详解 Go 语言实现高并发的基石:goroutine
楔子
这次我们说一说 Go 的并发编程,并发可以说是 Go 语言的一个最大的卖点,因为它在语言层面上就支持并发,而且使用方式非常简单。
在早期,CPU 都是以单核的形式顺序执行机器指令,Go 语言的祖先 C 语言正是这种顺序编程语言的代表。顺序编程语言中的顺序是指:所有的指令都以串行的方式执行,在相同的时刻有且仅有一个 CPU 在顺序执行程序的指令。
但随着处理器技术的发展,在单核时代通过提升处理器频率来提高运行效率的方式遇到了瓶颈,目前各种主流的 CPU 频率基本被锁定在了 3GHZ 附近。单核 CPU 发展的停滞,给多核 CPU 的发展带来了机遇。相应地,编程语言也开始逐步向并行化的方向发展,而 Go 语言正是在多核和网络化的时代背景下诞生的原生支持并发的编程语言。
并发与并行
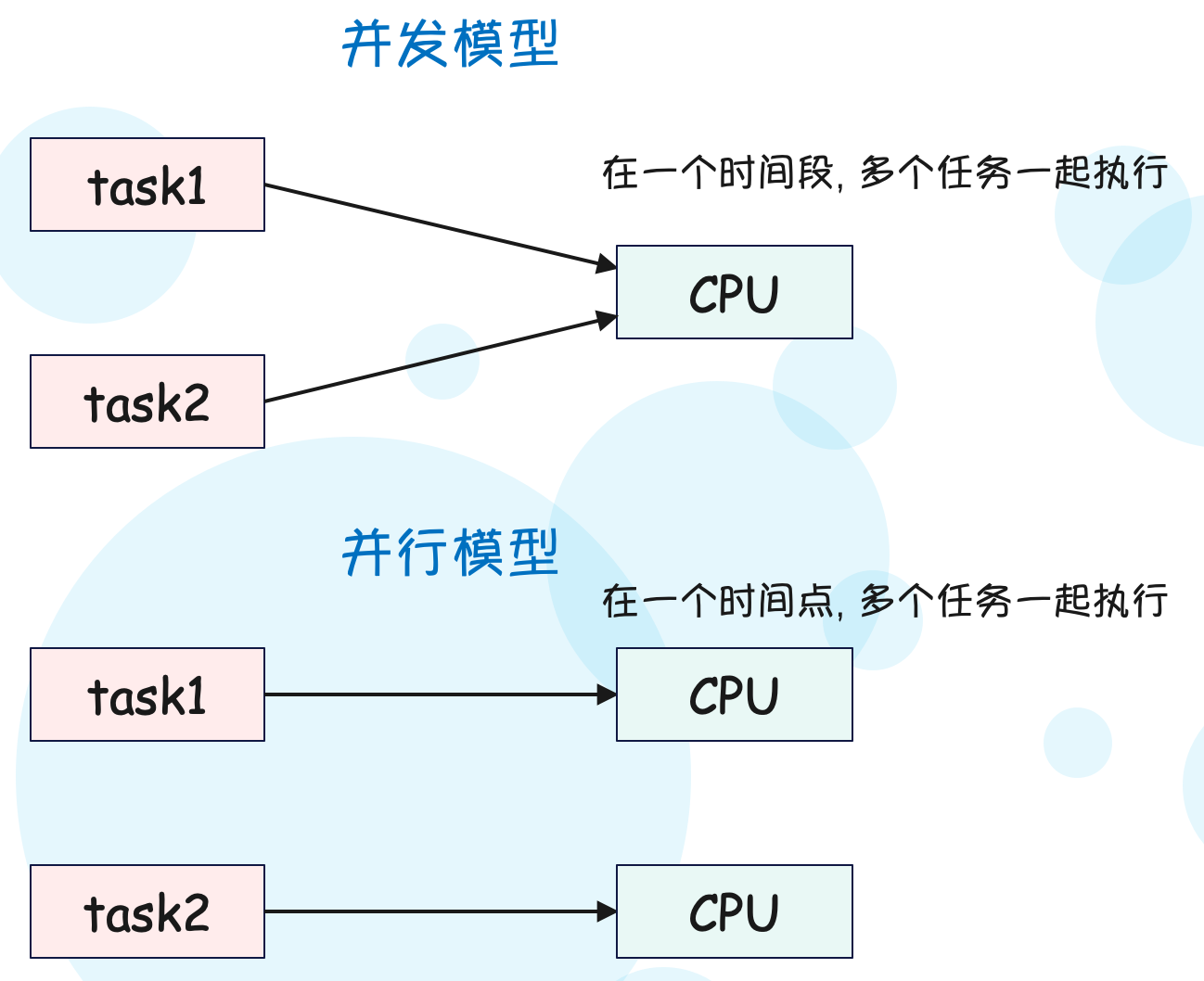
关于并发和并行的区别:
并行: 在一个时间点可以执行多个任务并发: 在一个时间段可以执行多个任务
而受限于 CPU 处理器的核心数,显然不可能对所有任务都执行并行操作,所以我们经常听到的是"高并发",而不是"高并行"。因为"高并行"只能通过硬件方面实现,而"高并发"是可以通过代码层面解决的。
常见的并行编程有多种模型,主要有多线程、消息传递等。从理论上来看,多线程和基于消息的并发编程是等价的。由于多线程并发模型可以自然对应到多核的处理器,主流的操作系统因此也就提供了系统级的多线程支持,同时从概念上讲多线程似乎也更直观,因此多线程编程模型逐步被吸纳到主流的编程语言特性或语言扩展库中。
而主流编程语言对基于消息的并发编程模型支持则相对较少,Erlang 语言是支持该模型的代表者,但它的并发体之间不共享内存。而 Go 语言是基于消息的并发模型的集大成者,它将基于 CSP 模型的并发编程内置到了语言中,通过一个 go 关键字就可以轻易地启动一个 goroutine,与 Erlang 不同的是 Go 语言的 goroutine 之间是共享内存的。
goroutine 和系统线程
goroutine 是 Go 语言特有的并发体,是一种轻量级的线程(或者理解为协程),由 go 关键字启动。在真实的 Go 语言的实现中,goroutine 和系统线程也不是等价的。尽管两者的区别实际上只是一个量的区别,但正是这个量变引发了 Go 语言并发编程质的飞跃。
首先,每个系统级线程都会有一个固定大小的栈(一般默认可能是 2MB),这个栈主要用来保存函数调用时的参数和局部变量。固定了栈的大小会导致两个问题:一是对于很多只需要很小的栈空间的线程来说是一个巨大的浪费,二是对于少数需要巨大栈空间的线程来说又面临栈溢出的风险。针对这两个问题的解决方案是:要么降低固定的栈大小,提升空间的利用率;要么增大栈的大小以允许更深的函数递归调用,但这两者是没法同时兼得的。
相反,一个 goroutine 会以一个很小的栈启动(可能是 2KB 或 4KB),当遇到深度递归导致当前栈空间不足时,goroutine 会根据需要动态地伸缩栈的大小(主流实现中栈的最大值可达到 1GB)。因为启动的代价很小,所以我们可以轻易地启动成千上万个 goroutine。
Go 的运行时还包含了其自己的调度器,这个调度器使用了一些技术手段,可以在 n 个操作系统线程上调度 m 个 goroutine。Go 调度器的工作原理和内核的调度是相似的,但是这个调度器只关注单独的 Go 程序中的 goroutine。goroutine 采用的是半抢占式的协作调度,只有在当前 goroutine 发生阻塞时才会导致调度;同时发生在用户态,调度器会根据具体函数只保存必要的寄存器,切换的代价要比系统线程低得多。运行时有一个 runtime.GOMAXPROCS 函数,用于控制当前运行正常非阻塞 goroutine 的系统线程数目。
在 Go 语言中启动一个 goroutine 不仅和调用函数一样简单,而且 goroutine 之间调度代价也很低,这些因素极大地促进了并发编程的流行和发展。
创建 goroutine
下面我们来看看如何在 Go 中启动 goroutine。
package main
import (
"fmt"
)
func f(n int64) {
fmt.Println("f ->", n)
}
func main() {
// Go 语言中启动一个 goroutine 非常简单, 直接通过 go 关键字即可
// 注意: go 关键字后面必须跟一个函数调用才可以
