(更新中)HBase:大数据中的NoSQL
楔子
下面我们来学习一下HBase,我们说 Google 有三驾马车:GFS、MapReduce、BigTable,奠定了整个大数据的根基,而 HBase 便是基于 BigTable 而诞生的。那么 HBase 到底是什么呢?下面就来学习一下 HBase 吧。
HBase 简介
HBase 定义
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库。
所以使用 HBase 首先要保证数据量大,如果数据量不大的话使用 HBase 其实不划算的,因为 HBase 还是比较耗资源的。有的公司一开始就使用 HBase,结果没一段时间又给换掉了,但如果你的数据量很大,使用 HBase 就会有明显的优势,因为 HBase 是可以在几十亿条数据中做到秒级查询的。
再回忆一下 HDFS,我们说 HDFS 不支持随机写操作,但是 HBase 是支持的。因为 HBase 是一个 NoSQL,它是支持数据的增删改查的,但 HBase 的数据存储基于 HDFS,那么它是怎么做到的呢?
如果让你实现 HDFS 的随机写操作的话,要怎么实现呢?最直观的想法就是,将文件下载下来,然后进行修改,再将 HDFS 上文件删掉,重新上传。没错,HBase 就是这么干的,可能有人好奇了,如果这么做的话速度应该不可能这么快吧。所以 HBase 在底层做了很多的优化,有很多其它的组件在帮它做这些事情,所以它比较耗资源。具体我们后面会一点一点介绍,到时候也会明白 HBase 是如何实现在几十亿条数据中做到秒级查询的。
HBase 数据模型
逻辑上 HBase 的数据模型和关系型数据库很类似,数据存在一张表中,有行有列。但从 HBase 的底层物理存储结构来看,HBase 更像是一个 multi-dimension map(多维度map)。所以 HBase 在底层存储上,和传统的关系型数据库还是不一样的,不然就没必要单独拿出来说了。
HBase 数据逻辑结构:
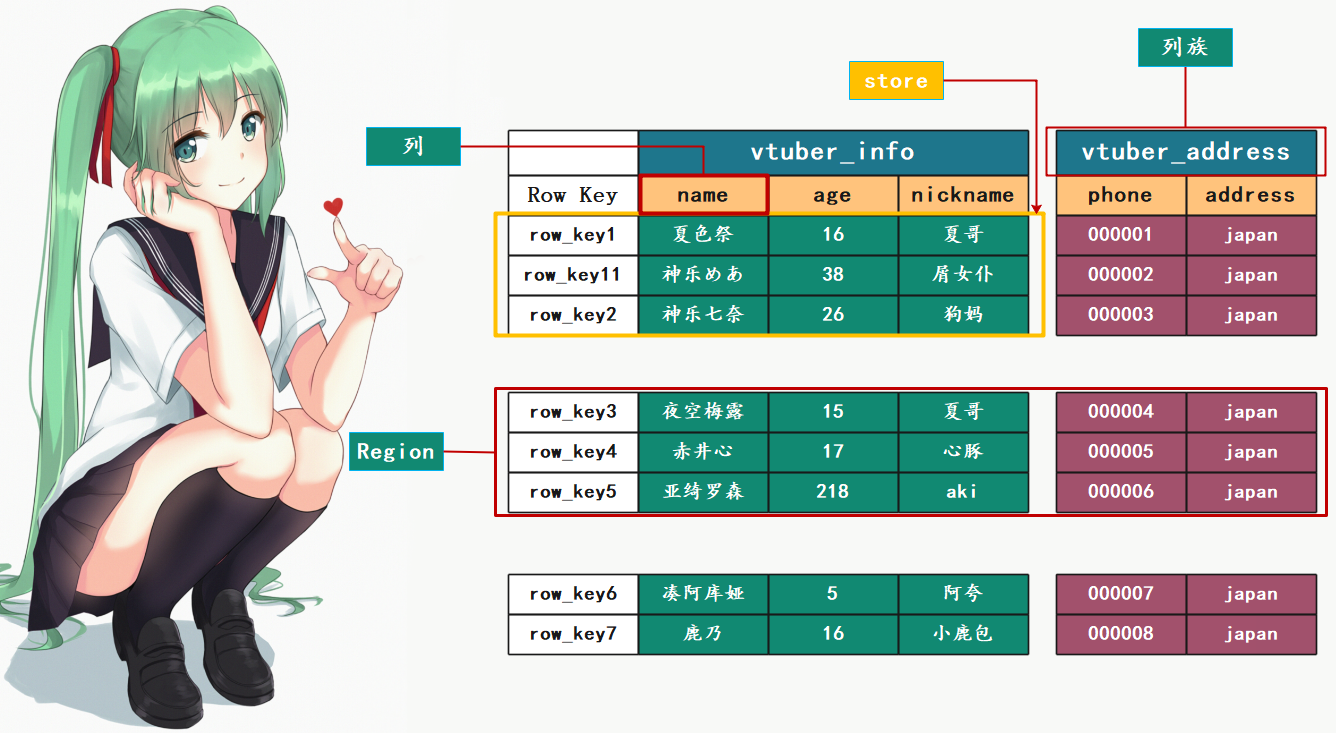
我们说逻辑上数据模型和关系型数据库类似,确实如此。首先是列:name、age、nickname、phone、address它们都属于列,但是除了列之外我们还看到了一个新的东西:列族。将多个列按照特征归为一类,便是列族,比如图中的:vtuber_info、vtuber_address,这个列族会影响到数据的存储,因为不同的列族对应的数据存在不同的目录中。所以 HBase 中的一个表会对应多个目录,而具体怎么对应则取决于列族。
列族中可以只有一个列,可以有上百个列,而且列族中的列可以动态增加。
然后是 Row Key(行键),这个是必须有的,它类似于关系型数据库中的主键。而且排序的时候是按照字典序来排的。
