机器学习 学习笔记(2) -- 单变量线性回归
课程老师:吴恩达
课程视频:网易云课堂-吴恩达机器学习 (最原始版本在Coursera)
二、单变量线性回归
1. 模型描述
1.1. 训练集
在课程中,学习的第一个机器学习算法是线性回归(linear regression)。
课程开始还是以一个例子开头,介绍了什么是监督学习:给定一堆房子大小和售价的数据,让机器预测其它房子大小的售出价格。
课程还提到了有监督学习中会有训练集。还有一些与其相关的名词。
- training set:指用来训练机器的带有答案的数据集。如上述例子的房价数据。
- m:训练样本的数目
- x's :输入变量/输入特征
- y's :输出变量/目标变量
- (x,y):一个训练样本
- (x^(i), y^(i)):表示第i个训练样本

1.2. 监督学习的流程
-
我们向学习算法提供训练集(喂数据),例如房价数据。
-
学习算法的任务是输出一个假设函数。函数的作用是将房子的大小作为输入变量,尝试输出相应房子的预测y值。
假设函数:这个函数通常用h来表示。一般称为hypothesis。有时等式左侧简写为h(x)。以下是线性回归的假设函数。
\[h_θ(x)=θ_0~+θ_1~x \]
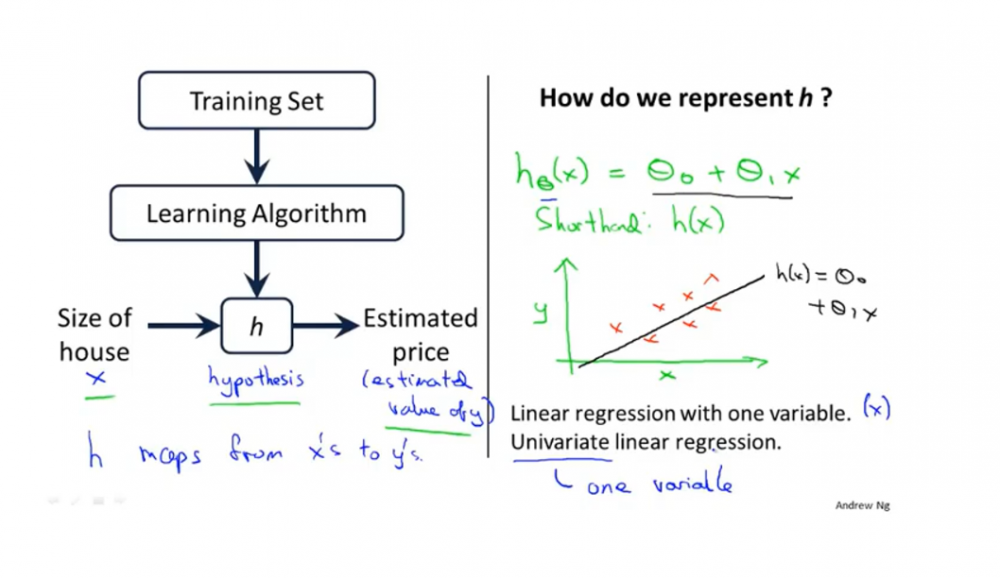
1.3. 线性回归模型