go f(1)
go f(2)
go f(3)
// 上面三个函数都会启动一个单独的 goroutine 去执行
}
但是当我们执行这段程序时却发现什么都没有输出,原因是程序默认有一个主 goroutine,在启动三个子 goroutine 之后,程序就结束了。因此我们看到主 goroutine 是不会等待子 goroutine 的,如果想象成多线程的话,那么子 goroutine 就类似于守护线程。
因此我们可以让主线程强制等待一下:
package main
import (
"fmt"
"time"
)
func f(n int64) {
// 睡 n 秒
time.Sleep(time.Second * time.Duration(n))
fmt.Println("f ->", n)
}
func main() {
go f(3)
go f(1)
go f(2)
// 写一个死循环, 让主线程一直不结束
// 我们看到 go 里面死循环是不是特别简单呢? 因为 go 里面经常要用到死循环
for {}
/*
f -> 1
f -> 2
f -> 3
*/
}
通过程序输出结果,我们知道这几个函数在执行的时候都是并发执行的,谁先睡完,谁就先打印。三个 goroutine 执行完之后,总共花费了 3 秒钟,因为它们是由不同的 goroutine 执行的;如果不是通过 go 关键字启动,那么三个函数执行完之后,会总共花费六秒钟,而且是顺序打印的。
注意:在使用 goroutine 的时候,经常会不注意调到坑里面,举个例子。
package main
import (
"fmt"
)
func main() {
for i := 1; i <= 5; i++ {
go func() {
fmt.Printf("goroutine %d\n", i)
}()
}
for {}
/*
goroutine 6
goroutine 6
goroutine 6
goroutine 6
goroutine 6
*/
}
我们看到打印的结果和我们想象中的不一样啊,因为 goroutine 还没执行时,循环就结束了,此时 i 已经变成了 6。因此解决办法就是,在启动 goroutine 的时候指定好参数。
func main() {
for i := 1; i <= 5; i++ {
go func(i int) {
fmt.Printf("goroutine %d\n", i)
}(i)
}
for {}
/*
goroutine 2
goroutine 5
goroutine 1
goroutine 4
goroutine 3
*/
}
因为不知道哪个 goroutine 先执行完毕,所以打印的顺序是不固定的。
主 goroutine 和子 goroutine 的同步
由于主 goroutine 不会等待子 goroutine,所以我们采用一个死循环,但这样做显然是不科学的。要是循环下面还有代码呢,我们希望某一段代码一定要等到当前子 goroutine 执行完之后才可以执行,这个时候使用死循环显然是不行的。如果采用 time.Sleep 的话显然也是不推荐的,因为不知道子 goroutine 什么时候执行完毕。
这个时候,我们就需要通过"等待组"的方式来实现:
package main
import (
"fmt"
"sync"
)
func f(wg *sync.WaitGroup, n int) {
wg.Done()
fmt.Printf("goroutine %d\n", n)
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
// "等待组" 内部有一个计数器, 调用 Add 方法让计数器增加, 增加的值等于传入的值
// 每启动一个 goroutine, 就将计数器加 1
wg.Add(1)
// 因为 "等待组" 本质是一个结构体, 所以需要传递指针, 不然就会拷贝一份
go f(&wg, i)
// 在函数 f 的内部, 我们调用了 wg.Done(), 这个方法会使得 "等待组" 内部的计数器减一
}
// 如果 "等待组" 内部的计数器不为 0, 那么调用 Wait() 会一直阻塞在这里; 如果为 0, 那么会顺利通行
wg.Wait()
fmt.Println("程序结束......")
/*
goroutine 5
goroutine 2
goroutine 1
goroutine 3
goroutine 4
程序结束......
