MoblieNetV1V2V3
V1
可分离卷积(深度卷积depthwise+逐点卷积pointwise)
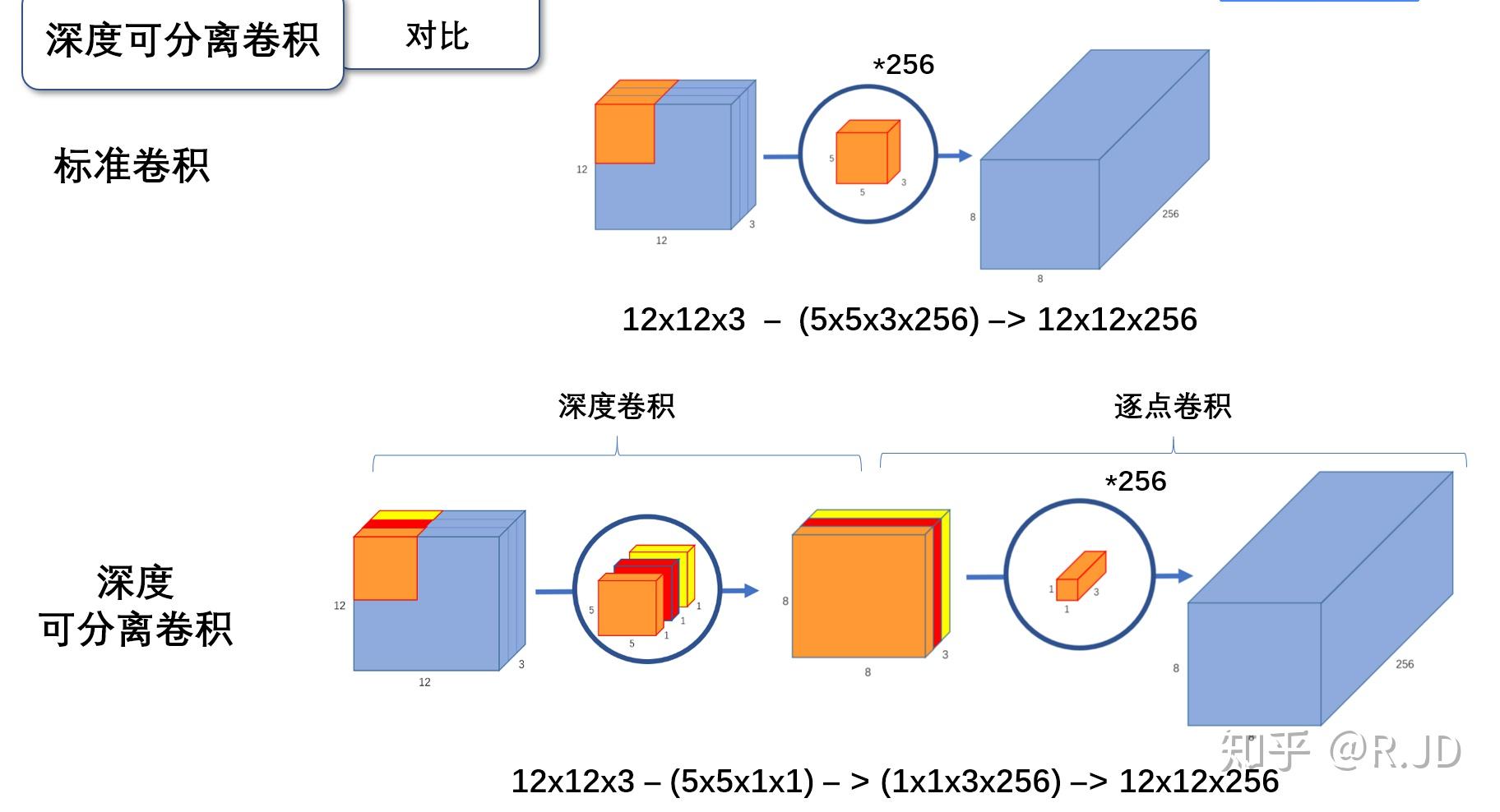
最主要就是为了减少参数量,而且准确率差得不多
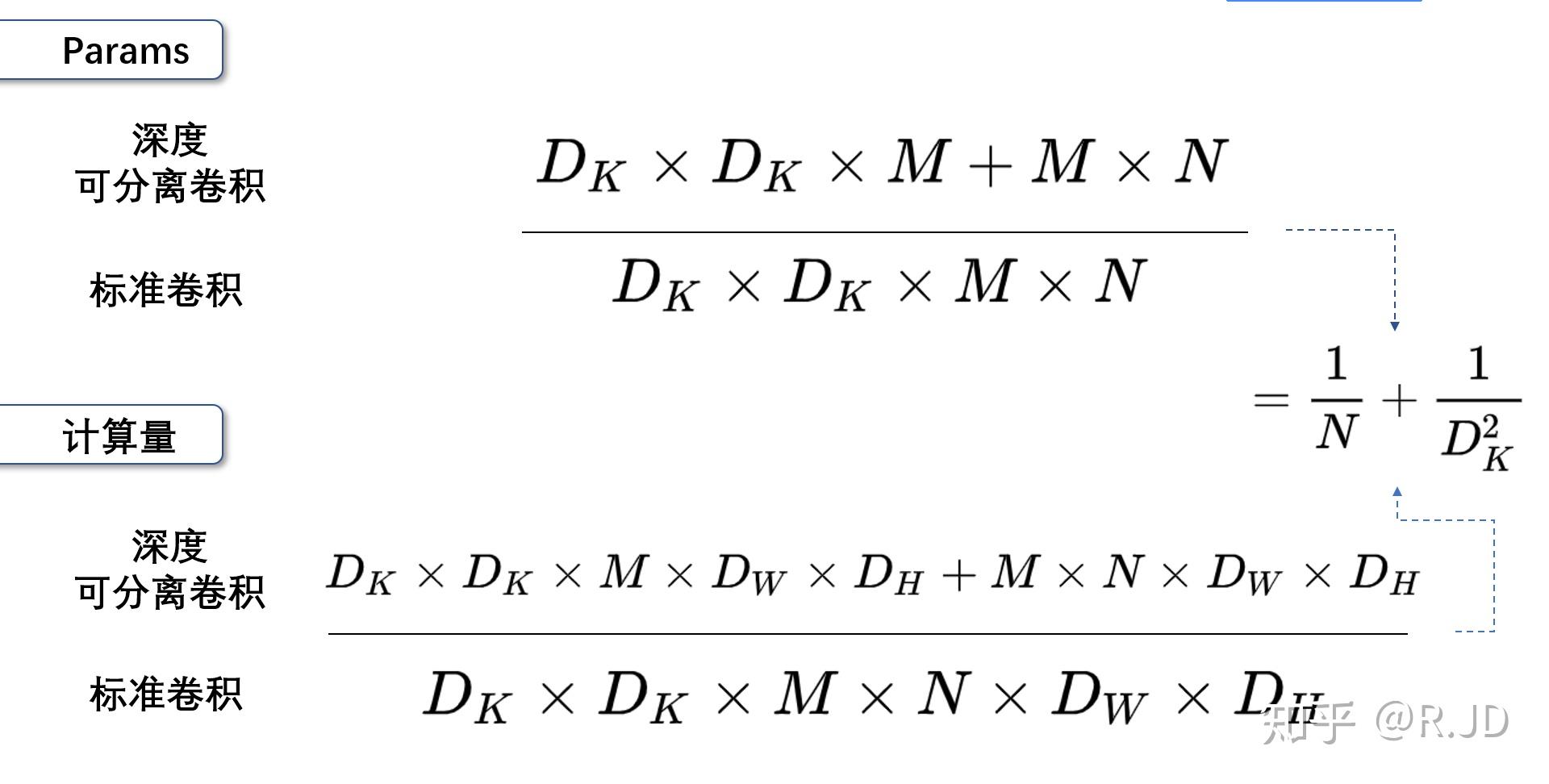
对比标准卷积,参数量和计算量都少了很多