当我们的假设函数是线性函数时,如上图所示,上述模型可以叫做线性回归(linear regression),或者叫做一元回归函数,或者叫做单变量线性回归(univariate linear regression)。
2. 代价函数
2.1. 什么是代价函数
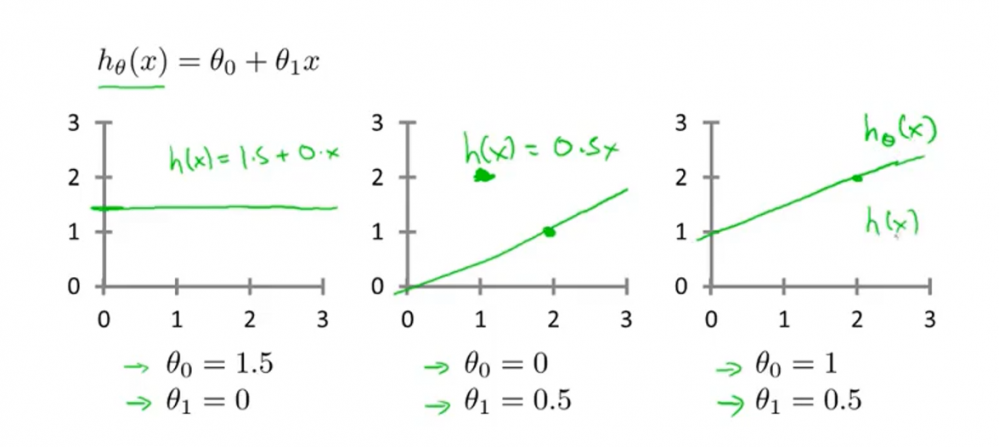
前面说了机器实际上说通过假设函数来预测其它数据的,故对于上述的线性回归模型,当选择不同的$ θ_0 $ 和$ θ_1 $时,模型效果肯定是不一样的。如下图所示,三种不同参数的线性效果不一样。
$ θ_0 $ $ θ_1 $ 也被叫做参数。
故现在的问题是如何去决定这两个参数,使得将训练集\(x^i\)输入该函数后,函数输出的y值能与训练集\(y^i\) 的值尽量接近。这里用到了均方误差的作为判断标准,该值越小,说明该参数能让假设函数越接近正确结果。公式如下:
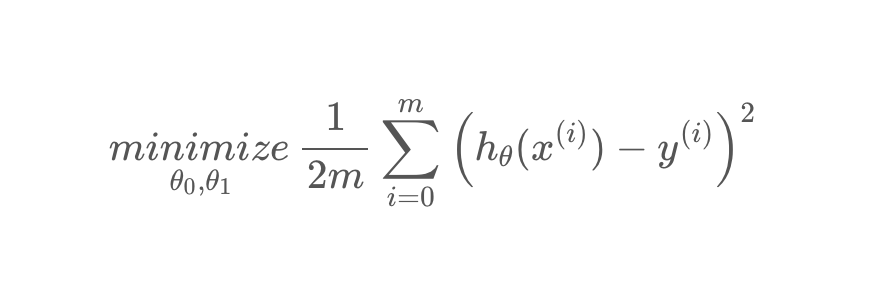
m:训练集数
1/2:为了后面方便计算。
更准确的写法如下,其实这就是代价函数:
视频中老师并没有提及代价函数的具体定义,但我认为代价函数可以理解为一个求出代入某参数的假设函数的误差性的函数。也就是其作用是算出在该参数的作用下,假设函数预测的准确程度。
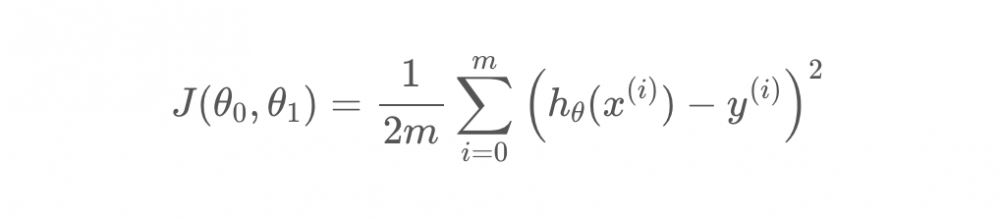
