你知道怎么用Python处理 NetCDF 格式的文件吗?
楔子
最近需要处理有关气象方面的数据,而这些数据都是以 NetCDF 文件(.nc)的形式存储的,我需要将 NetCDF 文件读取出来,然后进行处理,最后导入到库中。所以我们今天的主题就是如何读取并处理 NetCDF 文件,但是在这之前我们必须先了解什么是 NetCDF 文件。
NetCDF 全称为 network Common Data Format(网络通用数据格式),它是由美国大学大气研究协会的 Unidata 项目科学家针对科学数据的特点开发的,是一种面向数组型、并适于网络共享的数据描述和编码标准。NetCDF 文件的后缀名为 .nc,它和 zip、jpeg、bmp 文件是类似的,都是一种文件格式的标准。一开始,NetCDF 文件只是用于存储气象科学中的数据,现在已经成为许多数据采集软件生成文件的格式,利用 NetCDF 可以对网络数据进行高效地存储、管理、获取和分发等操作。并且由于其灵活性,以及能够传输海量的面向阵列(array-oriented)数据,所以目前已广泛应用于大气科学、水文、海洋学、环境模拟、地球物理等诸多领域。
那么问题来了, NetCDF 文件里面存储什么数据呢?从数学上来讲,NetCDF 存储的数据就是一个多自变量的单值函数,用公式来说的话就是 \(f(x, y, z, ...) = value\)。在 NetCDF 中,函数的自变量 x、y、z 叫做维度(Dimensions),函数值 value 叫做变量(Variables)。而自变量和函数值在物理学上的一些性质,比如计量单位(量纲)、物理学名称等等,在 NetCDF 中被称为属性(Attributes)。
我们以一个具体的 NetCDF 文件为例:
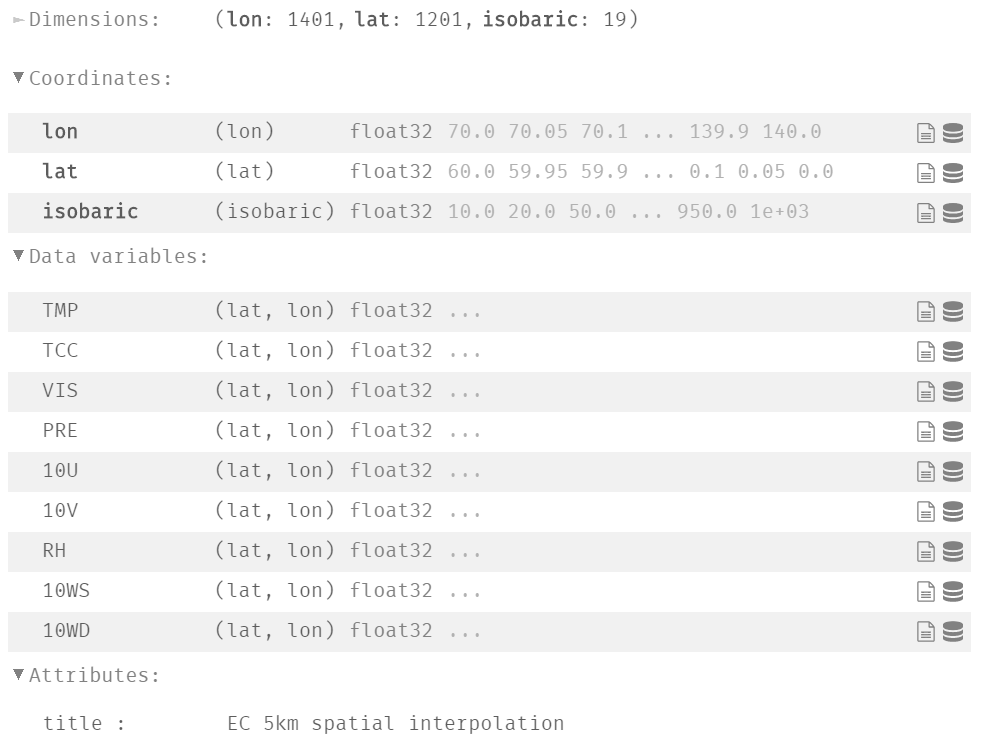
该文件是通过 xarray 读取的,我们后面会详细介绍该模块,当然读取 NetCDF 文件除了使用 xarray 之外,还可以使用 netcdf4 模块读取。我们先来介绍一下 NetCDF 文件的一些属性:
Dimensions
维度(简称维),对应函数中的自变量,当然维度可以有多个,因为我们说它类似于多自变量函数,而从图中可以看到当前的 NetCDF 文件有三个维。并且每一个维都有一个名字和一个长度,比如维度 lon 的长度为 1401、维度 lat 的长度为 1201、维度 isobaric 的长度为 19。
另外,维的长度基本都是有限的,最多只能有一个具有无限长的维。
Coordinates
每一个维度对应的具体的值(一个一维数组),比如 lon 和 lat 就是一个长度分别为 1401、1201 的一维数组。
Data variables
变量,对应着真实的物理数据。比如我们家里的电表,每个时刻显式的度数就是用户截止到此刻的耗电量,这个数值就可以使用 NetCDF 中的变量来表示,显然它是一个以时间为自变量(或者说自变量个数为 1)的单值函数。那么随着时间不断采集,该变量就是一个一维数组;再比如在气象学中要做出一个气压图,也就是获取"东经 xx 度、北纬 yy 度的大气压为多少帕",显然这就是一个二维单值函数,两个维度分别是经度和纬度,函数值为大气压。
因此,NetCDF 中的变量就是一个 N 维数组,数组的维度是实际问题中的自变量个数,数组的值就是观测得到的物理值。而数组类型在 NetCDF 中有 6 种,分别是 ASCII 字符(char)、字节(byte)、短整型(short)、整形(int)、单精度(float)、双精度(double),显然这些类型和 C 语言中的类型是对应的。
然后我们看一下上图中的 Data Variables 这一部分,以第一行为例:
TMP (lat, lon) float32 ...
首先变量也有名字,比如这里的 TMP,然后后面的 (lat, lon) 表示自变量,也就是维,因此变量 TMP 数组里的值是随着 lat、lon 这两个维不断变化的。但是我们从 Dimensions 看到了三个维,除了 lat、lon 之外,还有一个 isobaric,而这里的 TMP 变量只和其中的两个维有关系,这是允许的。最后面的是 float32,表示数据的存储类型,xarray 在解析之后使用的是 Numpy 的数据类型来表示的。
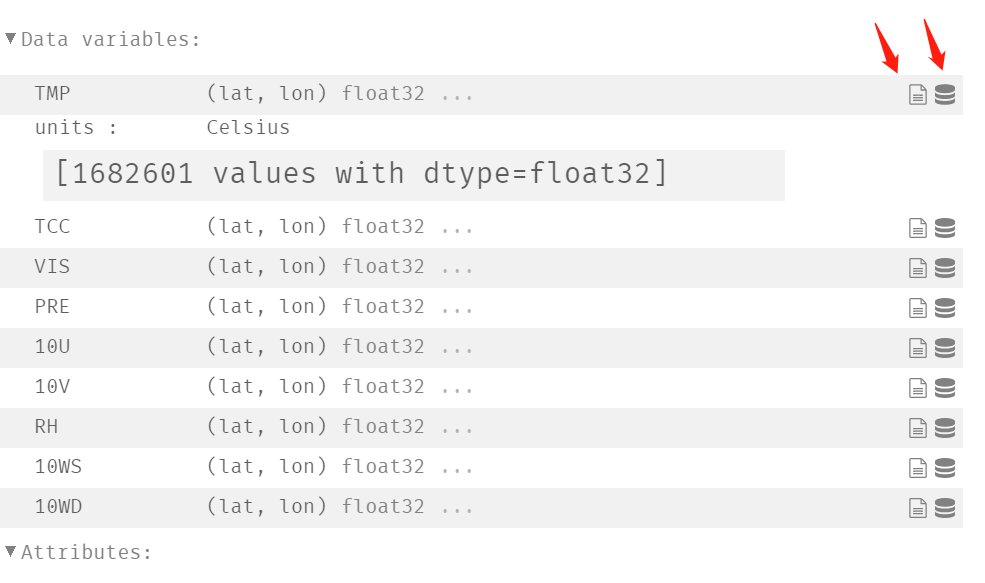
我们上面是通过 jupyter notebook 显式的,所以格式非常优雅,点击红色箭头指向地方,会额外弹出一些信息。比如图中的 units,它表示 TMP 的单位信息,因为数组里面就是一个个的小数,没有单位的话我们不知道它代表什么含义,所以每一个变量都有自身的一些描述属性。因此我们上面说变量就是一个数组其实不太准确,因为除了数组之外还包含了一些元信息。比如下面的 1682601 values ...... 则是告诉我们变量对应的数组里的元素个数,因为数组的元素是随着 lat 和 lon 变化的。lat 的长度为 1201、lon 的长度为 1401,所以 TMP 内部的数组的 shape 为 (1201,1401),元素个数等于两者相乘,也就是 1682601,并且元素类型是 float32。
