celery:强大的定时任务模块
celery介绍
什么是celery
这次我们来介绍一下Python的一个第三方模块celery,那么celery是什么呢?
celery是一个灵活且可靠的,处理大量消息的分布式系统,可以在多个节点之间处理某个任务。celery是一个专注于实时处理的任务队列,支持任务调度。celery是开源的,有很多使用者。celery完全基于Python语言编写。
所以celery是一个任务调度框架,类似于Apache的airflow,当然airflow也是基于Python语言编写。不过有一点需要注意,celery是用来调度任务的,它本身并不具备任务的存储功能,而我们说在调度任务的时候肯定是要把任务存起来的,因此在使用celery的时候还需要搭配一些具备存储、访问功能的工具,比如:消息队列、Redis缓存、数据库等等。官方推荐的是消息队列RabbitMQ,个人认为有些时候使用Redis也是不错的选择,当然我们都会介绍。
那么celery都可以在哪些场景中使用呢?
异步任务:一些耗时的操作可以交给celery异步执行,而不用等着程序处理完才知道结果。比如:视频转码、邮件发送、消息推送等等。定时任务:比如定时推送消息、定时爬取数据、定时统计数据等等。
celery的架构
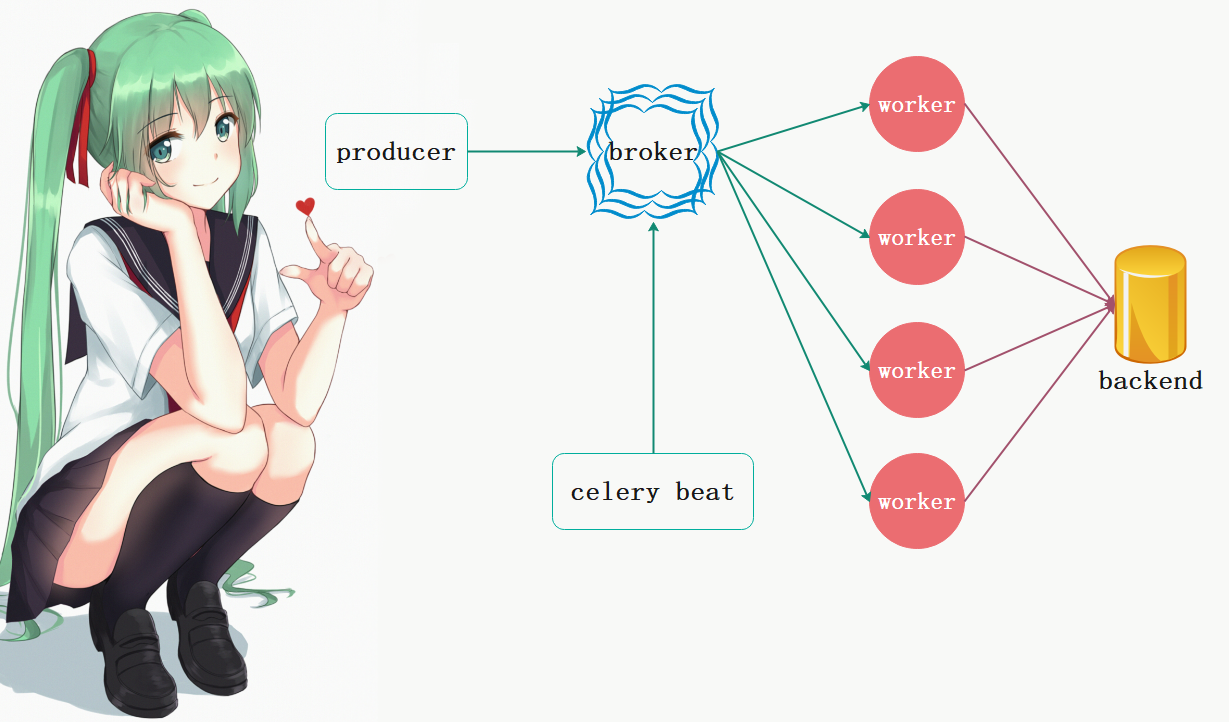
producer:任务生产者,专门用来生产任务(task)的;broker:任务队列,用于存放生产者生产的任务。一般使用消息队列或者Redis来存储,但是具有存储功能的数据库也是可以的。这一部分是celery所不提供的,需要依赖第三方。作用就是接收生产者生产的消息,存进队列,再按顺序发给消费者;celery beat:任务调度器,调度器进程会读取配置文件的内容,周期性地将配置文件中到期需要执行的任务发送给消息队列。worker:消费者,执行任务的消费者,可以同时运行多个消费者,并行消费;backend:用于在任务结束之后保存状态信息和结果,以便查询,一般是数据库。
下面我们来安装celery,安装比较简单,直接pip install celery即可,另外我当然的Python版本是3.8.1,操作系统是Windows。
另外,我们说celery不提供任务存储的功能,所以这里我们使用Redis作为消息队列,因此你还要在机器上安装Redis,后面还会使用RabbitMQ。
当然celery要想把任务存到broker里,肯定还需要能够操作相应broker的驱动。Python操作Redis的驱动也叫redis,操作RabbitMQ的驱动叫pika,也是直接pip install安装即可。
celery实现异步任务
下面我们就来看看celery如何实现异步任务,首先我们建立两个py文件,一个叫做task.py,一个叫做execute.py。
task.py
import time
# 这个Celery就类似于flask中的Flask, 然后实例化得到一个app
from celery import Celery
# 指定一个name、以及broker的地址、backend的地址
app = Celery("satori",
# 这里使用我阿里云上的Redis, broker用1号库, backend用2号库
broker="redis://47.94.174.89:6379/1",
backend="redis://47.94.174.89:6379/2")
# 这里通过@app.task对函数进行装饰,那么之后我们便可通过调用task.delay创建一个任务
@app.task
def task(name, age):
print("准备执行任务啦")
time.sleep(3)
return f"name is {name}, age is {age}"
我们说执行任务的对象是worker,那么我们是不是需要创建一个worker呢?显然是需要的,而创建worker可以使用如下命令:celery worker -A task -l info -P eventlet
-A参数:表示Celery对象所在的py文件的文件名,会自动记录task.py里面被@app.task装饰的函数。-l参数:日志级别-P参数:表示事件驱动使用eventlet,这个需要在Windows平台设置,但在Linux平台不需要-c参数:表示并发数量,比如再加上-c 10,表示限制并发数量为10
下面执行该命令:celery worker -A task -l info -P eventlet
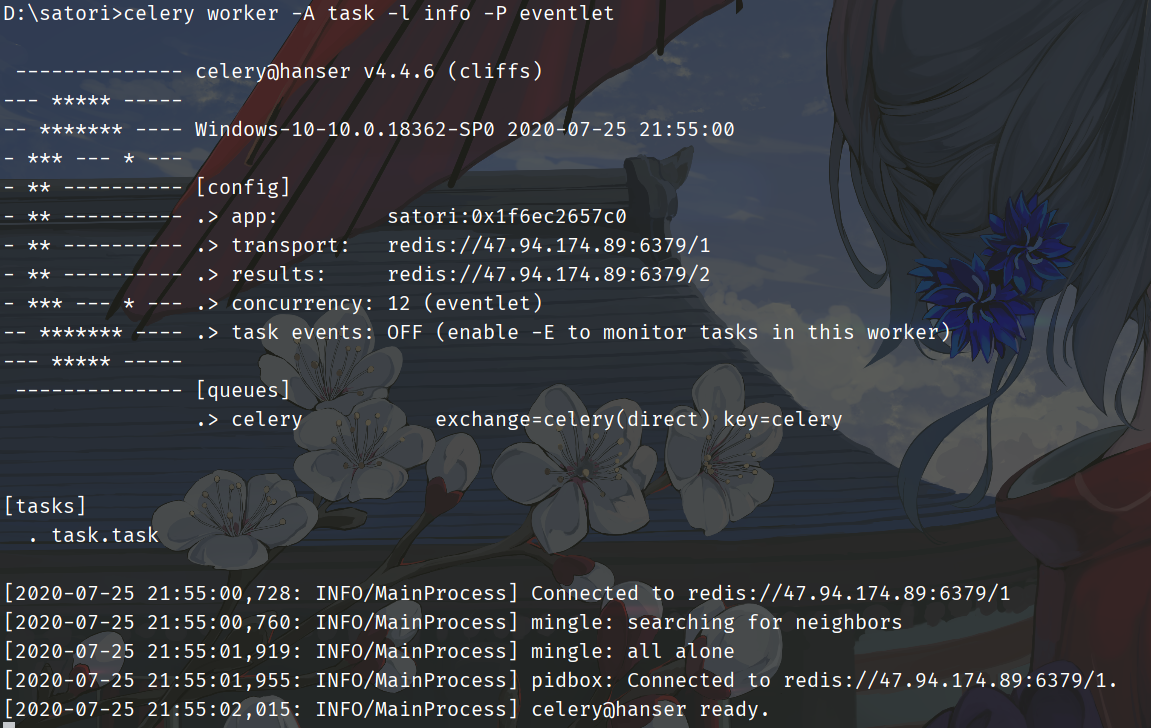
以上便创建了一个worker,等待从队列中获取任务执行,图中显示了相应的信息。然鹅此时队列中并没有任务,所以我们需要在另一个文件execute.py中创建一个任务并发送到队列里面去。
execute.py
import time
from task import task
# 导入task, 创建任务
# 但是注意: 不要直接调用task, 因为那样的话就在本地执行了
# 我们的目的是将任务发送到队列里面去, 然后让监听队列的worker从队列里面取任务并执行
# 而task是被@app.task装饰了, 所以它不在是原来的task了, 我们需要调用它的delay方法
# 调用delay之后, 就会创建一个任务, 然后发送到队列里面去, 也就是我们这里的Redis
# 至于参数, 普通调用的时候怎么传, 在delay里面依旧怎么传
start = time.perf_counter()
task.delay("古明地觉", 17)
print(time.perf_counter() - start) # 0.5087445999999999
然后执行该文件,发现用了0.5秒,而我们的task里面明明sleep了3秒,所以这一步是不会阻塞的。我们再看一下输出信息:

我们看到任务已经被消费者接收并且消费了,而且调用delay方法是不会阻塞的,花费了那0.5秒是用在了其它地方,比如连接Redis发送任务等等。
