InfluxDB:最受欢迎的时序型数据库
初识 InfluxDB
这次来聊一下 InfluxDB,不过在介绍之前,我们需要先了解一下什么是 "时序数据"。按照时间顺序记录系统、设备状态变化的数据被称为时序数据(Time Series Data),如 CPU 利用率、服务器指标、应用程序性能指标、函数接口调用指标、网络流量数据、探测器数据、日志等等。时序数据以时间作为主要的查询纬度,通常会将连续的多个时序数据绘制成线,制作基于时间的多纬度报表,用于揭示数据背后的趋势、规律、异常,进行实时在线预测和预警,时序数据普遍存在于 IT 基础设施、运维监控系统和物联网中。时序数据主要有如下3个特点:
抵达的数据几乎总是作为新条目被记录,无更新操作数据通常按照时间顺序抵达时间是一个主坐标轴
时序型数据库是存放时序数据的专用型数据库,并且支持时序数据的快速写入、持久化、多纬度的实时聚合运算等功能。传统数据库通常记录数据的当前值,时序型数据库则记录所有的历史数据,在处理当前时序数据时又要不断接收新的时序数据,同时时序数据的查询也总是以时间为基础查询条件,并专注于解决以下海量数据场景的问题:
时序数据的写入:如何支持千万级/秒数据的写入时序数据的读取:如何支持千万级/秒数据的聚合和查询成本敏感:海量数据存储带来的是成本问题,如何更低成本地存储这些数据,是时序型数据库需要解决的关键问题
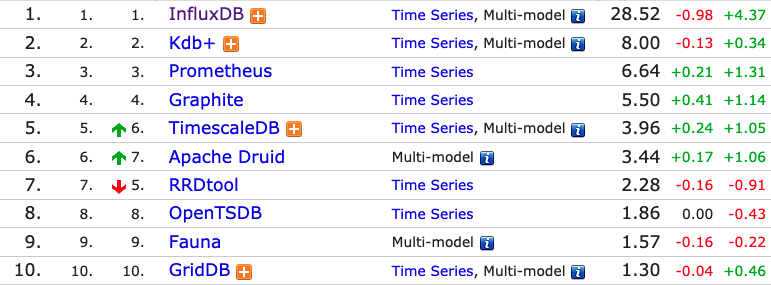
而 InfluxDB 便是一个由 InfluxData 公司开发的时序型数据库,专注于海量时序数据的高性能读、高性能写、高效存储与实时分析,广泛应用于DevOps监控、IoT监控、实时分析等场景。而在时序型数据库排行榜上, InfluxDB 也位列榜首:
那么 InfluxDB 都有哪些优点呢?
- 1. 部署简单,使用方便,在技术实现上充分利用了 Go 语言的特性,无须任何外部依赖即可独立部署;
- 2. 提供类似于SQL的查询语言,接口友好,使用方便;
- 3. 拥有丰富的聚合运算和采样能力;
- 4. 提供灵活的数据保留策略(Retention Policy)来设置数据的保留时间和副本数;
- 5. 在保障数据可靠性的同时,及时删除过期数据,释放存储空间;
- 6. 提供灵活的连续查询(Continuous Query)来实现对海量数据的采样;
- 7. 支持多种通信协议,除了HTTP、UDP等原生协议,还兼容CollectD、Graphite、OpenTSDB、Prometheus等组件的通信协议;
而讲到 InfluxDB,就不得不提 InfluxData 公司开源的高性能时序中台 TICK(Telegraf+InfluxDB + Chronograf + Kapacitor),其中 InfluxDB 就是作为 TICK 的存储系统进行设计和开发的。TICK 专注于 DevOps 监控、IoT监控、实时分析等应用场景,是一个集成了采集、存储、分析、可视化等能力的开源时序中台,由 Telegraf、InfluxDB、Chronograf、Kapacitor 共 4 个组件以一种灵活松散但紧密配合、互为补充的方式构成。
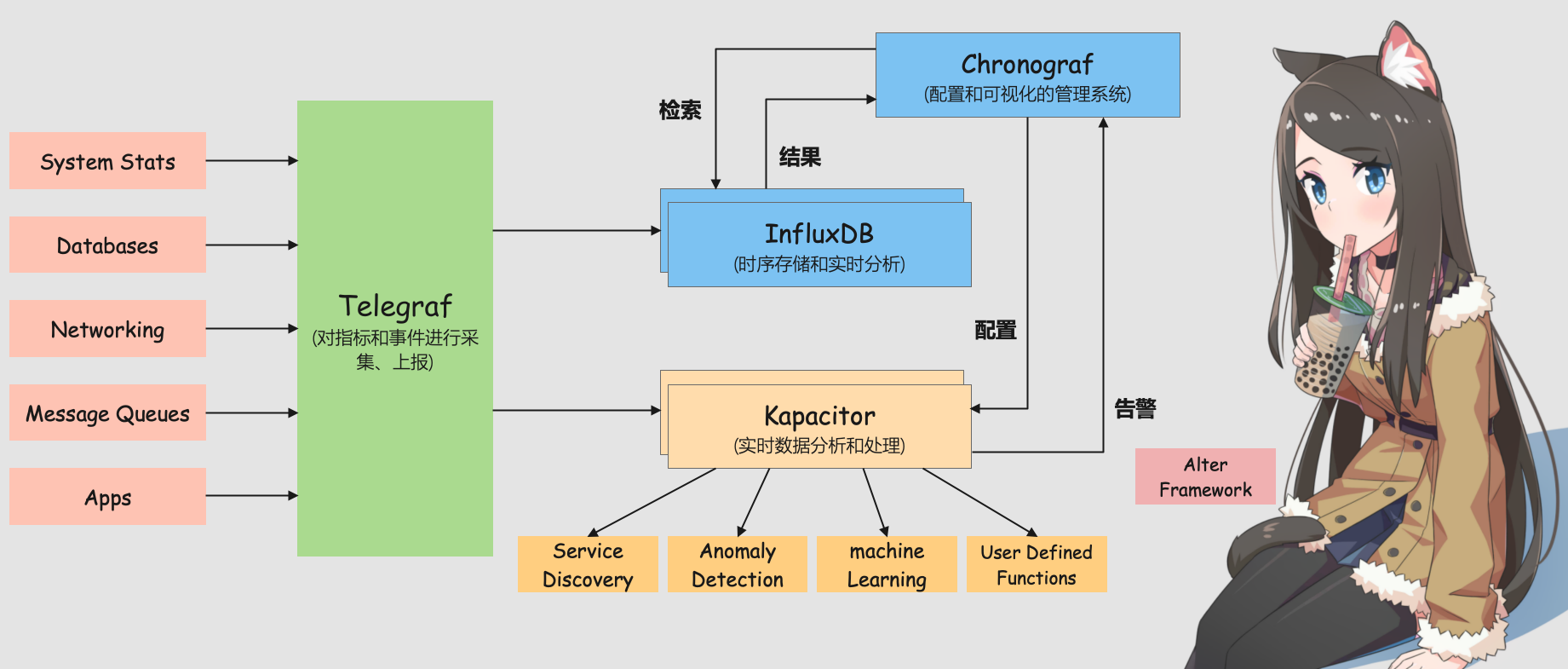
- Telegraf 是用于采集和上报指标的数据采集程序,采用灵活的、可配置的插件实现。Telegraf 可以通过配置文件中的相关配置,采集当前运行主机的指定指标,如 CPU 负载、内存使用等,也可以从第三方消费者服务(如 StatsD、Kafka)拉取数据,上报到已支持的多种存储系统、服务或消息队列,如 InfluxDB、Graphite、OpenTSDB、Datadog、Librato、Kafka、MQTT、NSQ 等。
- InfluxDB 是专注于时序数据场景(如 DevOps 监控、IoT 监控、实时分析等)的高性能时序型数据库,支持灵活的自定义保留策略和类 SQL 的操作接口。
- Chronograf 是可视化的、BS 架构管理系统,可用于配置和管理接收到的监控数据、告警,并支持通过灵活强大的模块和库,快速配置数据可视化仪表盘、告警规则、可视化规则。
- Kapacitor 是从零构建的原生数据处理引擎,支持流式处理和批量处理,支持灵活强大的自定义功能,如定义新的告警阈值、告警指标特征、告警统计异常特征等,以及后续的告警处理行为。除了灵活,Kapacitor 也很开放,能灵活地集成对接第三系统,如 HipChat、OpsGenie、Alerta、Sensu、PagerDuty、Slack 等。
所以 TICK 是一个集成了采集、存储、分析、可视化等能力的开源时序型中台,由 Telegraf 实现数据的采集功能、InfluxDB 实现数据的时序存储和分析功能、Chronograf 实现数据的可视化功能、Kapacitor 实现数据的实时流式处理功能,是一个完善的时序数据解决方案。这些组件的 GitHub 地址如下:
Telegraf:https://github.com/influxdata/telegrafInfluxDB:https://github.com/influxdata/influxdbChronograf:https://github.com/influxdata/chronografKapacitor:https://github.com/influxdata/kapacitor
InfluxDB 的优势
存储和分析时序数据的时序型系统并不鲜见,自计算机问世以来,我们一直在数据库中存储时序数据,比如 MySQL。在之后第一代时序平台,如 KDB +、RRDtool、Graphite 等就推出了,主要用于存储和分析数据中心的时序数据,以及高频金融数据、股票波动率等。
