如何保证缓存和数据库的数据一致性
楔子
下面说一个老生常谈的话题,就是缓存和数据库的一致性问题,很多人会好奇,我们在更新的数据的时候是先更新缓存还是先更新数据库。如果其中一个更新成功,另一个更新失败了怎么办?下面我们就来探讨一下这个问题。
为什么要有缓存?
在早期业务访问量不大的时候,基本上都是直接请求数据库,这样做是没有问题的。但随着业务量的增长,如果每次还是从数据库中获取数据,那么必然会有性能问题。这个时候,基本上都会引入 Redis 作为缓存来解决,但与此同时问题又来了:数据库的数据要如何放到缓存中呢?
首先我们能想到一个最简单粗暴的方案:将数据库中的全量数据都刷到缓存中,并且不设置失效时间。如果需要更新数据,那么只更新数据库,不更新缓存,而是由一个专门的定时任务去对缓存进行更新。
虽然这是一个解决方案,但是这个方案明显存在两个缺陷:
缓存利用率低,那么不常用的数据也会一直驻留在缓存中,因为缓存的空间比磁盘空间要宝贵的多数据不一致,因为是定时更新缓存,那么定时任务在还没有将新数据从数据库刷到缓存时,就会读到旧数据
如果你的公司很有钱的话,可以并且愿意提供足够大的缓存空间存放所有的数据,那么第一个问题就不再是问题了,但绝大部分公司基本上都不会这么做的;而第二个问题,可能有人觉得将定时任务的执行频率设置的高一些,或者每次更新数据库的同时也更新缓存不就行了。其实即使将执行频率设置的高一些,还是有可能出现数据不一致的,如果更新数据库的同时也更新缓存,那有一方更新失败了怎么办。
那么下面我们就来解决这一问题。
缓存利用率和数据一致性
那么下面我们就来解决这一问题,如何提高缓存利用率?想要最大化缓存利用率,我们很容易想到的方案是,让缓存只保留最近访问的热点数据。做法如下:
写请求不仅写数据库,还要写缓存缓存中的数据,都设置失效时间读请求先读缓存,如果缓存里不存在,则读数据库,然后写入缓存
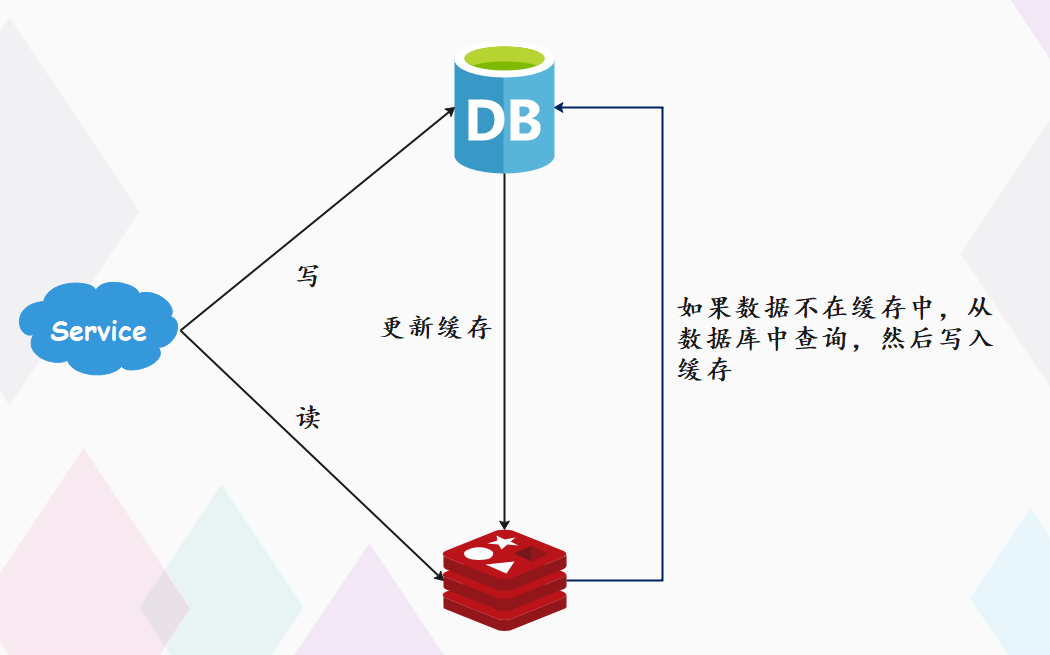
这样一来,缓存中不经常访问的数据,会随着时间的推移,因为过期而被逐渐淘汰掉,最终缓存中保留的,都是经常被访问的热点数据,缓存利用率得以最大化。
缓存利用率解决了,下面再看看数据一致性的问题,因为要保证数据一致,那么就不能再使用定时任务刷新缓存了。而是当数据发生更新时,不仅要更新数据库,也要连带缓存一起更新。但数据库和缓存都更新,就出现了先后问题,到底是先更新缓存呢?还是先更新数据库呢?
