详解 Go 的并发原语 sync.RWMutex,使用读写锁替换互斥锁增加并发量
楔子
上一篇文章我们花了很大的笔墨介绍了 Mutex,这是完全值得的,因为它是最基础的并发原语,也是 sync 包的基石,甚至其它的一些并发原语也是基于它实现的。但是使用 Mutex 是一个代价比较昂贵的操作,因为不管是读还是写,我们都通过 Mutex 来保证只有一个 goroutine 访问共享资源,这在某些情况下有点 "浪费"。比如在写少读多的情况下,即使一段时间内没有写操作,大量并发的读访问也不得不在 Mutex 的保护下变成了串行访问,这个时候使用 Mutex,对性能的影响就比较大。
显然我们可以区分读写操作,如果某个读操作的 goroutine 持有了锁,在这种情况下,其它读操作的 goroutine 就不必一直傻傻地等待了,而是可以并发地访问共享变量,这样我们就可以将串行的读变成并行读,提高读操作的性能,因为读操作不涉及数据的修改。但是当写操作的 goroutine 持有锁的时候,那么该锁就是一个排他锁,其它的写操作和读操作的 goroutine,需要阻塞等待,直到持有这个锁的 goroutine 释放锁。
而 RWMutex 就是专门实现这一功能的,下面来介绍一下 RWMutex 的实现原理以及使用场景。
什么是 RWMutex
RWMutex 是一个读写锁,在某一时刻可以由任意数量的 reader 持有,或者只被单个 writer 持有。而它的方法要比 Mutex 多几个:
Lock/Unlock:Lock 表示施加写锁,如果某个 goroutine 施加了写锁,那么其它 goroutine 再加锁时都会阻塞(无论是读锁还是写锁),Unlock 表示释放写锁。因此对于 Lock/Unlock 方法,Mutex 和 RWMutex 是等价的RLock/RUnlock:RLock 表示施加读锁,如果某个 goroutine 施加了读锁,那么其它 goroutine 加写锁时会阻塞,加读锁会成功,RUnlock 表示释放读锁RLocker:这个方法的作用是为读操作返回一个 Locker 接口的对象。它的 Lock 方法会调用 RWMutex 的 RLock 方法,它的 Unlock 方法会调用 RWMutex 的 RUnlock 方法。因此它和直接调用 RMMutex 的 Lock 和 ULock 是等价的
举个栗子:
package main
import (
"sync"
"time"
)
func main() {
var m sync.RWMutex
go func() {
m.Lock()
}()
time.Sleep(time.Second)
m.RLock()
}
上面这段程序是会出现死锁的,因为在子协程中施加了写锁,但是没有释放,所以主协程再施加锁的时候就会阻塞,最终出现死锁。
下面这段程序也是会出现死锁的:
func main() {
var m sync.RWMutex
go func() {
m.RLock()
}()
time.Sleep(time.Second)
m.Lock()
}
因为子协程施加了读锁,但是没有释放。而我们说在施加了读锁之后,如果再施加写锁的话,也会阻塞。所以我们可以将程序改一下:
package main
import (
"sync"
"time"
)
func main() {
var m sync.RWMutex
go func() {
m.RLock()
}()
time.Sleep(time.Second)
m.RLock()
}
此时是没有任何问题的,因为子协程和主协程施加的都是读锁,读锁的话不会阻塞,因此不会出现死锁。所以如果是写操作,那么就使用 Lock 施加写锁,此时临界区被独占。如果是读操作,那么就使用 RLock 施加读锁,读锁可以施加多个,可以支持多个 goroutine 共享临界区,但是不能施加写锁,在施加了读锁的情况下再施加写锁一样会阻塞。
注意:调用 Lock 施加写锁,那么要调用 Unlock 释放写锁;调用 RLock 表示施加读锁,那么要调用 RUnlock 释放读锁,所以加锁和解锁使用的方法要配对。
那什么时候使用读写锁呢?很明显,读写锁主要应用在读多写少的场景,举个栗子:
package main
import (
"sync"
"time"
)
type Counter struct {
sync.RWMutex
count uint64
}
func (c *Counter) Incr() {
