最流行的web服务器nginx
楔子
相信很多人都用 Nginx 搭建过反向代理服务器,但其实这仅仅只是 Nginx 的一些最基本的用法,我们还需要熟悉 Nginx 底层的运行原理,比如:Nginx 的架构、进程模型,以及 Liunx 中的 CPU、内存、磁盘、网络等等要如何与 Nginx 配置文件中的指令相结合从而使得 Nginx 的性能达到最大化。那么下面我们就从零开始,一点一点深入挖掘 Nginx。
首先 Nginx 是一个高性能的 HTTP 和反向代理服务器,而且 Nginx 的作者是一个对操作系统有着深入研究的人,可以说他把 Nginx 已经优化到极致了,使得 Nginx 具备高性能和高吞吐量。当然 Nginx 还有很多其它优点:
- Nginx 的模块化设计,使得它可以很容易被扩展,因此 Nginx 有着丰富的第三方模块;
- Nginx 可靠性高,可以持续不间断地提供服务;
- Nginx 支持热部署,能够在不停止服务的情况下升级 Nginx;
- Nginx 遵循 BSD 协议,可以自由地进行二次开发(比如淘宝的 Tengine)。
安装 Nginx
Nginx 现在分为四种:Nginx 开源版、Nginx plus 商业版、OpenResty、Tengine,这里我们直接选择开源版本即可。然后是 Nginx 的安装,可以使用 Docker 安装、也可以使用 yum 安装,但我个人更建议的做法是通过源码编译的方式安装。因为 yum 在安装的时候不一定会把第三方模块也集成进去,而且任何一个软件,我们也都应该知道如何通过源码编译的方式去安装。
下面进入 Nginx 官网将源码下载下来。

我们注意到上面有三个版本,Mainline version 是正在主力开发的版本,Stable version 是稳定的最新版本,而 Legacy versions 则是稳定的老版本。这里下载稳定的最新版本,也就是 1.24.0。
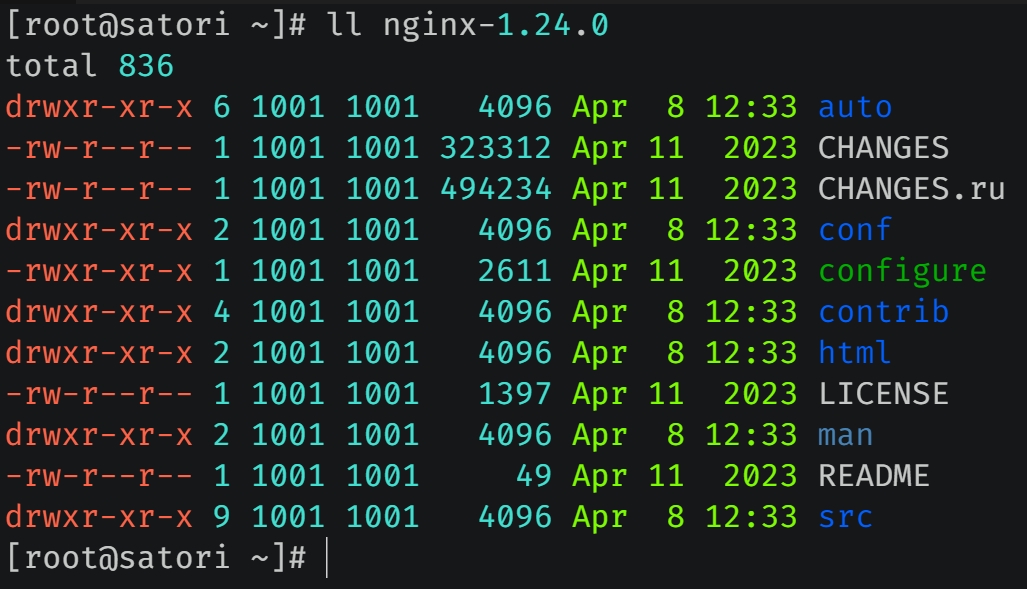
上传到服务器之后解压,目录结构如图所示,我们解释一下每个目录是做什么的。
- auto 目录里面有几个子目录,auto/cc 用于编译,auto/lib 包含一些额外的库,auto/os 用于判断并适配操作系统。至于 auto 目录里的其它文件则是用来辅助 configure 脚本在执行的时候判定 Nginx 支持哪些模块,以及当前的操作系统有什么特性可以供 Nginx 使用。
- conf 目录里面提供了配置文件的模板,后续直接拷贝过来进行修改即可。
- contrib 目录提供了两个 perl 脚本和一个 vim 工具,我们在 Linux 上打开配置文件的时候默认是没有语法高亮的,而如果将 contrib/vim/* 拷贝到 ~/.vim 之后再打开的话,会发现文件具备了语法高亮效果。
- html 目录提供了两个标准的 html 文件,当 Nginx 成功启动时显示的 html,以及发生 500 错误时的 html。
- man 目录则提供了一些 Linux 的帮助手册。
- src 目录应该无需解释,它是 Nginx 源代码所在的目录。
除了上面说的目录之外,我们看到 Nginx 主目录中还有几个文件。
- CHANGES:记录 Nginx 每个版本所做的修改。
- CHANGES.ru:Nginx 作者是俄罗斯人,所以还提供了一个俄语版本。
- configure:编译之前的必备动作,生成 Makefile、检查依赖等等,在执行 configure 的时候可以指定参数来对安装进行控制。当执行完 configure 之后就可以使用 make 进行编译了,编译之后再使用 make install 进行安装。
- LICENSE: 相关许可证明。
- README: README 文件。
接下来将目光放在 configure 文件上,看看它支持哪些选项,可以通过 ./configure --help 查看。虽然支持的选项非常多,但是不需要全部都用,可以根据自己的情况进行选择,并且每个选项都有相应的注释。
./configure --prefix=/usr/local/nginx
这里只指定安装的目录(其实默认也是安装在 /usr/local/nginx 中),其余选项直接使用默认的。如果不出意外的话,执行之后会报错,因为缺少依赖,我们需要执行:
yum install gcc gcc-c++ make automake autoconf libtool pcre* zlib openssl openssl-devel
将相关依赖安装之后,再执行 ./configure --prefix=/usr/local/nginx 即可。

安装完毕之后,结尾会有一个 Configuration summary,告诉我们一些相关信息。比如 nginx path prefix 表示编译安装后的目录,nginx binary file 表示安装后的二进制文件等等。但需要注意:我们此时还没有编译、也没有安装,这一步只是相当于根据指定的参数生成了 Makefile、进行了一些依赖检查。
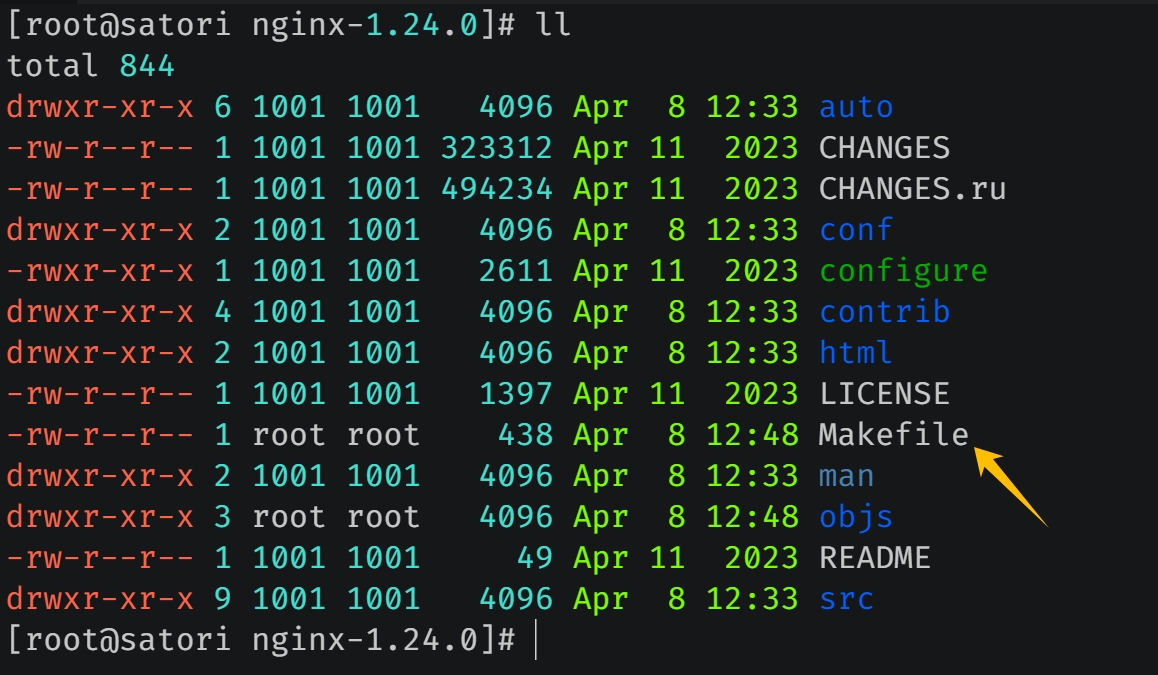
接下来执行 make && make install 进行编译安装,这个过程需要花费一些时间。等安装完毕之后,/usr/local 中会多出一个 nginx 目录。
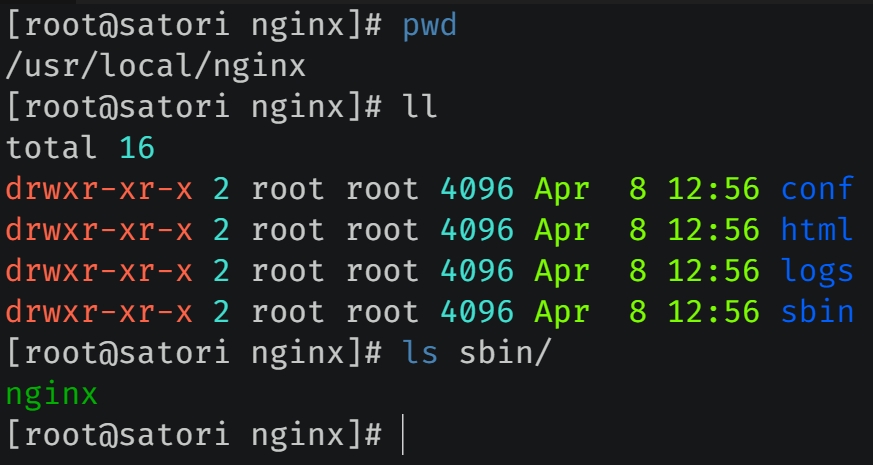
