《Cython系列》6. 使用 Cython 包装 C、C++ 外部库
楔子
在前面的系列中我们知道了 Cython 如何通过提前编译的方式来对 Python 代码进行加速,这一节我们聚焦在另一个方向上:假设有一个现成的 C 源文件,那么如何才能让 Python 操作它呢?
事实上,Python 访问 C 源文件,我在其它文章中介绍过。当时的方式是将 C 源文件编译成动态库,然后通过 Python 自带的 ctypes 模块来调用它,当然除了 ctypes,还有 swig、cffi 等专门的工具。而 Cython 也是支持我们访问 C 源文件的,只不过它是通过包装的方式让我们访问。
因为 Cython 同时理解 C 和 Python,所以它可以在 Python 语言和 C 语言结合的时候控制所有的方方面面,在完成这一壮举的同时,不仅保持了 Python 的风格,还使得 Cython 代码更加容易定位和调试。
如果做得好的话,那么生成的库将具有 C 级的性能、最小的包装开销,和一个友好的 Python 接口,我们也不需要怀疑正在使用的是包装的 C 代码。那么下面就来看看 Cython 如何包装 C 源文件。
要用 Cython 包装 C 源文件,我们必须在 Cython 中声明我们使用的 C 组件的接口。为此,Cython 提供了一个 extern 语句,它的目的就是告诉 Cython,我们希望从指定的 C 头文件中使用 C 结构。语法如下:
cdef extern from "header_name":
# 相应的声明, 你希望使用哪些 C 结构, 那么就在这里声明
# 如果不需要的话可以写上一个pass
我们知道 C 头文件存放声明,C 源文件存放实现。而在 C 语言中,如果一个源文件想使用另一个源文件定义的函数,那么只需要导入相应的头文件即可,会自动去源文件中寻找对应的实现。比如在 a.c 中想使用 b.c 里面的一个函数,那么我们需要在 a.c 中 #include "b.h",然后就可以使用 b.c 里面的内容了。而对于当前的 Cython 也是同理,如果想要包装 C 源文件,那么也是要引入对应的头文件的,通过 cdef extern from 来引入,引入之后也可以在 Cython 里面直接使用,真的是非常方便,因为我们说 Cython 它同时理解 C 和 Python。此外 Cython 会在编译时检查 C 的声明是否正确,如果不正确会编译错误。
下面我们就来详细介绍 cdef extern from 怎么用,不过在介绍之前,我们需要了解一下它不会做哪些事情。
cdef extern from 语句块的目的很简单,但是乍一看可能会产生误导,首先在 Cython 中存在 extern 块(cdef extern from 声明),确保我们能够以正确的类型调用声明的 C 函数、变量、结构体等等,但是它不会自动地为这些 C 级结构创建 Python 的包装器。我们仍然需要在 Cython 中使用 def、或者 cpdef 将 extern 块中声明的 C 级结构包装一下才能给 Python 调用,否则 Python 是无法访问的。所以说 Cython 不会自动包装,我们需要手动实现这一点,而这么做的原因也很好理解,因为 Cython 中包装器的实现已经非常简单了,我们完全可以自己自定制,自动实现的话反而会任务变得复杂。
声明外部的 C 函数以及给类型起别名
extern 块中最常见的声明是 C 函数和 typedef,这些声明几乎可以直接写在 Cython 中,只需要做一下修改:
1. 将 typedef 变成 ctypedef
2. 删除类似于 restrict、volatile 等不必要、以及不支持的关键字
3. 确保函数的返回值和对应类型的声明在同一行
// 在 C 中,可以这么写,但是 Cython 中要在同一行
int
foo(){
return 123
}
4. 删除行尾的分号
此外,在 Cython 中声明函数时,参数可以写在多行,就像 Python 一样。下面我们定义一个 C 的头文件:header.h,写上一些简单的 C 声明和宏。
#define M_PI 3.1415926
#define MAX(a, b) ((a) >= (b) ? (a) : (b))
double hypot(double, double);
typedef int integral;
typedef double real;
void func(integral, integral, real);
real *func_arrays(integral[], integral[][10], real **);
如果你想在 Cython 中使用的话,那么就把那些想用的写在 Cython 中,当然我们说不能直接照搬,因为 C 和 Cython 的声明还是有些略微的差异的,上面已经介绍过了。
cdef extern from "header.h":
double M_PI
float MAX(float a, float b)
double hypot(double x, double y)
ctypedef int integral
ctypedef double real
void func(integral a, integral b, real c)
real *func_arrays(integral[] i, integral[][10] j, real **k)
注意:我们在 Cython 中声明 C 中 M_PI 这个宏时,将其声明为 double 型的变量,同理对于 MAX 宏也是如此,就把它当成接收两个 float、返回一个 float 的名为 MAX 函数。
另外我们看到在 extern 块的声明中,我们为函数参数添加了一个名字。这是推荐的,但并不是强制的;如果有参数名的话,那么可以让我们通过关键字参数调用,对于接口的使用会更加明确。
Cython 支持 C 中的所有声明,甚至函数指针接收函数指针、返回包含函数指针的数组也是可以的。当然简单的类型声明:数值、字符串、数组、指针、void 等等已经构成了 C 声明的大多数,大多数时候我们可以直接将 C 中的声明复制粘贴过来,然后去掉分号就可以了。
cdef extern from "header2.h":
ctypedef void (*void_int_fptr)(int)
void_int_fptr signal(void_int_fptr)
# 上面两行等价于 void (*signal(void(*)(int)))(int)
所以我们可以进行非常复杂的声明,当然日常也很少会用到。
声明并包装 C 结构体、共同体、枚举
如果声明一个结构体、共同体、枚举,那么可以使用如下方式:
cdef extern from "header_name":
struct struct_name:
struct_members # 创建变量的时候通过 "cdef struct_name 变量" 的方式
union struct_name:
union_members
enum struct_name:
enum_members
如果是在 C 中,等价于如下:
struct struct_name {
struct_members
}; // 创建变量的时候通过 "struct struct_name 变量" 的方式
union union_name {
union_members
};
enum enum_name {
enum_members
};
当然我们在 C 中还可以使用 typedef。
typedef struct struct_name {
struct_members
} struct_alias; // 然后创建变量的时候直接通过 "struct_alisa 变量" 即可,所以定义结构体的时候 struct_name 也可以不写
typedef union union_name {
union_members
} union_alias;
typedef enum enum_name {
enum_members
} enum_alias;
Cython 中的 typedef 则是使用 ctypedef。
cdef extern from "header_name":
ctypedef struct struct_alias:
struct_members
# 创建变量的时候通过 "cdef struct_name 变量" 的方式
# 所以无论是哪种方式,在 Cython 中创建结构体变量的时候是没有任何区别的
ctypedef union struct_alias:
union_members
ctypedef enum struct_alias:
enum_members
Cython 中的 typedef 则是使用 ctypedef,此时就定义了一个类型别名。但是注意:如果结构体中没有字段,那么 Cython 中应该要给一个 pass 语句作为占位符。
举栗说明
下面我们来实际演示一下,直接以结构体为例:
// header.h
struct Girl1 {
char * name;
int age;
};
typedef struct {
char *name;
int age;
} Girl2;
以上是一个 C 的头文件,我们在 Cython 中导入之后要怎么进行声明呢?
