【scarpy】笔记三:实战一
一、前提
我们开始爬虫前,基本按照以下步骤来做:
1.爬虫步骤:新建项目,明确爬虫目标,制作爬虫,存储爬虫内容

二、实战(已豆瓣为例子)
2.1 创建项目
1.打开pycharm -> 点开terminal (或者命令行都可以)输入
scrapy startproject douban
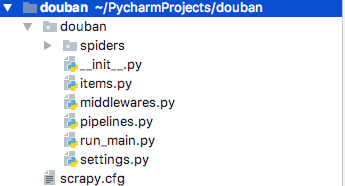
2.导入 douban scrapy项目,项目结构如下
--spiders 爬虫主文件,爬虫文件在这个里面编写
--items 数据结构文件,封装提取的文件字段,保存爬取到的数据的容器
--settings 项目设置文件
--pipelines 项目中的pipelines文件
2.2 分析网站
->需求:
1.目标站点:https://movie.douban.com/top250
2.获取第一页 所有电影对应的编号,电影名称,星级,评论,介绍
3.获取所有页数的 电影信息
2.3 步骤
1.编辑items.py
数据结构文件,简单的理解成,爬取的数据都存在这里面,要单独定义个字段以字典的形式去存储
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#序号
serial_number = scrapy.Field()
#电影名称
movie_name = scrapy.Field()
#电影介绍
movie_introduce = scrapy.Field()
#星级
movie_start = scrapy.Field()
#电影评论数
movie_evaluate = scrapy.Field()
#电影描述
movie_describe = scrapy.Field()
2.编辑settings.py,编辑 USER_AGENT
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
3.在spiders下面新增douban_spider.py
class DoubanSpiderSpider(scrapy.Spider):
#爬虫名
name = 'douban_spider'
#允许爬虫的域名
allowed_domains = ['movie.douban.com']
#入口url,放到调度器里->到引擎->到下载器->返回到scarpy
start_urls = ['http://movie.douban.com/top250']
print(response.text)
def parse(self, response):
print(response.text)
4.我们来运行一下,打开pycharm-terminal-输入scrapy crawl douban_spider
5.但是每次输入的话,都很麻烦,我们新建一个run_main.py,每次运行这个文件就可以了
from scrapy import cmdline
cmdline.execute('scrapy crawl douban_spider'.split())
6.获取单个页面信息代码
知识点:
1.用xpath解析网页
2..extract() 通过xpath获取的是selector,我们在通过extract()方法得到内容 extract_first(),获取第一个内容
3.yield 返回内容
def parse(self, response):
#单个页面的电影列表 movie_list = response.xpath('//*[@id="content"]/div/div[1]/ol/li') for i_item in movie_list:
#声明item.py方法 douban_item = DoubanItem() douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first() douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//span[@class='title']/text()").extract_first() douban_item['movie_introduce'] = i_item.xpath(".//div[@class='bd']//span[@class='inq']/text()").extract_first() douban_item['movie_start'] = i_item.xpath(".//div[@class='star']//span[@class='rating_num']/text()").extract_first() douban_item['movie_evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first() content = i_item.xpath(".//div[@class='item']//div[@class ='bd']//p/text()").extract() yield douban_item
7.获取所有的完整的页面代码
class DoubanSpiderSpider(scrapy.Spider):
#爬虫名
name = 'douban_spider'
#允许爬虫的域名
allowed_domains = ['movie.douban.com']
#入口url,放到调度器里->到引擎->到下载器->返回到scarpy
start_urls = ['http://movie.douban.com/top250']
def parse(self, response):
movie_list = response.xpath('//*[@id="content"]/div/div[1]/ol/li')
for i_item in movie_list:
douban_item = DoubanItem()
douban_item['serial_number'] = i_item.xpath(".//div[@class='item']//em/text()").extract_first()
douban_item['movie_name'] = i_item.xpath(".//div[@class='info']//span[@class='title']/text()").extract_first()
douban_item['movie_introduce'] = i_item.xpath(".//div[@class='bd']//span[@class='inq']/text()").extract_first()
douban_item['movie_start'] = i_item.xpath(".//div[@class='star']//span[@class='rating_num']/text()").extract_first()
douban_item['movie_evaluate'] = i_item.xpath(".//div[@class='star']//span[4]/text()").extract_first()
content = i_item.xpath(".//div[@class='item']//div[@class ='bd']//p/text()").extract()
yield douban_item
#下一页的xpath
next_link = response.xpath("//*[@id='content']//span[@class='next']//link/@href").extract()
#如果是true,执行,并且回调self.parse
if next_link:
next_link = next_link[0]
print(next_link)
yield scrapy.Request("https://movie.douban.com/top250"+next_link,callback=self.parse)
参考文档:https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