根据数据库趋势跟踪和行业分析网站(DB-Engines)发布的信息,时序型数据库是数据库市场中份额增长最快的部分。原因很明显,计算机世界中的数据库、网络、容器、系统、应用程序等,和物理世界中的家用设备、城市基础设施、工厂机器、电力设施等,正在创建海量的时序数据。现在更多的企业会通过时序存储和数据分析来获得预测能力和实时决策能力,从而为客户提供更好的使用体验。这意味着底层数据平台需要发展以应对新的工作负载的挑战,以及更多的数据点、数据源、监控维度、控制策略和精度更高的实时响应,对下一代时序中台提出了更高的要求,比如:
专为时序存储和高性能读写而设计:计算机世界的各种系统和应用,以及物理世界的 IoT 设备都在创建海量的时序数据,每秒千万级的数据吞吐量是很常见的,而且这些数据还需要可以以非阻塞方式接收并且可压缩以节省有限的存储资源专为实时操作而设计:预测能力和实时决策能力,需要收到数据后,就能实时输出最新的数据分析结果,执行预定义的操作专为高可用性而设计:现代软件系统需要全天候可用,除了基本的集群能力,还需要根据需求自动扩容和缩容,支持柔性可用等
InfluxData 公司选择从头开始构建 InfluxDB 以支持下一代时序中台的需求,InfluxDB 通过实现高度可扩展的数据接收和存储引擎,可以高效地实时收集、存储、查询、可视化显示和执行预定义操作。它通过连续查询提升查询效率和缩短延迟,通过数据保留策略,及时高效地删除过期冷数据,提升存储效率。
到这里就必须提一下其它种类的数据库了,比如关系型数据库、Cassandra、MongoDB、HBase 等,利用它们也可以实现时序数据的存储,但却不是最优的选择,这是为什么呢?原因就在于和 InfluxDB 相比,其需要开发人员投入大量的时间进行代码编写,以开发和 InfluxDB 相似的功能,比如:
编写代码实现跨集群数据分片功能、聚合运算和采样功能、数据生命周期管理功能等实现丰富的 API 接口编写用于数据采集的工具实现实时处理模块并编写用于监控和警报的代码编写可视化引擎以向用户显示时序数据
为了能对 InfluxDB 的优势有个直观的认识,接下来我们将 InfluxDB 和其他被用作时序存储的系统(如 ElasticSearch、MongoDB、OpenTSDB)做个简要的对比,更直观地感受 InfluxDB 的优势。
InfluxDB vs ElasticSearch
ElasticSearch 是专为搜索而设计的系统,是实现搜索功能的绝佳选择,然而对于时序数据,却并非如此。在处理时序数据时,InfluxDB 的性能远远超过 ElasticSearch 系统,对于写入吞吐量,ElasticSearch 通常少于 InfluxDB 5~10 倍,具体差值取决于架构。对于特定时序的查询速度,使用 ElasticSearch 比使用 InfluxDB 要慢 5~100 倍,具体差值取决于查询的时间范围。最后,如果需要存储原始数据以便稍后查询,则 ElasticSearch 上的硬盘占用比 InfluxDB 大 10~15 倍。如果先汇总数据再存储,ElasticSearch 的硬盘占用比 InfluxDB 大 3~4 倍。综合来看,ElasticSearch 非常适合进行搜索,但不适用于时序存储和实时分析。
InfluxDB vs MongoDB
MongoDB 是一个开源的、面向文档的数据库,俗称 NoSQL 数据库,用 C 和 C ++ 语言编写。虽然它通常不被认为是真正的时序型数据库(TSDB),但它经常被用作时序存储系统。它以时间戳和分组的形式提供建模原语,使用户能够存储和查询时序数据。MongoDB 旨在存储 "无模式" 数据,其中每个对象可能具有不同的结构。实际上,MongoDB 通常用于存储内容大小可变的 JSON 或 BSON 对象。由于其采用通用性和无模式数据存储区设计,MongoDB 无法利用时序数据的高度结构化特性。需要特别指出的是,时序数据由标签(键/值串对)和时间戳组成,这时必须对 MongoDB 做专门配置以支持时序数据,但这样做效率很低。相比 MongoDB,InfluxDB 的性能和成本优势明显,InfluxDB 的写性能大约是 MongoDB 的 2.4 倍,存储效率大约是 MongoDB 的 20 倍,查询效率大约是 MongoDB 的 5.7 倍。综合来看,MongoDB 非常适合文档和自定义对象,但不适用于大规模的时序数据和实时分析。
InfluxDB vs OpenTSDB
OpenTSDB 是一个可扩展的分布式时序型数据库,用 Java 语言编写,构建在 HBase 之上。它最初是由 Benoît Sigoure 于2010年开始编写的,并在 LGPL 下开源。OpenTSDB 不是一个独立的时序型数据库,相反,它依赖 HBase 作为其数据存储层,因此 OpenTSDB 时序守护进程(OpenTSDB 中的 TSD)在实例之间没有共享状态可以高效地提供查询引擎的功能。OpenTSDB 允许通过其 API 进行简单的聚合和数学运算,但没有完整的查询语言。OpenTSDB 支持毫秒的分辨率,但随着亚毫秒级操作的普及,OpenTSDB 有时会出现精度不足的问题。相比 OpenTSDB,InfluxDB 的性能和成本优势明显,InfluxDB 的写性能大约是 OpenTSDB 的 5 倍,存储效率大约是 OpenTSDB 的 16.5 倍,查询效率大约是 OpenTSDB 的 3.65 倍。另外,OpenTSDB 的设计初衷主要是用于生成仪表板图,不是为了满足任意查询,也不是为了存储数据,这些限制会影响它的使用方式。
InfluxDB 的特性
作为一个开源系统,InfluxDB 究竟有什么魅力吸引了如此多的用户,从而在时序型数据库排行榜上排名第一呢,并且还和第二名拉开如此大的差距。
首先 InfluxDB 是支持时序数据高效读写、压缩存储、实时计算能力的数据库服务,除了具有成本优势的高性能读、高性能写、高存储率之外,InfluxDB 还具有如下特点:
无系统环境依赖,部署方便无模式(schema-less)的数据模型,灵活强大原生 HTTP 管理接口,免插件配置和免第三方依赖强大的类 SQL 查询语句,学习成本低,上手快丰富的权限管理功能:精细到"表"级别丰富的时效管理功能:自动删除过期数据,自定义删除指标数据低成本存储,采样时序数据,压缩存储丰富的聚合函数,支持 AVG、SUM、MAX、MIN 等聚合函数
