《数据库基础语法》13. 数据的多维度交叉统计
我们之前学习了基础的数据分组汇总操作,现在,让我们讨论一些更高级的分组统计分析功能,也就是 GROUP BY 子句的扩展选项。
销售示例数据:
本节我们使用新的数据集,表名叫做sales_data,它包含了 2019 年 1 月 1 日到 2019 年 6 月 30 日三种产品在三个渠道的销售情况。以下是该表中的部分数据:
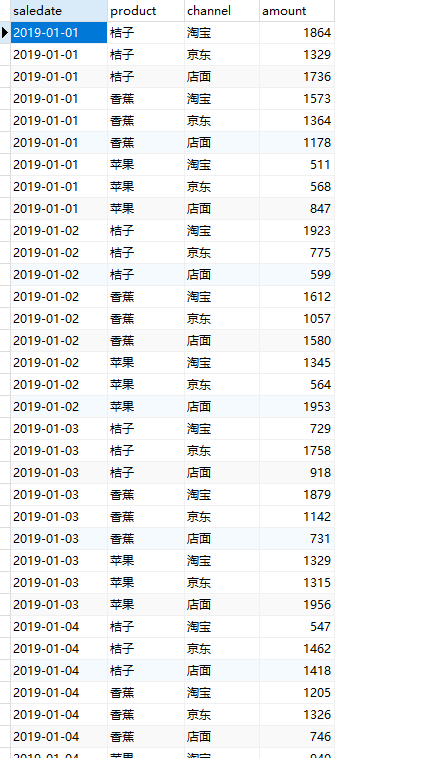
saledate 表示销售日期,product 表示产品,channel 表示平台,amount 表示销售金额。
现在就让我们来看看 GROUP BY 支持哪些高级分组选项。
层次化的统计:
这个就比较简单了,就是我们之前使用的 GROUP BY。
SELECT product,
channel,
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY product, channel;

这是一个简单的分组汇总操作,我们得到了每种产品在每个渠道的销售金额。现在我们来思考一个问题:如何知道每种产品在所有渠道的销售金额合计,以及全部产品的销售金额总计呢?有人肯定觉得,直接按照 product 进行分组、sum 一下不就行了,但这需要单独写一个SQL。如果我们需要连同上面的内容一起输出,这个时候就需要 ROLLUP 函数了。
在 SQL 中可以使用 GROUP BY 子句的扩展选项:ROLLUP。ROLLUP 可以生成按照层级进行汇总的结果,类似于财务报表中的小计、合计和总计。
-- PostgreSQL 支持
SELECT product,
channel,
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup(product, channel);
-- 我们不再 GROUP BY product, channel,而是GROUP BY rollup(product, channel)
-- 注意:如果是 MySQL,那么要这样写,GROUP BY product, channel with rollup

我们注意到,多了四条数据,上面三条,就是按照 product、channel 汇总之后,再单独按 product 汇总,因此,此时就给对应的 channel 赋值为 null 了。同理最后一条数据是全量汇总,不需要指定 product 和 channel,所以显示为 product 和 channel 都显示为 null。我们看到这就相当于按照 product 单独聚合然后再自动拼接在上面了,排好序,并且自动将 channel 赋值为 null,同理最后一条数据也是如此。当然我们也可以写多个语句,然后通过 union 也能实现上面的效果,有兴趣可以自己试一下。但是数据库提供了 rollup 这个非常方便的功能,我们就要利用好它。
所以该查询的结果中多出了 4 条记录,分别表示三种产品在所有渠道的销售金额合计(渠道显示为 NULL)以及全部产品的销售金额总计(产品和渠道都显示为 NULL)。
GROUP BY 子句加上 ROLLUP 选项时,首先按照分组字段进行分组汇总;然后从右至左依次去掉一个分组字段再进行分组汇总,被去掉的字段显示为空;最后,将所有的数据进行一次汇总,所有的分组字段都显示为空。