# cython_test.pyx
cdef extern from "header.h":
struct Girl1:
char *name
int age
ctypedef struct Girl2:
char *name
int age
# 我们说对于结构体而言, 里面的成员只能用 C 中的类型
# 而且如何创建结构体的对应实例, 我们之前也说过了, 直接 "cdef 结构体类型 变量名 = " 即可
cdef Girl1 g1 = Girl1("komeiji satori", 16)
cdef Girl1 g2 = Girl1("komeiji koishi", age=16)
# 可以看到无论是 cdef struct 定义的, 还是通过 ctypedef 起的类型别名, 使用方式没有任何区别
print(g1)
print(g2)
然后我们来进行编译,测试一下:
from distutils.core import setup, Extension
from Cython.Build import cythonize
# 我们只导入了一个头文件, 但是头文件不需要关心
ext = [Extension("cython_test",
sources=["cython_test.pyx"],
# 因为头文件和 pyx 文件就在同一个目录, 所以指定为 ["."] 即可, 也可以不指定
# 但如果当前目录中还有一个 header_file 目录, 而头文件在这里面
# 那么这里就需要指定为 ["header_file"], 否则不知道从哪里去找这个头文件, 默认从当前目录中找
# 或者你还可以这么做, 将 pyx 文件中的 extern from "header.h" 改成 extern from "header_file/header.h"
# 这样做也是可以的, 只不过一般我们会只写头文件名, 头文件的位置在编译的时候通过这里的 include_dirs 指定
include_dirs=["."])]
setup(ext_modules=cythonize(ext, language_level=3))
下面来进行导入:
import cython_test
"""
{'name': b'komeiji satori', 'age': 16}
{'name': b'komeiji koishi', 'age': 16}
"""
因为里面有 print 所以导入的时候自动打印了,我们看到 C 的结构体到 Python 中会变成字典。
有一点需要注意:我们使用 cdef extern from 导入头文件的时候,代码块里面的声明应该在 C 头文件里面存在。假设我们还想通过 ctypedef 给 int 起一个别名,而这个逻辑在 C 的头文件中是不存在的,而是我们自己想这么做,那么这个逻辑就不应该放在 cdef extern from 中,而是应该放在全局区域,否则是不起作用的。cdef extern from 里面的类型别名、声明什么的,都是根据头文件来的,我们将头文件中想要使用的放在 cdef extern from 中进行声明。而我们自己单独设置的声明、类型别名(头文件中不存在相应的逻辑)应该放在外面。
此外,除了 cdef extern from 之外,ctypedef 只能出现在全局区域(说白了就是没有缩进),像 if 语句、for 循环、while 循环、函数等等,内部都不能出现 ctypedef。
包装 C 函数
在最开始介绍斐波那契数列的时候,我们已经演示过这种方式了,再来感受一下。
// header.h
typedef struct {
char *name;
int age;
} Girl;
// 里面定义一个结构体类型 和 一个函数声明
char *return_info (Girl g);
// source.c
#include <stdio.h>
#include <stdlib.h>
#include "header.h"
char *return_info (Girl g) {
// 堆区申请一块内存
char *info = (char *)malloc(20);
// 拷贝一个字符串进去
sprintf(info, "name: %s, age: %d", g.name, g.age);
// 返回指针
return info;
}
from libc.stdlib cimport free
cdef extern from "header.h":
# C 头文件中变量的声明 和 Cython 这里的声明是很类似的
ctypedef struct Girl:
char *name
int age
# 声明函数时不需要使用 cdef
char *return_info(Girl)
# 然后我们说如果想被 Python 访问, 还需要定义一个包装器
# 我们通过 Python 无法直接调用 return_info, 因为它没有暴露给 Python
# 我们需要在 Cython 内部定义一个可以暴露给 Python 的函数, 然后在这个函数中调用 return_info
cpdef bytes info(dict d):
cdef:
# 接收一个字典
str name = d["name"]
int age = d["age"]
# 根据对应的值创建结构体实例, 但 name 需要转成 bytes 对象, 因为 char * 对应 Python 的 bytes 对象
cdef Girl g = Girl(name=bytes(name, encoding="utf-8"), age=age)
# 构造出结构体之后, 传到 C 的函数中, 得到返回值, 也就是字符串的首地址
cdef char *p = return_info(g)
# 这里需要先拷贝给 Python, 此时会根据 p 这个 char * 来创建一个 Python 的 bytes 对象, 然后让变量 res 指向
# 至于为什么不直接返回 p, 是因为 p 是在堆区申请的, 我们需要将它释放掉
res = p
free(p)
# 返回 res
return res
然后来进行编译:
from distutils.core import setup, Extension
from Cython.Build import cythonize
ext = [Extension("cython_test",
sources=["cython_test.pyx", "source.c"])]
setup(ext_modules=cythonize(ext, language_level=3))
最后调用:
import cython_test
print(cython_test.info({"name": "satori", "age": 16})) # b'name: satori, age: 16'
我们看到整体没有任何问题,但是很明显我们这个例子有点刻意了,故意兜这么一个圈子。但这么做主要是想介绍 C 和 Cython 之间的交互方式,以及 Cython 调用 C 库是有多么的方便。
当然我们还可以写一些更加复杂的逻辑,比如我们可以定义一个类,但这样也会带来一些方便之处,那就是 __dealloc__。我们把释放 C 申请在堆区的指针的逻辑写在这里面,然后当对象被销毁时会自动调用。
另外 cdef extern from 除了可以引入 C 头文件之外,还可以引入 C 源文件:
// source.c
int func(int a, int b) {
return a + b;
}
以上是一个 C 源文件,我们也是可以直接通过 cdef extern from 来引入的:
cdef extern from "source.c":
# 注意:这个 func 不能直接被 Python 调用,因为它是 C 的函数
# 并且我们说 Cython 不会自动创建包装器,需要我们手动创建
int func(int a, int b)
def py_func(int a, int b):
return func(a, b)
一旦涉及到 C 源文件,我们无法通过 pyximport.install 的方式让 import 直接导入,此时需要涉及到手动编译的过程。
from distutils.core import setup, Extension
from Cython.Build import cythonize
ext = [Extension("cython_test",
sources=["cython_test.pyx"])]
setup(ext_modules=cythonize(ext, language_level=3))
但是我们注意到在 sources 参数里面我们只写了 cython_test.pyx,并没有写 source.c。原因是它已经在 pyx 文件中通过 cdef extern from 的方式引入了,如果这里再将其指定在 sources 参数中的话,那么相当于将 source.c 里面的内容写入了两遍,在编译的时候就会出现符号多重定义的错误。但如果导入的是只存放声明头文件的话,那么为了在编译的时候能找到具体的实现,就必须要在 sources 参数中指定 C 源文件,否则编译时会出现符号找不到的错误。编译成扩展模块之后导入一下:
import cython_test
print(cython_test.py_func(22, 33)) # 55
我们看到是没有问题的,当然如果将 source.c 改成 source.h 也是可以的,也就是说把具体实现放在头文件中,那么 cdef extern from "source.h" 之后也是可以直接用的,编译时也只需要指定 pyx 文件即可。只不过规范的做法是头文件放存放声明,源文件存放具体实现,然后 cdef extern from 导入头文件,编译时在 sources 参数中指定源文件。
头文件的包含
但有时一个头文件已经被包含在另一个头文件中了,比如:在 a.h 里面引入了 b.h 和 c.h,那我们只需要 cdef extern from "a.h" 即可,然后可以同时使用 a.h、b.h、c.h 里面的内容。