InfluxDB 的安装
InfluxDB 支持多个主流系统环境下的安装部署,这里我们以 CentOS 为例,我使用的是阿里云上的云服务器。我们直接进入 InfluxDB 的下载页面,选择相应的系统之后,会自动显示下载方式。
这里我们直接选择 InfluxDB 1.8.9,我们按照提示进行安装即可。另外需要说明的是,这篇关于 InfluxDB 的博客很早就有了,但当时因为用不上所以就写了一点,最近打算写完整。
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.8.9.x86_64.rpm
sudo yum localinstall influxdb-1.8.9.x86_64.rpm
我这里已经安装成功了,安装时需要使用 root 或管理员权限。如果想卸载的话也很简单,直接 yum remove influxdb -y 即可。
然后是端口,默认情况下,InfluxDB 服务监听了两个端口:8086 和 8088。其中 8086 端口是 InfluxDB 服务端 HTTP RESTful API 接入服务的监听端口,8088 端口是 RPC 服务的监听端口,主要用于数据的备份与还原、以及通信等等。如果使用的是云服务器,那么要确保这两个端口是对外开放的。除了这些端口外,InfluxDB 还集成了第三方插件的服务监听端口,所有端口都可以通过 InfluxDB 配置文件进行修改,默认情况下,该文件位于 /etc/influxdb/influxdb.conf 下。
InfluxDB 软件包程序
通常,InfluxDB 在安装之后会提供以下几个程序:
influx:InfluxDB 的命令行工具,如果以 Redis 为例,那么这里的 influx 就类似于 redis-cliinfluxd:InfluxDB 的服务器程序,如果以 Redis 为例,那么这里的 influxd 就类似于 redis-serverinflux_inspect:InfluxDB 的数据检查工具influx_stress:压力测试工具
接下来,我们分别看一下这几个程序的使用方式和参数。
influx 介绍
influx 是 InfluxDB 的命令行工具,用于通过命令行的形式访问 InfluxDB 服务。
注意:influx 的版本必须和 InfluxDB 服务器程序(influxd)的版本相同,如果两者版本不相同,则查询时可能会出现解析错误的问题。
InfluxDB 的常用参数如下:
-version:显示程序版本信息-host 'IP 或者主机名':指定要连接的主机-port '端口':指定要连接的主机的端口号-socket 'unix domain socket':以 UNIX 域 socket 的方式连接 InfluxDB-database '数据库名':指定要连接的数据库-username '用户名':连接时用于认证的用户名-password '密码':连接时用于认证的密码-ssl:启用 HTTPS 连接-unsafeSsl:当使用 HTTPS 连接到集群时不使用 SSL 验证-execute '命令':要执行的命令-type 'influxql、fux':指定调用 REPL 时使用的查询语言-format 'json、csv、column':指定服务器响应内容的格式,支持 JSON、CVS、COLUMN-precision 'rfc3339、h、m、s、ms、u、ns':指定时间戳的格式,支持 rfc3339、h、m、s、ms、u、ns,默认格式为 rfc3339-consistency 'any、one、quorum、all':指定写入一致性级别,支持 any、one、quorum、all-pretty:以阅读友好的方式显示 JSON 格式的内容-import:从之前的备份文件中还原备份数据-pps:设置数据导入时每秒允许导入多少条时序数据,默认值为 0,不限制导入速率-path:需要还原的备份文件的存储路径-compressed:设置为 true 时,表示支持导入压缩格式的备份文件
此外 influx 还支持代理访问,可以通过 HTTP_PROXY 和 HTTPS_PROXY 环境变量设置相应的 HTTP 代理和 HTTPS 代理,比如:
HTTP_PROXY=http://ip:port
HTTPS_PROXY=http://ip:port
以上就是 influx 的常用参数,也可以通过 influx -h 进行查看。
influxd 介绍
influxd 是 InfluxDB 的服务器守护进程,启动之后即可提供相关服务了,而启动方式如下:
influxd -config 配置文件路径
下面再来看看 influxd 的基本语法和支持的命令,先有个印象,后面会详细说。
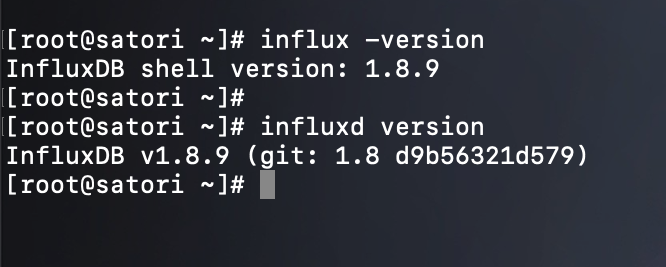
influxd backup:数据备份influxd config:显示 influxd 的配置信息influxd help:显示帮助信息influxd restore:还原之前通过 backup 命令备份的数据influxd run:运行程序,默认参数,可以省略,也就是说 influxd 和 influxd run 效果是一样的influxd version:显示 influxd 程序的版本信息
我们打印一下版本信息,来演示一下。
influx_inspect 介绍
influx_inspect 是 InfluxDB 的数据检查工具,可通过 influx_inspect 查看 InfluxDB 的 TSM 格式文件的内容。InfluxDB 存储的数据在物理磁盘上由 .tsm 文件所承载,我们使用 influx_inspect 可以查看其内容。
其命令如下:
deletetsm:批量删除原始 TSM 文件dumptsi:显示 tsi1 文件的底层细节信息dumptsm:显示 tsm1 文件的底层细节信息buildtsi:从 tsm1 数据中生成 tsi1 索引信息help:显示帮助信息export:导出数据report:显示分片级别的数据信息verify:验证 TSM 文件的完整性verify-seriesfile:验证时序文件的完整性
InfluxDB 配置文件
InfluxDB 的配置文件为 /etc/influxdb/influxdb.conf,我们将里面的注释删掉贴出来,看看都有哪些可配置项。或者我们也可以通过 influxd config 命令进行查看,更方便一些,因为如果将配置文件中的注释都删掉,那么和 influxd config 输出的内容是一样的。
所以,如果哪天不小心把配置文件给搞没了,那么也可以通过 influxd config > /etc/influxdb/influxdb.conf 重新生成一份。
可配置内容如下:
#### 全局配置 ####
# 是否禁止将 InfluxDB 使用信息上报到 usage.influxdata.com,默认为 false,也就是不禁止,也就是上报
reporting-disabled = false
# RPC 服务对应的地址,用于数据备份、通信等等
bind-address = "127.0.0.1:8088"
#### meta 节点相关配置 ####
[meta]
# META 数据和 Raft 数据库的存储目录
dir = "/var/lib/influxdb/meta"
# 是否在创建数据库时,创建默认保留策略 autogen,默认为 true
retention-autocreate = true
# 是否开启 META 日志,默认为 true
logging-enabled = true
#### data 节点相关配置 ####
[data]
# TSM 文件的存储目录,我们说该文件是实际数据的载体
dir = "/var/lib/influxdb/data"
# 分片索引类型
index-version = "inmem"
# WAL 文件的存储目录
wal-dir = "/var/lib/influxdb/wal"
# 在同步写入之前等待的总时间
wal-fsync-delay = "0s"
# 检查写请求中的表名、标签键、标签值是否是有效的 UNICODE 字符,此设置会产生额外的性能开销
# 因为必须检查每条时序数据的表名、标签键、标签值,默认为 false,也就是不检查
validate-keys = false
# 是否提供更多的错误检查
strict-error-handling = false
# 是否开启查询日志,默认为 true
query-log-enabled = true
# 设置分片缓存最大值,大于该值的时候拒绝写入,单位 byte,也就是 1GB
cache-max-memory-size = 1073741824
# 设置快照大小,大于该值时数据会写入到 TSM 格式的文件中,默认大小为 25MB
cache-snapshot-memory-size = 26214400
# TSM 引擎快照写入磁盘延时,默认值为 10 分钟
cache-snapshot-write-cold-duration = "10m0s"
# TSM 文件在压缩前可以存储的最大时间,默认为 4 小时
compact-full-write-cold-duration = "4h0m0s"
# 设置 TSM 压缩写入磁盘的速率限制,单位 "字节/秒"
compact-throughput = 50331648
# 设置 TSM 压缩写入磁盘的峰值速率限制,单位 "字节/秒"
compact-throughput-burst = 50331648
# 设置数据库的时间序列线最大值,该值为 0 时表示无限制,默认值为 1000000
max-series-per-database = 1000000
# 设置一个标签键对应的标签值的最大数量,该值为 0 时表示无限制,默认值为 100000
max-values-per-tag = 100000
# TSM 压缩的最大并发数,默认为 0,表示当前 CPU 核数除以 2,否则以设置的非零值为准
max-concurrent-compactions = 0
# WAL 文件压缩到 TSI 索引文件的阈值,单位为 byte,默认值为 1m
max-index-log-file-size = 1048576
# TSI 索引引擎用于存放处理后的时序结果的内部缓存大小
series-id-set-cache-size = 100
# 是否开启 TSM 引擎和 WAL 模块的调试日志记录,可以提供更详细的内容,默认为 false
trace-logging-enabled = false
# 该配置不建议使用,作用是帮助磁盘速度较慢的用户,但是会存在一些问题,所以为 false,不建议改为 true
tsm-use-madv-willneed = false
#### coordinator 节点相关配置 ####
[coordinator]
# 写超时阈值,默认值为 10 秒
write-timeout = "10s"
# 最大并发查询数,默认为 0 表示无限制
max-concurrent-queries = 0
# 查询超时阈值,0 表示不设置超时时间
query-timeout = "0s"
# 慢查询超时阈值,超时后生成一条慢查询日志,0 表示无限制
log-queries-after = "0s"
# 一次 SELECT 操作可以处理的最大时序数据记录的条数,0 表示无限制
max-select-point = 0
# 一次 SELECT 操作可以处理的最大时间序列线的数量,0 表示无限制
max-select-series = 0
# 一次 SELECT 操作可以创建的 GROUP BY 时间段的最大数量,0 表示无限制
max-select-buckets = 0
#### coordinator 节点相关配置 ####
[retention]
