Redis6 新特性
ACL安全策略
ACL(access control list): 访问控制列表,可以设置多个用户,并且给每个用户单独设置命令权限和数据权限
default用户和使用requirepass的方式给default用户设置密码,默认情况下default用户拥有Redis最大权限,我们使用redis-cli连接时如果没有指定用户名,用户也是默认default
| 命令 | 描述 |
|---|---|
| ACL HELP | 查看ACL 的help文档 |
| ACL LIST | 查看当前活动的ACL |
| ACL USERS | 返回所有用户名 |
| ACL WHOAMI | 返回当前用户名 |
| ACL CAT | 查看命令类别 |
| ACL SETUSER |
创建或修改用户属性 |
| ACL GETUSER |
查看用户的ACL权限 |
| ACL DELUSER | 删除指定的用户 |
| ACL SAVE | 当前服务器中的ACL权限持久化到aclfile中 |
| ACL LOAD | 将aclfile中的权限加载至redis服务中,使其立刻生效 |
| ACL GENPASS | 随机返回sha256密码,我们可以直接使用该密文配置ACL密码 |
| ACL LOG | 查看ACL安全日志 |
| AUTH |
切换用户 |
规则
启用和禁用用户
- on:启用用户,可以以该用户身份进行认证。
- off:禁用用户,不再可以使用此用户进行身份验证,但是已经通过身份验证的连接仍然可以使用。
允许和禁止调用命令
- +
:将命令添加到用户可以调用的命令列表中。 - -
:将命令从用户可以调用的命令列表中移除。 - +@
:允许用户调用 类别中的所有命令,有效类别为@admin,@set,@sortedset等,可调用ACL CAT命令查看完整列表。特殊类别@all表示所有命令,包括当前和未来版本中存在的所有命令。 - -@
:禁止用户调用 类别中的所有命令。 - +
|subcommand:允许使用已禁用命令的特定子命令。 - allcommands:+@all的别名。包括当前存在的命令以及将来通过模块加载的所有命令。
- nocommands:-@all的别名,禁止调用所有命令。
允许或禁止访问某些Key
- <pattern>:添加可以在命令中提及的键模式。例如和 allkeys 允许所有键。
- resetkeys:使用当前模式覆盖所有允许的模式。如: ~foo:* ~bar:* resetkeys ~objects:* ,客户端只能访问匹配 object:* 模式的 KEY。
为用户配置有效密码
:将此密码添加到用户的有效密码列表中。例如,>mypass将“mypass”添加到有效密码列表中。该命令会清除用户的nopass标记。每个用户可以有任意数量的有效密码。 - <
:从有效密码列表中删除此密码。若该用户的有效密码列表中没有此密码则会返回错误信息。 -
:将此SHA-256哈希值添加到用户的有效密码列表中。该哈希值将与为ACL用户输入的密码的哈希值进行比较。允许用户将哈希存储在users.acl文件中,而不是存储明文密码。仅接受SHA-256哈希值,因为密码哈希必须为64个字符且小写的十六进制字符。 - !