另外图中整体是一张表,但是我们看到这张表貌似有点支离破碎的样子,感觉像是被横着切了两刀,竖着又切了一刀。没错,横着切是按照 Row Key 切的,竖着切是按照 列族 切的。
想象一下关系型数据库中的高表和宽表,如果数据量非常大是不是要横向切分呢?字段非常多是不是要垂直切分呢?HBase与之同理,显然HBase中的表即是高表又是宽表,因为它数据量非常大,字段非常多。
而横向切分得到的每一个切片叫做一个 Region,显然图中有 三个 Region。这也类似于 Hive 中的分区表,查找的时候只需要到指定的某一切片中查找即可,避免扫描全表。
最后一个概念是 store,显然它是存放的实际数据,这些数据是存放在 HDFS 上的。问题来了,图中有几个 store 呢?显然是 6 个,因为有 6 块嘛。
而列名等信息在存放在内存中,因为它是元数据。
HBase 物理存储结构:
我们说虽然在逻辑上,HBase 的数据模型和关系型数据库很类似,但是在实际的物理存储上,可谓是千差万别。

我们这些实际数据是要放在 HDFS 中的,尽管数据模型和关系型数据库很类似,但是它在存储方面却不是这样的。

我们看到在数据存储方面还是有很大差别的,Row Key不用说,Column Family 是列族,Column Qualifier是列名,Value则对应具体的值。等于说模型中的每一个单元格都是单独的一行,当然图中只相当于模型中的一条数据,但是我们看到多了两列:TimeStamp 和 Type。
Type表示操作的类型,Put相当于往里面放入数据。而TimeStamp表示时间戳,但是这个时间戳不单单是为了表示记录插入的时间,HBase能实现HDFS的随机写操作,完全是基于这个时间戳来的,HBase的优化也在这,后面详细聊。
然后我们看图中的最后两条数据,我们发现只有时间戳和值不一样,很明显,这里相当于对 Row Key 为 row_key1、列为 nickname 的值进行了修改。所以这里的修改就是再 Put 一条进去,然后查找的时候选择时间戳最大的即可。
那么删除怎么办呢?很简单,不是有一个Type吗?如果删除的话,还是插入一条数据,但是将Type对应的值改成Delete即可。查找的时候依旧查找时间戳最大的,如果发现Type是Delete,那么就不返回数据。所以 HBase 是通过这种手法实现的,数据相当于是一个逻辑删除,反正对于用户而言数据确实删掉了,因为不返回了嘛。当然数据最终肯定也是要被物理删除的,只不过并不是当时就删掉,否则 HBase 的速度不可能这么快。
至于到底什么时候删,我们后面聊,到后面你会发现HBase操作数据实际上就是一个合久必分、分久必合的过程。
