《数据库基础语法》14. SQL 的窗口函数
使用窗口函数进行移动分析和累计求和
上一节我们学习了利用 GROUP BY 子句的扩展选项(ROLLUP、CUBE 以及 GROUPING SETS)实现数据的层次统计、交叉汇总以及自定义维度分析等高级功能。
不过,产品和业务对于复杂报表的需求并不仅仅止步于此。例如,如何分析员工在部门内的薪酬排名、计算产品每个月的累计销量以及与去年同期相比的增长率等。这些分析功能通过分组汇总操作通常很难或者无法实现,因此我们需要了解更加强大的 SQL 窗口函数(Window Function)。
窗口函数定义:
与聚合函数类似,窗口函数也是针对一组数据进行分析计算;但窗口函数不是将一组数据汇总成单个结果,而是为每一行数据返回一个分析结果。下图演示了两者之间的区别:
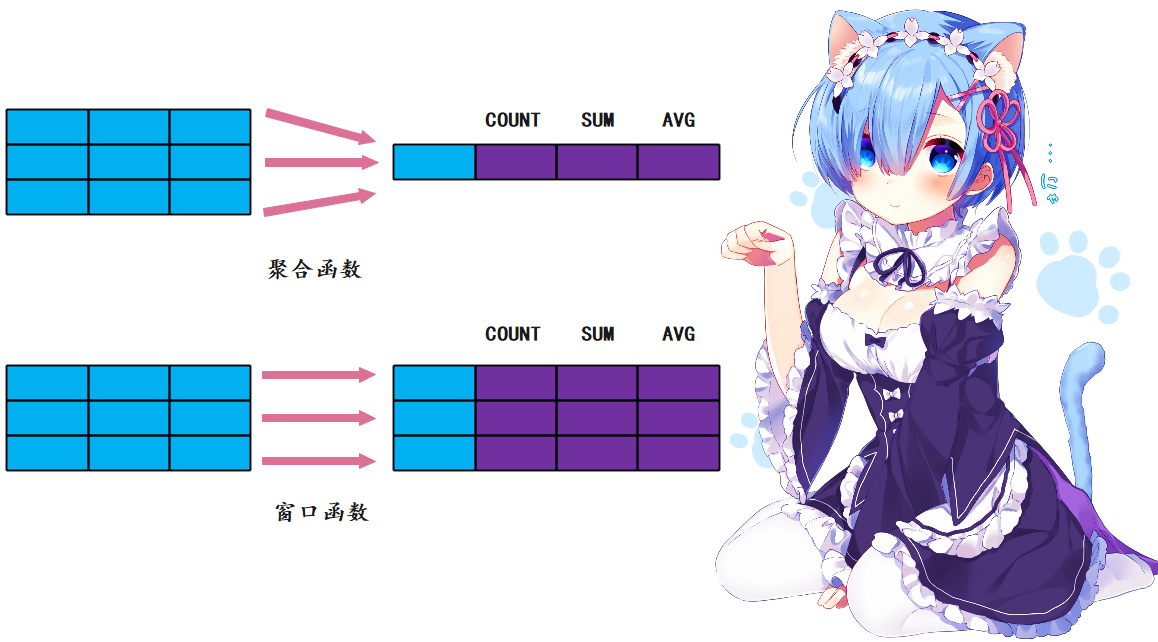
聚合函数会将同一个组内的多条数据汇总成一条数据,但是窗口函数保留了所有的原始数据。
窗口函数也被称为联机分析处理(OLAP)函数,或者分析函数(Analytic Function)。
我们以 SUM 函数为例,比较这两种函数的差异。如果例子不理解的话,继续往下看。
select sum(amount) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
11970
*/
select saledate, product, sum(amount) over() as sum_amount
from sales_data
where saledate = '2019-01-01'
/*
2019-01-01 桔子 11970
2019-01-01 桔子 11970
2019-01-01 桔子 11970
2019-01-01 香蕉 11970
2019-01-01 香蕉 11970
2019-01-01 香蕉 11970
2019-01-01 苹果 11970
2019-01-01 苹果 11970
2019-01-01 苹果 11970
2019-01-01 桔子 11970
*/
OVER 关键字表明 SUM 是一个窗口函数;括号内为空表示将所有数据作为整体进行分析。
查询结果返回了所有的记录,并且 SUM 聚合函数为每条记录都返回了相同的汇总结果。
从上面的示例可以看出,窗口函数与其他函数的不同之处在于它包含了一个 OVER 子句;OVER 子句用于定义一个分析数据的窗口。完整的窗口函数定义如下:
window_function ( expression ) OVER (
PARTITION BY ...