这就是编译安装之后的结果,conf 目录存放配置文件,html 目录包含两个标准的 html 文件,logs 目录存放日志,sbin 目录存放启动文件(只有一个 nginx,通过该文件即可启动 Nginx 服务,它是所有模块编译之后的最终结果)。可以看到编译安装的整个过程还是很简单的,并且安装之后 Nginx 的目录也很简洁。
至于安装之前的 nginx-1.24.0 源码目录就可以直接删掉了。
然后看看 Nginx 支持的命令行操作,为了操作方便,建议先配置一下环境变量。
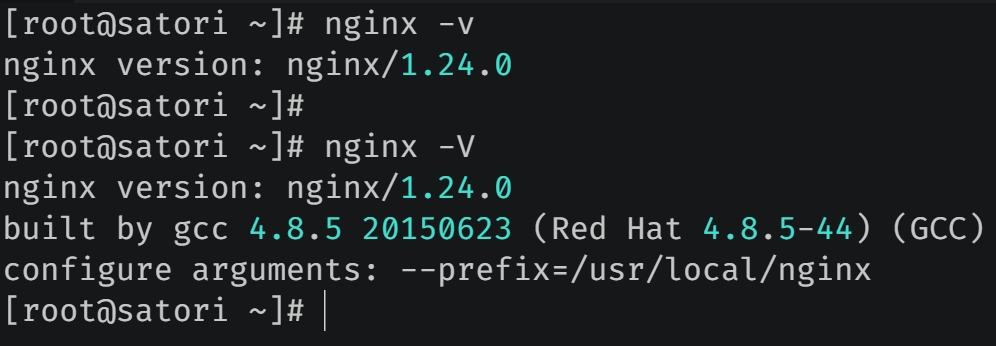
查看 Nginx 版本信息
帮助信息
输入 nginx -? 或者 nginx -h 即可。
启动 Nginx
- nginx:直接启动,会使用默认的配置文件。
- nginx -g 配置指令:指定配置指令启动,不常用。
- nginx -c 配置文件:指定配置文件启动,最常用。
- nginx -p 运行目录:指定 Nginx 的运行目录,然后相应的日志文件就会记录在指定的目录中。
关闭 Nginx
Nginx 是通过信号来控制进程的,我们既可以使用 Linux 中自带的 kill 命令,也可以通过 nginx -s 的方式。
- nginx -s stop:立刻停止服务。
- nginx -s quit:优雅地停止服务,在退出前会完成已经接受的连接请求。
- nginx -s reload:重新加载配置文件,如果配置文件修改了,那么无需重启 Nginx,可以通过重新加载的方式。
- nginx -s reopen:新打开日志文件,重头开始记录(记得要先备份)。
检测配置文件是否有误
如果修改配置文件出错,那么会导致 Nginx 无法启动,这个时候可以通过 nginx -t 或者 nginx -T 来检测配置文件是否有语法错误。

检测结果正常,因为我们目前还没有对配置文件做修改。
下面我们来启动一下 Nginx,直接命令行输入 nginx 即可。
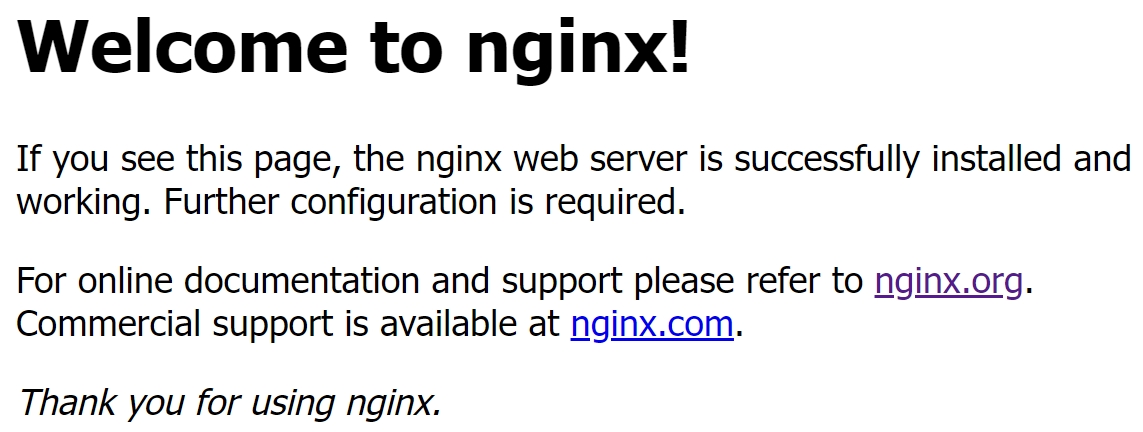
html 目录下有两个标准的 html 文件,一个用于成功访问 Nginx 时返回,另一个用于出现 500 错误时返回,显然我们这里安装成功了。
另外可能因为防火墙的原因,会使得端口未对外开方,导致无法访问,这时我们需要开放让外界访问的端口号。我这里使用的是腾讯云服务器,因此可以通过腾讯云提供的 Web 页面的方式开放端口,如果通过命令的话该怎么做呢?
systemctl status firewalld:查看防火墙状态firewall-cmd --list-all:查看所有开放的端口号firewall-cmd --add-service=http --permanentfirewall-cmd --add-port=80/tcp --permanent:设置要开放的端口号firewall-cmd --reload:重启防火墙
Nginx 配置文件解析
Nginx 配置文件是 Nginx 的核心,我们用 Nginx 主要就是在编写配置文件。首先 Nginx 的配置文件在 conf 目录下,名字为 nginx.conf,根据配置文件的内容,我们可以将整体分为三部分。
- 第一部分:全局块
- 第二部分:events 块
- 第三部分:http 块
当然 Nginx 支持的配置有很多,但默认的配置文件中并没有全部写上,这里我们尽量介绍地详细一点。
Nginx 配置文件是有格式要求的,每一行配置都要以分号结尾,# 表示注释。
第一部分:全局块
从配置文件开始到 events 块之间的内容,主要会设置一些影响 Nginx 服务器整体运行的配置指令。
# 指定 Nginx 的启动用户
user root;
# 工作进程(Worker)的数量,Nginx 是 Master Worker 多进程架构,当执行 nginx 命令时,会启动一个 Master 进程
# Master 进程验证配置文件 nginx.conf 是否正常,如果正常,那么启动子进程处理请求
# 所以 Master 不直接处理请求,而是用来管理、监控其它组件,处理请求会交给子进程 Worker 来做
# 如果 Worker 挂掉了,那么会发送一个信号给 Master,这样的话 Master 会重新启动一个 Worker
# 而该参数便是指定工作进程、也就是 Worker 的数量,通常等于 CPU 数量或者 2 倍的 CPU 数量
worker_processes 16;
# 错误日志的存放路径,以及打印的日志级别
error_log logs/error.log;
error_log logs/error.log notice;
error_log logs/error.log info;
# pid(进程标识符)的存放路径
pid logs/nginx.pid;
# 指定一个 nginx 进程最多可以打开多少个文件描述符
# 理论值应该是最多打开文件数(ulimit - n)与 Nginx 进程数相除,但多个进程分配请求并不是那么均匀,所以最好与 ulimit -n 的值保持一致
# 总之最好往大了写
worker_rlimit_nofile 204800;
以上就是全局块,可以看到配置的也确实是一些全局信息。
第二部分:events 块