*/
}
在使用 goroutine 的时候,一定要注意死锁的问题。
package main
import (
"fmt"
"sync"
)
func f(wg *sync.WaitGroup, n int) {
fmt.Printf("goroutine %d\n", n)
}
func main() {
var wg sync.WaitGroup
for i := 1; i <= 5; i++ {
wg.Add(1)
go f(&wg, i)
}
wg.Wait()
fmt.Println("程序结束......")
/*
goroutine 5
goroutine 2
goroutine 1
goroutine 3
goroutine 4
fatal error: all goroutines are asleep - deadlock!
*/
}
我们看到在 goroutine 执行完之后,就造成了死锁,原因就是在函数 f 中我们将 wg.Done() 这行代码给去掉了。当子 goroutine 结束之后,只剩下一个主 goroutine,而且 "等待组" 的计数器不为 0。
因为 wg.Wait() 处于阻塞状态,所以就需要有其它的子 goroutine 将 "等待组" 的计数器减少到 0,所以但凡还有一个子 goroutine,都不会报错,而且程序也是等 5 个子 goroutine 都执行完之后才报的错。而子 goroutine 都执行完之后,只剩下主 goroutine 了,而且"等待组" 的计数器还不为 0,这个时候就出现死锁了。
关于并发编程中容易出现的错误问题,我们后续会用单独的文章进行解释。
goroutine 之间的调度
在 runtime 包中存在三个函数,可以对 goroutine 进行调度。
- runtime.GOMAXPROCS(n):用来设置可以并行计算的 CPU 核数最大值,并返回之前的值。
- runtime.Gosched():让出 CPU 时间片(当前 goroutine 的执行权限),调度器安排其它等待的任务运行,并在下次某个时候从该位置恢复执行。这就像跑接力赛,A 跑了一会碰到代码 runtime.Gosched() 就把接力棒交给 B 了,A 歇着了,B 继续跑。
- runtime.Goexit(),调用此函数会立即中止当前的 goroutine,而其它的 goroutine 并不会受此影响。Goexit 在终止当前 goroutine 前会先执行此 goroutine 中还未执行的 defer 语句。另外注意千万别在主协程中调用 runtime.Goexit,因为会引发 panic。
package main
import (
"fmt"
"runtime"
)
func main() {
// 默认采用 CPU 的所有核心, 我们可以查看 CPU 的核心数
fmt.Println(runtime.NumCPU()) // 8
// 设置使用的 CPU 核心数, 如果值小于 1, 则采用默认配置
// 返回 8, 说明默认是跑满了所有的核
fmt.Println(runtime.GOMAXPROCS(0)) // 8
}
然后我们看看在 Go 中,如何主动交出一个 goroutine 的执行权。
package main
import (
"fmt"
"runtime"
"time"
)
func f1(){
runtime.Gosched() // 此处将执行权让出
fmt.Println("f1 -> 1")
// 将控制权让出
runtime.Gosched()
fmt.Println("f1 -> 2")
}
func f2(){
// 这里会是第一个打印
fmt.Println("f2 -> 1")
// 将控制权让出, 显然会执行 f1 的第一个打印语句
runtime.Gosched()
fmt.Println("f2 -> 2")
}
func main() {
go f1()
go f2()
time.Sleep(time.Second * 1)
/*
f2 -> 1
f1 -> 1
f2 -> 2
f1 -> 2
*/
// 打印的结果和我们想的是一样的, 首先打印: f2 -> 1, 然后交出执行权
// 再打印 f1 -> 1, 然后交出执行权打印 f2 -> 2, 最后打印 f1 -> 2
}
最后看看 goroutine 的主动退出:
package main
import (
"fmt"
"runtime"
"time"
)
func f1(){
fmt.Println("f1")
// 注意: 一旦函数内部出现了 Gosched 或者 Goexit
// 那么这个函数一定要出现在 goroutine 中
// 可以是在 main 函数中 go f1(), 也可以在其它函数中 go f1()
// 如果是直接通过 f1() 调用的话, 那么外层函数一定要通过 goroutine 的方式启动
runtime.Goexit()
}
func f2(){
f1()
fmt.Println("f2")
}
func f3(){
go f1()
fmt.Println("f3")
}
func main() {
// f2 里面调用了 f1, 但 f2 是通过 goroutine 启动的, 所以是合法的
// 并且会直接将整个 goroutine 停止掉, 因此 fmt.Println("f2") 没有执行
go f2()
time.Sleep(time.Second * 1)
/*
f1
*/
// f3 里面的 f1 函数是通过 goroutine 启动的, 因此 goroutine 里面又启动了一个 goroutine
// 而 Goexit 只会退出自身的 goroutine(最内层), 所以 fmt.Println("f3") 会被执行
go f3()
time.Sleep(time.Second * 1)
/*
f1
f3
*/
// 依旧退出自身的 goroutine, 跟外层无关
f3()
time.Sleep(time.Second * 1)
/*
f1
f3
*/
}
以上就是 goroutine 之间的调度,可以体会一下。
goroutine 中的 defer
再来看看 defer 在 goroutine 中是如何体现的。
package main
import (
"fmt"
)
func f1(){
defer fmt.Println("f1 defer")
fmt.Println("f1")
}
func main() {
// 首先执行 f1(), 因为是 f1() 不是 go f1()
// 所以 fmt.Println("func") 一定会在 f1() 执行完毕之后才会执行
// 所以输出是什么很好分析
go func() {
defer fmt.Println("func defer")
f1()
fmt.Println("func")
}()
/*
f1
f1 defer
func
func defer
*/
// 里面是 go f1(), 是 goroutine 里面启动一个 goroutine
// 因此这是两个 goroutine, 它们之间是没有关系的
go func() {
defer fmt.Println("func defer")
go f1()
fmt.Println("func")
}()
/*
f1
func
func defer
f1 defer
*/
for{}
}
如果里面出现了 return 呢?