ORDER BY ...
frame_clause
)
其中,window_function 是窗口函数的名称;expression 是窗口函数操作的对象,可以是字段或者表达式;OVER 子句包含三个部分:分区(PARTITION BY)、排序(ORDER BY)以及窗口大小(frame_clause)。
接下来我们分别介绍这些选项的作用。
分区(PARTITION BY):
OVER 子句中的 PARTITION BY 选项用于定义分区,作用类似于 GROUP BY 分组;如果指定了分区选项,窗口函数将会分别针对每个分区单独进行分析。
select saledate, product, sum(amount) over(partition by product) as sum_amount
from sales_data
where saledate = '2019-01-01'

我们看到窗口函数就是针对partition by后面字段进行分区,相同的分为一个区,然后对每个分区里面的值进行计算。我们按照product进行分区,那么所有值为"桔子"的分为一区,那么它的sum_amount就是所有值为"桔子"的amount之和,同理苹果、香蕉也是如此。
我们看到窗口函数,虽然也用到了聚合,但是它并不需要group by,因为字段的数量和原来保持一致。只是针对partition by后面的字段进行分区,然后对每一个区使用聚合得到一个值,然后给该分区的所有记录都添上这么一个值。
现在再回来看开始的例子,saledate='2019-01-01'的记录有10条,那么select sum(amount) from sale_data saledate='2019-01-01'得到的数据只有一条,也就是所有的amount之和。而select sum(amount) over() from sale_data saledate='2019-01-01',我们说由于over()里面是空的,所以相当于整体只有一个分区,这个分区就是整个筛选出来的数据集,那么还是计算所有的amount之和,但是返回的是10条,和原来的数据行数保持一致。
并且窗口函数不需要group by,前面可以直接加上指定的字段,还是那句话,它不改变数据集的大小,而是在聚合之后给原来的每一条记录都添上这么一个值。但是普通的聚合就不行了,如果select指定了其它字段,那么这些字段必须出现在聚合函数、或者group by字句中,并且计算完之后数据行数会减少(除非group by后面的字段都不重复,但如果不重复的话,我们一般也不会用它来group by)
partition by后面可以指定多个字段,比如:
select saledate, product, amount, sum(amount) over(partition by saledate, product) as sum_amount
from sales_data
where saledate < '2019-01-04'
/*
2019-01-01 桔子 1864.00 5929
2019-01-01 桔子 1329.00 5929
2019-01-01 桔子 1736.00 5929
2019-01-01 桔子 1000.00 5929
2019-01-01 苹果 568.00 1926
2019-01-01 苹果 847.00 1926
2019-01-01 苹果 511.00 1926
2019-01-01 香蕉 1364.00 4115
2019-01-01 香蕉 1178.00 4115
2019-01-01 香蕉 1573.00 4115
2019-01-02 桔子 775.00 3297
2019-01-02 桔子 599.00 3297
2019-01-02 桔子 1923.00 3297
2019-01-02 苹果 564.00 3862
2019-01-02 苹果 1953.00 3862
2019-01-02 苹果 1345.00 3862
2019-01-02 香蕉 1057.00 4249
2019-01-02 香蕉 1580.00 4249
2019-01-02 香蕉 1612.00 4249
2019-01-03 桔子 1758.00 3405
2019-01-03 桔子 918.00 3405
2019-01-03 桔子 729.00 3405
2019-01-03 苹果 1329.00 4600
2019-01-03 苹果 1315.00 4600
2019-01-03 苹果 1956.00 4600
2019-01-03 香蕉 1142.00 3752
2019-01-03 香蕉 731.00 3752
2019-01-03 香蕉 1879.00 3752
*/
我们看到,partition by后面指定了saledate、product,那么相当于按照sale、product进行分区,相同的分为一区。然后对每一个分区里面的amount进行求和,然后给该分区里面的所有的行都添上求和之后的值。所以2019-01-01 桔子对应的sum_amount是5929,因为所有2019-01-01 桔子 对应的amount加起来是5929,然后给这个分区对应的每条记录都添上5929这个值。同理对于其它的记录也是同样的道理。
在窗口函数中指定 PARTITION BY 选项之后,不需要 GROUP BY 子句也能获得分组统计信息。如果不指定 PARTITION BY 选项,所有的数据作为一个整体进行分析。
排序(ORDER BY):
OVER 子句中的 ORDER BY 选项用于指定分区内的排序方式,与 ORDER BY 子句的作用类似;排序选项通常用于数据的排名分析。
partition by ... order by ... [asc|desc]
排序也是可以指定多个字段进行排序的,多个字段逗号分隔,order by要在partition by的后面。并且排序也是针对自身所在的分区来的,每个分区的内部进行排序。
对于 Oracle 和 PostgreSQL,OVER 子句中的 ORDER BY 选项也可以使用 NULLS FIRST 指定空值排在最前,或者 NULLS LAST 指定空值排在最后。这一点与 ORDER BY 子句相同。
