换呢?
问题真的是一波接一波,感觉像套娃一样,那么下面就来解决它。
哨兵集群:哨兵挂了,主从节点还能切换吗?
在演示完哨兵集群的搭建之后我们抛出了两个问题,第一个问题是:如果有哨兵实例在运行时发生了故障,主从节点是否还能正常切换。
实际上,一旦多个实例组成了哨兵集群,即使有哨兵实例出现故障挂掉了,其他哨兵还能继续协作完成主从节点切换的工作,包括判定主节点是不是处于下线状态,选择新主节点,以及通知从节点和客户端。
而我们之前在部署哨兵的时候说过,哨兵之间不需要显式地指定彼此的地址,只要它们监听到同一个主节点,就会自动发现彼此、组成集群,那么这究竟是怎么实现的呢?接下来就来聊一聊哨兵的组成和运行机制。
基于 pub/sub 机制的哨兵集群组成
哨兵实例之间可以相互发现,要归功于 Redis 提供的 pub/sub 机制,也就是发布 / 订阅机制。哨兵只要和主节点建立起了连接,就可以在主节点上发布消息了,比如发布它自己的连接信息(IP 和端口)。同时,它也可以从主节点上订阅消息,获得其它哨兵发布的连接信息。当多个哨兵实例都在主节点上做了发布和订阅操作后,它们之间就能知道彼此的 IP 地址和端口。
除了哨兵实例,我们自己编写的应用程序也可以通过 Redis 进行消息的发布和订阅,所以为了区分不同应用的消息,Redis 会以频道的形式,对这些消息进行分门别类的管理。而所谓的频道,实际上就是消息的类别,当消息类别相同时,它们就属于同一个频道,反之就属于不同的频道。只有订阅了同一个频道的应用,才能通过发布的消息进行信息交换。
在主从集群中,主节点上有一个名为 "__sentinel__:hello" 的频道,不同哨兵就是通过它来相互发现,实现互相通信的。举个栗子:
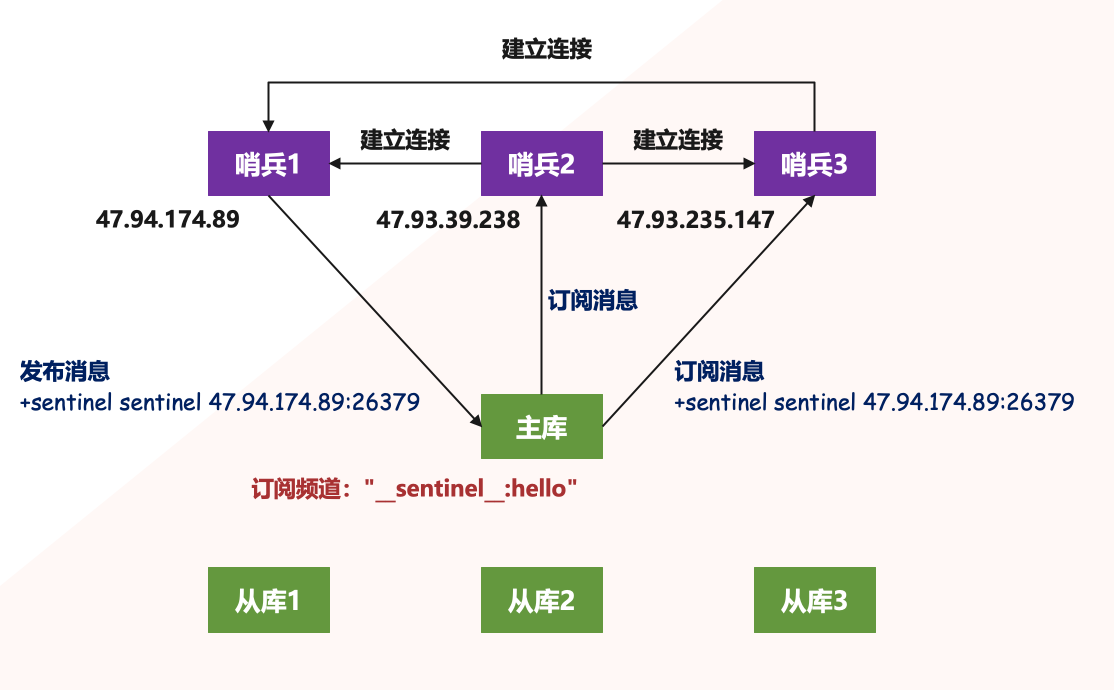
