解密 Paxos 算法
楔子
提到分布式算法,就不得不提 Paxos 算法,在过去几十年里,它基本上是分布式共识的代名词,因为当前最常用的一批共识算法都是基于它改进的,比如 Fast Paxos 算法、Cheap Paxos 算法、Raft 算法、ZAB 协议等等。而很多小伙伴都会在准确和系统理解 Paxos 算法上踩坑,比如,只知道它可以用来达成共识,但不知道它是如何达成共识的。
这其实侧面说明了 Paxos 算法有一定的难度,可分布式算法本身就很复杂,Paxos 算法自然也不会例外,当然了,除了这一点,还跟兰伯特有关。兰伯特提出的 Paxos 算法包含 2 个部分:
一个是 Basic Paxos 算法,描述的是多节点之间如何就某个值(提案 Value)达成共识;另一个是 Multi-Paxos 思想,描述的是执行多个 Basic Paxos 实例,就一系列值达成共识。
可因为兰伯特提到的 Multi-Paxos 思想,缺少代码实现的必要细节(比如怎么选举领导者),所以在理解上比较难。下面我们就来以 Basic Paxos 和 Multi-Paxos 为核心,来了解 Basic Paxos 如何达成共识,以及针对 Basic Paxos 的局限性 Multi-Paxos 又是如何改进的。下面先来聊聊 Basic Paxos,因为 Basic Paxos 是 Multi-Paxos 思想的核心,说白了 Multi-Paxos 就是多执行几次 Basic Paxos。所以掌握它之后,我们能更好地理解基于 Multi-Paxos 思想的共识算法(比如 Raft 算法),还能掌握分布式共识算法的最核心内容,当现在的算法不能满足业务需求,进行权衡折中,设计自己的算法。
如何在多个节点间确定某变量的值?
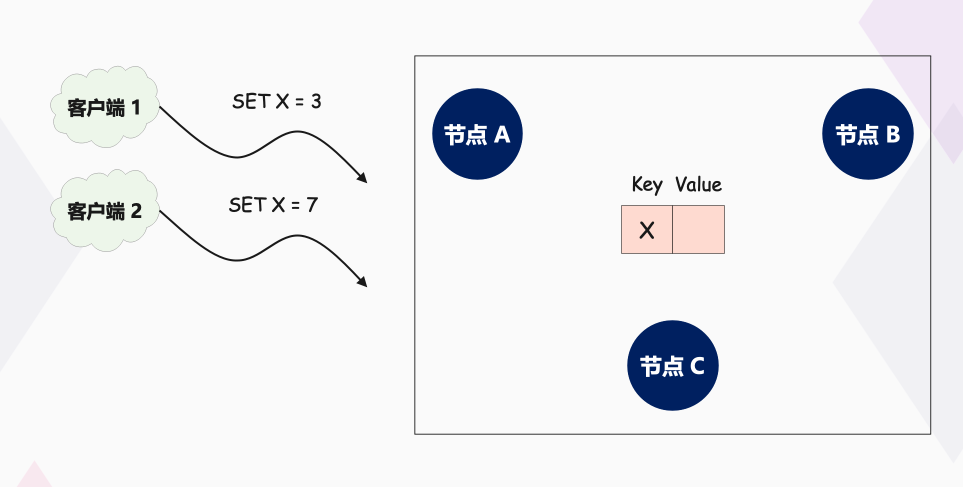
假设我们要实现一个分布式集群,这个集群是由节点 A、B、C 组成,提供只读 KV 存储服务。你应该知道,创建只读变量的时候,必须要对它进行赋值,而且这个值后续没办法修改。因此一个节点创建只读变量后就不能再修改它了,因此所有节点必须要先对只读变量的值达成共识,然后所有节点再一起创建这个只读变量。
那么,当有多个客户端(比如客户端 1、2)访问这个系统,试图创建同一个只读变量 X,客户端 1 试图创建值为 3 的 X,客户端 2 试图创建值为 7 的 X,这样要如何达成共识,实现各节点上 X 值的一致呢?带着这个问题,我们进入今天的学习。