# 是否开启保留策略功能,默认为 true
enabled = true
# 检查的时间间隔,默认值为 30 分钟
check-interval = "30m0s"
#### shard-precreation 节点相关配置 ####
[shard-precreation]
# 是否开启分片预创建服务,默认值为 true
enabled = true
# 检查时间间隔,默认值为 10 分钟
check-interval = "10m0s"
# 创建分片组的最大提前时间间隔,默认值为 30 分钟
advance-period = "30m0s"
#### monitor 节点相关配置 ####
[monitor]
# 是否开启 Monitor 功能,默认值为 true
store-enabled = true
# 默认数据库名
store-database = "_internal"
# 统计时间间隔,默认值为 10 秒
store-interval = "10s"
#### subscriber 节点相关配置 ####
[subscriber]
# 是否开启 Subscriber 功能,默认值为 true
enabled = true
# HTTP 通信超时阈值,默认值为 30 秒
http-timeout = "30s"
# 是否准许接入自签名证书的 HTTPS 连接,默认值为 false
insecure-skip-verify = false
# 设置 CA 证书的存储目录
ca-certs = ""
# 设置写并发数,默认为 40
write-concurrency = 40
# 设置写缓存大小,默认为 1000,单位 byte
write-buffer-size = 1000
#### http 节点相关配置 ####
[http]
# 是否开启 HTTP 服务
enabled = true
# HTTP 服务监听的地址信息
bind-address = ":8086"
# 是否开启认证,默认不开启
auth-enabled = false
# 是否开启 HTTP 请求日志
log-enabled = true
# 当启用 HTTP 请求日志时,是否关闭 HTTP 写请求日志
suppress-write-log = false
# 是否开启写操作日志,如果为 true,那么每一次写操作都会打开日志
write-tracing = false
# 是否开启 flux 查询协议
flux-enabled = false
# 是否开启 flux 查询日志
flux-log-enabled = false
# 是否开启 pprof
pprof-enabled = true
# 开启 pprof 是否启用认证
pprof-auth-enabled = false
# 是否开启 pprof,并绑定 localhost:6060 端口
debug-pprof-enabled = false
# 是否启用 HTTPS 功能
https-enabled = false
# 设置 HTTPS 证书的路径
https-certificate = "/etc/ssl/influxdb.pem"
# 设置 HTTPS 私钥的存储路径
https-private-key = ""
# 配置查询返回的最大行数,0 表示无限制
max-row-limit = 0
# 配置最大连接数,0 表示无限制
max-connection-limit = 0
# 用于 JWT 签名的共享密钥
shared-secret = ""
# 配置 realm,默认值为 "InfluxDB"
realm = "InfluxDB"
# 是否启用 UNIX 域 socket 通信
unix-socket-enabled = false
# 设置 UNIX 域 socket 的权限
unix-socket-permissions = "0777"
# 设置 UNIX 域 socket 的路径
bind-socket = "/var/run/influxdb.sock"
# 客户端请求主体的最大值,以字节为单位
max-body-size = 25000000
# HTTP 请求日志的存储目录
access-log-path = ""
# 并发处理的写请求的最大数量,0 表示无限制
max-concurrent-write-limit = 0
# 排队等待处理的写请求的最大数量,0 表示无限制
max-enqueued-write-limit = 0
# 在队列汇总等待处理的写请求的超时阈值,单位 秒
enqueued-write-timeout = 30000000000
#### logging 节点相关配置 ####
[logging]
# 日志格式,默认为 auto
format = "auto"
# 日志级别,默认为 info,也可以改成 debug、warn、error
level = "info"
# 当程序启动时,是否禁用打印 LOGO 信息,默认为 false,也就是打印
suppress-logo = false
#### graphite 节点相关配置 ####
[[graphite]]
# 是否启用该模块,默认 false
enabled = false
# Graphite 接入服务的地址信息
bind-address = ":2003"
# 数据库名称
database = "graphite"
# 配置保留策略,默认为保留策略默认值
retention-policy = ""
# 通信协议
protocol = "tcp"
# 批处理阈值
batch-size = 5000
# 在内存中等待批处理的最大值
batch-pending = 10
# 批处理等待阈值,默认值为 1 秒
batch-timeout = "1s"
# 一致性级别
consistency-level = "one"
# 多个表名之间的连接符
separator = "."
