STL——配接器、常用算法使用
学习STL,必然会用到它里面的适配器和一些常用的算法。它们都是STL中的重要组成部分。

适配器
在STL里可以用一些容器适配得到适配器。例如其中的stack和queue就是由双端队列deque容器适配而来。其实适配器也是一种设计模式,该种模式是将一个类的接口转换成用户希望的另外一个接口。简单的说:就是需要的东西就在眼前,但却不能用或者使用不是很方便,而短时间又无法改造它,那我们就通过已存在的东西去适配它。
STL中的适配器一共有三种:
①应用于容器的即容器适配器;比如stack和queue就是对deque的接口进行了转调
②应用于迭代器的即迭代器适配器;比如反向迭代器就是对迭代器的接口进行了转调
③应用于仿函数的即函数适配器
不过我们平常用容器适配器用得比较多,所以我们着重容器适配器的使用,其它适配器可参考《STL源码剖析》。
(1)stack/queue
我们都知道stack和queue都是一种特殊的线性数据结构,要求在其固定端进行数据的插入和删除操
作。而在STL的容器当中,deque是双开口的结构,因此STL就将它作为栈和队列的底层结构,然后对deque稍加改装后就实现出来了stack和queue。
像这种:将某个类的接口进行重新包装而实现出的新结构,称之为适配器
如stack原型定义:

常用接口:
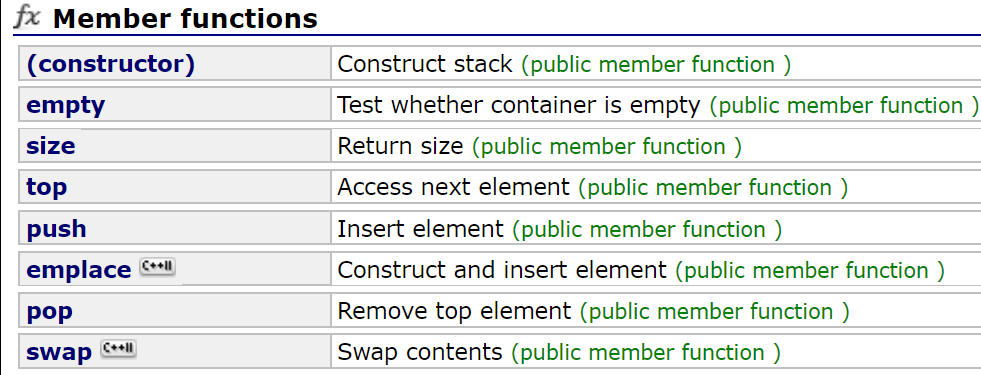
queue原型定义类似:

注意:由于栈和队列不能遍历,所以stack queue没有提供迭代器。
(2)priority_queue
priority_queue(优先级队列)是一个拥有权值关键的队列,允许用户以任意次序将元素插入容器内,但取出时每次都是取优先级最高(低)的元素,这正是heap所具有该特性,因此priority_queue以vector作为底层存储元素空间,将heap算法进行包装,实现出了优先级队列 。
定义原型:

注:它的头文件包含在#include <queue>中
关于它的使用:
1.因为仅需取队首和队尾元素的操作,因此 priority_queue 优先队列容器也不提供迭代器,对其他任意位置处的元素进行直接访问操作。
2.调用top成员函数取队头元素时,由于队列内部封装的堆算法,取得的元素是权值最大的元素。
3.调用pop删除顶部的元素时, 删除的元素是具有最高权值的元素。并且通常pop前会调用成员top进行检索。
pop成员函数有效地调用pop_heap算法来保留priority_queues的heap属性,然后调用基础容器对象的成员函数pop_back来删除该元素。
4.它同样支持定制比较的仿函数进行自定义顺序比较。
结合这些操作,我们可以来实现一个小功能。
案例:根据出现次数,统计前k项编程语言
/************************************************************************
> File Name: 1.cc
> Author: tp
> Mail:
> Created Time: Sun 20 May 2018 10:51:06 PM CST
************************************************************************/
#include <iostream>
#include <vector>
#include <queue>
#include <unordered_map>
using namespace std;
typedef unordered_map<string, int>::iterator UmapIte;
struct CountCompare
{
bool operator( )(UmapIte lhs, UmapIte rhs )
{
return lhs->second > rhs->second;
}
};
vector<string> GetTopKLanguage( const vector<string>& v, int k)
{
unordered_map<string, int> umap;
//将每种语言次数对应统计起来
for( int i=0; i< v.size( ) ; ++i)
{
umap[ v[ i] ] ++;
}
UmapIte it1 = umap.begin( ) ;
while( it1 != umap.end( ) )
{
cout<<it1->first<<" :" <<it1->second<<endl;
++it1;
}
//用priority_queue对pair<string, int>按权值排序
priority_queue<string, vector<UmapIte>, CountCompare> pq;
UmapIte it = umap.begin( ) ;
int m = k;
while( it != umap.end( ) )
{
if( m > 0 && m--)
pq.push( it) ;
else
{
//取到当前队列中权值最大(值最小)的元素来pop,
//相当于逐渐把出现次数较少的语言弹出,将出现次数较多的留下。
UmapIte top = pq.top( ) ;
if( it->second > top->second)
{
pq.pop( ) ;
pq.push( it) ;
}
}
++it;
}
cout<<endl;
while( !pq.empty( ) )
{
cout<<pq.top( ) ->first<<" :" <<pq.top( ) ->second<<endl;
pq.pop( ) ;
}
// vector<string> ret;
// for( int i=0; i<k; ++i)
// {
// ret.push_back( pq.top( ) ->first) ;
// pq.pop( ) ;
// }
// return ret;
}
int main( )
{
vector<string> v;
v.push_back( " PHP" ) ;
v.push_back( " Python" ) ;
v.push_back( " Python" ) ;
v.push_back( " Java" ) ;
v.push_back( " PHP" ) ;
v.push_back( " C/C++" ) ;
v.push_back( " C/C++" ) ;
v.push_back( " C/C++" ) ;
v.push_back( " PHP" ) ;
v.push_back( " Java" ) ;
v.push_back( " PHP" ) ;
v.push_back( " Go" ) ;
v.push_back( " PHP" ) ;
v.push_back( " Java" ) ;
v.push_back( " PHP" ) ;
v.push_back( " PHP" ) ;
v.push_back( " PHP" ) ;
GetTopKLanguage( v, 3) ;
return 0;
}
这里要统计出现次数前3的语言(其中由于优先级队列遍历的特殊性,世上最好的语言最后出现):

常用算法
STL中的算法是将常用的算法规范出来,它作用的元素范围是可以通过迭代器或指针访问的任何对象序列;但算法只关心操作的步骤,与数据的结构没有任何的关系(即它不会影响容器的结构 如大小或存储分配),而且STL在设计时就有一个目标,就是算法可复用,效率要尽可能的高。STL中收录了极具复用价值的70多个算法,包括:排序,查找,排列组合,数据移动,拷贝,删除,比较组合,运算等。
关于它的用法:
首先要包含头文件<algorithm>,里面定义了各种的算法的函数集合。
常见算法:
查找类算法 find/find_if/find_first_of/binary_search/count/count_if 排序和通用算法 sort/stable_sort/partial_sort/partial_sum/partition/merge/reverse 删除和替换算法 copy/copy_backward/remove/remove_if/swap/unique 排列组合算法 prev_permutation/next_permutation 集合操作 set_difference/set_union/set_intersection
简单应用
1.查找
//binary_search
void test_binary_search( )
{
int a[ ] = {11,2,4,5,9,0,3,6};
vector<int> v(a, a+ 8);
sort(v.begin( ), v.end( ));
cout<<binary_search(v.begin( ), v.end( ), 6);
//结果 1
}
2.排序
//partiton
bool IsBigerK(int curValue)
{
return curValue < 3;
}
void test_partition( )
{
vector<int> a;
a.push_back(6);
a.push_back(5);
a.push_back(4);
a.push_back(3);
a.push_back(2);
a.push_back(1);
//以3为边界划分
partition(a.begin( ), a.end( ), IsBigerK);
for( int i=0; i< a.size(); ++i)
cout<<a[ i]<<" ";
cout<<endl;
//结果:1 2 4 3 5 6
}
//sort
//template<class T> //形如这样自定义来比较
//struct Greater
//{
// bool operator()(const T& l, const T& r)
// {
// return l > r;
// }
//};
void test_sort( )
{
vector<int> v;
v.push_back(1);
v.push_back(3);
v.push_back(4);
v.push_back(0);
v.push_back(10);
v.push_back(3);
sort(v.begin( ), v.end(), greater<int>());
for( int i=0; i< v.size( ); ++i)
cout<<v[i]<<" ";
cout<<endl;
//结果:
//10 4 3 3 1 0
}
3.排列组合问题
//排列问题
//next_permutation 求得下一个排列
void test_permutation( )
{
string str("abc");
do
{
cout<<str.c_str( )<<endl;
}while(next_permutation(str.begin( ), str.end( )));
//结果:
//abc
//acb
//bac
//bca
//cab
//cba
//注意:对于值重复,不造成影响. aab求得的全排列不会用重复
}
4.集合操作
set_difference
关于使用:
1. 在两个集合中找出不同的元素,这些不同的元素全部来自与第一组中,不从第二组中来。
2.它的返回值为一个迭代器it,迭代器指向存储的结果(即找出来的不同元素)最后一个位置。通常 用it-ret.begin()得到不同元素的个数。
void test_set_difference( ) { int a[ ] = {1, 4, -1, 5, 2}; int b[ ] = {3, 4, 1, 5, 6}; //+5 注意! sort(a, a+5); //-1 1 2 4 5 sort(b, b+5); //1 3 4 5 6 vector<int> v(10); vector<int>::iterator it; it =set_difference(a, a+5, b, b+5, v.begin()) ;//it是-1 2 0 0 0 0 0 0 0 0 的结尾 v.resize(it-v.begin()); //-1 2 it = v.begin( ); while( it != v.end( )) { cout<<*it<<" "; ++it; } //结果:-1 2 }
算法当中的相关分类总览:


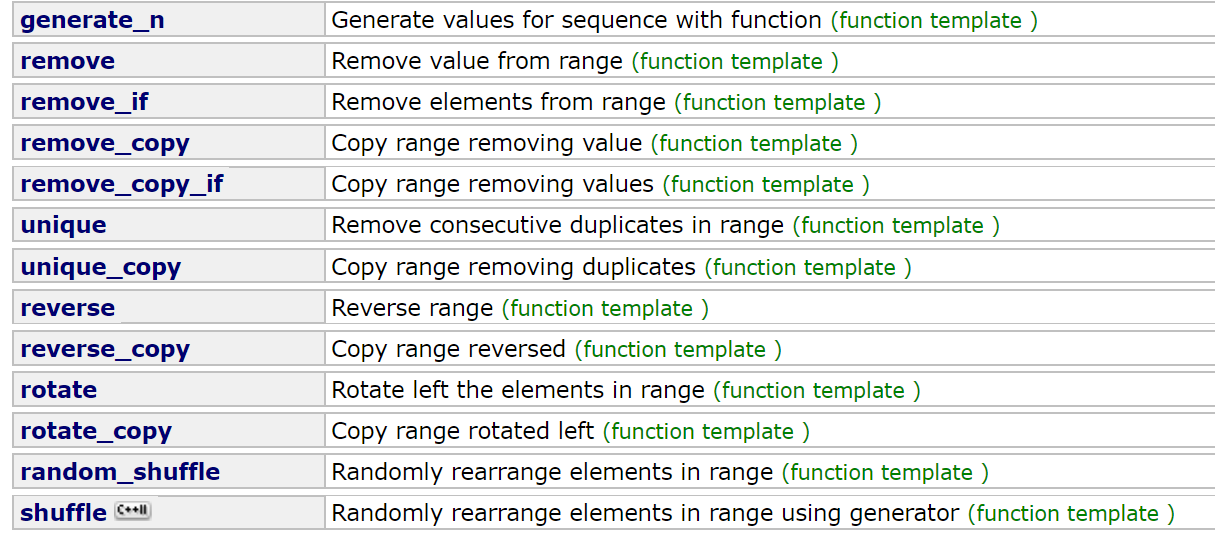



参考:http://www.cplusplus.com/reference/algorithm/
本文来自博客园,作者:tp_16b,转载请注明原文链接:https://www.cnblogs.com/tp-16b/p/9186826.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号