:从有效密码列表中删除该哈希值。当不知道哈希值对应的明文是什么时很有用。 - nopass:移除该用户已设置的所有密码,并将该用户标记为nopass无密码状态:任何密码都可以登录。resetpass命令可以清除nopass这种状态。
- resetpass:清空该用户的所有密码列表。而且移除nopass状态。resetpass之后用户没有关联的密码同时也无法使用无密码登录,因此resetpass之后必须添加密码或改为nopass状态才能正常登录。
- reset:重置用户状态为初始状态。执行以下操作resetpass,resetkeys,off,-@all
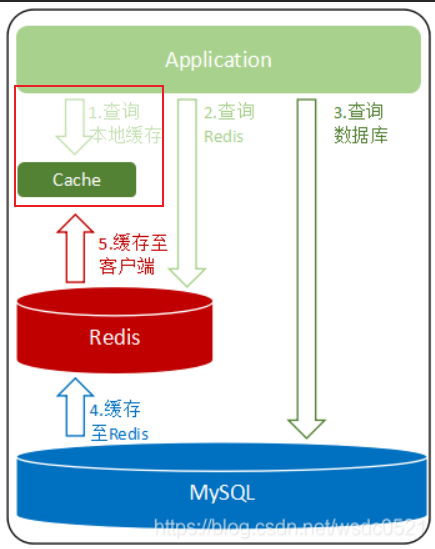
客户端缓存(Tracking)
一种用于创建高性能服务的技术:数据缓存在客户端本地的内存中,问数据时直接从本机内存中读取,而无需连接数据库端,减少了网络IO,提升了应用程序的响应速度,同时也减少了数据库端的压力
如下图,有客户端缓存和无客户端缓存的对比
| 无客户端缓存 | 有客户端缓存 |
|---|---|
 |
 |
优点:
- 降低了客户端的数据延迟,提升客户端的响应速度;
- 数据库端接收的查询减少,降低了数据库端的压力,因此在相同的数据集下可以使用更少的节点提供服务
RESP3
REdis Serialization Protocol,是 Redis 服务端与客户端之间通信的协议。在Redis6之前的版本,使用的是RESP2协议,数据都是以字符串数组的形式返回给客户端,不管是 list 还是 sorted set。因此客户端需要自行去根据类型进行解析,这样会增加了客户端实现的复杂性。
客户端缓存在基于RESP3才能有更好的实现,可以在同一个连接中运行数据的查询和接收失效消息,并且根据数据类型有更友好的显示。而目前在RESP2上实现的客户端缓存,需要两个客户端连接以转发重定向的形式实现
使用HELLO命令在RESP2和RESP3协议之间进行切换:
#使用RESP2协议
HELLO 2
#使用RESP3协议
HELLO 3
实现方式
打开客户端缓存
#开启RESP3协议
HELLO 3
#开启tracking 客户端缓存
client tracking on
#关闭tracking 客户端缓存
client tracking off
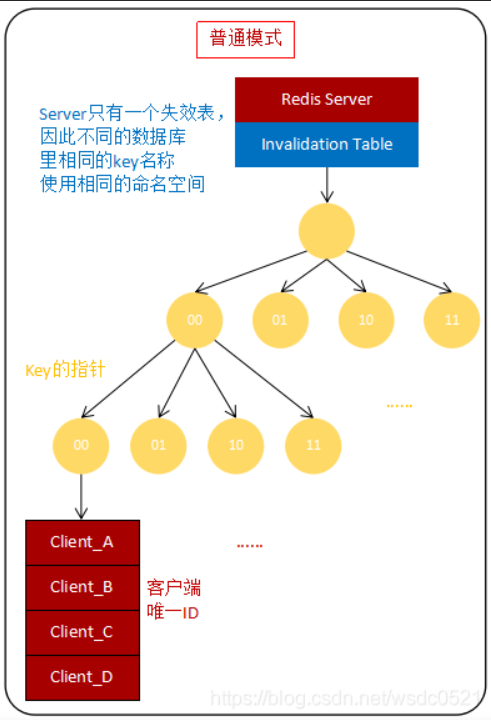
默认模式
原理
服务器端会记录访问key的客户端列表并维护一个表,这个表被称为失效表(Invalidation Table),如果插入一个新的key,服务器端会给客户端发送失效信息并从客户端踢除该key,避免提供过时数据。
- 只会记录key的指针和各客户端ID(每个Redis客户端都有一个唯一ID)的映射关系,当发送完失效信息后,客户端剔除key,服务端从失效表中删除key的指针和客户端ID的映射关系。
- 在失效表中key的命名空间只有一个,即是说,在db0~db15中相同的key名,在失效表中会记录在同一个命名空间内,即使客户端缓存的是db0内的key,如果db1内的同名key被更新,也会通知客户端剔除db0内的同名key。
客户端缓存的操作就是对key的内存地址进行操作:
- 当开启客户端缓存的客户端从Redis获取数据时,Redis服务端会调用 enableTracking 方法在上面的失效表中记录key和客户端ID的映射关系;
