《数据库基础语法》12. 表的集合运算,以及将表变成一个变量
表的集合运算
上一节我们介绍了 SQL 中各种形式的子查询,以及与子查询相关的 IN、ALL、ANY/SOME、EXISTS 运算符。
我们已经学习了两种涉及多个表的查询语句,今天我们来讨论另一种从多个查询中返回组合结果的方法:集合运算。
集合运算:
数据库中的表与集合理论中的集合非常类似,表是由行组成的集合。因此, SQL 支持基于行的各种集合操作:并集运算(UNION)、交集运算(INTERSECT)和差集运算(EXCEPT)。它们都用于将两个查询的结果集合并成一个结果集,但是合并的规则各不相同。
需要注意的是,SQL 集合操作中的两个查询结果需要满足以下条件:
- 结果集中字段的数量和顺序必须相同;
- 结果集中对应字段的类型必须匹配或兼容。
也就是说,对于参与运算的两个查询结果,要求它们的字段结构相同。如果一个查询返回 2 个字段,另一个查询返回 3 个字段,肯定无法合并。如果一个查询返回数字类型的字段,另一个查询返回字符类型的字段,通常也无法合并;不过数据库可能会尝试执行隐式的类型转换。
交集运算:
INTERSECT 操作符用于返回两个查询结果中的共同部分,即同时出现在第一个查询结果和第二个查询结果中的数据,并且对最终结果进行了去重操作。交集运算的示意图如下:

SELECT *
FROM girl_info
WHERE id IN (1002, 1003, 1004)
INTERSECT
SELECT *
FROM girl_info
WHERE id IN (1002, 1003)
/*
1002 古明地恋 15
1003 椎名真白 17
*/
并集运算:
UNION 操作符用于将两个查询结果相加,返回出现在第一个查询结果或者第二个查询结果中的数据。并集运算的示意图如下:
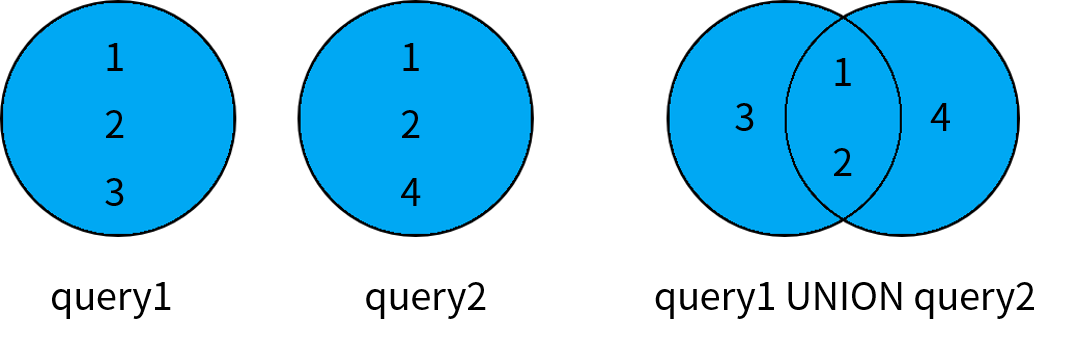
SELECT *
FROM girl_info
WHERE id IN (1002, 1003, 10040)
UNION
SELECT *
FROM girl_info
WHERE id IN (1002, 1003)
/*
1002 古明地恋 15
10040 芙兰朵露 400
1003 椎名真白 17
*/
但我们发现这个结果是去重了的,还有 UNION 等同于 UNION DISTINCT,除此之外还有 UNION ALL,用于返回所有记录,也就是不去重。
SELECT *
FROM girl_info
WHERE id IN (1002, 1003, 10040)
UNION ALL
SELECT *
FROM girl_info
WHERE id IN (1002, 1003)
/*
1002 古明地恋 15
1003 椎名真白 17
10040 芙兰朵露 400
1002 古明地恋 15
1003 椎名真白 17
*/
差集运算:
EXCEPT 操作符用于返回出现在第一个查询结果中,但不在第二个查询结果中的记录,并且对最终结果进行了去重操作。差集运算的示意图如下:

SELECT *
FROM girl_info
WHERE id IN (1002, 1003, 10040)
EXCEPT
SELECT *
FROM girl_info
WHERE id IN (1002, 1003)
/*
10040 芙兰朵露 400
*/
Oracle 使用关键字 MINUS 表示差集运算,MySQL 不支持差集运算。
集合操作中的排序:
如果要对集合操作的结果进行排序,需要将 ORDER BY 子句写在最后;集合操作符之前的查询语句中不能出现排序操作。以下是一个错误的语法示例:
SELECT *
FROM girl_info
WHERE id IN (1002, 1003, 10040)
ORDER BY age
UNION
SELECT *
FROM girl_info
WHERE id IN (1002, 1003);
-- 我们union的时候就写了排序,不单单是因为union之前排序跟union之后是否有序没有任何关系
-- 而是这么写压根就是错误的语法,集合操作的两端不能出现order by关键字
SELECT *
FROM girl_info
WHERE id IN (1002, 1003, 10040)
UNION
SELECT *
FROM girl_info
WHERE id IN (1002, 1003);
ORDER BY age; -- 这么写是正确的
/*
1002 古明地恋 15
1003 椎名真白 17
10040 芙兰朵露 400
*/
-- 此时的 ORDER BY 不是对下面的 SELECT 查询结果进行排序,而是对整个 UNION 之后的结果进行排序
-- 但是在 UNION 上面的 SELECT 语句后面使用 ORDER BY 进行排序的话,则肯定是不符合语法规范的
另外除了 ORDER BY 子句的位置,还有一个常见的问题就是集合操作符的优先级。
集合操作符的优先级:
SQL 提供了 3 种集合操作符:UNION [ALL]、INTERSECT 以及 EXCEPT。我们可以通过多个集合操作符将多个查询的结果进行组合。此时,需要注意它们之间的优先级和执行顺序:
- INTERSECT 的优先级高于 UNION 和 EXCEPT,但是 Oracle 中所有集合操作符的优先级相同;
- 相同的集合操作符按照从左至右的顺序执行;
- 使用括号可以明确指定执行的顺序。
因此很多操作符,包括编程语言也是,尽量还是使用括号进行限定,尽管不加括号,根据优先级,结果也是正确的,但是如果多了的话,还是要加上。一方是为了避免错误,另一方面则是更加的直观。
WITH 语句把表变成一个变量
上一节我们讨论了如何利用 SQL 集合运算符(UNION [ALL]、INTERSECT 以及 EXCEPT)将多个查询结果合并成一个结果。
接下来我们介绍 SQL 中一个非常强大的功能:通用表表达式(Common Table Expression)。
表即变量:
在编程语言中,通常会定义一些变量和函数(方法);变量可以被重复使用,函数(方法)可以将代码模块化并且提高程序的可读性与可维护性。
与此类似,SQL 中的通用表表达式能够实现查询结果的重复利用,简化复杂的连接查询和子查询;并且可以完成数据的递归处理和层次遍历。
举个例子:
SELECT * FROM girl_info
WHERE id in (SELECT id FROM girl_score WHERE id > 1001);
/*
1002 古明地恋 15
1003 椎名真白 17
1006 坂上智代 19
*/
这个是我们之前的例子,我们可以使用with语句,将子查询的结果变成一张临时表。
WITH tmp AS (
SELECT id FROM girl_score WHERE id > 1001
)
SELECT * FROM girl_info
WHERE id IN (SELECT * FROM tmp);
/*
1002 古明地恋 15
1003 椎名真白 17
1006 坂上智代 19
*/
我们将子查询的逻辑写在了 WITH 里面,把子查询返回的内容赋给了变量 tmp。此时 tmp 就相当于是一张表,但是它在数据库中并不真实存在,是一张临时表,但我们是可以当成普通的表来使用的,tmp表的内容就是里面语句返回的结果,那么我们直接对 tmp 进行 SELECT * 即可。
专业一点的话就是,WITH 关键字用于定义通用表表达式(cte);它实际上是定义了一个临时结果集(表),名称为 tmp;AS 关键字指定了 tmp 的结构和数据。
由于我们这里的示例比较简单,所以没啥区别,但如果子查询一多、或者发生了嵌套,WITH 语句就很有用了。
另外 WITH 语句中不要出现分号,因为出现了分号就表示结束了,而我们的 WITH 显然和下面的 SELECT 是分不开了,所以在 WITH xxx AS () 的后面不要出现分号。另外,with也可以同时创建多张临时表。
-- 多个临时表之间使用逗号分隔,tmp1和tmp2就相当于普通的表
-- 可以进行union、join等等
WITH tmp1 AS (
SELECT id FROM girl_score WHERE id > 1001
), tmp2 as (
SELECT id FROM girl_score WHERE id > 1001
)
SELECT * FROM tmp1
UNION ALL
SELECT * FROM tmp2
;
/*
1002
1003
1004
1005
1006
1002
1002
1003
1004
1005
1006
1002
*/
-- 独立的语句之间若想一次性全部执行,需要使用分隔进行分隔
-- 因为独立的语句之间没有关系,需要使用分号标志结束,才能执行下一行语句
-- 而一旦 WITH 下面的语句结束,那么 WITH 创建的临时表的生命周期也结束了
-- 也就是说,接下来我们是无法使用 tmp1 和 tmp2 的,因为它们已经不存在了
WITH 子句相当于定义了一个变量,变量的值是一个表,所以称为通用表表达式。CTE 和子查询类似,可以用于 SELECT、INSERT、UPDATE 以及 DELETE 语句中。Oracle 中称之为子查询因子(subquery factoring)
因此普通的通用表表达式可以将 SQL 语句进行模块化,便于阅读和理解;而递归形式的通用表表达式可以非常方便地遍历具有层次结构或者树状结构的数据,例如组织结构遍历和航班中转信息查询。
下面来看看递归查询。
递归查询:
通用表表达式支持在定义中调用自己,也就是实现编程中的递归调用。接下来我们就介绍一些常用的递归 CTE 案例。
以下是一个简单的递归查询示例,该语句用于生成一个 1 到 10 的数字序列:
-- MySQL 以及 PostgreSQL需要加上 recursive 才表示递归
-- 而Oracle 以及 SQL Server不需要recursive,直接还是使用with即可