我们现在知道了,partition by是根据指定字段分区,然后对每个分区使用前面的函数忘记说了,over()前面必须是函数,比如:sum(amount) over(),不可以是amount over()。然后order by是根据指定字段,对分区里面的记录进行排序。可以只指定partition by不指定order by,如果不考虑窗口内部记录的顺序的话。也可以只指定order by,不指定partition by。我们先来看看只指定order by,不指定partition by的话,会是什么结果。
select amount, sum(amount) over(order by amount) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
511.00 511
568.00 1079
847.00 1926
1000.00 2926
1178.00 4104
1329.00 5433
1364.00 6797
1573.00 8370
1736.00 10106
1864.00 11970
*/
select amount, sum(amount) over(order by amount desc) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
1864.00 1864
1736.00 3600
1573.00 5173
1364.00 6537
1329.00 7866
1178.00 9044
1000.00 10044
847.00 10891
568.00 11459
511.00 11970
*/
我们看到实现了累加的效果,我们知道指定partition by,那么根据哪些字段分区是由partition by后面的字段决定的。但如果在不指定partition by、只指定order by的情况下,那么就只有一个分区,这个分区就是全部记录,然后会根据order by后面的字段对全部记录进行排序,然后再进行累和(假设是对于sum而言,其它的函数也是类似的),所以第2行的值等于原来第1行的值加上原来第2行的值(后面举例说明)。
当然我们这里说的先干什么、然后干什么,只是为了方便理解,但是SQL在执行的时候,不一定是我们说的这样。但是逻辑是可以这样来理解的,按照这个逻辑来分析是可以完全吻合返回的结果的。
回到上面的例子,我们说是先排序,然后逐行累加。这是因为我们这里的amount没有重复的,所以是逐行累加。第1行:1864,第二行:1864+1736=3600,第3行:1864+1736+1573=5173
如果我们是根据product进行order by的话,product有重复的
select product, amount, sum(amount) over(order by product) as sum_amount
from sales_data where saledate = '2019-01-01';
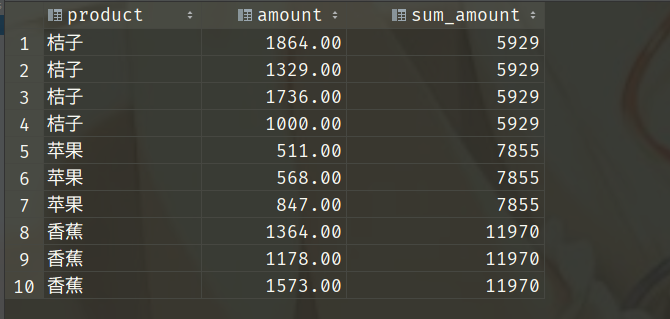
我们说order by是先排序,这是按照product排序,显然是按照其拼音首字符的ascii码进行排序。当然排序不重要,重点是后面的累加。我们看到并没有逐行累加,而是把product相同的先分别加在一起,得到的结果是:桔子:5929 苹果: 1926 香蕉:4115,然后再对整体进行累加,所以苹果的值应该是:5929+1926=7855,同理香蕉的值:5929+1926+4115=11970。
所以这个累加并不是针对每一行来的,而是先把product相同的amount都加在一起,然后对加在一起的值进行累加。并且累加之后,再将累加的的结果添加到对应product的每一条记录上。而我们上面第一个例子之所以是逐行累加,是因为我们order by指定的是amount,而amount都不重复。
但是问题来了,单独指定partition by和单独指定order by我们已经知道了,但如果partition by和order by同时指定的话会怎么样呢?
select product, amount, sum(amount) over (partition by product order by amount desc) as sum_amount
from sales_data
where saledate = '2019-01-01';
/*
桔子 1864.00 1864
桔子 1736.00 3600
桔子 1329.00 4929
桔子 1000.00 5929
苹果 847.00 847
苹果 568.00 1415
苹果 511.00 1926
香蕉 1573.00 1573
香蕉 1364.00 2937
香蕉 1178.00 4115
*/
我们看到是按照product分区,按照amount排序,但此时依旧出现了累和(假设前面的聚合是sum),但显然它是在分区内部进行累和。我们知道如果不指定partition by的话,那么order by amount会对整个数据集进行排序,然后进行累和。但是现在指定partition by了,那么会先根据partition by进行分区,然后order by的逻辑还是跟之前一样,可以认为是在各自的分区内部分别执行了order by。我们再来看个栗子
select product, saledate, amount, sum(amount) over (partition by product order by saledate) as sum_amount
from sales_data
where saledate < '2019-01-04';
/*
桔子 2019-01-01 1864.00 5929
桔子 2019-01-01 1329.00 5929
桔子 2019-01-01 1736.00 5929
桔子 2019-01-01 1000.00 5929
桔子 2019-01-02 775.00 9226
桔子 2019-01-02 1923.00 9226
桔子 2019-01-02 599.00 9226
桔子 2019-01-03 729.00 12631
桔子 2019-01-03 918.00 12631
桔子 2019-01-03 1758.00 12631