events 块主要设置 Nginx 服务器与用户的网络连接,常用的设置包括是否开启对多 Worker(工作进程)下的网络连接进行序列化、是否允许同时接收多个网络连接、选取哪种事件驱动模型来处理连接请求、每个 Worker 可以同时支持的最大连接数。
events {
# 事件驱动模型,Linux 指定为 epoll,Unix 指定为 Kqueue,Windows 不指定
use epoll;
# 每个工作进程支持的最大连接数,这部分配置对 Nginx 的性能影响较大,在实际中应该灵活配置
# 理论上每台 Nginx 服务器的最大连接数为 worker_processes * worker_connections
worker_connections 204800;
# 每个 TCP 连接最多可以保持多长时间
keepalive_timeout 60;
# 客户端请求头部的缓冲区大小,这个可以根据你的系统分页大小来设置
# 一般一个请求头的大小不会超过 1k,不过由于系统分页都要大于 1k,所以这里设置为分页大小
# 分页大小可以用命令 getconf PAGESIZE 取得,在我当前机器上是 4096
# 不过也有 client_header_buffer_size 超过 4k 的情况,但 client_header_buffer_size 必须设置为 系统分页大小 的整数倍
client_header_buffer_size 4k;
# 为打开的文件指定缓存,max 表示缓存的文件数量,inactive 表示文件经过多长时间没被请求后删除缓存
open_file_cache max=65535 inactive=60s;
# 多长时间检查一次缓存的有效信息
open_file_cache_valid 80s;
# open_file_cache 指令中的 inactive 时间内文件的最少使用次数
# 如果超过这个数字,文件描述符一直是在缓存中打开的,如果有一个文件在 inactive 时间内一次没被使用,它将被移除。
open_file_cache_min_uses 1;
}
如果你打开默认配置文件的话,会发现 events 块里面只有一个指令 worker_connections,其它指令也是支持的,只不过没有写在默认的配置文件中。很多指令如果不配置的话,那么会使用默认的,Nginx 会根据当前平台进行选择。
第三部分:http 块
http 块算是 Nginx 中配置最为频繁的部分,代理、缓存、日志定义以及我们说的负载均衡、动静分离等绝大部分功能都是在这里面进行配置的,另外 http 块也可以分为 http 全局块和 server 块。
http 全局块
http 全局块配置的指令包括文件的引入,MIME-TYPE 定义,日志自定义,连接超时时间,单链接请求数上限等等。
http {
# 在 conf 目录中还有很多其它文件,可以通过 include 导入进来
# 这里就是设置 mime 类型,类型由 mime.type 文件定义
include mime.types;
# 响应体的 Content-Type
default_type application/octet-stream;
# 日志格式
# $remote_addr 与 $http_x_forwarded_for 用来记录客户端的 ip 地址
# $remote_user:用来记录客户端用户名称
# $time_local: 用来记录访问时间与时区
# $request: 用来记录请求的 url 与 http 协议
# $status: 用来记录请求状态,成功是 200
# $body_bytes_sent:记录发送给客户端的文件主体内容大小
# $http_referer:用来记录是从哪个页面跳转过来的
# $http_user_agent:记录客户浏览器的相关信息
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
# 通常 Web 服务器放在反向代理的后面,这样就不能获取到客户端的 IP 地址了,通过 $remote_addr 拿到的 IP 地址是反向代理服务器的 IP 地址
# 因此反向代理服务器在转发请求的 http 头信息中,可以增加 x_forwarded_for 信息,用来记录真实客户端的 IP 地址和请求的服务器地址
# 该指令用于指定日志文件的存放路径
access_log logs/access.log main;
# 和 events 块中的 client_header_buffer_size 类似
client_header_buffer_size 4k;
# 客户请求头缓冲大小,Nginx 默认会用 client_header_buffer_size 这个 buffer 来读取 header 值
# 如果 header 过大,它会使用 large_client_header_buffers 来读取
large_client_header_buffers 8 128k;
# 和 events 块中的 open_file_cache、open_file_cache_valid、open_file_cache_min_uses 类似
open_file_cache max=102400 inactive=20s;
open_file_cache_valid 80s;
open_file_cache_min_uses 2;