所以 xarray 在读取文件之后做了一个很好的抽象,将信息统计了出来,比如维的名字和长度、维的坐标、变量的名字、对应的自变量、还有数组元素个数以及类型,并借助 jupyter notebook 进行优雅的展示。并且我们看到变量可以有很多个,每个变量可以对应不同的维度,其数组的元素类型也可以不同。
为了更好的理解,这里我们再举例说明一下:假设有个变量 m,它是随着 x、y 变化的,关系为 f(x, y) = x + y。其中 x 是一个长度 3 的数组 [1 2 3],y 是一个长度为 2 的数组 [5 6],那么你觉得 m 对应的数组是多少呢?很简单。
x = [1 2 3]
y = [5 6]
m = [
[1+5 1+6],
[2+5 2+6]
[3+5 3+6]
]
假设我想获取 x 为 3、y 为 5 时对应的值,那么拿到 m 对应的数组,然后再通过索引 [2, 0] 的方式获取即可。
因此 NetCDF 文件的功能非常强大,很快就取代了传统的 GeoTIFF 文件,原因就在于:
NetCDF 可存储多维数据,而 GeoTIFF 只是一个二维矩阵,无法体现时间或其它维度的信息,如果想做时空分析,就必须打开多个 GeoTIFF 文件。而 NetCDF 将多个维度的信息存储在一块,无论读取还是操作都非常方便NetCDF 可存储多个变量,从图中即可看出。如果是 GeoTIFF 格式的文件,那么每个变量要单独对应一个文件,而 NetCDF 相当于将多个 GeoTIFF 文件打包在了一起,并且每个变量都有自己的名字,所以要更加方便
Attributes
NetCDF 文件的一些描述属性。
以上就是 NetCDF 文件的大致介绍,下面我们就来看看如何操作这种类型的文件,主要有两种方式,使用 xarray 模块或者 netCDF4 模块,我们先来看看 xarray 模块。
xarray 模块详解
xarray 在原始的 Numpy 多维数组之上引入了维度、坐标、属性等标签,使得开发人员能够获得更直观、更简洁、更不易出错的操作体验。我们知道 Numpy 为多维数组提供了基本的数据结构和 API,但来自真实世界的数据集通常不仅仅是原始数据,这些数据还自带了标签,来进行标识。换言之,xarray 不仅可以让我们像 Numpy 那样通过索引去获取,还可以根据标签进行筛选,并且支持的操作种类也十分丰富。
说到这里,你肯定想到了 pandas,没错,xarray 的 API 很大程度上借鉴了 pandas,但 xarray 适合处理更加高维的数据。如果你的数据是一维或者二维,那么交给 pandas 的 Series 和 DataFrame 再合适不过了;但如果数据是三维、四维或者更高维度,那么最好还是交给 xarray。
而 xarray 内部提供了两个最重要的数据结构,DataArray 和 DataSet,我们在读取 NetCDF 文件的时候便是通过 open_dataarray 和 open_dataset 两个函数进行读取,将其转成 DataArray 或 DataSet 进行操作的(主要是 DataSet)。所以我们的重点就是学习一下这两个数据结构,以及它们所支持的一些 API。
安装:pip install xarray
xarray.DataArray
DataArray 是带标签的多维数组的实现,有以下几个属性:
data:多维数组,一般是 numpy.ndarraydims:每个维度的名字coords:每个维度对应的一维数组attrs:给 DataArray 实例额外添加的一些属性name:DataArray 的名字
我们来实际创建一下:
import numpy as np
from xarray import DataArray
dims = ["x", "y"]
coords = [[1, 2, 3, 4], [11, 22, 33]]
data = np.random.randint(1, 100, size=(4, 3))
# 注意 data 的维度要匹配,显然它的 shape 为 (4, 3)
array = DataArray(data, dims=dims, coords=coords)
print(array)
"""
<xarray.DataArray (x: 4, y: 3)>
array([[30, 63, 94],
[ 7, 38, 5],
[89, 83, 32],
[26, 22, 71]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22 33
"""
创建完毕,结构显示的很清晰了,只是我们发现这和刚才读取 NetCDF 文件所显式内容不太一样啊。是的,DataArray 只支持一个变量,如果我们用 open_dataarray 读取刚才的 .nc 文件的话是会报错的。所以在操作 .nc 文件的时候,我们都是转成 DataSet 进行操作,因为 DataSet 的数据表现形式和 NetCDF 文件是一致的。只不过在学习 DataSet 之前,我们有必要先学习一下 DataArray。
