海量数据处理问题
海量数据的处理在互联网行业一直是很受关注的一类问题。面对如此庞大的数据量,要在它们当中进行查找、找最值、统计等操作,不难想象,这是一件比较困难的事情。而实际处理当中,通常是会利用 布隆过滤器和 哈希两种数据结构来解决这类问题。
布隆过滤器(Bloom Filter)
Bloom Filter(BF)是一种空间效率很高的随机数据结构,它底层利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。它是一个能快速判断元素是否存在集合的一种概率算法。之所以说是概率的是因为Bloom Filter有可能会出现错误判断 (即如果判断元素存在集合中,有一定的概率判断错误);但它不会漏判,如Bloom Filter判断元素不在集合,那肯定不在。因此,Bloom Filter不适合那些“零错误”的应用场合。
构成:一个位图和多个哈希函数
原理:
(1)基于位图:位图底层是一个位数组,每一位就有0和1 两种状态,那么通过这两种状态便可以标识一个数据是否存在;同时根据不同的需求我们还可以用多个比特位来标识数据的状态(如后面的应用)。
(2)设置多个独立hash函数
我们知道当进行哈希映射时,是会产生哈希冲突的。譬如处理字符串“sort”和“srot”时很有可能得到相同的哈希值,而实际应用当中,这便造成大量的冲突。为了减少冲突,Bloom Filter使用m个相互独立的哈希函数(Hash Function), 通过 m个哈希函数将其转成不同的整型 进而得到m个哈希值,然后在位数组中所有对应的比特位都设置为1。当一个元素的这m个位置都为1时,便可以大致确定它存在于集合了,这便大大减少了冲突。 注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,3个哈希函数,且有两个哈希函数选中同一个位置(下标4)
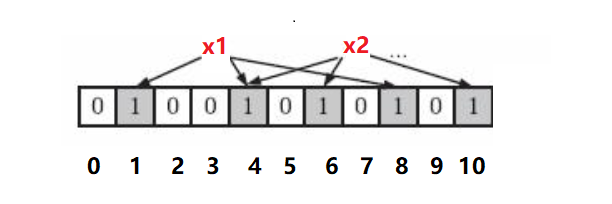
总结下来就分这么几个步骤:
- 一数据元素使用m个哈希函数得到m个哈希值
- 判断是否所有哈希值对应的位置都被置为1(1≤i≤m)
- 如果所有位置都已置成了‘1’,该元素可大致确定为集合中的元素;只要有一个位置上是‘0’,那该元素一定不是集合中的元素。
注意:.布隆过滤器除了存在误判以外 还不能删除元素。删除一个元素就要把m个位置置为‘0’,这样就会影响其他元素。(不过可以改进)


#pragma once #include "BitMap.h" typedef const char* KeyType; typedef size_t (*HASH_FUNC)(KeyType); //计算哈希值的函数指针 typedef struct BloomFilter { BitMap _bm; //size_t* _bm; //Reset时将一个query用一个32位一个数据项保存信息,如此可以表示更大的引用计数 HASH_FUNC _hashfunc1; //计算字符串的哈希值函数 HASH_FUNC _hashfunc2; HASH_FUNC _hashfunc3; }BloomFilter; void BloomFilterInit(BloomFilter* bf, size_t range); void BloomFilterSet(BloomFilter* bf, KeyType key); //void BloomFilterReset(BloomFilter* bf, KeyType key); //优化后可实现 int BloomFilterTest(BloomFilter* bf, KeyType key); size_t BKDRHash(KeyType str) { register size_t hash = 0; while(size_t ch = (size_t)*str++) { hash = hash * 131 + ch;// 也可以乘以31、131、1313、13131、131313.. } return hash; } size_t SDBMHash(KeyType str) { register size_t hash =0; while(size_t ch = (size_t)*str++) { hash = 65599 * hash + ch;//hash =(size_t)ch + (hash <<6) + (hash << 16) - hash; } return hash; } size_t RSHash(KeyType str) { register size_t hash = 0; size_t magic = 