# 默认值为 off,表示是否记录 cache 错误
open_file_cache_errors on
# 请求体的最大值
client_max_body_size 300m;
# 指定 nginx 是否调用 sendfile 函数(zero copy 方式)来输出文件,如果反向代理的是普通应用,应该设为 on
# 如果代理的是下载相关的会导致磁盘 IO 重负载的应用,那么可设置为 off,以平衡磁盘与网络 IO 处理速度,降低系统 uptime
sendfile on;
# 允许或禁止使用 socket 的 TCP_CORK 选项,仅在 sendfile 为 on 的时候使用
tcp_nopush on;
# 每个 TCP 连接最多可以保持多长时间
keepalive_timeout 65;
# 后端服务器连接的超时时间,发起握手等候响应的超时时间
proxy_connect_timeout 90;
# 连接成功后等待后端服务器响应的时间,其实已经进入后端的队列之中等候处理(也可以说是后端服务器处理请求的时间)
proxy_read_timeout 180;
# 后端服务器数据回传时间,就是在规定时间之内后端服务器必须传完所有的数据
proxy_send_timeout 180;
# 设置从被代理服务器读取的第一部分响应的缓冲区大小,通常情况下这部分应答中包含一个小的应答头
# 默认情况下这个值的大小为指令 proxy_buffers 中指定的一个缓冲区的大小,不过可以将其设置为更小
proxy_buffer_size 256k;
# 设置用于读取响应(来自被代理服务器)的缓冲区数目和大小,默认情况也为分页大小,根据操作系统的不同可能是 4k 或者 8k
proxy_buffers 4 256k;
# 使 nginx 阻止 HTTP 应答代码为 400 或者更高的应答。
proxy_intercept_errors on;
# Nginx 分配给请求数据的 Buffer 大小,如果请求的数据小于 client_body_buffer_size 直接将数据先在内存中存储
# 如果请求的值大于 client_body_buffer_size 小于 client_max_body_size,就会将数据先存储到临时文件中
# 通过 client_body_temp 指定,默认是 /tmp,所以配置的 client_body_temp 路径,一定要让启动 Nginx 的用户有读写权限
# 否则,当传输的数据大于 client_body_buffer_size,会写入临时文件失败并报错
client_body_buffer_size 512k;
# 传输的数据大于 client_max_body_size,一定是传不成功的,小于 client_body_buffer_size 直接在内存中高效存储
# 如果大于 client_body_buffer_size 小于 client_max_body_size 会存储在临时文件中,临时文件一定要有权限
# 如果追求效率,就让 client_max_body_size 和 client_body_buffer_size 保持一致,这样就不会存储在临时文件中,而是直接存储在内存里
# 开启 gzip 压缩,默认是被注释掉的
gzip on;
# 用于负载均衡,后面介绍
upstream ... {
}
http 块是由 http 全局块和 server 块组成的,而 server 块位于 http 内部。这里先来简单总结一下 nginx.conf 的结构:
# 全局块
user nobody;
worker_processes 1;
pid logs/nginx.pid;
... ...;
# events 块
events {
worker_connections 1024;
... ...;
}
# http 块
http {
# http 全局块
include mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
... ...;
... ...;
#gzip on;
upstream {
}
# server 块,可以配置多个,位于 http 块中
server {
listen 80;
server_name localhost;
... ...;
}
server {
listen 8080;
server_name localhost;
... ...;
}
server {
listen 8081;
server_name localhost;
... ...;
}
}
所以整体结构还是比较清晰的,尽管每个块里面的内容有很多,但并不是每一个都需要,很多指令直接采用默认值即可。最后来介绍一下 server 块。
server 块
server 块可以说是我们改动最频繁的部分了,里面支持的操作非常多,因为大部分都是在 server 块里面配置的。事实上其它的块我们只需要根据配置文件做简单修改即可,但是 server 块比较特殊,所以我们通过几个例子来介绍 server 块是如何使用的。
Nginx 配置实例
接下来我们将只修改 server 块,像全局块、events 块我们直接采用默认值即可,工作中则具体根据业务需求修改。
实现反向代理(一)
需求:当我打开浏览器,输入服务器的 IP 的时候,会自动跳转到百度页面。
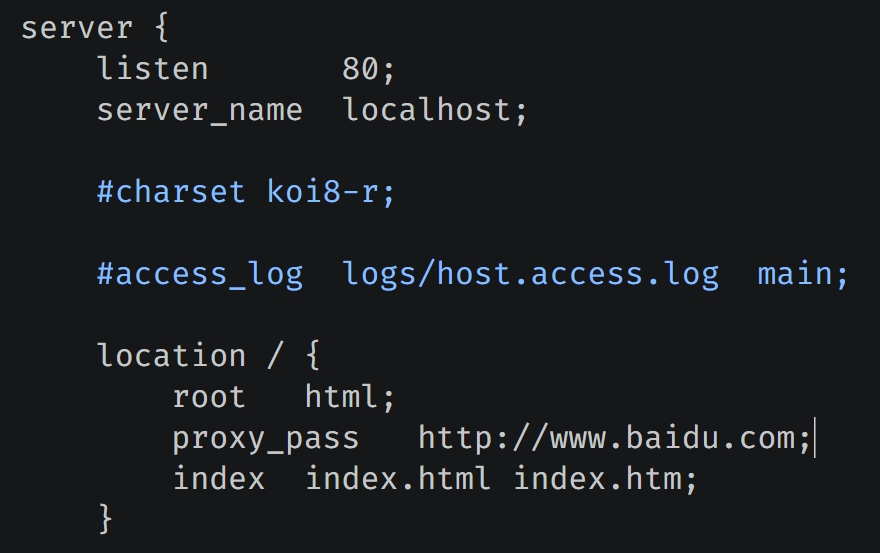
