《Cython系列》5. Cython 模块之间的相互导入,组织你的 Cython 代码
楔子
我们之前在介绍 Cython 语法的时候,一直都是一个 pyx 文件,而且文件名也一直叫 cython_test.pyx 就没变过,但如果是多个 pyx 文件改怎么办?怎么像 Python 那样进行导入呢?
Python 提供了 modules 和 packages 来帮助我们组织项目,这允许我们将函数、类、变量等等,按照各自的功能或者实现的业务,分组到各自的逻辑单元中,从而使项目更容易理解和定位。并且模块和包也使得代码重用变得容易,在 Python 中我们使用 import 语句访问其它 module 和 package 中的函数。
而 Cython 也支持我们将项目分成多个模块,首先它完全支持 import 语句,并且含义与 Python 中的含义完全相同。这就允许我们在运行时访问外部纯 Python 模块中定义的 Python 对象,或者其它扩展模块中定义的可以被访问的 Python 对象。
但故事显然没有到此为止,因为只有 import 的话,Cython 是不允许两个模块访问彼此的 cdef、cpdef 定义的函数、ctypedef、struct 等等,也不允许访问对其它的扩展类型进行 C 一级的访问。比如:cython_test1.pyx 和 cython_test2.pyx ,这两个文件之间无法通过 import 互相访问,当然 cimport 也无法实现这一点。
而为了解决这一问题,Cython 提供了相应类型的文件来组织 Cython 文件以及 C 文件。到目前为止,我们一直使用扩展名为 .pyx 的 Cython 源文件,它是包含代码的逻辑的实现文件,但是除了它还有扩展名为 .pxd 的文件。
pxd 文件你可以想象成类似于 C 中的头文件,用于存放一些声明之类的,而 Cython 的 cimport 就是从 pxd 文件中进行属性导入。
这一节我们就来介绍 cimport 语句的详细信息,以及 .pyx、.pxd 文件之间的相互联系,我们如何使用它们来构建更大的 Cython 项目。有了 cimport 和这两种类型的文件,我们就可以有效地组织 Cython 项目,而不会影响性能。
Cython的实现文件(.pyx文件)和声明文件(.pxd文件)
我们目前一直在处理 .pyx 文件,它是我们编写具体 Cython 代码的文件,当然它和 py 文件是等价的。如果的 Cython 项目非常小,并且没有其它代码需要访问里面的 C 级结构,那么一个 .pyx 文件足够了。但如果我们想要共享 pyx 文件中的 C 级结构,那么就需要 .pxd 文件了。
假设我们的文件还叫 cython_test.pyx。
from libc.stdlib cimport malloc, free
ctypedef double real
cdef class Girl:
cdef public :
str name # 姓名
long age # 年龄
str gender # 性别
cdef real *scores # 分数, 这里我们的 double 数组长度为3, 但是 real * 不能被访问,所以它不可以使用 public
def __cinit__(self, *args, **kwargs):
self.scores = <real *> malloc(3 * sizeof(real))
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def __dealloc__(self):
if self.scores != NULL:
free(self.scores)
cpdef str get_info(self):
return f"name: {self.name}, age: {self.age}, gender: {self.gender}"
cpdef set_score(self, list scores):
# 虽然 not None 也可以写在参数后面, 但是它只适用于 Python 函数, 也就是 def 定义的函数
assert scores is not None and len(scores) == 3
cdef real score
cdef long idx
for idx, score in enumerate(scores):
self.scores[idx] = score
cpdef list get_score(self):
cpdef list res = [self.scores[0], self.scores[1], self.scores[2]]
return res
目前来讲,由于所有内容都在一个 pyx 文件里面,因此任何 C 级属性都可以自由访问。
import pyximport
pyximport.install(language_level=3)
import cython_test
g = cython_test.Girl('古明地觉', 16, 'female')
print(g) # <cython_test.Girl object at 0x000001C49D81B330>
g.get_info()
g.set_score([90.4, 97.3, 97.6])
print(g.get_score()) # [90.4, 97.3, 97.6]
访问非常地自由,没有任何限制,但是随着我们 Girl 这个类的功能越来越多的话,该怎么办呢?
