《数据库基础语法》17. 数据库的事务、索引、视图、执行计划、查询优化技巧
为什么数据库事务如此重要?
当我们在操作数据的同时,其他人或者应用程序可能也在操作相同的数据;此时数据库必须保证多个用户之间不会产生影响,数据不会出现不一致性。这就涉及到一个重要的概念:数据库事务(Transaction)。
什么是数据库事务:
在企业应用中,数据库通常需要支持多用户并发访问;并且保证多个用户并发访问相同的数据时,不会造成数据的不一致性和不完整性。同时,在用户执行操作的过程中,可能会遇到系统崩溃、介质失效等故障,数据库也必须能够从失败的状态恢复到一致状态。这些核心功能在数据库中都是通过事务来实现的。
在数据库中,事务是指一组相关的 SQL 语句,它们在业务逻辑上组成一个原子单元。数据库必须保证事务中的所有操作全部成功,或者全部撤销。
最常见的数据库事务就是银行账户之间的转账操作;例如从 A 账户转出 1000 元到 B 账户,就是一个事务,该事务主要包括以下步骤:
- 查询 A 账户的余额是否足够;
- 从 A 账户减去 1000 元;
- 往 B 账户增加 1000 元;
- 记录本次转账流水。
显然,数据库必须保证所有的操作要么全部成功,要么全部失败。如果从 A 账户减去 1000 元成功执行,但是没有往 B 账户增加 1000 元,意味着客户将会损失 1000 元。用数据库中的术语来说,这种情况导致了数据库的不一致性。
事务控制语句:
SQL 定义了用于管理数据库事务的事务控制语句(Transaction Control Language)。MySQL 实现了以下语句:
- BEGIN 或者 START TRANSACTION,开始一个事务;
- COMMIT,提交事务;
- ROLLBACK,撤销事务;
- SAVEPOINT,事务保存点,用于撤销部分事务;
- SET autocommit = {0 | 1},设置事务是否自动提交。
事务的 ACID 属性:
SQL 标准定义了数据库事务的四种特性:ACID。
原子性
原子性(Atomic)是指一个事务包含的所有 SQL 语句要么全部成功,要么全部失败。例如,某个事务需要更新 100 条记录;但是在更新到一半时系统出现故障,数据库必须保证能够回滚已经修改过的数据,就像没有执行过任何修改一样。
一致性
一致性(Consistency)意味着事务开始之前,数据库位于一致性的状态;事务完成之后,数据库仍然位于一致性的状态。例如,银行转账事务中;如果一个账户扣款成功,但是另一个账户加钱失败,就会出现数据不一致(此时需要回滚已经执行的扣款操作)。另外,数据库还必须保证满足完整性约束,比如账户扣款之后不能出现余额为负数(在余额字段上添加检查约束)。
隔离性
隔离性(Isolation)与并发事务有关,一个事务的影响在提交之前对其他事务不可见,多个并发的事务之间相互隔离。例如,账户 A 向账户 B 转账的过程中,账户 B 查询的余额应该是转账之前的数目;如果多人同时向账户 B 转账,结果也应该保持一致性,和依次进行转账的结果一样。SQL 标准定义了 4 种不同的事务隔离级别,我们将会在下文进行介绍。
持久性
持久性(Durability)表示已经提交的事务必须永久生效,即使发生断电、系统崩溃等故障,数据库都不会丢失数据。数据库系统通常使用重做日志(REDO)或者预写式日志(WAL)实现事务的持久性。简单来说,它们都是在提交之前将数据的修改操作记录到日志文件中;当数据库出现崩溃时,可以利用这些日志重做之前的修改,从而避免数据的丢失。
对于我们开发者而言,重点需要注意的是隔离级别,而隔离级别又与并发访问有关。
并发与隔离级别:
数据库的并发意味着多个用户同时访问相同的数据,例如 A 和 C 同时给 B 转账。数据库的并发访问可能带来以下问题:
- 脏读(Dirty Read)。当一个事务允许读取另一个事务修改但未提交的数据时,就可能发生脏读。例如,B 的初始余额为 0;A 向 B 转账 1000 元但没有提交;此时 B 能够看到 A 转过来的 1000 元,并且成功取款 1000 元;然后 A 取消了转账;银行损失了 1000 元。很显然,银行不会允许这种事情发生。
- 不可重复读(Nonrepeatable Read)。一个事务读取某一记录后,该数据被另一个事务修改提交,再次读取该记录时结果发生了改变。例如,B 查询初始余额为 0;此时 A 向 B 转账 1000 元并且提交;B 再次查询发现余额变成了 1000 元,以为天上掉馅饼了。