63689; while(size_t ch = (size_t)*str++) { hash = hash * magic + ch; magic*= 378551; } return hash; } void BloomFilterInit(BloomFilter* bf, size_t range) { assert(bf); BitMapInit(&bf->_bm, range); bf->_hashfunc1 = BKDRHash; bf->_hashfunc2 = SDBMHash; bf->_hashfunc3 = RSHash; } void BloomFilterSet(BloomFilter* bf, KeyType key) { assert(bf); //假如sort 123 size_t hash1 = bf->_hashfunc1(key); //得到字符串的size_t类型的一个哈希值 size_t hash2 = bf->_hashfunc2(key); size_t hash3 = bf->_hashfunc2(key); BitMapSet(&bf->_bm, hash1%bf->_bm._range); //算得的hash 可能比 range大,产生越界访问;故取模运算 BitMapSet(&bf->_bm, hash2%bf->_bm._range); BitMapSet(&bf->_bm, hash3%bf->_bm._range); } int BloomFilterTest(BloomFilter* bf, KeyType key) //验证实现 { assert(bf); size_t hash1 = bf->_hashfunc1(key); //得到字符串的size_t类型的一个哈希值 if(BitMapTest(&bf->_bm, hash1%bf->_bm._range) == -1) return -1; size_t hash2 = bf->_hashfunc2(key); if(BitMapTest(&bf->_bm, hash2%bf->_bm._range) == -1) return -1; size_t hash3 = bf->_hashfunc2(key); if(BitMapTest(&bf->_bm, hash3%bf->_bm._range)) return -1; return 0; }
注:里面的字符串转整型算法详细介绍参考http://www.cnblogs.com/-clq/archive/2012/05/31/2528153.html
Bloom Filter改进
布隆底层是一个位图(其实就是一个位数组在保持数据),删除一个元素就要把m个位置都置为‘0’,这样就会影响其他元素。那就不妨用多个bit位来存储元素的一个哈希映射位(相当于增添计数)。比如用8个比特位(即1字节)来存储

8位进行映射
这里为了计算方便,不妨直接用32个bit来存储一个哈希映射位(可以表示所有整型)。只是这样的改进一定程度上加大了对内存的消耗。
大致知道了布隆过滤器,就可以来看看它是如何来应用的了。
应用
题目:给两个文件,分别有100亿个query(查询),我们只有1G内存,如何找到两个文件交集?分别给出近似算法和精确算法
近似算法:上布隆过滤器
1. 将第一个文件中每个query通过字符串算法转换成整型。
2. 通过多个哈希函数把每个query映射到布隆过滤器中。
3. 把第二个文件中的query也利用字符串转换算法转换位整型,然后一个一个在布隆过滤器中查找,看是否存在。
布隆过滤器以其良好的空间和时间效率能够较快的找这两个文件的交集。但因为布隆过滤器判断一个元素是否存在是不准确的,所以这只是一个近似算法。
精确算法:哈希切分 如下图,
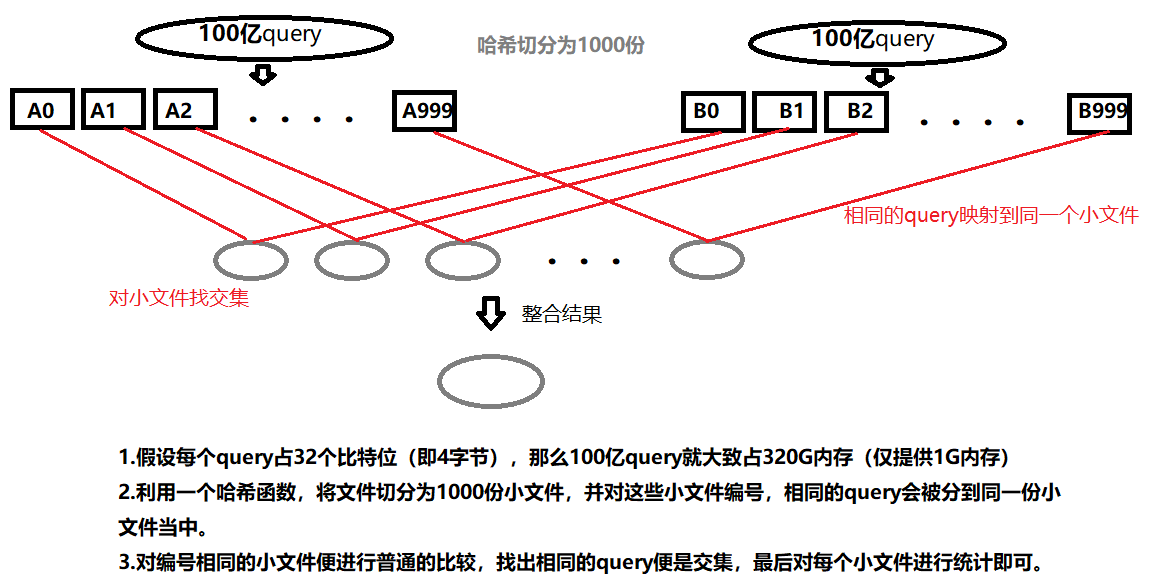
由于布隆过滤器存在误判的现象,所以它的应用通常是用来进行大致的判断。而针对那种要求零误差的情形,它便不适用了,想要精确的判断,通常会先利用哈希进行切分,切分为许多的小文件,然后对小文件进行操作。以此来解决内存不够的问题。
对于哈希切分,还有很多与上面类似的问题,如在一个很大的日志文件中找出出现次数最多的IP, 找出出现次数前K位的IP等,解决它们的思路都大同小异,借助空间效率很高的位图 配合着哈希切分来解决就ok了。
本文来自博客园,作者:tp_16b,转载请注明原文链接:https://www.cnblogs.com/tp-16b/p/8605937.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号