在上面的示例中,显示为空的字段作用不太明显。我们可以利用空值函数 COALESCE 将结果显示为更易理解的形式:
SELECT coalesce(product, '所有产品'),
coalesce(channel, '所有渠道'),
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup(product, channel);

除了 ROLLUP 之外,GROUP BY 还支持 CUBE 选项。
多维度的交叉统计:
CUBE 代表立方体,它用于对分组字段进行各种可能的组合,能够产生多维度的交叉统计结果。CUBE 通常用于数据仓库中的交叉报表分析。
示例数据集 sales_data 中包含了产品、日期和渠道 3 个维度,对应的数据立方体结构如下图所示:
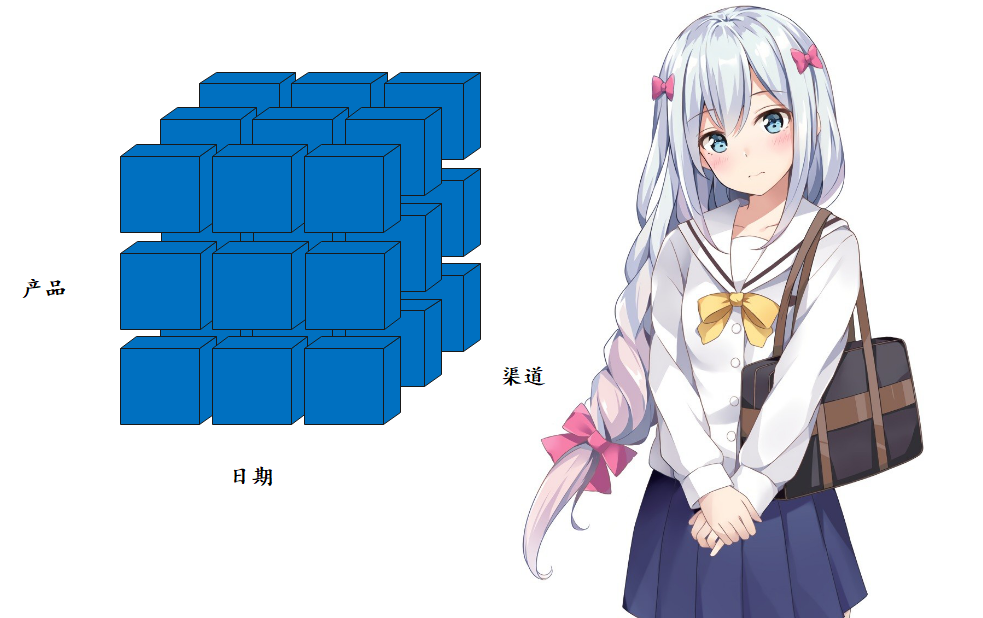
其中,每个个小的方块表示一个产品在特定日期、特定渠道下的销售金额。以下语句利用 CUBE 选项获得每种产品在每个渠道的销售金额小计,每种产品在所有渠道的销售金额合计,每个渠道全部产品的销售金额合计,以及全部产品在所有渠道的销售金额总计:
-- PostgreSQL 支持
SELECT coalesce(product, '所有产品'),
coalesce(channel, '所有渠道'),
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY cube(product, channel);
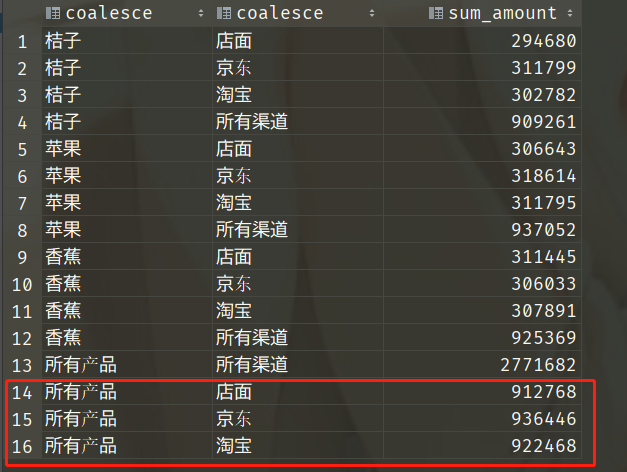
从以上结果可以看出,CUBE 返回了更多的分组数据,其中不仅也包含了 ROLLUP 汇总的结果,还包含了相当于按照 channel 进行聚合的记录。因此随着分组字段的增加,CUBE 产生的组合将会呈指数级增长。
MySQL 目前还不支持 CUBE 选项。
ROLLUP 和 CUBE 都是按照预定义好的组合方式进行分组;GROUP BY 还支持一种更灵活的统计方式:GROUPING SETS。
自定义分组粒度:
GROUPING SETS 选项可以用于指定自定义的分组集,也就是分组字段的组合方式。实际上,ROLLUP 和 CUBE 都属于特定的分组集。比如:
GROUP BY product, channel;
-- 等价于
GROUP BY GROUPING SETS ((product, channel));
(product, channel) 定义了一个分组集,也就是按照产品和渠道的组合进行分组。注意,括号内的所有字段作为一个分组集,外面再加上一个括号包含所有的分组集。
GROUP BY ROLLUP (product, channel);
-- 相当于
GROUP BY GROUPING SETS ((product, channel),
(product),
()
);
首先,按照产品和渠道的组合进行分组;然后按照不同的产品进行分组;最后的括号( () )表示将所有的数据作为整体进行统计。上文中的 CUBE 选项示例:
GROUP BY CUBE (product, channel);
-- 相当于
