python面试10问
生成器send的应用场景
- 当生成器生成一个新值时,通过send函数传递一个新的参考值(赋值给=yield的左边),然后根据这个参考值去做事情
- 可以了理解为用于和生成器通信
- 第一次生成器启动必须使用next()或者send(None)
如何动态创建类,应用场景是什么
type
使用type()函数创建元类(metaclass)
type(类名,(父类的元组),{键值对}),键值对一般时方法名或者变量名的映射
class Say:
...
def hello_world(self):
print("hello")
Hello = type('Hello',(Say,),{'hello':hello_world,'num':3})
--------------相当于---------------
class Hello(Say):
self.num = 3
def hello(self):
print("hello")
metaclass
可以把类看成是metaclass创建出来的“实例”
metaclass的类名总是以Metaclass结尾
# metaclass是创建类,所以必须从`type`类型派生:
class FriendMetaclass(type):
def __new__(cls, name, bases, attrs):
'''
cls:当前准备创建的类的对象;
name:类的名字;
basees:类继承的父类集合;
attrs:类的属性集合。
'''
attrs['add'] = lambda self, value: self.append(value)
return type.__new__(newcls, name, bases, attrs)
# 指示使用FriendMetaclass来定制类,此处list说明MyFriend传入cls对象是List类型
class MyFriend(list, metaclass=FriendMetaclass):
pass
场景
典型例子:ORM
编写一个ORM框架,所有的类都只能动态定义,因为只有使用者才能根据表的结构定义出对应的类
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
# 当前类名为Model就直接创建
if name == 'Model':
return type.__new__(cls, name, bases, attrs)
print('Found model: %s' % name)
# metaclass可以隐式地继承到Model的子类
mappings = dict()
for k, v in attrs.items():
if isinstance(v, Field):
print('Found mapping: %s ==> %s' % (k, v))
mappings[k] = v
for k in mappings.keys(): # 这里为什么要pop呢?
attrs.pop(k)
attrs['__mappings__'] = mappings # 保存属性和列的映射关系
attrs['__table__'] = name # 假设表名和类名一致
return type.__new__(cls, name, bases, attrs)
class Model(dict, metaclass=ModelMetaclass):
def __init__(self, **kw):
super(Model, self).__init__(**kw)
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Model' object has no attribute '%s'" % key)
def __setattr__(self, key, value):
self[key] = value
def save(self):
fields = []
params = []
args = []
for k, v in self.__mappings__.items():
fields.append(v.name)
params.append('?')
args.append(getattr(self, k, None))
sql = 'insert into %s (%s) values (%s)' % (self.__table__, ','.join(fields), ','.join(params))
print('SQL: %s' % sql)
print('ARGS: %s' % str(args))
metaclass在这里的作用可以简单地理解为动态地根据Model的子类中的属性去设置Model类中的定义,有种父类反过来继承子类的意思
socket如何解决粘包问题
什么是粘包
当发送网络数据时,tcp协议会根据Nagle算法将时间间隔短,数据量小的多个数据包打包成一个数据包,先发送到自己操作系统的缓存中,然后操作系统将数据包发送到目标程序所对应操作系统的缓存中,最后将目标程序从缓存中取出,但是应用程序并不知道第一个数据包的长度,所以会直接从缓存中取出数据或者取出部分数据,留部分数据在缓存中,取出的数据可能第一个数据包和第二个数据包粘到一起
客户端出现粘包:数据无法一次性读完
服务端出现粘包:当发送的消息数据的间隔短,会将几次的分开的消息一次性读出来
解决方案
由于应用程序自己发送的数据可以进行打包处理,自己制作协议,对数据进行封装添加报头,然后发送数据的部分。
因为报头必须是固定长度,所以对方接收时可以先接收报头,对报头进行解析,然后根据报头内的封装的数据的长度对数据进行读取,这样收取的数据就是一个完整的数据包
代码实现
使用struct模块进行打包
- pack():打包
- unpack():拆包
服务端
- 接收客户端报头信息
- 启动一个新进程读取并打包信息
- 将打包好的信息发送给客户端
import socket
import struct
import subprocess
# 服务端绑定+监听
phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
phone.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
phone.bind(('127.0.0.1', 8080))
phone.listen(5)
while True:
conn, addr = phone.accept() # 获取连接过来的对象和地址
# 服务端对客户端的数据每到1024长度的数据就打一次包
while 1:
try:
data = conn.recv(1024)
# 启动一个新进程,并连接到它们的输入/输出/错误管道,从而获取返回值
res = subprocess.Popen(data.decode('utf-8'), shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
stdout = res.stdout.read()
stderr = res.stderr.read()
# 发送报头,i表示int类型
res = struct.pack('i', len(stdout) + len(stderr))
conn.send(res)
# 将报头的解析发送发送回客户端
conn.send(stdout)
conn.send(stderr)
except Exception:
break
conn.close()
phone.close()
客户端
import socket
import struct
# 连接服务端
phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
phone.connect(('127.0.0.1', 8080))
while True:
cmd = input('请输入>>:').strip()