# UDP 读缓存的大小,0 表示使用操作系统提供的值
udp-read-buffer = 0
#### collectd 节点相关配置 ####
[[collectd]]
# 是否启用该模块,默认 false
enabled = false
# Collectd 接入服务的地址信息
bind-address = ":25826"
# 数据库名称
database = "collectd"
# 配置保留策略,默认为保留策略默认值
retention-policy = ""
# 批处理阈值
batch-size = 5000
# 在内存中等待批处理的最大值
batch-pending = 10
# 批处理等待阈值,默认值为 10 秒
batch-timeout = "10s"
# UDP 读缓存的大小,0 表示使用操作系统提供的值
read-buffer = 0
# DB 文件存放目录
typesdb = "/usr/share/collectd/types.db"
# 安全级别
security-level = "none"
# 认证文件存放路径
auth-file = "/etc/collectd/auth_file"
# 两种处理方式:split 和 join,默认 split
# split:将不同插件的数据存储到不同的表中;join:将多个插件的数据存储到同一张表中
parse-multivalue-plugin = "split"
#### opentsdb 节点相关配置 ####
[[opentsdb]]
# 是否启用该模块,默认 false
enabled = false
# Opentsdb 接入服务的地址信息
bind-address = ":4242"
# 数据库名称
database = "opentsdb"
# 配置保留策略,默认为保留策略默认值
retention-policy = ""
# 一致性级别
consistency-level = "one"
# 是否开启 TLS
tls-enabled = false
# 整数存储路径
certificate = "/etc/ssl/influxdb.pem"
# 批处理阈值
batch-size = 1000
# 在内存中等带批处理的最大值
batch-pending = 5
# 批处理等待阈值
batch-timeout = "1s"
# 当检测到数据格式异常时,输出错误日志
log-point-errors = true
#### udp 节点相关配置 ####
[[udp]]
# 是否启用该模块,默认 false
enabled = false
# UDP 接入服务的地址信息
bind-address = ":8089"
# 数据库名
database = "udp"
# 配置保留策略,默认为保留策略默认值
retention-policy = ""
# 批处理阈值
batch-size = 5000
# 在内存中等带批处理的最大值
batch-pending = 10
# UDP 读缓存的大小,0 表示使用操作系统提供的值
read-buffer = 0
# 批处理等待阈值,默认值为 1 秒
batch-timeout = "1s"
# 解析时间戳的精度值,默认使用数据库默认值,即纳秒
precision = ""
#### continuous_queries 节点相关配置 ####
[continuous_queries]
# 是否开启日志,默认值为 true
log-enabled = true
# 是否启用该模块
enabled = true
# 是否记录连续查询执行的统计信息
query-stats-enabled = false
# 连续查询定时运行的时间间隔
run-interval = "1s"
#### tls 节点相关配置 ####
[tls]
# 支持的 TLS 协议的最小版本,有效值包括 tls1.0、tls1.1 和 tls1.2
# 如果未指定,min-verison 则为编译 InfluxDB 的 Go 编译器中,crypto/tls 包内指定的最小 TLS 版本
min-version = ""
# 支持的 TLS 协议的最大版本
max-version = ""
以上就是相关配置,基本上能用到的也比较少。
写入和查询
了解完 InfluxDB 的安装部署之后,我们就开始激动人心的 InfluxDB 基础操作。作为一款优秀的开源软件,InfluxDB 不仅提供了操作友好的类 SQL 风格的操作接口,如 influx 命令行工具、类 SQL 语法等,还支持 RESTful API 风格的 InfluxDB API,学习成本低,使用方便。下面就来 3 个部分介绍 InfluxDB 的写入和查询,首先介绍 InfluxDB 的操作模式,接着介绍行协议和数据的写入操作,最后介绍 InfluxQL 和数据的查询操作。
首先我们将服务启动起来,由于默认是前台启动的,我们改成需要后台启动。
nohup influxd -config /etc/influxdb/influxdb.conf > /dev/null &
操作模式
InfluxDB 支持两种原生的操作模式:influx 命令行工具和 InfluxDB API。influx 命令行工具是一种类似于 mysql 命令行工具的命令行接口,可以方便地执行管理、运维、调试性质的操作。InfluxDB API 是一种可编程性强、编程语言友好的 RESTful API 的操作接口,支持 HTTP 和 HTTPS 协议。
influx 命令行模式
influx 是 InfluxDB 的命令行工具,用于通过命令行的形式访问 InfluxDB 服务。