listen 表示监听 80 端口,当然也可以改成别的,只不过在用浏览器访问的时候就需要显式地指定要访问的端口了。server_name 表示监听的域名或主机名,如果你没有配置域名,那么使用 localhost 即可。location / 表示当你访问的路径是 / 的时候,进行相应的处理,我们很多时候都只是用 Nginx 做一层转发,而实现转发则需要配置 location。
我们在 location 块中只需要加上一行 proxy_pass http://www.baidu.com 即可,由于该机器监听的是 80 端口,而浏览器默认访问 80 端口,那么当我们直接输入 IP 地址访问该机器的时候,会自动转发到百度。如果你尝试失败了,那么想想是不是忘记 nginx -s reload 了。
如果不指定 proxy_pass 这一行,那么就会来到 nginx 的指定页面,root html 表示 Nginx 主目录下的 html 目录,index index.html index.htm 表示目录下的文件。当没有指定 proxy_pass 时,就会到 root 指定的目录中查找 index 指定的文件。
这里我们把 proxy_pass 这一项给去掉,然后让 nginx 访问我们自己指定的页面,先创建一个 /root/satori.html。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1 style="text-align: center">古明地さとりの避難小屋へようこそ</h1>
</body>
</html>
然后别忘记赋予权限,因为 Nginx 默认使用 nobody 用户启动,如果没有权限或者资源不存在,那么会抛出 403 错误。接下来修改 nginx.conf:
location / {
# 指定静态文件的根目录
root /root;
# index 可以同时指定多个文件,如果第一个不存在,那么会去找下一个
index satori.html index.html index.htm;
}
nginx -s reload 之后,我们再来访问一下。

此时就访问成功了,所以如果不扣底层细节,直接用 Nginx 的话还是很简单的,主要搞清楚配置文件怎么配就可以了。假设我们希望访问 IP:8888 时,返回 /usr/local/nginx/conf/nginx.conf 该怎么做呢?
# 可以配置很多个 server 快,因此 Nginx 可以监听多个端口
server {
listen 8888;
server_name localhost;
location / {
root /usr/local/nginx/conf;
index nginx.conf;
# .conf 后缀的文件会被浏览器当成二进制文件,直接下载下来
# 因此告诉浏览器,返回的内容是纯文本格式的,直接展示在页面上即可
default_type text/plain;
# 文本使用 UTF-8 编码,不然中文会出现乱码
charset utf-8;
}
}
nginx -s reload 之后,访问 8888 端口。
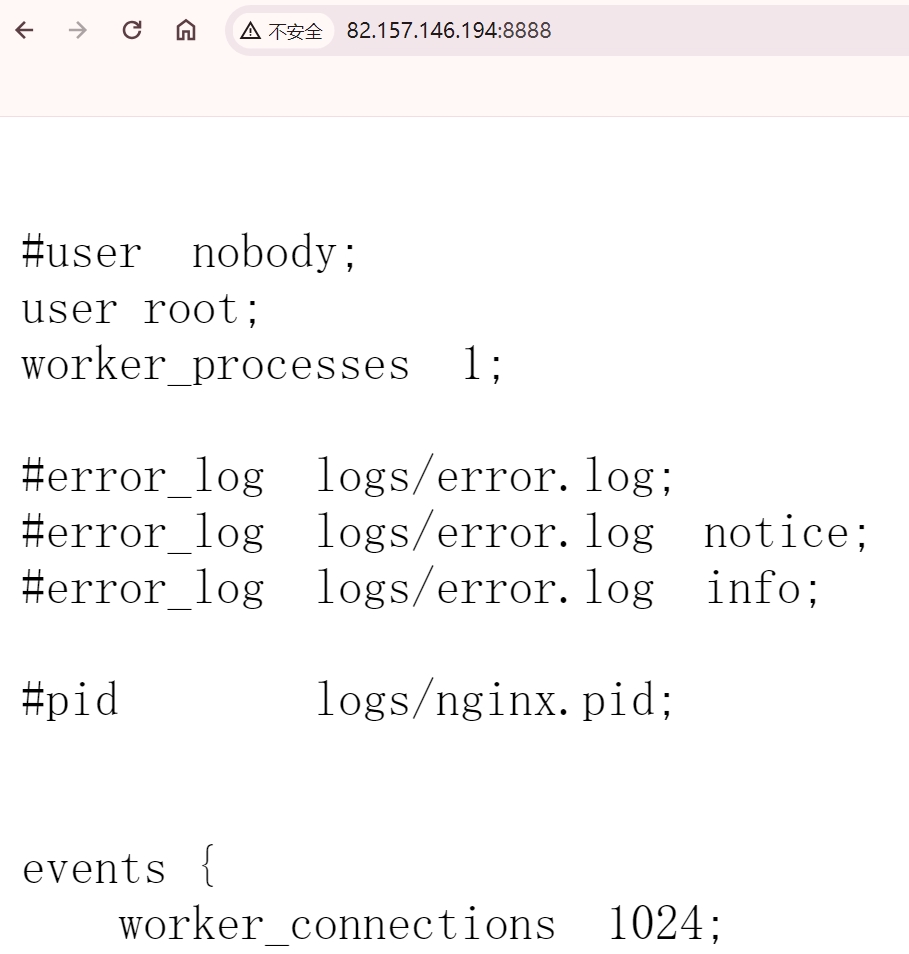
结果没有问题,一个 http 块可以配置多个 server 块,每个 server 块监听一个端口,并且可以配置多个 location 块。并且 default_type 和 charset 等指令可以放在单独的 location 中,也可以放在整个 server 中(会作用于所有的 location)。
实现反向代理(二)
需求:访问不同的路径,跳转到不同的 url。比如输入 IP/satori 的时候跳转到 bilibili 页面,输入 IP/koishi 的时候跳转到知乎页面。显然此时就需要两个 location 了,因为这是两个不同的url。
server {
listen 80;
server_name localhost;
# 这个原来的 location,就还让它保持原样
location / {
root html;
index index.html index.htm;
}
# 有了 proxy_pass,可以不用写 root 和 index 指令
location /satori {
proxy_pass https://www.bilibili.com;
}
location /koishi{
proxy_pass https://www.zhihu.com;
}
}
没有什么难度,我们来测试一下:
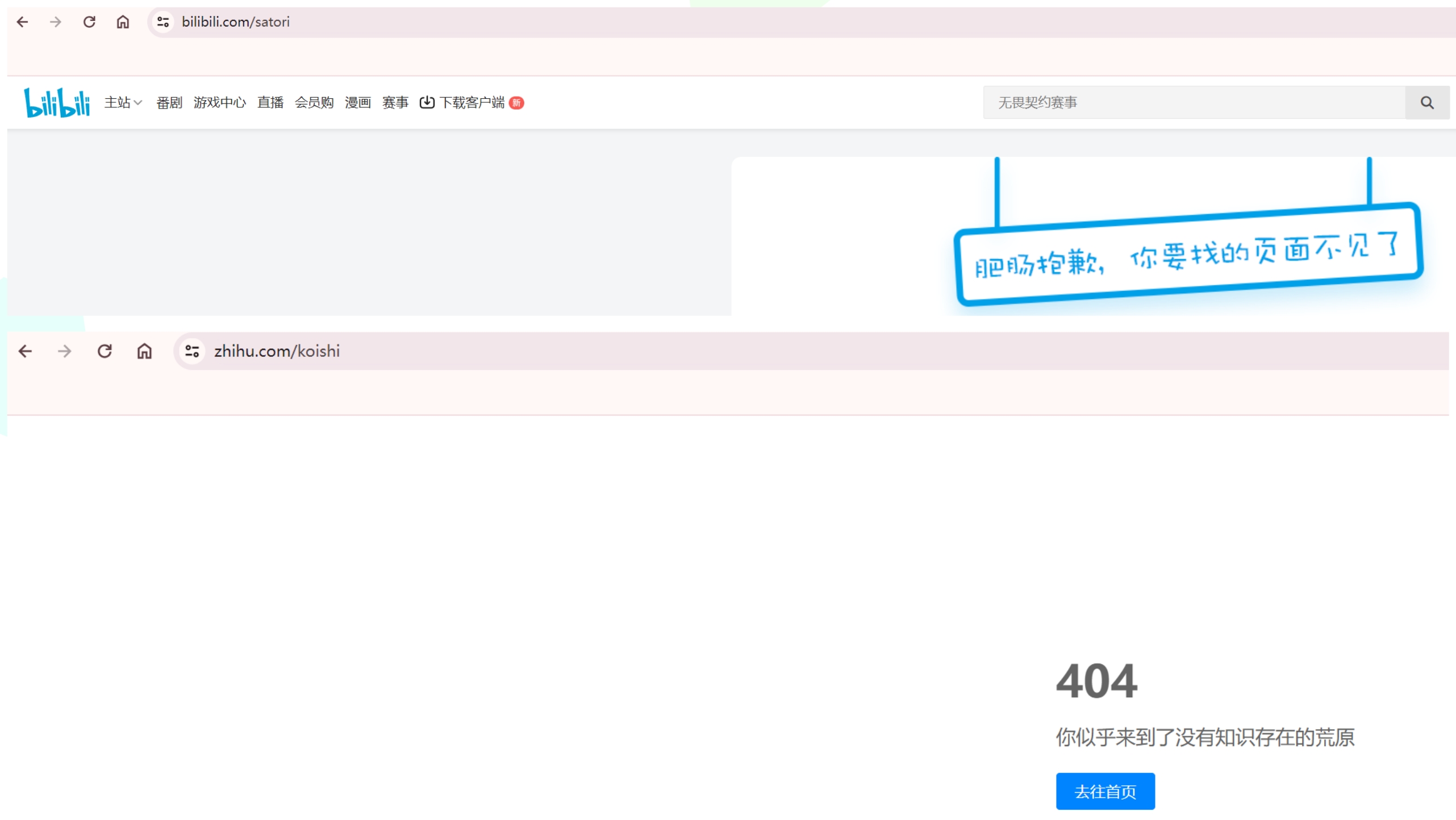
首先访问成功了,但是我们看到路径参数会自动跟在要映射的 URL 后面,即使路径参数有多个也是如此。
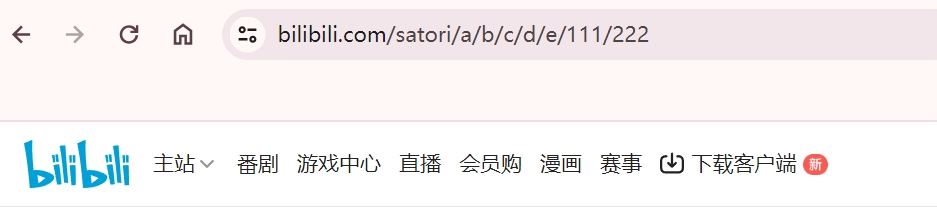
从图中可以看到,不管访问的 URL 有多长,只要 location 是访问的 URL 的路径参数的前缀,那么就算匹配上了。
location /satori访问的 URL 的路径参数 /satori/a/b/c/d/e/111/222
显然 location /satori 是访问的 URL 的路径参数的前缀,所以此时匹配成功,然后会将访问的 URL 的路径参数追加在 proxy_pass 指定的 URL 的屁股后面。但如果 proxy_pass 指定的 URL 也包含了路径参数,情况会稍有不同。