在一些经典的算法中,我们会看到一些既形象又独有的概念(比如二阶段提交协议中的协调者),Basic Paxos 算法也不例外。为了帮助人们更好地理解 Basic Paxos 算法,兰伯特在讲解时,也使用了一些独有而且比较重要的概念,「提案」、「准备(Prepare)请求」、「接受(Accept)请求」、「角色」等等,其中最重要的就是「角色」。因为角色是对 Basic Paxos 中最核心的三个功能的抽象,比如由接受者(Acceptor)对提议的值进行投票,并存储接受的值。
你需要了解的三种角色
在 Basic Paxos 中,有提议者(Proposer)、接受者(Acceptor)、学习者(Learner)三种角色,他们之间的关系如下:
- 提议者(Proposer):提议一个值,用于投票表决。为了方便演示,你可以把上图中的客户端 1、2 看作是提议者。但在绝大多数场景中,集群中收到客户端请求的节点,才是提议者(上图这个架构,是为了方便演示算法原理)。这样做的好处是,对业务代码没有入侵性,也就是说,我们不需要在业务代码中实现算法逻辑,就可以像使用数据库一样访问后端的数据。
- 接受者(Acceptor):对每个提议的值进行投票,并存储接受的值,比如 A、B、C 三个节点。 一般来说,集群中的所有节点都在扮演接受者的角色,参与共识协商,并接受和存储数据。
讲到这儿,你可能会有疑惑:前面不是说接收客户端请求的节点是提议者吗?这里怎么又是接受者呢?这是因为一个节点(或进程)可以身兼多个角色。想象一下,一个 3 节点的集群,1 个节点收到了请求,那么该节点将作为提议者发起二阶段提交,然后这个节点和另外 2 个节点一起作为接受者进行共识协商,就像下图的样子:
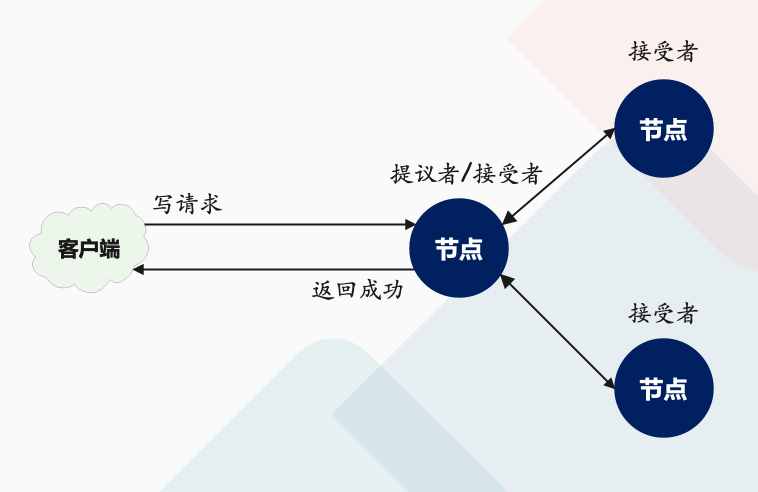
- 学习者(Learner):被告知投票的结果,接受达成共识的值,存储保存,不参与投票的过程。一般来说,学习者是数据备份节点,比如「Master-Slave」模型中的 Slave,被动地接受数据,容灾备份。
其实,这三种角色,在本质上代表的是三种功能:
提议者代表的是接入和协调功能,收到客户端请求后,发起二阶段提交,进行共识协商;接受者代表投票协商和存储数据,对提议的值进行投票,并接受达成共识的值,存储保存;学习者代表存储数据,不参与共识协商,只接受达成共识的值,存储保存。