- 幻读(Phantom Read)。一个事务第一次读取数据后,另一个事务增加或者删除了某些数据,再次读取时结果的数量发生了变化。幻读和非重复读有点类似,都是由于其他事务修改数据导致的结果变化。
- 更新丢失(Lost Update)。第一类:当两个事务更新相同的数据时,如果第一个事务被提交,然后第二个事务被撤销;那么第一个事务的更新也会被撤销。第二类:当两个事务同时读取某一记录,然后分别进行修改提交;就会造成先提交的事务的修改丢失。
为了解决并发访问可能导致的各种问题,SQL标准定义了 4 种不同的事务隔离级别(从低到高):
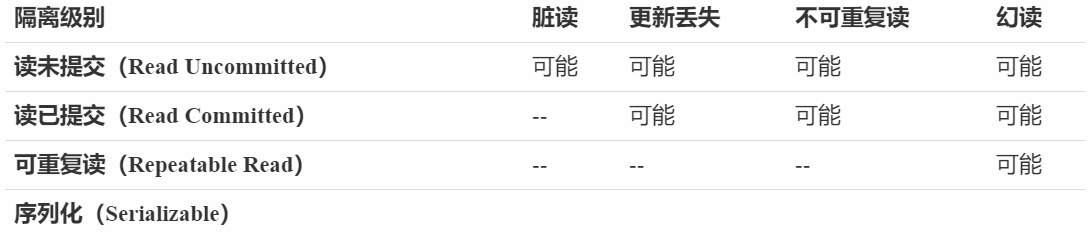
读未提交 隔离级别最低,一个事务可以看到其他事务未提交的修改。该级别可能产生各种并发异常;如果一个事务已经修改某个数据,则另一个事务不允许同时修改该数据,写操作一定是按照顺序执行。PostgreSQL 消除了读未提交级别时的脏读。读已提交 只能看到其他事务已经提交的数据,不会出现脏读。可重复读 可能出现幻读。MySQL 中的 Innodb 存储引擎和 PostgreSQL 在可重复读级别消除了幻读。序列化 提供最高级别的事务隔离。它要求事务只能一个接着一个地执行,不支持并发访问。
事务的隔离级别越高,越能保证数据的一致性;但同时会对并发带来更大的影响。不同数据库默认使用的隔离级别如下:
Oracle、SQL Server 以及 PostgreSQL 默认使用读已提交隔离级别MySQL InnoDB 存储引擎默认使用可重复读隔离级别
一般情况下,大多数数据库的默认隔离级别为读已提交;此时,可以避免脏读,同时拥有不错的并发性能。尽管可能会导致不可重复度、幻读以及丢失更新,但是可以通过应用程序加锁进行处理。
小结
数据库事务是指多个相关操作组成一个原子单元,所有操作全部成功,或者全部失败。事务具有 ACID 属性,能够确保数据库的完整性和一致性。数据库通过隔离来实现对并发事务的支持,隔离级别与并发性能不可兼得,在开发应用程序时需要进行权衡和选择;一般情况下,我们使用数据库的默认隔离级别。
索引一定能提高性能吗?
介绍完数据库事务的概念和重要性、事务的 ACID 属性,以及并发事务的控制与隔离级别。
下面我们讨论与性能相关的一个重要对象:索引(Index)。你一定听说过:索引可以提高查询的性能。那么,索引的原理是什么呢?有了索引就一定可以查询的更快吗?索引只是为了优化查询速度吗?接下来我们就一一进行解答。
索引的原理:
以下是一个简单的查询,查找工号为 5 的员工:
SELECT *
FROM employee
WHERE emp_id = 5;
数据库如何找到我们需要的数据呢?如果没有索引,那就只能扫描整个 employee 表,然后使用工号依次判断并返回满足条件的数据。这种方式一个最大的问题就是当数据量逐渐增加时,全表扫描的性能也就随之明显下降。
为了解决查询的性能问题,数据库引入了一个新的数据结构:索引。索引就像书籍中的关键字索引,按照关键字进行排序,并且提供了指向具体内容的页码。如果我们在 email 字段上创建了索引(例如 B-树索引),数据库查找的过程大概如下图所示:

B-树(Balanced Tree)索引就像是一棵倒立的树,其中的节点按照顺序进行组织;节点左侧的数据都小于该节点的值,节点右侧的数据都大于节点的值。数据库首先通过索引查找到工号为 5 的节点,再通过该节点上的指针(通常是数据的物理地址)访问数据所在的磁盘位置。
举例来说,假设每个索引分支节点可以存储 100 个记录,100 万(100^3)条记录只需要 3 层 B-树即可完成索引。通过索引查找数据时需要读取 3 次索引数据(每次磁盘 IO 读取整个分支节点),加上 1 次磁盘 IO 读取数据即可得到查询结果。
如果采用全表扫描,需要执行的磁盘 IO 可能高出几个数量级。当数据量增加到 1 亿时,B-树索引只需要再增加一次索引 IO 即可;而全表扫描需要再增加几个数量级的 IO。
以上只是一个简化的 B-树索引原型,实际的数据库索引还会在索引节点之间增加互相连接的指针(B+树),能够提供更好的查询性能。该网站提供了一个可视化的 B+树模拟程序,可以直观地了解索引的维护和查找过程。
索引的类型:
虽然各种数据库支持的索引不完全相同,对于相同的索引也可能存在实现上的一些差异;但它们都实现了许多通用的索引类型。