因此这个时间戳就类似于版本,所以在使用HBase的时候,时间是很重要的。后面我们会在Windows上使用Python去操作,而HBase部署在Linux服务器上,如果这两个时间不一样,那么很容易造成数据删不掉、或者数据不更新等情况。因此在工作中,你电脑的时间和服务器的时间一定要统一。
HBase 数据模型:
1. NameSpace
命令空间,类似于关系型数据的 database,每个命令空间下有多个表。HBase有两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default 是用户默认使用的命名空间。
2. Region
类似于关系型数据库表的概念(如果表记录不多,一个表就是一个Region;记录多的时候,表的一个切片就是一个Region),不同的是,HBase 定义表时只需要声明列族即可,不需要声明具体的列。这意味着,往HBase写入数据时,字段可以 动态、按需 指定。因此和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
3. Row
HBase表中的每行数据都有一个 RowKey 和 多个Column(列)组成,数据是按照RowKey的字典序进行排序的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
4. Column
HBase 中的每个列都由 Column Family 和 Column Qualifier 进行限定,例如:vtuber_info:name,vtuber_info:age 等等。建表时,只需声明列族,而列限定符无需预先定义。
5. TimeStamp
用于标识数据的不同版本,每条数据写入时,如果不指定时间戳,系统会自动为其指定,值为写入HBase的时间。
6. Cell
由
{rowkey, column Family, column Qualifier, timeStamp}唯一确定的单元,cell 中的数据是没有类型的,全部都是以字节码的形式存储。
HBase 基本架构
我们说 HBase 是将数据存储在 HDFS 上的,那么肯定要有相应的服务去做这样一件事情,那么下面就来看看 HBase 的基本架构。
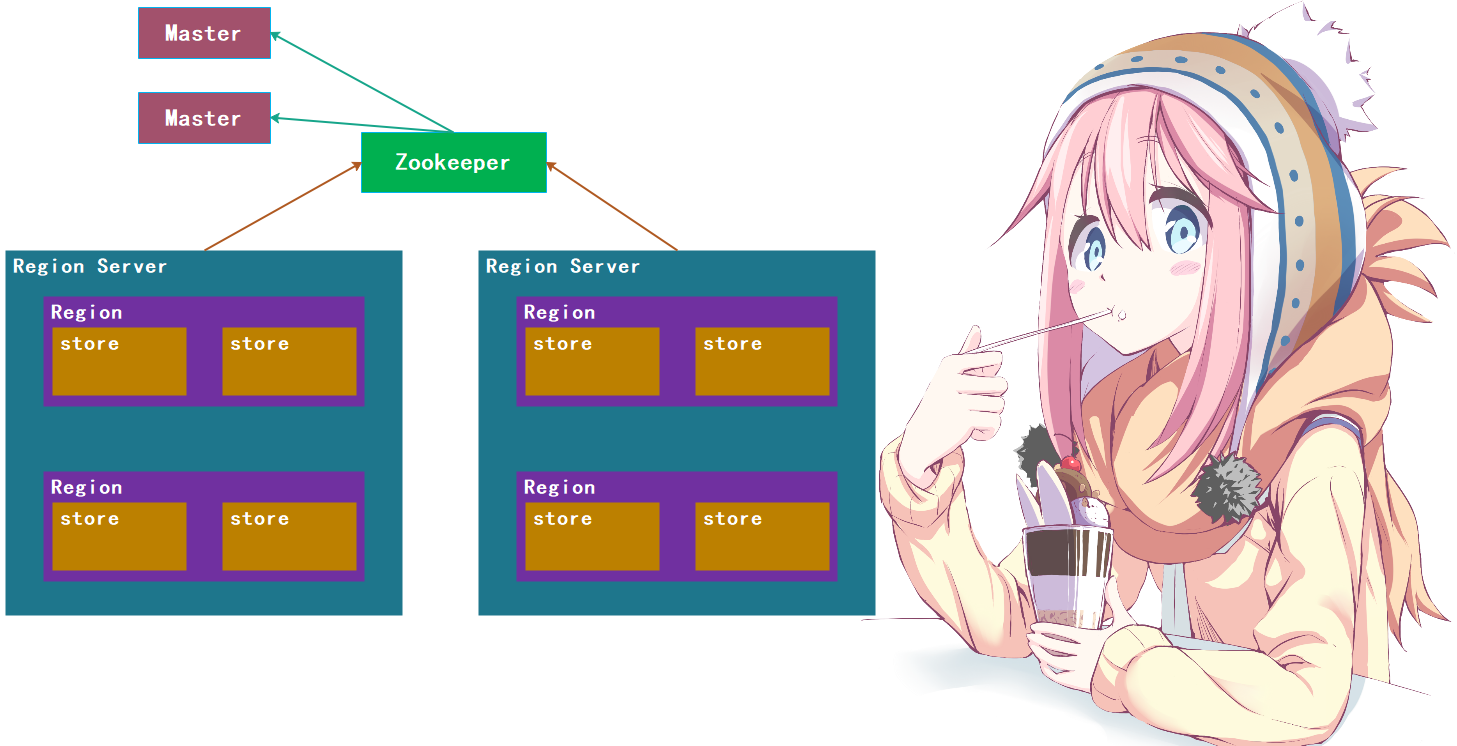
首先 Region 代表的是表的一个切片,里面的 store 则代表的是实际存储的数据,但由于可能不在同一个列族中,所以是多个 store。
然后是 Region Server,首先它可以管理数据,数据我们可以进行 Get、Put、Delete 操作,对应获取、添加、删除,至于修改也是通过 Put 完成的;其实是管理 Region,控制 Region 的切分(splitRegion)、合并(compactRegion),至于怎么分、怎么合,什么时候分、什么时候合,我们后面说。而且 Region Server 是一个分布式的。