WITH RECURSIVE recursion(n) AS (
SELECT 1
UNION all
SELECT n + 1 FROM recursion WHERE n < 10
)
SELECT * FROM recursion;
/*
1
2
3
4
5
6
7
8
9
10
*/
我们这里不再只使用 WITH,而是使用 WITH RECURSIVE,这样后面定义的 recursion 临时表才是可以递归的,我们下面才能 FROM recursion。但是我们注意到,我们定义的时候还加上了一个参数。不加参数的话,里面的内容是从其它地方过来的,但是我们这里是 FROM recursion,也就是说我们定义了一张表 recursion,然后这张表的内容还是从 recurion 里面获取,而我们的数据是 n 取不同的值进行 UNION 得到的,显然这个 n 得有地方接收,那么接收的位置显然就是参数了。而这个 n 则是自动生成的,作为参数的它初始值的时候为 1。
- 运行初始化语句,生成数字 1;
- 第 1 次运行递归部分,此时 n 等于 1,返回数字 2( n+1 );
- 第 2 次运行递归部分,此时 n 等于 2,返回数字 3( n+1 );
- 第 9 次运行递归部分,此时 n 等于 9,返回数字 10( n+1 );
- 第 10 次运行递归部分,此时 n 等于 10;由于查询不满足条件( WHERE n < 10 ),不返回任何结果,并且递归结束;
- 最后的查询语句返回 t 中的全部数据,也就是一个 1 到 10 的数字序列。
显然,递归 CTE 非常合适用于生成具有某种规律的数字序列,例如斐波那契数列(Fibonacci series)。
斐波那契数列指的是这样一个数列:0、1、1、2、3、5、8、13、...。从数字 0 和 1 开始,每个数字都等于它前面的两个数字之和。如果递归查询中的每一行都基于前面的两个数值求和,就能生成一个斐波那契数列:
WITH RECURSIVE fibonacci (n, fib_n, next_fib_n) AS (
SELECT 1, 0, 1
UNION ALL
SELECT n + 1, next_fib_n, fib_n + next_fib_n
FROM fibonacci
WHERE n < 10
)
SELECT *
FROM fibonacci;

n,fib_n,next_fib_n,三者初始值均为1。
该语句的执行过程如下:
- 初始化第一个斐波那契数列值。字段 fib_n 表示第 n 个斐波那契数列值,第 1 个值为 0;字段 next_fib_n 表示下一个斐波那契数列值,第 2 个数列值为 1;
- 第一次运行递归部分,字段 n 等于 2(1 + 1);字段 fib_n 的值为 1(上一次的 next_fib_n);字段 next_fib_n 的值为 1(0 + 1);
- 继续执行递归部分,字段 n 加上 1;使用上一条记录中的 next_fib_n 作为此次的斐波那契数列值,并且使用 fib_n + next_fib_n 作为下一个斐波那契数列值;
- 不断迭代该过程,当 n 到达 10 之后结束递归过程;
- 最后的查询语句返回所有的数列值。
关于这里的递归,个人觉得不是很重要,了解一下即可。但是有时候递归却有很重要,因为使用递归最大的特点就是会用的话,那么问题就变得非常简单,几行就写完了。但是换来的代价就是非常的不好理解,因此关于递归可以自己平时多练习,至于工作中是否使用递归就看你自己的了。只是希望不要为了耍帅为用递归,普通办法能够高效率解决的话,那么还是使用普通办法。
递归限制:
通常来说,递归 CTE 的定义中需要包含一个终止递归的条件;否则的话,递归将会进入死循环。递归终止的条件可以是遍历完表中的所有数据,不再返回结果;或者是一个 WHERE 终止条件。
WITH RECURSIVE t (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM t
)
SELECT n FROM t;
我们上面没有终止条件,因为没有使用 WHERE 对 n 进行限定,那么执行该语句时,Oracle 能够检测到查询语句中的问题并提示错误;MySQL 默认递归 1000 次后提示错误;SQL Server 默认递归 100 次后提示错误;PostgreSQL 没有进行控制,而是进入死循环。
小结
SQL 中的集合操作符可以将多个查询的结果组合成一个结果。本节讨论了三种集合操作符:UNION [ALL]、INTERSECT 以及 EXCEPT。但是有时候,可以利用连接查询实现与集合操作相同的效果,有兴趣可以自己尝试一下。
SQL 中的通用表表达式(CTE)相当于定义了一个表的变量,能够将复杂的查询结构化,并且实现结果集的重复利用。CTE 比子查询更易阅读和理解,递归 CTE 则提供了遍历层次数据和树状结构图的编程功能。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号