分布式任务队列Celery入门与进阶(一)
一、简介
Celery是由Python开发、简单、灵活、可靠的分布式任务队列,其本质是生产者消费者模型,生产者发送任务到消息队列,消费者负责处理任务。Celery侧重于实时操作,但对调度支持也很好,其每天可以处理数以百万计的任务。特点:
- 简单:熟悉celery的工作流程后,配置使用简单
- 高可用:当任务执行失败或执行过程中发生连接中断,celery会自动尝试重新执行任务
- 快速:一个单进程的celery每分钟可处理上百万个任务
- 灵活:几乎celery的各个组件都可以被扩展及自定制
应用场景举例:
1.web应用:当用户在网站进行某个操作需要很长时间完成时,我们可以将这种操作交给Celery执行,直接返回给用户,等到Celery执行完成以后通知用户,大大提好网站的并发以及用户的体验感。
2.任务场景:比如在运维场景下需要批量在几百台机器执行某些命令或者任务,此时Celery可以轻松搞定。
3.定时任务:向定时导数据报表、定时发送通知类似场景,虽然Linux的计划任务可以帮我实现,但是非常不利于管理,而Celery可以提供管理接口和丰富的API。
二、架构&工作原理
Celery由以下三部分构成:消息中间件(Broker)、任务执行单元Worker、结果存储(Backend),如下图:
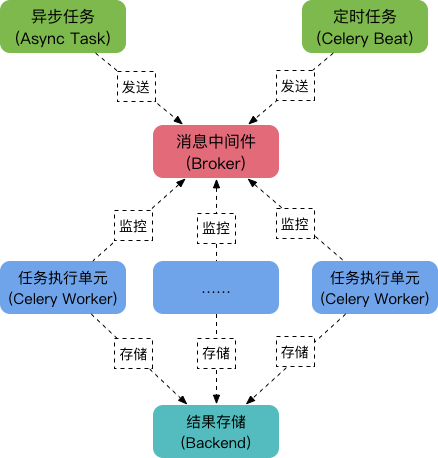
工作原理:
- 任务模块Task包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往消息队列,而定时任务由Celery Beat进程周期性地将任务发往消息队列;
- 任务执行单元Worker实时监视消息队列获取队列中的任务执行;
- Woker执行完任务后将结果保存在Backend中;
消息中间件Broker
消息中间件Broker官方提供了很多备选方案,支持RabbitMQ、Redis、Amazon SQS、MongoDB、Memcached 等,官方推荐RabbitMQ。
任务执行单元Worker
Worker是任务执行单元,负责从消息队列中取出任务执行,它可以启动一个或者多个,也可以启动在不同的机器节点,这就是其实现分布式的核心。
结果存储Backend
Backend结果存储官方也提供了诸多的存储方式支持:RabbitMQ、 Redis、Memcached,SQLAlchemy, Django ORM、Apache Cassandra、Elasticsearch。
三、安装使用
这里我使用的redis作为消息中间件
Celery安装:
pip3 install celery
简单使用
目录结构:
project/ ├── __init__.py ├── config.py └── tasks.py
#!/usr/bin/env python3 # -*- coding:utf-8 -*- # Author:wd from celery import Celery app = Celery('project') # 创建 Celery 实例 app.config_from_object('project.config') # 加载配置模块