苹果 2019-01-01 568.00 1926
苹果 2019-01-01 511.00 1926
苹果 2019-01-01 847.00 1926
苹果 2019-01-02 1345.00 5788
苹果 2019-01-02 564.00 5788
苹果 2019-01-02 1953.00 5788
苹果 2019-01-03 1315.00 10388
苹果 2019-01-03 1329.00 10388
苹果 2019-01-03 1956.00 10388
香蕉 2019-01-01 1573.00 4115
香蕉 2019-01-01 1178.00 4115
香蕉 2019-01-01 1364.00 4115
香蕉 2019-01-02 1580.00 8364
香蕉 2019-01-02 1057.00 8364
香蕉 2019-01-02 1612.00 8364
香蕉 2019-01-03 1142.00 12116
香蕉 2019-01-03 731.00 12116
香蕉 2019-01-03 1879.00 12116
*/
以桔子为例,这个结果像不像我们单独使用order by的时候所得到的结果呢?我们是按照product分区的,相同的product归为一个区。然后在各自的分区里面,先通过order by saledate进行排序,再把saledate相同的amount先进行求和,以桔子为例:2019-01-01的amount总和是5929,2019-01-02的amount总和是3297,然后累加,2019-01-02的amount总和就是5929+3297=9226,同理3号、4号的逻辑也是如此。所以我们看到order by的逻辑不变,如果没有partition by,那么它的作用范围就是整个数据集、因为此时整体是一个分区;如果有partition by,那么在分区之后,order by的作用范围就是一个个的分区,就把每一个分区想象成独立的数据集就行,在各自的分区内部执行order by的逻辑。同理下面的苹果和香蕉也是一样的逻辑。
可能我说的有点绕,但是操作一下还是很好理解的。
指定窗口大小:
指定窗口大小稍微有点复杂,可能需要花点时间来理解,与其说复杂,倒不如说东西有点多。可能开始不理解,但是坚持看完,你肯定会明白的,不要看到一半就放弃了,一定要看完,因为通过后面的例子、以及解释会对开始的内容进行补充和呼应。
OVER 子句中的 frame_clause 选项用于指定一个移动的窗口。窗口总是位于分区范围之内,是分区的一个子集。指定了窗口之后,函数不再基于分区进行计算,而是基于窗口内的数据进行计算。窗口选项可以实现许多复杂的计算。例如,累计到当前日期为止的销量总计,每个月份及其前后各一月(3 个月)的平均销量等。
窗口大小的具体选项如下:
ROWS frame_start
-- 或者
ROWS BETWEEN frame_start AND frame_end
其中,ROWS 表示以行为单位计算窗口的偏移量。frame_start 用于定义窗口的起始位置,可以指定以下内容之一:
- UNBOUNDED PRECEDING,窗口从分区的第一行开始,默认值;
- N PRECEDING,窗口从当前行之前的第 N 行开始;
- CURRENT ROW,窗口从当前行开始。
frame_end 用于定义窗口的结束位置,可以指定以下内容之一:
- CURRENT ROW,窗口到当前行结束,默认值;
- N FOLLOWING,窗口到当前行之后的第 N 行结束。
- UNBOUNDED FOLLOWING,窗口到分区的最后一行结束;
下图演示了这些窗口选项的作用:
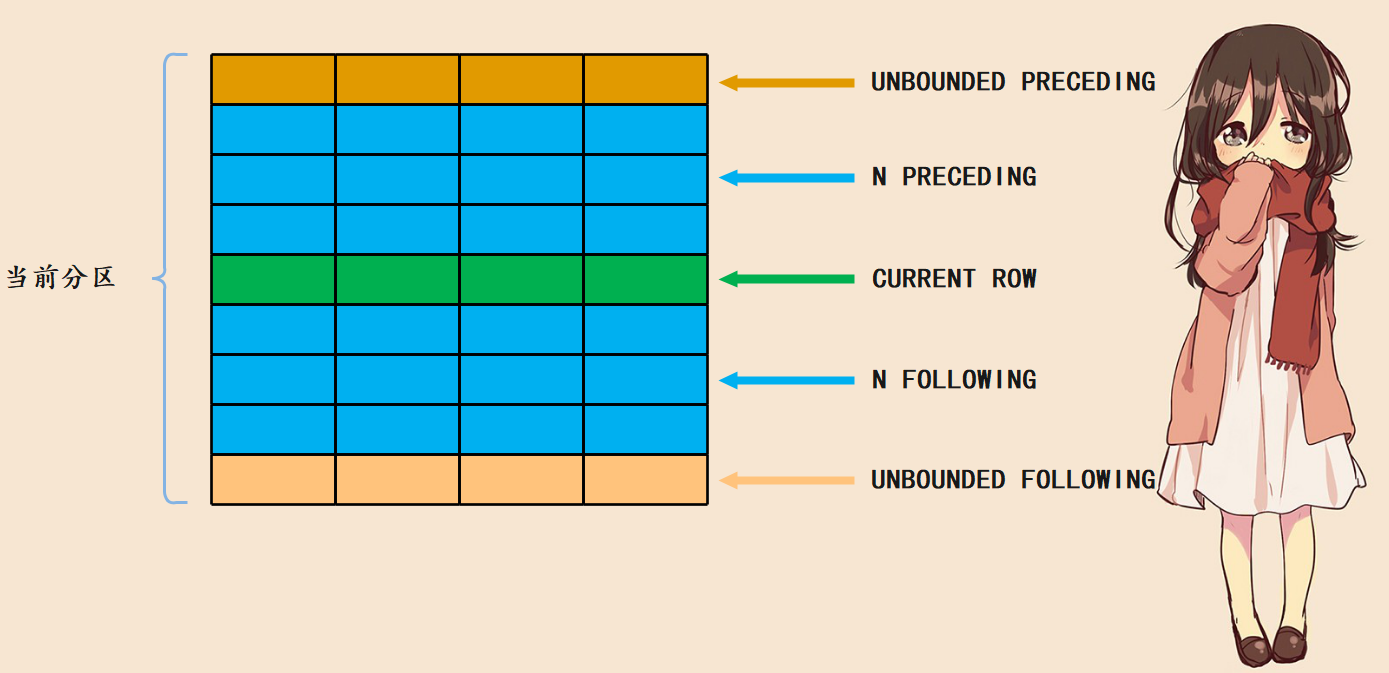
窗口函数依次处理每一行数据,CURRENT ROW 表示当前正在处理的数据;其他的行可以使用相对当前行的位置表示。需要注意的是,窗口的大小不会超出分区的范围。
窗口函数的选项比较复杂,我们通过一些常见的窗口函数示例来理解它们的作用。常见的窗口函数可以分为以下几类:聚合窗口函数、排名窗口函数以及取值窗口函数。
许多聚合函数也可以作为窗口函数使用,包括 AVG、SUM、COUNT、MAX 以及 MIN 等。
-- 本来order by amount是按对每个分区内部的记录进行累加的,当然这里的累加并不是逐行累加,是我们上面说的那样
-- 只是为了方便,我们就直接说累加了,或者累和也是一样,因为我们这里是以sum函数为例子
-- 但是我们指定了窗口大小,那么怎么加就由我们指定的窗口大小来决定了,而不是整个分区
select product, amount,
sum(amount) over(partition by product order by amount rows unbounded preceding) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
桔子 1000.00 1000
桔子 1329.00 2329
桔子 1736.00 4065
桔子 1864.00 5929
苹果 511.00 511
苹果 568.00 1079
苹果 847.00 1926
香蕉 1178.00 1178
香蕉 1364.00 2542
香蕉 1573.00 4115
*/
OVER 子句中的 PARTITION BY 选项表示按照product进行分区,ORDER BY 选项表示按照amount进行排序。窗口子句 ROWS UNBOUNDED PRECEDING 指定窗口从分区的第一行开始,默认到当前行结束;也就是分区的第一行从上往下一直加到当前行结束,因为前面的聚合是sum。
同理,N PRECEDING 则是从当前行的上N行开始、加到当前行结束,如果是2 PRECEDING ,那么第5行就是,第3行+第4行、再加上当前的第5行
select product, amount,
sum(amount) over(partition by product order by amount rows 2 preceding) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
桔子 1000.00 1000 -- 其本身