因为一个完整的算法过程是由这三种角色对应的功能组成的,所以理解这三种角色,是你理解 Basic Paxos 如何就提议的值达成共识的基础。那么接下来,我们就来看看如何使用 Basic Paxos 达成共识,解决最开始提到的那个问题。
如何达成共识
想象这样一个场景,在疫情严重的时候,每个村的路都封得差不多了,就你的村委会不作为,迟迟没有什么防疫的措施。你决定给村委会提交个提案,提一些防疫的建议,除了建议之外,为了和其他村民的提案做区分,你的提案还得包含一个提案编号,来起到唯一标识的作用。
与你的做法类似,在 Basic Paxos 中,兰伯特也是使用提案的方式。不过在提案中,除了提案编号,还包含了提议值。为了方便演示,这里使用 [n, v] 表示一个提案,其中 n 为提案编号,v 为提议值。
而整个共识协商是分两个阶段进行的,类似于两阶段提交,那么具体要如何协商呢?我们假设客户端 1 的提案编号为 1,客户端 2 的提案编号为 5,并假设节点 A、B 先收到来自客户端 1 的准备请求,节点 C 先收到来自客户端 2 的准备请求。
准备(Prepare)阶段
先来看第一个阶段,首先客户端 1、2 作为提议者,分别向所有接受者发送包含提案编号的准备请求:
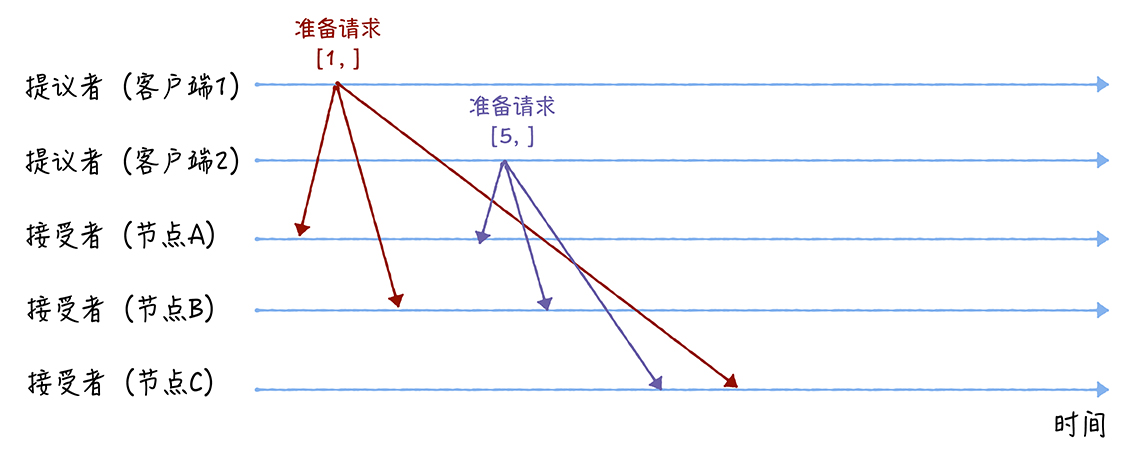
注意:在准备请求中是不需要指定提议的值的,只需要携带提案编号就可以了,这是很多人容易产生误解的地方。
接着,当节点 A、B 收到提案编号为 1 的准备请求,节点 C 收到提案编号为 5 的准备请求后,将进行这样的处理:
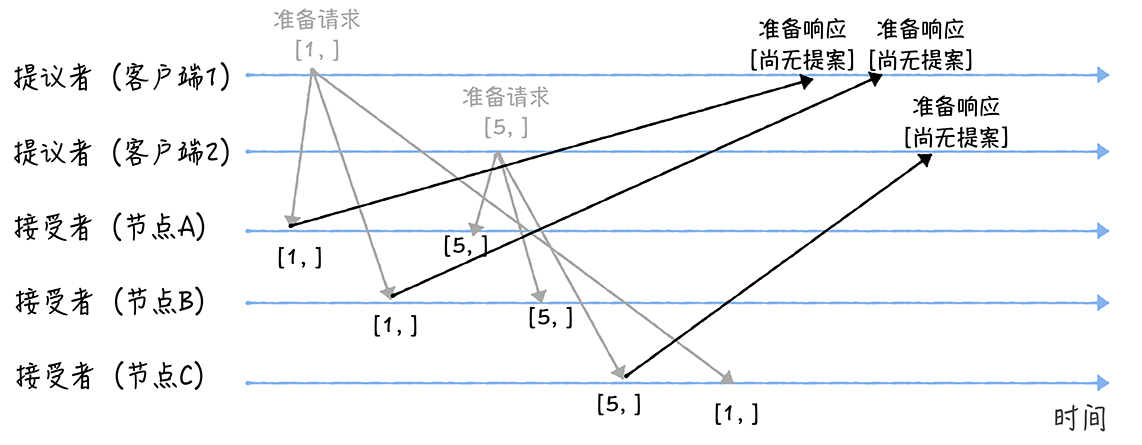
由于之前没有通过任何提案,所以节点 A、B 将返回一个「尚无提案」的响应。也就是说节点 A 和 B 在告诉提议者,我之前没有通过任何提案呢,并承诺以后不再响应提案编号小于等于 1 的准备请求,不会通过编号小于 1 的提案。节点 C 也是如此,它将返回一个「尚无提案」的响应,并承诺以后不再响应提案编号小于等于 5 的准备请求,不会通过编号小于 5 的提案。
另外,当节点 A、B 收到提案编号为 5 的准备请求,和节点 C 收到提案编号为 1 的准备请求的时候,将进行这样的处理过程:
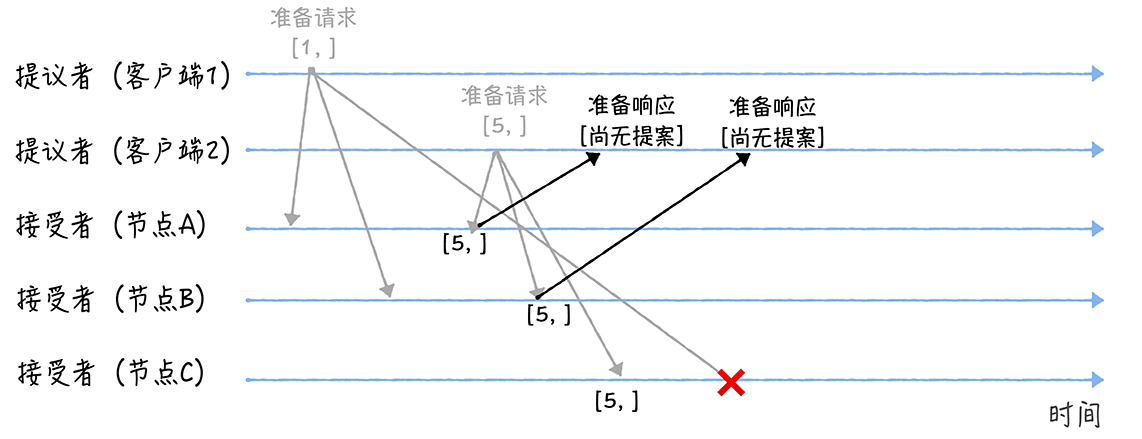