// 因为这里是修改数据,所以要施加写锁
c.Lock()
defer c.Unlock()
c.count++
}
func (c *Counter) Count() uint64 {
// 读取数据,施加读锁,提高并发量
c.RLock()
defer c.RUnlock()
return c.count
}
func main() {
var counter Counter
for i := 0; i < 10; i++ {
// 开启 10 个 goroutine,负责读操作,每次循环耗时 1 毫秒
go func() {
for {
counter.Count()
time.Sleep(time.Millisecond)
}
}()
}
for {
// 开启一个 goroutine,负责写操作,每次循环耗时 1 秒
counter.Incr()
time.Sleep(time.Second)
}
}
可以看到,Incr 方法会修改计数器的值,是一个写操作,我们使用 Lock/Unlock 进行保护。Count 方法会读取当前计数器的值,是一个读操作,我们使用 RLock/RUnlock 方法进行保护。
Incr 方法被调用时会施加写锁,此时它会独占临界区,其它的 goroutine 既不能施加写锁、也不能施加读锁,因此保证了数据的安全。但 Incr 方法是每秒才调用一次,所以该 goroutine 竞争锁的频率是比较低的,因为执行读操作的 10 个 goroutine 每毫秒就要执行一次。所以我们除了要保证写操作是安全的之外,还要保证在没有写操作的时候读操作能够是并发的,这样可以极大地提升性能,而读写锁就是专门为这种场景设计的。因为在读取的时候,可以并发进行,如果使用 Mutex,性能就不会像读写锁这么好,因为使用互斥锁会导致读也要排队。
所以如果你遇到可以明确区分读写场景,确实有大量的并发读、少量的并发写,并且有强烈的性能需求,你就可以考虑使用读写锁 RWMutex 替换互斥锁 Mutex。
RWMutex 的实现原理
RWMutex 是很常见的并发原语,很多编程语言的库都提供了类似的并发类型。RWMutex 一般都是基于互斥锁、条件变量(condition variables)或者信号量(semaphores)等并发原语来实现,Go 的 RWMutex 就是基于 Mutex 实现的。
而基于对读和写操作的优先级,读写锁的设计和实现也分成三类。
- Read-preferring:读优先,当读锁和写锁都可以获取时优先获取读锁。该设计可以提供很高的并发性,但是在竞争激烈的情况下可能会导致写饥饿。这是因为如果有大量的读,这种设计会导致只有在所有的读锁都释放了,写锁才可能被获取到。
- Write-preferring:写优先,当读锁和写锁都可以获取时优先获取写锁。当然,如果有一些 goroutine 已经获取了读锁,那么获取写锁的 goroutine 也必须要等待已经存在的读锁都被释放之后才可以获取。所以写优先级设计中的优先权是针对新来的读请求而言的,这种设计主要避免了写锁的饥饿问题。
- 不指定优先级:这种设计比较简单,不区分读锁和写锁的优先级,某些场景下这种不指定优先级的设计反而更有效。因为第一类优先级会导致写饥饿,第二类优先级可能会导致读饥饿,这种不指定优先级的访问不再区分读写,大家都是同一个优先级,有时反而解决了饥饿的问题。
Go 标准库 sync 中的 RWMutex 设计是 Write-preferring 方案,下面来分看一下底层结构。
type RWMutex struct {
// 获取写锁的 goroutine 称之为 writer,获取读锁的 goroutine 称之为 reader
w Mutex // 互斥锁,通过互斥锁实现写锁的互斥
writerSem uint32 // writer 信号量
readerSem uint32 // reader 信号量
readerCount int32 // reader 的数量
readWait int32 // writer 想要成功获取到写锁需要释放的读锁的数量,因为写锁要等到已存在的读锁释放之后才能获取
// 假设 writer 在获取写锁时,发现有 3 个 reader 获取到了读锁,那么 readWait 就是 3
}
const rwmutexMaxReaders = 1 << 30 // reader 的最大数量
RWMutex 包含一个 Mutex,以及四个辅助字段 writerSem、readerSem、readerCount 和 readerWait。以上就是 RWMutex 的结构体定义,下面来看看相关方法的实现。