接下来是 Master,它类似于 HDFS 的 NameNode,是整个元数据的入口。而且我们看到了 Zookeeper,它是帮助 Master 管理集群,因为 HBase 要做的事情太多了,如果都交给 Master,那么压力会非常大,所以会将一部分任务分摊出去交给ZK。因此在 Master 挂掉的一段时间内,做数据的增删改查是没有问题的,但做表级别的修改就不行了。所以 Master 是做表级别的管理,比如:create、delete、alter等等,其次是管理 Region Server。
因此它们的分工是比较明确的,我们总结一下:
Region Server 的作用:管理Data: Get、Put、Delete管理Region: splitRegion、compactRegion
Master的作用管理Table: create、delete、alter管理Region Server: 分配Region到RegionServer, 监控每个RegionServer的状态
所以 RegionServer 是数据级别的,Master 是表级别的,Master 可以决定每个 Region 要分配到哪个RegionServer上。如果一个 RegionServer挂掉了,那么上面的Region是不是就访问不到了呢?所以Master此时就要将上面的Region调度到其它的RegionServer上,因此Master是负责高层级的工作,而具体和数据打交道的则是RegionServer。
问题来了,我们说RegionServer是分布式的,如果一个挂了,可以将上面的Region转移到另一个RegionServer上。但如果Master挂了,就意味着不能做表级别的修改(数据的修改是可以的),虽然表级别的修改很少,但是显然Master也不能挂。因此Master存在单点故障的,所以它也应该是高可用的。
HBase 的安装
首先 jdk、Hadoop 这些就不说了,我这里已经安装好了,在前面介绍 Hadoop 的博客中已经说过了。
下面来安装 Zookeeper,由于它是 Apache 的一个顶级项目,所以官网是 zookeeper.apache.org,直接去下载即可。这里我下载的是 3.5.8 版本的,上传到阿里云服务器,解压到 /opt 目录下,将里面的 bin 目录配置到环境变量中。
我们安装完毕之后不能直接使用,需要修改一下配置。首先将/opt/apache-zookeeper-3.5.8-bin目录下的zoo_sample.cfg修改为zoo.cfg,直接cp zoo_sample.cfg zoo.cfg即可