server {
listen 80;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
location /satori {
# 包含路径参数
proxy_pass https://www.bilibili.com/v/dance;
}
location /koishi{
proxy_pass https://www.zhihu.com;
}
}
此时访问 /satori/a/b/c,因为可以和 location /satori 匹配上,那么会跳转到 https://www.bilibili.com/v/dance/a/b/c 页面,但此时的路径中不包含 satori。因为 proxy_pass 指定的 URL 带有路径参数,因此公共的前缀会被去掉。
import requests
res = requests.get("http://82.157.146.194/satori/a/b/c")
# 我们看到 satori 被去掉了
print(res.request.url)
"""
https://www.bilibili.com/v/dance/a/b/c
"""
res = requests.get("http://82.157.146.194/koishi/a/b/c")
# location /koishi 内部的 proxy_pass 指定的 URL 没有路径参数
print(res.request.url)
"""
https://www.zhihu.com/koishi/a/b/c
"""
总结:如果 location 是访问的 URL 的路径参数的前缀,那么两者匹配成功,此时请求会被转发到 proxy_pass 指定的 URL 中。如果 proxy_pass URL 没有路径参数,那么访问的 URL 的路径参数会被完整追加到 proxy_pass URL 中;如果 proxy_pass URL 包含了路径参数,那么访问的 URL 的路径参数中去除 location 的部分会被追加到 proxy_pass URL 中。
为了更好地理解,我们再举个例子。
import requests
# location /koishi,然后 proxy_pass 是 http://www.koishi.com
# /koishi 是 /koishi001/a/b/c 的前缀,两者能匹配上
res = requests.get("http://82.157.146.194/koishi001/a/b/c")
# 最终访问的 URL 是 http://www.koishi.com/koishi001/a/b/c
print(res.request.url)
"""
https://www.zhihu.com/koishi001/a/b/c
"""
# location /satori,然后 proxy_pass 是 http://www.bilibili.com/v/dance
# /satori 是 /satori001/a/b/c 的前缀,两者能匹配上
res = requests.get("http://82.157.146.194/satori001/a/b/c")
# 但 proxy_pass 带有路径参数,所以 location 会被去掉,留下的是 001/a/b/c
# 然后追加在 proxy_pass URL 后面,因此最终访问的 URL 是 https://www.bilibili.com/v/dance001/a/b/c
print(res.request.url)
"""
https://www.bilibili.com/v/dance001/a/b/c
"""
当然上面的 location 只有一个路径参数,而有多个也是可以的,规则不变。
问题来了,如果我们希望访问 IP 跳转到 bilibili,访问 IP:8888 跳转到 baidu 该怎么做呢?显然此时不再是添加 location 能解决的问题了,因为它们的端口都不一样了。但解决办法仍然简单,增加一个 server 块即可,我们说一个 http 块里面可以包含一个 http 全局块和多个 server 块。也就是说,Nginx 可以同时监听多个端口。
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://www.bilibili.com;
}
}
server {
listen 8888;
server_name localhost;
location / {
proxy_pass http://www.baidu.com;
}
}
Nginx 可以监听多个端口,如果我们只输入 IP、或者 IP:80,那么会被转发到 bilibili;如果输入 IP:8888,那么会被转发到 baidu。尽管 location 相同,但它们是在不同的端口下,因此不会相互影响。
实现反向代理(三)
需求:只要访问的 URL 中包含了 satori,就跳转到 bilibili。也就是说 url 可以是 IP/satori、IP/aaa/satori、ip/aaa/bbb/c/satori/aa,只要路径参数中包含了 satori,那么就跳转到 bilibili,怎么做呢?