// a.h
#include "b.h"
#include "c.h"
#define ADD(x, y) ((x) + (y))
// b.h
#define SUB(x, y) ((x) - (y))
// c.h
#define MUL(x, y) ((x) * (y))
在头文件中定义了一个宏,而在 Cython 我们可以看成是一个函数,而函数的类型可以是整型、浮点型,只要在 C 里面合法即可。
cdef extern from "a.h":
int ADD(int a, int b)
int SUB(int a, int b)
int MUL(int a, int b)
def py_ADD(int a, int b):
return ADD(a, b)
def py_SUB(int a, int b):
return SUB(a, b)
def py_MUL(int a, int b):
return MUL(a, b
注意:SUB 函数和 MUL 函数分别定义在 b.h 和 c.h 里面,但是我们只引入了 a.h,原因就是 a.h 里面已经包含了 b.h 和 c.h。
当然即使你像下面这么做也是可以的:
cdef extern from "a.h":
int ADD(int a, int b)
cdef extern from "b.h":
int SUB(int a, int b)
cdef extern from "c.h":
int MUL(int a, int b)
def py_ADD(int a, int b):
return ADD(a, b)
def py_SUB(int a, int b):
return SUB(a, b)
def py_MUL(int a, int b):
return MUL(a, b)
因为在 C 中允许将一个头文件 include 多次,但是毕竟 a.h 里面已经包含了所有的内容,我们直接在 cdef extern from "a.h" 里面把想要使用的 C 结构写上即可,没有必要再引入 b.h 和 c.h。如果你真的不想写在 cdef extern from "a.h"里面的话,你还可以这么做:
cdef extern from "a.h":
int ADD(int a, int b)
cdef extern from *:
int SUB(int a, int b)
cdef extern from *:
int MUL(int a, int b)
因为 SUB 和 MUL 在引入 a.h 的时候就已经在里面了,只不过我们需要显式地在 extern 块里面声明之后才能使用它。而 cdef extern from * 则表示里面的 C 结构在其它使用 cdef extern from 导入的头文件中已经存在了,因此会去别的已导入的头文件中找,所以下面的做法也是可以的:
cdef extern from "a.h":
pass
cdef extern from *:
int ADD(int a, int b)
int SUB(int a, int b)
int MUL(int a, int b)
在 Cython 中导入了头文件,但是可以不使用里面的 C 结构,并且不用的话需要使用 pass 做一个占位符。而我们将使用的 C 结构写在了 cdef extern from * 下面,表示这些 C 结构在导入的头文件中已经存在了,而我们目前只导入了 a.h,那么 ADD、SUB、MUL 就都会去 a.h 当中找,所以此时也是可以的。
导入头文件的花样还是比较多的,但最好还是以直观、清晰为主,像我们最后一种导入方式就有点刻意了。另外我们这里的头文件和 pyx 文件都在同一个目录,所以可以只通过文件名来进行导入,但是实际开发的时候基本上都会在不同的目录,而这个时候可以在编译时通过 include_dirs 指定头文件的目录。
以注释的形式嵌入 C 代码
如果你用过 CGO 的话估计你会深有体会, Go 支持以注释的形式嵌入 C 代码,而 Cython 同样是支持的,并且这些 C 代码要写在 extern 块中。当然我们说是注释其实不太准确,应该是三引号括起来的字符串,或者说 docstring 也可以。
// header.h
int add(int a, int b);
以上是一个简单的头文件,里面只有一个 add 函数的声明,但是没有具体实现,因为实现我们放在了 pyx 文件中。
cdef extern from "header.h":
"""
int add(int a, int b) {
return a + b;
}
"""
int add(int a, int b)
def my_add(int a, int b):
return add(a, b)
然后我们来进行编译:
from distutils.core import setup, Extension
from Cython.Build import cythonize
ext = [Extension("cython_test",
sources=["cython_test.pyx"])]
setup(ext_modules=cythonize(ext, language_level=3))
最后导入一下进行测试:
import cython_test
print(cython_test.my_add(6, 5)) # 11
是不是很有趣呢?直接将 C 代码写在 docstring 里面,等同于写在源文件中,另外我们说 cdef extern from 除了可以导入头文件之外,还可以导入源文件,所以上面的代码还可以再改一下。当然,虽然 Cython 支持这么做,但还是不建议这么使用
cdef extern from *:
"""
int add(int a, int b) {
return a + b;
}
"""
int add(int a, int b)
def my_add(int a, int b):
return add(a, b)
此时没有涉及到任何的头文件、源文件,但确实是合法的 Cython 代码,因为我们将 C 代码写在 docstring 中。不过显然这么做没什么意义,直接在里面通过 cdef 定义一个 C 级函数即可,没必要先用 C 定义、然后再使用 cdef extern from 引入,之所以这么做只是想表明 Cython 支持这种做法。并且当涉及到 C 时,绝大部分都不是源文件的形式,而是动态库,至于如何引入动态库后面会说,总之通过 docstring 写入 C 代码这个功能了解一下即可。
常量、其它修饰符、以及控制 Cython 生成的内容
正如我们之前的系列中提到的,Cython 理解 const 修饰符,但它在 cdef 声明中并不是有效的。它应该在 cdef extern from 语句块中使用,用来修饰一个函数的参数或者返回值。
typedef const int * const_int_ptr;
const double *returns_ptr_to_const(const_int_ptr);
如果我们在 Cython 中声明的话,应该这么做。
cdef extern from "header.h":
ctypedef const int* const_int_ptr
const double *returns_ptr_to_const(const_int_ptr)
我们看到声明真的非常类似,基本上没太大改动,只需要将 typedef 换成 ctypedef、并将结尾的分号去掉即可,但事实上即使分号不去掉在 Cython 中也是合法的,只不过这不是符合 Cython 风格的代码。
除了 const 还有 volatile、restrict,但这两个在 Cython 中是不合法的。
另外在 Cython 中,偶尔为函数、结构体使用别名是很有用的,这允许我们可以在 Cython 中以不同的名称引用一个 C 级对象,怎么理解呢?举个栗子:
// header.h
unsigned long __return_int(unsigned long);
// source.c
unsigned long __return_int(unsigned long n) {
return n;
}
我们的 C 函数前面带了两个下划线,但是我们看着别扭,再或者它和 Python 中的某个内置函数的名称、或者关键字发生冲突等等,这个时候我们需要为其指定一个别名。
cdef extern from "header.h":
# 在 C 中定义的是 __return_int, 但是这里我们为其起了一个别名叫做 return_int
# 再比如 ctypedef void klass "class", C 中定义的是 class, 但这是 Python 的关键字, 所以将其起个别名叫 klass
unsigned long return_int "__return_int"(unsigned long)
# 这个过程就你就可以看做是: C 中定义的名称是 __return_int, 这里的声明是 unsigned long return_int (unsigned long)
# 然后我们这里直接通过别名进行调用
def py_return_int(n):
return return_int(n)
编译一下进行测试,这里编译的代码不变。
import cython_test
print(cython_test.py_return_int(123)) # 123
我们看到没有任何问题,Cython 做的还是比较周密的,为我们考虑到了方方面面。这里起别名不仅仅可以对函数、ctypedef 使用,还可以是结构体、枚举之类的。
cdef extern from "header_file":
# C: struct del {int a, b}; 显然 del 是 Python 的关键字
struct _del "del":
int a, b
# C: enum yield {ALOT; SOME; ALTITLE;};
enum _yield "yield":
