《数据库基础语法》4. 使用 ORDER BY 进行排序,并实现 TOP-N 排行榜以及前端分页
楔子
上面我们讨论了如何使用 LIKE 运算符和正则表达式函数进行文本数据的模糊查找,但是有时候返回的数据的顺序未必是我们希望的,这是因为 SQL 在查询时不保证返回结果的顺序。
如果想要查询的结果按照某种规则进行排序,例如按照工资从高到低排序,可以使用 SQL 中的 ORDER BY 子句。
排序显示
SQL 中可以按照单个字段排序,也可以按照多个字段排序,我们分别介绍。
单列排序:
按照单个字段或者表达式的值进行排序称为单列排序,单列排序的语法如下:
SELECT col1, col2, ...
FROM t
ORDER BY col1 [ASC | DESC];
其中,ORDER BY 用于指定排序的字段;ASC 表示升序排序(Ascending),DESC 表示降序排序(Descending),默认值为升序排序。
SELECT * FROM staff WHERE title = '初级工';
/*
01010011095 26 初级工 生产人员
01010009147 30 初级工 生产人员
01010001274 33 初级工 生产人员
01010007889 34 初级工 生产人员
01010006199 33 初级工 生产人员
01010008105 47 初级工 生产人员
01010007064 31 初级工 生产人员
01010007119 46 初级工 生产人员
01010006109 40 初级工 生产人员
01010006735 33 初级工 生产人员
01010002428 29 初级工 生产人员
01010001274 33 初级工 生产人员
01010002428 29 初级工 生产人员
01010009135 29 初级工 生产人员
01010008442 33 初级工 生产人员
*/
-- 按照 age 升序排序
SELECT * FROM staff WHERE title = '初级工' ORDER BY age;
/*
01010011095 26 初级工 生产人员
01010002428 29 初级工 生产人员
01010002428 29 初级工 生产人员
01010009135 29 初级工 生产人员
01010009147 30 初级工 生产人员
01010007064 31 初级工 生产人员
01010001274 33 初级工 生产人员
01010006199 33 初级工 生产人员
01010006735 33 初级工 生产人员
01010001274 33 初级工 生产人员
01010008442 33 初级工 生产人员
01010007889 34 初级工 生产人员
01010006109 40 初级工 生产人员
01010007119 46 初级工 生产人员
01010008105 47 初级工 生产人员
*/
-- 按照 age 降序排序
SELECT * FROM staff WHERE title = '初级工' ORDER BY age DESC;
/*
01010008105 47 初级工 生产人员
01010007119 46 初级工 生产人员
01010006109 40 初级工 生产人员
01010007889 34 初级工 生产人员
01010001274 33 初级工 生产人员
01010006199 33 初级工 生产人员
01010006735 33 初级工 生产人员
01010001274 33 初级工 生产人员
01010008442 33 初级工 生产人员
01010007064 31 初级工 生产人员
01010009147 30 初级工 生产人员
01010002428 29 初级工 生产人员
01010002428 29 初级工 生产人员
01010009135 29 初级工 生产人员
01010011095 26 初级工 生产人员
*/
该查询中使用了 WHERE 过滤条件,此时 ORDER BY 子句位于 WHERE 之后。
对于升序排序,数字按照从小到大的顺序排列,字符按照编码的顺序排列,日期时间按照从早到晚的顺序排列;降序排序正好相反。
多列排序:
多列排序是指基于多个字段或表达式的排序,使用逗号进行分隔。多列排序的语法如下:
SELECT col1, col2, ...
FROM t
ORDER BY col1 ASC, col2 DESC, ...;
首先基于第一个字段进行排序;对于第一个字段排序相同的数据,再基于第二个字段进行排序;依此类推。
-- 按照 age 升序排序, 如果 age 相同则再按照 id 降序排序
SELECT * FROM staff WHERE title = '初级工' ORDER BY age, id DESC ;
/*
01010011095 26 初级工 生产人员
01010009135 29 初级工 生产人员
01010002428 29 初级工 生产人员
01010002428 29 初级工 生产人员
01010009147 30 初级工 生产人员
01010007064 31 初级工 生产人员
01010008442 33 初级工 生产人员
01010006735 33 初级工 生产人员
01010006199 33 初级工 生产人员
01010001274 33 初级工 生产人员
01010001274 33 初级工 生产人员
01010007889 34 初级工 生产人员
01010006109 40 初级工 生产人员
01010007119 46 初级工 生产人员
01010008105 47 初级工 生产人员
*/
中文排序:
在创建数据库或者表时,我们会指定一个字符集(Charset)和排序规则(Collation)。
字符集决定了数据库能够存储哪些字符,比如 ASCII 字符集只能存储简单的英文、数字和一些控制字符;GB2312 字符集可以存储中文;Unicode 字符集能够支持世界上的各种语言。
排序规则定义了字符集中字符的排序顺序,包括是否区分大小写,是否区分重音等。对于中文而言,排序方式与英文有所不同;中文通常需要按照拼音、偏旁部首或者笔画进行排序。
如果想要支持中文排序,最简单的方式就是使用支持中文排序的排序规则;但是常见的 Unicode 字符集默认不支持中文排序。所以我们需要解决这种情况下的中文排序问题。
首先是 Oracle,使用 AL32UTF8 字符编码时不支持中文排序规则,可以通过一个转换函数实现该功能。比如按照姓名的拼音进行排序:
-- Oracle 实现中文拼音排序
SELECT name
FROM xxx
ORDER BY NLSSORT(name,'NLS_SORT = SCHINESE_PINYIN_M');
/*
NLSSORT 是一个函数,返回了按照某种排序规则得到的字符序列;SCHINESEPINYINM 表示中文的拼音排序规则。
Oracle 还支持按偏旁部首进行排序:SCHINESE_RADICALM,以及按笔画进行排序:SCHINESE_STROKEM。
*/
对于 SQL Server,字符集和排序规则是同一个概念。如果需要存储中文,需要使用相应的排序规则,例如 Chinese_PRC_CI_AI_WS。以下查询按照员工姓名的拼音进行排序:
-- SQL Server 实现中文拼音排序
SELECT name
FROM xxx
ORDER BY name COLLATE Chinese_PRC_CI_AI_WS;
/*
COLLATE 表示按照某种排序规则进行排序;如果数据库使用的是 Chinese_PRC_CI_AI_WS 排序规则,可以省略 COLLATE 选项。该语句的结果和上面的 Oracle 示例一样。
*/
最后,PostgreSQL 默认使用 UTF8 编码字符集,不支持中文排序规则。以下示例按照员工姓名的拼音进行排序:
-- PostgreSQL 实现中文拼音排序
SELECT name
FROM xxx
ORDER BY name COLLATE "zh_CN";
/*
COLLATE 指定了中文排序规则 zh_CN,该语句的结果和上面的 Oracle 示例一样。
*/
空值排序:
空值(NULL)在 SQL 中表示未知或者缺失的值。如果排序的字段中存在空值时,会怎么样呢?由于比较简单,自己测试一下就知道了,这里直接说结论:
MySQL 和 SQL Server 认为空值最小,升序时空值排在最前,降序时空值排在最后Oracle 和 PostgreSQL 认为空值最大,升序时空值排在最后,降序时空值排在最前;同时支持使用 NULLS FIRST 和 NULLS LAST 指定空值的顺序
解决空值的排序问题还有一个更通用的方法,就是利用 COALESCE 函数将空值转换为一个指定的值。例如,将奖金为空的数据转换为 0,这样升序排序时一定在最前。当然即使不排序,我们在筛选字段的时候,如果存在空值,我们也可以替换成默认的值。
select id, age, title, type from staff where age = 28;
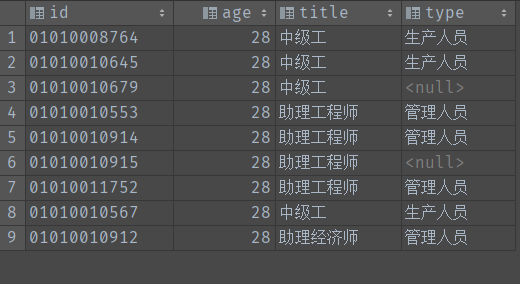
select id, age, title, COALESCE(type, 'UNKNOWN') AS type from staff where age = 28;

关于函数我们后面会说。
选择指定数量的记录
我们上面讨论了如何利用 ORDER BY 子句实现查询结果的排序。对数据进行排序之后,还可以进一步进行处理。我们经常会看到各种 Top-N 排行榜,例如十大热门金曲、电影排行榜、游戏排行榜等。另外,在客户端显示数据时通常不是一次列出所有的结果,而是每次显示 N 条(10、20、50 等)记录;然后提供 "下一页"、"上一页" 等翻页功能。本篇我们就来了解一下如何使用 SQL 语句实现以上两种常见的功能。
Top-N 排行榜:
Top-N 排行榜的原理就是先排序,再返回前 N 条记录。实现 Top-N 排行榜的方式主要有两种:
标准 SQL 提供的 FETCH 语法另一种常见的 LIMIT 语法
比如我们查看员工年龄最小的前五位。
-- Oracle、SQL Server 以及 PostgreSQL 支持
--表示先按照age升序排序,然后选取前5条
SELECT id, age from staff
ORDER BY age FETCH FIRST 5 ROWS ONLY OFFSET 0;
/*
01010011650 22
01010011650 22
01010011870 23
01010011859 23
01010011676 23
*/
--这里的语法规则就是,假设选取n条,那么就是fetch first n rows only
--后面的offset则表示偏移量,表示从第几条开始取5条,我们这里是0,表示从头开始,当然默认也是从头开始的
--假设我们从第三条开始取三条,从第三条开始则代表偏移量为2
SELECT id, age from staff
ORDER BY age FETCH FIRST 3 ROWS ONLY OFFSET 2;
/*
01010011870 23
01010011859 23
01010011676 23
*/
-- 结果正好是上面结果的最后三条
以上使用的是 FETCH,然后例子不变,使用 LIMIT 演示一下,个人用的最多的还是 LIMIT。
-- MySQL 以及 PostgreSQL 支持
SELECT id, age from staff
ORDER BY age LIMIT 5 OFFSET 0;
/*
01010011650 22
01010011650 22
01010011870 23
01010011859 23
01010011676 23
*/
SELECT id, age from staff
ORDER BY age LIMIT 3 OFFSET 2;
/*
01010011870 23
01010011859 23
01010011676 23
*/
我们发现使用 LIMIT 貌似变得方便多了,当然了两个 OFFSET 的含义都是一样的。
分页效果:
现在我们肯定能够明白分页效果是怎么做的了,分页查询的原理就是先跳过指定的行数,再返回 Top-N 记录。比如一页显示 20 条,我要查询第 3 页的内容就是:LIMIT 20 OFFSET 40
小结
ORDER BY 子句可以将查询的结果按照某种规则进行排序,排序方式分为升序和降序;可以基于单列或表达式排序,也可以基于多列或多个表达式排序。中文排序需要字符集和排序规则的支持,不同数据库的实现各不相同。另外,还需要注意空值的排序问题。
查询语句中的 FETCH 和 OFFSET 子句可以限定返回结果的数量和偏移量,从而实现排行榜和分页查询效果。LIMIT 和 OFFSET 子句也是实现该功能的一种常见的用法。另外,某些数据库还实现了其他的替代方式。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号