package main
import (
"fmt"
)
func f1(){
defer fmt.Println("f1 defer")
return
fmt.Println("f1")
}
func main() {
go func() {
defer fmt.Println("func defer")
f1()
fmt.Println("func")
}()
/*
f1 defer
func
func defer
*/
go func() {
defer fmt.Println("func defer")
go f1()
fmt.Println("func")
}()
/*
func
f1 defer
func defer
*/
for{}
}
结果很简单,那么重点来了,如果我们把 return 换成 Goexit 呢?
package main
import (
"fmt"
"runtime"
)
func f1(){
defer fmt.Println("f1 defer")
runtime.Goexit() // goroutine 退出
fmt.Println("f1")
}
func main() {
// 在 f1 中将整个 goroutine 都给终止掉了, 因为是同一个 goroutine, 因此两个 fmt.Println 函数都不会执行
// 但是: 两个 defer 都会调用
go func() {
defer fmt.Println("func defer")
f1()
fmt.Println("func")
}()
/*
f1 defer
func defer
*/
// 这是两个独立的 goroutine, go f1() 对应的 goroutine 会被终止掉
// 但是匿名函数对应的 goroutine 则不会
go func() {
defer fmt.Println("func defer")
go f1()
fmt.Println("func")
}()
/*
func
func defer
f1 defer
*/
for{}
}
关于协程的基础内容就介绍到这里,可能有人好奇返回值要怎么办?通过 goroutine 执行完毕之后函数的返回值要怎么获取呢?答案是通过 channel,关于 channel 后续再说,我们来剖析一下 goroutine 是怎么实现的。
Go 协程的底层结构
我们通过 go 关键字启动一个协程之后,编译器在底层会创建一个结构体 g,没错,协程在底层也是一个结构体。
type g struct {
// goroutine 使用的栈
stack stack
// 用于栈的扩张和收缩检查,抢占标志
stackguard0 uintptr
stackguard1 uintptr
_panic *_panic
_defer *_defer
// 当前与 g 绑定的 m,因为每个 goroutine 都对应一个工作线程
m *m
// goroutine 的运行现场
sched gobuf
syscallsp uintptr
syscallpc uintptr
stktopsp uintptr
// wakeup 时传入的参数
param unsafe.Pointer
// 协程的状态
atomicstatus uint32
stackLock uint32
// goroutine 的 id
goid int64
// 指向全局队列里下一个 g
schedlink guintptr
// g 被阻塞之后的近似时间
waitsince int64
// g 被阻塞的原因
waitreason waitReason
preempt bool
preemptStop bool
preemptShrink bool
asyncSafePoint bool
paniconfault bool
gcscandone bool