另外,如果我们在创建的时候不指定维度的名称,那么会默认生成:
import numpy as np
from xarray import DataArray
from sqlalchemy.engine import URL
dims = ["x", "y"]
coords = [[1, 2, 3, 4], ("y", [11, 22, 33])]
data = np.random.randint(1, 100, size=(4, 3))
array = DataArray(data, coords=coords)
print(array)
"""
<xarray.DataArray (dim_0: 4, y: 3)>
array([[10, 65, 45],
[27, 62, 50],
[29, 98, 87],
[28, 98, 59]])
Coordinates:
* dim_0 (dim_0) int32 1 2 3 4
* y (y) int32 11 22 33
"""
在没有指定 dims 参数的情况下,coords 里面可以是一个数组,此时会按照 dim_{n} 的规则自动生成维度名;或者也可以是一个元组,第一个元素是维度名,第二个元素是维度值。两种指定方式都是可以的,个人觉得第二种方式、也就是维度名和维度值都由 coords 参数指定,可读性更好一些,因为两者是放在一起的,更直观。
所以,corrds 还可以是一个字典,这样读起来就更清晰了。
import numpy as np
from xarray import DataArray
data = np.random.randint(1, 100, size=(4, 3))
array = DataArray(data, coords={"x": [1, 2, 3, 4], "y": [11, 22, 33]})
print(array)
这样也是可以的,个人最推荐这种方式。
除此之外,我们还可以根据 pandas 的 Series、DataFrame 来创建 DataArray,我们以 DataFrame 为例:
import pandas as pd
import xarray
# DataFrame 是一个二维数据,所以生成的 DataArray 也只有两个维度
# 并且两个维度对应的坐标长度是相等的
df = pd.DataFrame({"a": [1, 2], "b": [2, 3]}, index=['x', 'y'])
df.index.name = "dim_1"
df.columns.name = "dim_2"
# 根据 DataFrame 生成的 DataArray
# index 的名称就是第一个维度的名称,index 的值就是第一个维度的坐标
# columns 的名称就是第二个维度的名称,columns 的值就是第一个维度的坐标
# 所以维度一:dim_1 ['x', 'y'],维度二:dim_2 ['a', 'b']
array = xarray.DataArray(df) # 根据 DataFrame 生成的话,无需指定其它任何参数
print(array)
"""
<xarray.DataArray (dim_1: 2, dim_2: 2)>
array([[1, 2],
[2, 3]], dtype=int64)
Coordinates:
* dim_1 (dim_1) object 'x' 'y'
* dim_2 (dim_2) object 'a' 'b'
"""
根据现有的 DataFrame 来构建 DataArray 也是很方便的。
DataArray 的属性
DataArray 有一些非常重要的属性,我们来看一下。
import numpy as np
from xarray import DataArray
data = np.random.randint(1, 100, size=(4, 3))
array = DataArray(data,
coords={"x": [1, 2, 3, 4], "y": [11, 22, 33]},
attrs={"foo": "bar"},
name="xarray.DataArray")
print(array)
"""
<xarray.DataArray 'xarray.DataArray' (x: 4, y: 3)>
array([[71, 42, 80],
[42, 16, 50],
[74, 28, 49],
[96, 52, 65]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22 33
Attributes:
foo: bar
"""
# 获取变量,得到的是一个 Variable 对象
print(array.variable)
"""
<xarray.Variable (x: 4, y: 3)>
array([[71, 42, 80],
[42, 16, 50],