所以我们需要创建一个 pxd 文件: cython_test.pxd,然后把我们希望暴露给外界访问的 C 级结构放在里面。
# cython_test.pxd
ctypedef double real
cdef class Girl:
cdef public :
str name
long age
str gender
cdef real *scores
cpdef str get_info(self)
cpdef set_score(self, list scores) # 如果参数有默认值,那么在声明的时候让其等于 * 即可,比如:arg=*,表示该函数的 arg 参数有默认值
cpdef list get_score(self)
我们看到在 pxd 文件中,我们只存放了 C 级结构的声明,像 ctypedef、cdef、cpdef 等等,并且函数的话我们只是存放了定义,函数体并没有写在里面,同理后面也不可以有冒号。另外,pxd 文件是在编译时访问的,而且我们不可以在里面放类似于 def 这样的纯 Python 声明,否则会发生编译错误,因为纯 Python 的数据结构直接定义就好,不存在什么声明。
所以 pxd 文件只放相应的声明,而它们的具体实现是在 pyx 文件中,因此有人发现了,这个 pxd 文件不就是 C 中的头文件吗?答案确实如此。
然后我们对应的 cython_test.pyx 文件也需要修改,cython_test.pyx 和 cython_test.pxd 具有相同的基名称,Cython 会将它们视为一个命名空间。另外,如果我们在 pxd 文件中声明了一个函数或者变量,那么在 pyx 文件中不可以再次声明,否则会发生编译错误。怎么理解呢?
我们说类似于
cpdef func(): pass这种形式,它是一个函数(有定义);但是cpdef func()这种形式,它只是一个函数声明。所以 Cython 的函数声明和 C 的函数声明也是类似的,函数在 Cython 中没有冒号、以及函数体的话,那么就是函数声明。而在 Cython 的 pyx 文件中也可以进行函数声明,就像 C 源文件中也是可以声明函数一样,但是一般都会把声明写在 h 头文件中,在 Cython 中也是如此,会把 C 级结构、一些声明写在 pxd 文件中。而一旦声明了,就不可再次声明。比如 cdef public 那些成员变量,它们在 pxd 文件中已经声明了,那么 pyx 中就不可以再有了,否则就会出现变量的重复声明。
重新修改我们的 pyx 文件:
from libc.stdlib cimport malloc, free
cdef class Girl:
def __cinit__(self, *args, **kwargs):
self.scores = <real *> malloc(3 * sizeof(real))
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def __dealloc__(self):
if self.scores != NULL:
free(self.scores)
cpdef str get_info(self):
return f"name: {self.name}, age: {self.age}, gender: {self.gender}"
cpdef set_score(self, list scores):
assert scores is not None and len(scores) == 3
cdef real score
cdef long idx
for idx, score in enumerate(scores):
self.scores[idx] = score
cpdef list get_score(self):
cpdef list res = [self.scores[0], self.scores[1], self.scores[2]]
return res
虽然结构没有什么变化,但是我们把一些 C 级数据拿到 pxd 文件中了,所以 pyx 文件中的可以直接删掉了,会自动到对应的 pxd 文件中找,因为它们有相同的基名称,Cython 会将其整体看成一个命名空间。所以:这里的 pyx 文件和 pxd 文件一定要有相同的基名称,只有这样才能够找得到,否则你会发现代码中 real 是没有被定义的,当然还有 self 的一些属性,因为它们必须要使用 cdef 在类里面进行声明。
然后调用方式还是和之前一样,也是没有任何问题的。
但是哪些东西我们才应该写在 pxd 文件中呢?本质上讲,任何在 C 级别上,需要对其它模块(pyx)公开的,我们才需要写在 pxd 文件中,比如:
C类型声明--ctypedef、结构体、共同体、枚举(后续系列中介绍)外部的C、C++库的声明(后续系列中介绍)cdef、cpdef模块级函数的声明cdef class扩展类的声明扩展类的cdef属性使用cdef、cpdef方法的声明C级内联函数或者方法的实现
但是,一个 pxd 文件不可以包含如下内容:
Python函数和非内联C级函数、方法的实现Python类的定义IF或者DEF宏的外部Python可执行代码
那么我们的 pxd 文件都带来了哪些功能呢?那就是 cython_test.pyx 文件可以被其它的 pyx 文件导入了,这几个 pyx 文件作为一个整体为 Python 提供更强大的功能,否则的话其它的 pyx 文件是无法导入的。所以我们应该将需要其它 pyx 文件导入的内容在对应的 pxd 文件中进行声明,然后在导入的时候会去找 pxd 文件,根据里面声明去(和当前 pxd 文件具有相同基名称的 pyx 文件中)寻找对应的实现逻辑,而导入方式是使用 cimport。