ALOT
SOME
ALITTLE
在任何情况下,引号中的字符串都是生成的 C 代码中的对象名,Cython 不会检查该字符串的内容,因此可以使用(滥用)这一特性来控制 C 一级的声明。
错误检测和引发异常
对于外部 C 函数而言,如果出现了异常,那么一种常见的做法是返回一个错误的状态码或者错误标志。但这些异常是在 C 中出现的异常,不是在 Cython 中出现的,因此为了正确地表示 C 中出现的异常,我们必须要对其进行包装。当在 C 中出现异常时,显式地将其引发出来。如果不这么做、而只是单纯的异常捕获的话,那么是无效的,因为 Cython 不会对 C 中出现的异常进行检测,所以在 Python 中也是无法进行异常捕获的。
而如果想做到这一点,需要将 except 字句和 cdef 回调一起绑定起来。
回调
我们说过 Cython 支持 C 函数指针,通过这个特性,我们可以包装一个接收函数指针作为回调的 C 函数。回调函数可以是不调用 Python/C API 的纯 C 函数,也可以调用任意的 Python 代码,这取决于你要实现的功能逻辑。因此这个强大的特性允许我们在运行时通过 cdef 创建一个函数来控制底层 C 函数的行为,如果能实现这个功能的话就好办了。
但涉及到跨语言边界的回调可能会变得很麻烦,因为直接调用 C 的函数会很简单,只不过 C 内部的逻辑与我们无关,只是单纯的调用。但如果说在运行时,还能对 C 内部的实现插上一脚就不是那么简单了,特别是涉及到合适的异常处理的时候。
下面举栗说明,首先在 C 的标准库 stdlib 中有一个 qsort 函数,我们希望对它进行包装,来对 Python 中的列表进行排序。
# 因为 stdlib.h 位于标准库中,所以通过 <> 可以指定 cython 编译器直接去标准库中找
cdef extern from "<stdlib.h>":
# 这是 C 里面一个用于对数组进行排序的函数, 第一个参数是数组指针
# 第二个元素是数组元素的个数, 因为数组在作为参数传递的时候会退化为指针, 所以无法通过 sizeof 计算出元素个数
# 第三个参数是元素的大小
# 第四个参数是一个回调函数, 显然是每两个元素之间进行比较的逻辑; a > b 返回正数、a < b 返回负数、a == b 返回 0
# 而这第四个参数也是我们需要从外界(Cython)进行传递的, 此时就涉及到了 Cython 和 C 之间的交互
void qsort(
void *array,
size_t count,
size_t size,
int(*compare)(const void *, const void *)
)
# 从堆区申请内存、以及释放内存, 没错, 除了 from libc.stdlib cimport malloc, free 之外我们也可以使用这种方式
# 因为这两个函数本身就在 stdlib 中
void *malloc(size_t size)
void free(void *ptr)
# 定义排序函数
cdef int int_compare(const void *a, const void *b):
cdef:
int ia = (<int *>a)[0]
int ib = (<int *>b)[0]
return ia - ib
# 因为列表支持倒序排序, 所以我们需要再定义一个倒序排序函数
cdef int int_compare_reverse(const void *a, const void *b):
# 直接在正序排序的基础上乘一个 -1 即可
return -int_compare(a, b)
# 给一个函数指针起的类型别名
ctypedef int(*qsort_cmp)(const void *, const void *)
# 一个包装器, 外界调用的是这个 pyqsort, 在 pyqsort 内部会调用 qsort
cpdef pyqsort(list x, bint reverse=False):
"""
将 Python 中的列表转成 C 的数组, 用于排序, 排序之后再将结果设置到列表中
:param x: 列表
:param reverse: 是否倒序排序
:return:
"""
cdef:
int *array
int i, N
# 计算列表长度, 并申请对应容量的内存
N = len(x)
array = <int *>malloc(sizeof(int) * N)
if array == NULL:
raise MemoryError("内存不足, 申请失败")
# 将列表中的元素拷贝到数组中
for i, val in enumerate(x):
array[i] = val
# 获取排序函数
cdef qsort_cmp cmp_callback
if reverse:
cmp_callback = int_compare_reverse
else:
cmp_callback = int_compare
# 调用 C 中的 qsort 函数进行排序
qsort(<void *> array, <size_t> N, sizeof(int), cmp_callback)
# 调用 qsort 结束之后, array 就排序好了, 然后再将排序好的结果设置在列表中
for i in range(N):
# 注意: 此时不能对 array 使用 enumerate, 因为它是一个 int *
x[i] = array[i]
# 此时 Python 中的列表就已经排序好了
# 别忘记最后将 array 释放掉
free(array)
我们说当导入自定义的 C 文件时,应该通过手动编译的方式,否则会找不到相应的文件。但这里我们导入的是标准库中的头文件,不是我们自己写的,所以可以不用编译,通过 pyximport 的方式即可实现导入。
import pyximport
pyximport.install(language_level=3)
import random
import cython_test
# 我们看到此时的 pyqsort 和 内置函数 一样, 都属于 built-in function 级别的, 是不是很有趣呢
print(cython_test.pyqsort) # <built-in function pyqsort>
print(max) # <built-in function max>
print(isinstance) # <built-in function isinstance>
print(getattr) # <built-in function getattr>
# 然后我们来看看结果如何吧, 是不是能起到排序的效果呢
lst = [random.randint(10, 100) for _ in range(10)]
print(lst) # [65, 36, 12, 84, 97, 15, 19, 86, 11, 78]
# 排序
cython_test.pyqsort(lst)
# 再次打印
print(lst) # [11, 12, 15, 19, 36, 65, 78, 84, 86, 97]
# 然后倒序排序
cython_test.pyqsort(lst, reverse=True)
print(lst) # [97, 86, 84, 78, 65, 36, 19, 15, 12, 11]
目前看起来一切顺利,没有任何障碍,而且我们在外部自己实现了一个内置函数,这是非常了不起的。
但是如果出现了异常呢?我们目前还没有对异常进行处理,现在我们将逻辑改一下。
cdef int int_compare_reverse(const void *a, const void *b):
# 其它地方完全不变, 只是在用于倒序排序的比较函数中加入一行 [][3], 故意引发一个索引越界
[][3]
return -int_compare(a, b)
然后我们再调用它,看看会有什么现象:
import pyximport
pyximport.install(language_level=3)
import cython_test
cython_test.pyqsort([2, 1, 3], reverse=True)
"""
IndexError: list index out of range
Exception ignored in: 'cython_test.int_compare_reverse'
Traceback (most recent call last):
File "D:/satori/1.py", line 7, in <module>
cython_test.pyqsort(lst, reverse=True)
IndexError: list index out of range
IndexError: list index out of range
Exception ignored in: 'cython_test.int_compare_reverse'
Traceback (most recent call last):
File "D:/satori/1.py", line 7, in <module>
cython_test.pyqsort(lst, reverse=True)
IndexError: list index out of range
IndexError: list index out of range
Exception ignored in: 'cython_test.int_compare_reverse'
Traceback (most recent call last):
File "D:/satori/1.py", line 7, in <module>
cython_test.pyqsort(lst, reverse=True)
IndexError: list index out of range
"""
