可视化神器plotly(2):子图的绘制
楔子
下面我们来进行高级图表的绘制,说是高级图表,其实也不算高级,主要是一些子图的绘制。以下代码在 jupyter notebook 上运行,先导入几个模块:
import datetime
import plotly.graph_objs as go
import numpy as np
import pandas as pd
时间序列
plotly 对时间的支持特别友好,即支持字符串格式、也支持日期格式,而且使用起来比较简单。
x0 = [datetime.date(2018, 1, 1),
datetime.date(2018, 2, 1),
datetime.date(2018, 3, 1),
datetime.date(2018, 4, 1),
datetime.date(2018, 5, 1)]
x1 = ["2018-1-1", "2018-2-1", "2018-3-1", "2018-4-1", "2018-5-1"]
trace0 = go.Scatter(x=x0, y=[1, 2, 3, 4, 5], name="trace_date")
trace1 = go.Scatter(x=x0, y=[2, 3, 4, 5, 6], name="trace_string")
fig = go.Figure(data=[trace0, trace1])
fig
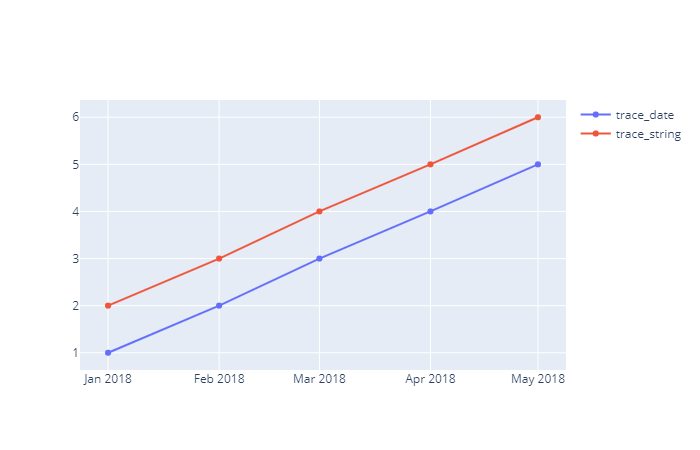
从代码中可以看出,只要是日期、或者符合时间格式的字符串,plotly 就会自动识别为日期格式。
表格
还记得我们之前创建甘特图吗?我们用到了 plotly.figure_factory,创建表格也是如此。
import plotly.figure_factory as ff
data= [
["姓名", "年龄", "性别"],
["古明地觉", 17, "女"],
["古明地恋", 16, "女"],
["椎名真白", 18, "女"],
["坂上智代", 19, "女"],
["雨宫优子", 16, "女"],
]
fig = ff.create_table(data)
fig
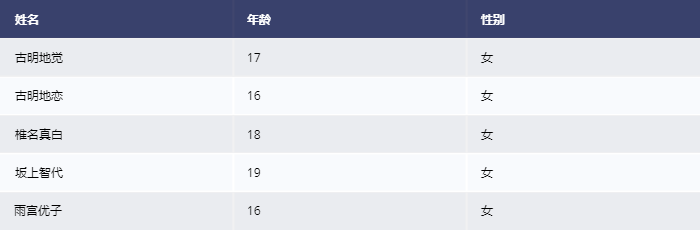
接收一个嵌套的二维列表,里面的第一个列表会被识别为表头,并且在里面还可以添加一些 html 属性。
import plotly.figure_factory as ff
data= [
["姓名", "年龄", "性别"],
['<a href="http://www.baidu.com">古明地觉</a>', 17, "女"],
["古明地恋", 16, "女"],
["椎名真白", 18, "女"],
["坂上智代", 19, "女"],
["雨宫优子", 16, "女"],
]
fig = ff.create_table(data)
fig
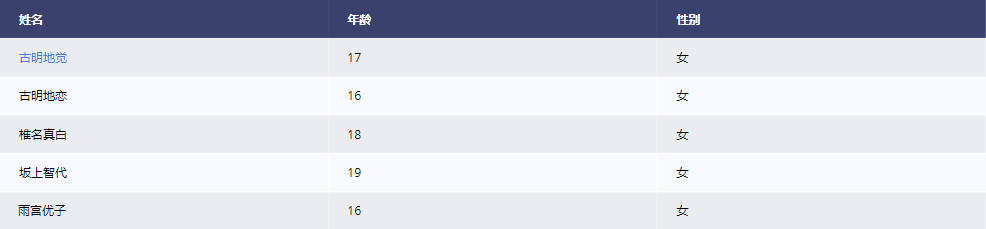
点击 古明地觉 即可跳转到百度页面,会在新标签页中打开百度页面。