首先在两者都更新成功的情况下,那么谁先更新没有任何区别,反正都是要更新的。但问题是缓存和数据库是两个不同的存储介质,我们不可能保证两者都能百分百同时更新成功,我们需要考虑有一方更新失败的情况。
先更新缓存,后更新数据库
如果缓存更新成功了,但数据库更新失败,那么此时缓存中是新值,数据库中的是旧值。虽然此时读请求可以命中缓存,拿到正确的值,但是,一旦缓存失效,就会从数据库中读取到旧值,重建缓存也是这个旧值。这时用户会发现自己之前修改的数据又变回去了,会对业务造成影响。
先更新数据库,后更新缓存
如果数据库更新成功了,但缓存更新失败,那么此时数据库中是新值,缓存中是旧值。而之后的读请求读到的都是旧数据,只有当缓存失效后,才能从数据库中得到正确的值。这时用户会发现,自己刚刚修改了数据,但却看不到变更,一段时间过后,数据才变更过来,对业务也会有影响。
可以看到,无论先更新谁,但凡后者发生异常,都会对业务造成影响。
于是可能有聪明的小伙伴想到了,我们能不能将这两步组成一个事务,让它们同时成功才算成功,只要有一方失败就回滚。这确实是一个解决方案,可以通过分布式事务来实现。但这么做会产生两个问题:
1. 采用分布式事务实际上会牺牲系统的可用性,也就是 CAP 中 A。
2. 缓存和数据库是两个独立的存储介质,我们不应该将两者的写操作绑定在一个事务里。
因此我们不推荐分布式事务,而至于如何保证两者都成功,我们一会再说,先来看看还有什么情况会影响数据一致性的问题。
并发引起的数据不一致
假设我们采用 "先更新数据库,再更新缓存" 的方案,并且两步都可以成功执行的前提下,如果存在并发,情况会是怎样的呢?假设有线程 A 和线程 B 两个线程,需要更新同一条数据,那么可能会发生这样的场景:
1. 线程 A 更新数据库(value = 1)2. 线程 B 更新数据库(value = 2)3. 线程 B 更新缓存(value = 2)4. 线程 A 更新缓存(value = 1)
最终 value 的值在数据库中是 2,但在缓存中是 1。也就是说,虽然 A 先于 B 发生,但操作数据库加缓存的整个过程,B 却比 A 先完成。
可能有人觉得,这是不是不太可能啊,事实上这完全是有可能的,我们无法保证 happens before。有可能 A 在更新完数据库,碰巧来了一次 GC,STW 导致在更新缓存之前,线程 B 将两步都完成了。虽然概率比较低,但绝对是有可能发生的。
同样地,采用 "先更新缓存,再更新数据库" 的方案,也会有类似问题。
除此之外,我们从缓存利用率的角度来评估这个方案,也是不太推荐的。这是因为每次数据发生变更,都无脑更新缓存,但是缓存中的数据不一定会被马上读取,这就会导致缓存中可能存放了很多不常访问的数据,浪费缓存资源。而且很多情况下,写到缓存中的值,并不是与数据库中的值一一对应的,很有可能是先查询数据库,再经过一系列计算得出一个值,再把这个值才写到缓存中。
由此可见,这种同时更新数据库和缓存的方案,不仅缓存利用率不高,还会造成机器性能的浪费,应该在读缓存的时候发现数据不存在,然后读取数据库并将数据写入缓存。所以此时我们可以考虑另外一种方案:删除缓存。
删除缓存保证数据一致性
经过分析我们知道,同时更新数据库和缓存会有两种可能导致数据不一致:一种是因为异常原因导致其中一方更新失败;另一种是由于并发带来的资源竞争,引起的数据的错误更新。并且这种做法还会带来资源上的浪费,所以我们不建议同时更新数据库和缓存,而是只更新数据库。因为一旦对数据进行修改,那么这个操作就已经发生了,一定要落盘,这样就至少能保证在任何时刻都能从数据库中读取到正确的数据。