当节点 A、B 收到提案编号为 5 的准备请求的时候,因为提案编号 5 大于它们之前响应的准备请求的提案编号 1,而且两个节点都没有通过任何提案,所以它将返回一个「尚无提案」的响应,并承诺以后不再响应提案编号小于等于 5 的准备请求,不会通过编号小于 5 的提案。当节点 C 收到提案编号为 1 的准备请求的时候,由于提案编号 1 小于它之前响应的准备请求的提案编号 5,所以丢弃该准备请求,不做响应。
接受(Accept)阶段
第二个阶段也就是接受阶段,首先客户端 1、2 在收到大多数节点的准备响应之后,会分别发送接受请求:
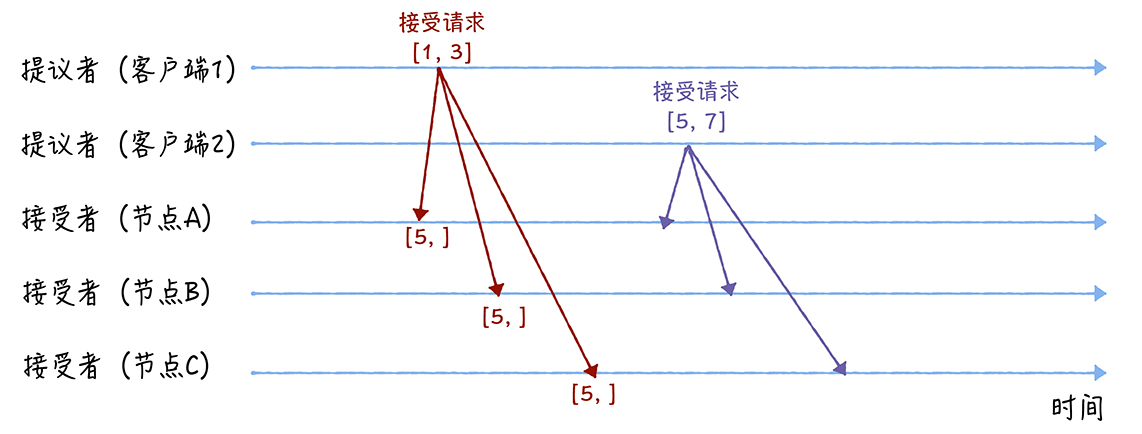
当客户端 1 收到大多数的接受者(节点 A、B)的准备响应后,根据响应中提案编号最大的提案的值,设置接受请求中的值。因为该值在来自节点 A、B 的准备响应中都为空(也就是「尚无提案」),所以就把自己的提议值 3 作为提案的值,发送接受请求[1, 3]。当客户端 2 收到大多数的接受者的准备响应后(节点 A、B 和节点 C),根据响应中提案编号最大的提案的值,来设置接受请求中的值。因为该值在来自节点 A、B、C 的准备响应中都为空,所以就把自己的提议值 7 作为提案的值,发送接受请求[5, 7]。
当三个节点收到两个客户端的接受请求时,会进行这样的处理:
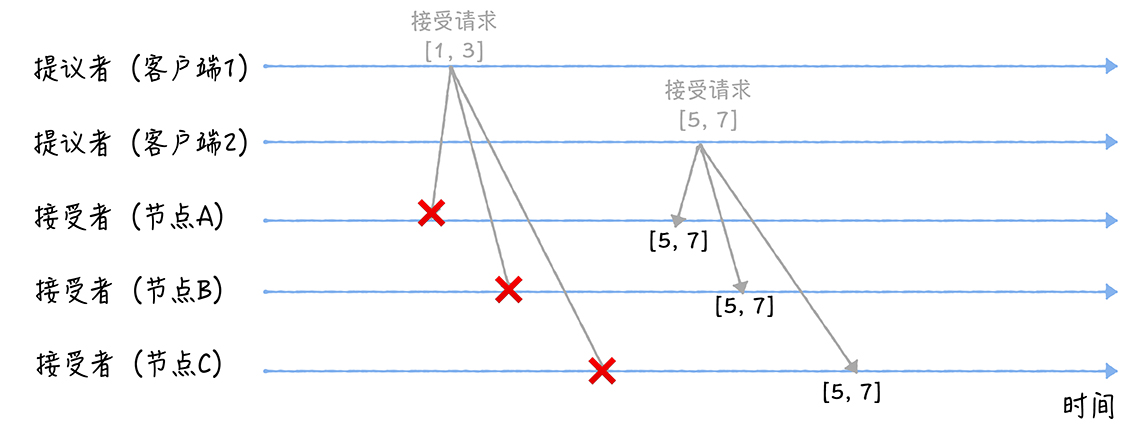
当节点 A、B、C 收到接受请求 [1, 3] 的时候,由于提案的提案编号 1 小于三个节点承诺能通过的提案的最小提案编号 5,所以提案 [1, 3] 将被拒绝。当节点 A、B、C 收到接受请求 [5, 7] 的时候,由于提案的提案编号 5 不小于三个节点承诺能通过的提案的最小提案编号 5,所以就通过提案 [5, 7],也就是接受了值 7,三个节点就 X 值为 7 达成了共识。
讲到这儿我想补充一下,如果集群中有学习者,当接受者通过了一个提案时,就通知给所有的学习者。当学习者发现大多数的接受者都通过了某个提案,那么它也通过该提案,接受该提案的值。通过上面的演示过程,我们可以看到,最终各节点就 X 的值达成了共识。那么在这里还需要强调一下,Basic Paxos 的容错能力,源自大多数的约定,你可以这么理解:当少于一半的节点出现故障的时候,共识协商仍然在正常工作。
总结
- 可以看到,Basic Paxos 是通过二阶段提交的方式来达成共识的。二阶段提交是达成共识的常用方式,如果你需要设计新的共识算法的时候,也可以考虑这个方式。