我们看到,明明出现了索引越界错误,但是程序居然没有立刻停下来,而是被忽略掉了。而每一次排序都需要调用这个函数,所以出现了多次 IndexError。但我们说虽然出现了异常,但不影响程序的执行,如果你再最后加上一个 print 逻辑,会发现它依旧正常打印,这显然不是我们想要的。那么下面我们就来解决它。
异常传递
我们上面的索引越界是在 int_compare_reverse 中设置的,而它的调用是发生在什么地方呢?显然是发生在 C 中,因为它很明显是作为回调传递给了 qsort 这个 C 函数。所以 int_compare_reverse 中的索引越界是在执行 C 的 qsort 函数时候发生的,而不是在 Cython 中,如果发生的地点是在 Cython 中,那么会直接引发错误,当然也可以异常捕获,和 Python 没有任何区别。但不幸的是,这个函数是一个传递给 C 的回调函数,它是在 C 中被调用的。而为了解决这一点, Cython 提供了一个 except * 字句来帮我们更好的处理异常。举个栗子:
cdef int int_compare_reverse(const void *a, const void *b) except *:
[][3]
return -int_compare(a, b)
只需要在结尾加上一个 except *,那么便可自动实现异常的传递。看到这个 except 是不是有点熟悉呢?我们之前在介绍 C 中的除法时,说如果返回值是 C 的类型、并且 C 中的整型发生除以 0 的情况,异常不会向上抛,我们需要在函数的结尾指定 except ? -1,来充当一个哨兵。这里也是与之类似的,通过指定 except *,使得它在作为回调函数的时候,如果内部发生了异常,能够转成传递给 Cython。但是这样还是不够的,因为这样会导致类型不匹配:
cdef extern from "stdlib.h":
void qsort(
void *array,
size_t count,
size_t size,
# 这里也需要加上 except *, 因为类型要一致
int(*compare)(const void *, const void *) except *
)
void *malloc(size_t size)
void free(void *ptr)
# 显然这里也要加上 except *
cdef int int_compare(const void *a, const void *b) except *:
cdef:
int ia = (<int *>a)[0]
int ib = (<int *>b)[0]
return ia - ib
cdef int int_compare_reverse(const void *a, const void *b) except *:
[][3]
return -int_compare(a, b)
# 这里也是如此, 否则类型不匹配
ctypedef int(*qsort_cmp)(const void *, const void *) except *
然后我们再来调用一下试试:
import pyximport
pyximport.install(language_level=3)
import cython_test
lst = [2, 1, 3]
cython_test.pyqsort(lst, reverse=True)
"""
Traceback (most recent call last):
File "cython_test.pyx", line 21, in cython_test.int_compare_reverse
[][3]
IndexError: list index out of range
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "D:/satori/1.py", line 7, in <module>
cython_test.pyqsort(lst, reverse=True)
SystemError: <built-in function pyqsort> returned a result with an error set
"""
我们看到此时程序就直接终止了,因为虽然错误在 C 中出现的,但是它传递给了 Cython,所以程序终止了。而且 Cython 在接收到这个异常时,并没有原原本本的直接输出,而是又引发了一个 SystemError,因为它是在 C 中出现的。
总结一下:Python 在调用 Cython 时(可以是 pyx、pyd),如果发生了异常,那么就看这个异常是在哪里发生的。如果是在 Cython 中,那么和纯 Python 中发生异常时的表现是一样的,可以使用 try except 进行异常捕获。但如果是在 C 中发生的(出现这种情况的可能性非常有限,基本上都是作为 C 函数的一个回调函数,在 C 函数中调用这个回调函数引发异常),那么异常不会导致程序停止、也无法进行异常捕获(因为异常会被忽略掉),我们需要在回调函数的结尾加上 except *,来使得在 C 中发生异常时能够传递给 Cython。
如果我们这里的索引越界是在 pyqsort 中出现的,那么直接就会出现 IndexError,程序终止。因为我们说,异常在 Cython 中的表现和 Python 是一模一样的。
异常的传递真的是非常的不容易,通过 except * 这种方式,使得 Cython 中即可以定义一个 C 函数的回调函数、还能在出现异常的时候传递给 Cython,这个过程真的是走了很长的一段路。
在 Cython 中引入 C艹
下面来看看如何在 Cython 中引入 C++,由于我本人不擅长 C++,所以细节的东西就不说了,这里主要介绍如何编译。
# distutils: language=c++
from libcpp.vector cimport vector
from libcpp.map cimport map
cdef vector[int] vect
cdef int i
for i in range(3):
vect.push_back(i) # 类似于 Python 列表的 append
for i in range(3):
print(vect[i])
cdef map[int, int] m
m[123] = 456
print(m[123])
注意:看一下最上面的注释,如果想要编译成功,那么必须要在开头加上 # distutils: language=c++。并且一定要通过 setup 进行编译,采用 pyximport 是会失败的。
然后我们来测试一下。
import cython_test
"""
0
1
2
456
"""
C++ 中的异常
然后是 C++ 中的异常,Cython 无法抛出 C++ 中的异常,并且也无法使用 try-except 语句进行捕获。但是我们可以进行特殊的声明,当 C++ 函数中引发异常的时候能够转化成 Python 的异常。先来看看 C++ 的异常和 Python 的异常之间的对应关系:

假设在 C++ 的函数中可能引发 bad_cast,那么我们在声明函数时就可以这么做:
cdef extern from "some_file.h":
int foo() except +TypeError
然后我们在调用 C++ 函数的时候,就可以进行异常捕获了,但如果我们不确定会引发什么错误,那么声明的时候通过 except +* 的方式即可,相当于 Python 的 Exception。
引入静态库和动态库
引入 C 源文件我们已经知道该怎么做了,但如果我们引入的不是源文件,而是已经存在的静态库或者动态库该怎么办呢?C 语言发展到现在已经拥有非常多成熟的库了,我们可以直接拿来用,这些库可以是静态库、也可以是动态库,这个时候 Cython 要如何和它们勾搭在一起呢?
要搞清楚这一点,我们需要先了解静态库和动态库。并且一个 C 源文件可以被编译成一个可执行文件,那么我们还需要先搞清楚在将 C 文件编译成可执行文件的时候静态库和动态库是如何起作用的。所以暂时不提 Cython,先来说一下静态库和动态库。
在 Windows 上静态库是以 .lib 结尾、动态库是以 .dll 结尾;在 Linux 上静态库则以 .a 结尾、动态库以 .so 结尾。
假设我们有一个 C 源文件 main.c,那么只需要通过 gcc main.c -o main.exe 即可编译成可执行文件( 如果只写 gcc main.c,那么 Windows 上会默认生成 a.exe、Linux 上会默认生成 a.out ),但是这一步可以拆解成如下步骤:
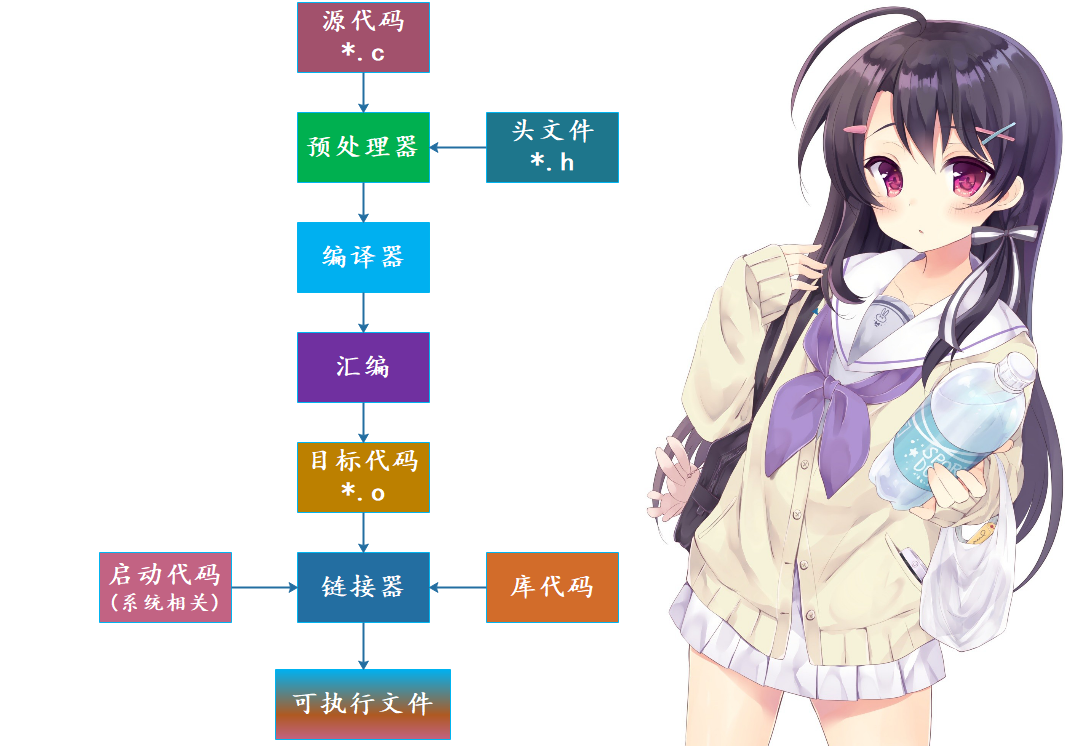
- 预处理:gcc -E main.c -o main.i,根据 C 源文件得到预处理之后的文件,这一步只是对 main.c 进行了预处理:比如宏定义展开、头文件展开、条件编译等等,同时将代码中的注释删除,注意:这里并不会检查语法;
- 编译:gcc -S main.i -o main.s,将预处理后的文件进行编译、生成汇编文件,这一步会进行语法检测、变量的内存分配等等;
- 汇编:gcc -c main.s -o main.o,根据汇编文件生成目标文件,当然我们也可以通过 gcc -c main.c -o main.o 直接通过 C 源文件得到目标文件;
- 链接:gcc main.o -o main.exe,程序是需要依赖各种库的,可以是静态库也可以是动态库,因此需要将目标文件和其引用的库链接在一起,最终才能构成可执行的二进制文件。
所以从 C 源文件到可执行文件会经历以上几步,不过我们一般都会将这几步组合起来,整体称之为编译。比如我们常说,将某个源文件编译成可执行文件。
因此我们看到静态库和动态库是在链接这一步发生的,比如我们在 main.c 中引入了 stdio.h 这个头文件,里面的函数( 比如 printf )不是我们自己实现的,所以在编译成可执行文件的时候还需要将其链接进去。
所以静态库和动态库的作用都是一样的,都是和汇编生成的目标文件( .o 文件)搅和在一起,共同组合生成可执行文件。那么它们之间有什么区别呢?
