【爬虫】基于PUPPETEER页面爬虫
一、简介
本文简单介绍一下如何用puppeteer抓取页面数据。
二、下载
npm install puppeteer --save-dev
npm install typescrip --save-dev
三、实例
(一)实例一(看一段代码)
import { launch } from 'puppeteer';
async function maoyan_board_run() {
let browser = await launch({
ignoreHTTPSErrors: true,
headless: true,
executablePath: 'D:\\wangxiao\\chrome-win\\chrome-win\\chrome.exe',
args: ['--start-maximized']
});
const page = await browser.newPage();
await page.setViewport({width:1980,height:1080});
await page.goto('https://maoyan.com/board', { waitUntil: 'load' });
console.log(await page.title());
await browser.close();
}
maoyan_board_run();

运行后,答应出当前页面的title,分析一下这段代码做什么
- launch() 模拟启动一个浏览器,注意里面的参数,headless:true 无头模式,不打开浏览器,--start-maximized:浏览器最大化,executablePath:chromiun指定的路径
- browser.newPage() 打开一个新的页面
- page.setViewport() 指定窗口的高宽
- page.goto() 打开某个网站,waitUtil:load 加载完成
(二)分析页面selector
我们先分析一下这个页面,首先我们发现热门排行榜,电影名,主演,上映时间都是在一列一列的,那我们是不是只要获取一个,其他的都一样都获取到了
我们先分析一个名次
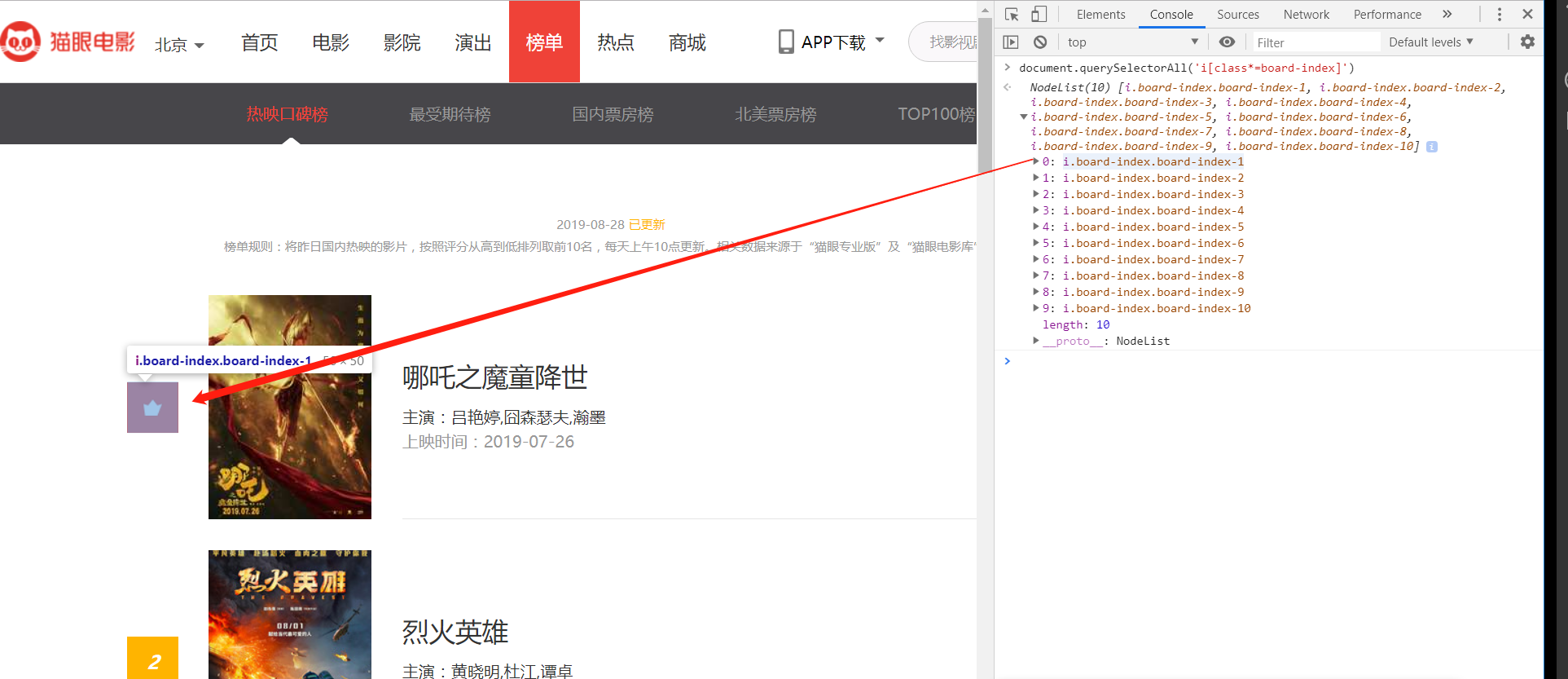
const movie_bank = 'i[class*=board-index]';
根据页面元素分析,要得到标签内的值($$eval用法不用说了,前面已经讲过了)
、

const banks = await page.$$eval(movie_bank, list =>
list.map(n => n.innerHTML)
);
其他内容获取方法依葫芦画瓢,完整代码如下
// 热门口碑榜-名次
const movie_bank = 'i[class*=board-index]';
// 热门口碑榜-名字
const movie_name = '.movie-item-info .name a';
// 热门口碑榜-主演
const movie_star = '.movie-item-info .star';
