

DOM LEVEL 1 中的那些事儿[总结篇-上]
DOM是前端编程中一个非常重要的部分,我们在动态修改页面的样式、内容、添加页面动画以及为页面元素绑定事件时,本质都是在操作DOM。DOM并不是JS语言的一个部分,我们通过JAVA、PHP等语言抓取网页内容时需要对网页进行解析并拿到我们感兴趣的那部分内容,这时其实也是在操作DOM。当然在前端领域,我们肯定还是通过JS来操作DOM,而DOM也是伴随JS的出现而诞生的,随着前端的不断发展,DOM标准也在不断演进,每个新的版本都为DOM进行了一定程度的扩展。本文主要总结DOM1级中的核心内容。
1、DOM的定义及历史
1998年10月,DOM1成为了W3C的推荐标准,我们看下标准中对于DOM的定义:
The Document Object Model (DOM) is an application programming interface (API) for HTML and XML documents. It defines the logical structure of documents and the way a document is accessed and manipulated.
从定义中可以看出,DOM是HTML或XML的API,它定义了文档的逻辑结构并且提供了能够操纵文档内容的方式,我们再看一下文档中提到的:
With the Document Object Model, programmers can build documents, navigate their structure, and add, modify, ordelete elements and content.
也就是说,我们通过DOM,可以构建一个文档、遍历文档结构,并且对文档元素和内容进行增、删、改。
1.1 DOM发展概述
非标准时期—DOM 0:
DOM是Netscape最早提出,并且与JS的诞生是在同一个时间。Netscape2浏览器首先实现了DOM,那时的DOM可以成为DOM0级,DOM0级中定义了获取文档中一些元素的入口,比如form(document.forms)和image(document.images),后期的浏览器为了实现向后兼容,同样也支持DOM0中的这些接口。在JS事件中,我们经常提及的DOM0事件,也是在这个阶段定义的。
标准时期—DOM1、2、3、4:
1998年10月,DOM1成为了W3C的推荐标准。DOM1主要定义的是HTML和XML文档的底层结构,为基本的文档结构和查询提供了接口。DOM2和DOM3标准的核心内容分别在2000年和2004年被提出,现代浏览器对DOM2和3已经有了比较好的支持。而在W3C的官网上,DOM4也已经在2015年11月份发布。
本文主要总结DOM1中的主要内容。
2、DOM1中的那些东东
DOM1定义了HTML和XML文档的底层结构,而这个结构其实就是由不同的节点(Node)构成的一个树状结构(DOM Tree),树的根节点就是文档的根节点(对于HTML来说,就是html节点)。在DOM树中,节点分为不同的类型,节点之间通过某种关系(父子关系,兄弟关系等)结合起来,就构成了整棵DOM树。这里对于树的结构我们不做深入分析,而重点放在构成树的这些不同类型的节点,了解了不同节点所拥有的特性和方法,那么我们进行基本的DOM操作就可以游刃有余了。
2.1 所有节点的基类—Node
我们通过浏览器的调试工具来看一下Node类型所具有的方法和属性(这些方法和属性是定义在Node的prototype上的,即由所有子类的实例所共享的):

我们可以看到,Node类的原型对象定义了很多的属性和方法(IE中不能直接访问该类),I比如最常见的nodeName, nodeValue, nodeType, childnodes, appendChild等等,这些方法是每一个节点类型都具有的(由于我们是在较新版的chrome浏览器中打印出如下内容的,因此有些方法可能后来的DOM标准扩展进来的)。 下面我们来对DOM1中Node的这些共享方法进行一下总结:
2.1.1 表示节点自身属性的
(1)nodeType属性:从截图中可以看出,Node类有一些静态属性表示不同类型的节点序号,DOM1中一共有12种节点类型:
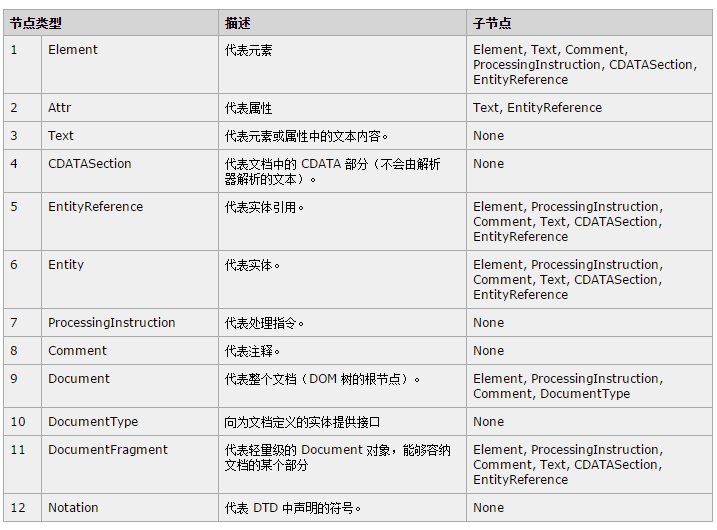
在HTML中,我们最常用的节点类型有:元素节点Element(1),属性节点Attr(2),文本节点Text(3),文档节点Document(9)。
(2)nodeName和nodeValue
这两个属性完全取决于节点的类型,nodeName是节点的标签名,nodeValue是节点的值。对于元素节点Element来说,nodeValue始终为null。