桔子 1329.00 2329 -- 上面只有1行,没有两行,那么有多少加多少 1000+1329
桔子 1736.00 4065
桔子 1864.00 4929 -- 上两行加上当前行,1329 + 1736 + 1864
苹果 511.00 511
苹果 568.00 1079
苹果 847.00 1926
香蕉 1178.00 1178
香蕉 1364.00 2542
香蕉 1573.00 4115
*/
最后再来看看CURRENT ROW,它是最简单的了
select product, amount,
sum(amount) over(partition by product order by amount rows current row ) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
桔子 1000.00 1000
桔子 1329.00 1329
桔子 1736.00 1736
桔子 1864.00 1864
苹果 511.00 511
苹果 568.00 568
苹果 847.00 847
香蕉 1178.00 1178
香蕉 1364.00 1364
香蕉 1573.00 1573
*/
我们看到没有变化,因为这表示从当前行开始、到当前行,所以就是其本身。所以它单独使用没有太大意义,而是和结束位置一起使用。
select product, amount,
sum(amount) over(
-- 从当前行加到窗口的结尾
partition by product order by amount rows between current row and unbounded following
) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
桔子 1000.00 5929 -- 1000 + 1329 + 1736 + 1864
桔子 1329.00 4929 -- 1329 + 1726 + 1864
桔子 1736.00 3600 -- 1726 + 1864
桔子 1864.00 1864 -- 1864
苹果 511.00 1926 -- 其它依次类推
苹果 568.00 1415
苹果 847.00 847
香蕉 1178.00 4115
香蕉 1364.00 2937
香蕉 1573.00 1573
*/
我们指定其它的范围
select product, amount,
-- 计算平均值
avg(amount) over(
-- 表示从当前行的上1行开始,到当前行的下1行结束。当然我们这里数据集比较少,具体指定为多少由你自己决定
-- 然后计算这三行的平均值
partition by product order by amount rows between 1 preceding and 1 following
) as sum_amount
from sales_data where saledate = '2019-01-01';
/*
桔子 1000.00 1164.5 -- 1000上面没有值,下面有一个1329,所以直接是(1000+1329) / 2,因为只有两个值,所是除以2
桔子 1329.00 1355 -- 上面的1000 + 当前的1329 + 下面的1736,然后总和除以3,等于1355
桔子 1736.00 1643 -- 上面的1329 + 当前的1736 + 下面的1864,然后总和除以3,等于1800
桔子 1864.00 1800 -- 上面的1736 + 当前的1864,因为下面没值了,准确的说是该窗口中下面已经没值了,所以总和加起来除以2,等于1800
苹果 511.00 539.5 -- 其它的以此类推
苹果 568.00 642
苹果 847.00 707.5
香蕉 1178.00 1271
香蕉 1364.00 1371.6666666666666667
香蕉 1573.00 1468.5
*/
所以我们看到可以在窗口中指定大小,方式为:rows frame_start或者rows between frame_start and frame_end,如果出现了frame_end那么必须要有frame_start,并且是通过between and的形式
frame_start的取值为:没有frame_end的情况下,unbounded preceding(从窗口的第一行到当前行),n preceding(从当前行的上n行到当前行),current now(从当前行到当前行)。
frame_end的取值为:current now(从frame_start到当前行),n following(从frame_start到当前行的下n行),unbounded following(从frame_start到窗口的最后一行)
具体怎么使用,由你当前业务决定。另外我们目前都是通过rows frame_start和rows between frame_start and between_end,其实这个rows也可以换成range,具体这两者什么区别这里不细说了,可以去网上搜索。但是基本上我们使用rows即可。
使用窗口函数进行分类排名和环比、同比分析
上一节我们介绍了窗口函数的概念和语法,以及聚合窗口函数的使用。下面我们继续讨论 SQL 中的排名窗口函数和取值窗口函数,它们分别可以用于统计产品的分类排名和数据的环比/同比分析
排名窗口函数:
排名窗口函数用于对数据进行分组排名。常见的排名窗口函数包括:
- ROW_NUMBER,为分区中的每行数据分配一个序列号,序列号从 1 开始分配。
- RANK,计算每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。
- DENSE_RANK,计算每行数据在其分区中的名次;即使存在名次相同的数据,后续的排名也是连续的值。
- PERCENT_RANK,以百分比的形式显示每行数据在其分区中的名次;如果存在名次相同的数据,后续的排名将会产生跳跃。
- CUME_DIST,计算每行数据在其分区内的累积分布。
- NTILE,将分区内的数据分为 N 等份,为每行数据计算其所在的位置。