RLock 和 RUnlock
首先是 RLock 和 RUnlock,代码有删减,只保留最核心的部分。
func (rw *RWMutex) RLock() {
if atomic.AddInt32(&rw.readerCount, 1) < 0 {
/* 可能你会感到好奇,readCount 表示 reader 的数量,为啥加 1 之后还可能小于 0 呢
* 因为 readCount 这个字段其实有双重含义
* 1. 如果没有 writer 竞争写锁、或持有写锁时,readerCount 和我们理解的 reader 数量是一样的
* 2. 但是当有 writer 竞争写锁或者持有写锁时,它的值就是一个负数,表示当前存在 writer 在竞争锁或持有锁
而 writer 优先,那么会进入阻塞状态
*/
runtime_SemacquireMutex(&rw.readerSem, false, 0)
}
}
func (rw *RWMutex) RUnlock() {
/* 调用 RUnlock 的时候,我们需要将 reader 的数量减 1,因为 reader 的数量少了一个
* 但我们说 readerCount 还表示是否有 writer 在竞争锁,因此如果 r 小于 0,那么说明确实有 writer 在竞争
* 这种情况下,会调用 rUnlockSlow 方法,检查是不是 reader 都释放读锁了
* 如果读锁都释放了,那么可以唤醒请求写锁的 writer 了
*/
if r := atomic.AddInt32(&rw.readerCount, -1); r < 0 {
rw.rUnlockSlow(r)
}
}
func (rw *RWMutex) rUnlockSlow(rint32) {
if atomic.AddInt32(&rw.readerWait, -1) == 0 {
/* 当一个或者多个 reader 持有锁的时候,那么必须等所有的 reader 将读锁全部释放之后才能唤醒 writer
* 打个比方,在房地产行业中有条规矩叫做"买卖不破租赁",
* 意思是说,就算房东把房子卖了,新业主也不能把当前的租户赶走,而是要等到租约结束后,才能接管房子
* 这和 RWMutex 的设计是一样的
* 当 writer 请求锁的时候,不会强制这些已获取锁的 reader 释放锁,它的优先权只是限定后来的 reader 不要和它抢
* 所以,rUnlockSlow 将持有锁的 reader 计数减少 1 的时候,会检查既有的 reader 是不是都已经释放了锁
* 如果都释放了锁,就会唤醒 writer,让 writer 持有锁
*/
runtime_Semrelease(&rw.writerSem, false, 1)
}
}
以上是读写锁的方法。
Lock 和 Unlock
但是当施加写锁时,就必须要保证互斥了。
一旦一个 writer 获得了内部的互斥锁,就会反转 readerCount 字段,把它从原来的正整数 readerCount 修改为负数(readerCount 减去 rwmutexMaxReaders),让这个字段保持两个含义(既保存了 reader 的数量,又表示当前有 writer)。
func (rw *RWMutex) Lock() {
// 这里使用的是 Mutex 的 Lock,解决了其它 writer 竞争问题
rw.w.Lock()
// 反转 readerCount,告诉 reader 有 writer 竞争锁
r := atomic.AddInt32(&rw.readerCount, -rwmutexMaxReaders) + rwmutexMaxRead
// 如果当前有 reader 持有锁,那么需要等待,并且要将 readerCount 赋值给 readerWait 保存起来
// 然后每当一个 reader 释放读锁的时候,readWait 字段的值就减一
// 直到所有的活跃的 reader 都释放了读锁,才会唤醒这个 writer
if r != 0 && atomic.AddInt32(&rw.readerWait, r) != 0 {
runtime_SemacquireMutex(&rw.writerSem, false, 0)
}
}
然后是释放写锁:
func (rw *RWMutex) Unlock() {