哨兵 1 把自己的 IP(47.94.174.89)和端口发布到 "__sentinel:hello__" 频道上,哨兵 2 和哨兵 3 订阅该频道,那么此时哨兵 2 和哨兵 3 就可以从该频道直接获取哨兵 1 的 IP 和端口号,然后哨兵 2、3 即可和哨兵 1 建立网络连接。通过这个方式,哨兵 2 和 3 也可以建立网络连接,这样一来,哨兵集群就形成了,它们相互间可以通过网络连接进行通信,比如说对主节点有没有下线这件事儿进行判断和协商。
哨兵除了彼此之间建立起连接形成集群外,还需要和从节点建立连接。这是因为在哨兵的监控任务中,它需要对主从节点都进行心跳判断,而且在主从节点切换完成后,它还需要通知从节点,让它们和新主节点进行同步。
那么问题来了,哨兵是如何知道从节点的 IP 地址和端口的呢?显然是通过主节点,想都不用想,但这个具体过程是怎么样的呢,我们来说一下。
哨兵会向主节点发送 INFO 命令,就像下图所示,哨兵 2 给主节点发送 INFO 命令,主节点在接受到这个命令后,就会把从节点列表返回给哨兵。接着哨兵就可以根据从节点列表中的连接信息,和每个从节点建立连接,并在这个连接上持续地对从节点进行监控,其它哨兵也是同理。
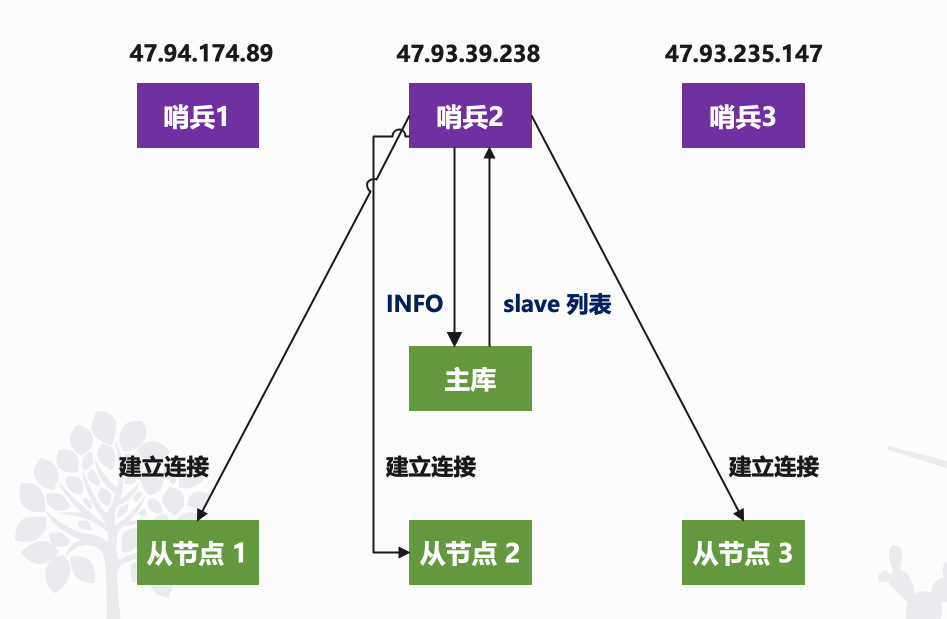
所以通过 pub/sub 机制,哨兵之间可以组成集群,同时哨兵又通过 INFO 命令,获得了从节点连接信息,也能和从节点建立连接,并进行监控了。
但哨兵不能只和主、从节点连接,因为主从节点切换后,客户端也需要知道新主节点的连接信息,才能向新主节点发送请求操作,所以哨兵还需要把新主节点的信息告诉客户端。而且,在实际使用哨兵时,我们有时会遇到这样的问题:如何在客户端通过监控来了解哨兵进行主从切换的过程呢?比如说,主从切换进行到哪一步了?这其实就是要求,客户端能够获取到哨兵集群在监控、选主、切换这个过程中发生的各种事件。
此时,我们仍然可以依赖 pub/sub 机制,来帮助我们完成哨兵和客户端间的信息同步。
基于 pub/sub 机制的客户端事件通知