排名窗口函数不支持动态的窗口大小(frame_clause),而是以整个分区(PARTITION BY)作为分析的窗口。接下来我们通过示例了解一下这些函数的作用。
按照分类进行排名:
select product, amount, row_number() over (partition by product order by amount) as sum_amount
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 1
桔子 1329.00 2
桔子 1736.00 3
桔子 1864.00 4
苹果 511.00 1
苹果 568.00 2
苹果 847.00 3
香蕉 1178.00 1
香蕉 1364.00 2
香蕉 1573.00 3
*/
我们使用order by进行排序的时候,除了进行累和之外,很多时候也会通过SQL提供的排名窗口函数为其加上一个排名。比如row_numer(),它是针对每个窗口、然后给里面的记录生成1 2 3...这样的序列号。我们先按照amount排个序,然后此时的序列号不就相当于名次了吗。当然如果没有partition by,那么就是针对整个数据集进行排名,因为此时只有一个窗口,也就是整个数据集。
当然如果不排序的话,也是可以使用row_number(),只不过此时的序号就不能代表什么了。
select product, amount, row_number() over (partition by product)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1864.00 1
桔子 1329.00 2
桔子 1736.00 3
桔子 1000.00 4
苹果 511.00 1
苹果 568.00 2
苹果 847.00 3
香蕉 1364.00 1
香蕉 1178.00 2
香蕉 1573.00 3
*/
-- 如果不指定order by也是可以使用row_number()生成序列号,但还是那句话,此时的序列号只是单纯的1 2 3...
-- 它不能代表什么。如果还按照amount排序了,那么我们说此时的row_number()则是对应窗口内部的amount的排名。
再来看看rank()
-- rank()就是排名了, 功能和row_number()类似
select product, amount, rank() over (partition by product order by amount)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 1
桔子 1329.00 2
桔子 1736.00 3
桔子 1864.00 4
苹果 511.00 1
苹果 568.00 2
苹果 847.00 3
香蕉 1178.00 1
香蕉 1364.00 2
香蕉 1573.00 3
*/
-- 如果不指定order by,那么使用rank()会得到什么结果呢?
select product, amount, rank() over (partition by product)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1864.00 1
桔子 1329.00 1
桔子 1736.00 1
桔子 1000.00 1
苹果 511.00 1
苹果 568.00 1
苹果 847.00 1
香蕉 1364.00 1
香蕉 1178.00 1
香蕉 1573.00 1
*/
-- 我们看到全部是1,都是第一名
我们看到除了rank,还有dense_rank,那么它们有什么区别呢?假设A和B考了100分,那么A和B都是第一。但如果是rank()的话,紧接着考了99分的C只能是第3名,因为前面已经有两人了,可以认为是按照人数算的;但如果是dense_rank()的话,考了99分的C则是第二名,也就是并列第一看做是一个人,可以认为是按照名次的顺序算的,因为A和B都是第一,那么C就该第二了。
所以两者的区别就在于此。
select product, amount, percent_rank() over (partition by product order by amount)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 0
桔子 1329.00 0.3333333333333333
桔子 1736.00 0.6666666666666666
桔子 1864.00 1
苹果 511.00 0
苹果 568.00 0.5
苹果 847.00 1
香蕉 1178.00 0
香蕉 1364.00 0.5
香蕉 1573.00 1
*/
至于percent_rank()则是按照排名计算百分比,区间是[0, 1],也就是位于这个区间的什么位置。
select product,
amount,
rank() over (partition by product order by amount) as rank,
dense_rank() over (partition by product order by amount) as dense_rank,
percent_rank() over (partition by product order by amount) as percent_rank
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 1 1 0
桔子 1329.00 2 2 0.3333333333333333
桔子 1736.00 3 3 0.6666666666666666
桔子 1864.00 4 4 1
苹果 511.00 1 1 0
苹果 568.00 2 2 0.5
苹果 847.00 3 3 1
香蕉 1178.00 1 1 0
香蕉 1364.00 2 2 0.5
香蕉 1573.00 3 3 1
*/
-- 关于窗口函数的写法,我们也可以按照如下方式
-- 由于我们这里的窗口都是(partition by product order by amount),如果是多个窗口
-- 那么就是 window r1 as (...), r2 as (...)