B-树索引与 Hash 索引
B-树索引,使用平衡树或者扩展的平衡树(B+树、B*树)结构创建索引。这是最常见的一种索引,主流的数据库默认都采用 B-树索引。这种索引通常用于优化 =、<、<=、>、BETWEEN、IN 以及字符串的前向匹配('abc%')查询。
Hash 索引,使用数据的哈希值创建索引。使用哈希索引查找数据的过程如下:
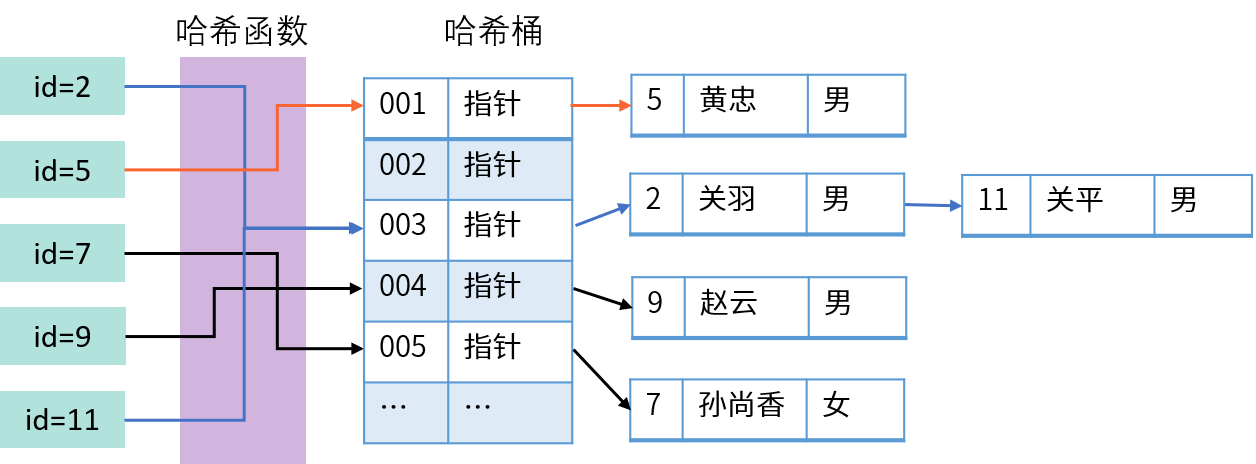
查询时通过检索条件(例如 id=5)的哈希值直接进行匹配,从而找到数据所在的位置。哈希索引主要用于等值(=)查询,速度更快;但是哈希函数的结果没有顺序,因此不适合范围查询,也不能用于优化 ORDER BY 排序。
聚集索引与非聚集索引:
聚集索引(Clustered index)将表中的数据按照索引的结构(通常是主键)进行存储。也就是说,索引的叶子节点中存储了表的数据。
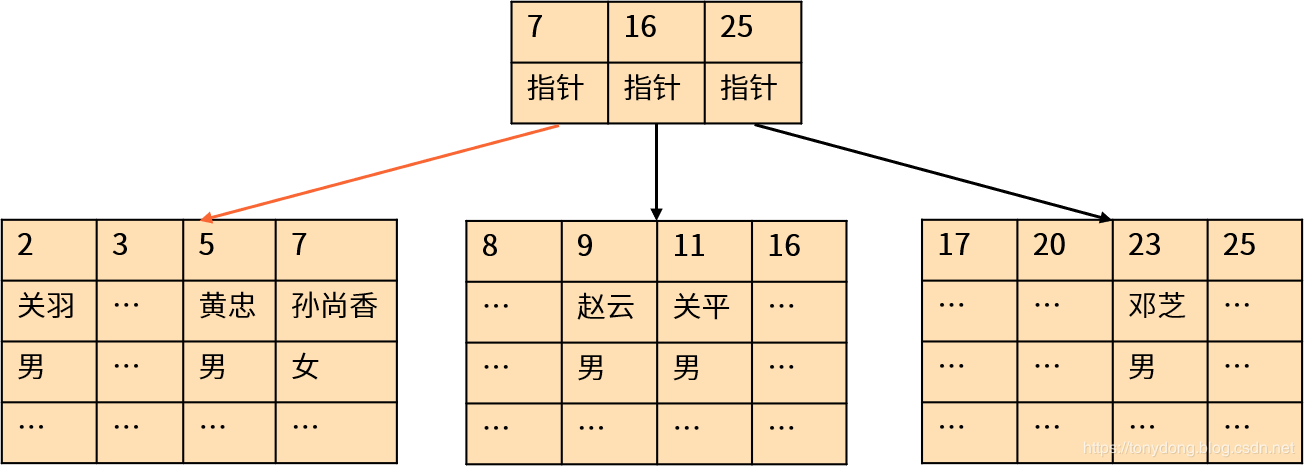
严格来说,聚集索引其实是一种特殊的表。MySQL(InnoDB 存储引擎)和 SQL Server 将这种结构的表称为聚集索引,Oracle 中称为索引组织表(IOT)。这种存储数据的方式适合使用主键进行查询的应用,类似于 key-value 系统。
非聚集索引就是普通的索引,索引的叶子节点中存储了指向数据所在磁盘位置的指针,数据在磁盘上随机分布。MySQL(InnoDB 存储引擎)称之为二级索引(Secondary index),叶子节点存储的是聚集索引的键值(通常是主键);通过二级索引查找时需要先找到相应的主键值,再通过主键索引查找数据。因此,创建聚集索引的主键字段越小,索引就越小;一般采用自增长的数字作为主键。
SQL Server 如果使用聚集索引创建表,非聚集索引的叶子节点存储的也是聚集索引的键值;否则,非聚集索引的叶子节点存储的是指向数据行的地址。
唯一索引与非唯一索引:
唯一索引(UNIQUE)中的索引值必须唯一,可以确保被索引的数据不会重复,从而实现数据的唯一性约束。
非唯一索引 允许被索引的字段存在重复值,仅仅用于提高查询的性能。
单列索引与多列索引:
单列索引 是基于单个字段创建的索引。例如,员工表的主键使用 emp_id 字段创建,就是一个单列索引。
多列索引 是基于多个字段创建的索引,也叫复合索引。创建多列索引的时候需要注意字段的顺序,查询条件中最常出现的字段放在最前面,这样可以最大限度地利用索引优化查询的性能。
其他索引类型:
全文索引(Full-text),用于支持全文搜索,类似于 Google 和百度这种搜索引擎。
函数索引,基于函数或者表达式的值创建的索引。例如,员工的 email 不区分大小写并且唯一,可以基于 UPPER(email) 创建一个唯一的函数索引。
有了索引的概念之后,我们来看一下如何创建和管理索引。
维护索引:
使用 CREATE INDEX 语句创建索引,默认情况下创建的是 B+ 树索引:
CREATE [UNIQUE] INDEX index_name
ON table_name(col1 [ASC | DESC], ...);
其中,UNIQUE 表示创建唯一索引;ASC 表示索引按照升序排列,DESC 表示索引按照降序排列,默认为 ASC。
定义主键和唯一约束时,数据库自动创建相应的索引。MySQL InnoDB 存储引擎也会自动为外键约束创建索引。
DROP INDEX 语句用于删除一个索引:
-- Oracle 和 PostgreSQL 实现
DROP INDEX idx_emp_devp_name;
-- MySQL 和 SQL Server 实现
DROP INDEX idx_emp_devp_name ON emp_devp; -- 对于 MySQL 和 SQL Server 而言,删除索引时需要指定表名:
索引不是约束:
在数据库中,索引还用于实现另一个功能:主键约束和唯一约束。因此,很多人存在一个概念上的误解,认为索引就是约束。唯一约束是指字段的值不能重复,但是可以为 NULL;例如,员工的邮箱需要创建唯一约束,确保不会重复。
理论上可以编写一个程序,在每次新增或修改邮箱时检查是否与其他数据重复,来实现唯一约束;但是这种方式的性能很差,并且无法解决并发时的冲突问题。但是,如果在该字段上增加一个唯一索引,就很方便地满足了唯一性的要求,而且能够提高以邮箱作为条件时的查询性能。
索引注意事项:
既然索引可以优化查询的性能,那么我们是不是应该将所有字段都进行索引?显然并非如此,因为索引在提高查询速度的同时也需要付出一定的代价。
首先,索引需要占用磁盘空间。索引独立于数据而存在,过多的索引会导致占用大量的空间,甚至超过数据文件的大小。
其次,对数据进行 DML 操作时,同时也需要对索引进行维护;维护索引有时候比修改数据更加耗时。
索引是优化查询的一个有效手段,但是过渡的索引可能给系统带来负面的影响。我们将会在第 34 篇中讨论如何创建合适的索引,利用索引优化 SQL 语句,以及检查索引是否被有效利用等。
小结
SQL 语句的声明性使得我们不需要关心具体的操作实现,但同时也可能因此导致数据库的性能问题。索引可以提高数据检索的速度,也可以用于实现唯一约束;但同时索引也需要占用一定的磁盘空间,索引的维护需要付出一定的代价。
视图有哪些优缺点,什么时候使用视图?
上节我们介绍了索引的概念、索引提高查询性能的原理,以及索引需要付出的代价。
这节我们来讨论另一个重要的数据库对象:视图(View),学习如何利用视图简化查询语句、实现业务规则以及提高数据的安全性。
视图不是表:
简单来说,视图就是一个预定义的查询语句。视图在许多情况下可以当作表来使用,因此也被称为虚拟表(Virtual Table)。视图与表最大的区别在于它不包含数据,数据库中只存储视图的定义语句。以下是一个视图的示意图:

知道了什么是视图,那为什么需要视图呢?因为它可以给我们带来许多好处:
- 替代复杂查询,减少复杂性。将复杂的查询语句定义为视图,然后使用视图进行查询,可以隐藏具体的实现;
- 提供一致性接口,实现业务规则。在视图的定义中增加业务逻辑,对外提供统一的接口;当底层表结构发生变化时,只需要修改视图接口,而不需要修改外部应用,可以简化代码的维护并减少错误;
- 控制对于表的访问,提高安全性。通过视图为用户提供数据访问,而不是直接访问表;同时可以限制允许访问某些敏感信息,例如身份证号、工资等。
不过,视图也可能带来一些问题:
- 不当的使用可能会导致性能问题。视图的定义中可能包含了复杂的查询,例如嵌套的子查询和多个表的连接查询,可能导致使用视图进行查询时性能不佳;
- 视图通常用于查询操作,可更新视图(Updatable View)需要满足许多限制条件。可更新视图可以支持通过视图对底层表进行增删改的操作。
接下来我们介绍如何创建、修改、删除和使用视图。
创建视图:
-- 我们可以使用 CREATE VIEW 语句创建一个新的视图:
CREATE VIEW view_name
AS select_statement;
其中,view_name 是视图的名称;select_statement 是视图的定义,也就是一个 SELECT 语句。视图可以基于一个或多个表定义,也可以基于其他视图进行定义。创建视图之后,可以像普通表一样将视图作为查询的数据源。
视图定义中的 SELECT 语句与普通的查询一样,可以包含任意复杂的选项。例如子查询、集合操作、分组聚合等。但有一个需要注意的选项就是 ORDER BY 子句。许多数据库都支持在视图定义中使用 ORDER BY 子句;但是 SQL 标准并不支持这种写法,因为视图并不存储数据。所以建议最好不要在视图的定义中使用 ORDER BY,因为这种排序并不能保证最终结果的顺序;而且可能由于不必要的排序降低查询的性能。
修改视图:
如果需要修改视图的定义,可以删除并重新创建视图。除此之外,各种数据库也提供了直接替换视图定义的命令:
-- Oracle、MySQL 以及 PostgreSQL 实现
CREATE OR REPLACE VIEW view_name
AS select_statement;
-- SQL Server 实现
CREATE OR ALTER VIEW view_name
AS select_statement;
其中 CREATE OR REPLACE VIEW 表示如果视图不存在,创建视图;如果视图已经存在,替换视图。SQL Server 使用 CREATE OR ALTER VIEW 实现相同的功能。
MySQL 和 SQL Server 还支持使用 ALTER VIEW view_name AS select_statement; 命令修改视图的定义。 Oracle 和 PostgreSQL 中的 ALTER VIEW 命令用于修改视图的其他属性。
删除视图:
-- 使用 DROP VIEW 命令可以删除一个视图:
DROP VIEW [IF EXISTS] view_name;
指定 IF EXISTS 选项后,删除一个不存在的视图时也不会产生错误。Oracle 不支持 IF EXISTS 选项。
通常来说,视图主要用于查询数据;但是某些视图也可以用于修改数据,这种视图被称为可更新视图(Updatable View)。
可更新视图:
可更新视图是指通过视图更新底层表,对于视图的 INSERT、UPDATE、DELETE 等操作最终会转换为针对底层基础表的相应操作。可更新视图的定义需要满足许多限制条件,包括:
- 不能使用聚合函数或窗口函数,例如 AVG、SUM、COUNT 等;
- 不能使用 DISTINCT、GROUP BY、HAVING 子句;
- 不能使用集合运算符,例如 UNION、INTERSECT 等;
- 修改操作只能涉及单个表中的字段,不能同时修改多个表;
- 不同数据库实现的其他限制条件。
总之,对视图的修改只有在能够映射为对基础表的修改时,数据库才能执行视图的修改操作。
小结
视图与子查询和通用表表达式有类似之处,都可以作为查询的数据源;但是视图是存储在数据库中的对象,可以被重复使用。合理的使用视图可以实现底层数据表的隐藏,对外提供一致接口,提高数据访问的安全性。不过,复杂的视图可能导致维护和性能问题;在实际应用之前最好进行相关的性能测试。
执行计划
下面我们开始扩展篇的学习。首先,让我们深入到数据库服务器的内部,探索一下 SQL 查询的执行过程。
SQL 查询执行过程:
不同数据库对于 SQL 语句的执行过程采用了各自的实现方式;我们虽然不能通过一篇文章涵盖这些实现细节,但是可以尝试概括其中的关键过程和差异之处。简单来说,一个 SQL 查询语句从客户端的提交开始直到服务器返回最终的结果,整个过程大致如下图所示:

第一步:客户端提交 SQL 语句。当然,在此之前客户端必须连接到数据库服务器。在上图中的连接器就是负责建立和管理客户端的连接。
第二步:分析器/解析器。分析器首先解析 SQL 语句,识别出各个组成部分;然后进行语法分析,检查 SQL 语句的语法是否符合规范。例如,以下语句中的 FROM 写成了 FORM:
SELECT *
FORM people
WHERE pk = 1;
-- Oracle
SQL Error [923] [42000]: ORA-00923: FROM keyword not found where expected
-- MySQL
SQL Error [1064] [42000]: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'FORM people
WHERE pk = 1' at line 2
-- SQL Server
SQL Error [102] [S0001]: Incorrect syntax near 'FORM'.
-- PostgreSQL
SQL Error [42601]: ERROR: syntax error at or near "FORM"
Position: 13
数据库返回了一个语法错误。
接下来是语义检查,确认查询中的表或者字段等对象是否存在,用户是否拥有访问权限等。例如,以下语句写错了表名:
SELECT *
FROM ppeople
WHERE pk = 1;
-- Oracle
SQL Error [942] [42000]: ORA-00942: table or view does not exist
-- MySQL
SQL Error [1146] [42S02]: Table 'my_db.ppeople' doesn't exist
-- SQL Server
SQL Error [208] [S0002]: Invalid object name 'ppeople'.
-- PostgreSQL
SQL Error [42P01]: ERROR: relation "ppeople" does not exist
Position: 18
数据库显示对象不存在或者无效。这一步还包括处理语句中的表达式,视图转换等。
第三步:优化器。利用数据库收集到的统计信息决定 SQL 语句的最佳执行方式。例如,使用索引还是全表扫描的方式访问单个表,使用什么顺序连接多个表。优化器是决定查询性能的关键组件,而数据库的统计信息是优化器判断的基础。