[74, 28, 49],
[96, 52, 65]])
Attributes:
foo: bar
"""
# 获取变量对应的数组,等价于 array.values
print(array.variable.values)
"""
[[71 42 80]
[42 16 50]
[74 28 49]
[96 52 65]]
"""
# 获取维度,等价于 array.dims
print(array.variable.dims)
"""
('x', 'y')
"""
# 获取坐标,此时直接通过 array 获取即可
print(array.coords)
"""
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22 33
"""
# 通过 array.coords 也可以获取维度
print(array.coords.dims)
"""
('x', 'y')
"""
# 获取某个维度对应的坐标,但通过 key 获取到的不是数组
# 因为数组会自动给包装成 DataArray,此时里面的 values 属性才是我们想要坐标数据
# 我们还需要通过调用 .variable.values 才能获取到数组,当然也可以直接调用 values
print(array.coords["x"].values)
"""
[1 2 3 4]
"""
# 也可以调用 keys、values、items
# 其中 k 是维度名,v 是用维度对应的坐标构建的新的 DataArray
print({k: v.values for k, v in array.coords.items()})
"""
{'x': array([1, 2, 3, 4]), 'y': array([11, 22, 33])}
"""
# 获取 DataArray 的 name
print(array.name)
"""
xarray.DataArray
"""
# 获取 DataArray 的属性
print(array.attrs)
"""
{'foo': 'bar'}
"""
这些属性支持本地修改,修改完之后重新打印 array 即可看到效果。比如我们的 array 没有名字,那么可以通过 array.name = "myarray" 来实现。
import numpy as np
from xarray import DataArray
data = np.random.randint(1, 100, size=(4, 3))
array = DataArray([1, 2, 3],
coords={"x": ['a', 'b', 'c']})
print(array)
"""
<xarray.DataArray (x: 3)>
array([1, 2, 3])
Coordinates:
* x (x) <U1 'a' 'b' 'c'
"""
array.name = "xarray.DataArray"
print(array)
"""
<xarray.DataArray 'xarray.DataArray' (x: 3)>
array([1, 2, 3])
Coordinates:
* x (x) <U1 'a' 'b' 'c'
"""
# 如果想改名,还有一个 rename 方法,此时会返回一个新的 DataArray
另外,如果我们想获取某个维度的坐标,可以通过 array.coords["x"],但其实也可以可以直接通过 array["x"] 来获取,效果是一样的。
import numpy as np
from xarray import DataArray
data = np.random.randint(1, 100, size=(4, 3))
array = DataArray(data,
coords={"x": [1, 2, 3, 4], "y": [11, 22, 33]},
attrs={"foo": "bar"},
name="xarray.DataArray")
# 我们看到原来的坐标变成了新的 DataArray 的数组
print(array["x"])
"""
<xarray.DataArray 'x' (x: 4)>
array([1, 2, 3, 4])
Coordinates:
* x (x) int32 1 2 3 4
"""
# 再调用 values 就可以获取到原来 DataArray 的相应维度的坐标
print(array["x"].values) # [1 2 3 4]
print(array["x"].variable.values) # [1 2 3 4]
# 显然 array['x'] 只有一个维度,就是 'x';arra['y'] 同理
print(array["x"].dims) # ('x',)
print(array["y"].dims) # ('y',)
# 但是 keys、values、items 这几个方法我们只能通过 array.coords 来调用
以上就是 DataArray 的一些基本内容,我们下面来看一下 DataSet。