但问题是缓存中的旧数据怎么办?缓存如果不更新,就会读出旧数据。因此我们可以考虑从缓存中删除该数据,那么可能有人问,难道将更新缓存换成删除缓存就能保证一致性了吗。首先我们说同时更新数据库和缓存会有两种原因数据不一致,而将更新缓存换成删除缓存,至少可以解决并发导致的数据不一致。
那么问题来了,更新数据库和删除缓存到底先执行哪一步才能解决并发带来的数据不一致问题呢?下面分析一下。注意:这里我们先假设两步都成功,因为目前只考虑并发。
先删除缓存,后更新数据库
如果有两个线程要并发读写数据,可能会发生以下场景:
1. 线程 A 要更新 value = 2(之前 value = 1),但是更新之前先删除缓存2. 线程 B 读缓存,发现不存在,因为 A 已经删掉了,所以会从数据库中读取到旧值(value = 1)3. 线程 A 将新值写入数据库(value = 2)4. 线程 B 在读缓存的时候发现 Cache Miss,于是将从数据库中读取的值写入缓存(value = 1)
最终 value 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致。可见,先删除缓存,后更新数据库,当发生读写并发时,还是存在数据不一致的情况。
先更新数据库,后删除缓存
依旧是两个线程并发「读写」数据:
1. 线程 A 读缓存,发现不存在2. 线程 A 读取数据库,得到值(value = 1)3. 线程 B 更新数据库(value = 2)4. 线程 B 删除缓存5. 线程 A 将旧值写入缓存(value = 1)
最终 value 的值在缓存中是 1(旧值),在数据库中是 2(新值),也发生不一致。咦,不是说可以解决并发带来的不一致吗?为啥两种方式都会导致数据不一致呢?
我们不妨再仔细看一下 "先更新数据库,后删除缓存" 这种方式,它所造成的数据不一致真的有可能发生吗?首先它如果想发生,必须满足 3 个条件:
缓存刚好已失效读请求 + 写请求并发更新数据库 + 删除缓存的时间(步骤 3、4),要比读数据库 + 写缓存时间短(步骤 2、5)
首先条件 1 和 2 的概率虽然低,但也有可能发生,但条件 3 发生的概率可以说是微乎其微的。因为写数据库一般会先加锁,所以写数据库,通常是要比读数据库的时间更长的。所以 "先更新数据库,后删除缓存" 在并发层面是可以保证数据一致性的,那么接下来的问题就是当两个操作中的第二个(显然是删除缓存)执行失败时,该怎么办?
如何保证两步都执行成功?
前面我们分析到,无论是更新缓存还是删除缓存,只要第二步发生失败,那么就会导致数据库和缓存不一致。只不过更新缓存这种做法即使在两步都成功的前提下也会出现数据不一致,而删除缓存不会,所以我们最终决定采用"更新数据库+删除缓存"这一策略。所以剩下的问题就是如何保证第二步的成功,这是问题的关键。
想一下,程序在执行过程中发生异常,最简单的解决办法是什么?没错,就是重试。这里我们也是同样的做法,无论是先操作缓存,还是先操作数据库,但凡后者执行失败了,我们就可以发起重试,尽可能地去做补偿。但这仍然会带来几个问题:
立即重试很大概率还会失败重试次数设置多少才合理重试会一直占用这个线程资源,无法服务其它客户端请求
虽然我们想通过重试的方式解决问题,但采用同步重试的方案依旧不严谨,因此最正确的做法是采用异步重试。