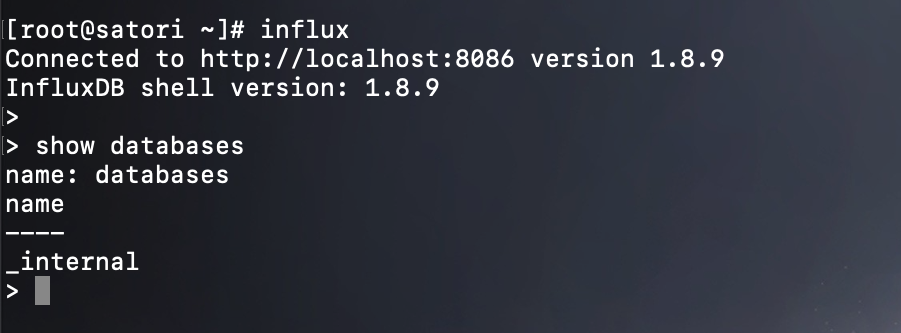
默认连接至本地的 8086 端口,当然我们也可以手动指定。注意:还是之前那句话,InfluxDB 服务器程序版本和 influx 命令行程序版本要相同,如果不相同,则查询时可能会出现解析错误的问题。
我们还可以在不进入 influx 命令行的情况下执行相关命令:

当前默认只有一个 _internal 数据库。
InfluxDB API 模式
InfluxDB API 是一种 RESTful API 风格的接口,返回 JSON 格式的响应数据,并支持身份认证、JWT令牌、丰富的HTTP响应代码等。
InfluxDB API 支持的接口及接口的定义描述如下所示。
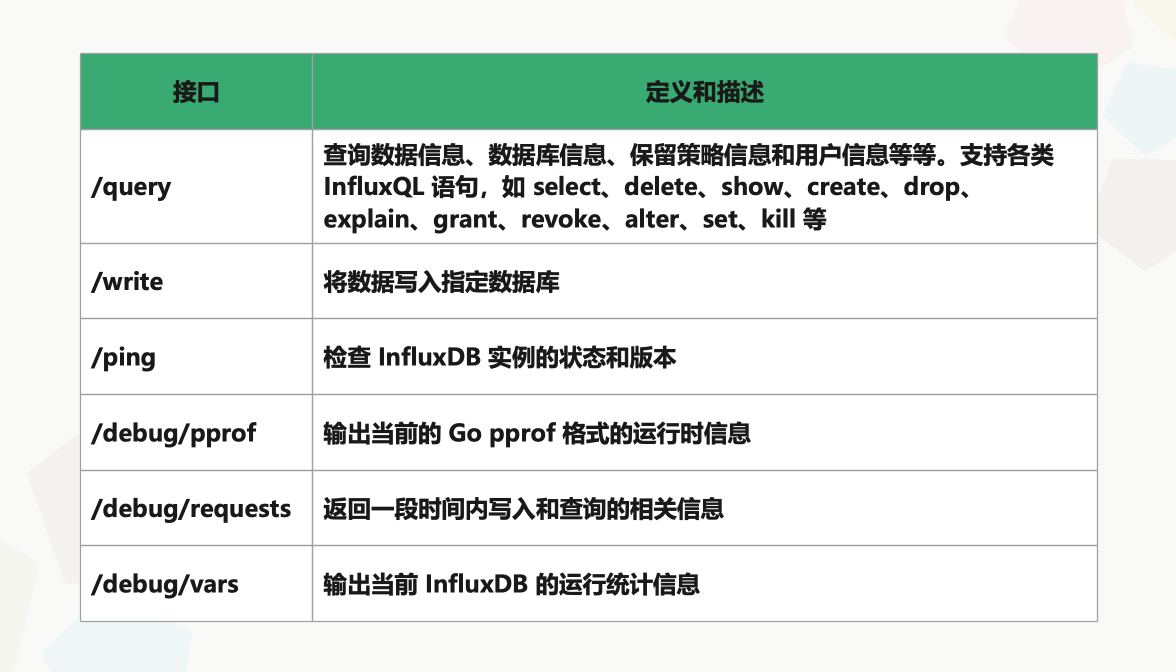
举个栗子,我们可以使用 /ping 接口检查当前地址的 InfluxDB 实例是否健康,如果实例健康运行则返回 InfluxDB 的版本信息;如果实例运行异常,则返回相关错误信息。
from pprint import pprint
import requests
res = requests.get("http://47.94.174.89:8086/ping")
print(res.text == "") # True
pprint(dict(res.headers))
"""
{'Content-Type': 'application/json',
'Date': 'Tue, 12 Oct 2021 12:08:38 GMT',
'Request-Id': '2219324c-2b55-11ec-805d-00163e2e4507',
'X-Influxdb-Build': 'OSS',
'X-Influxdb-Version': '1.8.9',
'X-Request-Id': '2219324c-2b55-11ec-805d-00163e2e4507'}
"""
返回响应体是一个空字符串,证明实例健康运行,而实例版本信息则在请求头中。
InfluxDB API 支持丰富的 HTTP 响应码,在异常跟踪定位上尤其有用,HTTP 响应码列表和含义如下:
204 No Content:执行成功400 Bad Request:请求错误,可能是由于行协议语法错误或写入了一个错误的字段类型401 Unauthorized:请求错误,可能是由于认证凭据无效404 Not Found:请求错误,可能是由于指定了一个不存在的数据库500 Internal Server Error:系统过载或核心信息不匹配,可能是由于指定了一个不存在的保留策略
以上就是 influx 的两种模式,简单介绍一下,更多内容我们在下面的数据写入和数据读取中介绍。
数据写入
InfluxDB 写操作支持简明的行协议(Line Protocol),行协议是一种基于文本格式的协议。
基于兼容开放和生态的考虑,除了行协议,InfluxDB 还支持 CollectD、Graphite、OpenTSDB、Prometheus、UDP 等第三方协议,第三方协议将会在后续详细介绍。
行协议
行协议的单行文本表示一条时序数据,由表、标签集、指标集和时间戳 4 部分组成,行协议的基本语法如下所示。
<measurement> [, <tag-key>=<tag-value>...] <field-key>=<field-value> [, <field-key>=<field-value>...] [timestamp]
InfluxDB 实现了类 SQL 的接口,但在语义体系上还是有很大差别的,我们解释一下这些标签的含义。
- measurement:必填,表示一组有关联的时序数据,类似于 MySQL 中表(Table)的概念。
- tag:选填,表示标签,由标签键(tag-key)和标签值(tag-value)共同组成,比如 host=server01 和 location=cn-sz 这种形式。标签可以用于创建索引,提升查询性能,一般存放的是表示数据点来源的属性信息。
- field:表示指标,同 tag 类似,指标由指标键(field-key)和指标值(field-value)共同组成,比如 user=23.0 和 system=57.0。一般存放的是具体的时序数据,即随着时间戳的变化而变化的数据,与标签不同的是,指标数据不会被索引,并且至少出现一组。指标键要求是字符串,而指标值可以是字符串、浮点型、整型,或布尔型。
- timestamp:可选,表示纳秒级精度的时间戳,如果没有该参数,那么 InfluxDB 写入数据时会根据当前时间自动生成。与 MySQL 不同的是,在 Influx DB中,时间几乎可以看作主键的代名词,因为是时序数据库。
还有几个需要注意的地方:
行协议对空格敏感,标签集和指标集中间必须有空格时间戳参数不可以加引号,否则会报错指标值支持字符串类型,要使用双引号将字符串类型的指标值括起来;但对于非字符串类型的指标值,要注意不能加引号,否则会被当成字符串类型来处理整型默认会被当成浮点型处理,比如 23 会被解析成 23.0,如果想表示整型,那么需要在结尾加上小写字母 i,比如 23i
我们举个栗子:
cpu_usage,host=server01,location=cn-sz user=23,system=57
以上就是一个单行的行协议表达式,也代表一条时序数据,我们注意到第一个指标的前面不是逗号,而是一个空格。然后时间戳我们没有指定,那么 InfluxDB 会自动生成一个。
最后是 InfluxDB 中的的保留字,我们要避免在表名或者字段名中使用 InfluxDB 的保留字,那么 InfluxDB 中的保留字都有哪些呢?