这种做法显然要使用正则来实现,对于上面的需求,location 使用正则简直不要太好配,直接 ~ /satori 即可。此时匹配上之后,所有的路径参数同样会跟在跳转的 URL 的后面。
server {
listen 80;
server_name localhost;
location ~ /satori {
# 跳转的 URL
proxy_pass http://www.bilibili.com;
}
}
配置完成,重启加载配置文件,然后访问 IP/a/b/c/satori/d/e。
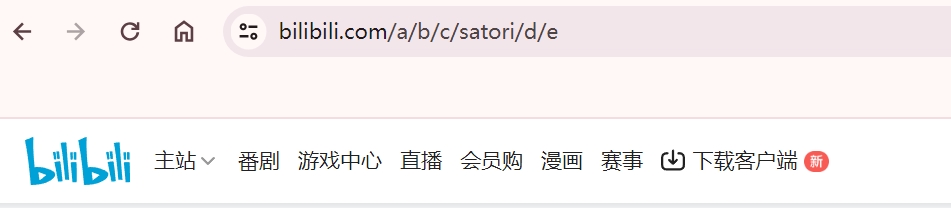
只要路径有 satori,那么就能匹配成功,然后访问的路径参数会自动全部跟在跳转的 URL 的屁股后面。那如果 proxy_pass URL 包含路径参数呢?答案是如果使用了正则表达式,那么 proxy_pass URL 不允许包含路径参数。
下面简单介绍一下 Nginx 中的正则,主要体现在 location 中:
=:表示 url 不包含正则表达式,要求访问的 url 和 location 指定的 url 完全一致~:url 包含正则表达式,并且区分大小写~*:url 包含正则表达式,并且不区分大小写^~:url 不包含正则表达式,要求 Nginx 找到请求的 url 和 location 指定的 url 相似度最高的 location,然后用该 location 进行请求处理
当然 ^ 跟在路径前面表示这个以此为开头,同理还有 $ 跟在路径后面表示以此为结尾。
负载均衡
需求:假设有两台服务器,我们需要实现当访问 IP:90/satori 的时候,能够把请求转发到不同的服务器当中去,也就是实现负载均衡的效果。而实现这个功能需要使用 upstream,我们在介绍 http 全局块的时候说过 upstream 用于负载均衡,但是怎么使用没有说,那么现在就来介绍一下。
http {
include mime.types;
# 之前我们介绍过 default_type,它可以放在 http 全局块中,作用所有的 server 下的所有 location
# 也可以放在某个 server 中,作用指定 server 下的所有 location
# 当然也可以放在某个 location 中,只针对所在的 location,如果都指定了,那么优先级从内到外依次降低
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
# 使用 upstream,然后给 upstream 起一个名字,假设就叫 my_server
upstream my_server {
# 写上你要转发的机器的 IP 地址或主机名
server 39.23.48.129:5555;
server 39.35.137.238:6666;
}
server {
# 监听 90 端口
listen 90;
# 主机依旧是本地
server_name localhost;
# 配置 location
location /satori {
# 这里将 proxy_pass 改成 http://my_server 即可,这个 my_server 就是给 upstream 起的名字
proxy_pass http://my_server;
}
}
}
当我们访问 IP:90/satori 的时候,就会将请求转发到 http://my_server 中,也就是 upstream my_server 中指定的目标服务器。
但随着互联网信息的爆炸式增长,负载均衡(Load Balance)早已不再是一个陌生的话题,就是把负载分摊到不同的存储单元,既保证服务的可用性,又保证服务足够快。但问题是负载均衡只是平摊负载吗?如果有的机器性能好,那么它的负载是不是应该要多一些呢?所以 Nginx 在负载均衡方面有如下策略。
轮询(默认)
每个请求按照时间顺序逐一分配到不同的后端服务器,如果后端服务器宕机了,会自动剔除。
weight(权重)
权重越高,被分配的请求越多,权重与请求数成正比。默认是 1,比如 server 39.23.48.129:5555 weight=10,此时 39.23.48.129:5555 这台服务器的权重就是 10。
ip_hash
每个请求按访问 IP 的 hash 结果分配,这样每个访客固定访问一个后端服务器,可以解决 Session 的问题。
upstream my_server {
ip_hash;
server 39.23.48.129:5555;
server 39.35.137.238:6666;
}
fair
按照服务器的响应时间来分配,响应时间短的优先分配。
upstream my_server {
fair;
server 1.1.1.1:80;
server 2.2.2.2:88;
}
动静分离
Nginx 的动静分离简单来说,就是把动态请求和静态请求分开,但不能理解成只是把动态页面和静态页面物理分离。严格来讲,是动态请求和静态请求分开,可以理解成使用 Nginx 处理静态页面,uWSGI 处理动态页面,动静分离从实现角度上大致分为两种:
纯粹把静态文件独立出来,放在一个单独服务器上,也是目前主流方案把动态和静态文件放在一起,通过 Nginx 来分开
在 /etc/ssh 目录下有一些文件,下面我们就进行配置,通过 Nginx 直接访问静态资源。我们希望当输入 /file/xxx 的时候,就会访问 /etc/ssh 下面的 xxx。
server {