我们说函数被@app.task装饰之后,可以理解为它就变成了一个任务工厂,因为被装饰了嘛。调用这个任务工厂的delay方法即可创建任务并发送到队列里面了。我们也可以多创建几个任务工厂,只不过需要注意的是:当前有哪些任务工厂必须要让worker知道,所以如果修改了某个任务工厂、或者添加、删除了某个任务工厂,并且想让worker知道,那么一定要先停止celery worker,然后再重新启动。
其实很好理解,比如你执行一段代码,已经加载到内存里面了,这个时候即便你修改了源文件也没用,因为加载到内存里面的是你原来的代码,不是你修改过后的。
如果我们在没有重启worker的情况下,我们后续再使用app.task装饰函数、创建任务、调用delay方法添加任务进队列的时候,会抛出一个KeyError,提示找不到相应的任务工厂。
然后我们再来看看Redis中存储的信息:
[root@iZ2ze3ik2oh85c6hanp0hmZ ~]# docker exec -it redis /bin/bash
root@12573158d296:/data# redis-cli
127.0.0.1:6379> select 2
OK
127.0.0.1:6379[2]> keys * # 查看里面key
1) "celery-task-meta-5f01cad9-6251-48ac-8b6c-e451b821cdb9"
127.0.0.1:6379[2]>
127.0.0.1:6379[2]> # 里面给出了任务对应的信息, 比如: status表示任务的执行状态
127.0.0.1:6379[2]> # result表示任务的返回值, date_done表示任务执行完毕时的时间, task_id表示任务的id
127.0.0.1:6379[2]> get celery-task-meta-5f01cad9-6251-48ac-8b6c-e451b821cdb9
"{\"status\": \"SUCCESS\",
\"result\": \"name is \\u53e4\\u660e\\u5730\\u89c9, age is 17\",
\"traceback\": null,
\"children\": [],
\"date_done\": \"2020-07-25T15:02:24.906906\",
\"task_id\": \"ebad32f2-eb30-43e4-88b3-2ba522c8b4ee\"}"
直接查看返回的信息
我们看到Redis中存储了很多关于任务的信息,这些信息我们可以直接在程序中获取。
from task import task
t = task.delay("古明地觉", 17)
# 返回的是一个<class 'celery.result.AsyncResult'>对象
print(type(t)) # <class 'celery.result.AsyncResult'>
# 直接打印, 显示的是任务的id
print(t) # 29e8e2e5-baca-4f64-bb40-a7dc0f8dd385
# 获取状态
# 显然此刻没有执行完, 因此结果是PENDING, 表示等待状态
print(t.status) # PENDING
# 获取id, 可以调用task_id或者id
print(t.task_id, t.id) # 29e8e2e5-baca-4f64-bb40-a7dc0f8dd385 29e8e2e5-baca-4f64-bb40-a7dc0f8dd385
# 获取任务执行结束时的时间
# 任务还没有结束, 所以返回None
print(t.date_done) # None
# 获取任务的返回值, 可以通过result或者get()
# 注意: 如果是result, 那么任务还没有执行完的话会直接返回None
# 如果是get(), 那么会阻塞直到任务完成
print(t.result) # None
print(t.get()) # name is 古明地觉, age is 17
# 再次查看状态和执行时间
# 发现status变成SUCCESS, data_done变成了执行结束时的日期
print(t.status) # SUCCESS
print(t.date_done) # <class 'str'>
# 另外: t.status返回的是一个字符串, t.date_done返回的是datetime
另外我们说backend是用来存储结果的,如果没有配置backend,那么获取结果的时候会报错。
celery.result.AsyncResult对象
我们说调用完delay方法之后,会返回一个AsyncResult对象,我们也可以使用手动构造一个该对象,举个栗子:
# 我们不光要导入task, 还要导入里面的app
from task import app, task
# 导入AsyncResult这个类
from celery.result import AsyncResult
# 发送任务到队列当中
t = task.delay("古明地觉", 17)
# 传入任务的id和app, 创建AsyncResult对象
async_result = AsyncResult(t.id, app=app)
# 此时的这个t和async_result之间是等价的
# 两者都是AsyncResult对象, 它们所拥有的方法也是一样的, 下面用谁都可以
while True:
import time
if async_result.successful(): # 等价于async_result.state == "SUCCESS"
print(async_result.get())
break
elif async_result.failed(): # 等价于async_result.state == "FAILURE"
print("任务执行失败")
elif async_result.status == "PENDING":
print("任务正在被执行")
elif async_result.status == "RETRY":
print("任务执行异常正在重试")
elif async_result.status == "REJECTED":
print("任务被拒绝接收")
elif async_result.status == "REVOKED":
print("任务被取消")