而我们的目标就是找到某参数,使代价函数最小:
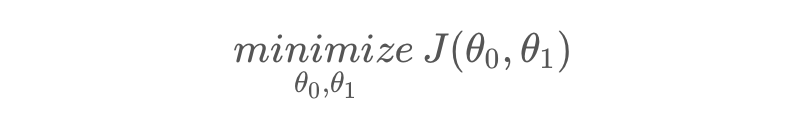
2.2. 代价函数和假设函数
以下小节内容仍基于线性模型讨论。
- 假设函数是关于两个参数的函数,其作用得到输入值x对应的预测值y。
- 代价函数是也是关于两个参数的函数,其作用是对代入两个具体参数值的假设函数进行判断,判断假设函数的输出值偏离正确值的程度。我们最后一般会选择使代价函数最小对应的参数值
为了更好地了解这两种函数,请看以下两个例子。
2.2.1. 举例学习-例子A
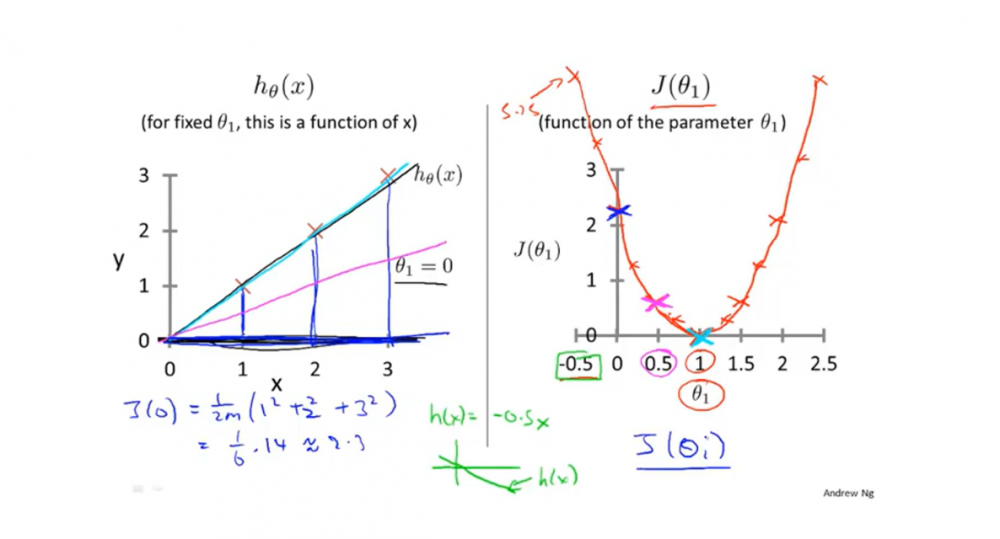
以下例子是基于\(h_θ(x)=θ_0+θ_1x\)假设函数,并且为了更容易让读者明白其区别。老师使\(θ_0 = 0\),简化了函数。
该例子的代价函数如下右图,当\(θ_1\)取不同值时,可以得出不同的代价函数值,而代价函数值最小时(这里例子最小是0),假设函数预测值误差最小。
2.2.2. 举例学习-例子B
这个例子是对上面例子的进一步深入学习,在该例子中,依然使用\(h_θ(x)=θ_0+θ_1x\)假设函数,但是两个参数都保留。
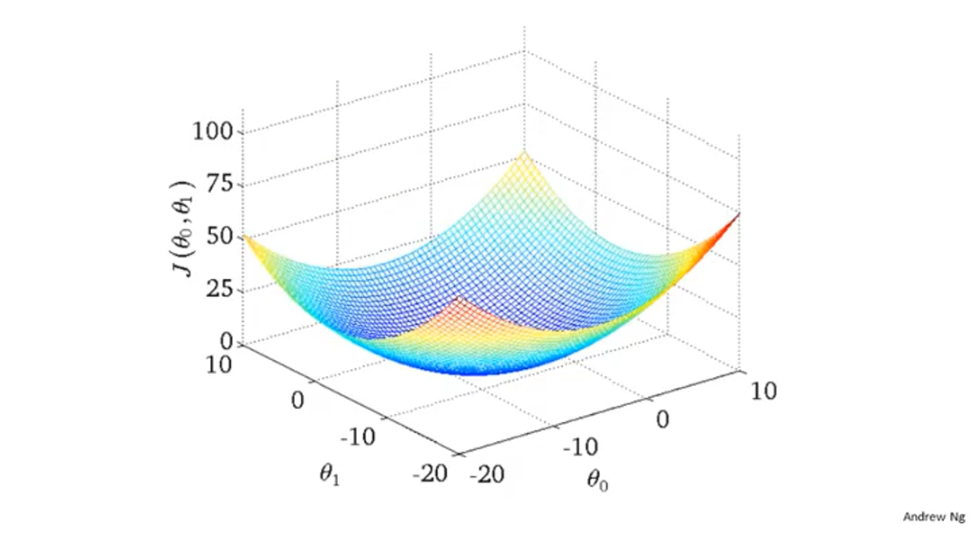