- 除了共识,Basic Paxos 还实现了容错,在少于一半的节点出现故障时,集群也能工作。它不像分布式事务算法那样,必须要所有节点都同意后才提交操作,因为「所有节点都同意」这个原则,在出现节点故障的时候会导致整个集群不可用。也就是说,「大多数节点都同意」的原则,赋予了 Basic Paxos 容错的能力,让它能够容忍少于一半的节点的故障。
- 本质上而言,提案编号的大小代表着优先级,你可以这么理解,根据提案编号的大小,接受者保证三个承诺:如果准备请求的提案编号,小于等于接受者已经响应的准备请求的提案编号,那么接受者将承诺不响应这个准备请求;如果接受请求中的提案的提案编号,小于接受者已经响应的准备请求的提案编号,那么接受者将承诺不通过这个提案;如果接受者之前有通过提案,那么接受者将承诺,会在准备请求的响应中,包含已经通过的最大编号的提案信息。
可以看到,Basic Paxos 是通过二阶段提交的方式来达成共识的。二阶段提交是达成共识的常用方式,如果你需要设计新的共识算法的时候,也可以考虑这个方式。
Multi-Paxos不是一个算法,而是统称
通过上面的学习,我们知道 Basic Paxos 只能就单个值(Value)达成共识,一旦遇到为一系列的值实现共识的时候,它就不管用了。虽然兰伯特提到可以通过多次执行 Basic Paxos 实例(比如每接收到一个值时,就执行一次 Basic Paxos 算法)实现一系列值的共识,但是很多人读完论文后,应该还是两眼摸黑,虽然每个英文单词都能读懂,但还是不理解兰伯特提到的 Multi-Paxos,为什么 Multi-Paxos 这么难理解呢?
原因就是兰伯特并没有把 Multi-Paxos 讲清楚,只是介绍了大概的思想,缺少算法过程的细节和编程所必须的细节(比如缺少选举领导者的细节),这也就导致每个人实现的 Multi-Paxos 都不一样。不过从本质上看,大家都是在兰伯特提到的 Multi-Paxos 思想上补充细节,设计自己的 Multi-Paxos 算法,然后实现它(比如 Chubby 的 Multi-Paxos 实现、Raft 算法、ZAB 协议等)。
所以需要在此补充一下:兰伯特提到的 Multi-Paxos 是一种思想,不是算法。而 Multi-Paxos 算法是一个统称,它是指基于 Multi-Paxos 思想,通过多个 Basic Paxos 实例实现一系列值的共识的算法(比如 Chubby 的 Multi-Paxos 实现、Raft 算法等)。这一点需要注意。