else:
print("其它的一些状态")
time.sleep(0.8)
"""
任务正在被执行
任务正在被执行
任务正在被执行
任务正在被执行
name is 古明地觉, age is 17
"""
我们看到任务的状态主要有上面这几种,当然AsyncResult还有一些方法,我们来看一下:
from task import task
# 我们通过t来调用也是一样的, 因为它也是个AsyncResult对象
t = task.delay("古明地觉", 17)
# 1. ready():查看任务状态,返回布尔值。任务执行完成返回True,否则为False
# 那么它和successful()有什么区别呢? successful()是在任务执行成功之后返回True, 否则返回False
# 而ready()只要是任务没有处于阻塞状态就会返回True, 比如执行成功、执行失败、被worker拒收都看做是执行完了
print(t.ready()) # False
# 2. wait():和之前的get一样, 在源码中写了: wait = get, 所以调用哪个都可以, 不过wait可能会被移除
# 所以直接用get就可以
# 3. trackback:如果任务抛出了一个异常,可以获取原始的回溯信息
# 执行成功就是None
print(t.traceback) # None
celery的配置
celery的配置不同,所表现出来的性能也不同,比如序列化的方式、连接队列的方式,单线程、多线程、多进程等等。那么celery都有那些配置呢?
-
BROKER_URL:代理人的地址,就是Celery里面传入的broker。
-
CELERY_RESULT_BACKEND:结果存储的地址,就是Celery里面传入的backend。
-
CELERY_TASK_SERIALIZER:任务序列化方式,支持以下几种:
1. binary:二进制序列化方式,python的pickle默认的序列化方法。
2. json:支持多种语言,可解决扩语言的问题,但好像不支持自定义类。
3. XML:标签语言。
4. msgpack:二进制的类json序列化,但比json更小、更快。
5. yaml:表达能力更强、支持的类型更多,但是在python下性能不如json。
根据情况,选择合适的类型。如果不是跨语言的话,直接选择binary即可,默认是json。
-
CELERY_RESULT_SERIALIZER:任务执行结果序列化方式,支持的方式和任务序列化方式一致。
-
CELERY_TASK_RESULT_EXPIRES:任务结果的过期时间,单位是秒。
-
CELERY_ACCEPT_CONTENT:指定任务接受的内容序列化类型(序列化),一个列表,比如:["msgpack, binary, json"]。
-
CELERY_TIMEZONE:时区,默认是UTC时区。
-
CELERY_ENABLE_UTC:如果为False,则使用本地时区,默认是True,使用UTC时区。
-
CELERY_TASK_PUBLISH_RETRY:发送消息失败时是否重试,默认是True。
-
CELERY_CONCURRENCY:并发的worker数量。
-
CELERY_PREFETCH_MULTIPLIER:每次worker从任务队列中获取的任务数量。
-
CELERY_MAX_TASKS_PER_CHILD:每个worker执行多少次就会被杀掉,默认是无限的。
-
CELERY_TASK_TIME_LIMIT:单个任务执行的最大时间,单位是秒。
-
CELERY_DEFAULT_QUEUE :设置默认的队列名称,如果一个消息不符合其他的队列就会放在默认队列里面,如果什么都不设置的话,数据都会发送到默认的队列中。
-
CELERY_QUEUES :设置详细的队列。
# 这些是将RabbitMQ作为broker的时候需要使用的 CELERY_QUEUES = { "default": { # 这是上面指定的默认队列 "exchange": "default", "exchange_type": "direct", "routing_key": "default" }, "topicqueue": { # 这是一个topic队列 凡是topictest开头的routing key都会被放到这个队列 "routing_key": "topic.#", "exchange": "topic_exchange", "exchange_type": "topic", }, "task_eeg": { # 设置扇形交换机 "exchange": "tasks", "exchange_type": "fanout", "binding_key": "tasks", }, }
尽管配置有很多,但并不是每一个都要用,可以根据自身的业务合理选择。
然后下面我们就根据配置文件的方式启动celery,另外我们需要单独创建一个目录,然后在里面写相应的文件,这个目录就叫app吧,目录结构如下:
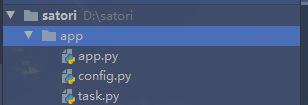
app/config.py
BROKER_URL = "redis://47.94.174.89:6379/1"
CELERY_RESULT_BACKEND = 'redis://47.94.174.89:6379/2'
# 写俩就完事了
app/task.py
# 这个task.py不再是之前的task.py了,这个task.py用于专门定义一些创建任务工厂的函数
def add(x, y):
return x + y
def sub(x, y):
return x - y
app/app.py
from celery import Celery
from . import config
from .task import add, sub
# 只需要执行一个celery name即可, 其它参数不需要指定了
app = Celery(__name__)
# 通过加载配置文件的方式制定
app.config_from_object(config)
"""
我们看到这跟flask不是一毛一样的嘛, 所以我们之前的文件名叫做task.py实际上不太合适