select product,
amount,
rank() over r as rank,
dense_rank() over r as dense_rank,
percent_rank() over r as percent_rank
from sales_data
where saledate = '2019-01-01'
window r as (partition by product order by amount)
;
-- 得到的结果和上面是一样的
我们在查询的最后定义了一个窗口(WINDOW)变量 r,然后在窗口函数的 OVER 子句中使用了该变量;这样可以简化函数的输入。不过,Oracle 和 SQL Server 目前还不支持这种写法。
另外,利用排名窗口函数可以获得每个类别中的 Top-N 排行榜。
select * from
(select product,
amount,
rank() over (partition by product order by amount) as rank
from sales_data
where saledate = '2019-01-01') as tmp -- 我们说select from也可以当成一张表来用,tmp就是表名
-- 获取tmp.rank <= 2的,就拿出了每个product对应amount的前两名,当然我们这里是升序排序的
where tmp.rank <= 2;
/*
桔子 1000.00 1
桔子 1329.00 2
苹果 511.00 1
苹果 568.00 2
香蕉 1178.00 1
香蕉 1364.00 2
*/
-- 倒序排序
select * from
(select product,
amount,
rank() over (partition by product order by amount desc) as rank
from sales_data
where saledate = '2019-01-01') as tmp
where tmp.rank <= 2
/*
桔子 1864.00 1
桔子 1736.00 2
苹果 847.00 1
苹果 568.00 2
香蕉 1573.00 1
香蕉 1364.00 2
*/
累积分布与分片位置:
CUME_DIST 函数计算数据对应的累积分布,也就是排在该行数据之前的所有数据所占的比率;取值范围为大于 0 并且小于等于 1。
select product,
amount,
cume_dist() over (order by amount),
percent_rank() over (order by amount)
from sales_data
where saledate < '2019-01-03'
/*
苹果 511.00 0.05263157894736842 0
苹果 564.00 0.10526315789473684 0.05555555555555555
苹果 568.00 0.15789473684210525 0.1111111111111111
桔子 599.00 0.21052631578947367 0.16666666666666666
桔子 775.00 0.2631578947368421 0.2222222222222222
苹果 847.00 0.3157894736842105 0.2777777777777778
桔子 1000.00 0.3684210526315789 0.3333333333333333
香蕉 1057.00 0.42105263157894735 0.3888888888888889
香蕉 1178.00 0.47368421052631576 0.4444444444444444
桔子 1329.00 0.5263157894736842 0.5
苹果 1345.00 0.5789473684210527 0.5555555555555556
香蕉 1364.00 0.631578947368421 0.6111111111111112
香蕉 1573.00 0.6842105263157895 0.6666666666666666
香蕉 1580.00 0.7368421052631579 0.7222222222222222
香蕉 1612.00 0.7894736842105263 0.7777777777777778
桔子 1736.00 0.8421052631578947 0.8333333333333334
桔子 1864.00 0.8947368421052632 0.8888888888888888
桔子 1923.00 0.9473684210526315 0.9444444444444444
苹果 1953.00 1 1
*/
这个cume_dist和percent_rank有点像,但是percent_rank类似于排名,根据记录数将[0, 1]等分,然后计算该值在区间中所占的位置。我们以桔子 1329.00 0.5263157894736842 0.5为例,0.5percent_rank表示该值正好排在中间的位置。0.5263157894736842cume_dist表示有大概百分之52.63的amount小于等于1329。
最后再来看看NTILE,NTILE 函数将分区内的数据分为 N 等份,并计算数据所在的分片位置。
select product,
amount,
ntile(5) over (order by amount)
from sales_data
where saledate = '2019-01-01'
/*
苹果 511.00 1
苹果 568.00 1
苹果 847.00 2
桔子 1000.00 2
香蕉 1178.00 3
桔子 1329.00 3
香蕉 1364.00 4
香蕉 1573.00 4
桔子 1736.00 5
桔子 1864.00 5
*/
-- 为1的表示对应的amount(销售额)最低的百分之20的水果
取值窗口函数:
取值窗口函数用于返回指定位置上的数据。常见的取值窗口函数包括:
- FIRST_VALUE,返回窗口内第一行的数据。
- LAG,返回分区中当前行之前的第 N 行的数据。
- LAST_VALUE,返回窗口内最后一行的数据。
- LEAD,返回分区中当前行之后第 N 行的数据。
- NTH_VALUE,返回窗口内第 N 行的数据。
其中,LAG 和 LEAD 函数不支持动态的窗口大小(frame_clause),而是以分区(PARTITION BY)作为分析的窗口。
我们先来看看lag,lag比较重要,它可以用来计算差值。
select product,
amount,
-- lag是返回当前行的第n行数据,我们这里1
-- 所以第2行,返回第1行,第3行返回第2行,依次类推,至于第1行,由于上面没有东西,所以返回null
lag(amount, 1) over (order by amount)
from sales_data
where saledate = '2019-01-01';
-- 我们这里没有指定分区,所以是整个数据集。如果指定了分区,那么就是每一个窗口
/*
苹果 511.00 null
苹果 568.00 511
苹果 847.00 568
桔子 1000.00 847
香蕉 1178.00 1000
桔子 1329.00 1178
香蕉 1364.00 1329
香蕉 1573.00 1364
桔子 1736.00 1573
桔子 1864.00 1736
*/
-- 如果一来,我们就可以计算amount的增长值,这里还是针对整个数据集
-- 如果想看每一天的增长值,那么就针对日期进行开窗即可。
select product,
amount,
concat(amount, ' - ', lag(amount, 1) over (order by amount), ' = ',
amount - (lag(amount, 1) over (order by amount))
) as incr
from sales_data
where saledate = '2019-01-01';
/*
苹果 511.00 511.00 - =
苹果 568.00 568.00 - 511.00 = 57.00
苹果 847.00 847.00 - 568.00 = 279.00
桔子 1000.00 1000.00 - 847.00 = 153.00
香蕉 1178.00 1178.00 - 1000.00 = 178.00
桔子 1329.00 1329.00 - 1178.00 = 151.00
香蕉 1364.00 1364.00 - 1329.00 = 35.00
香蕉 1573.00 1573.00 - 1364.00 = 209.00
桔子 1736.00 1736.00 - 1573.00 = 163.00
桔子 1864.00 1864.00 - 1736.00 = 128.00
*/
当然计算差值之后,我们还可以用来计算比率。
LEAD 函数与 LAG 函数类似,但它返回的是当前行之后的第 N 行数据。
再来看看first_value、last_value
select product,
amount,
-- 返回每个窗口的第一个排序之后的amount的值
first_value(amount) over (partition by product order by amount),
-- 返回每个窗口的最后一个排序之后的amount的值
last_value(amount) over (partition by product order by amount)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 1000 1000
桔子 1329.00 1000 1329
桔子 1736.00 1000 1736
桔子 1864.00 1000 1864
苹果 511.00 511 511
苹果 568.00 511 568
苹果 847.00 511 847
香蕉 1178.00 1178 1178
香蕉 1364.00 1178 1364
香蕉 1573.00 1178 1573
*/
-- 我们看到last_value对应的值貌似不太正常,以桔子为例,难道不应该都是1864吗?