第四步:执行器。根据优化之后的执行计划,调用相应的执行模块获取数据,并返回给客户端。对于 MySQL 而言,会根据表的存储引擎调用不同的接口获取数据。PostgreSQL 12 版本开始引入类似的插件存储引擎功能。
以上流程在各种数据库中大体相同,但还有一些重要的组件就是缓存:
- 查询缓存 。MySQL 5.7 之前的版本有一个查询缓存模块,以 key-value 的形式缓存了执行过的查询语句和结果集。但是查询缓存的失效频率非常高;因为只要有任何更新,表上所有的查询缓存都会被清空。因此,MySQL 8.0 版本删除了查询缓存的模块。
- 查询计划缓存。对于完全相同的 SQL 语句,利用已经缓存的执行计划,从而跳过解析和生成执行计划的过程。Oracle 和 SQL Server 都提供了查询计划缓存;MySQL 和 PostgreSQL 的查询计划在使用预编译语句(Prepared Statement )时被缓存,但只在当前会话中有效。
- 数据缓存。对于已经访问过的磁盘数据(表和索引),在缓冲区中进行缓存;下次访问时可以直接读取内存中的数据。数据缓存可以明显提高数据访问的速度,已经成为了各种数据库的标配。
从以上流程可以看出,执行计划是决定查询性能的关键;如果想查看一条语句的执行情况,可以通过explain。
小结
一个查询语句大概需要经过分析器、优化器、执行器的处理并返回最终结果,同时还可能利用各种缓存功能提高查询的性能。决定查询性能的主要因素就是执行计划,大多数数据库可以通过 EXPLAIN 命令查看执行计划。理解执行计划是进行查询优化的关键。
了解常见 SQL 查询优化技巧
下面我们来介绍一些常见的查询优化方法和技巧。
首先一点:优化规则千万条,执行计划第一条。不要盲目相信什么规则,包括本文列出的规则;因为数据库优化器在不断改进,许多规则已经或者将来不再适用。不过另一方面,通过执行计划找出性能问题并进行优化的方法不会改变。
一般来说,对于 OLTP 应用减少数据库磁盘 IO 是 SQL 优化需要考虑的首要因素,因为磁盘通常是性能的瓶颈所在。除此之外,还需要考虑降低 CPU 和内存的消耗;DISTINCT、GROUP BY、ORDER BY 等操作都需要涉及大量 CPU 运算,而且还会占用大量内存或者使用临时文件。
创建合适的索引:
索引是优化查询性能的主要方法,因此首先需要考虑创建有效的索引。我们在前面介绍了索引的原理,现在来看看哪些字段适合创建索引:
- 经常出现在 WHERE 条件或者 ORDER BY 中的字段创建索引,可以避免全表扫描和额外的排序操作;
- 多表连接查询的关联字段,外键涉及的字段;
- 查询中的分组操作字段;
创建索引时还有一些注意事项。首先,尽量选择区分度高的列作为索引,例如各种编号;而性别这种重复性高的字段不适合单独创建索引。其次,对于组合索引,查询条件中最常出现的列放在最左边,这个称为组合索引最左前缀原则。
另外,还需要注意有些情况不适合创建索引。例如,频繁更新的字段不适合创建索引,因为更新索引也需要付出代价;表中记录较少时不需要创建索引,直接通过全表扫描可能更快;大文本数据考虑使用全文索引。
避免使用 SELECT *:
SELECT * 表示查询表中的所有字段,这种写法可能返回了不必要的信息,导致性能的下降。因为数据库需要读取更多的数据,同时网络需要传输更多的数据,而且客户端可能并不需要这些信息。
我们在学习过程中为了方便,可以使用星号编写查询语句;但是在实际开发中应该严格控制只返回业务需要的字段
优化查询条件:
虽然我们已经为查询条件中的字段创建了合适的索引,但是如果 WHERE 子句编写不当,同样会导致数据库无法使用索引。
首先,在 WHERE 子句中对索引字段进行表达式运算或者使用函数都会导致索引失效。
比如:我们将email字段作为索引,但是在查询的时候,使用upper(email),那么该索引就会失效
其次,使用 LIKE 匹配时,如果通配符出现在左侧无法使用索引,因为不确定左边的起始字符是什么、以及有多少个。
另外,如果 WHERE 条件中的字段上创建了索引,尽量设置为 NOT NULL。不是所有数据库使用 IS [NOT] NULL 判断时都可以利用索引
多表连接实现:
连接查询首先需要避免缺少连接条件导致的笛卡尔积,这是非常消耗资源的操作。对于 JOIN 查询使用的关联字段,应该确保数据类型和字符集相同,并且创建了合适的索引。
对于多表连接查询,数据库底层的实现方式通常有三种:
- 嵌套循环连接(Nested Loop Join),针对驱动表(外表)中的每条记录,遍历另一个表找到匹配的数据,相当于两层 for 循环。
- 哈希连接(Hash Join),将一个表的连接字段计算出一个哈希表,然后从另一个表中一次获取记录并计算哈希值,根据两个哈希值来匹配符合条件的记录。
- 排序合并连接( Sort Merge Join),先将两个表中的数据基于连接字段分别进行排序,然后合并排序后的结果。
数据库优化器选择哪种方式取决于许多因素,例如表中的数据量、关联字段是否已经排序或者创建索引等:
- Nested Loop Join 适用于驱动表数据比较少,并且连接表中有索引的时候;
- Hash Join 对于数据量大,且没有索引的情况下可能性能更好;
- Sort Merge Join 通常用于没有索引,并且数据已经排序的情况。
一般连接查询的表较少时,优化器可以自行选择合适的实现方法;当复杂查询性能不够理想时,我们可以通过执行计划查看是否缺少索引、调整多表连接的顺序等方式进行优化。
另外,还有一种减少连接查询的方法,就是增加冗余字段,利用空间换时间。
除此之外还可以优化子查询、优化union、优化分页查询等等。
小结
SQL 优化本质上是了解优化器的的工作原理,并且为此创建合适的索引和正确的语句。当优化器由于自身的限制无法进一步优化时,我们可以人为进行查询的重写,共同实现查询的优化。另外我们还需要知道,SQL 优化只是数据库性能优化的一部分;相关的技术还包括表结构优化、配置参数优化、操作系统和硬件调整,甚至架构优化(分库分表、读写分离等)。
全文总结
如果你看到了这里,那么恭喜你完成了从初级查询到高级分析功能、从增删改查到数据库设计、从性能优化到应用开发等相关知识的学习。我们最后再总结一些:
再谈关系:
最开始我们介绍了 SQL 编程中的一个最重要思想:一切都是关系。关系在数据库中实现为二维表,由数量固定的列和任意数量的行组成;所以,关系表可以看作是一个由元素(数据行)构成的集合。而 SQL 语言本质上是为关系表提供的各种操作,我们可以将以上内容汇总如下:
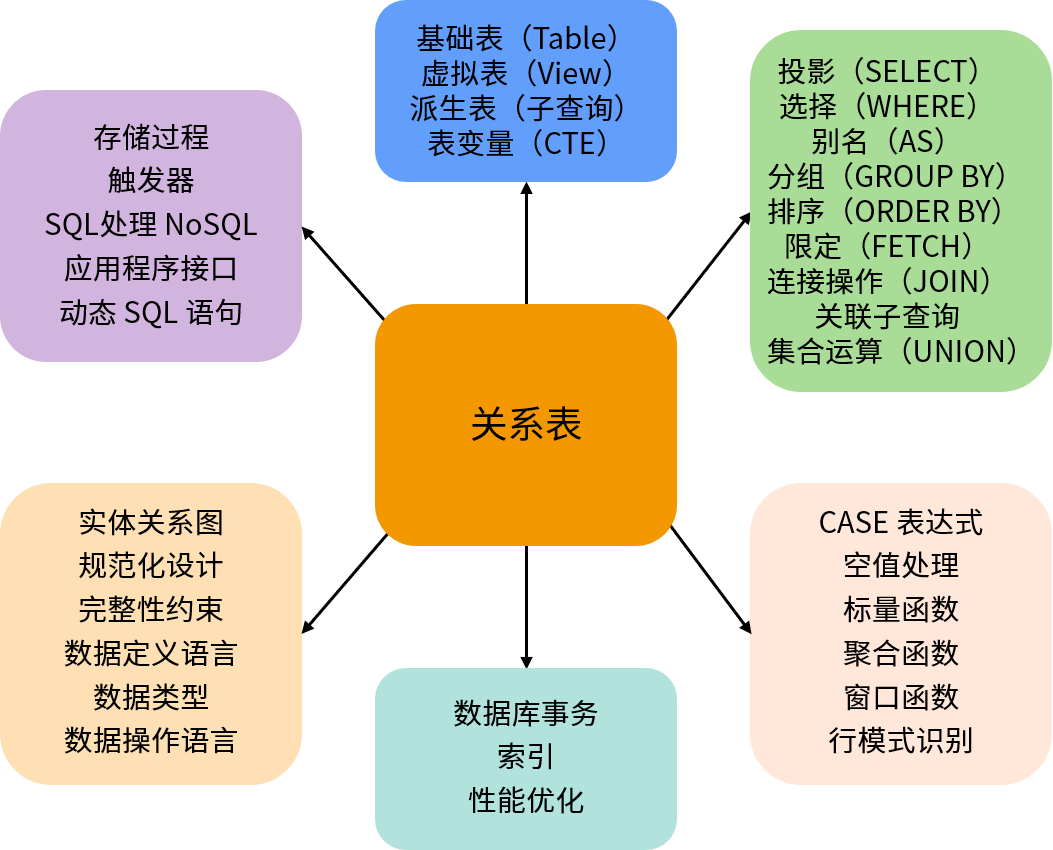
首先,关系表在数据库中存在几种不同的表现形式:
- 基础表(Table)是数据库中存储数据的主要对象;
- 视图(View)是一个命名的查询语句。视图不存储数据,但是经常当作表来使用,因此被称为虚拟表;
- 查询的结果集被称为派生表(Derived Table);
- 通用表表达式(CTE)是语句级别的临时表,也称为表变量。
数据库中还有一种表叫做临时表(temporary table)。根据定义的不同,临时表会在事务结束或者会话终止时被自动清空或者删除。
接下来就是主要内容,也就是实现了各种关系操作的 SQL 语言。SQL 是一种面向集合(关系表)的声明式语言,操作的对象和结果都是集合。我们来看一个 PostgreSQL 中的示例:
-- PostgreSQL
SELECT * FROM abs(-1); -- 1
学习了 SQL 之后,我们应该都知道 FROM 子句指定的是一个表;而 abs 是求绝对值的函数,所以在 PostgreSQL 中甚至函数的结果都是一个表。
伟大的设计通常都体现了简单的哲学思想,就像在 Unix/Linux 中一切皆文件一样,在 SQL 中一切皆关系。
除此之外,我们还详细介绍了关系操作中的投影(SELECT)、选择(WHERE)、别名(AS)、分组(GROUP BY)、排序(ORDER BY)、限定(FETCH/LIMIT)、集合操作(UNION、INTERSECT 和 EXCEPT)、连接操作(INNER/LEFT/RIGHT/FULL JOIN、CROSS JOIN)以及子查询等。当我们使用这些操作组合成一个复杂的 SQL 语句时,需要注意它们的编写顺序和逻辑执行顺序。
SQL 执行顺序:
回顾一下我们学习过的 SQL 查询语句:
(6)SELECT [DISTINCT | ALL] col1, col2, agg_func(col3) AS alias
(1) FROM t1 JOIN t2
(2) ON (join_conditions)
(3) WHERE where_conditions
(4) GROUP BY col1, col2
(5)HAVING having_condition
(7) UNION [ALL]
...