应该叫做app.py才对
"""
# 然后我们启动worker的时候肯定启动这个app.py, 那么必须要把任务工厂放到这里面来
# 这种方式和装饰器的方式是等价的
add = app.task(add)
sub = app.task(sub)
然后启动worker:
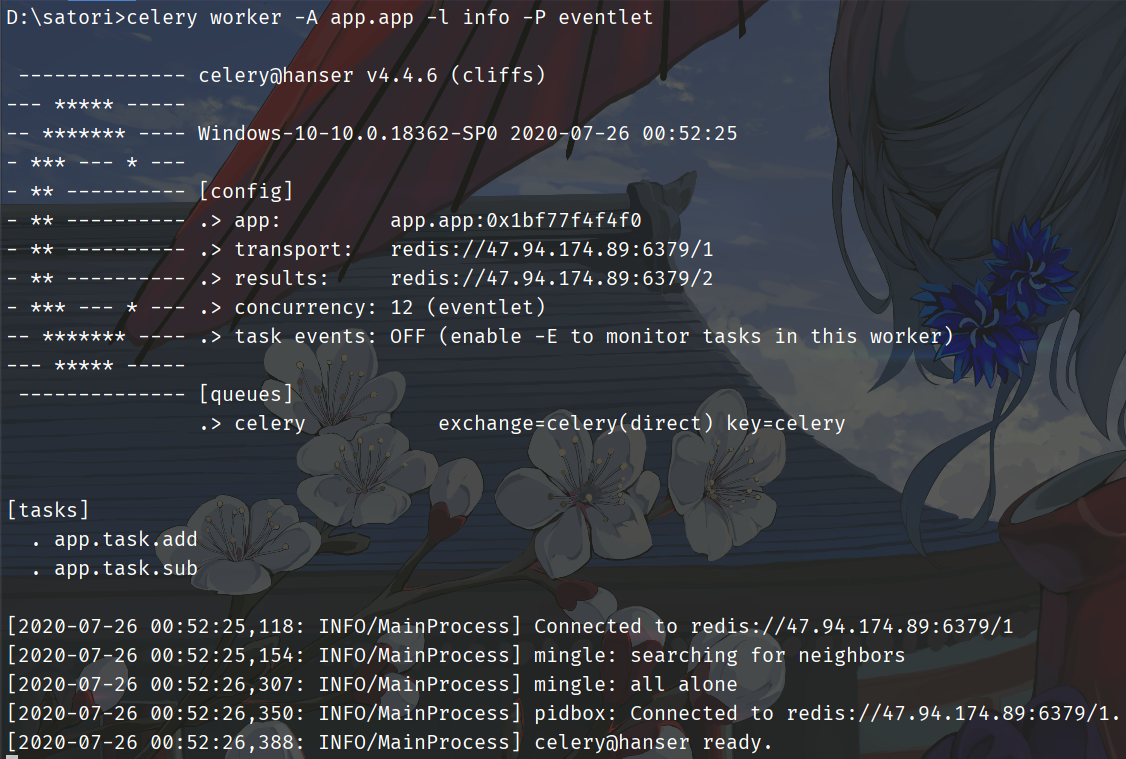
注意:原来的task要改成app.app,此外我们不可以进入到app目录下启动worker,可能有人觉得是不是在app目录下,可以不用app.app、直接app就行了呢?答案是不行的,因为我们在里面使用了相对导入,所以必须在app目录的外面才行。
此外我们看到,task里面的任务已经被加载进行来了,然后我们来发送任务。
from app.app import add, sub
print(add.delay(2, 3).get()) # 5
print(add.delay(3, 2).get()) # 5
print(sub.delay(2, 3).get()) # -1
print(sub.delay(3, 2).get()) # 1

多个任务被执行了。
发送任务时可以指定的参数
我们在发送任务给worker的时候,使用的是task.delay()方法,里面直接传递函数所需的参数即可,那么除了函数需要的参数之外,还有没有其它参数呢?
首先task.delay实际上调用了task.apply_async,这个delay里面虽然只接收函数的参数,但是apply_async接收的参数就很多了,我们先来看看它们的函数定义:
def delay(self, *args, **kwargs):
# *args和**kwargs是函数的参数
# 所以delay实际上是下面的apply_async别名,但是接收的参数很简单
return self.apply_async(args, kwargs)
def apply_async(self, args=None, kwargs=None, task_id=None, producer=None,
link=None, link_error=None, shadow=None, **options):
# delay接收的参数会直接传给这里的args和kwargs
# 而其它的参数就是发送任务时所设置的一些参数,我们这里重点介绍一下apply_async的其它参数
args:函数的位置参数kwargs:函数的关键字参数countdown: 倒计时,表示多少秒后执行,参数为整型eta:任务的开始时间,datetime类型,如果指定了countdown,那么这个参数就不应该再指定expires:datetime或者整型,如果到规定时间、或者未来的多少秒之内,任务还没有发送到队列被worker执行,那么app.py里面指定的任务将被丢弃。shadow:重新指定任务的名称,覆盖app.py创建任务时日志上所指定的名字retry:任务失败之后是否重试,bool类型retry_policy:重试所采用的策略,如果指定这个参数,那么retry必须要为True。参数类型是一个字典,里面参数如下max_retries : 最大重试次数, 默认为 3 次interval_start : 重试等待的时间间隔秒数, 默认为 0 , 表示直接重试不等待interval_step : 每次重试让重试间隔增加的秒数, 可以是数字或浮点数, 默认为 0.2interval_max : 重试间隔最大的秒数, 即 通过 interval_step 增大到多少秒之后, 就不在增加了, 可以是数字或者浮点数, 默认为 0.2
routing_key:自定义路由键,针对于rabbitmqqueue:指定发送到哪个队列,针对于rabbitmqexchange:指定发送到哪个交换机,针对于rabbitmqpriority:任务队列的优先级,0-9之间,对于RabbitMQ而言,0是最高级serializer:任务序列化方法;通常不设置compression:压缩方案,通常有zlib, bzip2headers:为任务添加额外的消息;link:任务成功执行后的回调方法;是一个signature对象;可以用作关联任务;link_error: 任务失败后的回调方法,是一个signature对象;
我们随便挑几个举例说明:
from app.app import add
# 使用apply_async, 参数位置参数就要通过元组或者列表传递
# 关键字参数需要通过字典传递, 因为是args和kwargs, 不是*args和**kwargs
print(add.apply_async([1], {"y": 2}, task_id="琴肥梦", countdown=5).get()) # 3

我们看到一个神奇的事情,日志上显示的是7月26号,但是任务的执行时间显示的是7月25号,原因就在于日志上的时间是我本地的时间,而任务的执行时间是UTC时间。因为上海位于东八区,比如UTC快了八小时,我们如果只看秒钟的话,发现是33秒收到任务,但是执行时间显示的是38秒执行,原因就是我们指定了countdown=5,此外这个id也变成了我们指定的id。
另外还需要注意一下那些接收时间的参数,比如eta。如果我们手动指定了eta,那么这个时间一定要注意,要么你在celery的配置中指定时区为Asia/Shanghai,要么你给eta参数传递一个utc时区的datetime,总之celery所使用的时区和你传递的datetime的时区要统一。比如:你传递了2020-7-26 9:30:30,但这是上海时区,而celery会当成是utc时区,所以任务执行的时候你所在地区的时间是2020-7-26 17:30:30,这与我们的预期是不符合的,因此时区一定要对应,最好在celery配置当中指定好时区。
其它的参数可以自己手动测试一下,这里不细说了,根据自身的业务选择合适参数即可。
创建任务工厂的另一种方式
我们之前在创建任务工厂的时候,是通过将函数导入到app.py中,然后通过手动装饰器add = app.task(add)的方式,因为都有哪些任务工厂必须要让worker知道,所以一定要在app.py里面出现。但是这显然不够优雅,那么可不可以这么做呢?