之前只有一个参数时,代价函数是呈碗状的。而当有2个参数,实际上代价函数的样子也是一个碗状,不过是一个3D的碗,如下图(3D曲面图)所示。
\(θ_0\)、\(θ_1\)是轴标。纵轴是 每一组(\(θ_0\),\(θ_1\))所对应的代价值J(\(θ_0\),\(θ_1\))
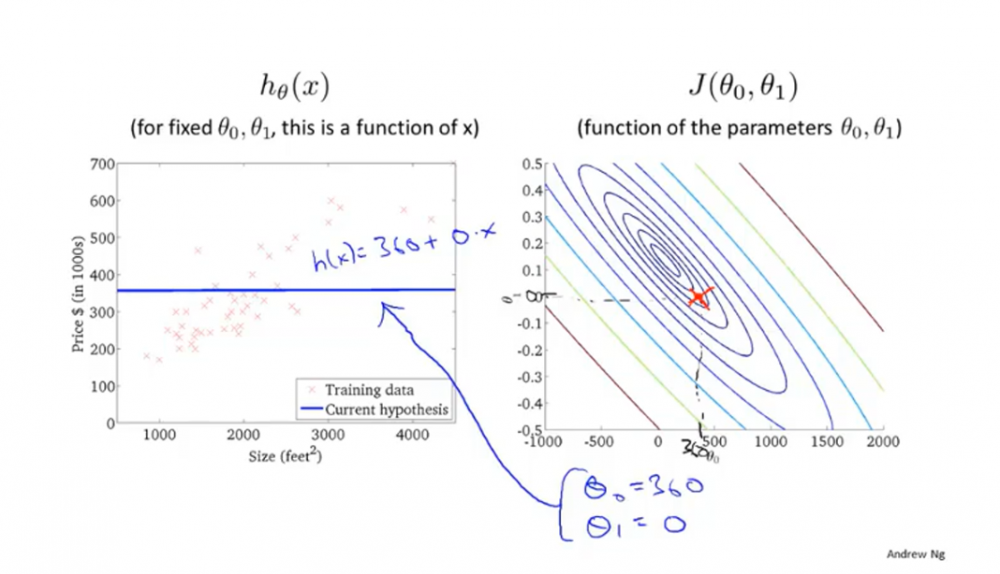
然而,一般会用等高线图代替3D曲面图。如下图所示,该图便是等高线图,其主要是把代价值J(\(θ_0\),\(θ_1\))放在了一个二维平面上。而且越靠近同心圆的圆心,其代价函数值越小。读图举例:下图标注的红叉就是(360,0)对应的代价值。
由于它在三维是一个碗状,所以投影在平面上时,变成了一圈一圈的图案。
从上述可知,对于两个参数形成的代价函数图,我们可以用三维图表示,而且也可以用二维图表示。但是当遇到多参数时,这些更高维的图时,我们很难将其可视化,故想通过图像找到其代价最小值是很困难的。所以,我们需要一个算法,一个自动找到使函数最小的\(θ_0\),\(θ_1\)的算法。
3. 梯度下降算法
3.1. 作用
从上面学习可知,代价函数的最小值尤其重要。然而在这里就可以用梯度下降算法gradient descent来计算代价函数的最小值。故,梯度下降算法是用来求代价函数的最小值的。

举例学习