throwsplit bool
activeStackChans bool
parkingOnChan uint8
raceignore int8
sysblocktraced bool
tracking bool
trackingSeq uint8
runnableStamp int64
runnableTime int64
sysexitticks int64
traceseq uint64
tracelastp puintptr
lockedm muintptr
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
gopc uintptr
ancestors *[]ancestorInfo
startpc uintptr
racectx uintptr
waiting *sudog
cgoCtxt []uintptr
labels unsafe.Pointer
timer *timer
selectDone uint32
goroutineProfiled goroutineProfileStateHolder
gcAssistBytes int64
}
里面的字段非常多,我们先看其中的两个:
stack:类型为 stack,表示 goroutine 运行时的栈;sched:类型为 gobuf,goroutine 在运行时光有栈还不够,还必须包含 PC、SP 等寄存器;
type stack struct {
// 栈的低地址
lo uintptr
// 栈的高地址
hi uintptr
}
type gobuf struct {
// 栈指针,指向程序正在执行的指令
sp uintptr
// 程序计数器,标示程序执行到了哪一行
pc uintptr
g guintptr
ctxt unsafe.Pointer
ret uintptr
lr uintptr
bp uintptr // for framepointer-enabled architectures
}
然后我们用一段代码,来解释一下这些底层结构:
func f3() {fmt.Println("Hello")}
func f2() {f3()}
func f1() {f2()}
func main() {
go f1()
for {}
}
通过 go f1() 开启一个协程,我们假定协程执行到了 f3() 函数里的打印语句。
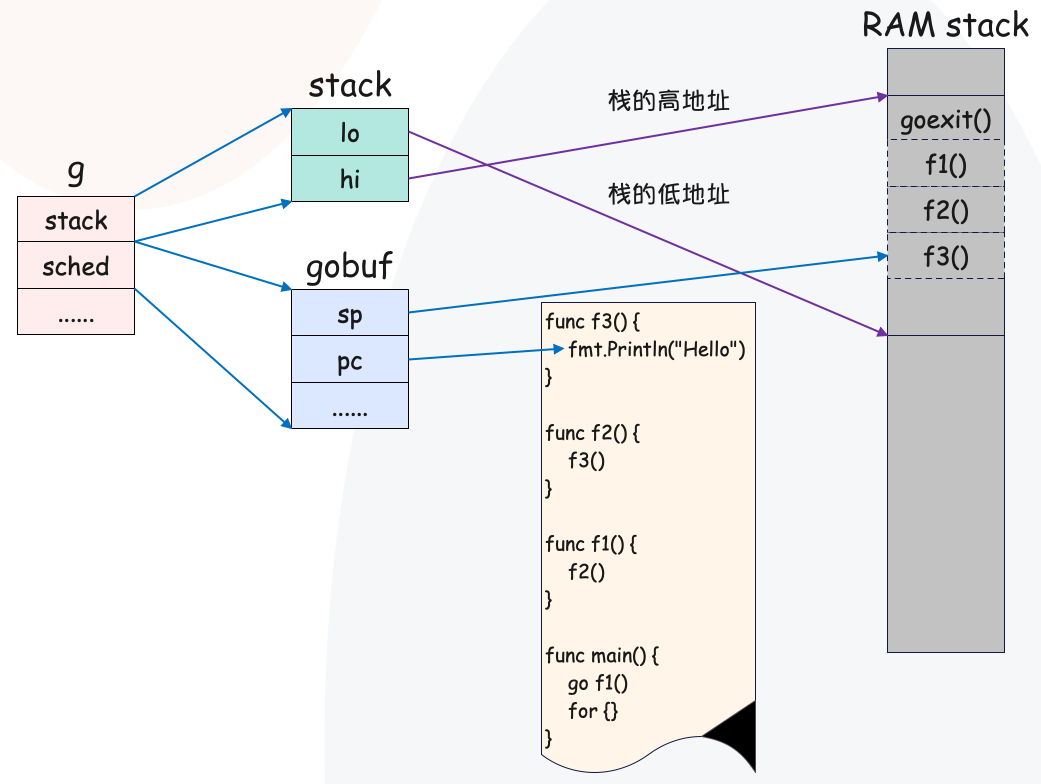
因此从协程的底层结构,可以总结出来如下信息:
在 runtime 中,协程本质就是一个 g 结构体里面的 stack 记录了协程的堆栈地址gobuf 则记录了程序的运行现场atomicstatus 则记录了协程状态
需要注意的是,协程的执行依赖线程,因为协程本质上就是一个结构体,真正负责执行的还是线程。所谓的多个协程并发执行,不过是线程在多个协程之间来回切换罢了。
线程的底层结构
然后是线程,它是由操作系统控制的,具体的执行过程 Go 编译器无权干涉,但 Go 编译器需要记录线程执行时的一些状态信息,这个状态信息在底层由 m 结构体表示。
// m 代表工作线程,保存了自身使用的栈信息
type m struct {
// Go 启动的第一个协程(不是主协程)
g0 *g
morebuf gobuf
divmod uint32
_ uint32
procid uint64
gsignal *g
goSigStack gsignalStack
sigmask sigset
// 通过 tls 结构体实现 m 与工作线程的绑定,这里是线程本地存储
tls [tlsSlots]uintptr
mstartfn func()
// 指向正在运行的 gorutine 对象
curg *g
caughtsig guintptr
// 当前工作线程绑定的 p