为了更好地理解 Multi-Paxos 思想,我们会先了解对于 Multi-Paxos,兰伯特是如何思考的,也就是说,如何解决 Basic Paxos 的痛点问题;然后我们再以 Chubby 的 Multi-Paxos 实现为例,具体讲解一下。为啥选它呢?因为 Chubby 的 Multi-Paxos 实现,代表了 Multi-Paxos 思想在生产环境中的真正落地,它将一种思想变成了代码实现。
兰伯特关于 Multi-Paxos 的思考
我们说 Basic Paxos 是通过二阶段提交来达成共识的。在第一阶段,也就是准备阶段,接收到大多数准备响应的提议者,才能发起接受请求进入第二阶段(也就是接受阶段)。
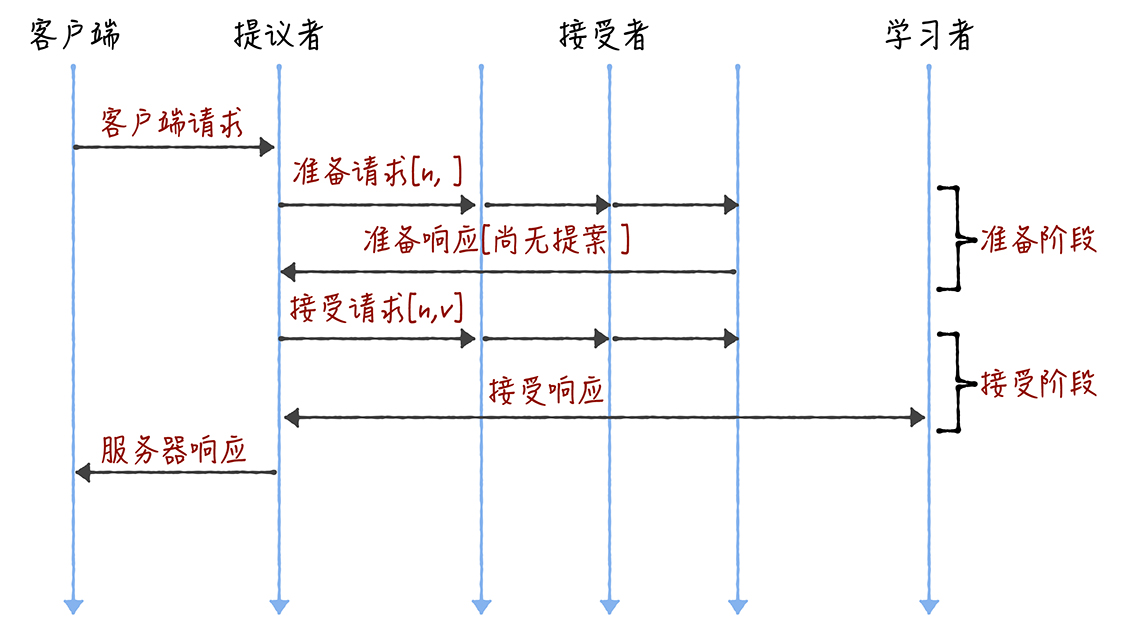
而如果我们直接通过多次执行 Basic Paxos 实例,来实现一系列值的共识,就会存在这样几个问题:
如果多个提议者同时提交提案,可能出现因为提案冲突,在准备阶段没有提议者接收到大多数准备响应,协商失败,需要重新协商。你想象一下,一个 5 节点的集群,如果 3 个节点作为提议者同时提案,就可能发生因为没有提议者接收大多数响应(比如 1 个提议者接收到 1 个准备响应,另外 2 个提议者分别接收到 2 个准备响应)而准备失败,需要重新协商。两轮 RPC 通讯(准备阶段和接受阶段)往返消息多、耗性能、延迟大。你要知道,分布式系统的运行是建立在 RPC 通讯的基础之上的,因此,延迟一直是分布式系统的痛点,是需要我们在开发分布式系统时认真考虑和优化的。
那么如何解决上面的 2 个问题呢?可以通过引入领导者和优化 Basic Paxos 执行来解决,咱们首先聊一聊领导者。
领导者(Leader)
我们可以通过引入领导者节点,也就是说,领导者节点作为唯一提议者,这样就不存在多个提议者同时提交提案的情况,也就不存在提案冲突的情况了:
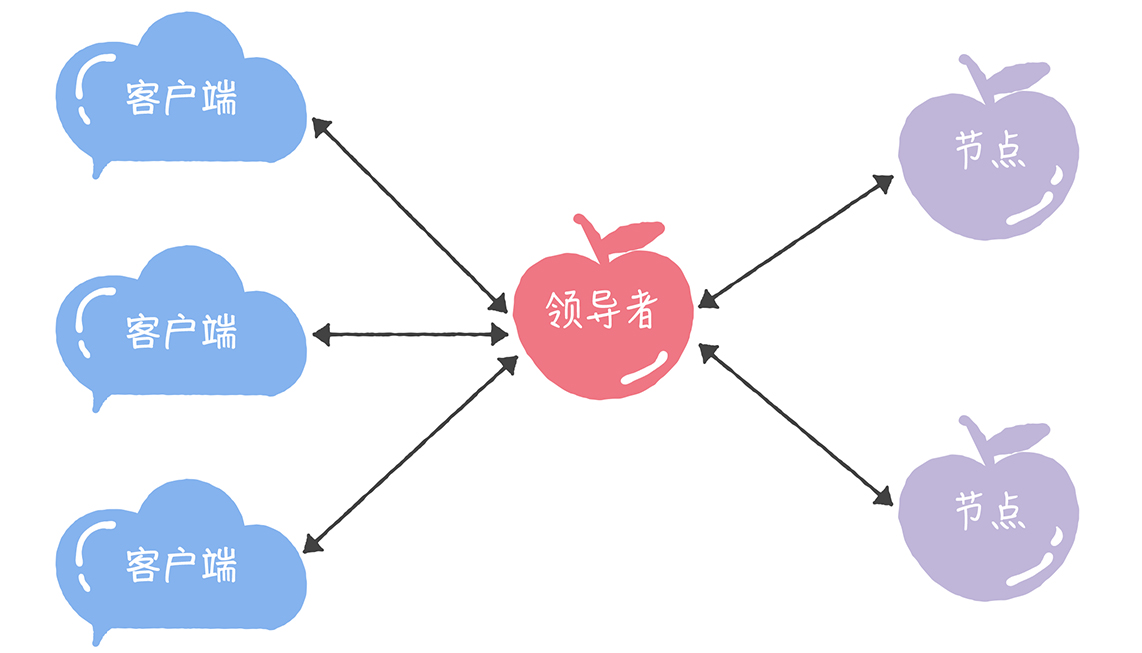
这里补充一点,在论文中,兰伯特没有说如何选举领导者,需要我们在实现 Multi-Paxos 算法的时候自己实现。 比如在 Chubby 中,主节点(也就是领导者节点)是通过执行 Basic Paxos 算法,进行投票选举产生的。
那么,如何解决第二个问题,也就是如何优化 Basic Paxos 执行呢?