- 举例说明其大概效果:对于下面2个参数的代价函数(如下图),假如要找到一个最低点,我们可以从山顶出发(这是随机取的点),然后找到往最陡的方向走一步。后面每一步都是走最陡的,结果可能会找到下面所示的点(靠近\(θ_0\)轴的那个点)。
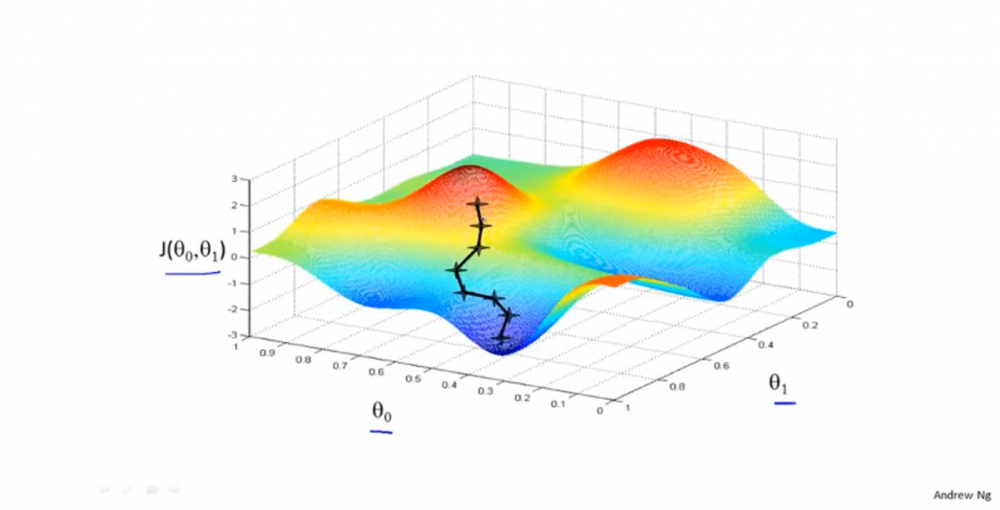
- 不同点出发可能会有不同的局部最优解。如下图所示,从另一点出发,得到的终点不一样。
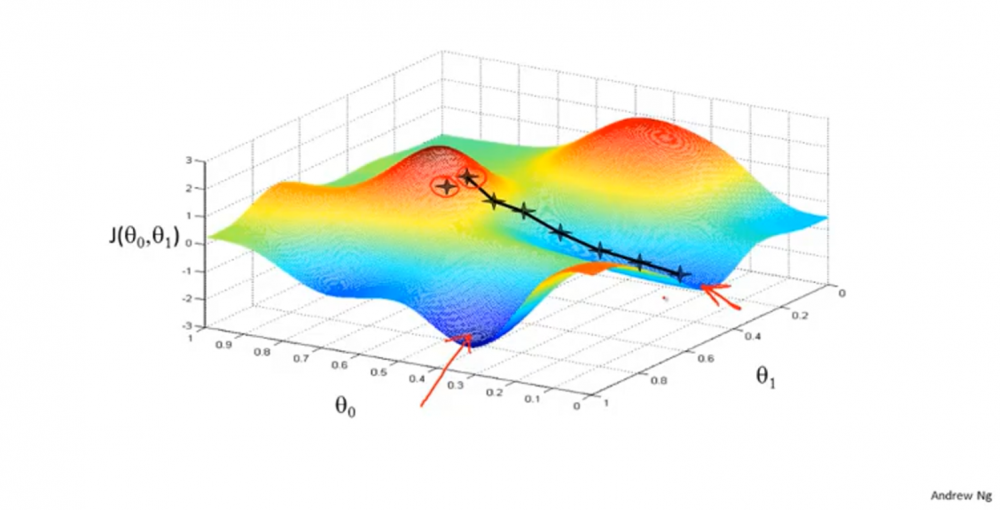
3.2. 函数公式
以下公式是基于两个参数的代价函数的。其它代价函数也是一样的,替换即可。

3.2.1. 公式解析
如上图所示,其公式就是从某对(\(θ_0\),\(θ_1\))开始,然后不停地通过上述公式迭代更新\(θ_0\),\(θ_1\),直到达到预期才停止。
𝛼:学习率,learinning rate。它控制更新\(𝜃_j\)幅度的大小。
:= 这个是赋值符号
公式的右侧是个偏导数。
下面以只有一个参数的代价函数进行举例学习该算法公式的特性。
- 偏导数实际上在求一个点所在位置的切线斜率。
- 学习率𝛼越小,其幅度越小。如下图上方曲线所示,蓝点不停地慢慢靠近局部最优解(切线斜率为0的点)。
- 学习率𝛼越大,其幅度越大。因为新θ是通过原θ减去𝛼乘上偏导数的。而且幅度若很大,会导致无法收敛甚至发散。因为每当要靠近局部最低点时,都会因为幅度太大而直接跳过局部最低点。也就是会出现下图下方曲线的情况。