/* 当一个 writer 释放锁的时候,它会再次反转 readerCount 字段,可以肯定的是,因为当前锁由 writer 持有
* 所以 readerCount 字段是反转过的,并且减去了 rwmutexMaxReaders 这个常数,变成了负数
* 因此这里的反转方法就是给它增加 rwmutexMaxReaders 这个常数值,也就是告诉 reader 没有活跃的 writer 了
*/
r := atomic.AddInt32(&rw.readerCount, rwmutexMaxReaders)
// 唤醒阻塞的 reader
for i := 0; i < int(r); i++ {
runtime_Semrelease(&rw.readerSem, false, 0)
}
// 最后释放写锁,释放内部的互斥锁
rw.w.Unlock()
}
上述代码中,都删除了 race 的处理和异常情况的检查,总体看来还是比较简单的。但是有几个重点,首先是要理解 readerCount 这个字段的含义以及反转方式,其次还要注意字段的更改和内部互斥锁的顺序关系。在 Lock 方法中,是先获取内部互斥锁,再修改其它字段;而在 Unlock 方法中,是先修改其它字段,再释放内部互斥锁,这样才能保证字段的修改也受到互斥锁的保护。
以上就是 RWMutex 的概念和实现原理,虽然内部结构比较复杂(锁方面的内容还是不简单的),但是使用起来很简单。并且 RWMutex 的使用场景很明确,就是负责解决 Mutex 在读多写少场景下的并发效率问题。
RWMutex 的 3 个踩坑点
RWMutex 和 Mutex 一样,虽然使用起来很简单,但有时不小心也会踩到坑里面。因为知名的开源项目中,同样犯过 RWMutex 相关的错误。
锁被复制
前面刚刚说过,RWMutex 是由一个互斥锁和四个辅助字段组成的。我们很容易想到,因为互斥锁是不可复制的,再加上四个有状态的字段,RWMutex 就更加不能复制使用了。不能复制的原因和互斥锁一样,因为复制之后就是两把不同的锁了。并且我们说 Go 只有值传递,所以如果将互斥锁传递到函数或方法中,那么只能传递指针。
重入导致的死锁
读写锁因为重入(或递归调用)导致死锁的情况更多。
第一种情况,因为读写锁内部基于互斥锁实现对 writer 的并发访问,而互斥锁本身是有重入问题的,所以 writer 重入调用 Lock 的时候,就会出现死锁的现象,这个问题我们之前在介绍 Mutex 的时候就已经演示过了。
第二种情况,就是同一个 goroutine 即施加了写锁、又施加了读锁。
package main
import "sync"
func main() {
var m sync.RWMutex
m.RLock()
m.Lock()
}
很明显这段程序会出现死锁,会阻塞在 m.Lock() 这一步。
然后是第三种情况,和第二种情况类似,但是更隐蔽一些。当一个 writer 请求锁的时候,如果已经有一些活跃的 reader,它会等待这些活跃的 reader 完成,才有可能获取到锁。但如果这些活跃的 reader 再依赖新的 reader 的话,这些新的 reader 就会等待 writer 释放锁之后才能继续执行(因为 Go 的 RWMutex 是写优先),所以此时又会出现死循环:
writer 依赖活跃的 reader -> 活跃的 reader 依赖新来的 reader -> 新来的 reader 依赖 writer
这个死锁发生的相当隐蔽,原因在于它和 RWMutex 的设计有关,我们举个栗子:
package main
import (
"fmt"
"sync"
"time"
)
// 递归调用计算阶乘
func factorial(m *sync.RWMutex, n int) int {
if n < 1 {
return 0
} else if n == 1 {
return 1
}
fmt.Println("RLock")
// 施加读锁
m.RLock()
defer func() {
// 释放读锁
fmt.Println("RUnlock")
m.RUnlock()
}()
time.Sleep(100 * time.Millisecond)
return factorial(m, n-1) * n // 递归调用
}
func main() {
var m sync.RWMutex
go func() {
factorial(&m, 10) // 计算 10 的阶乘, 10!