然后打开zoo.cfg文件,修改为dataDir=/opt/apache-zookeeper-3.5.8-bin/zkData,主要是为了持久化数据,类似于Hadoop一样,不然重启之后数据就没了。所以还要在/opt/apache-zookeeper-3.5.8-bin下mkdir zkData,当然也可以不叫zkData,叫什么都无所谓。
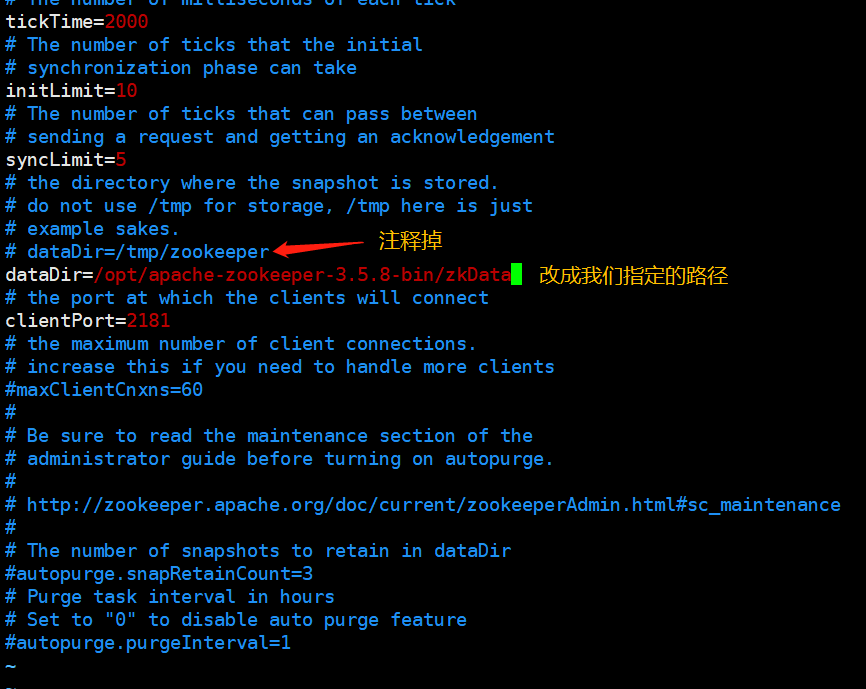
然后启动服务,由于配置了环境变量,所以直接输入 zkServe.sh start 启动即可。
下面我们来安装 HBase,它也是 Apache 的一个顶级项目,所以官网是 hbase.apache.org,但这里我们不使用官方版本,而是CDH版的 HBase。直接去:http://archive.cloudera.com/cdh5/cdh/5/ 页面,找到 hbase-1.2.0-cdh5.15.1.tar.gz,点击下载即可。完毕之后同样解压到 /opt 目录中,将 bin 目录配置到环境变量。
然后修改配置文件,配置文件都位于 conf 目录下,首先修改 hbase-env.sh,加入如下内容:
export JAVA_HOME=/opt/jdk1.8.0_221/
# 表示是否使用HBase内置的zookeeper, 这里改成false, 显然要使用我们自己安装的zk
export HBASE_MANAGES_ZK=false
然后在这个文件里面还有两个配置,我们将其注释掉,当然不注释也无所谓,只是会抛警告。
# Configure PermSize. Only needed in JDK7. You can safely remove it for JDK8+
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
告诉我们只在jdk1.7的时候需要,在1.8的时候可以安全移除。
下面修改hbase-site.xml,到这里我们发现所有的大数据组件不仅目录类似,就连配置文件的名字也是相似的,所以它们都具备统一的格式标准。
<property>
<!-- HBase存放数据的位置, 显然是位于HDFS上的 -->
<name>hbase.rootdir</name>
<value>hdfs://localhost:9000/hbase</value>
</property>
<property>
<!-- 是否是分布式, false表示单机, true表示集群, 默认是false; 但我们这里只有一台节点, 所以搭建伪分布式 -->
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<!-- 端口, 默认为 16000, 这个是 tcp 通信的端口 -->
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<!-- webUI端口 -->