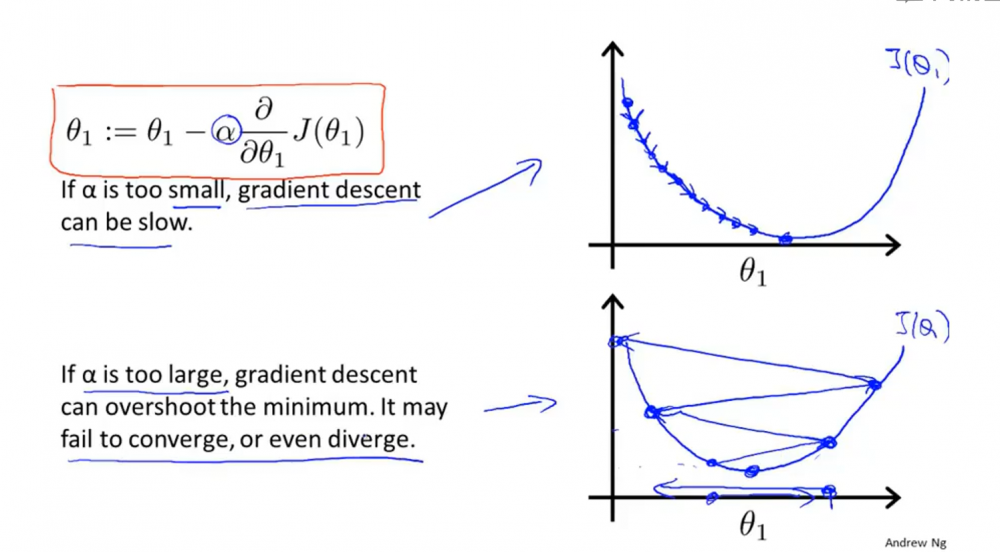
- 当θ越靠近局部最优点时,其幅度就会越小。因为越接近局部最优点,其斜率越小,所以其减去的部分就越小。(结合公式看,很容易得出。)。例子如下图。
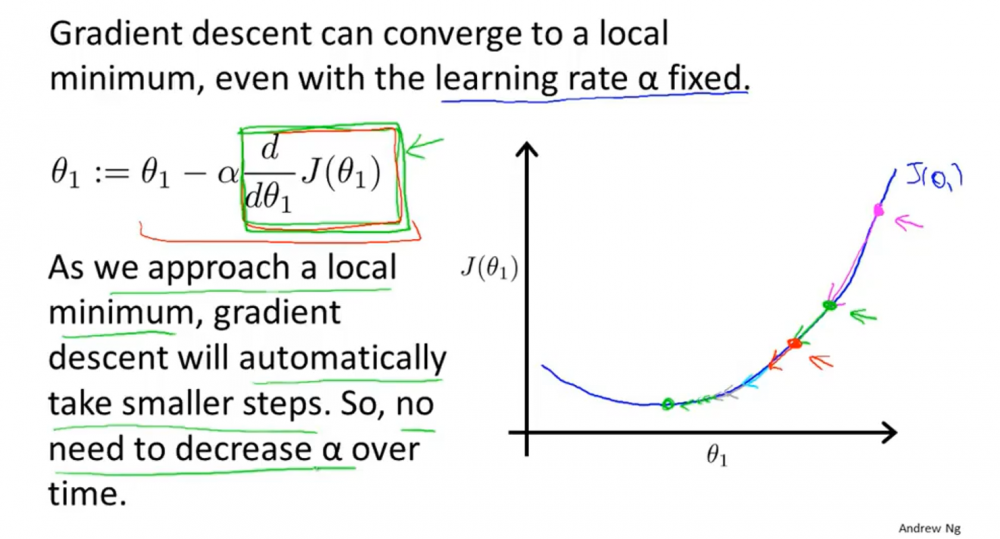
3.2.2. 公式注意事项
从上式可知,这个公式会对\(θ_0\),\(θ_1\)更新,那么记得要将这两个参数同时更新(如下图左侧所示:先全部计算出来,再同一更新)。不要计算一个就更新一个,否则会影响后面参数的计算。(如下图右侧所示,这是错误示范)
老师也说到:目前大家默认的梯度下降都是同时更新的。当然,在部分情况下即使不同时更新,结果可能也是正确的,但是这种方法并不是人们所指的梯度下降算法,而且具有不同性质的其它算法。

3.3. 线性回归的梯度下降
通过上面1.3.节 和2.2.节的学习可知,线性回归函数和其代价函数如下图右侧所示。那么下面将讨论线性回归模型的梯度下降是怎样计算的。

首先,我们先对梯度下降算法的公式进行一些处理。先将线性模型的假设函数代入梯度下降算法的公式,再对偏导数部分进行计算,得出进一步的公式结果。最后公式如下图所示。

再讨论一下线性回归的代价函数。事实上,用于线性回归的代价函数总是一个弓状函数,被称为凸函数
