sync.Pool:通过缓存对象的方式,大幅提升性能
楔子
Go 是一个自带垃圾回收的编程语言,采用三色标记算法标记对象并回收,和其它没有自动垃圾回收的编程语言不同,使用 Go 语言创建对象的时候,我们没有回收 / 释放的心理负担,想用就用,想创建就创建。
但如果你想使用 Go 开发一个高性能的应用程序的话,就必须考虑垃圾回收给性能带来的影响,毕竟 Go 的自动垃圾回收机制还是有一个 STW(stop-the-world,程序暂停)的时间,而且大量地创建在堆上的对象,也会影响垃圾回收标记的时间。所以,一般我们做性能优化的时候,会采用对象池的方式,把不用的对象回收起来,避免被垃圾回收掉,这样使用的时候就不必在堆上重新创建了。
不止如此,像数据库连接、TCP 的长连接,这些连接在创建的时候是一个非常耗时的操作。如果每次都创建一个新的连接对象,耗时较长,很可能整个业务的大部分耗时都花在了创建连接上。所以,如果我们能把这些连接保存下来,避免每次使用的时候都重新创建,不仅可以大大减少业务的耗时,还能提高应用程序的整体性能。
Go 标准库中提供了一个通用的 Pool 数据结构,也就是 sync.Pool,我们使用它可以创建池化的对象。下面我们就来了解一下 sync.Pool 的使用方法、实现原理以及常见的坑,全方位地掌握标准库 Pool。
sync.Pool 的特点
sync.Pool 数据类型用来保存一组可独立访问的临时对象,注意这里的临时二字,它说明了 sync.Pool 这个数据类型的特点,也就是说它池化的对象会在未来的某个时候被毫无预兆地移除掉。而且如果没有别的对象引用这个被移除的对象的话,这个被移除的对象就会被垃圾回收掉。所以 sync.Pool 对于数据库长连接等场景是不合适的,但是我们有其它的 Pool,专门用于保存连接。
因为 Pool 可以有效地减少新对象的申请,从而提高程序性能,所以 Go 内部库也用到了sync.Pool,比如 fmt 包,它会使用一个动态大小的 buffer 池做输出缓存,当大量的 goroutine 并发输出的时候,就会创建比较多的 buffer,并且在不需要的时候回收掉。
但是有两个知识点我们需要记住:
sync.Pool 本身就是线程安全的,多个 goroutine 可以并发地调用它的方法存取对象;sync.Pool 不可在使用之后再复制使用;
sync.Pool 的使用方法
知道了 sync.Pool 这个数据类型的特点,接下来我们来学习下它的使用方法。这个数据类型并不难,它只提供了三个对外的方法:New、Get 和 Put。
New
Pool struct 包含一个 New 字段,这个字段的类型是函数 func() interface{},当调用 Pool 的 Get 方法从池中获取元素,但没有空闲元素可返回时,就会调用这个 New 方法来创建新的元素。但如果你没有设置 New 字段,并且还没有空闲元素可返回时,Get 方法将返回 nil,表明当前没有可用的元素。
有趣的是,New 是可变的字段,这就意味着我们可以在程序运行的时候改变创建元素的方法。当然很少有人会这么做,因为一般我们创建元素的逻辑都是一致的,要创建的也是同一类的元素,所以在使用 Pool 的时候也没必要玩一些骚操作,在程序运行时更改 New 的值。
Get
如果调用这个方法,就会从 Pool 中取走一个元素,这也就意味着这个元素会从 Pool 中移除,返回给调用者。不过除了返回值是正常实例化的元素,Get 方法的返回值还可能是一个 nil(Pool.New 字段没有设置,又没有空闲元素可以返回),所以你在使用的时候,需要判断一下。
Put
这个方法用于将一个元素返还给 Pool,Pool 会把这个元素保存到池中,并且可以复用。但如果 Put 一个 nil 值,Pool 就会忽略这个值。
那么下面我们就来实际模拟一下:
package main
import (
"fmt"
"sync"
)
func main() {
var pool sync.Pool
// 调用 Put 方法可以将数据放入对象池中, 该函数接收一个 interface{}
// 说明我们可以放入任意类型的数据
pool.Put(123)
pool.Put("你好呀")
pool.Put([]int{1, 2, 3})
// 取出数据可以调用 Get 方法, 得到的也是一个 interface{},并且是先进后出
// 但是注意: 第一个取出的元素永远是最先放进去的, 除去第一个元素之外的所有元素先进后出
fmt.Println(pool.Get()) // 123
fmt.Println(pool.Get()) // [1 2 3]
fmt.Println(pool.Get()) // 你好呀
// 当池子空了之后, 再获取值的话得到的就是一个nil
fmt.Println(pool.Get()) // <nil>
fmt.Println(pool.Get()) // <nil>
fmt.Println(pool.Get()) // <nil>
}
