软件工程实践2017 结队项目——第二次作业
作业链接 
031502333
前言
近期比较倾向于使用Go语言写小工具,所以在看到作业不限制编程语言时就决定使用Go作为开发语言。而由于Go的诸多优秀特性,使得编写代码效率极高,所以在此安利一波!
数据生成
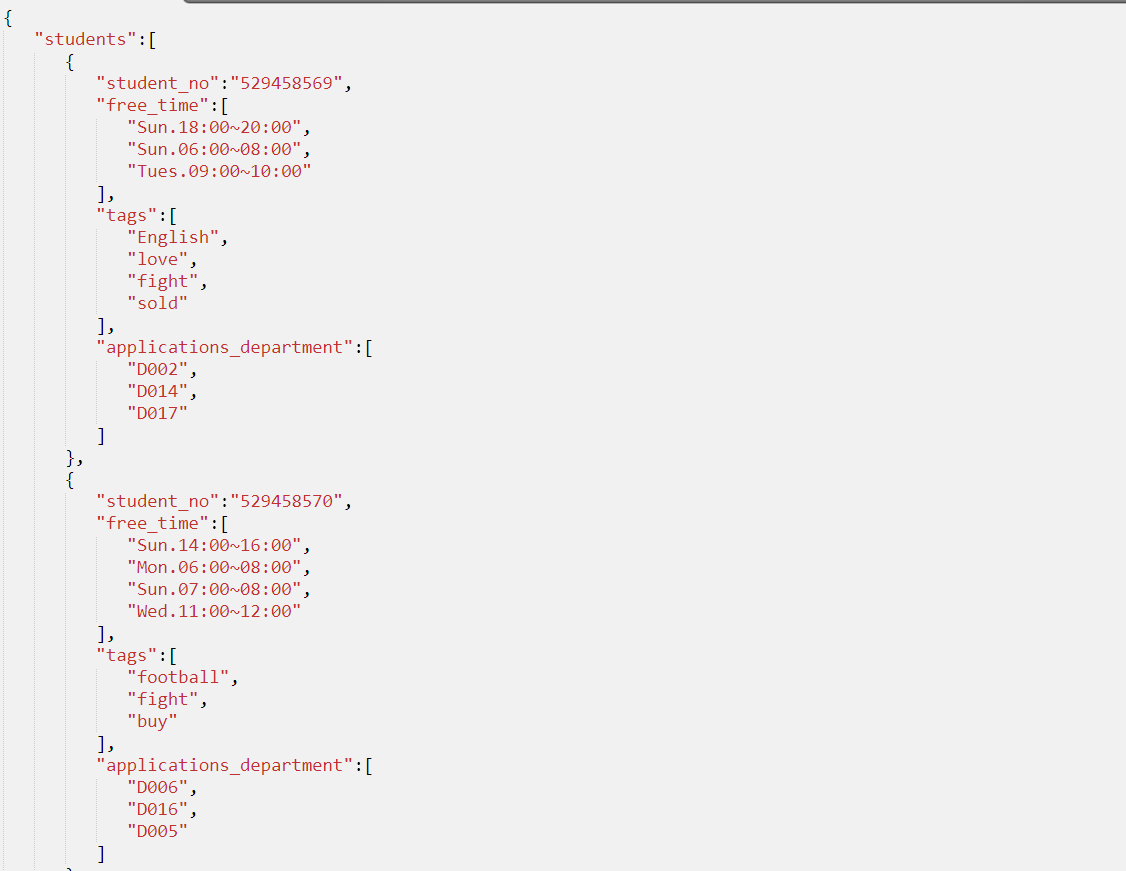
数据生成部分在构思时就偏向于随机化,虽然学生的兴趣、空闲时间可能存在着某种规律,但总会有大量噪点的存在,于是我就大胆地认为随机化的数据并不比定制数据差,并以此为基础构思整个数据生成程序。
初始化:
- 学号基数
随机生成基数作为学号的起始编号 - 标签池
初始化标签,方便之后进行随机化生成 - 时间生成函数
返回在一周7天内的(6.am-9.pm)的时间跨度小于4的随机时段
学生:
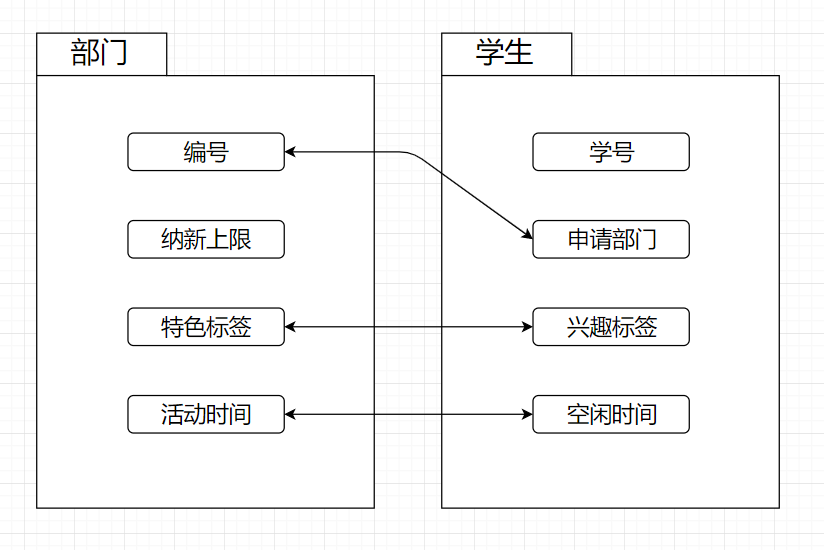
- 学号
根据初始化时生成的学号为基数,进行累加生成新的学号 - 兴趣标签
生成随机数n(n<5),随机抽取n+2个不重复标签,作为其兴趣标签 - 空闲时间
调用时间生成函数,生成任意[2,10)个不重复的空闲时间段 - 申请部门
在已生成的部门中进行随机挑选[1,5]个不重复志愿
部门:
- 编号
按照生成个数顺序生成,如D001,D002,... - 纳新上限
随机取值范围在[1,5]之间 - 特色标签
与学生的兴趣标签生成方法相同 - 活动时间
与学生的空闲时间生成方法相同
总的来说就是一句话——“开局一种子,数据全靠猜 ,一刀999级...”
数据建模
匹配程序
首先,在现实生活中,学生填报社团时都是因为感兴趣而自愿申请的,几乎不存在乱报的情况。因此,在匹配时应当尽可能的为申请人匹配到其想参加的社团,而至于他没有填报的一定是存在某种原因。所以本着宁缺毋滥的原则,我们应该在公平竞争的基础上尽可能迎合学生意愿。因此我们将学生的申请志愿投递到对应部门名下,而部门将对其进行筛选,择优录取。
站在部门的视角,自然是希望所接纳的部员都是所有申请人中最好的一批,同时部门组织的活动自然是参加得越频繁越好。因此,部门在进行筛选时所采用的标准是,一定权值的空闲时间段匹配度+一定权值的兴趣标签匹配度,选择所有申请人中权重最高的前n个接纳为新部员。
于是问题就变成了高考志愿填报的问题,区别在于学生一方可以选择多个部门,也就是Gale-Shapley的延迟接受算法(Deferred acceptance algorithm)的修改版。