v1的一个block
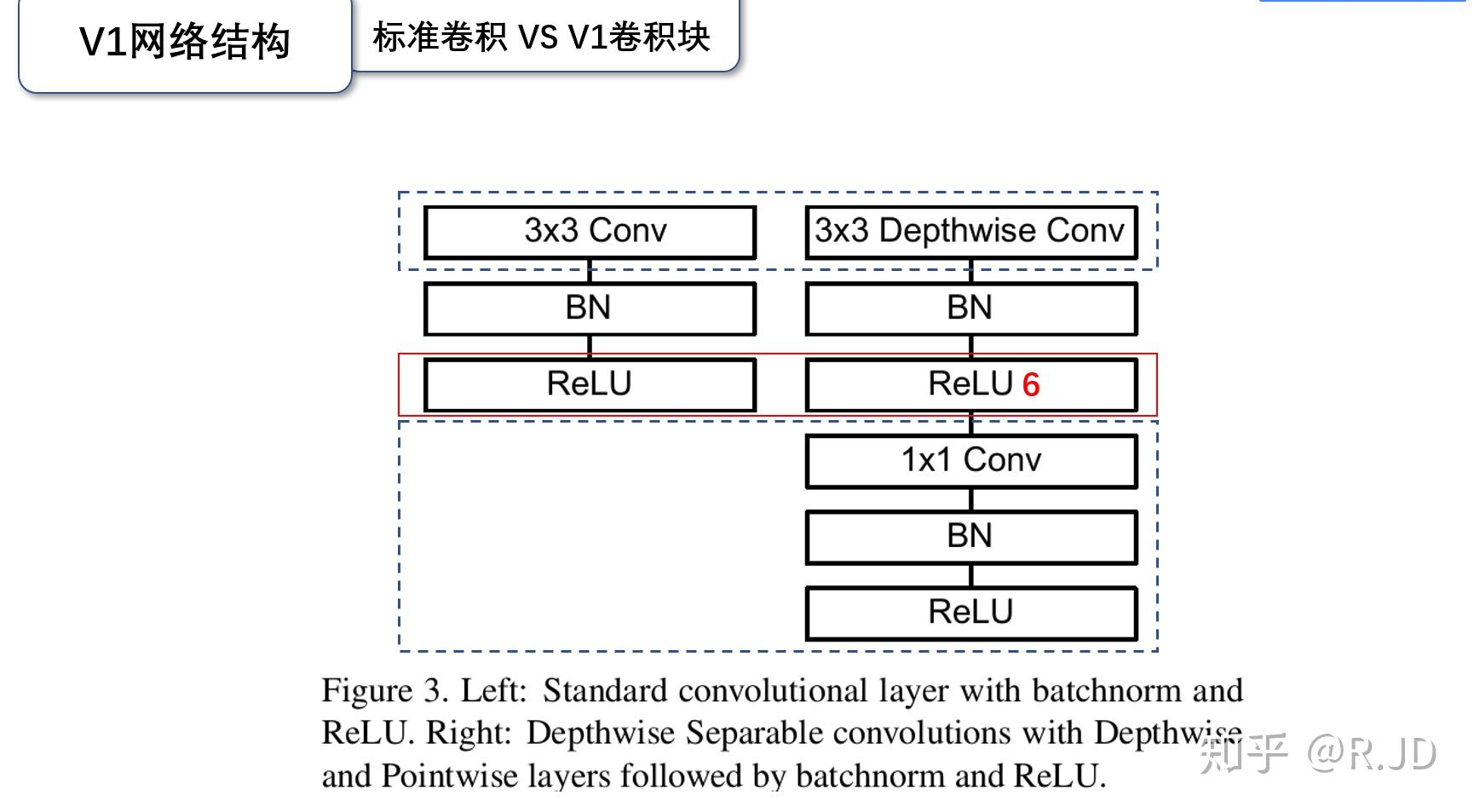
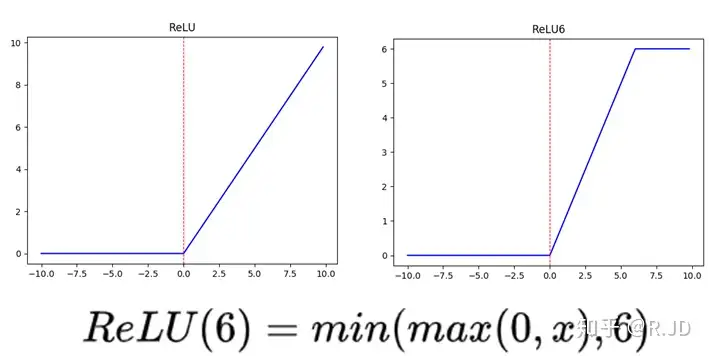
Relu6,感觉还是为了防止梯度爆炸吧
V2
Inverted residuals
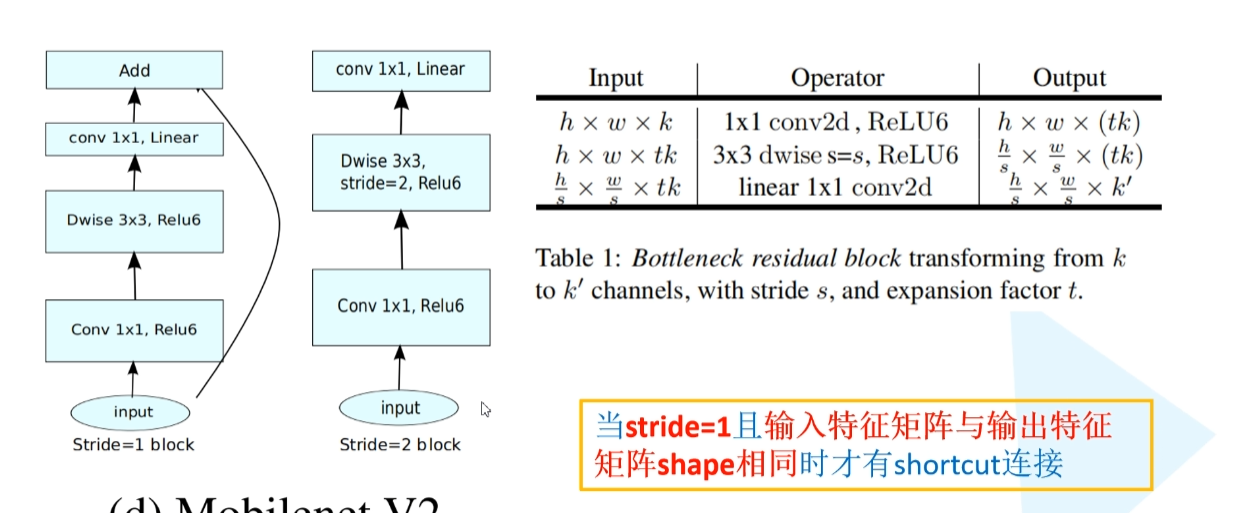