从本质上说,哨兵就是一个运行在特定模式下的 Redis 实例,只不过它并不服务请求操作,只是完成监控、选主和通知的任务。所以,每个哨兵实例也提供 pub/sub 机制,客户端可以从哨兵订阅消息。哨兵提供的消息订阅频道有很多,不同频道包含了主从节点切换过程中的不同关键事件。
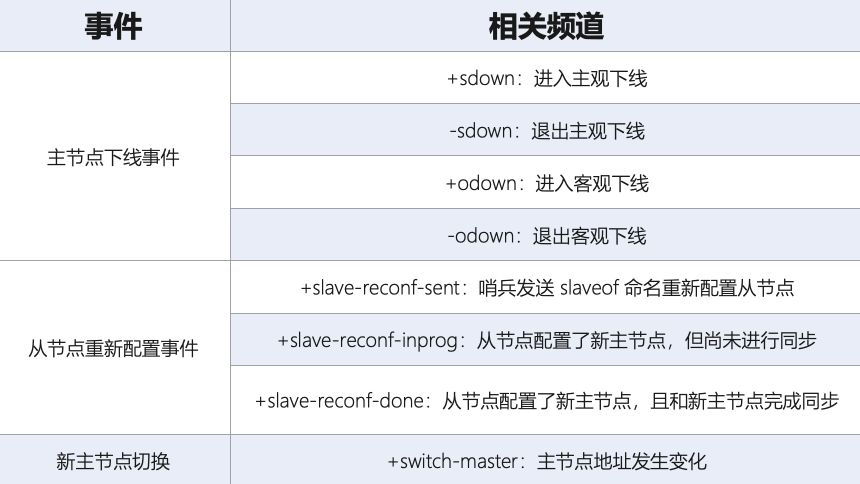
知道了这些频道之后,客户端就可以从哨兵这里订阅消息了。具体的操作步骤是,客户端读取哨兵的配置文件后,可以获得哨兵的地址和端口,和哨兵建立网络连接,然后获取事件消息。
比如:客户端(通过 redis-cli -p 26379)可以执行如下操作,来订阅 "所有实例进入客观下线的事件"。
SUBSCRIBE +odown
当然也可以执行如下操作来订阅所有的事件。
PSUBSCRIBE *
当哨兵把新主节点选择出来后,客户端就会看到下面的 switch-master 事件,这个事件表示主节点已经切换了,新主节点的 IP 地址和端口信息已经有了。这个时候,客户端就可以用这里面的新主节点地址和端口进行通信了。
switch-master <master-name> <master-old-ip> <master-old-port> <master-new-ip> <master-new-port>
有了这些事件通知,客户端不仅可以在主从切换后得到新主节点的连接信息,还可以监控到主从节点切换过程中发生的各个重要事件。这样,客户端就可以知道主从切换进行到哪一步了,有助于了解切换进度。
好了,有了 pub/sub 机制,哨兵和哨兵之间、哨兵和节点之间、哨兵和客户端之间就都能建立起连接了,再加上我们上次介绍的主节点下线判断和选主依据,以及哨兵集群的监控、选主和通知,就基本可以正常工作了。不过,我们还需要考虑一个问题:主节点故障以后,哨兵集群有多个实例,那怎么确定由哪个哨兵来进行实际的主从切换呢?