-- 其实还是我们之前说的,order by排序之后,会有一个累计的效果,比如前面的窗口函数,如果是sum,那么就会累加
-- 比如第一行1000,那么first_value就是1000,last_value也是1000。
-- 但是到了第二行,显然last_value就是1329了,因为1329是排好序的最后一行(对于当前位置来说),至于first_value在该窗口内部永远是1000,因为1000是第一个值
-- 所以order by让人不容易理解的地方就在于,一旦它被指定,那么就不再是对分区进行整体计算了,而是对窗口内部的记录进行排序、并且进行累计
-- 还是sum,此时不是对整个分区求和、把值添加到分区对应记录中,而是对分区的记录的值进行累加
-- 对应到这里的last_value也是一样的,一开始是1000,但是order by具有累计的效果,至于怎么累计就取决于前面的函数是什么
-- 如果sum就是和下一条记录的值(amount)1329累加,这里是last_value,那么累计在一起就表现在1329取代1000变成了新的最后一行。
-- 当然我们这里以amount进行的order by,而amount都是不一样的
-- 如果按照product就不一样了
select product,
amount,
first_value(amount) over (partition by product order by product),
last_value(amount) over (partition by product order by product)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1864.00 1864 1000
桔子 1329.00 1864 1000
桔子 1736.00 1864 1000
桔子 1000.00 1864 1000
苹果 511.00 511 847
苹果 568.00 511 847
苹果 847.00 511 847
香蕉 1364.00 1364 1573
香蕉 1178.00 1364 1573
香蕉 1573.00 1364 1573
*/
-- 每个分区里面的product都是一样的, 而我们按照product进行order by的话
-- 那么相同的product应该作为一个整体,所以结果就是上面的那样
-- 至于first_value和last_value的关系,桔子对应的是first_value大于last_value
-- 苹果对应的是first_value小于last_value,这是由amount的顺序决定的
-- 总之first_value是整个分区的第一条记录,last_value是整个分区的最后一条记录
-- 因为order by指定的是product,而product在每个分区里面都是一样的,而它们是一个整体
-- 有点不好理解,但如果是作用整个分区,order by发挥作用,就是我们上一节说的逻辑
-- 但是像我们通过rows指定窗口大小、以及刚才的leg等等,如果是它们的话,那么就不用考虑order by了
-- 此时的order by只负责排序,计算的话也不是先聚合再累加,而是我们对指定的窗口内的数据进行聚合。
-- 如果是lag,那么order by也只负责排序,怎么计算由lag决定,lag是要求当前数据的上N行的数据。
最后再来看看nth_value,返回窗口内第n行数据
select product,
amount,
-- 返回每个窗口的第2个排序之后的amount的值
nth_value(amount, 2) over (partition by product order by amount)
from sales_data
where saledate = '2019-01-01';
/*
桔子 1000.00 null
桔子 1329.00 1329
桔子 1736.00 1329
桔子 1864.00 1329
苹果 511.00 null
苹果 568.00 568
苹果 847.00 568
香蕉 1178.00 null
香蕉 1364.00 1364
香蕉 1573.00 1364
*/
-- 这个也是一样,order by也是具有累计的效果
-- 以第一个分区为例,第1行记录是1000,它没有第2个元素,所以是null
-- 第2行记录是1329,那么第2个就是1329
-- 同理第3、第4,第2个也是1329,我们说order by具有累计的效果
SQL Server 目前不支持 NTH_VALUE 函数。
小结
窗口函数是一类能够提供复杂统计报表的强大函数,这些功能通常很难使用一般的聚合函数和分组操作来实现。本节介绍了窗口函数的定义和选项,以及如何将聚合函数作为窗口函数使用,实现数据的累计求和与移动分析。
本节我们学习了另外两类窗口函数:用于计算分类排名的排名窗口函数,以及获取指定位置数据的取值窗口函数。SQL 分析函数为数据仓库和在线分析系统(OLAP)提供了强大易用的分析和报表功能,并且在各种数据库中可以通用。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号