使用 pandas
除了二维列表,我们还可以传递一个 DataFrame。
import plotly.figure_factory as ff
from sqlalchemy import create_engine
engine = create_engine("postgresql://postgres:zgghyys123@localhost:5432/postgres")
df = pd.read_sql("select * from t_case", engine)
# 直接将DataFrame传进去即可
fig = ff.create_table(df)
fig
如果是 DataFrame,那么列名就是这里的表头,但是我们看到索引貌似没了,那么如何将索引也显示在上面呢?
import plotly.figure_factory as ff
from sqlalchemy import create_engine
engine = create_engine("postgresql://postgres:zgghyys123@localhost:5432/postgres")
df = pd.read_sql("select * from t_case", engine)
# 直接将DataFrame传进去即可
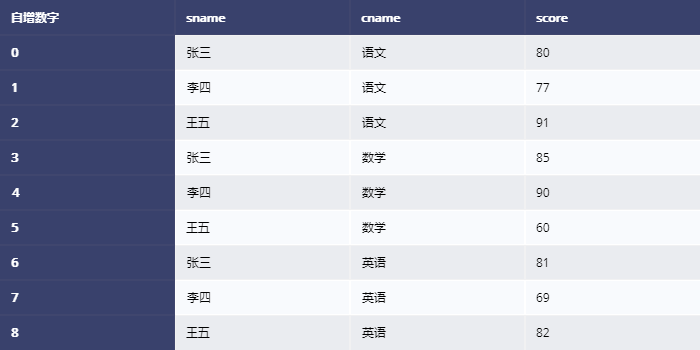
fig = ff.create_table(df, index=True, index_title="自增数字")
fig
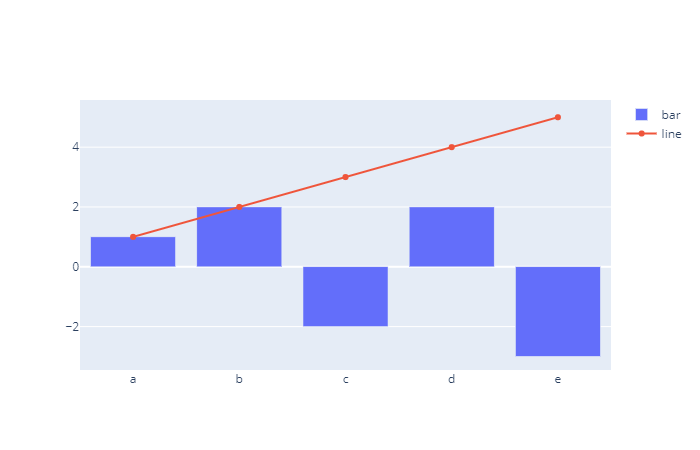
多图表
多图表其实在前面博客中已经说了,这里再简单提一嘴,就是画布上显示多条轨迹而已。
x = list("abcde")
y0 = [1, 2, -2, 2, -3]
y1 = [1, 2, 3, 4, 5]
trace0 = go.Bar(x=x, y=y0, name="bar")
trace1 = go.Scatter(x=x, y=y1, name="line")
fig = go.Figure(data=[trace0, trace1])
fig
多个坐标轴
多坐标轴是最复杂的地方,那为什么会有多个坐标轴呢。首先我们上面的多个图表是显示在相同坐标轴上面的,但是如果两个轨迹的数值相差比较大、还使用这种方法,那么 plotly 为了显示所有的轨迹,就会把坐标轴往大的方向调整,从而导致数值小的轨迹不明显。我们举个栗子看一下就很直观了:
x0 = np.linspace(1, 100, 5)
x1 = np.linspace(0, 1000, 5)
y0 = x0 ** 2 + x0 + 1
y1 = x1 ** 2 + x1 + 1
trace0 = go.Scatter(x=x0, y=y0)
trace1 = go.Scatter(x=x1, y=y1)
fig = go.Figure(data=[trace0, trace1])
fig
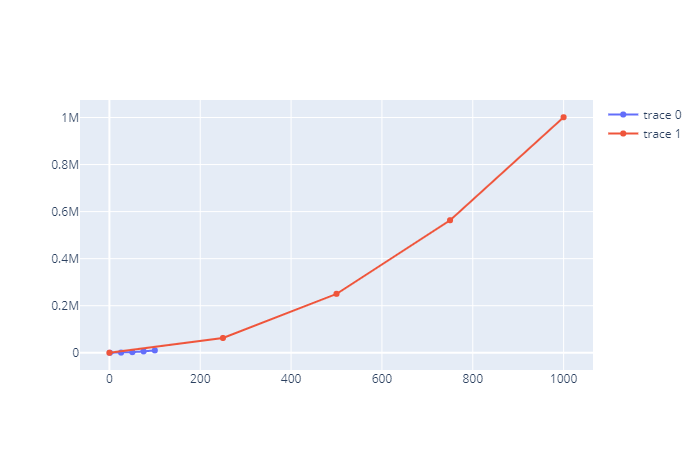