# task.py
from .app import app
@app.task
def add(a, b):
return f"a + b = {a + b}"
@app.task
def sub(a, b):
return f"a - b = {a - b}"
# app.py
from .task import add, sub
按照上面这种做法,理想上可以,但现实不行,因为会发生循环导入。
所以celery给我们提供了一个办法,我们在task.py中依旧导入app,但是在app中我们不导入task,而是通过include加载的方式,我们看一下:
# task.py
from .app import app
@app.task
def add(x, y):
return x + y
@app.task
def sub(x, y):
return x - y
# app.py
from celery import Celery
from . import config
# 直接在include写入存放任务的py文件的名字即可, 当然我们是在app目录外面启动的, 所以是app.task
app = Celery(__name__, include=["app.task"])
# 如果还有其它文件,比如有一个新的目录tasks
# 里面有四个文件task1.py, task2.py, task3.py, task4.py, 因为任务很多的话需要写在多个文件里面
# 那么include里面就写上["app.tasks.task1", "app.tasks.task2", "app.tasks.task3", "app.tasks.task4"]
# 我们这里的task.py和app.py在同一个目录,所以include里面直接写上"app.task"即可
app.config_from_object(config)
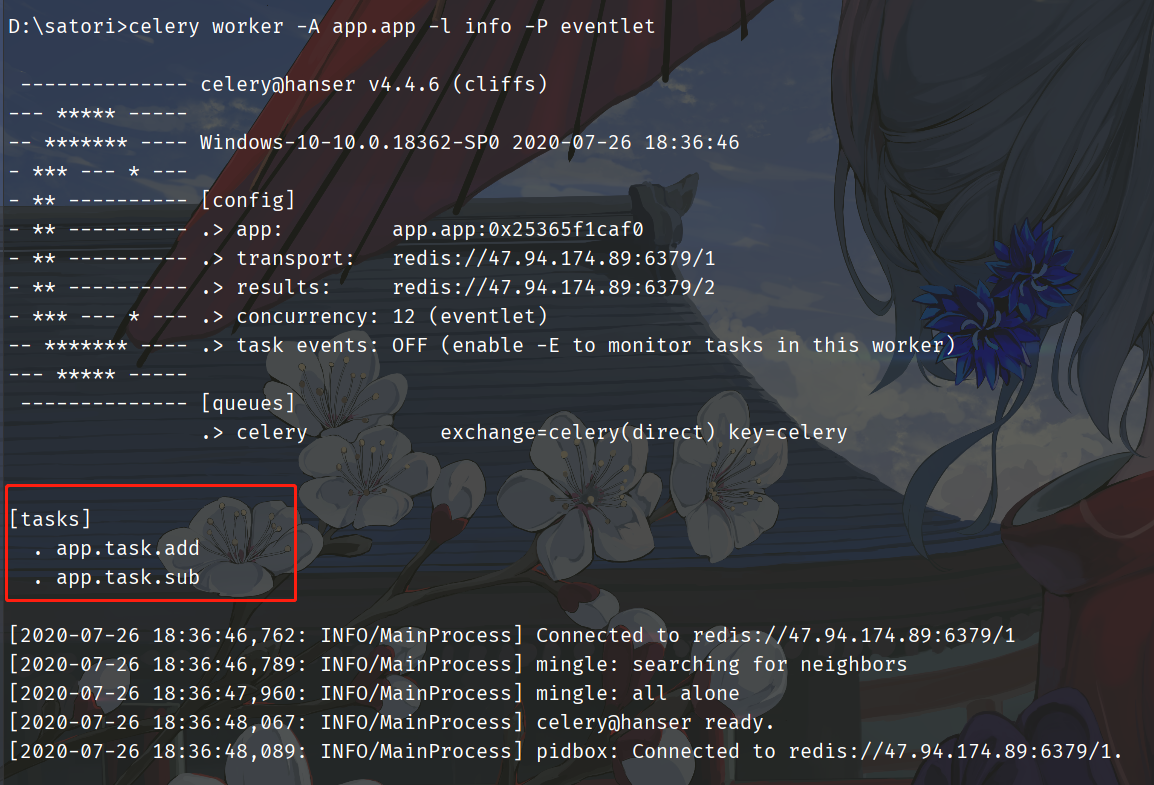
我们看到成功启动了,下面发送任务交给worker执行。

可以看到这样就方便多了,之前的话是在task.py中定义函数,然后把task.py中的函数导入到app.py里面,然后手动调用装饰器,但是这样肯定不适合管理。所以将app.py中的app导入到task.py中直接创建任务工厂,但是如果task.py中的任务工厂在导入了app.py中就会发生循环导入,于是celery提供了一个include参数,可以让我们直接写上相应的py文件,会自动把里面所有的任务工厂加载进来,然后启动worker的时候能够告诉worker有哪些任务工厂。
Task
我们之前通过对一个函数使用@app.task即可将其变成一个任务工厂,而这个任务工厂对应的就是一个Task对象。我们在使用@app.task的时候,其实是可以加上很多的参数的,常用参数如下:
name:默认的任务名是一个uuid,我们可以通过name参数指定任务名,当然这个name就是apply_async中的name,如果在apply_async中指定了,那么以apply_async中指定的为准。bind:一个bool值,表示是否绑定一个task的实例,如果绑定,task实例会作为参数传递到任务方法中,可以访问task实例的所有属性。base:定义任务的基类,用于定义回调函数,当任务到达某个状态时触发不同的回调函数,默认是Task,所以我们一般会自己写一个类然后继承Task。default_retry_delay:设置该任务重试的延迟机制,当任务执行失败后,会自动重试,单位是秒,默认是3分钟。serializer:指定序列化的方法。
当然task还有很多不常用的参数,这里就不说了,有兴趣可以去查看官网,这里演示一下几个常用的参数:
# task.py
from .app import app
@app.task(name="哈哈哈")
def add(a, b):
return f"a + b = {a + b}"
@app.task(name="嘎嘎嘎", bind=True)
def sub(self, a, b):
"""我们这里的self是<class 'celery.app.task.sub'>对象
没错,celery根据函数名创建了一个类
"""
print("self:", self)
# self.request存储了相应的属性
print("self.request:", self.request)
# 获取name
print("name:", self.name)
return f"a - b = {a - b}"
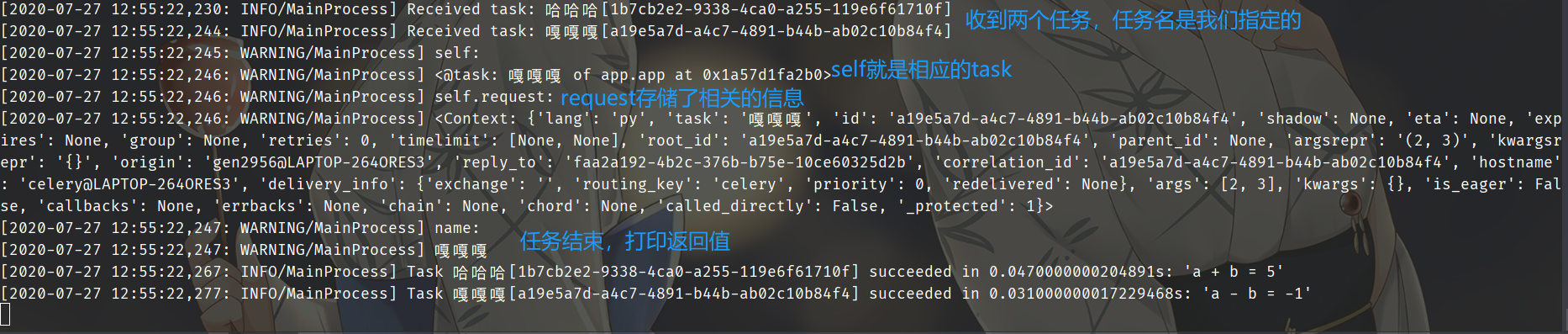
self都能获取哪些属性,我们可以通过Task这个类来查看,因此sub函数里面的self就是对应的Task实例。
下面重点说一下@app.task里面的base参数:
# task.py
from .app import app
from celery import Task
class MyTask(Task):
"""自定义一个类,继承自celery.Task"""
"""
exc:失败时的错误的类型;
task_id:任务的id;
args:任务函数的参数;