由哪个哨兵执行主从切换?
下面来解决第二个问题,当主从切换的时候,由哪个哨兵执行呢?
确定由哪个哨兵执行主从切换的过程,和主节点 "客观下线" 的判断过程类似,也是一个 "投票仲裁" 的过程。在具体了解这个过程前,我们再来看下,判断客观下线的仲裁过程。
哨兵集群要判定主节点客观下线,需要有一定数量的实例都认为该主节点已经主观下线了,我们之前介绍了判断客观下线的原则,接下来,我们就来聊一下具体的判断过程。
任何一个实例只要自身判断主节点主观下线后,就会给其他实例发送 is-master-down-by-addr 命令。接着,其它实例会根据自己和主节点的连接情况,做出 Y 或 N 的响应,Y 相当于赞成票,N 相当于反对票。
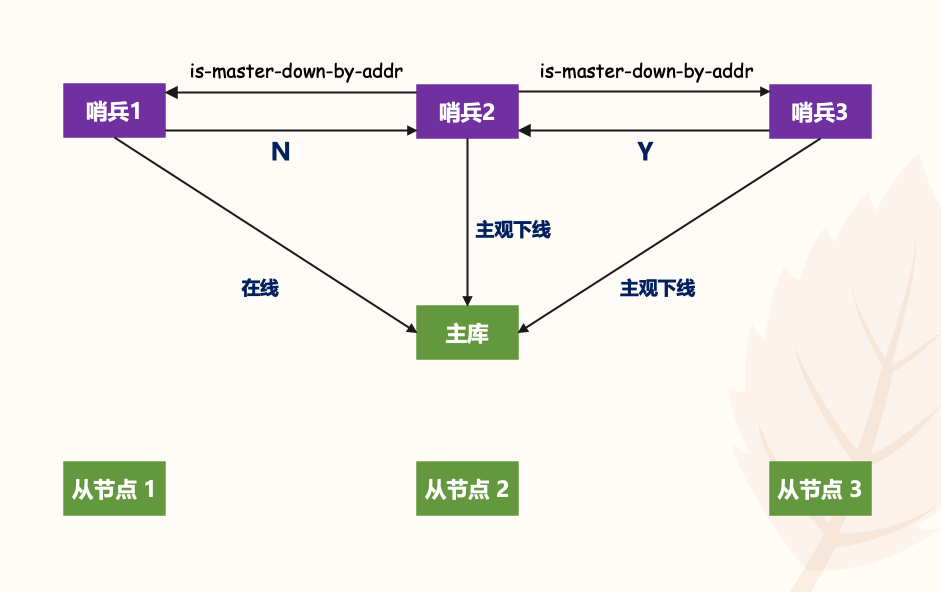
一个哨兵获得了仲裁所需的赞成票数后,就可以标记主节点为客观下线,而这个所需的赞成票数是通过哨兵配置文件中的 quorum 配置项设定的。例如,现在有 5 个哨兵,quorum 配置的是 3,那么一个哨兵如果能获得 3 张赞成票,那么就可以标记主节点为客观下线了。这 3 张赞成票包括哨兵自己的一张赞成票和另外两个哨兵的赞成票。
此时,这个哨兵就可以再给其它哨兵发送命令,表明希望由自己来执行主从切换,并让所有其他哨兵进行投票。这个投票过程称为 Leader 选举,因为最终执行主从切换的哨兵称为 Leader,投票过程就是确定 Leader。
而在投票过程中,任何一个想成为 Leader 的哨兵,要满足两个条件:
1. 拿到半数以上的赞成票2. 到的票数同时还需要大于等于哨兵配置文件中的 quorum 值
以 3 个哨兵为例,假设此时的 quorum 设置为 2,那么任何一个想成为 Leader 的哨兵只要拿到 2 张赞成票,就可以了。举个栗子:
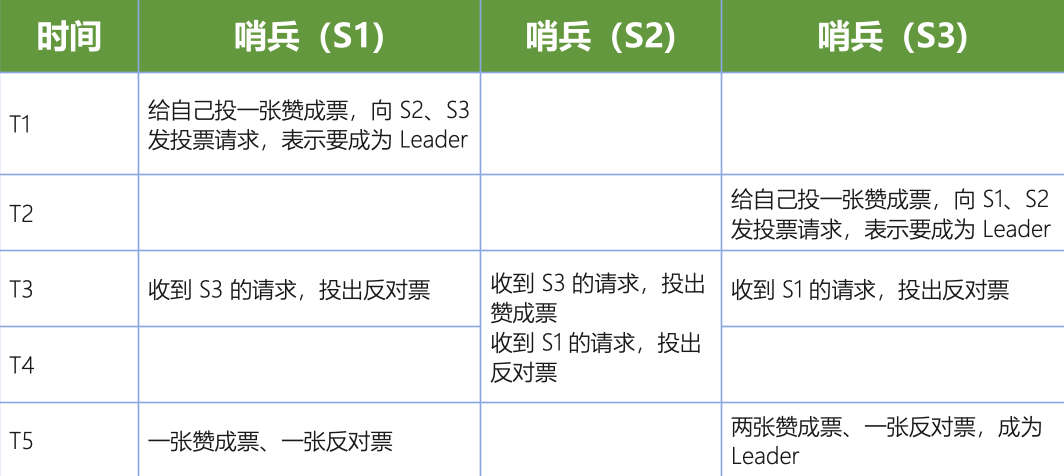
- 在 T1 时刻,S1 判断主节点为客观下线,而它想成为 Leader,就先给自己投一张赞成票,然后分别向 S2 和 S3 发送命令,表示要成为 Leader。
- 在 T2 时刻,S3 判断主节点为客观下线,它也想成为 Leader,所以也先给自己投一张赞成票,再分别向 S1 和 S2 发送命令,表示要成为 Leader。
- 在 T3 时刻,S1 收到了 S3 的 Leader 投票请求。因为 S1 已经给自己投了一张赞成票,所以它不能再给其他哨兵投赞成票了,所以 S1 只能投反对票,而 S3 与 S1 同理。与此同时,S2 收到了 T2 时 S3 发送的 Leader 投票请求,因为 S2 之前没有投过票,它会给第一个向它发送投票请求的哨兵投赞成票,给后续再发送投票请求的哨兵投反对票。所以在 T3 时,S2 回复 S3,表示同意 S3 成为 Leader。
- 在 T4 时刻,S2 才收到 T1 时 S1 发送的投票命令,因为 S2 已经在 T3 时同意了 S3 的投票请求,所以 S2 只能给 S1 投反对票,表示不同意 S1 成为 Leader。至于为什么 S3 的投票请求会比 S1 先到达 S2 这里,原因是 S3 和 S2 之间的网络传输正常,而 S1 和 S2 之间的网络传输可能正好拥塞了,导致投票请求传输慢了。
- 最后,在 T5 时刻,S1 得到的票数是来自它自己的一张赞成票和来自 S2 的一张反对票。而 S3 除了自己的赞成票以外,还收到了来自 S2 的一张赞成票。所以此时 S3 不仅获得了半数以上的 Leader 赞成票,也达到预设的 quorum 值(quorum 为 2),所以它最终成为了 Leader。接着,S3 会开始执行选择新主节点操作,而且在选定新主节点后,会给其他从节点和客户端通知新主节点的信息。