一条轨迹我们指定的数据是 0 到 1000,一条是 0 到 100。但是 plotly 为了展示所有的轨迹,坐标轴上刻度会按照轨迹的数值大的一方来显示,因此这就造成了数值小的轨迹的局部细节展示不出。所以在轨迹的数值相差比较大的时候,我们需要绘制第二个坐标轴。
绘制第二个坐标轴非常简单,只需要在 layout 中指定一个 xaxis2 和 yaxis2 即可,同理第三个坐标轴就是 xaxis3 和 xaxis3,以此类推。
x0 = np.linspace(1, 100, 5)
x1 = np.linspace(0, 1000, 5)
y0 = x0 ** 2 + x0 + 1
y1 = x1 ** 2 + x1 + 1
trace0 = go.Scatter(x=x0, y=y0)
# 我们虽然在 layout 中传入 xaxis2 和 yaxis2 创建了第二坐标轴,但是还要指明到底是哪个轨迹使用
# 因此要在轨迹上显式地通过 xaxis 和 yaxis 指明,到底是哪个轨迹使用哪个坐标轴
# 但是在指定的时候,第二坐标轴直接写 x2、y2 即可。默认的坐标轴是第一坐标轴、也就是最原始的那个坐标轴
trace1 = go.Scatter(x=x1, y=y1, yaxis="y2", xaxis="x2")
fig = go.Figure(data=[trace0, trace1],
layout={
# 由于在同一个画布上,所以网格会重叠,我们将其中的一个轴的网格给隐藏掉
# 以及zeroline,这些参数都是关于视觉上的,对于表达数据则无影响
# 具体如何影响图表的模样,可以自己去试一下
"xaxis": {"title": "trace0的x轴", "showgrid": False, "zeroline": False},
"yaxis": {"title": "trace0的y轴", "showgrid": False},
# 这里就是第二坐标轴的x轴了
"xaxis2": {"title": "trace1的x轴",
"side": "top", # 这个很重要,要设置方向,显然设置为上方
# 必须要写,否则图像无法显示,同理下面的yaxis也是类似
"overlaying": "x"},
"yaxis2": {"title": "trace1的y轴",
# 第二y轴要设置在右边
"side": "right",
"overlaying": "y"}
}
)
fig
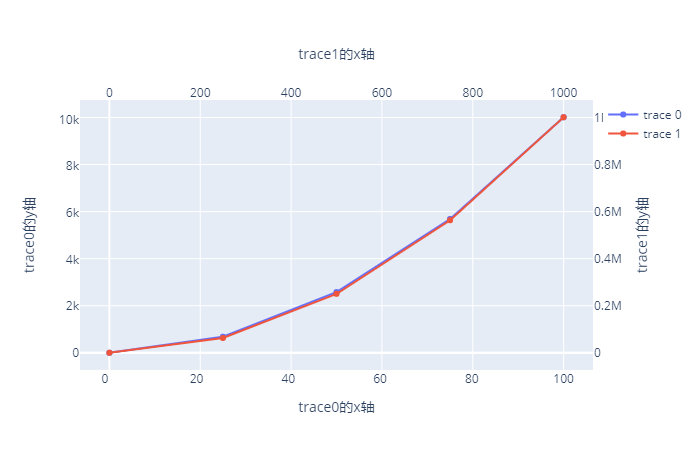
此时就绘制出来了,因为现在两个轨迹的坐标不是同一个坐标了。但是它们之间的规律是一样的,再加上又显示在同一个画布上,所以轨迹是差不多重合的。
绘制子图(方式一)
说实话,共享坐标轴的方式展示多图表还不是很常见,常见的是一个画布分为多个区域,每个区域展示各自的图表。就可以想象成之前的一张画布显示一个轨迹,然后把多个画布放在一起显示。这样,它们各自的坐标轴、标题等属性都是独立的。
# 创建子图使用make_subplots
from plotly.subplots import make_subplots