cimport 和 import 语法一致,只不过前者多了一个 c,但是 cimport 是用来导入 pxd 文件中声明的静态数据。
多文件互相导入
然后我们在另一个 pyx 文件中导入这个 cython_test.pyx,当然导入的话其实寻找的是 cython_test.pxd,然后调用的是 cython_test.pyx 里面的具体实现。
# 文件名: caller.pyx
from cython_test cimport Girl
cdef class NewGirl(Girl):
pass
这里由于涉及到了多个 pyx 文件,所以我们先来介绍一下通过编译的方式。
from distutils.core import Extension, setup
from Cython.Build import cythonize
# 不用管 pxd, 会自动包含, 因为它们具有相同的基名称, cython 在编译的时候会自动寻找
ext = [Extension("caller", ["caller.pyx"]),
Extension("cython_test", ["cython_test.pyx"])]
setup(ext_modules=cythonize(ext, language_level=3))
编译的命令和之前一样,编译之后会发现原来的目录中有两个 pyd 文件了。
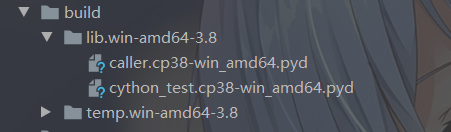
将这两个文件拷贝出来,首先在 caller.pyx 中是直接导入的 cython_test.pyx,因此这两个 pyd 文件要也在一个目录中。所以编译之后,还要注意它们之间的层级关系。
import caller
print(caller) # <module 'caller' from 'D:\\satori\\caller.cp38-win_amd64.pyd'>
g = caller.NewGirl("古明地觉", 17, "female")
print(g.get_info()) # name: 古明地觉, age: 17, gender: female
g.set_score([99.9, 90.4, 97.6])
print(g.get_score()) # [99.9, 90.4, 97.6]
我们看到完全没有问题,而且我们还可以将 caller.pyx 写更复杂一些。
from cython_test cimport Girl
cdef class NewGirl(Girl):
cdef public str where
def __init__(self, name, age, gender, where):
self.where = where
super().__init__(name, age, gender)
def new_get_info(self):
return super(NewGirl, self).get_info() + f", where: {self.where}"
重新编译之后,再次导入。
import caller
# 自己定义了 __init__, 传递 4 个参数, 前面 3 个会交给父类处理
g = caller.NewGirl("古明地觉", 17, "female", "东方地灵殿")
# 父类的方法
print(g.get_info()) # name: 古明地觉, age: 17, gender: female
# 在父类的方法返回的结果之上,进行添加
print(g.new_get_info()) # name: 古明地觉, age: 17, gender: female, where: 东方地灵殿
因此我们看到使用起来基本上和 Python 之间是没有区别,主要就是如果涉及到多个 pyx,那么这些 pyx 都要进行编译。并且想被导入,那么该 pyx 文件一定要有相同基名称的 pxd 文件。导入的时候使用 cimport,会去 pxd 文件中找,然后具体实现则是去 pyx 文件中寻找。
另外,可能有人发现了,我们这里是绝对导入。但实际上,一些 pyd 文件会放在单独工程目录中,这时候应该采用相对导入,况且它无法作为启动文件,只能被导入。所以我们可以在 pyx 文件中进行相对导入,因为编译之后的 pyd 文件和之前的 pyx 文件之间的关系是对应的。
然后我们将之前的 cython_test.pxd、cython_test.pyx、caller.pyx 放在一个单独目录中。
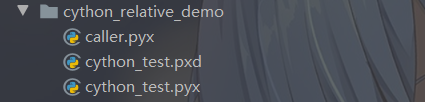
然后将 caller.pyx 中的绝对导入改成相对导入。
from .cython_test cimport Girl
然后编译扩展模块的时候可以用之前的方式编译,只不过 Extension 中文件路径要指定对。
from distutils.core import setup, Extension
from Cython.Build import cythonize
# 注意: Extension 的第一个参数, 首先我们这个文件叫做 build_ext.py, 当前的目录层级如下
"""
当前目录:
cython_relative_demo:
caller.pyx
cython_test.pxd
cython_test.pyx
build_ext.py
"""
# 所以我们的 build_ext.py 和 cython_relative_demo 是同级的
# 然后我们在编译的时候, name(Extension 的第一个参数) 不可以指定为 caller、cython_test
# 如果这么做的话, 当代码中涉及到相对导入的时候, 在编译时就会报错: relative cimport beyond main package is not allowed
# cython 编译器要求, 你在编译 pyx 文件、指定模块名的时候, 也需要把该 pyx 文件所在的目录也带上
ext = [