其实就是把重试请求写到消息队列中,然后由专门的消费者来重试,直到成功。或者更直接的做法,为了避免第二步执行失败,我们可以把删除缓存这一步,直接放到消息队列中,由消费者来删除缓存。到这里你可能会问,写消息队列也有可能会失败啊?而且,引入消息队列,这又增加了更多的维护成本,这样做值得吗?这个问题很好,但我们思考这样一个问题:如果在执行失败的线程中一直重试,还没等执行成功,此时如果项目重启了,那这次重试请求也就丢失了,那这条数据就一直不一致了。
所以,这里我们必须把重试或第二步操作放到另一个服务中,这个服务用消息队列最为合适,因为消息队列的特性,正好符合我们的需求:
消息队列保证可靠性:写到队列中的消息,成功消费之前不会丢失(重启项目也不担心)消息队列保证消息成功投递:下游从队列拉取消息,成功消费后才会删除消息,否则还会继续投递消息给消费者(符合我们重试的场景)
至于写队列失败和消息队列的维护成本问题:
写队列失败:操作缓存和写消息队列,同时失败的概率其实是很小的维护成本:我们项目中一般都会用到消息队列,维护成本并没有新增很多
所以,引入消息队列来解决这个问题,是比较合适的。此时架构模型就变成了这样:
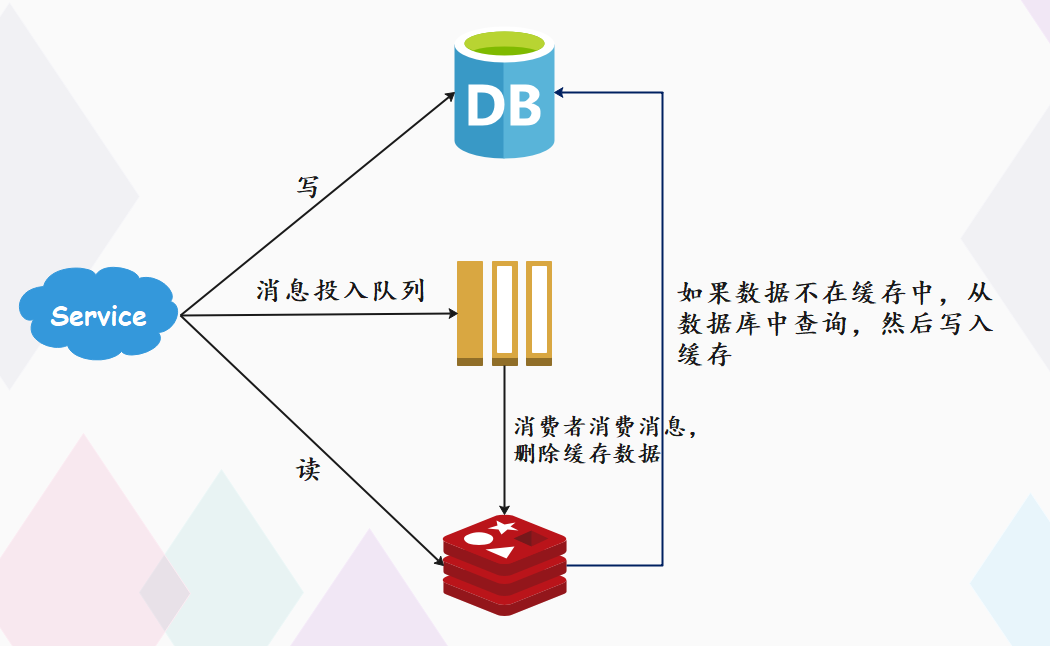
如果你确实不想在应用中去写消息队列,是否有更简单的方案,同时又可以保证一致性呢?方案还是有的,这就是近几年比较流行的解决方案:订阅数据库变更日志,再操作缓存。具体来讲就是,我们的业务应用在修改数据时,只需修改数据库,无需操作缓存。那什么时候操作缓存呢?这就和数据库的变更日志有关了。
拿 MySQL 举例,当一条数据发生修改时,MySQL 就会产生一条变更日志(Binlog),我们可以订阅这个日志,拿到具体操作的数据,然后再根据这条数据,去删除对应的缓存。订阅变更日志,目前也有了比较成熟的开源中间件,例如阿里的 canal,当然与此同时,我们需要投入精力去维护 canal 的高可用和稳定性。
如果你有留意观察很多数据库的特性,就会发现其实很多数据库都逐渐开始提供「订阅变更日志」的功能了,相信不远的将来,我们就不用通过中间件来拉取日志,自己写程序就可以订阅变更日志了,这样可以进一步简化流程。
至此,我们可以得出结论,想要保证数据库和缓存一致性,推荐采用"先更新数据库,再删除缓存" 方案,并配合消息队列或订阅变更日志来实现。所以对于业务调用方而言,如果数据库更新成功,那么直接返回成功即可,删除缓存这一步异步实现;如果数据库更新失败,那么直接返回失败,删除缓存也无需再进行了。
主从库延迟和延迟删除
目前还没有万事大吉,这里还有一个问题,我们说 "更新数据库 + 删除缓存" 可以解决数据不一致,但如果遇到了 "读写分离 + 主从复制延迟",那么还是会导致数据不一致的。举个栗子:
1. 线程 A 更新主库 value = 2(旧值value = 1)2. 线程 A 删除缓存3. 线程 B 查询缓存,没有命中,于是查询从库得到旧值(从库 value = 1)4. 从库同步完成(主从库 value = 2)5. 线程 B 将旧值写入缓存(value = 1)
最终 value 的值在缓存中是 1(旧值),在主从库中是 2(新值),也发生不一致。所以我们在删除缓存的时候不能立即删,而是需要延迟删。
具体做法就是:线程 A 可以生成一条延时消息,写到消息队列中,消费者延时删除缓存。但问题来了,这个延迟删除缓存,延迟时间到底设置要多久呢?