trace0 = go.Scatter(x=[1, 2, 3, 4, 5], y=[1, 2, 3, 4, 5])
trace1 = go.Scatter(x=[2, 3, 4, 5, 6], y=[2, 3, 4, 5, 6])
trace2 = go.Scatter(x=[1, 2, 3, 4, 5], y=[1, 2, 3, 4, 5])
trace3 = go.Scatter(x=[2, 3, 4, 5, 6], y=[2, 3, 4, 5, 6])
fig = make_subplots(rows=2, # 将画布分为两行
cols=2, # 将画布分为两列
subplot_titles=["trace0的标题",
"trace1的标题",
"trace3的标题",
"trace4的标题"], # 子图的标题
x_title="x轴标题",
y_title="y轴标题"
)
# 添加轨迹
fig.append_trace(trace0, 1, 1) # 将trace0添加到第一行第一列的位置
fig.append_trace(trace1, 1, 2) # 将trace1添加到第一行第二列的位置
fig.append_trace(trace2, 2, 1) # 将trace2添加到第二行第一列的位置
fig.append_trace(trace3, 2, 2) # 将trace3添加到第二行第二列的位置
fig
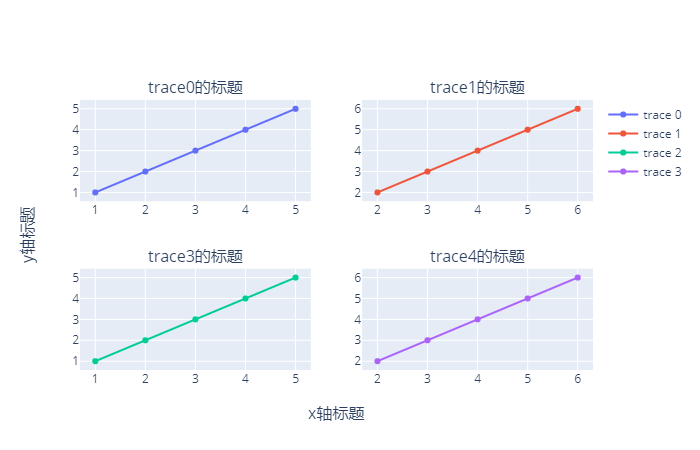
此时我们就成功绘制出来了子图,但是有一点不完美的地方是,它的这个坐标轴的标题是针对整体的。我可不可以对不同的坐标轴施加不同的描述呢?显然是可以的。
但是我们这里需要再补充一下,我们之前创建画布的时候是通过 go.Figure,然后将画布参数通过字典的方式先写好,然后传给 layout。但是事实上我们也可以后续在进行添加的,比如 fig["layout"]["xaxis"].update({"title": "x坐标轴"}),这样做也是可以的。fig["data"] 拿到的就是所有的轨迹,我们也可以往里面加入新的轨迹,fig["layout"] 则是拿到的画布的属性,一个字典,我们同样可以往里面添加、删除属性。
之所以说这些,就是因为 make_subplots 里面没办法直接传递 layout,只能通过创建出来的画布、手动获取里面的 layout、然后添加。
from plotly.subplots import make_subplots
trace0 = go.Scatter(x=[1, 2, 3, 4, 5], y=[1, 2, 3, 4, 5])
trace1 = go.Scatter(x=[2, 3, 4, 5, 6], y=[2, 3, 4, 5, 6])
trace2 = go.Scatter(x=[1, 2, 3, 4, 5], y=[1, 2, 3, 4, 5])
trace3 = go.Scatter(x=[2, 3, 4, 5, 6], y=[2, 3, 4, 5, 6])
fig = make_subplots(rows=2,