if not cmd: continue
# 发送报头信息给服务端
phone.send(cmd.encode('utf-8'))
# 接收服务端解析并打包好的报头
res = phone.recv(4)
# 解压报头,从报头中获取数据长度
data_size = struct.unpack('i', res)[0]
recv_size = 0
total_data = b''
# 若剩余数据长度不足1024,就只取这剩余的数据,而不是从下一个包中拿数据填充1024的长度
while recv_size < data_size:
data_recv = phone.recv(1024)
if (data_size - len(data_recv)) < 1024:
# 剩余数据
left_data = phone.recv(data_size - len(data_recv))
total_data += left_data
total_data += data_recv
recv_size += len(data_recv)
data = phone.recv(1024)
print(data.decode('gbk'))
phone.close()
socket断点续传如何解决
断点续传就是从文件中断的地方接下去下载,而不必重新下载
实现断点续传功能,客户端要记录下载进度即下载区域,再续传就要传递下载的区域片段。
socket实现
发送端
- 打包并文件头信息(包含文件大小)
- 接收客户端发来的信息(包含已下载的信息)
- 根据已下载信息中的文件大小,对文件进行定位
- 从定位出开始发送剩余的数据
import socket
import struct
import sys
import os
import time
if __name__ == '__main__':
file_name = sys.argv[1]
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((socket.gethostname(), 12345))
# 将文件信息打包发送给客户端
file_head = struct.pack('128sl', os.path.basename(file_name).encode(),
os.stat(file_name).st_size)
sock.send(file_head)
# 获取从接收端发来的已下载的文件大小
received_size = int(sock.recv(2014).decode())
read_file = open(file_name, "rb")
# 根据已下载的大小定位到游标位置
read_file.seek(received_size)
while True:
# time.sleep(1)
file_data = read_file.read(10240)
if not file_data:
break
# 发送剩余的文件大小,直到读完
sock.send(file_data)
read_file.close()
sock.close()
接收端
- 接收服务端文件头信息(包含下载文件的大小)
- 根据本地下载路径确定文件是否存在以及文件目前的大小
- 将文件当前的信息发送给服务端
- 接收剩余文件的数据,写入文件中
import socket
import threading
import os
import struct
def sending_file(connection):
try:
file_info_size = struct.calcsize('128sl')
# 接受缓存
buf = connection.recv(file_info_size)
if buf:
# 定位并判断文件路径在接收端是否存在,若存在则获取已下载的大小
file_name, file_size = struct.unpack('128sl', buf)
file_name = file_name.decode().strip('\00')
file_new_dir = os.path.join('receive')
# print(file_name, file_new_dir)
if not os.path.exists(file_new_dir):
os.makedirs(file_new_dir)
file_new_name = os.path.join(file_new_dir, file_name)
received_size = 0
if os.path.exists(file_new_name):
received_size = os.path.getsize(file_new_name)
# 向发送端发送已下载的大小
connection.send(str(received_size).encode())
# 从文件尾部逐渐写入,直到文件大小与发送端的一致
w_file = open(file_new_name, 'ab')
print("start receiving file:", file_name)
while not received_size == file_size:
r_data = connection.recv(10240)
received_size += len(r_data)
w_file.write(r_data)
w_file.close()
print("接收完成!\n")
connection.close()
except Exception as e:
print(e)
if __name__ == '__main__':
host = socket.gethostname()
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind((host, 12345))
sock.listen(5)
print("服务已启动---------------")
while True:
connection, address = sock.accept()
print("接收地址:", address)
thread = threading.Thread(target=sending_file, args=(connection,))
thread.start()
django实现
功能基于django.views.static.serve实现,实现的关键点是:
- response中增加'Content-Range'、'Cache-Control'的参数
- 根据不同的情况为response设置不同的status
- 根据HTTP_RANGE对读取文件时的起始位置进行设置
myproject/views_file.py
import re
import os
import stat
import mimetypes
import posixpath
from django.utils._os import safe_join
from django.utils.http import http_date
from django.views.static import was_modified_since
from django.http import Http404, FileResponse, HttpResponseNotModified
# 基于django.views.static.serve实现,支持大文件的断点续传(暂停/继续下载)
def get_file_response(request, path, document_root=None):
# 防止目录遍历漏洞
path = posixpath.normpath(path).lstrip('/')
fullpath = safe_join(document_root, path)
if os.path.isdir(fullpath):
raise Http404('Directory indexes are not allowed here.')