GROUP BY GROUPING SETS ((product, channel),
(product),
(channel),
()
);
首先,按照产品和渠道的组合进行分组;然后按照不同的产品进行分组;接着按照不同的渠道进行分组;最后将所有的数据作为一个整体。
GROUPING SETS 选项的优势在于可以指定任意的分组方式。以下示例返回不同产品的销售金额合计以及不同渠道的销售金额合计:
-- 分别按照product和channel汇总
SELECT product,
channel,
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY grouping sets ((product), (channel));
/*
桔子 null 909261
苹果 null 937052
香蕉 null 925369
null 店面 912768
null 京东 936446
null 淘宝 922468
*/
-- 我们使用union也是可以实现的
select product, null as channel, sum(amount) as sum_amount
from sales_data group by product
union
select null as product, channel, sum(amount) as sum_amount
from sales_data group by channel
order by product, channel nulls last
/*
桔子 null 909261
苹果 null 937052
香蕉 null 925369
null 店面 912768
null 京东 936446
null 淘宝 922468
*/
可以看到我们把(product) 和 (channel) 分别指定了一个分组集。通过 GROUPING SETS 选项可以实现任意粒度(维度)的组合分析。
MySQL 目前还不支持 GROUPING SETS 选项。
GROUPING 函数:
在进行分组统计时,如果源数据中存在 NULL 值,查询的结果会产生一些歧义。我们先插入一条模拟数据,它的渠道为空:
-- 只有 Oracle 需要执行以下 alter 语句
-- alter session set nls_date_format = 'YYYY-MM-DD';
INSERT INTO sales_data VALUES ('2019-01-01','桔子', NULL, 1000.00);
再次运行之前的 ROLLUP 示例
SELECT product,
channel,
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup (product, channel);

我们说尽管 null 值无法判断是否相等,但是在分组的时候所有为 null 都会分到同一组,不过我们这里只插入了一条 channel 为空的记录,无所谓啦。注意看此时的数据:黄色框框的部分出现了两个 channel 为 null 的,显然从数据我们能看出来,sum_amount 为 1000 的,是我们在聚合的时候产生的,它并不是 "桔子" 在所有渠道的销售金额合计,第五行才是 "桔子" 在所有渠道的销售金额合计(910261)。问题的原因在于 GROUP BY 将空值作为了一个分组,于是有两个null,可能有人觉得使用COALESCE 函数转化一下不就行了,是这样吗?我们来试一下。