cols=2,
subplot_titles=["trace0的标题",
"trace1的标题",
"trace2的标题",
"trace3的标题"],
)
fig.append_trace(trace0, 1, 1)
fig.append_trace(trace1, 1, 2)
fig.append_trace(trace2, 2, 1)
fig.append_trace(trace3, 2, 2)
# 创建了四个子图,自动就会有四个坐标轴。
# 每个轨迹占一个,因此这种情况我们是不需要在轨迹里面通过xaxis和yaxis来指定到底使用哪一个坐标轴的,因为已经分配好了
fig["layout"]["xaxis"].update({"title": "trace0的x轴", "titlefont": {"color": "red"}})
fig["layout"]["yaxis"].update({"title": "trace0的y轴", "titlefont": {"color": "red"}})
fig["layout"]["xaxis2"].update({"title": "trace1的x轴", "titlefont": {"color": "green"}})
fig["layout"]["yaxis2"].update({"title": "trace1的y轴", "titlefont": {"color": "green"}})
fig["layout"]["xaxis3"].update({"title": "trace2的x轴", "titlefont": {"color": "pink"}})
fig["layout"]["yaxis3"].update({"title": "trace2的y轴", "titlefont": {"color": "pink"}})
fig["layout"]["xaxis4"].update({"title": "trace3的x轴", "titlefont": {"color": "yellow"}})
fig["layout"]["yaxis4"].update({"title": "trace3的y轴", "titlefont": {"color": "yellow"}})
fig["layout"]["template"] = "plotly_dark"
fig

绘制子图(方式二)
我们下面这种绘制子图的方式有点类似于共享坐标轴的方式,主要在于内部的一个 domain 参数。
trace0 = go.Scatter(x=[1, 2, 3, 4, 5], y=[1, 2, 3, 4, 5])
trace1 = go.Scatter(x=[2, 3, 4, 5, 6], y=[2, 3, 4, 5, 6], xaxis="x2", yaxis="y2")
fig = go.Figure(data=[trace0, trace1],
layout={"xaxis": {"domain": [0, 0.6]}, # 指定第一幅图的范围是0到百分之60