listen 80;
server_name localhost;
# 配置 location
location /file {
# 当我们访问 /file/xxx,会返回 /etc/ssh/xxx
alias /etc/ssh;
# 而这个 autoindex 指的是当输入 /file 的时候,是否把 /etc/ssh 里面的内容全部列出来,像索引一样
# 可以通过点击的方式访问指定的静态资源
autoindex on;
}
}
我们输入 IP/file 查看一下。
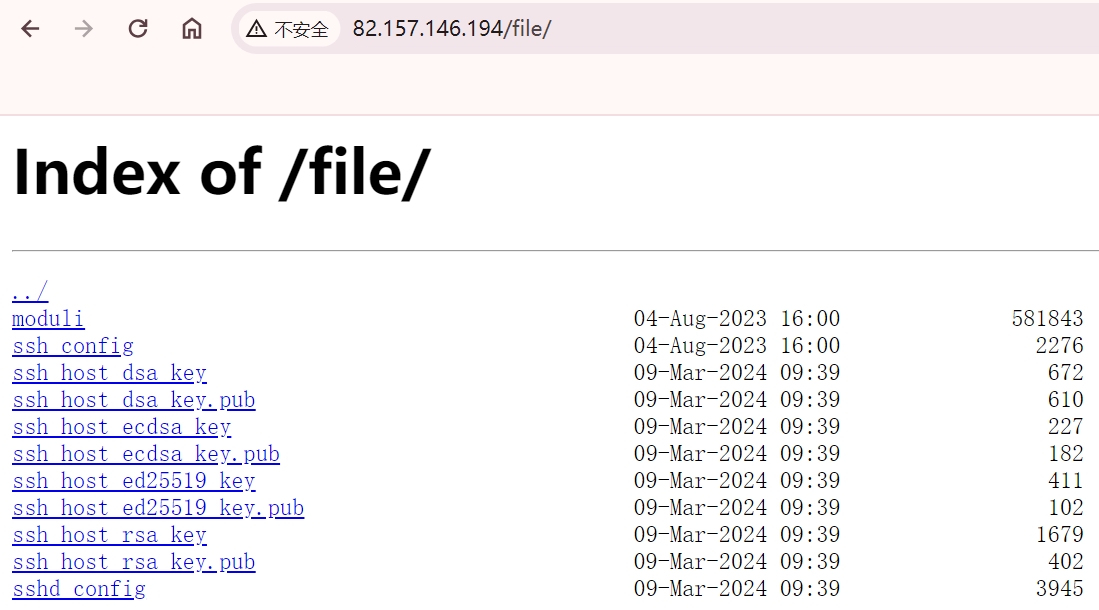
点击之后即可访问指定的文件,当然也可以直接输入 URL。然后这里出现了 alias,它和之前的 root 有什么区别呢?其实这两者的区别主要在于 Nginx 如何解释 location 后面的 url。对于上面来说,访问 /file/xxx,那么得到的就是 /etc/ssh/xxx;如果将 alias 改成 root,那么访问 /file/xxx,得到的就是 /etc/ssh/file/xxx。所以对于 alias 而言,它不会把 location 后面的路径给带过去,但是 root 会。
并且 root 可以出现在 http、server、location、if 等很多块中,但是 alias 只能出现在 location 块中。所以对于 location 而言,如果访问的是根路径,那么就按照 Nginx 默认使用 root 即可,返回写死的文件,一般都是一个默认的 html 文件;如果访问的不是根路径,那么就使用 alias 来实现返回静态文件的效果,显然这是最正确的做法。
另外如果我们不希望输入 /file 的时候显示所有的内容,那么只需要将 autoindex on 给注释掉即可。但如果我们又希望在输入 /file 的时候返回一个默认的文件,那么可以通过 index xxx 的方式实现。
要是 index 和 autoindex 都指定了,那么优先 index;如果 index 指定的文件都找不到,那么再看 autoindex。
server_name
假设你的服务器绑定了一个域名,就叫 example.com 吧,现在需要实现以下需求:
访问 www.example.com 跳转到百度访问 bilibili.example.com 跳转到哔哩哔哩访问 zhihu.example.com 跳转到知乎
server {
listen 80;
server_name www.example.com;
location / {
proxy_pass http://www.baidu.com;
}
}
server {
listen 80;
server_name bilibili.example.com;
location / {
proxy_pass http://www.bilibili.com
}
}
server {
listen 80;
server_name zhihu.example.com;
location / {
proxy_pass http://www.zhihu.com
}
}
这里指定了多个 server,监听的端口是一样的,但 server_name 不一样,也就是说如果有多个 server,那么 list 和 server_name 组合起来必须是唯一的。因此这三个 server 虽然 listen 一样,但 server_name 不一样,所以没有问题。根据 server_name 的不同,会转发到不同的地址,比如:
访问 bilibili.example.com/v/dance 会跳转到 www.bilibili.com/v/dance
当然啦,上面是属于精确匹配,但 server_name 也可以指定通配符。
server {
listen 80;
# 所有以 .mail.example.com 结尾的域名会匹配成功,比如 google.mail.example.com
# server_name 可以指定多个,比如我们希望 mail.example.com 本身也能匹配上
server_name *.mail.example.com mail.example.com;
location / {
proxy_pass http://www.baidu.com;
}
}
server {
listen 80;
# 还可以使用正则表达式,比如匹配以 www. 开头、.example.com 结尾的域名
server_name ~^www\..+\.example\.com?;
location / {
proxy_pass http://www.bilibili.com;
}
}
注意:通配符只能在 server_name 的起始处或结尾处使用一个星号,并且星号与其它字符之间用点号分隔,所以 www.*.example.com 就是非法的。然后是正则,如果使用正则,那么必须以 ~ 开头,否则会被认为是一个普通的名字。并且开头和结尾需要 ^ 和 $ 作为锚点,尽管语法上不是必须的,但逻辑上必须这么做,然后域名中的点号记得转义。
由于我这里没有域名,具体就不演示了。
如果觉得文章对您有所帮助,可以请囊中羞涩的作者喝杯柠檬水,万分感谢,愿每一个来到这里的人都生活愉快,幸福美满。
微信赞赏

支付宝赞赏


 浙公网安备 33010602011771号
浙公网安备 33010602011771号