}()
// writer 稍微等待,然后制造一个调用 Lock 的场景
go func() {
time.Sleep(200 * time.Millisecond)
m.Lock()
fmt.Println("Lock")
time.Sleep(100 * time.Millisecond)
m.Unlock()
fmt.Println("Unlock")
}()
// 主协程阻塞在这里
for {}
}
首先调用 factorial 的子协程会获取读锁,然后另一个子协程获取写锁,为了确保写锁后获取,这里 sleep 200 毫秒。另外在 factorial 里面有 sleep 100 毫秒的逻辑,并且递归会调用 10 层,所以最后的结果就是先获取读锁,然后递归调用个大概两层,然后在另一个子协程中获取写锁。
于是问题来了,writer 想获取锁,那么必须等到所有的 reader 释放锁,而在 writer 之前的 reader 只有前两层递归中的 reader。因为是写优先,后面八层递归中的 reader 的不会和它抢。但问题是前两层递归中的 reader 依赖后面的 reader,因为释放锁的逻辑写在 defer 中。所以 writer 想获取锁需要前两个 reader 释放锁,前两个 reader 想释放锁,需要后八个 reader 先获取锁,然后再从内而外一层一层释放,但后面八个 reader 想获取锁,需要 writer 先获取锁,因此便出现了死循环。
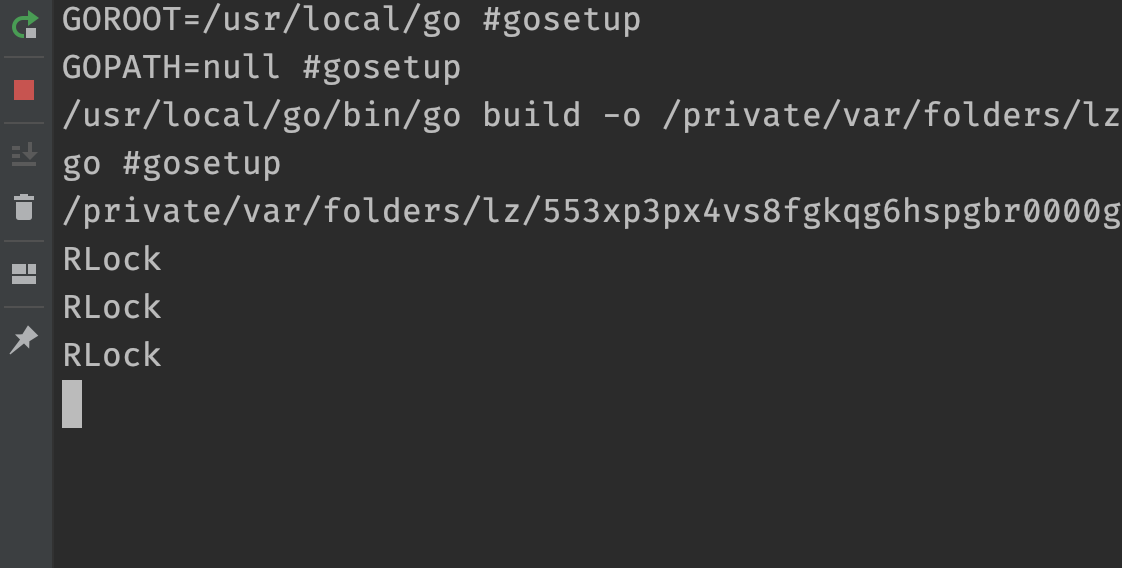
我们看到执行第三次递归时,两个子协程便发生了锁之间的冲突,互不退让,最终谁也无法执行。所以,使用读写锁最需要注意的一点就是尽量避免重入,重入带来的死锁非常隐蔽,而且难以诊断。
释放未加锁的 RWMutex
这一点其实之前提到了,和互斥锁一样,Lock 和 Unlock 的调用总是成对出现的,RLock 和 RUnlock 的调用也必须成对出现。Lock 和 RLock 多余的调用会导致锁没有被释放,可能会出现死锁,而 Unlock 和 RUnlock 多余的调用会导致 panic。
RWMutex 总结
在开发过程中,一开始考虑共享资源并发访问问题的时候,我们就会想到互斥锁 Mutex。因为刚开始的时候,我们还并不太了解并发的情况,所以就会使用最简单的同步原语来解决问题。等到系统成熟,真正到了需要性能优化的时候,我们就能静下心来分析并发场景的可能性,这个时候我们就要考虑是否可以将 Mutex 修改为 RWMutex,来压榨系统的性能。
当然,如果一开始你的场景就非常明确了,比如我就要实现一个线程安全的 map,那么一开始你就可以考虑使用读写锁。正如之前说的,如果你能意识到你要解决的问题是使用 Mutex 时的效率问题、并且读多写少,那么你直接就可以毫不犹豫地选择 RWMutex,不用考虑其它选择。但是在使用 RWMutex 时,最需要注意的一点就是尽量避免重入,重入带来的死锁非常隐蔽,而且难以诊断。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号