- 若key被修改,则Redis服务端会调用 trackingInvalidateKey 函数根据该key被缓存的客户端列表ID调用 sendTrackingMessage 函数向它们发送失效消息。(发送失效消息前会检查客户端的Client_Tracking和NOLOOP状态)
- 服务端发送完失效消息后会从失效表中将该key与客户端ID的映射关系删除;
- 由于客户端可能会在开启之后关闭了缓存功能,在失效表中删除key和该客户端ID之间的映射关系比较消耗性能,因此服务端采用懒删除的方式,只是将该客户端的Client_Tracking相关标志位删除;
应用
这里使用telnet测试客户端缓存,然后在另一个redis-cli对key做操作:
#使用telnet连接客户端
telnet admin 123456
#【telnet窗口】auth命令登录服务器(如果没有密码可以忽略)
auth default 123456
#【telnet窗口】开启RESP3
hello 3
#【telnet窗口】开启客户端缓存 tracking
client tracking on
#【telnet窗口】查询一个key 同时该key会被缓存
get sample
# ----------------------------------------------
#【另一个redis客户端】 修改/删除/过期/淘汰 该key
set sample new_values
#【telnet窗口】会收到key失效的消息如下:
get sample #客户端缓存key
$3
old_values
>2 #失效消息
$10
invalidate
*1
$4
new_values
#【telnet窗口】关闭客户端缓存 tracking,关闭后不会再收到key的失效消息
client tracking off
注意:
- 当开启了tracking后,客户端缓存的key如果在别处被修改为与原值一样,也会收到失效消息;
- 当客户端缓存失效后,该key再被修改时,客户端不会再收到消息,也就是再查询该key之后 才会在客户端缓存key的值;
- 当客户端缓存的key因过期策略或内存淘汰策略被驱逐时,服务端也会发送失效消息给开启了tracking的客户端
- 当开启了tracking的客户端获取的key不存在时,如果在另一个客户端新增/修改了该key,那个tracking的客户端也会收到失效消息
广播模式
原理
广播不会消耗服务端的内存,而是向各客户端发送更多的失效消息。广播模式与默认模式类似,不同的是广播模式下维护的是前缀表(存储客户端订阅的key前缀与客户端ID之间的映射关系)
主要行为:
- 客户端使用 BCAST 选项开启客户端缓存的广播模式,并使用 PREFIX 指定一个或多个前缀。如果不指定前缀则默认客户端接收所有的key的失效消息,如果指定则只会接收匹配该前缀的key的失效消息;
- 每次修改跟任意前缀匹配的键时,所有订阅该前缀的客户端都将收到失效消息;
- 服务端的CPU消耗与订阅的key前缀数量成正比,订阅的key前缀数量越多服务器端压力越大;
- 服务器可以为订阅特定前缀的客户端创建单个回复,并向所有的客户端发送相同的回复来进行优化,有助于降低CPU使用率

应用
#【另一个redis客户端】先设置几个key
set a 1
set b 1
set c 1
#【telnet窗口】开启RESP3
hello 3
#【telnet窗口】开启广播模式的客户端缓存tracking,只接受指定前缀'hcy'的key的失效信息