xarray.DataSet
DateSet 等价于多维度的 pandas.DataFrame,它类似于一个字典,里面是包含多个维度对其的 DataArray。最关键的是,DataSet 的内存布局和 NetCDF 文件是相同的,因此我们用 DataSet 可以很轻松的处理 NetCDF 文件。
创建 DataSet 对象
实例化的时候可以传递以下几个参数,分别是 data_vars、coords、attrs,我们分别介绍。
import numpy as np
from xarray import Dataset, Variable
ds = Dataset(
# data_vars 接收的一个字典,里面的 key 就是变量名,value 就是变量对应的数组
# 当然啦,说数组其实不太准确,应该说是一个 Variable 对象
# Variable 的第一个参数表示变量使用了哪些维度
# 第二个参数就是变量对应的数组啦
# 第三个参数 attrs 表示变量的附加属性
# 另外,要注意这里维度要匹配,比如"变量1"的数组的shape 为(2, 2, 3)
# 那么显然使用了三个维度,并且维度坐标(一维数组)的长度分别是 2、2、3
data_vars={"变量1": Variable(["维度1", "维度2", "维度3"],
data=np.random.randint(1, 15, size=(2, 2, 3)),
attrs={"单位": "米"}),
"变量2": Variable(["维度1", "维度2"],
data=np.random.randint(1, 15, size=(2, 2)),
attrs={"单位": "厘米"})
},
# coords 描述维度的坐标,我们在 data_vars 里面使用的维度,显然要通过 coords 定义好
# 当然,在定义的时候别忘记size要匹配
coords={"维度1": [1, 2], "维度2": [2, 3], "维度3": [3, 4, 5]},
# attrs 则是描述整个 DataSet
attrs={"title": "我是 DataSet"}
)
print(ds)
我们打印一下,看看结果。

到此,相信 DataSet 的结构应该已经很清晰了,它的内存布局和 NetCDF 文件是一致的。
然后我们也可以获根据变量名获取对应的值,这个值是一个 DataArray 类型:
print(ds["变量1"])
"""
<xarray.DataArray '变量1' (维度1: 2, 维度2: 2, 维度3: 3)>
array([[[ 3, 4, 12],
[ 2, 9, 5]],
[[14, 9, 7],
[ 2, 10, 12]]])
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
* 维度3 (维度3) int32 3 4 5
Attributes:
单位: 米
"""
print(ds["变量1"].variable)
"""
<xarray.Variable (维度1: 2, 维度2: 2, 维度3: 3)>
array([[[ 3, 4, 12],
[ 2, 9, 5]],
[[14, 9, 7],
[ 2, 10, 12]]])
Attributes:
单位: 米
"""
print(ds["变量1"].coords)
"""
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
* 维度3 (维度3) int32 3 4 5
"""
print(ds["变量2"].coords)
"""
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
"""
操作某一个变量就跟操作 DataArray 没有任何区别了,因为类型就是 DataArray,所以我们在一开始才会先介绍 DataArray。
然后我们在创建变量的时候,指定了一个 attrs 属性,显然它就是 DataArray 的 attrs。当然啦,我们在创建 DataSet 的时候,也给 DataSet 指定了 attrs,我们都可以获取。
# 变量的附加描述,对应 DataArray 的 attrs
print(ds["变量1"].attrs) # {'单位': '米'}
print(ds["变量2"].attrs) # {'单位': '厘米'}
# DataSet 的 attrs
print(ds.attrs) # {'title': '我是 DataSet'}
和 DataArray 一样,DataSet 也支持动态修改。
ds.attrs["嘿"] = "蛤"
print(ds.attrs) # {'title': '我是 DataSet', '嘿': '蛤'}
然后是获取维度的坐标,使用变量获取的话,只能获取某个变量使用的维度,而通过 ds.coords 可以获取全部的维度坐标。
# 查看所有的维度
print(ds.coords)
"""