对stride为1的block加入残差结构,先升维(维度太低,卷积效果不好。这里可以与v1对比),卷积,再降维
跟v1比多了先升维,逆残差,bottleneck( 把最后的那个ReLU6换成Linear ,作者把这个部分称为linear bottleleneck)
V3
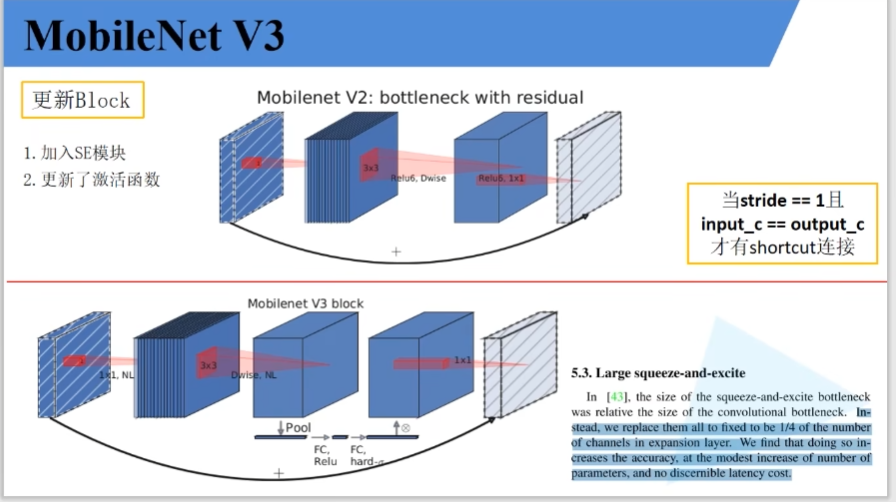
