一致性Hash与Redis集群数据分片
一、Hash算法引入--分布式缓存
有一个电商平台,需要使用Redis存储商品的图片资源,key为图片名称,value为图片所在服务器的路径。利用随机分配的规则进行分库。总量3000w,以每台服务器存500w的数量,部署12台缓存服务器,并且进行主从复制,架构图如下图:
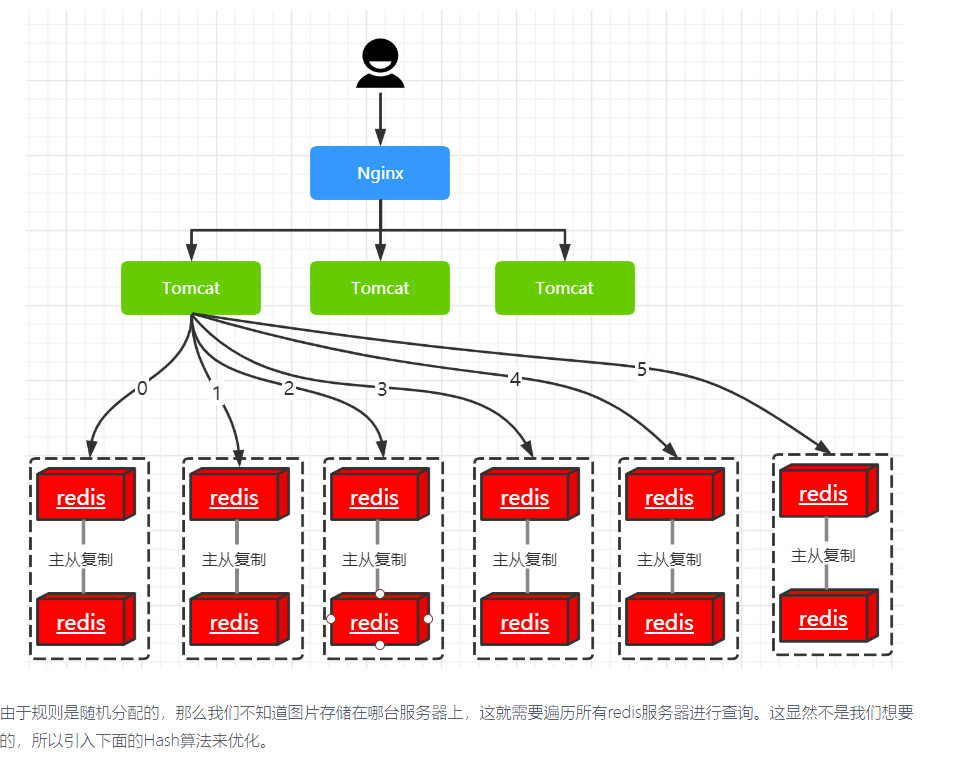
1.Hash算法优化
目的是为了每张图片在进行分库时都可以得到特定的服务器。我们共有六台主服务器,计算的公式为:hash(milk.png) % 6 = 5 这样就不需要进行遍历redis主从服务器,节省时间,提升性能。

2.Hash算法弊端
当Redis缓存服务器的节点数发生变化时,所有的缓存位置都会发生改变。 假如我们增加2台Redis缓存服务器,计算公式从`hash(milk.png) % 6 = 5`变成了`hash(milk.png) % 8 = ?` 结果肯定不是5。 再或者,6台服务器集群中,当某个主从出现故障无法进行缓存,故障机器需要移除,取余数从6变成5,也会导致缓存位置更改。 为了解决上述问题,又引入了Hash一致性算法
二、一致性Hash算法引入
再说一致性Hash算法原理之前,首先要知道我们现在在做的是要优化我们的分配规则,这个优化就是通过(一致性hash算法)进行优化,算法如何实现的不去深究,只要知道算法最终达到的效果即可。
1.分配规则
一致性Hash是由一个固定长度的Hash环构成,大小为2的32次方.
一般用在服务器集群的增删节点的处理上,根据节点名称的Hash值(其分布为[0, 2^32-1])将服务器节点放置在这个Hash环上,然后根据数据的Key值计算得到其Hash值(其分布也为[0, 232-1]),接着在Hash环上顺时针查找距离这个Key值的Hash值最近的服务器节点,完成Key到服务器的映射查找!
节点分配规则
图1为hash环的整体布局,数值为[0, 2^32-1] 图2中A、B、C三个节点对其ip:port经过hash计算之后得到三个值,对应hash环上ABC三个点,因此将整个hash环分成3部分 图2中1234代表4个值经过hash计算后的位置,那么依据顺时针找服务器节点的方式 1,2->A节点, 4->B节点, 3->C节点
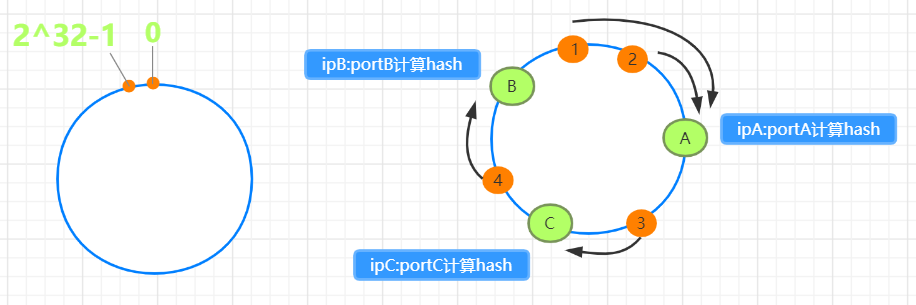
增加和减少节点的影响
图1为去掉C节点后的分布,如图所示,按照规则,3->B节点,A节点无影响 图2增加D节点,1->D节点,2->A节点,B和C节点无影响