p puintptr
nextp puintptr
oldp puintptr
// 线程 ID
id int64
mallocing int32
throwing throwType
// 该字段不等于空字符串的话,要保持 curg 始终在这个 m 上运行
preemptoff string
locks int32
dying int32
profilehz int32
// 为 true 时表示当前 m 处于自旋状态,正在从其他线程偷工作
spinning bool
// m 是否正阻塞在 note 上
blocked bool
newSigstack bool
printlock int8
// 是否正在执行 cgo 调用
incgo bool
freeWait atomic.Uint32 /
fastrand uint64
needextram bool
traceback uint8
ncgocall uint64
ncgo int32
cgoCallersUse uint32
cgoCallers *cgoCallers
// 没有 goroutine 需要运行时,工作线程睡眠在这个 park 成员上,
// 其它线程通过这个 park 唤醒该工作线程
park note
// 记录所有工作线程的链表
alllink *m
schedlink muintptr
lockedg guintptr
createstack [32]uintptr
lockedExt uint32
lockedInt uint32
// 正在等待锁的下一个 m
nextwaitm muintptr
waitunlockf func(*g, unsafe.Pointer) bool
waitlock unsafe.Pointer
waittraceev byte
waittraceskip int
startingtrace bool
syscalltick uint32
freelink *m
libcall libcall
libcallpc uintptr
libcallsp uintptr
libcallg guintptr
syscall libcall
vdsoSP uintptr
vdsoPC uintptr
preemptGen uint32
signalPending uint32
dlogPerM
// 记录线程的一些额外信息(针对操作系统而异)
mOS
locksHeldLen int
locksHeld [10]heldLockInfo
}
runtime 中将操作系统线程抽象为 m 结构体,里面的 g0 字段表示启动的第一个协程,主要用来操作调度器(一会解释);里面的 curg 字段表示当前正在运行的协程。
操作系统是感知不到 goroutine 的存在的,在早期的 Go 中,每个系统线程会执行一个调度循环,顺序执行 goroutine。整个过程就类似于线程池一样,每个线程不停地获取 goroutine,执行完了销毁协程栈,然后再执行下一个。
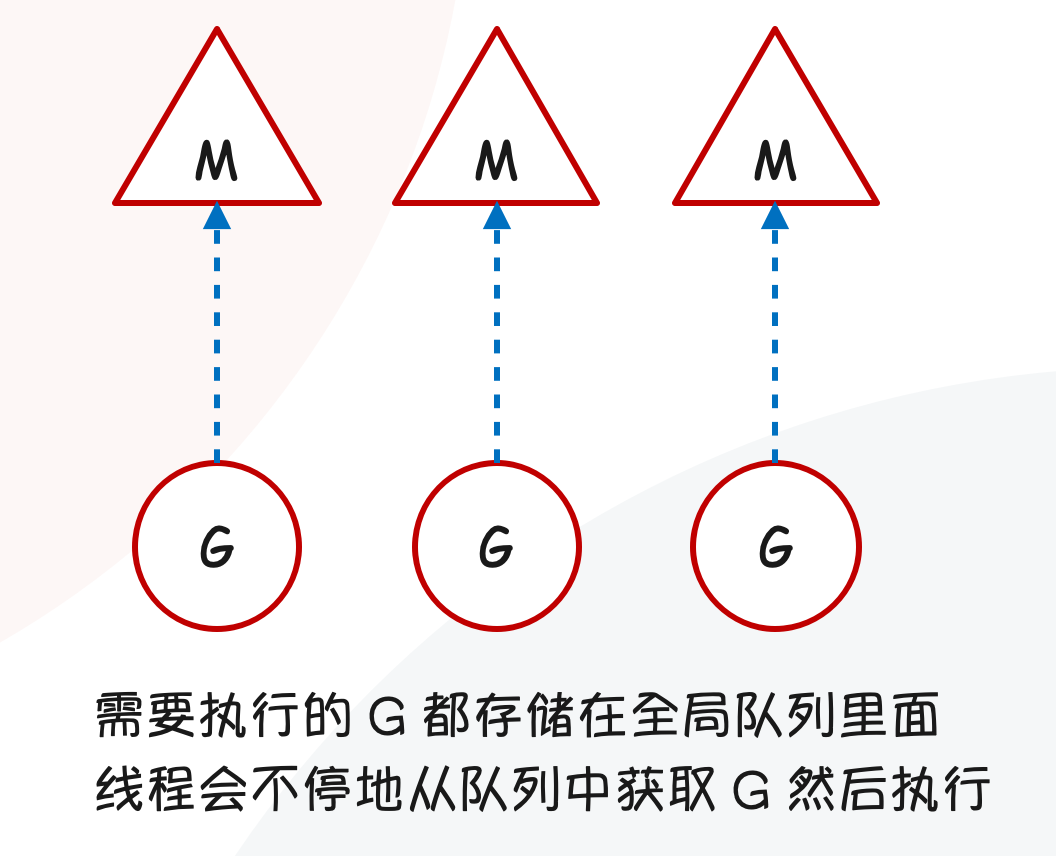
但是目前这种工作模式存在两个问题:
- 无法实现高并发,因为一个线程同时只能执行一个 G;
- 多线程并发时,会抢夺队列的全局锁;
所以为了解决这两个问题,Go 编译器又引入了 P。
GPM 模型
G、P、M 是 Go 调度器的三个核心组件,各司其职。在它们精密地配合下,Go 调度器得以高效运转,这也是 Go 天然支持高并发的内在动力。
- G:取 goroutine 的首字母,主要保存 goroutine 的一些状态信息以及 CPU 的一些寄存器的值,例如 IP 寄存器,以便在轮到本 goroutine 执行时,CPU 知道要从哪一条指令处开始执行。当 goroutine 被调离 CPU 时,调度器负责把 CPU 寄存器的值保存在 g 对象的成员变量之中。当 goroutine 被调度起来运行时,调度器又负责把 g 对象的成员变量所保存的寄存器值恢复到 CPU 的寄存器。