kwargs:参数;
einfo:失败时的异常详细信息;
retval:任务成功执行的返回值;
"""
def on_failure(self, exc, task_id, args, kwargs, einfo):
"""任务失败时执行"""
def on_success(self, retval, task_id, args, kwargs):
"""任务成功时执行"""
print("任务执行成功")
def on_retry(self, exc, task_id, args, kwargs, einfo):
"""任务重试时执行"""
# 在使用app.task的时候,指定base即可
# 然后任务在执行的时候,会触发MyTask里面的回调函数
@app.task(name="憨八嘎", base=MyTask)
def add(x, y):
print("加法计算")
return x + y

另外我们这里只启动了一个worker,worker是可以启动很多个的。
自定义任务流
# task.py
from .app import app
@app.task()
def add(x, y):
print("加法计算")
return x + y
@app.task()
def sub(x, y):
print("减法计算")
return x - y
@app.task()
def mul(x, y):
print("乘法计算")
return x * y
@app.task()
def div(x, y):
print("除法计算")
return x // y
我们来导入这几个任务:
from app.task import add, sub, mul, div
from celery import group
# 可以调用signature方法,变成一个signature对象
# 此时调用t1.delay和直接调用add.delay之间是等价的, 当然参数要在signature中设置好
t1 = add.signature(args=(2, 3))
t2 = sub.signature(args=(2, 3))
t3 = mul.signature(args=(2, 3))
t4 = div.signature(args=(4, 2))
# 但是变成signature对象之后,我们可以将其当成一个组来执行
gp = group(t1, t2, t3, t4)
# 执行组任务,返回一个<class 'celery.result.GroupResult'>对象
res = gp()
print("组id:", res.id) # 组id: 0eb91aef-ea48-4a6a-bd3e-9cddaa80889e
print("组结果:", res.get()) # 组结果: [5, -1, 6, 2]
"""
可以看到整个组是有唯一的id的。
另外signature也可以写成,subtask或者s,在源码里面这几个是等价的,净搞这么多花里胡哨的。
"""
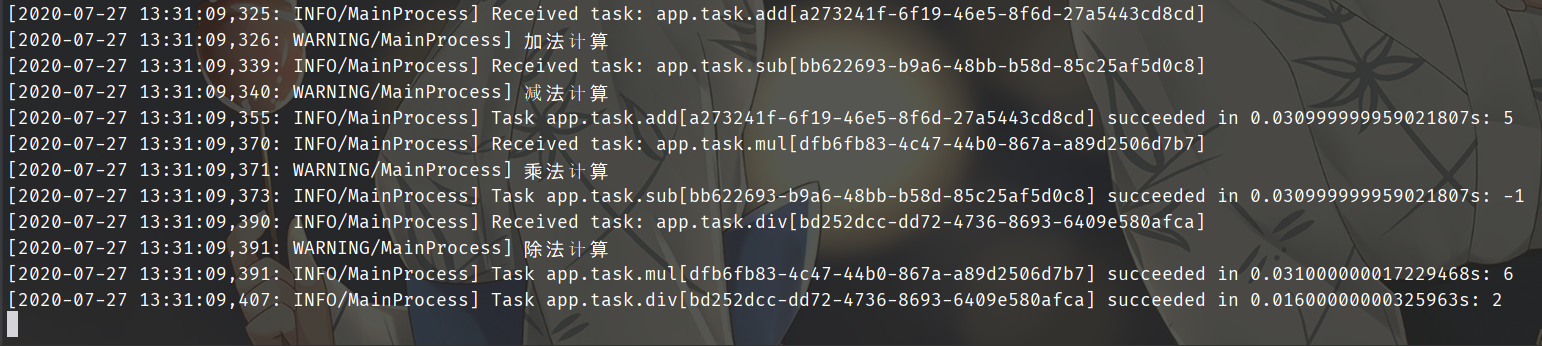
除此之外,一个任务的返回值还可以作为另一个任务的参数。将多个任务像链子一样串起来,第一个任务的输出会作为第二个任务的输入,会传递给下一个任务的第一个参数
# task.py
from .app import app
@app.task
def task1():
l = []
return l
@app.task
# task1的返回值会传递给这里的task1_return
def task2(task1_return, value):
task1_return.append(value)
return task1_return
@app.task
def task3(task2_return, num):
return [i + num for i in task2_return]
@app.task
def task4(task4_return):
return sum(task4_return)
from app.task import *
from celery import chain
# 将多个signature对象作为一个列表传进去
my_chain = chain(task1.s() | task2.s(123) | task3.s(5) | task4.s())
# 整个过程等价于[123+5]
# 执行任务链
res = my_chain()
# 获取最终返回值
print(res.get()) # 128
celery实现定时任务
既然是定时任务,那么就意味着worker要后台启动,否则一旦远程连接断开,就停掉了。因此celery是支持我们是可以后台启动的,并且可以启动多个,我们注意到此时没有 -P eventlet,这是因为我们不在windows下启动,原因是windows下不支持这种启动方式。
celery multi start -A app w1 -l info
celery multi start -A app w2 -l info
celery multi start -A app w3 -l info
...
