【PUPPETEER】初探之元素获取(二)
一、涉及的知识点
- 如何使用css selector
- 常用元素获取
- $ 元素选择
- type (api 输入)
- click (api 点击)
二、学习网址
三、环境
- node js
- puppeteer
- 编辑器 vscode
四、实例
-- 常用元素选择器
| 选择器 | 示例 | 解释 |
| id选择器 | #id | 选择匹配id的元素,仅存在一个 |
| class选择器 | .class | 同时匹配多个class 元素 |
| 属性选择器 | div[attr] | 匹配具有attr的属性,不考虑他的值 |
| 属性选择器 | div[attr='122'] | 匹配具有attr的属性,值为122 |
| 后代选择器 | div span | 后代选择器,匹配所有div 后面的span标签,div 与 span之间用空格隔开 |
| 子元素选择器 | div > span | 子元素选择器,匹配div 后所有的span |
| 匹配父元素下的第n个子元素 | div:nth-child(2) | 匹配父元素下的第2个元素 |
1. id 选择器

代码演示:
const puppeteer = require('puppeteer');
(async () => {
const brower = await puppeteer.launch({
executablePath:'D:\\wangxiao\\chrome-win\\chrome-win\\chrome.exe',
headless:false
});
const page = await brower.newPage();
await page.goto('https://www.cnblogs.com/');
const input = await page.$('#zzk_q');
input.type('12222');
//await brower.close();
})().catch(error =>{console.log('error')});
2.nth-child(n) 灵活运用
这里不一一演示了,演示主要的,比如子级,如图,我们想登入,但是登入没有id,也没有class, 那我们试试其他方式,往父级看,
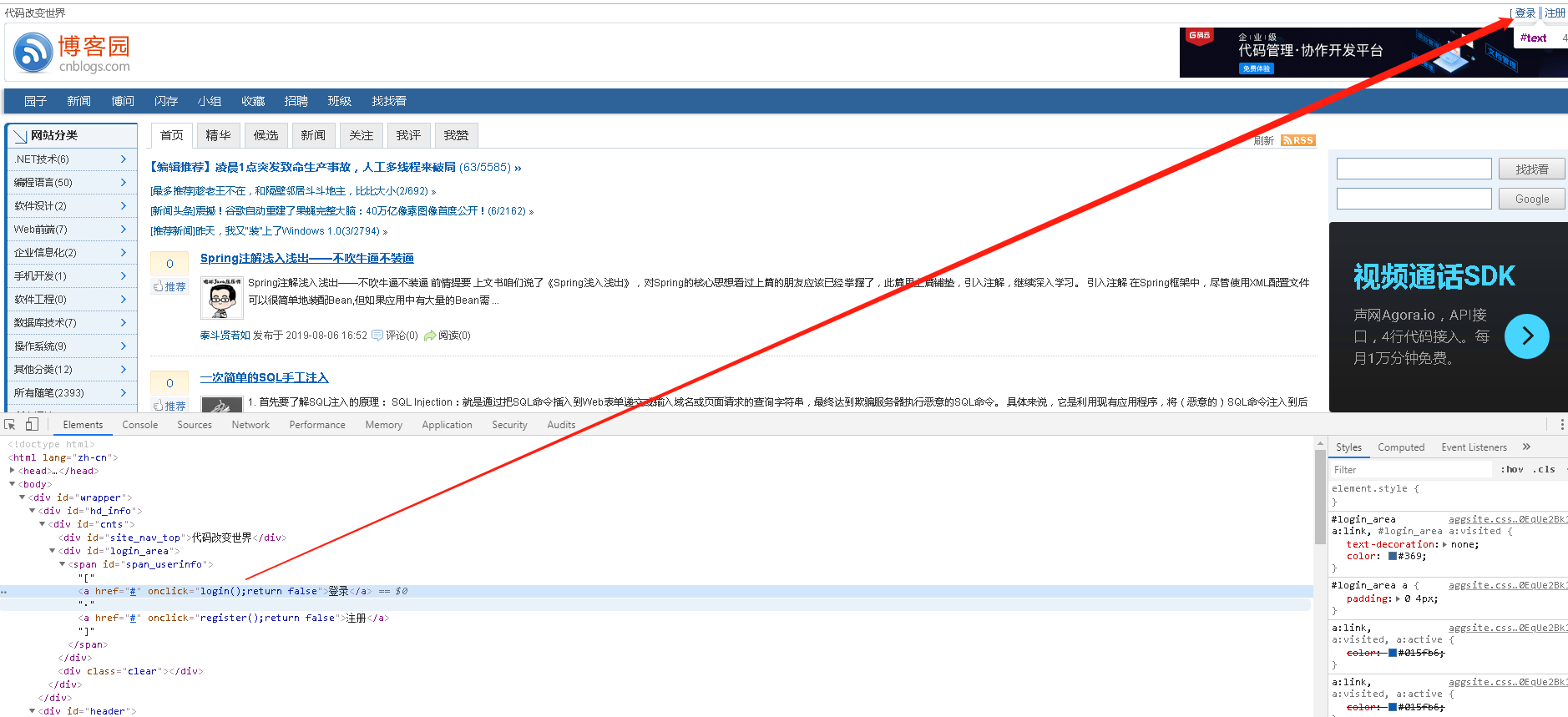
有唯一id = 'span_userinfo' ,那么我们可以手写成
获取所有的a标签 - >
element = '#span_userinfo a'
获取登入的超级链接
element = '#span_userinfo a:nth-child(1)'
我们代码验证一下对不对
const puppeteer = require('puppeteer');
(async () => {
const brower = await puppeteer.launch({
executablePath:'D:\\wangxiao\\chrome-win\\chrome-win\\chrome.exe',
headless:false
});
const page = await brower.newPage();
await page.goto('https://www.cnblogs.com/');
await page.click('#span_userinfo a:nth-child(1)')
//await brower.close();
})().catch(error =>{console.log('error')});
五、学会css Selector
步骤:
1.打开浏览器开发者工具(F12)
2.在浏览器的Console窗口中使用document.querySelectorAll调试你的css选择器