- M:取 machine 的首字母,它代表一个工作线程,或者说系统线程。G 需要调度到 M 上才能运行,M 是真正工作的人。结构体 m 就是我们常说的 M,它保存了 M 自身使用的栈信息、当前正在 M 上执行的 G 信息、与之绑定的 P 信息。当 M 没有工作可做的时候,在它休眠前,会“自旋”地来找工作:检查全局队列,查看 network poller,试图执行 gc 任务,或者“偷”工作。
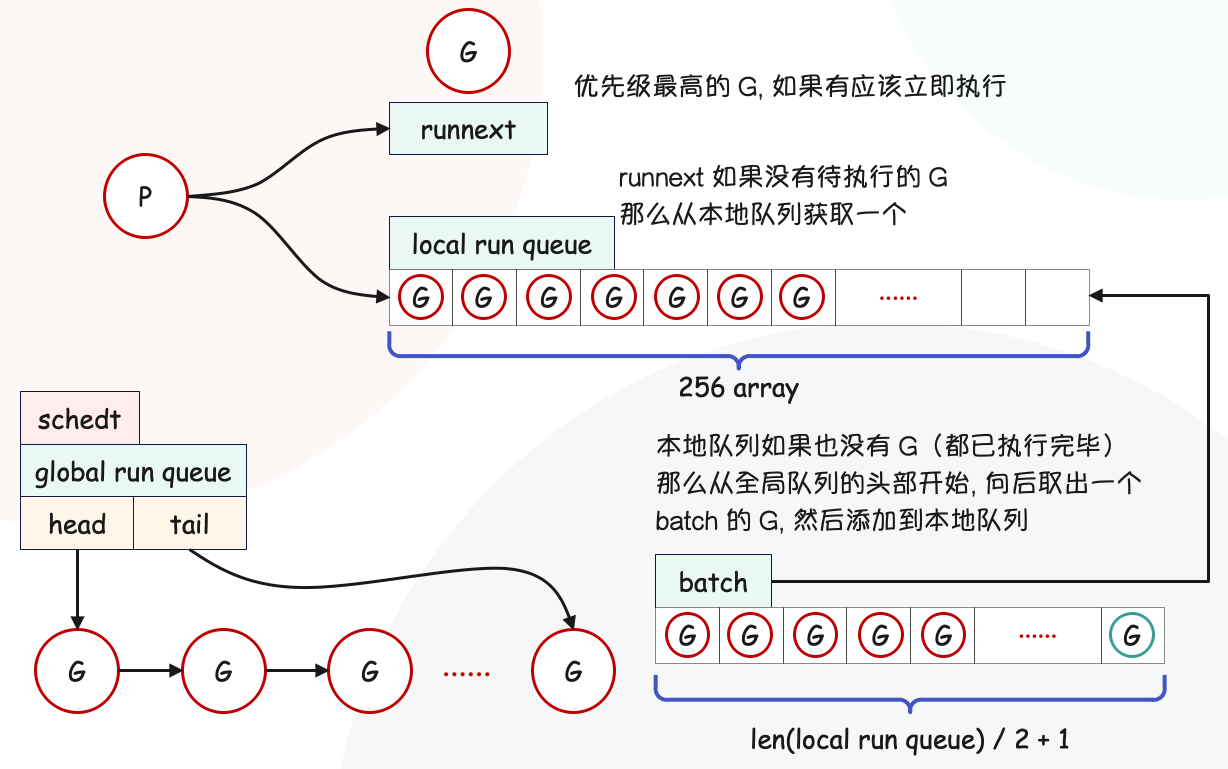
- P:取 processor 的首字母,为 M 的执行提供“上下文”,保存 M 执行 G 时的一些资源,例如本地可运行 G 队列,memeory cache 等。
所以通过引入 P,上面的两个问题都能得到解决,首先是第二个问题,多线程抢夺队列的全局锁问题。由于所有的 G 都放在一个全局队列里面,不同的线程每次获取 G 的时候,都要对队列加锁。那么问题来了,M 在获取 G 的时候能不能一次获取多个呢?这样就不用每执行完一个 G,就跑到队列获取一次了,所以就有了本地队列。
M 每次会从全局队列里面获取多个 G,存到本地队列里面,这样就不用每次都到全局队列里面取了。
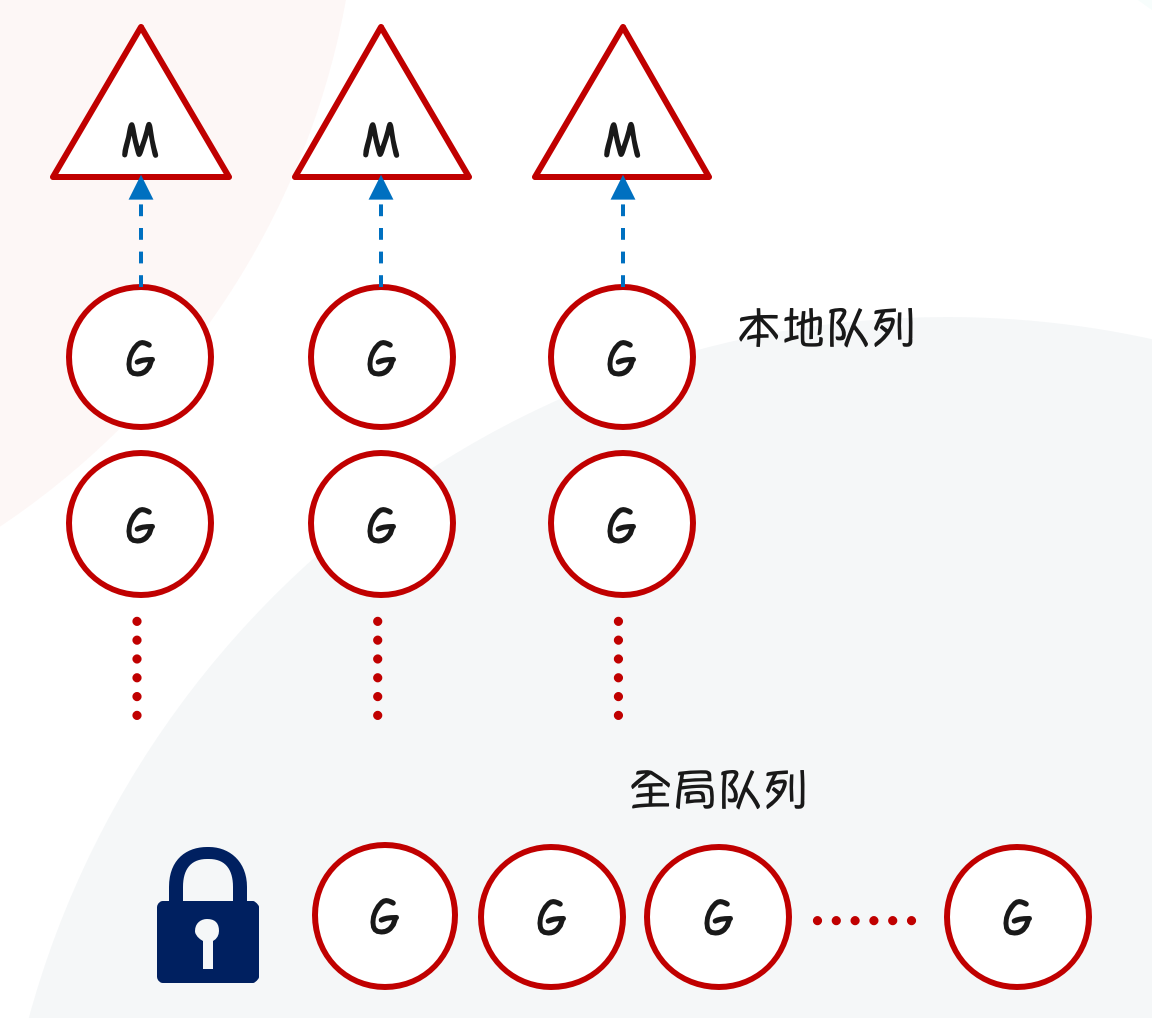
而这个本地队列就被放在 P 中,一个 M 只有绑定 P 才能执行 goroutine,当 M 被阻塞时,整个 P 会被传递给其他 M ,或者说整个 P 被接管。
type p struct {
id int32
status uint32
link puintptr
// 每次调用 schedule 时会加一
schedtick uint32
// 每次系统调用时加一
syscalltick uint32
// 用于 sysmon 线程记录被监控 p 的系统调用时间和运行时间
sysmontick sysmontick
// 指向绑定的 m,如果 p 是 idle 的话,那这个指针是 nil
m muintptr
mcache *mcache
pcache pageCache
raceprocctx uintptr
deferpool []*_defer
deferpoolbuf [32]*_defer
goidcache uint64
goidcacheend uint64
// 本地可运行的队列,不用通过锁即可访问
runqhead uint32 // 队列头
runqtail uint32 // 队列尾
// 使用数组实现的循环队列,长度为 256,并且是无锁访问
runq [256]guintptr
// runnext 非空时,代表的是一个 runnable 状态的 G
// 这个 G 被当前 G 修改为 ready 状态,相比 runq 中的 G 有更高的优先级
// 如果当前 G 还有剩余的可用时间,那么就应该运行这个 G
// 运行之后,该 G 会继承当前 G 的剩余时间
runnext guintptr
// 空闲的 g
gFree struct {
gList
n int32
}
sudogcache []*sudog
sudogbuf [128]*sudog
mspancache struct {
len int
buf [128]*mspan
}
tracebuf traceBufPtr
traceSweep bool
traceSwept, traceReclaimed uintptr
palloc persistentAlloc
_ uint32
timer0When uint64
timerModifiedEarliest uint64
gcAssistTime int64
