Kafka-爬虫

这看起来似乎和数据直接写进 MongoDB 里面,然后各个程序读取 MongoDB 没什么区别啊?那 Kafka 能解决什么问题?
我们来看看,在这个爬虫架构里面,我们将会用到的 Kafka 的特性:

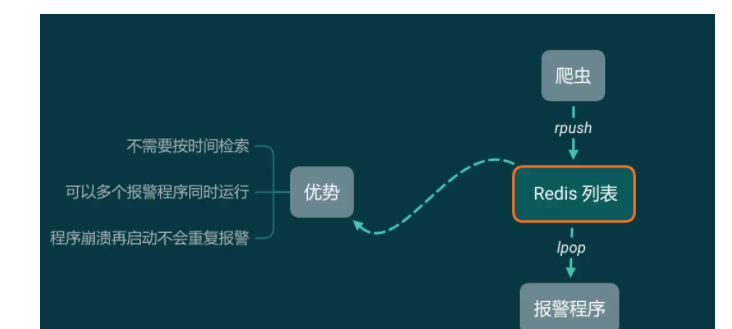
与其说 Kafka 在这个爬虫架构中像 MongoDB,不如说更像 Redis 的列表。
现在来简化一下我们的模型,如果现在爬虫只有一个需求,就是搜索,然后报警。那么我们可以这样设计:
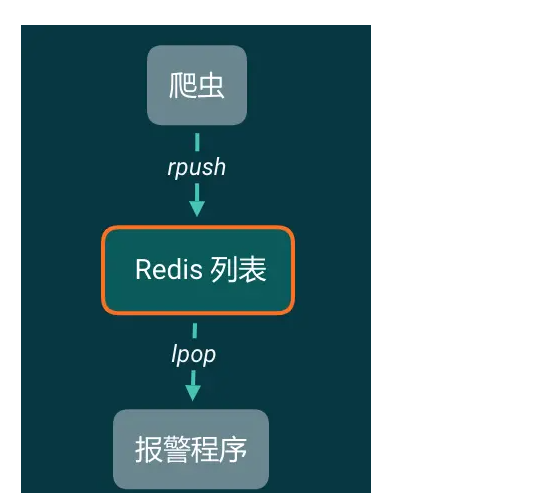


程序1:报警
从 Kafka 中一条一条读取数据,做报警相关的工作。程序1可以同时启动多个。关了再重新打开也不会重复消费。
程序2:储存原始数据
这个程序从 Kafka 中一条一条读取数据,每凑够1000条就批量写入到 MongoDB 中。这个程序不要求实时储存数据,有延迟也没关系。存入MongoDB中也只是原始数据存档。一般情况下不会再从 MongoDB 里面读取出来。
程序3:统计
从 Kafka 中读取数据,记录关键词、发布时间。按小时和分钟分别对每个关键词的微博计数。最后把计数结果保存下来。
程序4:情感分析
从 Kafka 中读取每一条数据,凑够一批发送给 NLP 分析接口。拿到结果存入后端数据库中。
大批量通用爬虫
除了上面的微博例子以外,我们再来看看在开发通用爬虫的时候,如何应用 Kafka。
在任何时候,无论是 XPath 提取数据还是解析网站返回的 JSON,都不是爬虫开发的主要工作。爬虫开发的主要工作一直是爬虫的调度和反爬虫的开发。
我们现在写 Scrapy 的时候,处理反爬虫的逻辑和提取数据的逻辑都是写在一个爬虫项目中的,那么在开发的时候实际上很难实现多人协作。
现在我们把网站内容的爬虫和数据提取分开,实现下面这样一个爬虫架构:
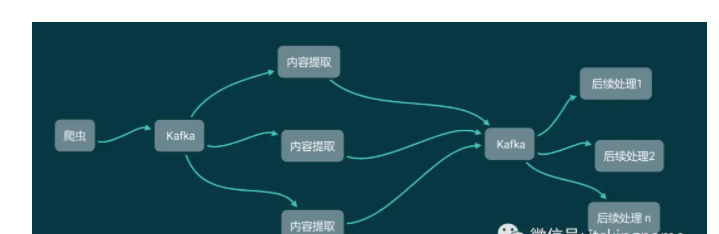
爬虫开发技术好的同学,负责实现绕过反爬虫,获取网站的内容,无论是 HTML 源代码还是接口返回的JSON。拿到以后,直接塞进 Kafka。
爬虫技术相对一般的同学、实习生,需要做的只是从 Kafka 里面获取数据,不需要关心这个数据是来自于 Scrapy 还是 Selenium。他们要做的只是把这些HTML 或者JSON 按照产品要求解析成格式化的数据,然后塞进 Kafka,供后续数据分析的同学继续读取并使用。
如此一来,一个数据小组的工作就分开了,每个人做各自负责的事情,约定好格式,同步开发,互不影响。
为什么是 Kafka 而不是其他
上面描述的功能,实际上有不少 MQ 都能实现。
但为什么是 Kafka 而不是其他呢?因为Kafka 集群的性能非常高,在垃圾电脑上搭建的集群能抗住每秒10万并发的数据写入量。而如果选择性能好一些的服务器,每秒100万的数据写入也能轻松应对。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号