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<!-- zookeeper的地址 -->
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
<property>
<!-- zookeeper数据的存储目录, 就是我们之前手动创建的那个目录 -->
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/apache-zookeeper-3.5.8-bin/zkData</value>
</property>
最后还有一个 regionservers,它就是类似于 Hadoop 里面的 slaves,将 RegionServer 所在的节点配在里面即可。但我们是单机所以不用改,因为里面正好只有一个localhost。
HBase 的启动和关闭
首先 HBase 没有sbin目录,所以启动客户端的脚本,和启动、关闭服务的脚本都在 bin 目录中。我们来看看这个目录里面有什么东西吧。
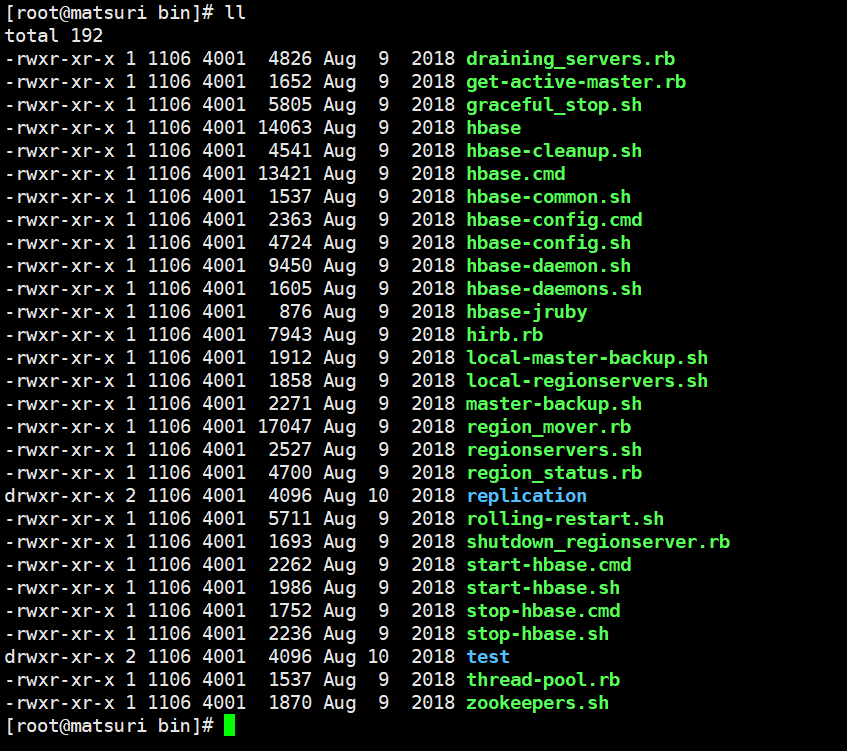
.cmd 是在 Windows上使用的,我们可以直接删掉了。然后我们看到 hbase-daemon.sh,显然它是启动单节点的;start-hbase.sh 和 stop-hbase.sh 是用来启动和关闭集群的,而 hbase 则是启动客户端的,整体和 Hadoop 也是类似的。
我们先来启动单节点 master,hbase-daemon.sh start master,然后打开 16010 页面。
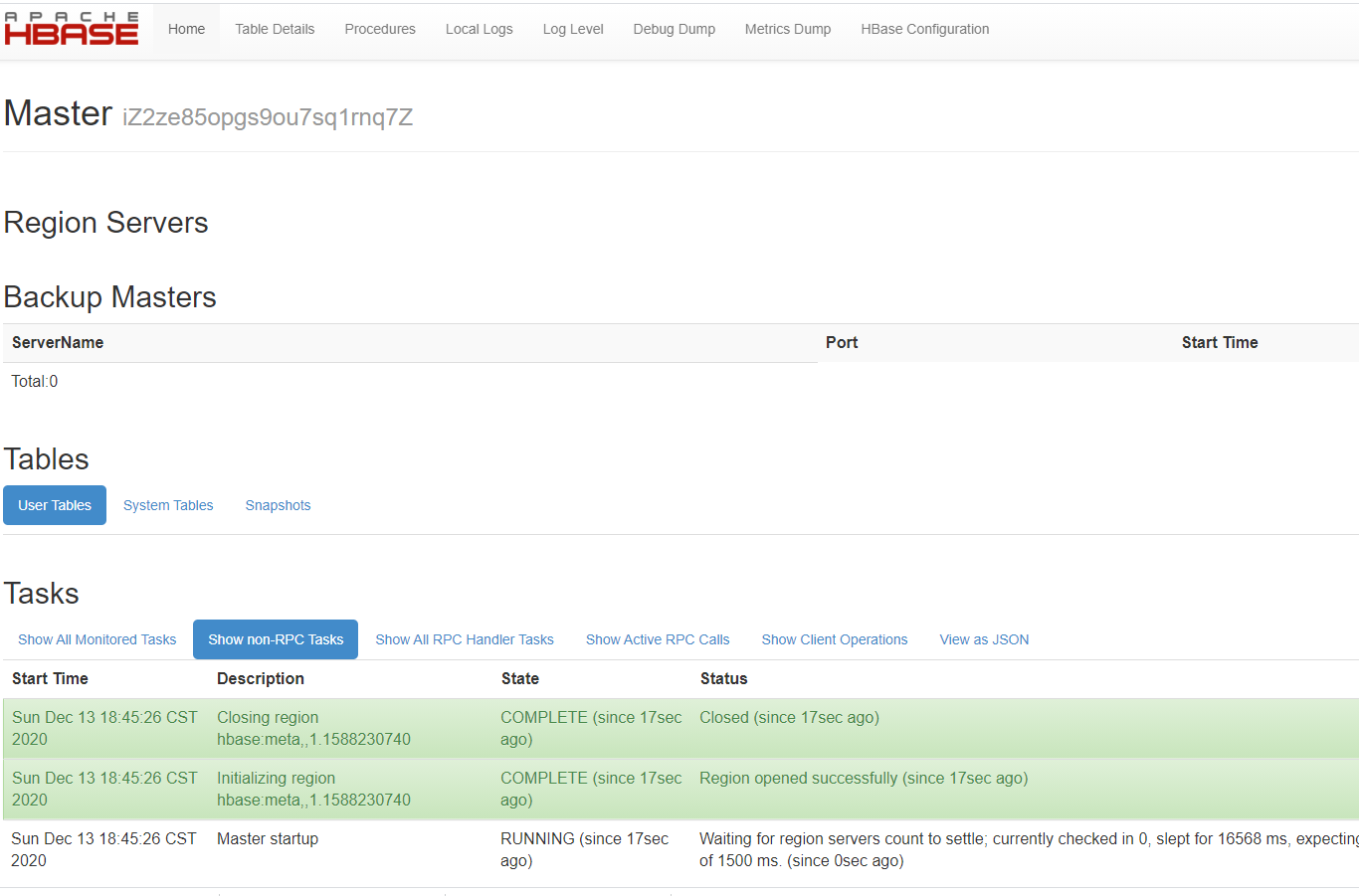
启动 master 之后,即可访问该页面,我们看到 Region Servers 是空的,这是肯定的因为我们压根就没有启动。下面启动Region Server,hbase-daemon.sh start regionserver,然后再来访问该页面。
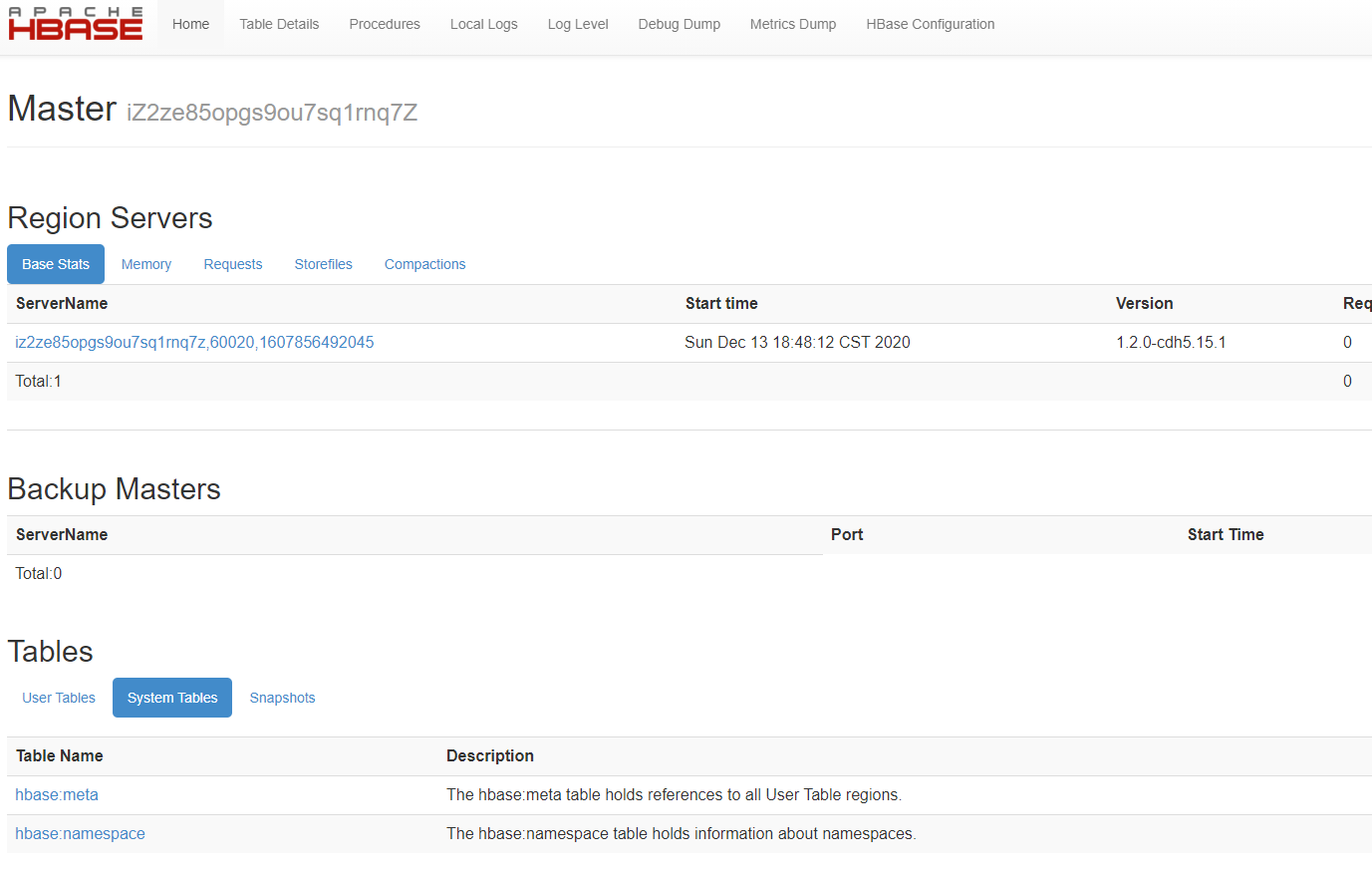
我们看到此时就有东西了,然后我们还看到了系统表。
HBase Shell 基本操作
安装完 HBase之后,我们来看看命令行操作都要哪些。在终端输入 hbase shell,即可进入命令行。
DDL基本操作
首先可以输入 help 查看帮助:
hbase(main):001:0> help
HBase Shell, version 1.2.0-cdh5.15.1, rUnknown, Thu Aug 9 09:07:24 PDT 2018
Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.
Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.
COMMAND GROUPS:
Group name: general
Commands: status, table_help, version, whoami
Group name: ddl
...
...
...
...
里面的内容非常多,非常详细,所有命令都在里面,如果有需要的可以直接在里面查。
hbase(main):009:0> list # list:查看默认命名空间(default)下有哪些表, 当然没有表
TABLE
0 row(s) in 0.0170 seconds
=> []
#########################################################
hbase(main):010:0> list_namespace_tables "default" # 手动查看某个命名空间下有哪些表, 目前没有
TABLE
0 row(s) in 0.0090 seconds
#########################################################
hbase(main):011:0> list_namespace_tables "hbase" # hbase下是有两张表的
TABLE
meta
namespace
2 row(s) in 0.0130 seconds
#########################################################
hbase(main):012:0> list_namespace # 查看当前有哪些命名空间, 总共有 hbase和default两个
NAMESPACE
default
hbase
2 row(s) in 0.0100 seconds
然后再来看看表的增删改查,首先是创建表。创建表的语法:
create '表名', '列族1', '列族2', ...
hbase(main):013:0> create 'vtuber', 'info', 'address'
0 row(s) in 1.2720 seconds
=> Hbase::Table - vtuber
#########################################################
hbase(main):018:0> list_namespace_tables "default"
TABLE
vtuber
1 row(s) in 0.0120 seconds
还可以通过 describe '表名' 查看该表具体的信息。
hbase(main):019:0> describe "vtuber"
Table vtuber is ENABLED
vtuber
COLUMN FAMILIES DESCRIPTION
{NAME => 'address', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false',
KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',
COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'info', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false',
KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER',
COMPRESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
2 row(s) in 0.0940 seconds
hbase(main):020:0>
首先 NAME 是表名,然后是 VERSION,表示对应列族中的数据最多存放几个版本。
还可以删除一张表,但是删除之前首先要让其变成不可用状态,否则删不掉。
disable '表名'
drop '表名'
如何创建一个命名空间呢?
hbase(main):033:0> create_namespace 'girls_home' # 删除命名空间使用 drop_namespace, 但前提是内部没有表
0 row(s) in 0.0240 seconds
#########################################################
hbase(main):034:0> list_namespace
NAMESPACE
default
girls_home
hbase
3 row(s) in 0.0110 seconds
hbase(main):035:0>
创建成功,那么如何才能让表创建在指定的命名空间中呢?
hbase(main):035:0> create "girls_home:vtuber","info","address" # 通过 命名空间:表名 的方式创建即可
0 row(s) in 2.2250 seconds
=> Hbase::Table - girls_home:vtuber
hbase(main):036:0>
DML基本操作
DDL基本上很少用,因为表一旦定义好,一般很少做修改。而DML用的则很普遍,因为我们是经常要对数据做增删改查的。
插入数据:
put '表名', 'row_key', '列族:列名', '值', '时间戳'
hbase(main):037:0> put 'vtuber', '001', 'info:name', '夏色祭' # 时间戳可以不指定, 会有一个默认的
0 row(s) in 0.0820 seconds
hbase(main):038:0>
查询数据:
下面来看看如何查询数据,首先是scan方法,可以直接全表扫描
hbase(main):038:0> scan 'vtuber'
ROW COLUMN+CELL
001 column=info:name, timestamp=1607860019310, value=\xE5\xA4\x8F\xE8\x89\xB2\xE7\xA5\xAD
1 row(s) in 0.0150 seconds
还可以使用 get 方法,不过在此之前,我们再来插入几条数据吧。并且为了直观,这里不用中文了。
hbase(main):047:0> scan 'vtuber'
ROW COLUMN+CELL
001 column=address:phone, timestamp=1607860452508, value=18888888
001 column=info:age, timestamp=1607860429650, value=16
001 column=info:name, timestamp=1607860416131, value=matsuroi
002 column=info:address, timestamp=1607860492603, value=japan
002 column=info:age, timestamp=1607860484940, value=38
002 column=info:name, timestamp=1607860477802, value=mea
003 column=info:address, timestamp=1607860533247, value=japan
003 column=info:name, timestamp=1607860518741, value=kano
3 row(s) in 0.0100 seconds
然后使用 get 获取,可以在获取的时候指定 row_key:
hbase(main):048:0> get 'vtuber', '001'
COLUMN CELL
address:phone timestamp=1607860452508, value=18888888
info:age timestamp=1607860429650, value=16
info:name timestamp=1607860416131, value=matsuroi
3 row(s) in 0.0120 seconds
返回指定的列族 / 列:
hbase(main):049:0> get 'vtuber', '001', 'info:name'
COLUMN CELL
info:name timestamp=1607860416131, value=matsuroi
1 row(s) in 0.0080 seconds
#########################################################
hbase(main):050:0> get 'vtuber', '001', 'info'