以上便是 "临时对象池" 的简单用法,另外既然叫 "临时对象池",那么里面不建议放入过多的对象;此外我们看到当池子中的数据没有了之后,再使用 Get 获取到的就是 nil;但是我们可以使用 New 函数来改变这一结果,举个栗子:
package main
import (
"fmt"
"sync"
)
func main() {
var pool sync.Pool
// 接收一个函数, 返回值是interface{}
pool.New = func() interface{} {
return "result"
}
pool.Put(123)
pool.Put("你好呀")
pool.Put([]int{1, 2, 3})
fmt.Println(pool.Get()) // 123
fmt.Println(pool.Get()) // [1 2 3]
fmt.Println(pool.Get()) // 你好呀
// 当池子空了之后, 再获取值的时候不会得到 nil, 而是会得到上面定义的函数的返回值
fmt.Println(pool.Get()) // result
fmt.Println(pool.Get()) // result
fmt.Println(pool.Get()) // result
}
以上就介绍了 Pool 的使用方式,但它最常用的一个场景就是:缓存池,因为 byte、slice 是经常被创建和销毁的一类对象,使用 buffer 池可以缓存已经创建的 byte、slice。比如著名的静态网站生成工具 Hugo 中,就包含这样的实现。
var buffers = sync.Pool{
New: func() interface{} {
return new(bytes.Buffer)
},
}
func GetBuffer() *bytes.Buffer {
return buffers.Get().(*bytes.Buffer)
}
func PutBuffer(buf *bytes.Buffer) {
buf.Reset()
buffers.Put(buf)
}
这段 buffer 池的代码非常常用,很可能你在阅读其它项目的代码的时候就碰到过,或者是你自己实现 buffer 池的时候也会这么去实现。但是需要注意,这段代码是有问题的,一定不要将上面的代码应用到实际的产品中,它可能会有内存泄漏的问题,下面会重点说明。
sync.Pool 的坑
sync.Pool 在使用的时候也会遇见一些坑,我们来看一下。
内存泄漏
我们前面看到可以使用 sync.Pool 实现 buffer 池,但实现的方式会有可能导致内存泄漏,下面来解释一下原因。
取出来的 bytes.Buffer 在使用的时候,我们可以往这个元素中增加大量的 byte 数据,这可能会导致底层的 byte、slice 的容量变得很大,这个时候即使 Reset 再放回到池子,这些 byte、slice 的容量也不会改变。这些大的 Buffer 放入池子中可能就不被回收了,而是会一直占用很大的空间,这便是内存泄漏。
即便是标准库,在上面也栽了几次坑,后来在元素放回时增加了检查逻辑,改成放回的 buffer 如果超过一定大小则直接丢弃,不再放到池子中。所以在使用 sync.Pool 回收 buffer 的时候,一定要检查回收的对象的大小,如果 buffer 太大,就不要回收了。
内存浪费
除了内存泄漏之外,还有内存浪费,就是池子中的 buffer 都比较大,但在实际使用的时候只需要一个小的 buffer。
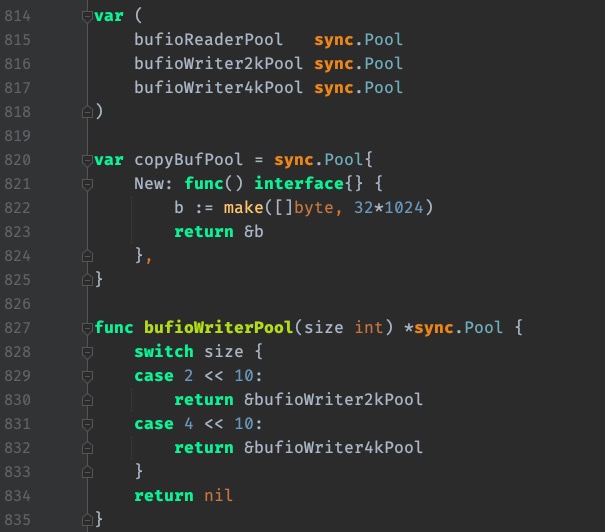
要做到物尽其用,尽可能不浪费的话,我们可以将 buffer 池分为几层。首先,小于 512 byte 的元素的 buffer 占一个池子;其次,小于 1K byte 大小的元素占一个池子;以及小于 4K byte 大小的元素占一个池子。这样分成几个池子以后,就可以根据需要,到所需大小的池子中获取 buffer 了。
在标准库 net/http/server.go 的代码中,就提供了 2K 和 4K 两个 writer 的池子。
Pool 小结
Pool 是一个通用的概念,也是解决对象重用和预先分配的一个常用的优化手段。即使你自己没在项目中直接使用过,但肯定在使用其它库的时候,享受到应用 Pool 的好处了,比如数据库的访问、http API 的请求等等。
我们一般不会在程序一开始的时候就考虑优化,而是等项目开发到一个阶段,或者快结束的时候,才全面地考虑程序中的优化点,而 Pool 就是常用的一个优化手段。如果你发现程序中有一种 GC 耗时特别高,并且伴随大量相同类型的临时对象,不断地被创建销毁,这时你就可以考虑是不是能通过池化的手段重用这些对象。
另外,在分布式系统或者微服务框架中,可能会有大量的并发 Client 请求,如果 Client 的耗时占比很大,你也可以考虑池化 Client,以便重用。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号