Extension("cython_relative_demo.caller", sources=["cython_relative_demo/caller.pyx"]),
Extension("cython_relative_demo.cython_test", sources=["cython_relative_demo/cython_test.pyx"])
]
setup(ext_modules=cythonize(ext, language_level=3))
这样编译就没有问题了,执行 python build_ext.py build 编译成功,然后我们来看一下编译之后的目录:
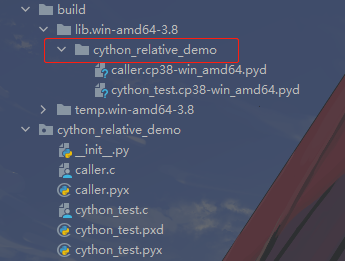
我们看到多了我们之前指定的目录,其实个人觉得 cython_relative_demo.caller 这种形式完全可以写成 caller,因为文件路径都已经指定了。但是 cython 编译器要求,我们在执行相对导入的时候不可以只指定模块名,我们也没得办法。
我们将这两个文件拷贝出来,移动到下面的 cython_relative_demo 目录中,因为我们的 pyx 文件就是在那里定义的,所以编译之后也应该放在原来的位置。
# 这里不需要 pyximport 了, 因为导入的是已经编译好的 pyd 文件
# 当然即使有 pyximport, 也会优先导入 pyd 文件
from cython_relative_demo import caller
g = caller.NewGirl("古明地觉", 17, "female", "东方地灵殿")
print(g.get_info()) # name: 古明地觉, age: 17, gender: female
print(g.new_get_info()) # name: 古明地觉, age: 17, gender: female, where: 东方地灵殿
结果是一样的,但是问题来了,如果这两个 pyx 文件的路径更复杂呢?
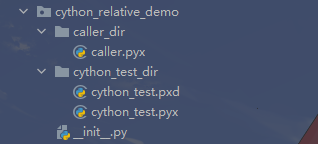
我们将其移动到了各自的目录中,那么这个时候要如何编译呢?不过编译之前,我们首先要改一下 caller.pyx。
# 应该将导入改成这样才行
from ..cython_test_dir.cython_test cimport Girl
然后修改编译时的文件:
from distutils.core import setup, Extension
from Cython.Build import cythonize
# 这里也是一样的道理, 因为我们这个编译用的文件和 cython_relative_demo 是同级的
# 所以在指定模块名的时候, 要从当前目录中的 cython_relative_demo 开始定位
ext = [
Extension("cython_relative_demo.caller_dir.caller",
sources=["cython_relative_demo/caller_dir/caller.pyx"]),
Extension("cython_relative_demo.cython_test_dir.cython_test",
sources=["cython_relative_demo/cython_test_dir/cython_test.pyx"])
]
# 同理, 如果我们哪天自己也编写一个开源的第三方库(假设叫 matsuri), 要将目录里面的 pyx 文件、或者目录里面的目录里面的 pyx 文件编译成 pyd 文件时候
# 也应该从库(matsuri)所在的目录进行编译, 然后从 matsuri 这一层开始进行文件定位, 即:
"""
ext = [Extension("matsur.xx.yy", sources=["matsur/xx/yy.pyx"]),
Extension("matsur.xx.xx.yy.zz", sources=["matsur/xx/xx/yy/zz.pyx"])
编译完成之后, 再将 pyd 文件拷贝到对应的 pyx 文件所在的位置
"""
setup(ext_modules=cythonize(ext, language_level=3))
最后再来重新编译,看看目录的结构如何:
我们看到目录变成了这样,然后 pyd 文件拷贝到对应 pyx 文件的所在目录中即可,然后之前的执行逻辑。
# 这里导入的位置也要变
from cython_relative_demo.caller_dir import caller
g = caller.NewGirl("古明地觉", 17, "female", "东方地灵殿")
print(g.get_info()) # name: 古明地觉, age: 17, gender: female
print(g.new_get_info()) # name: 古明地觉, age: 17, gender: female, where: 东方地灵殿
依旧可以执行成功,因此以上我们便介绍了当出现相对导入时 pyx 文件的编译方式,如果是 pyximport 的话,需要通过我们之前介绍的定义 .pyxbld 文件的方式,指定编译过程。否则的话,也会出现编译失败的情况,可以自己尝试一下。
以上我们便将多个 Cython 源代码组织起来了,但是除了这种方式之外,我们还可以使用 include 的方式。
# cython_test1.pyx
cdef a = 123
# cython_test2.pyx
include "./cython_test1.pyx"
cdef b = 234
print(a + b)