优化 Basic Paxos 执行
我们可以采用「当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段」这个优化机制,优化 Basic Paxos 执行。也就是说,领导者节点上,序列中的命令是最新的,不再需要通过准备请求来发现之前被大多数节点通过的提案,领导者可以独立指定提案中的值。这时,领导者在提交命令时,可以省掉准备阶段,直接进入到接受阶段:
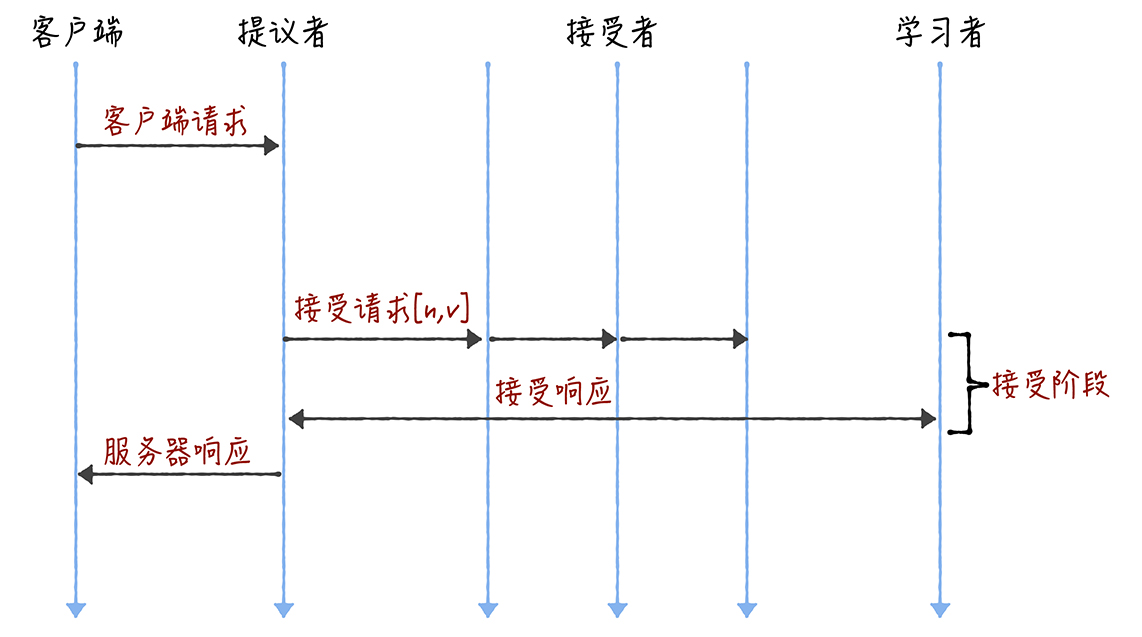
你看,和重复执行 Basic Paxos 相比,Multi-Paxos 引入领导者节点之后,因为只有领导者节点一个提议者,只有它说了算,所以就不存在提案冲突。另外,当主节点处于稳定状态时,就省掉准备阶段,直接进入接受阶段,所以在很大程度上减少了往返的消息数,提升了性能,降低了延迟。
讲到这儿,你可能会问:在实际系统中,该如何实现 Multi-Paxos 呢?接下来,我们以 Chubby 的 Multi-Paxos 实现为例,具体讲解一下。
Chubby 的 Multi-Paxos 实现
既然兰伯特只是大概的介绍了 Multi-Paxos 思想,那么 Chubby 是如何补充细节,实现 Multi-Paxos 算法的呢?
首先,它通过引入主节点,实现了兰伯特提到的领导者(Leader)节点的特性。也就是说,主节点作为唯一提议者,这样就不存在多个提议者同时提交提案的情况,也就不存在提案冲突的情况了。
另外,在 Chubby 中,主节点是通过执行 Basic Paxos 算法,进行投票选举产生的,并且在运行过程中,主节点会通过不断续租的方式来延长租期(Lease)。比如在实际场景中,几天内都是同一个节点作为主节点。如果主节点故障了,那么其他的节点又会投票选举出新的主节点,也就是说主节点是一直存在的,而且是唯一的。其次,在 Chubby 中实现了兰伯特提到的,「当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段」这个优化机制。
最后,在 Chubby 中,实现了成员变更(Group membership),以此保证节点变更的时候集群的平稳运行。
再补充一点:在 Chubby 中,为了实现了强一致性,读操作也只能在主节点上执行。 也就是说,只要数据写入成功,之后所有的客户端读到的数据都是一致的。具体的过程,就是下面的样子。
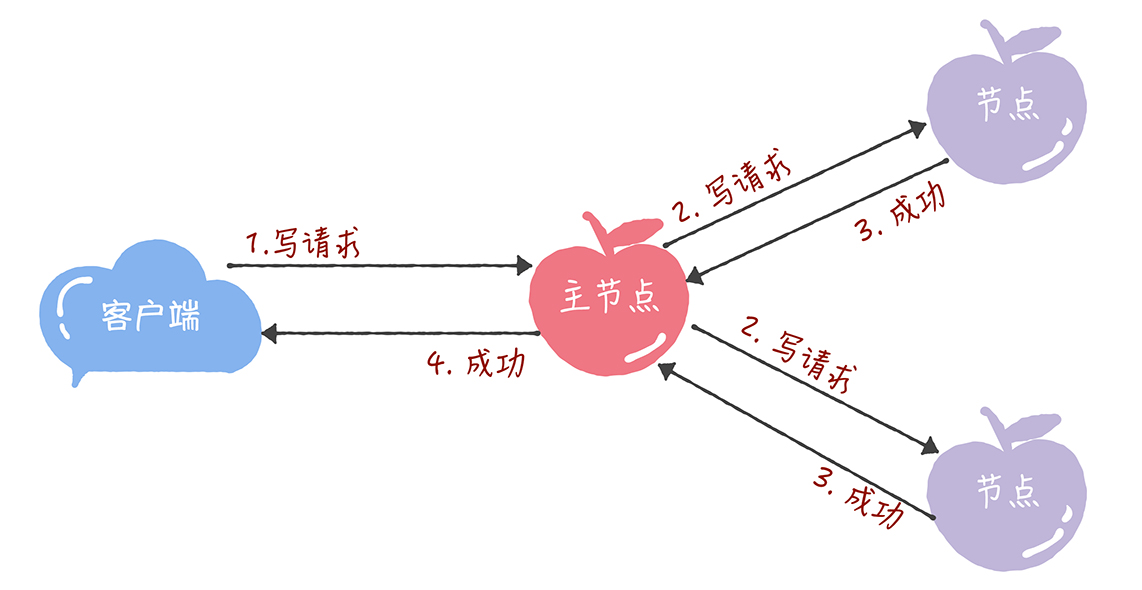