如果 S3 没有拿到 2 张赞成票,那么这轮投票就不会产生 Leader,哨兵集群会等待一段时间(也就是哨兵故障转移超时时间的 2 倍),再重新选举。这是因为,哨兵集群能够进行成功投票,很大程度上依赖于选举命令的正常网络传播,如果网络压力较大或有短时堵塞,就可能导致没有一个哨兵能拿到半数以上的赞成票。所以,等到网络拥塞好转之后,再进行投票选举,成功的概率就会增加。
需要注意的是,如果哨兵集群只有 2 个实例,此时一个哨兵要想成为 Leader,必须获得 2 票,而不是 1 票。所以如果有个哨兵挂掉了,那么此时的集群是无法进行主从节点切换的。因此,通常我们至少会配置 3 个哨兵实例(奇数个,quorum 为 N/2 + 1),这一点很重要,在实际应用时不能忽略了。
流程总结
通常,我们在解决一个系统问题的时候,会引入一个新机制,或者设计一层新功能,就像我们此时学习的哨兵机制一样:为了实现主从切换,我们引入了哨兵;为了避免单个哨兵故障后无法进行主从切换,以及为了减少误判率,又引入了哨兵集群;哨兵集群又需要有一些机制来支撑它的正常运行。
而制成哨兵集群运行的机制如下:
基于 pub/sub 机制的哨兵集群组成过程;基于 INFO 命令的从节点列表,这可以帮助哨兵和从节点建立连接;基于哨兵自身的 pub/sub 功能,这实现了客户端和哨兵之间的事件通知。
对于主从切换,当然不是哪个哨兵想执行就可以执行的,否则就乱套了。所以,这就需要哨兵集群在判断了主节点客观下线后,经过投票仲裁,选举一个 Leader 出来,由它负责实际的主从切换,即由它来完成新主节点的选择以及通知从节点与客户端。
最后再分享一个经验:要保证所有哨兵实例的配置是一致的,尤其是主观下线的判断值 down-after-milliseconds。如果这个值在不同的哨兵实例上配置不一致,就会导致哨兵集群一直没有对有故障的主节点形成共识,也就没有及时切换主节点,最终的结果就是集群服务不稳定,所以一定不要忽略这条看似简单的经验。
命令行操作
最后再来看下哨兵集群的命令操作,我们可以使用 redis-cli -p 26379 连接至哨兵集群,连接方式是一样的,只不过端口不一样罢了。
[root@aqua ~]# redis-cli -p 26379
127.0.0.1:26379> ping
PONG
127.0.0.1:26379>
注意:哨兵集群可以同时监视多个主节点,如果想要监视多个主节点,那么只需要在配置文件中设置多个 sentinel monitor <master-name> ip port quorum 即可,至于多个主节点之间我们通过 master-name 来区分。
查询所有被监控的主服务器信息
命令:sentinel masters
127.0.0.1:26379> sentinel masters
1) 1) "name"
2) "my_master"
3) "ip"
4) "47.93.235.147"
5) "port"
6) "6379"
7) "runid"
8) "1a9b7b64e8a1c186bdef74b6124541944a2f5271"
9) "flags"
10) "master"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "626"
19) "last-ping-reply"
20) "626"
21) "down-after-milliseconds"
22) "30000"
23) "info-refresh"
24) "8589"
25) "role-reported"
26) "master"
27) "role-reported-time"
28) "68338053"
29) "config-epoch"
30) "1"
31) "num-slaves"
32) "2"