这里的 cython_test1.pyx 和 cython_test2.pyx 都定义在当前目录吧,因为相对导入已经介绍完了,没有必要再放在一个单独的目录中了。然后我们看到可以像 C 一样使用 include 将别的 pyx 文件包含进来,就相当于在当前文件中定义的一样。
import pyximport
pyximport.install(language_level=3)
import cython_test2
"""
357
"""
如果我们要编译的话也是可以的,只需要指定 cython_test2 文件即可,include 的内容会自动加进来。
预定义的 .pxd 文件
还记得我们之前的 from libc.stdlib cimport malloc, free 这行代码吗?显然这是 Cython 提供的,没错它就在 Cython 模块主目录下的 Includes 目录中,libc 这个包下面除了 stdlib 之外,还有 stdio、math、string 等 pxd 文件。除此之外,Includes 目录还有一个 libcpp 包对应的 pxd 文件,里面包含了 C++ 标准模板库(STL)容器的声明,如:string、vector、list、map、pair、set 等等。当然它们都是声明,但是在编译的时候会自动寻找相关实现,只不过实现逻辑需要借助编译器,而我们看不到罢了。
当然除了 libc、libcpp 之外,Includes 目录中还有其它的好东西,比如 cpython 目录,里面提供了大量的 pxd 文件,通过它们可以方便地访问 Python/C API。当然还有一个最重要的包就是 numpy,Cython 也是支持的,当然这些我们会在后面系列中介绍了。
使用 cimport 导入一个 C 模块
# cython_test.pyx
from libc cimport math
print(math.sin(math.pi / 2))
from libc.math cimport sin, pi
print(sin(pi / 2))
import pyximport
pyximport.install(language_level=3)
import cython_test
"""
1.0
1.0
"""
cimport 的使用方式和 import 是一致的,但只不过上面导入的是更快的 C 版本。
from libcpp.vector cimport vector
cdef vector[int] *v1 = new vector[int](3)
Cython 也支持从 C++ STL 中导入 C++ 类。另外,如果我们使用 import、cimport 导入了具有相同名称的不同函数,Cython 将引发一个编译错误。
from libc.math cimport sin
from math import sin
"""
Error compiling Cython file:
------------------------------------------------------------
...
from libc.math cimport sin
from math import sin ^
------------------------------------------------------------
cython_test.pyx:2:17: Assignment to non-lvalue 'sin'
"""
为了修复这一点,我们只需要这么做。
from libc.math cimport sin as c_sin
from math import sin as py_sin
print(c_sin(3.1415926 / 2))
print(py_sin(3.1415926 / 2))
import pyximport
pyximport.install(language_level=3)
import cython_test
"""
0.9999999999999997
0.9999999999999997
"""
此时就没有任何问题了。但如果我们导入的是模块的话,那么是可以重名的。
from libc cimport math
import math
print(math.sin(math.pi / 2))
尽管 import math 是在下面,但是调用的时候会从 C 标准库中进行调用,但是不管怎么样,这种做法总归是不好的。我们应该修改一下:
from libc cimport math as c_math
import math as py_math
因此这些预定义的 pxd 文件就类似于 C、C++ 中的头文件。
它们都声明了 C 一级的数据结构供外界调用它们都允许我们对功能进行拆分, 分别通过不同的模块实现它们都实现了公共的 C 级接口
C、C++ 头文件通过 #include 命令进行访问,该命令会对相应的头文件进行包含。而 Cython 的 cimport 更智能,也更不容易出错,我们可以把它看做是一个使用命名空间的编译时导入语句。
而 Cython 的早期没有 cimport 语句,而是有一个 include 语句,我们之前说过了,它是在源码级对文件进行包含。而 include 则类似于 Python 的import,如果你觉得这个文件内容太多了,那么可以单独进行拆分,然后再使用 include 包含进去。
总结
pyx 文件、pxd 文件,再加上 cimport、include,我们可以将 Cython 代码组织到单独的模块和包中,而不牺牲性能。这使得 Cython 可以进行扩展,而不仅仅用来加速,它完全可以作为主力语言开发一个成熟的项目。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号