(8) ORDER BY col1 ASC,col2 DESC
(9)OFFSET m LIMIT N;
以上是 SQL 中各种关键字的编写顺序,前面括号内的数字代表了它们的逻辑执行顺序。也就是说,SQL 并不是按照编写顺序先执行 SELECT,然后再执行 FROM 子句。从逻辑上讲,SQL 语句的执行顺序如下:
- 首先,FROM 和 JOIN 是 SQL 语句执行的第一步。它们的逻辑结果是一个笛卡尔积,决定了接下来要操作的数据集。注意逻辑执行顺序并不代表物理执行顺序,实际上数据库在获取表中的数据之前会使用 ON 和 WHERE 过滤条件进行优化访问;
- 其次,应用 ON 条件对上一步的结果进行过滤并生成新的数据集;
- 然后,执行 WHERE 子句对上一步的数据集再次进行过滤。WHERE 和 ON 大多数情况下的效果相同,但是外连接查询有所区别,我们将会在下文给出示例;
- 接着,基于 GROUP BY 子句指定的表达式进行分组;同时,对于每个分组计算聚合函数 agg_func 的结果。经过 GROUP BY 处理之后,数据集的结构就发生了变化,只保留了分组字段和聚合函数的结果;
- 如果存在 GROUP BY 子句,可以利用 HAVING 针对分组后的结果进一步进行过滤,通常是针对聚合函数的结果进行过滤;
- 接下来,SELECT 可以指定要返回的列;如果指定了 DISTINCT 关键字,需要对结果集进行去重操作。另外还会为指定了 AS 的字段生成别名;
- 如果还有集合操作符(UNION、INTERSECT、EXCEPT)和其他的 SELECT 语句,执行该查询并且合并两个结果集。对于集合操作中的多个 SELECT 语句,数据库通常可以支持并发执行;
- 然后,应用 ORDER BY 子句对结果进行排序。如果存在 GROUP BY 子句或者 DISTINCT 关键字,只能使用分组字段和聚合函数进行排序;否则,可以使用 FROM 和 JOIN 表中的任何字段排序;
- 最后,OFFSET 和 FETCH(LIMIT、TOP)限定了最终返回的行数。
理解 SQL 的逻辑执行顺序可以帮助我们避免一些常见的错误,例如以下语句:
-- 错误示例
SELECT emp_name AS empname
FROM employee
WHERE empname ='张飞';
该语句的错误在于 WHERE 条件中引用了列别名;从上面的逻辑顺序可以看出,执行 WHERE 条件时还没有执行 SELECT 子句,也就没有生成字段的别名。
另外一个需要注意的操作就是 GROUP BY:
-- GROUP BY 错误示例
select saledate, product, sum(amount)
from sales_data group by saledate
由于经过 GROUP BY 处理之后结果集只保留了分组字段和聚合函数的结果,示例中的 product 字段已经不存在;如果需要同时显示product和saledate,可以使用窗口函数。
如果使用了 GROUP BY 分组,之后的 SELECT、ORDER BY 等只能引用分组字段或者聚合函数;不分组,则可以引用 FROM 和 JOIN 表中的任何字段。
还有一些逻辑问题可能不会直接导致查询出错,但是会返回不正确的结果;例如外连接查询中的 ON 和 WHERE 条件。以下是一个左外连接查询的示例:
SELECT e.emp_name, d.dept_name
FROM employee e
LEFT JOIN department d ON (e.dept_id = d.dept_id)
WHERE e.emp_name ='张飞';
/*
张飞 行政管理部
*/
SELECT e.emp_name, d.dept_name
FROM employee e
LEFT JOIN department d ON (e.dept_id = d.dept_id AND e.emp_name ='张飞');
/*
刘备 NULL
关羽 NULL
张飞 行政管理部
诸葛亮 NULL
*/
第一个查询在 ON 子句中指定了连接的条件,同时通过 WHERE 子句找出了 "张飞" 的信息。
第二个查询将所有的过滤条件都放在 ON 子句中,结果返回了所有的员工信息。这是因为左外连接会返回左表中的全部数据,即使 ON 子句中指定了员工姓名也不会生效;而 WHERE 条件在逻辑上是对连接操作之后的结果进行过滤。
除此之外,了解 SQL 逻辑执行顺序也可以帮助我们进行 SQL 优化。例如 WHERE 子句在 HAVING 子句之前执行,因此我们应该尽量使用 WHERE 进行数据过滤,避免无谓的操作;除非业务需要针对聚合函数的结果进行过滤。
数据分析功能:
SQL 作为一种数据领域的专用语言,必然支持数据分析所需的各种功能:
- CASE 表达式可以为 SQL 语句提供逻辑处理的能力,理论上来说可以实现任意复杂的处理逻辑;
- 空值(NULL)代表了缺失的数据,空值处理是数据分析中的常见问题;
- 函数通常为我们提供了某种功能, SQL 中的各种内置标量函数提高了我们处理数据的效率;
- 聚合函数与分组操作相结合可以实现数据的汇总和多维度分析报表;
- 窗口函数可以进一步完成累计分析、移动分析以及分类排名等复杂的报表需求;
- 行模式识别(MATCH_RECOGNIZE)可以用于分析各种数据流,例如股票行情数据分析、金融欺诈检测等。
数据库设计与应用开发:
数据库设计通常遵循一定的流程,其中 ER 图和规范化是两种常用的技术。设计关系模式时需要考虑字段类型的选择和完整性约束问题,最终我们可以使用 DDL 语句创建表和索引等对象,同时利用 DML 语句对表中的数据执行增删改合操作。
数据库事务是一组业务逻辑上的操作单元,具有 ACID 属性。隔离可以确保数据的一致性,但是会影响并发处理的能力。与数据库性能相关的一个重要对象是索引,合理利用索引和一些查询技巧通常可以优化 SQL 语句的性能,与此相关的一个重要的概念就是执行计划。
除了声明式的 SQL 语句之外,数据库还提供了服务器端的编程功能,例如存储过程和触发器。应用程序也可以通过驱动连接数据库,执行各种数据操作;为了防止动态语句可能带来的 SQL 注入问题,我们应该使用参数化或者带绑定变量的预编译语句。
另外,关系数据库对 JSON 文档的支持使得我们可以同时获得SQL 的强大功能和事务支持(ACID)以及 NoSQL 的灵活性和高性能。
到这里就结束了,当然还有不少本文没有说的,但是对于日常工作来说应该是差不多了。至于更高深的内容,可以工作中慢慢积累,或者网上搜索、寻找其他的教程。总而言之,SQL是很强大的,不要觉得SQL没什么东西,如果把SQL学好了,其实是件非常了不起的事情。
最后以我女神的照片作为结束吧

如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号