33) "num-other-sentinels"
34) "2"
35) "quorum"
36) "1"
37) "failover-timeout"
38) "180000"
39) "parallel-syncs"
40) "1"
因为我们配置的哨兵集群只监视了一个主节点,所以只有一个主节点的信息。
查询某个主节点的信息
命令:sentinel master <master_name>
# # 只有一个 master,所以输出和 sentinel master 是一样的
127.0.0.1:26379> sentinel master my_master
1) "name"
2) "my_master"
3) "ip"
4) "47.93.235.147"
5) "port"
6) "6379"
7) "runid"
8) "1a9b7b64e8a1c186bdef74b6124541944a2f5271"
9) "flags"
10) "master"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "17"
19) "last-ping-reply"
20) "17"
21) "down-after-milliseconds"
22) "30000"
23) "info-refresh"
24) "8104"
25) "role-reported"
26) "master"
27) "role-reported-time"
28) "68508409"
29) "config-epoch"
30) "1"
31) "num-slaves"
32) "2"
33) "num-other-sentinels"
34) "2"
35) "quorum"
36) "1"
37) "failover-timeout"
38) "180000"
39) "parallel-syncs"
40) "1"
查看某个主节点的 IP 和端口
命令:sentinel get-master-addr-by-name <master_name>
127.0.0.1:26379> sentinel get-master-addr-by-name my_master
1) "47.93.235.147"
2) "6379"
127.0.0.1:26379>
查看所有从节点的信息
命令:sentinel slaves <master_name>,在 Redis 5.0 之后也可以将 slaves 换成 replicas
127.0.0.1:26379> sentinel slaves my_master
1) 1) "name"
2) "47.93.39.238:6379"
3) "ip"
4) "47.93.39.238"
5) "port"
6) "6379"
7) "runid"
8) "e3deea4c66f59713d53aeab4814bb3a32e56e347"
9) "flags"
10) "slave"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "283"
19) "last-ping-reply"
20) "283"
21) "down-after-milliseconds"
22) "30000"
23) "info-refresh"
24) "602"
25) "role-reported"
26) "slave"
27) "role-reported-time"
28) "68719033"
29) "master-link-down-time"
30) "0"
31) "master-link-status"
32) "ok"
33) "master-host"
34) "47.93.235.147"