if not os.path.exists(fullpath):
raise Http404('"%(path)s" does not exist' % {'path': fullpath})
statobj = os.stat(fullpath)
# 判断下载过程中文件是否被修改过
if not was_modified_since(request.META.get('HTTP_IF_MODIFIED_SINCE'),
statobj.st_mtime, statobj.st_size):
return HttpResponseNotModified()
# 获取文件的content_type
content_type, encoding = mimetypes.guess_type(fullpath)
content_type = content_type or 'application/octet-stream'
# 计算读取文件的起始位置
start_bytes = re.search(r'bytes=(\d+)-', request.META.get('HTTP_RANGE', ''), re.S)
start_bytes = int(start_bytes.group(1)) if start_bytes else 0
# 打开文件并移动下标到起始位置,客户端点击继续下载时,从上次断开的点继续读取
the_file = open(fullpath, 'rb')
the_file.seek(start_bytes, os.SEEK_SET)
# status=200表示下载开始,status=206表示下载暂停后继续,为了兼容火狐浏览器而区分两种状态
# FileResponse默认block_size = 4096,因此迭代器每次读取4KB数据
response = FileResponse(the_file, content_type=content_type, status=206 if start_bytes > 0 else 200)
# 'Last-Modified'表示文件修改时间,与'HTTP_IF_MODIFIED_SINCE'对应使用
response['Last-Modified'] = http_date(statobj.st_mtime)
# 这里'Content-Length'表示剩余待传输的文件字节长度
if stat.S_ISREG(statobj.st_mode):
response['Content-Length'] = statobj.st_size - start_bytes
if encoding:
response['Content-Encoding'] = encoding
# 'Content-Range'的'/'之前描述响应覆盖的文件字节范围,起始下标为0,'/'之后描述整个文件长度,与'HTTP_RANGE'对应使用
response['Content-Range'] = 'bytes %s-%s/%s' % (start_bytes, statobj.st_size - 1, statobj.st_size)
# 'Cache-Control'控制浏览器缓存行为,此处禁止浏览器缓存
response['Cache-Control'] = 'no-cache, no-store, must-revalidate'
return response
myproject/urls.py
from django.urls import re_path
from django.conf import settings
from myproject import views_file
# MEDIA_ROOT是要下载的文件的存储路径的前半段,下面的配置中'files/.*'匹配到的路径则是后半段,两者合并就是要下载的文件的完整路径
urlpatterns = [re_path(r'^download/(files/.*)$', views_file.get_file_response, {'document_root': settings.MEDIA_ROOT})]
进程间通讯有哪些方式,哪个最高效
常见6种
-
管道pipe:
-
匿名管道:父子进程间的通信,只能 fork 复制父进程 fd 文件描述符来通信
- 比如: ps auxf | grep mysql中「|」竖线就是匿名管道
-
命名管道:突破只能父子间通信的限制,但要提前创建管道类型设备文件
-
不足:通信效率低,不适合频繁交换数据
-
-
消息队列MessageQueue:
-
解决频繁交换数据的问题
-
消息队列是由消息组成的链表,存放在内核中并由消息队列标识符标识。
-
不足:
- 通信不及时,用户态与内核态间数据拷贝有开销
- 消息和队列有大小限制,不适合大数据传输
from multiprocessing import Process, Queue import time # 向对列中写入数据 def write_task(q): if not q.full(): for i in range(5): message = "消息" + str(i) q.put(message) print("写入: %s" % message) # 从队列读取数据 def read_task(q): time.sleep(1) while not q.empty(): print("读取: %s" % q.get(True, 2)) # 等待 2 秒,如果还没有读取到任何消息,则抛出异常 if __name__ == '__main__': print("---父进程开始---") q = Queue() # 父进程创建 Queue,并传递给子进程 pw = Process(target=write_task, args=(q,)) pr = Process(target=read_task, args=(q,)) pw.start() pr.start() print("---等待子进程结束---") pw.join() pr.join() print("---父进程结束---")
-
-
共享存储SharedMemory:
- 解决用户态与内核间的消息拷贝
- 共享内存就是由一个进程映射一段能被其他进程所访问的内存,使多个进程都可以访问。(就是拿出一块虚拟地址空间来,映射到相同的物理内存中),这样写入,另一进程马上能看到,不需拷贝,传来传去,提高通信速度
- 共享内存是最快的 IPC(进程间通讯) 方式。
- 不足:同时修改同一共享内存容易产生冲突
-
信号量Semaphore:
- 解决共享内存的冲突
- 整型计数器,表示资源的数量,实现进程间互斥与同步
- 它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。主要作为进程间以及同一进程内不同线程之间的同步手段。
- 控制信号量两种原子操作:
- P 操作,减 -1,减后:< 0,被占用,进程阻塞等待; >= 0可用,继续执行
- V 操作,加 1, <= 0,有阻塞唤醒运行; > 0,没有阻塞
- P在进入共享资源之前,V 离开后,成对出现
-
信号 ( sinal ) :
- 异常用「信号」通知进程,唯一异步通信机制
- 比如:Ctrl+C:终止进程信号,Ctrl+Z:停止进程信号
- 查看所有信号可使用kill -l
- 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