Convex Function。这样的函数没有局部最优解,只有一个全局最优解。所以我们在使用梯度下降的时候,总会得到一个全局最优解。
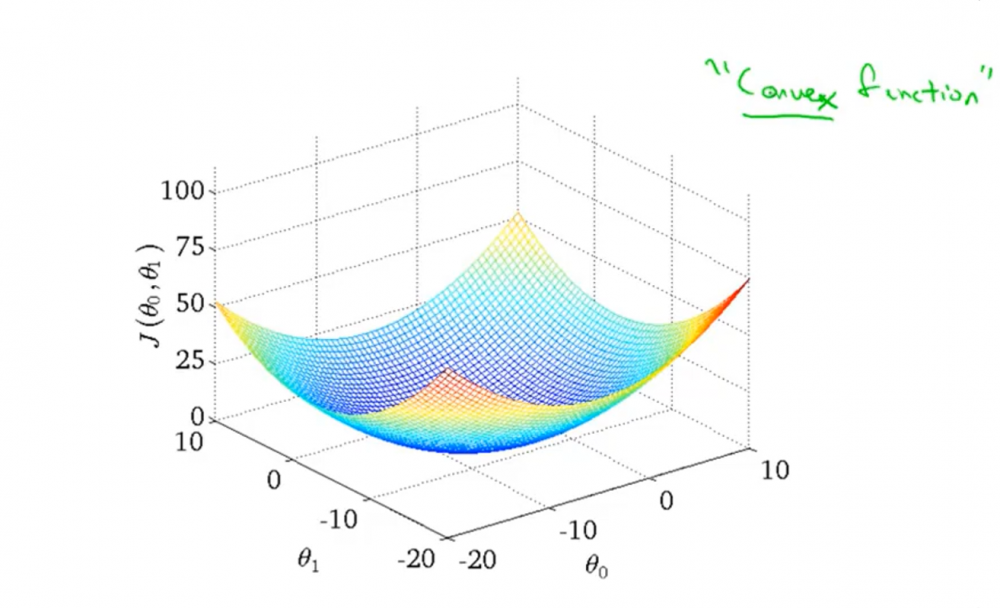
然后,从一组(\(θ_0\),\(θ_1\))开始,后面由于梯度算法,其(\(θ_0\),\(θ_1\))会不断更新,直到最后得到局部最优解。例如从(900, -0.1)开始,其梯度下降过程如下图所示(录制的gif,变化有点缓慢)。
老师说一般是从(0,0)开始,但课程视频为了更形象说明其效果,选择了从(900, -0.1)开始。

如果上述gif图无法加载,请直接下载观看:梯度下降过程gif图
3.4. Batch 梯度下降
上述所介绍的梯度下降算法实际上说梯度下降算法的一种,这个算法叫做Batch 梯度下降算法Batch gradient descent。该算法的特点是梯度下降的每一步都用到了整个训练集。而某些梯度下降算法只是关注部分子集的。这个后面会持续学习到。

3.5. 其它选择
其实,从数学的角度来说,我们说可以通过正规方程组方法normal equations method来求代价函数的局部最优解的(后面课程会讲解)。然而梯度下降的迭代算法适用于更大的数据集。
笔记参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号