注:我当前使用的操作系统是 Windows,但是在 Windows 上如何操作静态库和动态库,个人不是很熟悉,因此这一部分会使用 Linux。至于 Windows 如何操作,有兴趣可以自己了解一下。或者哪天我研究研究再补充上去。
静态库
一个静态库可以简单看成是一组目标文件的集合,也就是多个目标文件经过压缩打包之后形成的文件。而静态库最大的特点就是一旦链接成功,那么就可以删掉了,因为它已经链接到生成的可执行文件中了。所以从侧面也可以看出使用静态库比较浪费空间和资源,说白了就是生成的可执行文件会比较大,因为里面还包含了静态库。
而在 Linux 中静态库是有命名规范的,必须以 lib 开头、.a 结尾,假设你想生成一个名字为 hello 的静态库,那么它的文件名就必须是 libhello.a,这是一个规范。而在 Linux 中生成静态库的方式如下:
先得到目标文件:gcc -c 源文件 -o 目标文件,这里要指定 -c 参数,否则生成的就是可执行文件,例如 gcc -c test.c -o test.o通过 ar 工具构建静态库:ar rcs libtest.a test.o,此时就得到的静态库 test,但是我们说在 Linux 中静态库是有格式要求的,必须以 lib 开头、.a 结尾,所以是 libtest.a
我们来做一个测试,首先是编写一个 C 文件 test.c,里面内容如下:
// 计算 start 到 end 之间所有整数的和
int sum(int start, int end) {
int res = 0;
for (; start <= end; start++) {
res += start;
}
return res;
}
执行命令:
[root@satori ~]# gcc -c test.c -o test.o
[root@satori ~]# ar rcs libtest.a test.o
[root@satori ~]# ls | grep test.
libtest.a
test.c
test.o
[root@satori ~]#
此时 libtest.a 就成功生成了,然后我们再来编写一个 main.c 直接调用:
#include <stdio.h>
int sum(int, int);
int main() {
printf("%d\n", sum(1, 100));
}
我们看到只是声明了 sum,但是具体实现则没有编写,因为它已经在 libtest.a 中实现了,我们只需要在使用 gcc 编译的时候指定即可。
[root@satori ~]# gcc main.c -L . -l test -o main
[root@satori ~]# ./main
5050
[root@satori ~]#
可以看到执行成功了,打印结果也是正确的,但是这里需要解释一下里面的参数。首先 gcc main.c 无需解释,表示对 main.c 文件进行编译。而结尾的 -o main 也无需解释,表示指定生成的可执行文件名叫 main。
中间的 -L . 表示追加库文件的搜索路径,因为 gcc 在寻找库的时候,只会从标准位置进行查找。而我们当前所在目录明显不属于标准位置,因此需要通过 -L 参数将我们写好的静态库所在的路径追加进去,而 libtest.a 位于当前目录,所以是 -L .。
然后是 -l test,首先 -l 表示要链接的静态库(也可以是动态库,后面会说,目前就只看静态库即可),因为我们的静态库名字叫做 libtest.a,那么把开头的 lib 和结尾的 .a 去掉再和 -l 进行组合即可。如果我们再将静态库改名为 libxxx.a 的话,那么就需要指定 -l xxx;同理,要是我们指定的是 -l foo,那么在链接的时候会自动寻找 libfoo.a。所以从这里也能看出,在 Linux 中创建静态库的时候一定要遵循命名规范,以 lib 开头、.a 结尾,否则链接是会失败的。当然追加搜索路径、链接静态库的数量是没有限制的,比如除了 libtest.a 之外你还想链接 libfoo.a,那么就指定 -l test -l foo 即可。
注:
-l test也可以写成-ltest,即中间没有空格,这种写法更为常见。这里个人为了清晰,之间加了一个空格,对于编译而言是没有影响的。
同理还有头文件,虽然这里没有涉及到,但还是需要说一说,因为导入头文件更常见。如果想导入的头文件不在搜索路径中,我们在编译的时候也是需要指定的。假设 main.c 还引入了一个头文件,其位于当前目录下的 header 目录里,那么编译的时候为了让编译器能够找得到,我们需要通过 -I 来追加相应头文件的路径:
gcc main.c -I ./header -L . -l test -o main
对于头文件搜索路径、库文件搜索路径、引入的静态库的数量,都是没有限制的,可以指定任意个:-I、-L、-l。
动态库
通过静态库,我们算是实现了代码复用,而且静态库的使用也比较方便。那么问题来了,既然有了静态库,为什么我们还要使用动态库呢?首先是资源浪费,假设有一个静态库大小的是 1M,而它被 1000 个可执行程序依赖,那么这个静态库就相当于被拷贝了 1000 份,因为静态库是需要被链接到可执行文件当中的;然后是静态库的更新和部署会带来麻烦,假设静态库更新了,那么所有使用它的应用程序都必须重新编译、然后发布给用户。即使只改动了一小部分,也要重新编译生成可执行文件,因为要重新链接静态库。
所以我们有了动态库,动态库在链接的时候不会将自身的内容包含在可执行文件中,而是在程序运行的时候动态加载。相当于只是告诉可执行文件:"你的内部会依赖我,但由于哥是动态库,因此我不会像静态库一样被包含在你的内部,而是需要你运行的时候再去查找、加载"。所以多个可执行文件可以共享同一个动态库,因此也就避免了空间浪费的问题,并且动态库是程序运行时动态加载的,因此我们对动态库做一些更新之后可以不用重新编译生成可执行文件。
有优点就自然有缺点,相信都看出来了,既然是动态加载,就意味着即使在编译成可执行文件之后,依赖的动态库也不能丢。和静态库不同,静态库和最终的可执行文件是完全独立的,因为在编译成可执行文件的时候静态库里面的内容就已经被链接在里面了;而动态库是要被动态加载的,因此它是被可执行文件所依赖的,所以不能丢。
然后我们来生成一下动态库,生成动态库要比生成静态库简单许多:gcc 源文件 -shared -o 动态库文件,还是以之前的 test.c 为例:
gcc test.c -shared -o libtest.so
在 Linux 中,动态库也具有相同的命令规范,只不过它是以 .so 结尾。但是你真的不按照这个格式命名也是可以的,只不过你在使用 gcc 的时候会找不到相应的库。因为编译的时候会按照指定格式去查找库文件,所以我们在生成库文件的时候也要按照相同的格式起名字。