-
套接字Socket:
-
跨网络与不同主机上进程间通信
-
通信方式
- TCP 字节流通信:socket 是 AF_INET(即使IPV4,AF_INET6是IPV6) + SOCK_STREAM;
- UDP 数据报通信:socket 是 AF_INET + SOCK_DGRAM;
- 本地进程间通信:
- 字节流:socket是 AF_LOCAL + SOCK_STREAM
- 数据报:socket 是 AF_LOCAL + SOCK_DGRAM
-
套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
-
如何排查数据库慢的原因,步骤是什么
- 区分应用是属于CPU密集型还是I/O密集型
- CPU密集型:
- 问题:
- 复杂的查询语句、存储过程、触发器、自定义函数等
- 锁竞争问题
- 并发量大
- 解决思路:
- 通过慢查询日志,找出相关语句,优化查询语句调整索引策略。还可以将复杂存储过程、触发器、自定义函数交由应用代码实现;
- 根据infomation_schema中的innodb_trx、innodb_locks、innodb_lock_waits三种表,找出锁的事务与开发协调。如果场景允许,可以考虑把事务隔离级别降到读提交。
- 做读写分离、水平拆分。或者增加缓存层,让高并发的读写压力由缓存层消化;
- 调整mysql跟cpu相关参数。
- 问题:
- I/O密集型:
- 问题:
- 投影了所有字段、全表扫描、表结构设计、索引设计问题等;
- 内存缓冲区设置过小,造成了过多的磁盘I/O;
- 网络带宽较小(常见于分布式系统中)。
- 解决思路:
- 通过慢查询日志,找出执行时间久,而且结果集大的语句。减少投影的字段,只选择必要的字段做投影,优化表结构与索引设计;
- 调整内存缓冲区、日志刷新、刷新方法等等参数的设置;
- 提升网络带宽,调整内核参数。
- 问题:
- 纵向扩展:一般用于解决响应时间长的问题。增加CPU计算能力可以减少响应时间,增加内存可以减少磁盘I/O,并将磁盘做raid5、10、01或者直接使用SSD提升I/O处理能力;
- 横向扩展:一般用于解决高并发量问题。比如做简单的读写分离、使用mycat将数据量做分片等,尽量将单机压力分担出去。
如何优化慢查询语句
查询优化神奇Explain
使用方式
EXPLAIN SQL语句
+----+-------------+-------------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------------+------+---------------+------+---------+------+------+-------+
id: select查询的序列号,表示查询中执行select子句或操作表的顺序
- id相同,执行顺序由上至下
- id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
select_type:表示查询的类型
- SIMPLE :简单的select查询,查询中不包含子查询或者UNION
- PRIMARY :查询中若包含任何复杂的子部分,最外层查询则被标记为PRIMARY
- SUBQUERY :在SELECT或WHERE列表中包含了子查询
- DERIVED :在FROM列表中包含的子查询被标记为DERIVED(衍生),MySQL会递归执行这些子查询,把结果放在临时表中
- UNION :
- 若第二个SELECT出现在UNION之后,则被标记为UNION;
- 若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED
- UNION RESULT :从UNION表获取结果的SELECT
type:显示的是查询使用了哪种类型
- system:表只有一行记录(等于系统表),这是const类型的特列,平时不会出现,这个也可以忽略不计
- const:表示通过索引一次就找到了,const用于比较primary key 或者unique索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL就能将该查询转换为一个常量。
首先进行子查询得到一个结果的d1临时表,子查询条件为id = 1 是常量,所以type是const,id为1的相当于只查询一条记录,所以type为system。 - eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描。
- ref:非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体。
- range:只检索给定范围的行,使用一个索引来选择行,key列显示使用了哪个索引,一般就是在你的where语句中出现between、< 、>、in等的查询,这种范围扫描索引比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
- index:Full Index Scan,Index与All区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和Index都是读全表,但index是从索引中读取的,而all是从硬盘读取的)
id是主键,所以存在主键索引 - all:Full Table Scan 将遍历全表以找到匹配的行
从最好到最差依次是:system > const > eq_ref > ref > range > index > all。一般来说,得保证查询至少达到range级别,最好能达到ref。
key:实际使用的索引,如果为NULL,则没有使用索引。
ref:显示索引的那一列被使用了
rows:根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数,也就是说,用的越少越好
rows 是核心指标,绝大部分 rows 小的语句执行一定很快(也有例外)。所以优化语句基本上都是在优化rows
慢查询优化的基本步骤
- 先运行看看是否真的很慢,注意设置 SQL_NO_CACHE
- where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
- explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询),即查看id
- order by limit 形式的sql语句让排序的表优先查
- 了解业务方使用场景
- 加索引时参照建索引的几大原则
- 观察结果,不符合预期继续从0分析
慢查询日志管理
# 慢日志
- 执行时间 > 10,long_query_time的默认值为10
- 未命中索引
- 日志文件路径
# 配置:
- 内存
show variables like '%query%';
show variables like '%queries%';
set global 变量名 = 值
- 配置文件
mysqld --defaults-file='E:\cai\mysql-5.7.16-winx64\mysql-5.7.16-winx64\my-default.ini'
# my.conf内容:
slow_query_log = ON
slow_query_log_file = D:/....