gcFractionalMarkTime int64
limiterEvent limiterEvent
gcMarkWorkerMode gcMarkWorkerMode
gcMarkWorkerStartTime int64
gcw gcWork
wbBuf wbBuf
runSafePointFn uint32
statsSeq uint32
timersLock mutex
timers []*timer
numTimers uint32
deletedTimers uint32
timerRaceCtx uintptr
maxStackScanDelta int64
scannedStackSize uint64
scannedStacks uint64
preempt bool
}
GPM 三足鼎力,共同成就 Go scheduler。G 需要在 M 上才能运行,M 依赖 P 提供的资源,P 则持有待运行的 G。你中有我,我中有你。
所以相信你应该明白 P 的作用了,它相当于 G 和 M 之间的中介,P 持有相应的 G,使得 M 不需要每次获取 G 的时候都从全局队列中查找,从而大大减少了并发冲突的情况。
M 首先从 P 的 runnext 获取优先级最高的 Grunnext 如果没有待执行的 G, 那么从本地队列获取本地队列如果为空, 也就是里面的 G 都执行完了, 那么会从全局队列获取一个 batch 的 G 添加到本地队列如果全局队列也为空了, 那么会从其它的 P 的本地队列偷一些 G 过来, 不然绑定在该 P 上的 M 就会处于空闲状态
然后当我们新建一个协程时,编译器会认为它的优先级最高,于是会随机找一个 P,然后放在该 P 的 runnext 里面。
到目前为止我们解决了第二个问题,前面说了,在引入 P 之前,存在两个问题:
- 无法实现高并发,因为一个线程同时只能执行一个 G;
- 多线程并发时,会抢夺队列的全局锁;
第二个问题已经解决了,下面说一说第一个问题是怎么解决的。
在引入 P 之前,M 是顺序执行 G 的,从本地队列获取一个 G,执行完了再获取下一个。但这样容易造成饥饿问题,如果某一个 G 耗时特别长,那么其它的 G 永远得不到执行。另外当出现 IO 阻塞的时候,由于不耗费 CPU,那么这个时候干等也没有意义。所以当 G 出现了阻塞时,编译器会将它的状态保存起来放回本地队列,然后从本地队列获取别的 G 执行。
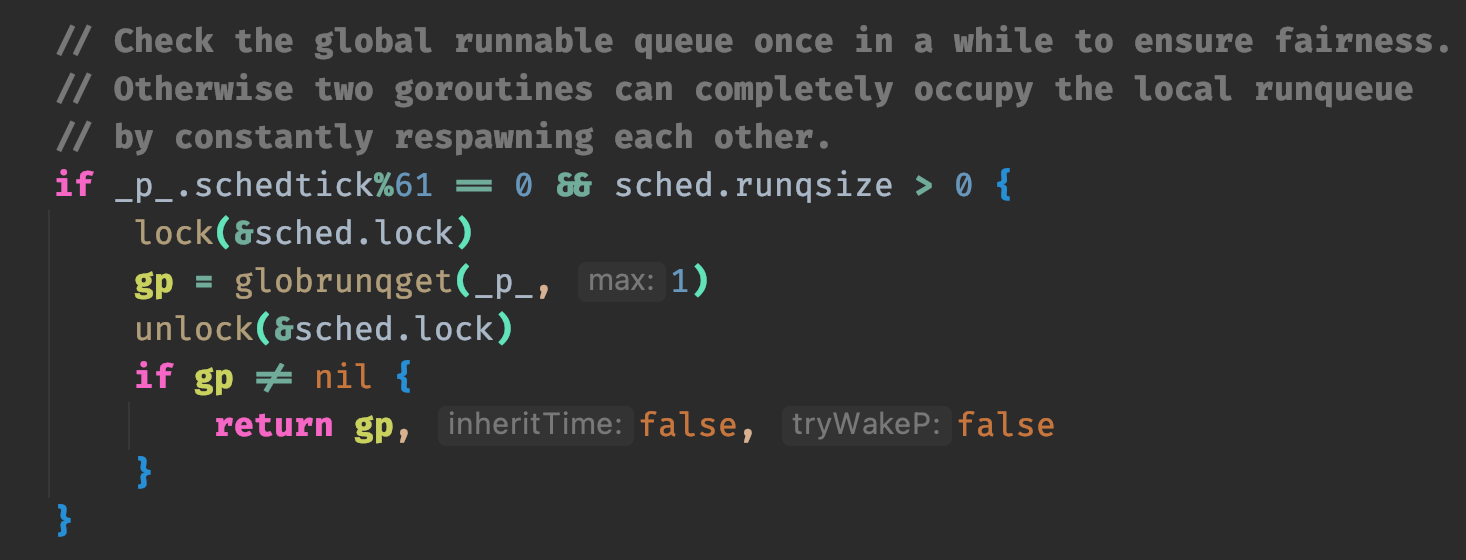
这么做解决了本地队列的协程饥饿以及 CPU 利用率的问题,但全局队列又可能会造成饥饿。前面说了,当本地队列为空时,会从全局队列获取一个 batch 的 G 添加到本地队列中,但如果本地队列的 G 耗时很长呢?因此会导致全局队列的 G 始终得不到执行。所以 Go 里面,每当本地队列的协程执行了 61 个,就从全局队列里面取一个 G 执行。
所以通过协程之间的切换,Go 实现了高并发。
小结
- 协程相当于对线程精打细算,可以支撑超高并发,当然从 runtime 的角度看,它就是一个可以被调用的 g 结构体(里面包含了要运行的代码)。从线程的角度上看,协程就是一个对象,自带执行现场。
- 光有 G 和 M 还不够,通过 P 达到了缓存部分 G 的目的。
- P 是一个结构体,但里面存储了包含 G 的本地队列,避免全局并发等待。
- 窃取式的工作分配机制,能够更加充分利用线程资源。
- 如果协程顺序执行,会有饥饿问题。于是在协程执行中需要被挂起的时候,将协程挂起(可以是主动挂起、也可以是需要完成系统时挂起),执行其它协程。所以通过 GPM 模型,即使只用一个线程也能实现并发。
- 为防止全局队列饥饿,会在本地队列完成 61 个 G 时,从全局队列抽取 1 个 G。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号