- 所有的读请求和写请求都由主节点来处理。当主节点从客户端接收到写请求后,作为提议者,执行 Basic Paxos 实例,将数据发送给所有的节点,并且在大多数的服务器接受了这个写请求之后,再响应给客户端成功:
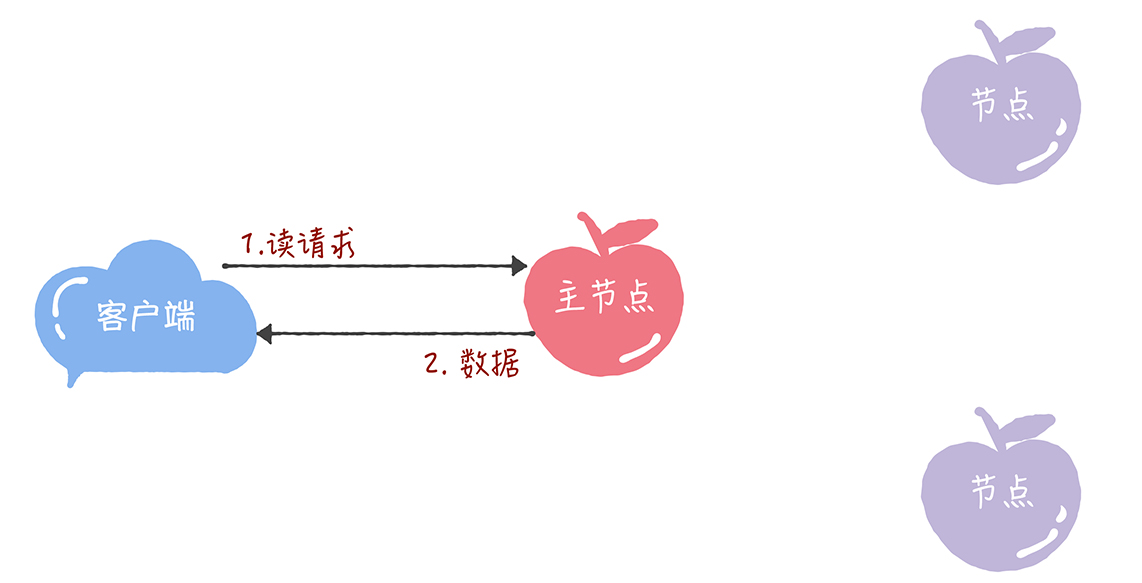
- 当主节点接收到读请求后,处理就比较简单了,主节点只需要查询本地数据,然后返回给客户端就可以了:
Chubby 的 Multi-Paxos 实现,尽管是一个闭源的实现,但这是 Multi-Paxos 思想在实际场景中的真正落地,Chubby 团队不仅编程实现了理论,还探索了如何补充细节。其中的思考和设计非常具有参考价值,不仅能帮助我们理解 Multi-Paxos 思想,还能帮助我们理解其他的 Multi-Paxos 算法(比如 Raft 算法)。
总结
- 兰伯特提到的 Multi-Paxos 是一种思想,不是算法,而且还缺少算法过程的细节和编程所必须的细节,比如如何选举领导者等,这也就导致了每个人实现的 Multi-Paxos 都不一样。而 Multi-Paxos 算法是一个统称,它是指基于 Multi-Paxos 思想,通过多个 Basic Paxos 实例实现一系列数据的共识的算法(比如 Chubby 的 Multi-Paxos 实现、Raft 算法等)。
- Chubby 实现了主节点(也就是兰伯特提到的领导者),也实现了兰伯特提到的「当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段」 这个优化机制,省掉 Basic Paxos 的准备阶段,提升了数据的提交效率,但是所有写请求都在主节点处理,限制了集群处理写请求的并发能力,约等于单机。
- 因为在 Chubby 的 Multi-Paxos 实现中,也约定了“大多数原则”,也就是说,只要大多数节点正常运行时,集群就能正常工作,所以 Chubby 能容错(n - 1)/ 2 个节点的故障。
- 本质上而言,「当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段」这个优化机制,是通过减少非必须的协商步骤来提升性能的。这种方法非常常用,也很有效。比如,Google 设计的 QUIC 协议,是通过减少 TCP、TLS 的协商步骤,优化 HTTPS 性能。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号