35) "master-port"
36) "6379"
37) "slave-priority"
38) "100"
39) "slave-repl-offset"
40) "14382756"
2) 1) "name"
2) "47.94.174.89:6379"
3) "ip"
4) "47.94.174.89"
5) "port"
6) "6379"
7) "runid"
8) "e47d664453f68ad8e2577b9806ef5bf0947685fc"
9) "flags"
10) "slave"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "285"
19) "last-ping-reply"
20) "285"
21) "down-after-milliseconds"
22) "30000"
23) "info-refresh"
24) "6839"
25) "role-reported"
26) "slave"
27) "role-reported-time"
28) "67467176"
29) "master-link-down-time"
30) "0"
31) "master-link-status"
32) "ok"
33) "master-host"
34) "47.93.235.147"
35) "master-port"
36) "6379"
37) "slave-priority"
38) "100"
39) "slave-repl-offset"
40) "14381484"
我们看到有两个从节点。
查看哨兵集群中其它哨兵的信息(当前哨兵不显示)
命令:sentinel sentinels <master_name>
127.0.0.1:26379> sentinel sentinels my_master
1) 1) "name"
2) "ddead28da06c11165c589575ee4293d39103e9f3"
3) "ip"
4) "47.94.174.89"
5) "port"
6) "26379"
7) "runid"
8) "ddead28da06c11165c589575ee4293d39103e9f3"
9) "flags"
10) "sentinel"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "537"
19) "last-ping-reply"
20) "537"
21) "down-after-milliseconds"
22) "30000"
23) "last-hello-message"
24) "1602"
25) "voted-leader"
26) "?"
27) "voted-leader-epoch"
28) "0"
2) 1) "name"
2) "32debec0f18d18c442804a6e2555119a871984ad"
3) "ip"
4) "47.93.39.238"
5) "port"
6) "26379"
7) "runid"
8) "32debec0f18d18c442804a6e2555119a871984ad"
9) "flags"
10) "sentinel"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "761"
19) "last-ping-reply"
20) "761"
21) "down-after-milliseconds"
22) "30000"
23) "last-hello-message"
24) "245"
25) "voted-leader"
26) "?"