--更新Block(benck)
--使用h-swish和h-sigmoid
--使用NAS搜索参数(不熟)
--引入se通道注意力结构
--重新设计耗时层
v3的block
h-swish激活函数
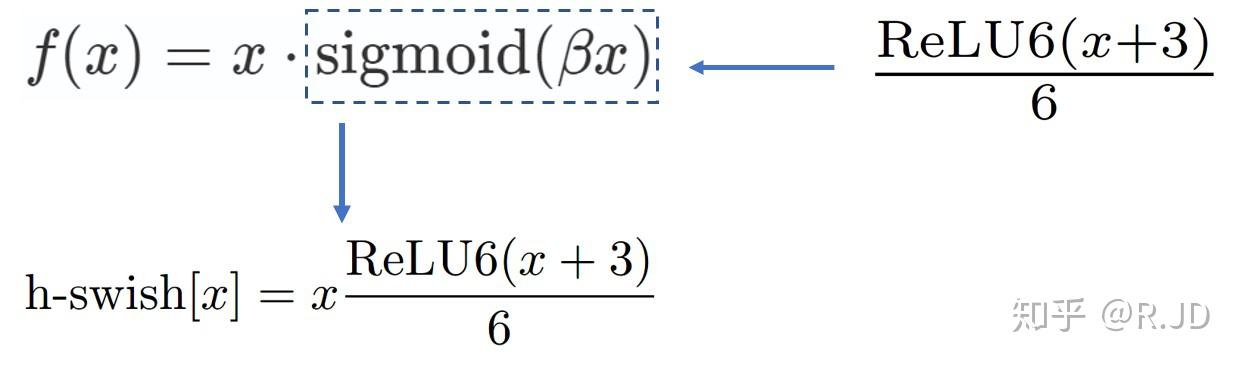
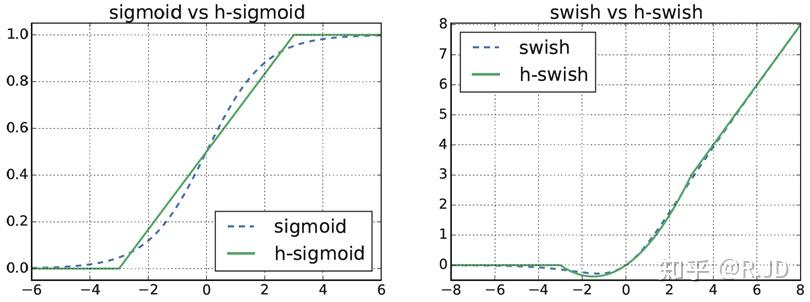