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
* 维度3 (维度3) int32 3 4 5
"""
# 拿到的仍然是一个 DataArray
print(ds.coords["维度1"])
"""
<xarray.DataArray '维度1' (维度1: 2)>
array([1, 2])
Coordinates:
* 维度1 (维度1) int32 1 2
"""
print(ds.coords["维度1"].values) # [1 2]
另外,DataSet 还支持我们像 DataFrame 一样操作,使用 ds["变量1"] 会得到一个 DataArray。但如果截取多个变量,那么会生成一个新的 DataSet。
print(ds["变量1"])
"""
<xarray.DataArray '变量1' (维度1: 2, 维度2: 2, 维度3: 3)>
array([[[ 3, 4, 12],
[ 2, 9, 5]],
[[14, 9, 7],
[ 2, 10, 12]]])
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
* 维度3 (维度3) int32 3 4 5
Attributes:
单位: 米
"""
print(ds[["变量1", "变量2"]])
"""
<xarray.Dataset>
Dimensions: (维度1: 2, 维度2: 2, 维度3: 3)
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
* 维度3 (维度3) int32 3 4 5
Data variables:
变量1 (维度1, 维度2, 维度3) int32 3 4 12 2 9 5 14 9 7 2 10 12
变量2 (维度1, 维度2) int32 3 14 7 7
Attributes:
title: 我是 DataSet
嘿: 蛤
"""
删除一个变量则可以通过 drop_vars,但该方法不是原地操作,会返回一个新的 DataSet,这个 pandas 也是类似的。
print(ds.drop_vars(["变量1"]))
"""
<xarray.Dataset>
Dimensions: (维度1: 2, 维度2: 2, 维度3: 3)
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
* 维度3 (维度3) int32 3 4 5
Data variables:
变量2 (维度1, 维度2) int32 3 14 7 7
Attributes:
title: 我是 DataSet
嘿: 蛤
"""
print(ds.drop_vars(["变量1", "变量2"]))
"""
<xarray.Dataset>
Dimensions: (维度1: 2, 维度2: 2, 维度3: 3)
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
* 维度3 (维度3) int32 3 4 5
Data variables:
*empty*
Attributes:
title: 我是 DataSet
嘿: 蛤
"""
除了删除变量,我们也可以删除维度,注意:一旦删除了维度,那么使用该维度的变量也会一同被删除。
# 维度3 被 变量1 使用
print(ds.drop_dims(["维度3"]))
"""
<xarray.Dataset>
Dimensions: (维度1: 2, 维度2: 2)
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
Data variables:
变量2 (维度1, 维度2) int32 3 14 7 7
Attributes:
title: 我是 DataSet
嘿: 蛤
"""
# 维度1 被 变量1和变量2 使用
print(ds.drop_dims(["维度1"]))
"""
<xarray.Dataset>
Dimensions: (维度2: 2, 维度3: 3)
Coordinates:
* 维度2 (维度2) int32 2 3
* 维度3 (维度3) int32 3 4 5
Data variables:
*empty*
Attributes:
title: 我是 DataSet
嘿: 蛤
"""
当然啦,我们也可以修改数据,比如给某个变量对应的数组乘以 2。
# 除了通过 ds["xxx"] 的形式获取变量,还可以通过 ds.xxx 的方式
print(ds.assign(变量1=ds["变量1"] * 2))
"""
<xarray.Dataset>
Dimensions: (维度1: 2, 维度2: 2, 维度3: 3)
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
* 维度3 (维度3) int32 3 4 5
Data variables:
变量1 (维度1, 维度2, 维度3) int32 6 8 24 4 18 10 28 18 14 4 20 24
变量2 (维度1, 维度2) int32 3 14 7 7
Attributes:
title: 我是 DataSet
嘿: 蛤
"""
# 这里我们为了清晰,变量名用了中文,但工作中都是英文
# 另外,ds.assagn 会返回新的 DataSet
# 我们也可以直接本地修改
ds["变量1"] = ds["变量1"] * 2
# 对 ds["变量1"] 进行数值运算的时候会自动操作底层数组
# 甚至我们还可以像 numpy 一样使用
ds["变量1"] = np.clip(ds["变量1"], 4, 8)
print(ds)
"""
<xarray.Dataset>
Dimensions: (维度1: 2, 维度2: 2, 维度3: 3)
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
* 维度3 (维度3) int32 3 4 5
Data variables:
变量1 (维度1, 维度2, 维度3) int32 4 4 8 4 8 4 8 8 6 4 8 8
变量2 (维度1, 维度2) int32 3 14 7 7
Attributes:
title: 我是 DataSet
嘿: 蛤
"""
# 调用方法也是可以的
print(ds["变量1"].astype("float64"))
就我个人而言,还是更喜欢获取 ds["变量1"].values,也就是 ndarray,之后进行操作。
甚至我们还可以给变量重命名:
print(ds.rename({"变量1": "var1"}))
"""
<xarray.Dataset>
Dimensions: (维度1: 2, 维度2: 2, 维度3: 3)
Coordinates:
* 维度1 (维度1) int32 1 2
* 维度2 (维度2) int32 2 3
* 维度3 (维度3) int32 3 4 5
Data variables:
var1 (维度1, 维度2, 维度3) int32 4 4 8 4 8 4 8 8 6 4 8 8
变量2 (维度1, 维度2) int32 3 14 7 7
Attributes:
title: 我是 DataSet
嘿: 蛤
"""
数据的索引和选择
和 Numpy 和 pandas 一样,xarray 也提供了非常灵活索引选择, 来对数据进行筛选。下面我们就来分别介绍:
import numpy as np
from xarray import DataArray
data = np.random.randint(1, 100, size=(4, 3))
array = DataArray(data, coords={"x": [1, 2, 3, 4], "y": [11, 22, 33]})
print(array)
"""
<xarray.DataArray (x: 4, y: 3)>
array([[32, 1, 70],
[20, 51, 16],
[71, 68, 43],
[36, 64, 92]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22 33
"""
print(array[0, 0])
"""
<xarray.DataArray ()>
array(32)
Coordinates:
x int32 1
y int32 11
"""
print(array[:, [2, 1]])
"""
<xarray.DataArray (x: 4, y: 2)>
array([[70, 1],
[16, 51],
[43, 68],
[92, 64]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 33 22
"""
以上是通过索引对 DataArray 对象进行选择,过程和 Numpy 的 ndarray 是类似的,并且属性在索引操作中会被持久化。也就是每一次索引操作,都会返回新的 DataArray,其属性和原来 DataArray 的属性互不影响。
除了通过索引进行选择,还可以按照维度进行选择,通过 .loc 语法。
import numpy as np
from xarray import DataArray
data = np.random.randint(1, 100, size=(4, 3))
array = DataArray(data, coords={"x": [1, 2, 3, 4], "y": [11, 22, 33]})
print(array)
"""
<xarray.DataArray (x: 4, y: 3)>
array([[81, 61, 30],
[98, 68, 12],
[71, 75, 58],
[43, 93, 93]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22 33
"""