2.虚拟节点
如上图所示已经帮我们解决了最初Redis分布式缓存集群在增加节点和减少节点的情况下,找不到图片路径的问题。但是由上面的增减节点,我们会发现一个问题---节点分布不均匀,会导致各个节点负载不均衡。又引出虚拟节点的概念。
图1中只有AB俩个节点且分布不均衡 1->A,2345->B
图2中采取增加副本数为2的算法,那么总共就是4个节点 A1&A2->A,B1&B2->B,结果1->A1,5->A2,2&3->B2,4->B1,即1&5->A,2&3&4->B
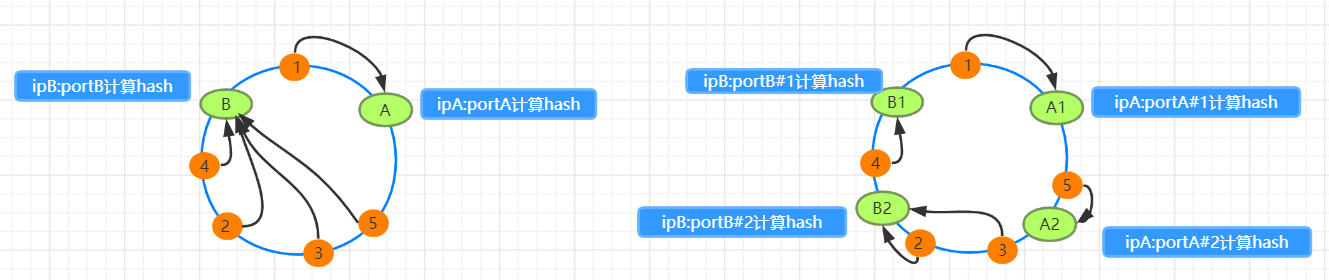
给出以下参数建议
横轴表示需要为每台服务器扩展的虚拟节点数,纵轴表示的是实际物理服务器数。
可以看出,物理服务器很少,需要更大的虚拟节点;反之物理服务器比较多,虚拟节点就可以少一些。
比如有10台物理服务器,那么差不多需要为每台服务器增加100~200个虚拟节点才可以达到真正的负载均衡
三、Redis集群分片
1.Redis 集群协议中的客户端和服务器端
1.1服务端节点功能,为满足下面的功能,集群节点之间通过gossip协议传播信息,监测心跳等功能
1.存储数据 2.记录集群的状态(包括键值到正确节点的映射) 3.自动发现其他节点,检测出没正常工作的节点, 并且在需要的时候在从节点中推选出主节点
以下是节点文件nodes.conf中的节点信息参数含义:

epoch 从节点选举机制:
epoch是一个集群中的逻辑时钟,主要用于从节点提升的过程,这个值在节点进行ping-pong时进行传输,在节点最初创建的时候,每个节点都会产生一个epoch值定义为currentepoch,如上图所示按节点顺序及主从顺序,产生了epoch的值1 2 3 4 5 6,以下是理解案例,只需要"大多数主节点"同意即可,案例只为演示epoch值增加的一个过程,正常是不需要请求从节点的同意的 主节点1宕掉 从节点1要想执行failover指令,要获得其他节点的同意,而其他节点只支持epoch的值最大的节点所提出的选举 从节点1 -> 主节点2 发送ping epoch4 - 回复pong epoch4 从节点1 -> 主节点3 发送ping epoch4 - 回复pong epoch4 从节点1 -> 从节点2 发送ping epoch4 - 回复pong currentepoch5 从节点1 -> 从节点2 发送ping currentepoch(5+1) - 回复pong epoch6 从节点1 -> 从节点2 发送ping epoch6 - 回复pong currentepoch6 从节点1 -> 从节点2 发送ping currentepoch(6+1) - 回复pong epoch7 此时,从节点1获取最大的epoch值,可以执行failover

1.2客户端功能:
由于集群节点不能代理(proxy)请求,所以客户端在接收到重定向错误(redirections errors) -MOVED 和 -ASK 的时候, 将命令重定向到其他节点。理论上来说,客户端是可以自由地向集群中的所有节点发送请求,在需要的时候把请求重定向到其他节点,所以客户端是不需要保存集群状态。 不过客户端可以缓存键值和节点之间的映射关系,这样能明显提高命令执行的效率。

1.在 Redis 集群中节点并不是把命令转发到管理所给出的键值的正确节点上,而是把客户端重定向到服务一定范围内的键值的节点上。 最终客户端获得一份最新的集群信息,包含哪些节点服务及其对应的键值子集,所以在正常操作中客户端是直接联系到对应的节点并把给定的命令发过去。 2.同样,由于一些命令不支持操作多个键值,如果不是槽重新分配(resharding),那么数据是永远不会在节点间移动的。 3.普通操作是可以被处理得跟在单一 Redis 上一样的。 这意味着,在一个拥有 N 个主节点的 Redis 集群中,由于 Redis 的设计是支持线性扩展的,所以你可以认为同样的操作在集群上的表现会跟在单一 Redis 上的表现乘以 N 一样。 同时,客户端会保持跟节点持续不断的连接,所以延迟数据跟在单一 Reids 上是一样的。
2.键分布模型
键空间被分割为 16384 槽(slot),所有的主节点都负责 16384 个哈希槽中的一部分。
当集群处于稳定状态时,集群中没有在执行重配置(reconfiguration)操作,每个哈希槽都只由一个节点进行处理
以下是用来把键映射到哈希槽的算法(下一段哈希标签例外就是按照这个规则):
HASH_SLOT = CRC16(key) mod 16384

通过客户端查询结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号