# 注意:修改配置文件之后,需要重启服务
# 查看慢查询日志
# 测试:BENCHMARK(count,expr)
SELECT BENCHMARK(50000000,2*3)
优化原则
- 日期大小的比较,传到xml中的日期格式要符合'yyyy-MM-dd',这样才能走索引
- 条件语句中无论是等于、还是大于小于,
WHERE左侧的条件查询字段不要使用函数或表达式或数学运算 WHERE条件语句尝试着调整字段的顺序提升查询速度,如把索引字段放在最前面、把查询命中率高的字段置前等,保证优化SQL前后其查询结果是一致的- 在查询的时候通过将
EXPLAIN命令写在查询语句前,测试语句是否有走索引 - 禁止使用
SELECT * FROM操作,不需要的字段不要返回 - 可以尝试分解复杂的查询,在应用层面进行表关联,以此代替SQL层面的表关联
WHERE子句和ORDER BY子句涉及到的列建索引- 避免在
WHERE子句中对字段进行NULL判断【可以对表字段改造一下,字符串型字段默认值设置为空字符串,数字型字段默认值设置为0,日期型字段默认值设置为1990-01-01等】 - 避免在
WHERE子句中使用!=或<>操作符或OR操作符 BETWEEN AND代替IN- ``LIKE
'%abc%'不会走索引,而<font color="red">LIKE` 'abc%'会走索引 - 避免对字段进行表达式操作或者函数操作
GROUP BY操作默认会对GROUP BY后面的字段进行排序,如果你的程序不需要排序,可在GROUP BY语句后面加上ORDER BY NULL去除排序- 如果是数值型字段,则尽量设计为数值型字段,不要为了方便、为了偷懒而给后面维护的同事埋坑
- 表中所有字段设计为
NOT NULL - 返回条数固定时,用
LIMIT语句限制返回记录的条数,如只需要一条记录,或肯定只有一条记录符合条件,那建议加上LIMIT 1 - 对于枚举类型的字段【即有固定罗列值的字段】,建议使用
ENUM而不是VARCHAR,如性别、星期、类型、类别等 - 对于存IP地址的字段设计为成
UNSIGNED INT型 - 避免在SQL中使用
NOW()、CURDATE()、RAND()函数【因为这种方式会导致MYSQL无法使用SQL缓存】,可以转化为通过传入参数的方式 - 对于统计类的查询【如查询连续几个月的数据总量,或查询同比、环比等】,可以通过定时查询并统计到统计表的方式提高查询速度
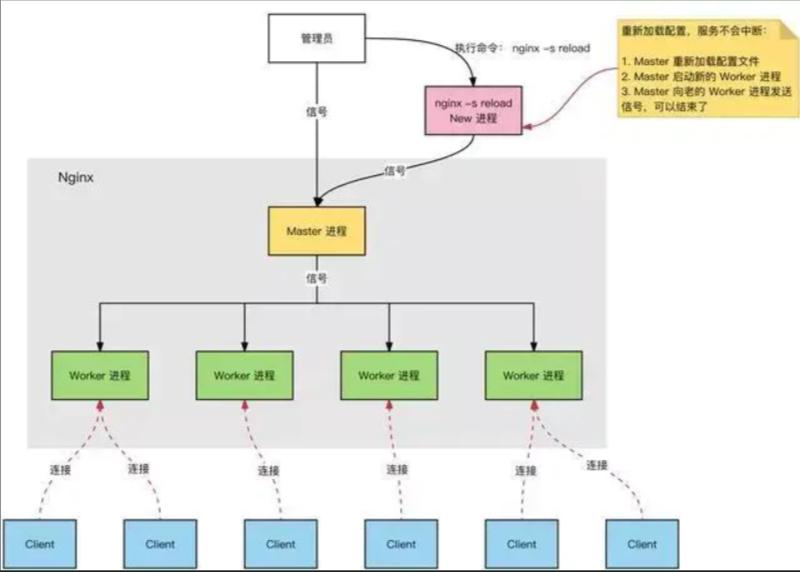
nginx为何单线程可数万并发,机制原理是什么
nginx实际上是一个供客户端访问的服务,但是nginx被访问的目的不是服务器中的项目,而是帮助客户端把请求具体的对应到当前可用的tomcat服务器上
Nginx 服务器(负载均衡和反向代理服务器),正常运行过程中:
多进程:一个 Master 进程、多个 Worker 进程。
- Master 进程:管理 Worker 进程。对外接口:接收外部的操作(请求信号);
- 对内转发:根据外部的操作的不同,通过信号管理 Worker;
- 监控:监控 Worker 进程的运行状态,Worker 进程异常终止后,自动重启 Worker 进程。
- Worker 进程:所有 Worker 进程都是平等的。实际处理:网络请求,由 Worker 进程处理。
- Worker 进程数量:在 nginx.conf 中配置,一般设置为核心数,充分利用 CPU 资源,同时,避免进程数量过多,避免进程竞争 CPU 资源,增加上下文切换的损耗。
大白话就是客户端发送请求给nginx的master进程,而master进程看哪个worker进程是空闲的,让多个空闲的woker进程去抢这个请求信号,谁抢到了就在谁那运行请求的操作,于是就出现了用户只要向一个IP地址发送请求,服务端就可以随机分配给多态服务器去处理
I/O复用技术(select、poll、epoll模型),即多个I/O可以复用一个进程
-
select、poll原理:当连接有I/O流事件产生的时候,就会去唤醒进程去处理,但是进程不知道是哪个连接产生的I/O流事件,于是就得挨个去遍历进程,遍历进程会浪费大量CPU时间片。select、poll原理是一样的,只不过select只能观察1024个连接,poll可以观察无限个连接。
-
epoll原理连接有I/O流事件产生的时候,epoll就会去告诉进程哪个连接有I/O流事件产生,然后进程就去处理这个链接。
Nginx就是采用epoll模型来实现的
每处理完一个请求,就会设置一个事件回调,然后开始处理新的请求。当回调事件被触发时再腾出手来处理回调事件之后的逻辑,整个过程中不会出现等待的情况。所以理论上Ngnix的一个进程就可以处理无限数量的连接,而且无需轮询
通过编辑nginx.conf文件来控制集群
http{
upstream myserver{
ip_hash; # 会话保持
server localhost:8080 weight=10; # weight(权重)越大,优先级越高
server localhost:8081 weight=15; # 除了端口不同以外,还可以IP地址不同
server localhost:8082 weight=20;
}
server{
location / {
proxy_pass http://myserver
}
}
}
前端Jsonp跨域方案原理
由于浏览器同源策略的限制,非同源下的请求,都会产生跨域问题,jsonp即是为了解决这个问题出现的一种简便解决方案。
同源策略即:同一协议,同一域名,同一端口号。当其中一个不满足时,我们的请求即会发生跨域问题。
举个简单的例子:
- http://www.abc.com:3000到https://www.abc.com:3000的请求会出现跨域(域名、端口相同但协议不同)
- http://www.abc.com:3000到http://www.abc.com:3001的请求会出现跨域(域名、协议相同但端口不同)
- http://www.abc.com:3000到http://www.def.com:3000的请求会出现跨域(域名不同)