# 有 x、y 两个维度
# 我们想获取 x 维度坐标为 2、y 维度坐标为 22 和 33 组成的 DataArray 该怎么做呢?
print(array.loc[2, [22, 33]])
"""
<xarray.DataArray (y: 2)>
array([68, 12])
Coordinates:
x int32 2
* y (y) int32 22 33
"""
如果有更多的维度,那么还是按照上面的方式,所以 xarray 和 pandas 比较类似,相当于多维的 DataFrame。如果是 array[],那么表示通过索引筛选;如果是 array.loc[],那么表示通过维度筛选。
另外,我们也是可以修改元素的,举个栗子:
import numpy as np
from xarray import DataArray
data = np.random.randint(1, 100, size=(4, 3))
array = DataArray(data, coords={"x": [1, 2, 3, 4], "y": [11, 22, 33]})
print(array)
"""
<xarray.DataArray (x: 4, y: 3)>
array([[41, 23, 7],
[64, 68, 56],
[70, 33, 96],
[90, 97, 16]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22 33
"""
# 有 x、y 两个维度
# 我们想获取 x 维度坐标为 2、y 维度坐标为 22 和 33 组成的 DataArray 该怎么做呢?
array.loc[[3, 4], [33]] = 666
print(array)
"""
<xarray.DataArray (x: 4, y: 3)>
array([[ 41, 23, 7],
[ 64, 68, 56],
[ 70, 33, 666],
[ 90, 97, 666]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22 33
"""
使用维度名进行选择
我们上面是通过维度坐标进行选择的,它和某个维度的具体坐标值有关。
import numpy as np
from xarray import DataArray
data = np.random.randint(1, 100, size=(4, 3))
array = DataArray(data, coords={"x": [1, 2, 3, 4], "y": [11, 22, 33]})
print(array)
"""
<xarray.DataArray (x: 4, y: 3)>
array([[89, 12, 74],
[82, 84, 81],
[41, 30, 11],
[ 5, 21, 78]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22 33
"""
# y 的坐标是 [11, 22, 33],所以筛选前两个是 [11: 22]
print(array.loc[:, 11: 22])
"""
<xarray.DataArray (x: 4, y: 2)>
array([[89, 12],
[82, 84],
[41, 30],
[ 5, 21]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22
"""
但如果我们希望在筛选的时候不参考维度的坐标,就是单纯的按照顺序筛选该怎么做呢?
import numpy as np
from xarray import DataArray
data = np.random.randint(1, 100, size=(4, 3))
array = DataArray(data, coords={"x": [1, 2, 3, 4], "y": [11, 22, 33]})
print(array)
"""
<xarray.DataArray (x: 4, y: 3)>
array([[70, 79, 95],
[83, 55, 70],
[88, 41, 33],
[ 5, 57, 23]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22 33
"""
# 参数名是维度名,值是切片,表示范围
# 没有指定的表示全部筛选
# 所以筛选 x 维度(跨度为 2),筛选 y 维度的前 1 个
print(array.isel(x=slice(0, None, 2), y=slice(0, 1)))
"""
<xarray.DataArray (x: 2, y: 1)>
array([[70],
[88]])
Coordinates:
* x (x) int32 1 3
* y (y) int32 11
"""
# 除了 isel 之外,还有 sel,此时和 array.loc 是等价的,并且包含切片的结尾
# x 维度全部筛选,y 维度筛选维度坐标从 11 到 22 之间的,这个是维度的值,不再是索引,因为函数是 sel,不是 isel
print(array.sel(y=slice(11, 22)))
"""
<xarray.DataArray (x: 4, y: 2)>
array([[70, 79],
[83, 55],
[88, 41],
[ 5, 57]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22
"""
最近邻查找
我们在查找的时候允许不精确的查找,什么意思呢?
import numpy as np
from xarray import DataArray
data = np.random.randint(1, 100, size=(4, 3))
array = DataArray(data, coords={"x": [1, 2, 3, 4], "y": [11, 22, 33]})
print(array)
"""
<xarray.DataArray (x: 4, y: 3)>
array([[ 1, 93, 68],
[61, 59, 25],
[73, 70, 92],
[58, 21, 40]])
Coordinates:
* x (x) int32 1 2 3 4
* y (y) int32 11 22 33
"""
# 这里是非精确查找,等价于 x[1, 2],注意不是 [1, 3]
print(array.sel(x=[1.1, 2.8], method="nearest"))
"""
<xarray.DataArray (x: 2, y: 3)>
array([[ 1, 93, 68],
[73, 70, 92]])
Coordinates:
* x (x) int32 1 3
* y (y) int32 11 22 33
"""
为什么要有这个方法,想象一下我们手机上关于天气的APP,我们可以查看任意一个地方的天气,那么这些数据是怎么计算出来的呢?很明显,找一个距离最近的自动站(该地方的数据是准确的),然后推出来的。
未完待续
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号