ALL ALTER ANALYZE ANY AS ASC
BEGIN BY CREATE CONTINUOUS DATABASE DATABASES
DEFAULT DELETE DESC DESTINATIONS DIAGNOSTICS DISTINCT
DROP DURATION END EVERY EXPLAIN FIELD
FOR FROM GRANT GRANTS GROUP GROUPS
IN INF INSERT INTO KEY KEYS
KILL LIMIT SHOW MEASUREMENT MEASUREMENTS NAME
OFFSET ON ORDER PASSWORD POLICY POLICIES
PRIVILEGES QUERIES QUERY READ REPLICATION RESAMPLE
RETENTION REVOKE SELECT SERIES SET SHARD
SHARDS SLIMIT SOFFSET STATS SUBSCRIPTION SUBSCRIPTIONS
TAG TO USER USERS VALUES WHERE
WITH WRITE
另外,关键字 time 是一个特殊的保留字,time 不可以用作标签键和指标键的命名,但可以用作其他命名,如表的命名、保留策略的命名等。除了时间戳字段,其他字段如表、标签键、标签值、指标键、指标值,是大小写敏感的。
数据写入
我们可以通过 influx 命令行写入数据,也可以使用 InfluxDB API 写入,先来看看命令行。
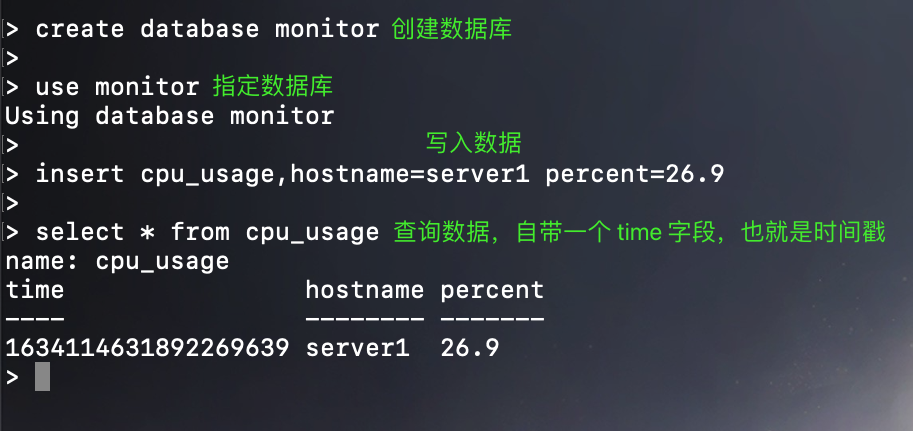
还是很简单的,然后我们看到写入数据通过 insert 进行写入,注意后面没有 into,直接跟行协议表达式。另外与 MySQL 等传统数据库不同的是,InfuxDB 不需要显式地创建新表,当使用 insert 语句插入数据时,InfuxDB 会自动根据 insert 数据的格式和指定的表名自动创建新表。
不过在实际应用中,我们更多还是通过 InfluxDB API 写入时序数据,我们可以一次只写入一条,也可以同时写入多条,多条数据之间用换行符分隔。
curl -ig http://47.94.174.89:8086/write?db=monitor -d "cpu_usage,hostname=server2 percent=32.9
mem_usage,hostname=server1 percent=38.733,value=298864752"
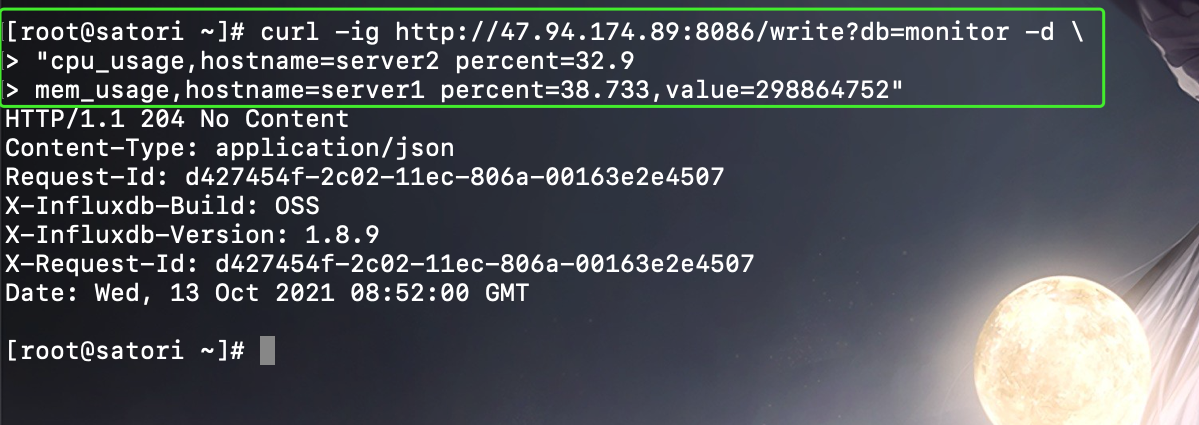
写入多条数据时,表可以不相同。
如果写入数据时没带上时间戳,InfuxDB 会默认使用本地 UTC 纳秒时间作为写入数据的时间,当需要同时向同一个数据库同一个时间序列线写入多条数据时,每条数据都需要带时间戳,否则后写的数据会覆盖前面的数据。
另外导入数据的时候也可以通过文件的方式,举个栗子:
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号