算法流程:
注:每个学生都有一个申请队列
循环遍历每个学生直到所有人的队列都清空为止
1.取出在队首的申请,将申请投递至对应部门,若无申请则跳过
2.申请的对应部门执行淘汰算法,来决定是否接纳该生
部门的淘汰算法如下
1.若人数不超过限制,则接纳
2.超过则计算新生的权值,与当前最小权值比较
3.若大于当前最小权值,则置换新生与该最小权值学生,否则不做操作
其中权值计算函数如下
1.将两个时间段进行交叉匹配,得出公共的时间段个数h
2.将两个标签组进行交叉匹配,得出公共的标签个数g
3.返回 2h+1g //这个比例因子是经过多次实验得来
代码规范
blog-gofmt
使用Go编程还有一大特点就是,官方已经帮我们制定好了代码规范,使用gofmt工具就可以规范化代码,十分有利于快速开发,同时开发者只需要闷头专注于功能实现即可。
type student struct {
UniqueID string `json:"student_no"`
FreeTime []string `json:"free_time"`
Tags []string `json:"tags"`
Applicants []string `json:"applications_department"`
// unexported fields
firstAppID int
}
结果评估
中选学生的满意度 = 中选部门/申请数量 = 45.39%
社团纳新程度 = 中选人数/部门纳新限制 = 100%
中选率 = 中选人数/总人数 = 17%
上述结果说明,所有部门的需求都得到了最大最优匹配,而对于学生来说,若中选,他所选的部门一定是提交的申请中的一个,而未中选则是因为在投递的部门中有人比他更符合部门的要求。
其实对于这个结果来说,个人还是不大满意的,因为中选率有点太低了,究其原因或许是因为随机生成算法还是不大符合题意吧。
结对感受&闪光点
写到这里有一点遗憾,并没能体验到软工结对编程的感觉,好在最近自己在课余的时间里有幸地体验到了(或者说是体验中)。结对编程最大的感触就是,需要和对友交流协商,因为很可能两个人的开发风格不一样,甚至开发的语言都不一样,这时候好的协商起到很大作用,两个人一起聊出一个最能接受的方案,然后顺着方案开发进入下一个阶段,negotiate,code,repeat....
闪光点或许就是别人都有对友,而我是solo buff加成吧/捂脸哭。