SELECT coalesce(product, '所有产品'),
coalesce(channel, '所有渠道'),
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup (product, channel);
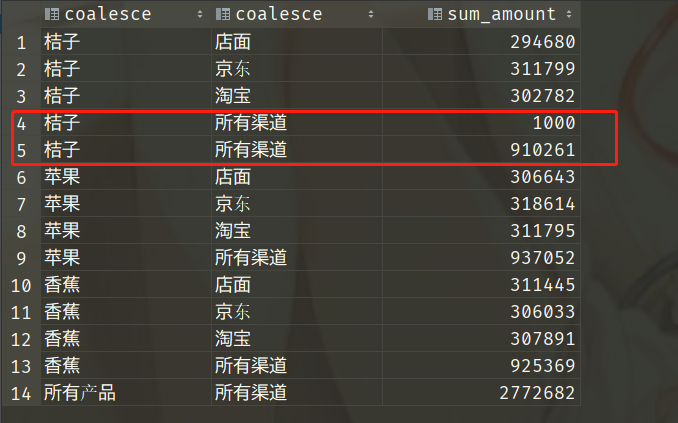
一样的结果,汇总之后 channel 是为 null 的,但是我们的 select 后面是 coalesce(channel, '所有渠道'),所以结果也就变成了 '所有渠道',因为我们的(COALESCE 函数)无法区分是由汇总产生的 NULL 值还是源数据中存在的 NULL 值。
为了解决这个问题,SQL 提供了一个函数:GROUPING。以下语句演示了 GROUPING 函数的作用:
SELECT product,
grouping(product), -- 多加了一个grouping(product)
channel,
grouping(channel), -- 多加了一个grouping(channel)
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup (product, channel);

其中,GROUPING 函数返回 0 或者 1。如果当前数据是某个字段上的汇总数据,该函数返回 1;否则返回 0。例如,第 4 行数据虽然渠道显示为 NULL,但不是所有渠道的汇总,所以 GROUPING(channel) 的结果为 0;第 5 行数据的渠道同样显示为 NULL,它是 "桔子" 在所有渠道的销售金额汇总,所以 GROUPING(channel) 的结果为 1。
因此,我们可以利用 GROUPING 函数显示明确的信息:
SELECT case grouping(product) when 1 then '所有商品' else product end as product,
case grouping(channel) when 1 then '所有渠道' else channel end as channel,
SUM(amount) AS sum_amount
FROM sales_data
GROUP BY rollup (product, channel);
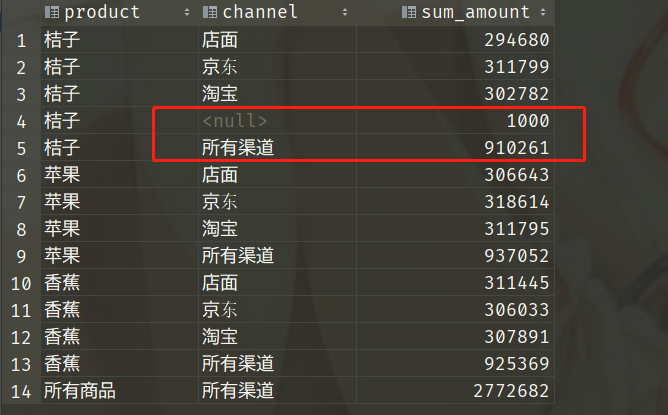
如此一来就变成我们想要的结果了,通过查询的结果可以清楚地区分出空值和汇总数据。
当然,如果源数据中不存在 NULL 值或者进行了预处理,也可以直接使用 COALESCE 函数进行显示。
小结
在 Excel 中有一个分析功能叫做数据透视表,利用 GROUP BY 的 ROLLUP、CUBE 以及 GROUPING SETS 选项可以非常容易地实现类似的效果,并且使用更加灵活。这些都是在线分析处理系统(OLAP)中的常用技术,能够提供多维度的层次统计和交叉分析功能。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号