将swish替换成h-swish,sigmoid替换成h-sigmoid
跟swish对比,hswish/hsigmoid函数更“hard”一点,相当于是swish的低精度化,但减少了计算量。
se通道注意力
注意力机制 SE通道注意力 - 知乎 (zhihu.com)
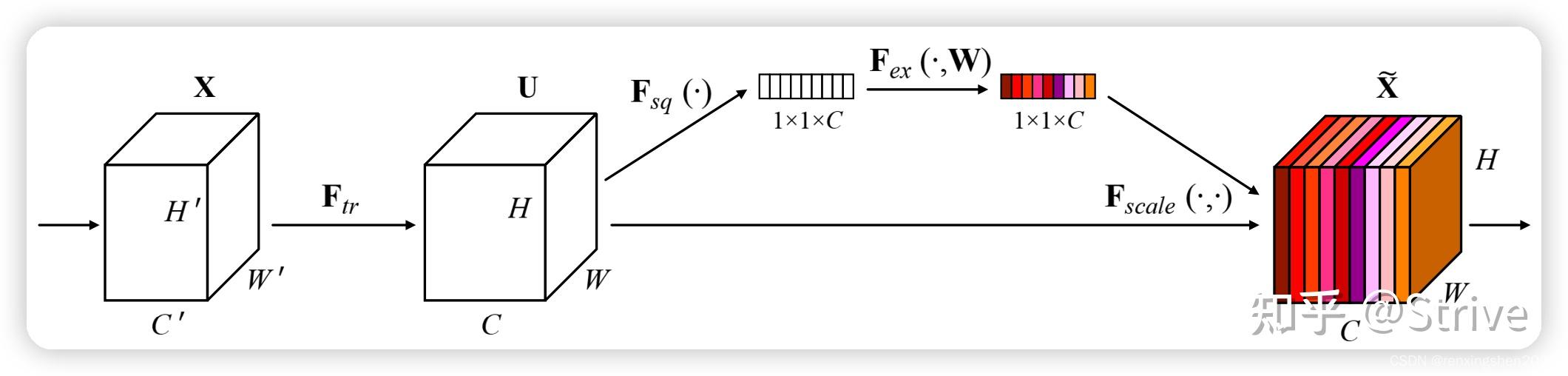
结构图