...
停止的话就是
celery multi stop -A app w1 -l info
celery multi stop -A app w2 -l info
celery multi stop -A app w4 -l info
...
...
为了演示,就在windows下前台启动。我们之前在介绍celery架构的时候,提到过一个celery beat,这个是调度器,是自动将任务添加到队列里面去执行的。这里我们新建一个tasks目录,里面有两个文件,一个是task.py,一个period_task.py。
# task.py
from ..app import app
@app.task
def task1():
print("我是task1")
return "task1你好"
@app.task
def task2(name):
print(f"我是{name}")
return f"{name}你好"
@app.task
def task3():
print("我是task3")
return "task3你好"
@app.task
def task4(name):
print(f"我是{name}")
return f"{name}你好"
# period_task.py
from celery.schedules import crontab
from ..app import app
from .task import task1, task2, task3, task4
@app.on_after_configure.connect
def 设置定时任务(sender, **kwargs):
# 第一个参数为schedule,可以是一个float,也可以是一个crontab
# crontab后面会说,第二个参数是任务,第三个参数是名字
sender.add_periodic_task(10.0, task1.s(), name="每10秒执行一次")
sender.add_periodic_task(15.0, task2.s("task2"), name="每15秒执行一次")
sender.add_periodic_task(20.0, task3.s(), name="每20秒执行一次")
sender.add_periodic_task(
crontab(hour=18, minute=5, day_of_week=0),
task4.s("task4"),
name="每个星期天的18:05运行一次"
)
# config.py
BROKER_URL = "redis://47.94.174.89:6379/1"
CELERY_RESULT_BACKEND = 'redis://47.94.174.89:6379/2'
# 之前说过,celery默认使用utc时间,其实我们是可以手动禁用的,然后手动指定时区
CELERY_ENABLE_UTC = False
CELERY_TIMEZONE = 'Asia/Shanghai'
# app.py
from celery import Celery
from . import config
app = Celery(__name__, include=["app.tasks.task", "app.tasks.period_task"])
app.config_from_object(config)
下面就来启动任务:
启动worker:celery worker -A app.app -l info -P eventlet
启动beat:celery beat -A app.tasks.period_task -l info,启动worker是celery worker,
启动beat则是celery beat,app.tasks.period_task就是我们的定时任务对应的py文件名
由于是在tasks目录里面,因此需要指定app.tasks.period_task
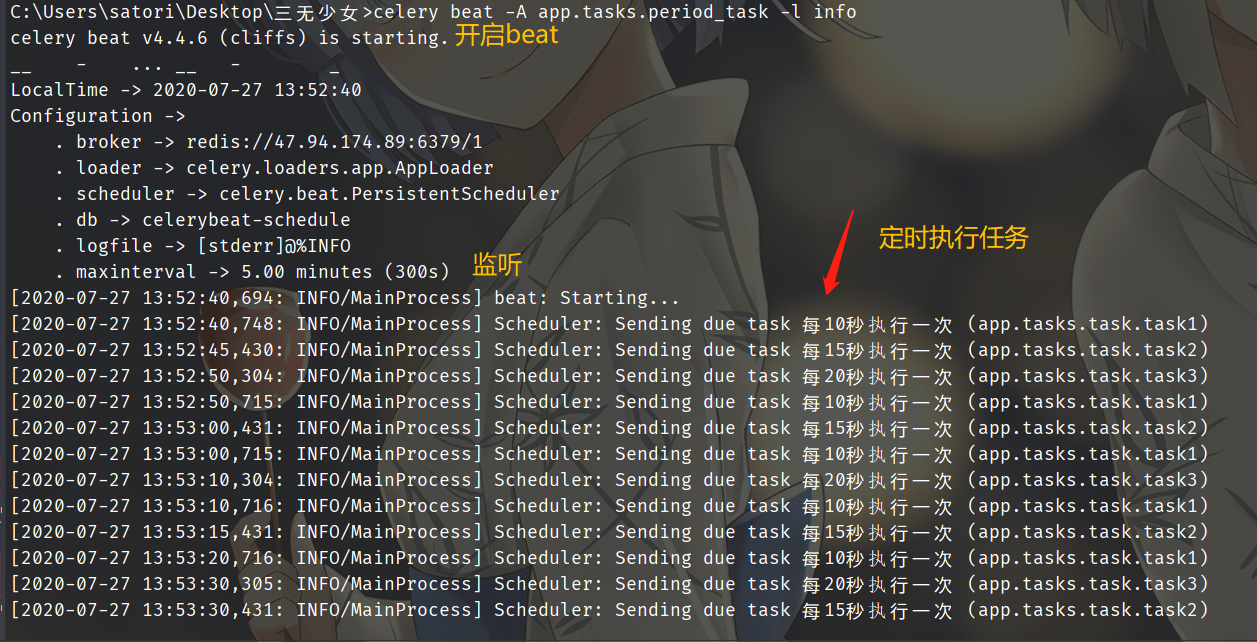
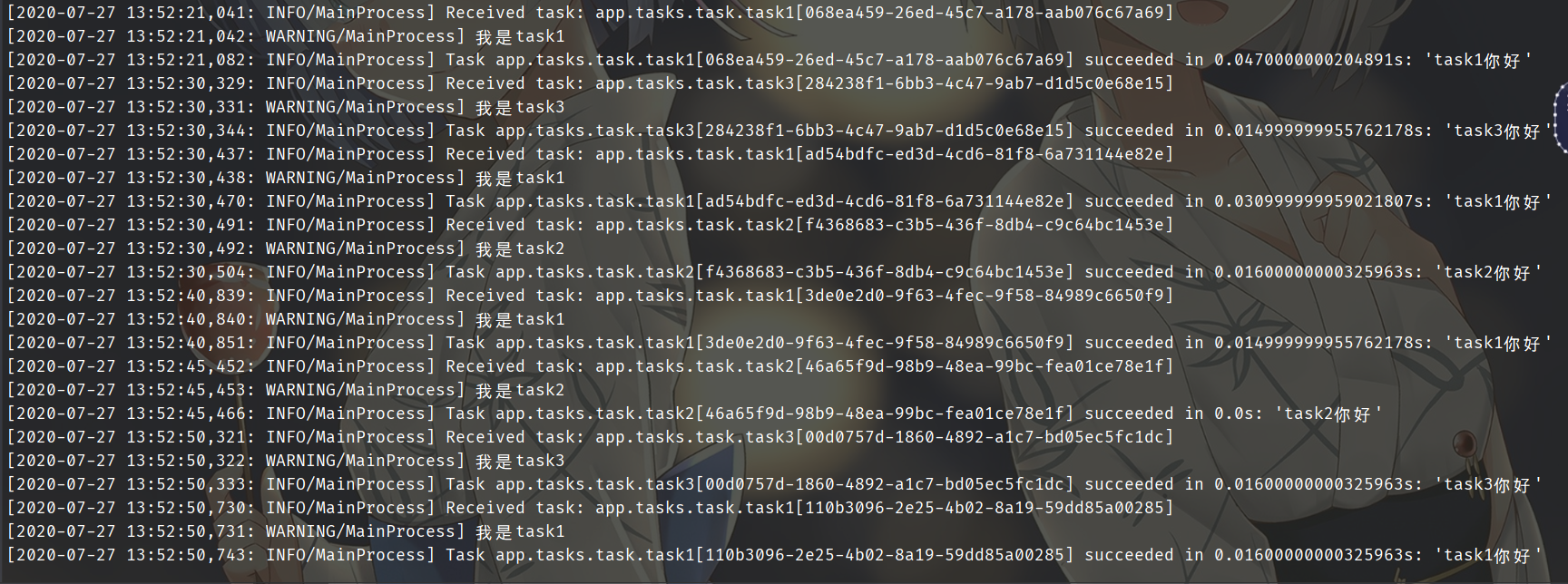
可以看到,此时定时任务就正常的启动了。另外我们刚才是通过设置函数、打上装饰器的方式实现的,我们还可以通过配置的方式实现。
from celery.schedules import crontab
from ..app import app
from .task import task1, task2, task3, task4