2.1.2 表示节点关系的
DOM中的节点之间具有某种关系,正是通过这些关系构建起了DOM树,Node中定义了能够让我们通过这些关系来操作DOM节点的属性和方法。
(1)childnodes属性:这个属性返回该节点的所有子节点所构成的NodeList对象,关于NodeList对象的操作可以参照《JavaScript高级程序设计》第3版的10.1节。
(2)parentNode属性:指向节点的父节点
(3)previousSibling和nextSibling属性:前一个和后一个兄弟节点,兄弟节点即拥有同一个父节点的节点。
(3)firstChild和lastChild属性:第一个和最后一个子节点
(4)hasChildNodes()方法:判断一个节点是否有一个或多个子节点
(5)ownerDocument:指向节点所在的文档对象Document
注:虽然每一个节点都有childNodes属性,但有些节点是没有子节点的,这一点在介绍具体的节点类型时会详细说明。
2.1.3 节点操作方法
(1)最常用的节点操作方法就是appendChild(),该方法用于为节点增加一个子节点,并返回新增的子节点。如果新增的子节点在调用这个方法前不是该节点的子节点,那么就将新增的节点添加到该节点的末尾;反之,则是把已经存在的子节点移动到该节点的末尾。
(2)insertBefore():这个方法接收两个参数:要插入的节点和参照节点,如果不传第二个参数,则默认增加到末尾。
(3)replaceChild():这个方法可以起到删除节点的作用,同样接收两个参数,第一个参数为要插入的节点,第二个参数为要替换的节点;如果参数不足2个则会报错。替换后的节点的所有关系指针都会从被它替换的节点复制过来。被替换的节点依然在文档中,但是文档中已经没有它的位置。
(4)removeChild():删除一个节点,与replaceChild相似,被删除的节点仍然在文档中,但是已经没有它的位置了。
2.1.4 其他方法
(1)cloneNode():cloneNode()方法执行对一个节点的复制并返回复制的节点,这个方法还接收一个布尔值参数,表示是否执行深复制。如果执行深复制,那么就克隆这个节点的整个节点树,否则就只克隆这个节点。
注:在执行 节点复制时,IE存在一个bug,即会复制该节点的JS属性,比如事件处理程序。
(2)normalize():这个方法的作用是处理文档中的文本节点,比如删除空的文本节点,合并相邻的两个文本节点等。
2.2 Document类型
在JS中,Document类型表示整个文档,在浏览器中,document对象是HTMLDocument的一个实例,表示整个HTML页面,同时它还是window对象的一个属性,因此可以将其作为全局对象来访问。它有如下特性:
[1]nodeType为9
[2]nodeName为#document
[3]nodeValue为null
[4]parentNode为null
[5]ownerDocument为null
[6]子节点可能是一个DocumentType(最多一个)、Element(最多一个)、ProccessingInstruction或Comment。
Document类型可以表示HTML页面或其他基于XML的文档,但最常见的还是作为HTMLDocument的实例代表一个HTML页面,通过document对象,不仅可以取得与页面相关的信息,还可以对页面的内容和结构进行修改。
2.2.1 获得文档的子节点
有两种方式可以获取文档的子节点:通过documentElement属性,这个属性指向html元素,或者通过childNodes[0]。
另外,作为HTMLDocument实例的document对象还有一个body属性,即document.body,指向<body>元素。
Document的子节点还可能是DocumentType,但浏览器对于document.doctype属性的支持差异较大,总结为如下:
[1]IE8及以下的版本,如果存在文档类型声明,会错误地把它视为一个Comment节点,而document.doctype始终为null。
[2]对于IE9+和其他新版浏览器,如果存在文档类型声明,则会把它作为document的第一个子节点。
注:《JavaScript高级程序设计》第三版的10.1.2节提到,Safari,chrome以及opera在文档类型声明存在的情况下,会解析文档声明,但是不作为document的子节点,在chrome47.0.2526.80中测试发现是会作为document的子节点的。
2.2.2 关于文档的信息
作为HTMLDocument的一个实例,document对象还有普通Document实例对象没有的属性,这些属性提供了一些与网页有关的信息:
(1)document.title:通过title属性可以获取该网页的标题,也可以修改该网页的标题,并且修改后的标题会反应在浏览器的标题栏。
(2)document.URL、document.domain、document.referrer:这三个属性全部对应于HTTP的头部之中,其中,URL属性可以取得完整的URL,domain可以取得域名,referrer可以取得当前页面的来源页面,如果没有来源页面,那么referrer为空。
这三个属性中,只有domain是可以设置的,但是在设置时也存在一些限制,即:不能将domain设置成URL属性中不包含的域,另外,如果一开始domain的设置的"松散的",则不能再将它设置成"紧绷的".。
比如一开始的时候:document.domain = xx.com,然后再设置:document.domain = ss.xx.com时就会报错了。
2.2.3 查找元素
document中定义的getElementById与getElementsByTagName方法恐怕是我们接触js dom操作时最先接触到的方法了,这两个方法也是查找元素时使用的非常常用的两个方法,另外,HTMLDocument还有一个特有的getElementByName方法,即根据name属性来查找元素。
(1)getElementById()方法:根据元素的id来查找元素,这个方法的注意点在于除IE7以及以下版本的浏览器中是区分大小写的。另外如果页面中存在多个ID相同的元素,则只会取第一个匹配到的元素。IE7及以下版本的浏览器中还有一个奇怪的现象:如果一个表单元素的name属性与该方法的id参数匹配,而且该元素在id匹配的元素之前,那么也会返回该元素。
(2)getElementsByTagName()方法:根据元素的标签名来查找元素,这个方法接收一个参数,并且会返回标签名与传入参数相匹配的元素组成的NodeList对象。在HTMLDocument中,返回的是一个HTMLCollection对象,这个对象与NodeList非常相似,除了可以用item()方法访问特定数值索引的节点之外,它还提供了namedItem()方法来匹配列表中特定name的元素;同时我们可以直接使用方括号的方法访问列表中特定的元素,可以传入数值索引值,也可以传入字符串值,后台会自动调用相应的方法。
注:我们还可以传入一个"*"通配符来获取页面的所有元素。
(3)getElementsByName()方法:这个也是HTMLDocument才有的方法,是根据name属性值来查找元素,与getElementByTagName相似,该方法也返回NodeList对象,而在HTMLDocument中返回的是HTMLCollection对象。
2.2.4 特殊集合
document对象还有一些特殊集合,并且很多特殊集合其实在DOM0阶段就已经存在了:
(1)document.anchors:获取页面中的所有锚点,即有name属性的a元素。
(2)document.applets:获取页面中所有的applet元素,但是现代web中已经很少出现applet元素了。
(3)document.images:获取页面中所有的img元素。
(4)document.links:获取页面所有带href属性的a元素。
2.2.5 DOM一致性检测
由于DOM分为多个级别,也包含多个部分,因此检测浏览器实现了哪一部分就十分必要。document.implementation属性就是为此提供相应信息的。DOM1级只为document.implementation实现了一个方法:hasfeature(),该方法接收两个参数,第一个是DOM功能的名称,第二个是版本号。如果浏览器支持给定的功能和版本则返回true,下表列出了可检测的功能和版本号。
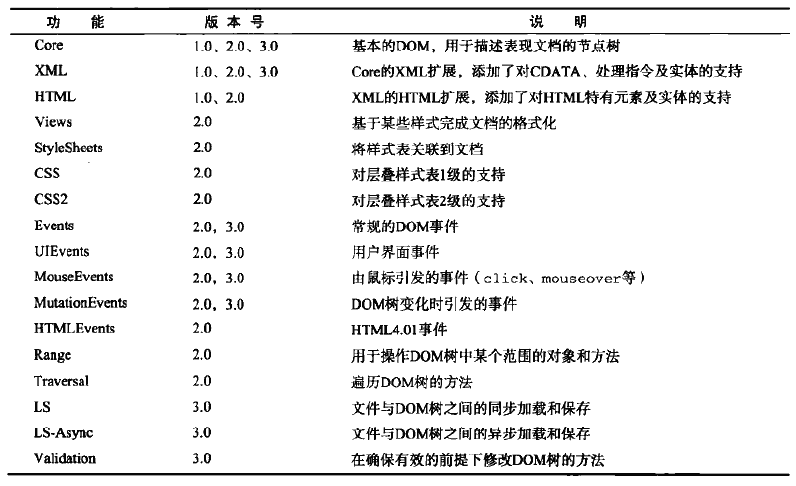
DOM一致性检测也存在不足,因为浏览器在实现时可以自行决定是否与DOM的功能保持一致,而且使得hasfeature()返回true容易,但是返回true却并不代表着浏览器确实实现了该功能。因此,在使用某个功能之前,还是要进行能力检测。
2.2.6 文档写入
document还提供了向文档写入内容的功能,有以下几个方法:
(1)document.write()和document.writeln():这两个的不同之处在于writeln会在每一次调用的末尾写入一个\n符号。如果在文档加载结束后再调用这两个方法,则会重写整个页面。
(2)document.close()和document.open():分别用于关闭和打开网页的输入流。
未完待续~~~