然后使用 gcc 对之前的 main.c 源文件进行编译,命令一模一样,不需要有任何的改变。
[root@satori ~]# gcc test.c -shared -o libtest.so
[root@satori ~]# ls libtest.so
libtest.so
[root@satori ~]# gcc main.c -L . -l test -o main1
[root@satori ~]#
我们看到可执行文件成功生成了,这里起名为 main1,引入动态库和引入静态库的方式是一样的。因为我们之前说过 -l 可以链接静态库、也可以链接动态库(要是静态库和动态库都有怎么办?别急,后面说,目前只考虑动态库)。
[root@satori ~]# ./main1
./main1: error while loading shared libraries: libtest.so: cannot open shared object file: No such file or directory
但是问题来了,虽然编译成功了,但是执行的时候却报错了,原因是找不到这个 libtest.so,尽管它就在当前可执行文件所在的目录下。
原因是可执行文件在查找动态库的时候也是会从指定的位置进行查找的,而我们当前目录不在搜索范围内,这时候可能有人会好奇,我们不是在编译的时候通过 -L 参数将当前路径追加进去了吗?答案是动态库和静态库不同,动态库在链接的时候自身不会被包含在可执行文件当中,我们指定的 -L . -l test 相当于只是在链接的时候告诉即将生成的可执行文件:"在当前目录下有一个 libtest.so,它将来会是你的依赖,你赶紧记录一下"。我们可以通过 ldd 命令查看可执行文件依赖的动态库:
[root@satori ~]# ldd main1
linux-vdso.so.1 => (0x00007ffe67379000)
libtest.so => not found
libc.so.6 => /lib64/libc.so.6 (0x00007f8d89bf9000)
/lib64/ld-linux-x86-64.so.2 (0x00007f8d89fc6000)
[root@satori ~]#
我们看到 libtest.so 已经被记录下来了,所以链接动态库时只是记录了动态库的信息,当程序执行时再去动态加载,因此它们会有一个指向。但我们发现 libtest.so 指向的是 not found,这是因为动态库 libtest.so 不在可执行文件执行时的动态库查找路径中,所以会指向 not found。因此我们还需要将当前目录加入到动态库查找路径中,vim /etc/ld.so.conf,将当前目录( 我这里是 /root )写在里面。
或者直接 echo "/root" >> /etc/ld.so.conf
然后执行 /sbin/ldconfig 使得修改生效。
最后再来重新执行一下 main1,看看结果如何:
[root@satori ~]# echo "/root" >> /etc/ld.so.conf
[root@satori ~]# /sbin/ldconfig
[root@satori ~]#
[root@satori ~]# ./main1
5050
可以看到此时也是成功执行了,因此我们发现使用动态库实际上会比静态库要麻烦一些,因为静态库在编译的时候就通过 -L 和 -l 参数直接把自身链接到可执行文件中了。而动态库则不是这样,用大白话来说就是它在链接的时候并没有把自身内容加入到可执行文件中,而是告诉可执行文件自己的信息、然后让其执行时再动态加载。但是加载的时候,为了让可执行文件能加载的到,我们还需要将动态库的路径配置到 /etc/ld.so.conf 中。
[root@satori ~]# ldd main1
linux-vdso.so.1 => (0x00007ffdbc324000)
libtest.so => /root/libtest.so (0x00007fccdf5db000)
libc.so.6 => /lib64/libc.so.6 (0x00007fccdf20e000)
/lib64/ld-linux-x86-64.so.2 (0x00007fccdf7dd000)
[root@satori ~]#
此时 libtest.so 就指向 /root/libtest.so 了,而不是 not found。虽然麻烦,但是我们说它更省空间,因为此时只需要有一份动态库,如果可执行文件想用的话直接动态加载即可。除此之外,我们说修改了动态库之后,原来的可执行文件不需要重新编译:
int sum(int start, int end) {
int res = 0;
for (; start <= end; start++) {
res += start;
}
return res + 1;
}
这里我们将返回的 res 加上一个 1,然后重新生成动态库:
[root@satori ~]# ./main1
5050
[root@satori ~]# gcc test.c -shared -o libtest.so
[root@satori ~]# ./main1
5051
我们看到结果变成了 5051,我们并没有对可执行重新编译,原因就是动态库的内容不是嵌入在可执行文件中的,而是可执行文件执行时动态加载的。如果是静态库的话,那么就需要重新编译生成可执行文件了。
同时指定静态库和动态库
我们发现无论是静态库 libtest.a 还是 libtest.so,在编译时都是通过 -l test 进行链接的。那如果内部同时存在 libtest.a 和 libtest.so,-l test 是会去链接 libtest.a 还是会去链接 libtest.so 呢?这里可以猜一下,首先我们上面所有的操作都是在 /root 目录下进行的,而且文件都没有删除:
[root@satori ~]# ls | grep test.
libtest.a
libtest.so
test.c
test.o
[root@satori ~]#
相信结果很好猜,我们介绍静态库的时候已经生成了 libtest.a,然后 -l test 找到了 libtest.a 这没有任何问题;然后介绍动态库的时候又生成了 libtest.so,但是并没有删除当前目录下的 libtest.a,而 -l test 依然会去找 libtest.so,说明了 -l 会优先链接动态库。如果当前目录不存在相应的动态库,才会去寻找静态库,但是问题来了,如果同时存在静态库和动态库的时候,我就想链接静态库的话该怎么做呢?