"xaxis2": {"domain": [0.7, 1]}, # 第二幅图的范围是百分之70到百分之百
# 这个参数可能有些费解,它是指定y轴位置的,如果是通过"side": "right"的话,那么这个轴会在第一幅图的右边
# 通过"anchor": "x2",那么y轴就是像现在这样出现在第二幅图的左边。
"yaxis2": {"anchor": "x2"}
}
)
fig

这种绘制子图的方式可能不是容易让人理解,主要就在于里面的 domain 参数。我们之前通过这种方式可以认为是两张子图(都占据全部位置)重合了,现在通过 domain 将两幅子图分开了。因此相比 make_subplots,这种绘制子图的方式有点让人费解,而且我们还要计算好位置。
但是这种绘制子图的方式的好处就在于我们可以自定义子图的位置,我们使用 make_subplots 的时候,多个子图大小的是一样的,并且间隔什么的是等分的,但是 domain 这种方式就不同了。
trace0 = go.Scatter(x=[1, 2, 3, 4, 5], y=[1, 2, 3, 4, 5])
trace1 = go.Scatter(x=[2, 3, 4, 5, 6], y=[2, 3, 4, 5, 6], xaxis="x2", yaxis="y2")
fig = go.Figure(data=[trace0, trace1],
layout={# xaxis不指定,则默认是占据全部
# 我们只指定xaxis2和yaxis2
# 我们之前好像在xaxis里面没有指定anchor,那是因为当时x轴就是在底部,或者说y轴占据了整个垂直方向
# 但是现在不一样了,我们还要指定y轴的范围
"xaxis2": {"domain": [0.6, 0.95], "anchor": "y2"},
"yaxis2": {"domain": [0.1, 0.4], "anchor": "x2"}
}
)
fig
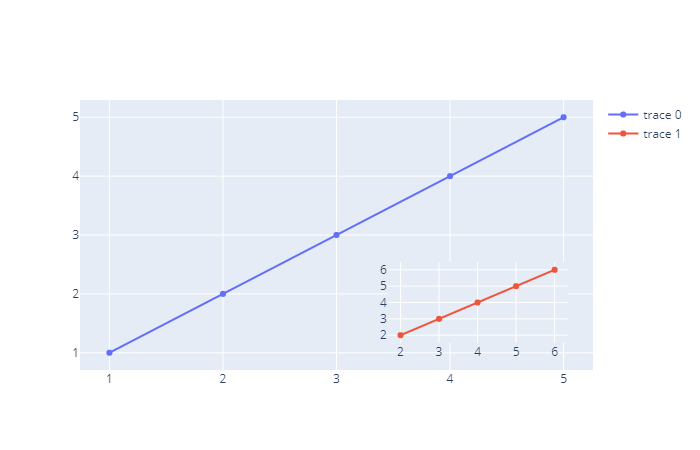
我们看到一张图出现在了另一张图的里面,这是因为第一坐标轴、也就是默认的轴它的范围是百分之百的,而我们指定了第二坐标轴的 x 方向和 y 方向只占据了一部分,那么使用该坐标的轴的轨迹就会显示在局部,而不是像之前一样占满全部范围。而绘制出类似于 make_subplots 的方式,则是让每个轴 domain 不重合即可,然后计算好位置。所以这种方式应该说更强大,只不过对于绘制标准的、一个子图占一个坑、规规整整的排列的多个子图的话,还是推荐使用 make_subplots。而 domain 这种方式这是让我们自定义的。
而最后再说说那个轴里面的 anchor,这个老铁主要是空值坐标轴的刻度显示在什么地方的。我们之前在绘制多个坐标轴的时候,直接使用的 side,那是因为坐标轴所在的两幅图的大小是一样的,但是现在不一样了。所以我们需要指定第 n 坐标轴的 x 轴的 "anchor" 为 yn、第 n 坐标轴的 y 轴的 "anchor" 为 xn。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号