script标签的src、img标签的src,或者说link标签的href他们没有被同源策略所限制(本质来说都是get请求),jsonp就是使用同源策略这一“漏洞”,实现的跨域请求(jsonp跨域只能用get请求的原因所在)
实现
浏览器端
<button id="btn">点击</button>
<script src="https://cdn.bootcss.com/jquery/3.3.1/jquery.min.js"></script>
<script>
$('#btn').click(function(){
var frame = document.createElement('script');
frame.src = 'http://localhost:3000/article-list?name=leo&age=30&callback=func';
$('body').append(frame);
});
function func(res){
alert(res.message+res.name+'你已经'+res.age+'岁了');
}
</script>
重点是callback
服务器端
router.get('/article-list', (req, res) => {
console.log(req.query, '123');
let data = {
message: 'success!',
name: req.query.name,
age: req.query.age
}
data = JSON.stringify(data)
res.end('func(' + data + ')');
});
其实jsonp的整个过程就类似于前端声明好一个函数,后端返回执行函数。(比如:使用其他网站的接口)
一般前端都是使用ajax调用jsonp
//项目1中html中部分代码
<script>
$(".ajax_btn").click(function () {
$.ajax({
url:"http://127.0.0.1:8002/send_ajax/",
dataType:"jsonp",
jsonp:'callbacks',
success:function (data) {
alert(data);
console.log(data)
}
})
});
</script>
//项目2中的视图函数,即跨域请求的路径
def send_ajax(request):
import json
func_name=request.GET.get("callbacks") #获得回调函数的名字
dic={"k1":"v1"}
print("ok")
return HttpResponse("%s('%s')" %(func_name,json.dumps(dic)))
python服务热更新方案
目标:
- 进程不重启的情况下,更新代码定义,且能按照预期正确执行
- 不更新数据对象
- 不要依赖热更新机制解决所有问题。过于复杂的改动,重启进程
Python的代码是通过module(模块)进行组织的,所以,对某些功能的热更新就是通过对module更新即可
使用reload
在不需要重启服务的情况下,重新加载相关模块
例如:
config1.py
aaa=223
bbb=24
brush.py
import time
from importlib import reload
while True:
import config1
reload(config1)
print(config1.aaa,config1.bbbb)
time.sleep(8)
'''
运行brush.py,因为是死循环,所以会一直运行
第一次打印
223 24
修改config1.py中变量的值
aaa = 333
则下一次打印
333 24
期间brush.py并没有停止
'''
但是:
- reload重新加载的模块不会删除旧版本的模块,也就是已经引用的旧模块无法更新
- 同样因为不能旧对象的引用,使用from ... import ... 方式引用的模块同样不能更新
- reload(m)后,class及其派生class的实例对象,仍然使用旧的class定义。
- 加载模块失败时候,没有rollback机制,需要重新import该模块
热更新当中实际的重点:
- 在于如何让已经创建的对象获得新代码的变化
- 在reload前后不产生类型上的不一致
刷新function,class内定义的method比较容易实现,但对于刷新module内定义的变量,class内定义的变量,还有新增加的成员变量,则需要有统一的约定。所以,在热更新过程中,我们只要考虑好代码更新和数据更新这两点,那么更新就是可行的。
新的reload具备哪些特性:
- 更新代码定义(function/method/static_method/class_method)
- 不更新数据(除了代码定义外的类型都当作是数据)
- 在module中约定reload_module接口,class中约定reload_class接口,在这两个接口中手动处理数据的更新,还有更多的约定和接口待完成
只需要遵守一个原则:保持对象address不变,也即是保证reload_xxxx前后的对象是同一个对象
更新函数
# 用新的函数对象内容更新旧的函数对象中的内容,保持函数对象本身地址不变
def update_function(oldobj, newobj, depth=0):
setattr(oldobj, "func_code", newobj.func_code)
setattr(oldobj, "func_defaults", newobj.func_defaults)
setattr(oldobj, "func_doc", newobj.func_doc)
更新类
# 用新类内容更新旧类内容,保持旧类本身地址不变
def _update_new_style_class(oldobj, newobj, depth):
handlers = get_valid_handlers()
for k, v in newobj.__dict__.iteritems(): # 遍历新对象中的所有属性