# 修改配置,将当前目录给去掉
[root@satori ~]# vim /etc/ld.so.conf
[root@satori ~]# /sbin/ldconfig
[root@satori ~]#
[root@satori ~]# gcc main.c -L . -l test -o main2
[root@satori ~]# ./main2
./main2: error while loading shared libraries: libtest.so: cannot open shared object file: No such file or directory
[root@satori ~]#
# 如果执行下面这行命令报错了:/usr/bin/ld: cannot find -lc,那么执行 yum install glibc-static 即可
# 因为高版本的 Linux 系统下安装 glibc-devel、glibc 和 gcc-c++ 时不会安装libc.a,而是只安装libc.so
# 所以当使用 -static 时,libc.a 不能使用,因此报错 "找不到 lc"
[root@satori ~]# gcc main.c -L . -static -l test -o main2
[root@satori ~]# ./main2
5050
[root@satori ~]#
我们在 /etc/ld.so.conf 中将当前目录给删掉了,所以此时编译成可执行文件之后执行就报错了,因为找不到 libtest.so,证明默认加载的确实是动态库。然后我们可以通过 -static,强制让 gcc 链接静态库,此时就执行成功了,由于 libtest.a 之前就已经生成了,所以结果还是原来的 5050。并且我们说在链接的时候静态库会被包含在可执行文件中,因此即使后续将 libtest.a 删掉也不影响可执行文件。
[root@satori ~]# rm -rf libtest.a
[root@satori ~]# ./main2
5050
[root@satori ~]#
这里再提一个问题:" 链接 libtest.a 生成的可执行文件 " 和 " 链接 libtest.so 生成的可执行文件" 哪一个占用的空间更大呢?好吧,这个问题问的有点白痴了,很明显示前者更大,但是究竟大多少呢?我们来比较一下吧。
# 链接 libtest.a
[root@satori ~]# size main2
text data bss dec hex filename
770336 6228 8640 785204 bfb34 main2
[root@satori ~]#
[root@satori ~]# gcc main.c -L . -l test -o main2
# 链接 libtest.so
[root@satori ~]# size main2
text data bss dec hex filename
1479 564 4 2047 7ff main2
[root@satori ~]#
我们看到大小确实差的不是一点半点,再加上静态库是每一个可执行文件内部都要包含一份,可想而知空间占用量是多么恐怖😱,所以才要有动态库。因此静态库和动态库各有优缺点,具体使用哪一种完全由你自己决定,就我个人而言更喜欢静态库,因为非常的方便,生成可执行文件之后就不用再管了(尽管对空间占用有点不负责任)。
Cython 和 静态库结合
然后回到我们的主题,我们的重点是 Cython 和 它们的结合,当然先对静态库和动态库有一定的了解是有必要的。下面来看看 Cython 要如何引入静态库,这里我们还是编写斐波那契数列,然后生成静态库。当然为了追求刺激,这里采用 CGO 进行编写。
// 文件名 go_fib.go
package main
import "C"
import "fmt"
//export go_fib
func go_fib(n C.int) C.double {
var i C.int = 0
var a, b C.double = 0.0, 1.0
for ; i < n; i++ {
a, b = a + b, a
}
fmt.Println("斐波那契计算完毕,我是 Go 语言")
return a
}
func main() {}
关于 CGO 这里不做过多介绍,你也可以使用 C 来编写,效果是一样的。然后我们来使用 go build 根据 go 源文件生成静态库:
go build -buildmode=c-archive -o 静态库文件 go源文件
[root@satori ~]# go build -buildmode=c-archive -o libfib.a go_fib.go
[root@satori ~]#
然后我们还需要一个头文件,这里定义为 go_fib.h:
double go_fib(int);
里面只需要放入一个函数声明即可,具体实现在 libfib.a 中,然后编写 Cython 源文件:
cdef extern from "go_fib.h":
double go_fib(int)
def fib_with_go(n):
"""调用 Go 编写的斐波那契数列,以静态库形式存在"""
return go_fib(n)
我们看到对于头文件和 Cython 文件来说并没有什么变化,函数的具体实现逻辑是以源文件形式存在、还是以静态库形式存在,实际上并不关心。因此我们的重担显然就要就落在调用 Extension 和 setup 上面了。
# 文件名:1.py
from distutils.core import setup, Extension
from Cython.Build import cythonize
# 这里我们不能在 sources 里面写上 ["fib.pyx", "libfib.a"] 这是不合法的,因为 sources 里面需要放入源文件
# 静态库和动态库需要通过 library_dirs 和 libraries 指定
ext = Extension(name="wrapper_gofib",
sources=["fib.pyx"],
# 相当于 -L 参数,路径可以指定多个
library_dirs=["."],
# 相当于 -l 参数,链接的库可以指定多个
# 注意:不能写 libfib.a,直接写 fib 就行,所以命名还是需要遵循规范,要以 lib 开头、.a 结尾,
libraries=["fib"]
# 如果还需要头文件的话,那么通过 include_dirs 指定
# 只不过由于头文件就在当前目录中,所以我们不需要指定
)
setup(ext_modules=cythonize(ext, language_level=3))
然后我们执行 python3 1.py build,因为我现在使用的是 Linux,所以需要输入 python3,要是输入 python 会指向 python2。
其实我们这里叫 1.py 是不符合规范的,实际工作中应该命名为 setup.py,当然起什么名字对编译生成扩展模块来说是没有任何影响的。
执行成功之后,会生成一个 build 目录,我们将里面的扩展模块移动到当前目录,然后进入交互式 Python 中导入它,看看会有什么结果。

此时我们就将 Cython、Go、C、Python 给结合在一起了,当然你可以再加入 C 源文件、或者 C 生成的库文件,怎么样,是不是很好玩呢。如果我们用 Go 写了一个程序,那么就可以通过编译成静态库的方式,嵌入到 Cython 中,然后再生成扩展模块交给 Python 调用。之前我本人也将 Python 和 Go 结合起来使用过,只不过是当时是编译成的动态库,然后通过 Python 的 ctypes 模块调用的。
但是注意:无论是这里的静态库还是一会要说的动态库,我们举的例子都会比较简单。但是实际上我们使用 CGO 的话,内部是可以编写非常复杂的逻辑的,因此我们需要注意 Go 和 C 之间内存模型的差异。因为 Python 和 Go 之间是无法直接结合的,但是它们都可以和 C 勾搭上,所以需要 C 在这两者之间搭一座桥。
但是不同的语言的内存模型是不同的,因此当跨语言操作同一块内存时需要格外小心,比如:Go 的导出函数不能返回 Go 的指针等等。所以里面的细节还是比较多的,当然我们这里的主角是 Cython,因此 Go 就不做过多介绍了。
Cython 和 动态库结合
然后是 Cython 和 动态库结合,显然我们已经猜到了,只需要生成 libfib.so 即可,然后其它地方不需要做任何改动。我们还用刚才的 go_fib.go,而 Go 生成动态库的命令如下:
go build -buildmode=c-shared -o 动态库文件 go源文件
[root@satori ~]# go build -buildmode=c-shared -o libfib.so go_fib.go
[root@satori ~]#
然后其它地方不做任何改动,直接执行 python3 1.py build 生成扩展模块即可,因为加载动态库和加载静态库的逻辑是一样的。而我们的动态库和刚才的静态库的名字也保持一致,所以整体不需要做任何改动。

整体效果和 C 使用动态库的表现是一致的,仍然优先寻找动态库,并且还要将动态库所在路径加入到 ld.so.conf 中。当然我们这里使用 Go 来生成库文件实际上有点刻意了,因为主要是想展现 Cython 的强大之处。但其实使用 C 来生成库文件也是一样的,因为我们使用 Go 本质上也是将 Go 的代码转成 C 的代码(因此叫 CGO),只不过用 Go 写代码肯定比用 C 写代码舒服,毕竟 Go 是一门带垃圾回收的高级语言。至于 Go 和 C 之间怎么转,那就不需要我们来操心了,Go 编译器会为我们处理好一切。正如我们此刻学习 Cython 一样,用 Cython 写扩展肯定比用 C 写扩展舒服,而 Cython 代码同样也是要转成 C 的代码,至于怎么转,也不需要我们来操心,cython 编译器会为我们处理好一切。
以上就是 Cython 和库文件(静态库、动态库)之间的结合,注:以上关于 Cython 引入库文件相关操作都是基于 Linux,至于 Windows 如何引入库文件个人不是很熟悉。
总结
在最开始我们就说过,其实可以将 Cython 当成两个身份来看待:如果将 Python 编译成 C,那么可以看成 Cython 的 '阴';如果将 Python 作为胶水连接 C 或者 C++,那么可以看成是 Cython 的 '阳'。但其实两者之间并没有严格的区分,一旦在 cdef extern from 块中声明了 C 函数,就可以像使用 Cython 本身定义的常规 cdef 函数一样使用。并且对外而言,在使用 Python 调用时,没有人知道里面的方法是我们自己辛辛苦苦编写的,还是调用了其它已经存在的。
这次我们介绍 Cython 的一些接口特性和一些使用方法,感受一下它包装 C 函数是多么的方便。而 C 已经存在很多年了,拥有大量经典的库,通过 Cython 我们可以很轻松地调用它们。
当然不只是 C,Cython 还可以调用使用同样广泛的 C++ 中的库函数,但是由于我本人不擅长 C++,因此有兴趣可以自己了解。不过调用的方式和调用 C 是类似的,如果你会 C++,那么你应该很清楚这一点。因此后面,我们就来介绍 Cython 中如何使用 Numpy,以及如何实现一个和 Numpy 中一样快的算法。至于 Cython 如何调用 C++ 有兴趣可以自己了解,这里因为我个人原因就不说了。

王来呼吸,王来雷普,王来斯哈整个世界。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号