COLUMN CELL
info:age timestamp=1607860429650, value=16
info:name timestamp=1607860416131, value=matsuroi
2 row(s) in 0.0030 seconds
hbase(main):051:0>
scan在扫描的时候也是可以加上条件的:
hbase(main):052:0> scan 'vtuber', {STARTROW=>'002'} # 从rowkey等于'002'的位置扫描到结尾
ROW COLUMN+CELL
002 column=info:address, timestamp=1607860492603, value=japan
002 column=info:age, timestamp=1607860484940, value=38
002 column=info:name, timestamp=1607860477802, value=mea
003 column=info:address, timestamp=1607860533247, value=japan
003 column=info:name, timestamp=1607860518741, value=kano
2 row(s) in 0.0100 seconds
hbase(main):053:0> scan 'vtuber', {STARTROW=>'002', STOPROW=>'003'} # 从rowkey等于'002'扫描到'003', 左闭右开
ROW COLUMN+CELL
002 column=info:address, timestamp=1607860492603, value=japan
002 column=info:age, timestamp=1607860484940, value=38
002 column=info:name, timestamp=1607860477802, value=mea
1 row(s) in 0.0070 seconds
hbase(main):054:0> scan 'vtuber', {STARTROW=>'001', STOPROW=>'003'}
ROW COLUMN+CELL
001 column=address:phone, timestamp=1607860452508, value=18888888
001 column=info:age, timestamp=1607860429650, value=16
001 column=info:name, timestamp=1607860416131, value=matsuroi
002 column=info:address, timestamp=1607860492603, value=japan
002 column=info:age, timestamp=1607860484940, value=38
002 column=info:name, timestamp=1607860477802, value=mea
2 row(s) in 0.0090 seconds
hbase(main):055:0> scan 'vtuber', {STOPROW=>'003'} # 从开始位置扫描到'003', 同样不包含结尾
ROW COLUMN+CELL
001 column=address:phone, timestamp=1607860452508, value=18888888
001 column=info:age, timestamp=1607860429650, value=16
001 column=info:name, timestamp=1607860416131, value=matsuroi
002 column=info:address, timestamp=1607860492603, value=japan
002 column=info:age, timestamp=1607860484940, value=38
002 column=info:name, timestamp=1607860477802, value=mea
2 row(s) in 0.0100 seconds
修改数据:
该数据我们之前已经用到了,就是put一条新数据。
hbase(main):056:0> get 'vtuber', '001', 'info:name'
COLUMN CELL
info:name timestamp=1607860416131, value=matsuroi
1 row(s) in 0.0080 seconds
hbase(main):057:0> put 'vtuber', '001', 'info:name', 'MATSURI'
0 row(s) in 0.0160 seconds
hbase(main):058:0> get 'vtuber', '001', 'info:name'
COLUMN CELL
info:name timestamp=1607861401401, value=MATSURI
1 row(s) in 0.0060 seconds
修改数据等于put一条新数据,然后时间戳比之前的大,然后返回的时候返回时间戳大的数据即可。那么之前的数据还在吗?显然是在的,那么我们再来做一个测试,我们看到 'vtuber', '001', 'info:name' 对应的value是 "MATSURI",时间戳是 1607861401401。
hbase(main):065:0> put 'vtuber', '001', 'info:name', '~~~~', 16078614014010
0 row(s) in 0.0040 seconds # 插入数据的时间戳比原来的大
#################################################################
hbase(main):066:0> get 'vtuber', '001', 'info:name' # 数据被改掉了
COLUMN CELL
info:name timestamp=16078614014010, value=~~~~
1 row(s) in 0.0020 seconds
#################################################################
hbase(main):067:0> put 'vtuber', '001', 'info:name', 'matsuri', 16078614014009
0 row(s) in 0.0030 seconds # 插入数据的时间戳比原来的小
#################################################################
hbase(main):068:0> get 'vtuber', '001', 'info:name' # 发现获取的还是原来的
COLUMN CELL
info:name timestamp=16078614014010, value=~~~~
1 row(s) in 0.0140 seconds
hbase(main):069:0>
删除数据:
删除数据,delete '表名', '列族:列名', 'rowkey', '时间戳(可选)'
hbase(main):069:0> get 'vtuber', '001', 'info:name'
COLUMN CELL
info:name timestamp=16078614014010, value=~~~~
1 row(s) in 0.0100 seconds
#################################################################
hbase(main):070:0> delete 'vtuber', '001', 'info:name'
0 row(s) in 0.0310 seconds
#################################################################
hbase(main):071:0> get 'vtuber', '001', 'info:name'
COLUMN CELL
info:name timestamp=16078614014009, value=matsuri
1 row(s) in 0.0160 seconds
我们发现在删除之后,跑到了上一个版本。
deleteall可以删除一个rowkey,delete则必须要指定列。
HBase 深入
未完待续
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号