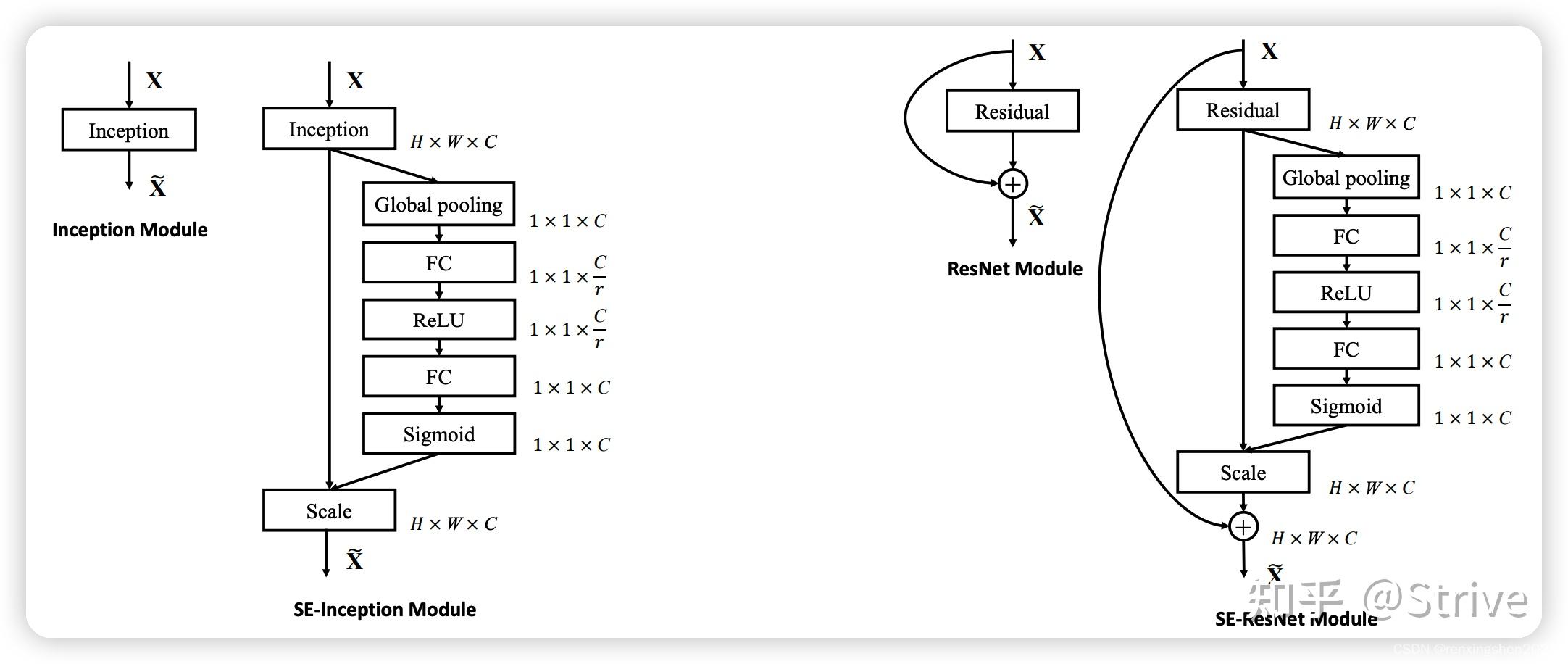
se是一个即插即用的模块,对于需要从channel角度赋予图像不同权重需求的时候就可以用。
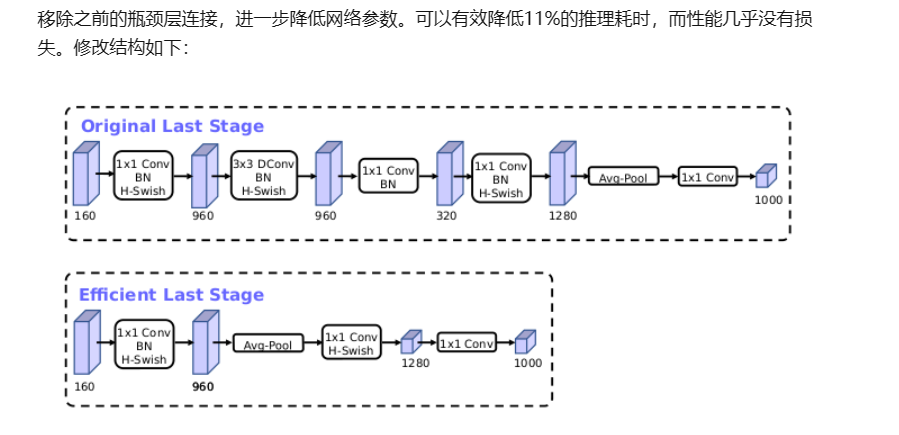
重新设计了耗时层

 浙公网安备 33010602011771号
浙公网安备 33010602011771号