config.py: Celery相关配置文件
#!/usr/bin/env python3 # -*- coding:utf-8 -*- # Author:wd BROKER_URL = 'redis://10.1.210.69:6379/0' # Broker配置,使用Redis作为消息中间件 CELERY_RESULT_BACKEND = 'redis://10.1.210.69:6379/0' # BACKEND配置,这里使用redis CELERY_RESULT_SERIALIZER = 'json' # 结果序列化方案 CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24 # 任务过期时间 CELERY_TIMEZONE='Asia/Shanghai' # 时区配置 CELERY_IMPORTS = ( # 指定导入的任务模块,可以指定多个 'project.tasks', )
tasks.py :任务定义文件
#!/usr/bin/env python3 # -*- coding:utf-8 -*- # Author:wd from project import app @app.task def show_name(name): return name
启动Worker:
celery worker -A project -l debug
各个参数含义:
worker: 代表第启动的角色是work当然还有beat等其他角色;
-A :项目路径,这里我的目录是project
-l:启动的日志级别,更多参数使用celery --help查看
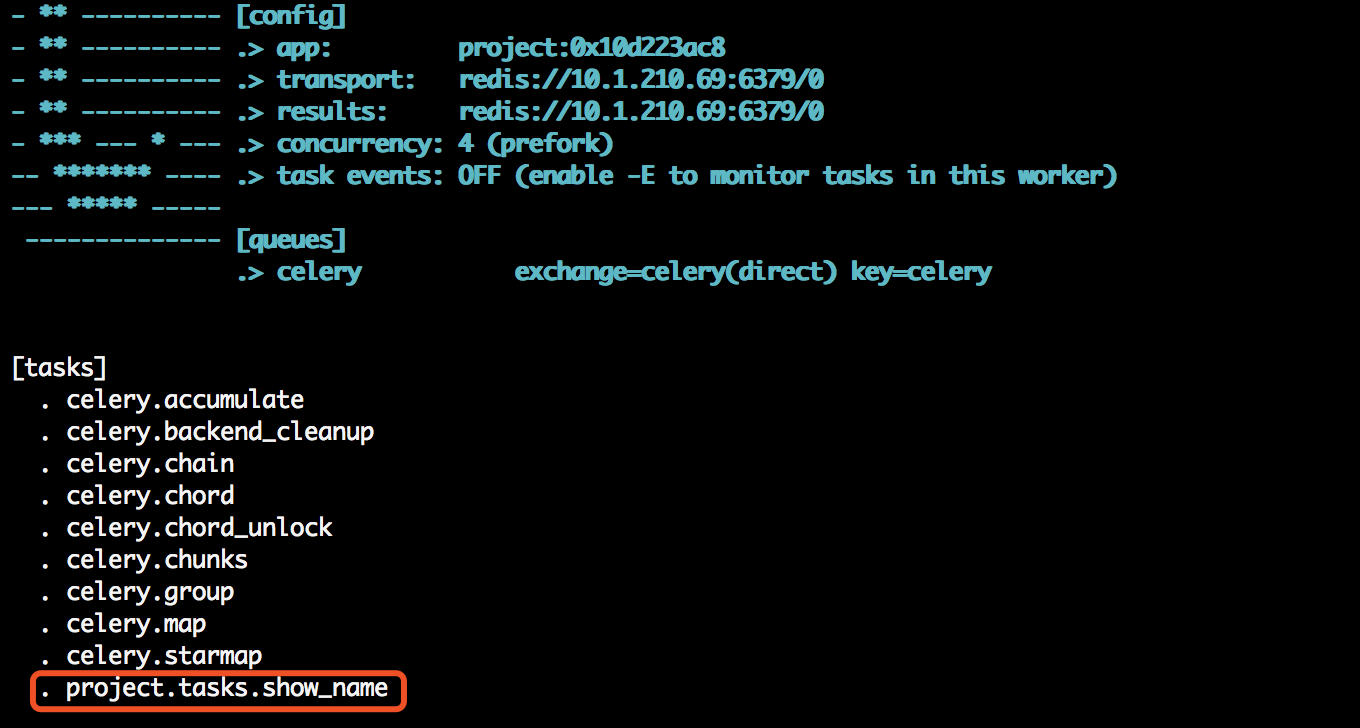
查看日志输出,会发现我们定义的任务,以及相关配置:
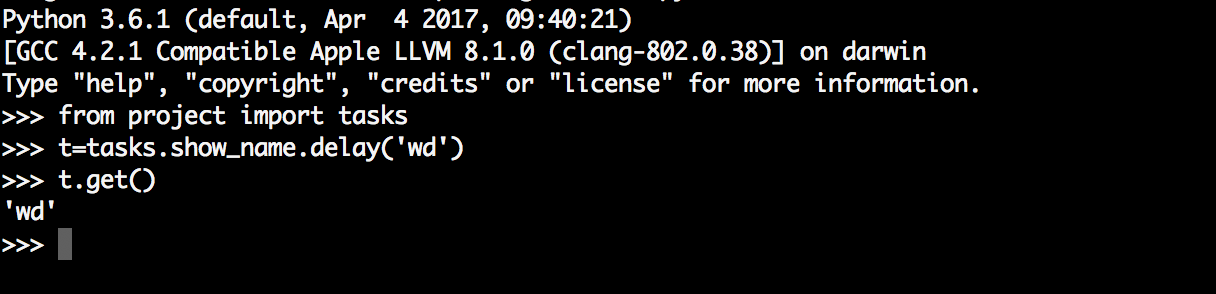
虽然启动了worker,但是我们还需要通过delay或apply_async来将任务添加到worker中,这里我们通过交互式方法添加任务,并返回AsyncResult对象,通过AsyncResult对象获取结果:
AsyncResult除了get方法用于常用获取结果方法外还提以下常用方法或属性:
- state: 返回任务状态;
- task_id: 返回任务id;
- result: 返回任务结果,同get()方法;
- ready(): 判断任务是否以及有结果,有结果为True,否则False;
- info(): 获取任务信息,默认为结果;
- wait(t): 等待t秒后获取结果,若任务执行完毕,则不等待直接获取结果,若任务在执行中,则wait期间一直阻塞,直到超时报错;
- successfu(): 判断任务是否成功,成功为True,否则为False;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号