1. 延迟时间要大于主从复制的延迟时间2. 延迟时间要大于线程 B 读取数据库 + 写入缓存的时间
而一旦涉及到时间,就意味着不精确,因为谁也说不清这个时间到底应该设置多长,尤其是在分布式和高并发场景下就变得更加难评估。很多时候,我们都是凭借经验大致估算这个延迟时间,例如延迟 1 到 5 秒,只能尽可能地降低不一致的概率,这个过程当中如果有请求过来,还是可能会读到旧数据的。但通过消息队列或订阅变更日志,我们是可以实现最终一致性的。所以实际使用中,建议采用先更新数据库,再删除缓存的方案,同时,要尽可能地保证主从复制不要有太大延迟,降低出问题的概率。
以上就是删除缓存所采用的策略,但其实这背后还有一个问题,那就是如果删除的数据是一个热点数据,是有可能造成缓存击穿的。针对这个问题,国外的 Facebook 给出了一个解决方案,就是在删除的时候,如果判定这是一个热门数据,那么不直接删,而是将它的生命周期设置的更短一些,比如 10 到 30 秒,然后业务方在调用的时候会表明这是一个脏数据。至于你要不要用,则交给业务方进行判断。
可以做到强一致吗?
看到这里你可能会想,这些方案还是不够完美,我就想让缓存和数据库强一致,到底能不能做到呢?首先要想做到强一致,最常见的方案是 2PC、3PC、Paxos、Raft 这类一致性协议,但它们的性能往往比较差,而且这些方案也比较复杂,还要考虑各种容错问题。
相反,这时我们换个角度思考一下,我们引入缓存的目的是什么?答案很明显,就是性能。一旦我们决定使用缓存,那必然要面临一致性问题,性能和一致性就像天平的两端,无法做到都满足要求。而且,就拿我们前面讲到的方案来说,当操作数据库和缓存完成之前,只要有其它请求可以进来,都有可能查到中间状态的数据。所以如果非要追求强一致,那必须要求所有更新操作完成之前期间,不能有任何请求进来。虽然我们可以通过加分布锁的方式来实现,但我们要付出的代价,很可能会超过引入缓存带来的性能提升。因此既然决定使用缓存,就必须容忍一致性问题,我们只能尽可能地去降低问题出现的概率。
总结
对上面的内容总结一下:
1. 想要提高应用的性能,可以引入缓存来解决2. 引入缓存后,需要考虑缓存和数据库一致性问题,可选的方案有:更新数据库 + 更新缓存、更新数据库 + 删除缓存3. 更新数据库 + 更新缓存方案,在并发场景下无法保证缓存和数据一致性,且存在缓存资源浪费、以及机器性能浪费的情况发生,所以推荐用 "先更新数据库,再删除缓存" 方案4. 在 "先更新数据库,再删除缓存" 方案下,为了保证两步都成功执行,需配合消息队列或订阅变更日志的方案来做,本质是通过重试的方式保证数据一致性5. 在 "先更新数据库,再删除缓存" 方案下,"读写分离 + 主从库延迟" 也会导致缓存和数据库不一致,缓解此问题的方案是凭借经验发送延迟消息到队列中,延迟删除缓存,同时也要控制主从库延迟,尽可能降低不一致发生的概率6. 为了避免缓存击穿,如果删除的是热门数据,那么建议采用不直接删除,而是设置一个较短的生命周期。业务方在获取数据的时候,告诉它这是一个旧数据,是否使用由你来决定
通过以上的学习,我们也对数据一致性有了更深的了解:
性能和一致性不能同时满足,为了性能考虑,通常会采用最终一致性的方案掌握缓存和数据库一致性问题,核心问题有 3 点:"缓存利用率"、"并发"、"缓存 + 数据库一起成功"失败场景下要保证一致性,常见手段就是重试,同步重试会影响吞吐量,所以通常会采用异步重试的方案订阅变更日志的思想,本质是把权威数据源(例如 MySQL)当做 leader 副本,让其它异质系统(例如 Redis / Elasticsearch)成为它的 follower 副本,通过同步变更日志的方式,保证 leader 和 follower 之间保持一致。正如 MySQL 的主从同步一样,也是订阅变更日志(Binlog)实现的,从机收到主机发来的 Binlog 之后,进行回放,从而保证数据一致。只不过其它异质系统没有订阅 Binlog 的能力,需要我们手动订阅(比如使用 canal),然后将数据更新进去,本质都是一样
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号