27) "voted-leader-epoch"
28) "0"
检查可用的哨兵数量
命令:sentinel ckquorum <master_name>
127.0.0.1:26379> sentinel ckquorum my_master
OK 3 usable Sentinels. Quorum and failover authorization can be reached
127.0.0.1:26379>
强制故障转移
命令:sentinel failover <master_name>
127.0.0.1:26379> sentinel failover my_master
OK
127.0.0.1:26379>
在 Redis 2.8.4 之前如果需要修改哨兵集群的配置文件,例如添加或删除一个监视主节点,需要先停止哨兵集群服务,将配置文件修改之后,再重新启动才行。这样就给我们带来了很多的不便,尤其是生产环境的哨兵集群,正常情况下如果是非致命问题我们是不能手动停止服务的,幸运的是 Redis 2.8.4 之后,我们可以不停机在线修改配置文件了,修改命令有以下几个。
- 1. 可以通过 sentinel monitor <master_name> ip port quorum 来增加一个监视的主节点,返回 OK 则表示添加成功。
- 2. 可以通过 sentinel remove <master_name> 来移除一个监视的主节点,返回 OK 则表示移除成功。
- 3. 可以通过 sentinel set <master_name> quorum <n> 来修改 quorum 参数。
注意:以上所有对配置的修改,都会自动被刷新到物理配置文件 sentinel.conf 中。
思考题
1)在主从切换过程中,客户端能否正常地进行请求操作呢?
主从集群一般是采用读写分离模式,当主节点故障后,客户端仍然可以把读请求发送给从节点,让从节点服务。但是对于写请求操作,客户端就无法执行了。
2)如果想要应用程序不感知服务的中断,还需要哨兵或客户端再做些什么吗?
一方面,客户端需要能缓存应用发送的写请求。只要不是同步写操作(Redis 应用场景一般也没有同步写),写请求通常不会在应用程序的关键路径上,所以,客户端缓存写请求后,给应用程序返回一个确认就行。
另一方面,主从切换完成后,客户端要能和新主节点重新建立连接,哨兵需要提供订阅频道,让客户端能够订阅到新主节点的信息。同时,客户端也需要能主动和哨兵通信,询问新主节点的信息。
3)由 5 个哨兵实例的集群,quorum 值设为 2。在运行过程中,如果有 3 个哨兵实例都发生故障了,此时,Redis 主节点如果有故障,还能正确地判断主节点客观下线吗?如果可以的话,还能进行主从节点自动切换吗?
因为判定主节点客观下线的依据是,认为主节点主观下线的哨兵个数要大于等于 quorum 值,现在还剩 2 个哨兵实例,个数正好等于 quorum 值,所以还能正常判断主节点是否处于客观下线状态。而如果一个哨兵想要执行主从切换,就要获到半数以上的哨兵投票赞成,也就是至少需要 3 个哨兵投票赞成。但是现在只有 2 个哨兵了,所以就无法进行主从切换了。
4)哨兵实例是不是越多越好呢?如果同时调大 down-after-milliseconds 值,对减少误判是不是也有好处?
哨兵实例越多,误判率会越低,但是在判定主节点下线和选举 Leader 时,实例需要拿到的赞成票数也越多,等待所有哨兵投完票的时间可能也会相应增加,主从节点切换的时间也会变长,客户端容易堆积较多的请求操作,可能会导致客户端请求溢出,从而造成请求丢失。如果业务层对 Redis 的操作有响应时间要求,就可能会因为新主节点一直没有选定,新操作无法执行而发生超时报警。
调大 down-after-milliseconds 后,可能会导致这样的情况:主节点实际已经发生故障了,但是哨兵过了很长时间才判断出来,这就会影响到 Redis 对业务的可用性。
以上就是 Redis 哨兵集群的全部内容,总的来说内容还是蛮多的,但是都很好理解。而哨兵模式在工作中也是非常常用的,因为为了防止意外故障,我们都会采用哨兵模式进行自动监测、实现故障转移。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号