// 热门口碑榜-上映时间
const movie_releasetime = '.movie-item-info .releasetime';
// 热门口碑榜-图片
const board_lists_images = '.board-wrapper dd .image-link .board-img';
async function maoyan_board_run() {
let browser = await launch({
ignoreHTTPSErrors: true,
headless: true,
executablePath: 'D:\\wangxiao\\chrome-win\\chrome-win\\chrome.exe',
args: ['--start-maximized']
});
const page = await browser.newPage();
await page.setViewport({width:1980,height:1080});
await page.goto('https://maoyan.com/board', { waitUntil: 'load' });
// await autoScroll(page);
const length = await page.evaluate( (movie_bank) => {
return document.querySelectorAll(movie_bank).length;
},movie_bank);
const banks = await page.$$eval(movie_bank, list =>
list.map(n => n.innerHTML)
);
const names = await page.$$eval(movie_name, list =>
list.map(n => n.getAttribute('title'))
);
const stars = await page.$$eval(movie_star, list =>
list.map(n => n.innerHTML.replace(/\n/g,"").replace(/\s/g,""))
);
const releasetimes = await page.$$eval(movie_releasetime, list =>
list.map(n => n.innerHTML)
);
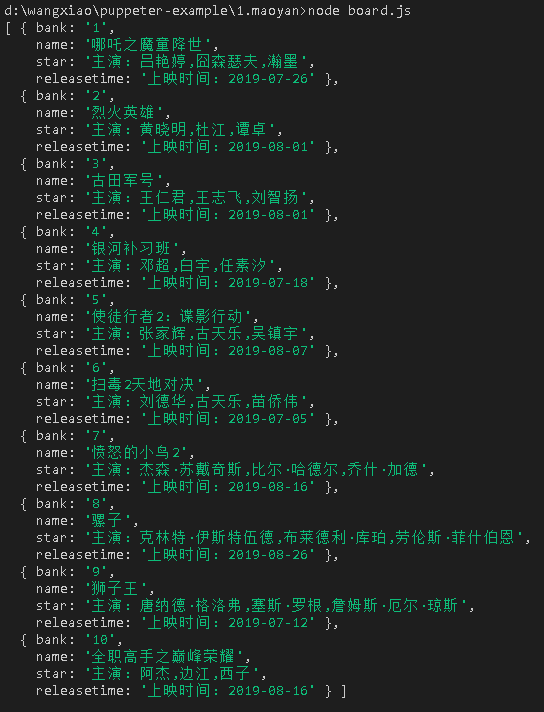
let data = [];
for (let i =0;i<length;i++) {
data.push({
bank:banks[i],
name:names[i],
star:stars[i],
releasetime:releasetimes[i]
})
}
await page.waitFor(10000);
console.log(data);
await browser.close();
}
maoyan_board_run();