# 如果新的key不在旧的class中,添加之
if k not in oldobj.__dict__:
setattr(oldobj, k, v)
_log("[A] %s : %s"%(k, _S(v)), depth)
continue
oldv = oldobj.__dict__[k]
# 如果key对象类型在新旧class间不同,那留用旧class的对象
if type(oldv) != type(v):
_log("[RD] %s : %s"%(k, _S(oldv)), depth)
continue
# 更新当前支持更新的对象
v_type = type(v)
handler = handlers.get(v_type)
if handler:
_log("[U] %s : %s"%(k, _S(v)), depth)
handler(oldv, v, depth + 1)
# 由于是直接改oldv的内容,所以不用再setattr了。
else:
_log("[RC] %s : %s : %s"%(k, type(oldv), _S(oldv)), depth)
# 调用约定的reload_class接口,处理类变量的替换逻辑
object_list = gc.get_referrers(oldobj)
for obj in object_list:
# 只有类型相同的才是类的实例对象
if obj.__class__.__name__ != oldobj.__name__:
continue
if hasattr(obj, "x_reload_class"):
obj.x_reload_class()
更新静态方法staticmethod
def _update_staticmethod(oldobj, newobj, depth):
# 一个staticmethod对象,它的 XXXX.__get__(object)便是那个function对象
oldfunc = oldobj.__get__(object)
newfunc = newobj.__get__(object)
update_function(oldfunc, newfunc, depth)
更新类方法classmethod
def _update_classmethod(oldobj, newobj, depth):
# 注意是对象的im_func
oldfunc = oldobj.__get__(object).im_func
newfunc = newobj.__get__(object).im_func
update_function(oldfunc, newfunc, depth)
修改内存中的配置文件
因为项目的配置文件中的变量属于全局变量。提供一个接口(此处安全问题暂时忽略),传递配置文件相关参数。在接口中修改相关全局变量。比如直接修改settings.py文件
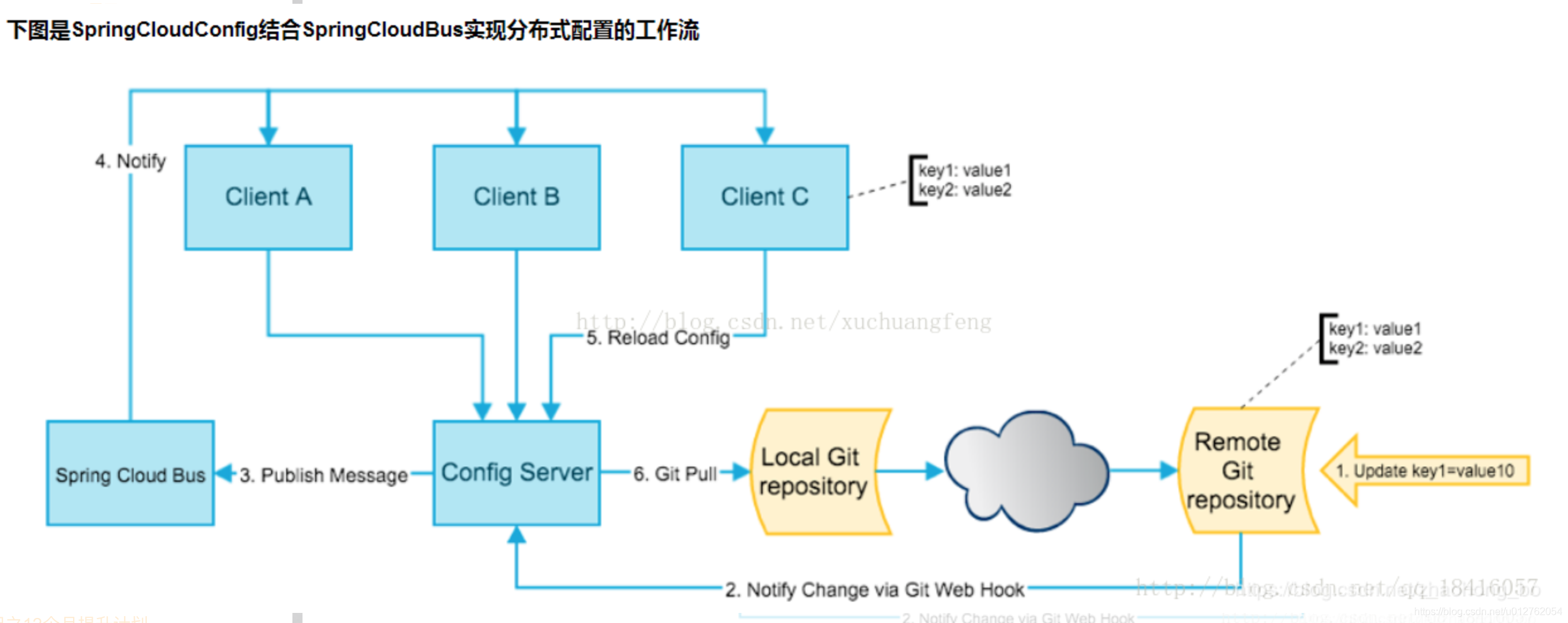
参照spring cloud config的方案
springCloudConfig分服务端和客户端,服务端负责将本地,git或者svn中存储的配置文件发布成REST风格的接口,客户端可以从服务端REST接口获取配置。为了客户端能主动感知到配置的变化,主动去获取新的配置,需要每个客户端通过POST方法触发各自的/refresh接口。而我们上面说的SpringCloudBus就发挥了其作用了
SpringCloudBus通过一个轻量级消息代理连接分布式系统的节点(有点像消息队列那种)。这可以用于广播状态更改(如配置更改)或其他管理指令。SpringCloudBus提供了通过post方法访问的endpoint/bus/refresh(spring boot 有很多监控的endpoint,比如/health),这个接口通常由git的钩子功能(监听触发)调用,用以通知各个SpringCloudConfig的客户端去服务端更新配置
完成了本地测试热更新成功后,就着手实现CS模式下的“发布订阅”消息通知功能,利用服务器对客户端推送一个更新指令,客户端就会自动更新模块。 而Redis自带“发布订阅”功能
-
在Redis服务端中,创建一个 update频道:SUBSCRIBE update
-
导入Redis模块后,链接到远程Redis数据库,订阅我们的update频道,再启动一个新的线程去监听update频道的消息。
- 因为如果直接在代码里面用单线程去监听消息的话,会造成线程阻塞在监听消息那里,导致界面刷新不出来。所以,我们只要导入threading库,再把监听消息做成一个函数,放到thread中去运行就可以了。由此避免线程阻塞问题。
-
在本地修改某个模块后,就到Redis服务的终端中,发布一个消息,reload
- 软件就会收到reload消息,对刚才被我修改后的模块进行热更新,即删掉源模块,再重新导入一次
-
若你在热更新前导入的模块生成了一个对象x,这个时候,你热更新了,然后又生成一个对象y。这个时候,你会发现,x指向的仍旧是旧的那个类,而y则指向了新的类。这个时候,可以通过修改x的__class__属性来对 x 的类进行强制修改,可以这样写:x.class == y.你的类
-
但是即使是这样写,你x里面的数据仍旧不会发生改变。我们只能更改代码的执行逻辑。