# @app.on_after_configure.connect
# def aaa(sender, **kwargs):
# sender.add_periodic_task(10.0, task1.s(), name="每10秒执行一次")
# sender.add_periodic_task(15.0, task2.s("task2"), name="每15秒执行一次")
# sender.add_periodic_task(20.0, task3.s(), name="每20秒执行一次")
# sender.add_periodic_task(
# crontab(hour=18, minute=5, day_of_week=0),
# task4.s("task4"),
# name="每个星期天的18:05运行一次"
# )
app.conf.beat_schedule = {
"每10秒执行一次": {"task": "task1", "schedule": 10.0},
"每15秒执行一次": {"task": "task2", "schedule": 15.0, "args": ("task2", )}, # 参数通过args和kwargs指定
"每20秒执行一次": {"task": "task3", "schedule": 20.0},
"每个星期天的18:05运行一次": {"task": "task4",
"schedule": crontab(hour=18, minute=5, day_of_week=0),
"args": ("task4", )}
}
# 上面定义定时任务的方式,可以下面配置的方式替代。
这种启动方式依旧是可以成功的,另外目录里面会多出几个文件,这是用来存储配置信息的。
crontab参数
@python_2_unicode_compatible
class crontab(BaseSchedule):
def __init__(self, minute='*', hour='*', day_of_week='*',
day_of_month='*', month_of_year='*', **kwargs):
上面是crontab对应的初始化函数:
minute:0-59,表示第几分钟触发,*表示每分钟触发一次hour:0-23,第几个小时触发,*表示每小时都会触发,比如:minute=2,hour=*,那么表示每小时的第二分钟触发一次day_of_week:一周的第几天,0-6,0是星期天,1-6分别是星期一到星期六,不习惯的话也可以用mon,tue,wed,thu,fri,sat,sun表示day_of_month:一个月的第几天month_of_year:当前年份的第几个月
通配符:
*:所有,比如minute=*,表示每分钟触发*/a:所有可被a整除的时候触发a-b:a到b范围内触发a-b/c:范围a-b且能够被c整除的时候触发2,10,40:比如minute=2,10,40表示第2、10、40分钟的时候触发
通配符之间是可以自由组合的,比如'*/3,8-17'就表示能被3整除,且范围处于8-17的时候触发。
天色:
是的,你没有看错,还可以根据天色来设置定时任务
from celery.schedules import solar
app.conf.beat_schedule = {
"日落": {"task": "task1",
"schedule": solar("sunset", -37.81753, 144.96715)
},
}
solor里面接收三个参数:
-
eventdawn_astronomical:天还未亮的时候,太阳在地平线下18度dawn_nautical:地平线有充足的阳光并且可以看清一些东西,太阳在地平线下12度dawn_civil:有充足的阳光并且可以看清东西、开始户外活动,太阳在地平线下6度sunrise:太阳的上边缘,出现在东方地平线上solar_noon:一天中太阳距离地平线最高的位置sunset:傍晚太阳的上边缘消失在西方地平线上dusk_civil:黄昏的尽头,还能看得见东西,太阳在地平线下6度dusk_nautical:已看不清东西,太阳在地平线下12度dusk_astronomical:天完全黑的时候,太阳在地平线下18度
-
lat:纬度大于0:南纬小于0:北纬
-
lon:经度大于0:东经小于0:西经
celery+rabbitmq
celery除了可以搭配Redis之外,还可以使用rabbitmq,我们只需要将broker换成rabbitmq即可。
# config.py
BROKER_URL = "amqp://admin:123456@47.94.174.89:5672"
# 但是结果存储的话还是使用Redis,或者数据库也可以。
CELERY_RESULT_BACKEND = 'redis://47.94.174.89:6379/2'
不想写了。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号