import threading import sys from PyQt5 import QtWidgets from updateServer.HotUpdate import myfunction import redis import random import importlib from updateServer.HotUpdate.HotFixSample import Ui_MainWindow class MainWindow(QtWidgets.QMainWindow, Ui_MainWindow): def __init__(self, parent=None): super(MainWindow, self).__init__(parent) self.setupUi(self) self.fun = importlib.import_module("myfunction") self.pushButton.clicked.connect(self.runFunction) # 点击后运行功能 self.pushButton_2.clicked.connect(self.hotfix) # 点击后热更新 # 连接redis self.ip = "47.xxx.xxx.xx" self.redisport = 2017 self.redis_manager = redis.StrictRedis(self.ip, port=self.redisport) self.textBrowser.append(str(sys.modules)) #print(sys.modules) # 关联订阅频道 self.tunnel = self.redis_manager.pubsub() self.tunnel.subscribe(["update"]) # 启动一个新的线程去监听update频道的消息 self.threads = [] self.t1 = threading.Thread(target=self.autoReload, ) self.threads.append(self.t1) self.threads[0].setDaemon(True) # 当主线程退出时,后台线程随即退出 self.threads[0].start() def autoReload(self): ''' 监听Redis服务端发布的消息 ''' for k in self.tunnel.listen(): if k.get('data') == b'reload': self.hotfix() def runFunction(self): version = self.fun.AllFunction().version self.textBrowser.append("功能运行,当前版本为:" + version) for i in range(4): x = random.randint(-454, 994) y = random.randint(-245, 437) self.textBrowser.append(str(x) + "\tfunction version {}\t".format(version) + str(y) + " = " + str( self.fun.AllFunction().second(x, y))) # self.textBrowser.append(self.fun.AllFunction().first()) def hotfix(self): # 下载新的myfunction模块的功能 ''' 1.遍历项目的文件 2.根据本地文件的MD5值和服务器上文件上的MD5值对比判断文件是否发生了变化,并将变化的文件的模块记录到一个列表中 3.发生变化则对文件进行下载更新 4.遍历列表,根据列表中的模块进行reload ''' # 将旧的myfunction模块加载记录从sys.modules中删除 del sys.modules["myfunction"] # 加载新的myfunction模块 self.fun = importlib.import_module('myfunction') self.textBrowser.append("热更新完毕") if __name__ == "__main__": app = QtWidgets.QApplication(sys.argv) mainWindow = MainWindow() mainWindow.show() sys.exit(app.exec_())import hashlib import os import json updateList={} def Getfile_md5(filename): ''' 根据文件名获取文件的MD5值 ''' if not os.path.isfile(filename): return myHash = hashlib.md5() f = open(filename, 'rb') while True: b = f.read(8096) if not b: break myHash.update(b) f.close() return myHash.hexdigest() def findFile(path): ''' 查找服务器文件 ''' fsinfo = os.listdir(path) for fn in fsinfo: temp_path = os.path.join(path, fn) if not os.path.isdir(temp_path): print('文件路径: {}' .format(temp_path)) fm=Getfile_md5(temp_path) print(fn) updateList[fn]=fm else: findFile(temp_path) # def generate(): directory = os.getcwd() findFile(directory) file_md5_list=json.dumps(updateList) print(file_md5_list) d = {} import pickle with open("listFile", "rb") as f: d = pickle.load(f) print(d)
总结
热更新实现流程:
- 建立Redis服务,搭建订阅发布频道
- 建立一个新的线程(看门狗),专门监听Redis服务是否有更新的消息发布
- 监听到发布消息,则执行更新下载操作
- 用字典记录本地文件的路径和文件的MD5值
- 用字典记录服务器文件的路径和文件的MD5值
- 若服务器文件与本地文件的MD5值不同则将服务器文件内容替换本地文件
- 若服务器文件不存在,而本地文件存在,则删除本地文件
- 若服务器上文件存在,而本地文件不存在,则在本地新增文件
- 在sys.module中删除旧模块,reload新模块

 浙公网安备 33010602011771号
浙公网安备 33010602011771号