client tracking on bcast prefix hcy
#【另一个redis客户端】
set a 123
# 【telnet窗口】会收到key失效的消息如下:
get a
$1
1
>2 #失效消息
$10
invalidate
*1
$5
a
注意:
- 只要符合客户端设置的key前缀的key发生新增、修改、删除、过期、淘汰等动作,即使该key没有被该客户端缓存,也会收到key的失效消息
重定向模式
为了兼容RESP2协议,在Redis6中客户端缓存以重定向(Redirect)的方式实现,不再使用 RESP3 原生支持的PUSH消息,而是将消息通过 Pub/Sub 通知给另外一个客户端连接
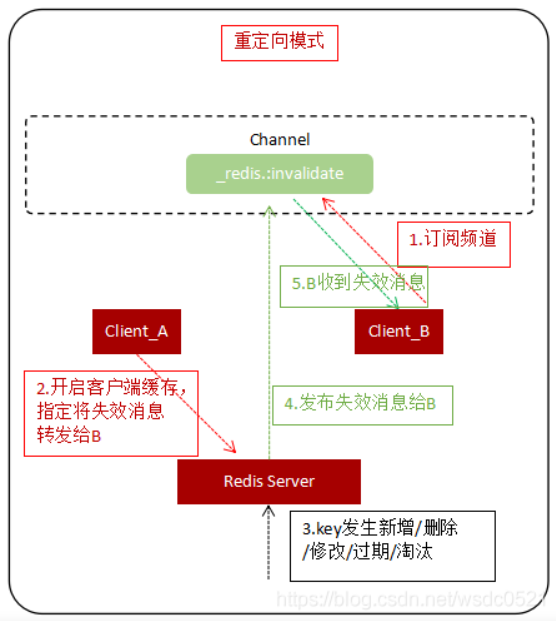
#查看客户端id
client id
#用于接收失效消息的客户端订阅频道
subscribe _redis_:invalidate
#客户端开启Tracking客户端缓存 并指定需要接收失效消息的客户端ID
client tracking on bcast redirect receive_client_id
常用选项
-
optin和optout
-
optin:只有执行client caching yes之后的第一个只读key才会被缓存
-
optout:只有执行client caching no之后的第一个只读key不会被缓存
-
# optin client tracking on optin client caching yes # optout client tacking on optout client caching no
-
-
noloop
- 开启noloop选项的客户端,如果在该客户端上修改它已经缓存的key,自己不会收到该key的失效消息
- 没开启noloop选项的客户端,如果在该客户端上修改它已经缓存的key,自己也会收到该key的失效消息
- client tracking on noloop
失效表上限
#查询最大缓存的数量
config get tracking-table-max-keys
#设置最大缓存数量为300
config set tracking-table-max-keys 300
集群代理(Redis Cluster Proxy)
集群代理与Redis在Github上是不同的项目
将集群抽象为单实例,客户端不需要知道集群中的具体节点个数和主从身份,通过代理访问集群,就像访问单机Redis一样。同时集群代理也能解决在集群模式下multiple操作的限制及跨slot操作限制
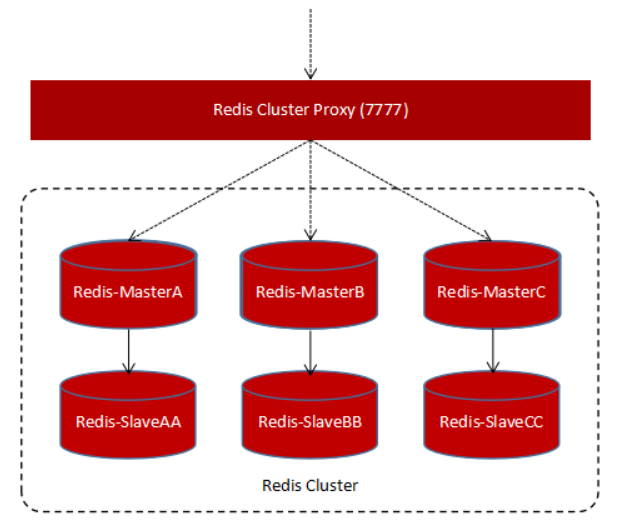
特点:
- 自动化路由:每个查询被自动路由到集群的正确节点;
- 多线程:多路复用通信模型,每个线程都有自己的集群连接;
- 顺序性:在多路复用上下文中,保证查询的执行和应答顺序;
- 无感知更新集群信息:当请求/重定向错误时会自动更新集群信息,客户端提交的查询会在集群信息更新完成后重新执行,对于客户端来说这一切是无感的,客户端不会收到请求/重定向的错误信息,而是直接收到查询的结果;
- 跨槽/节点查询:支持跨slot或node的mutiple操作key,如mget,mset,del等。但由于mset,del会破坏原子性,因此该配置默认关闭;
- ACL:支持连接开启了ACL的Redis集群;
- DBSIZE:对于没有指定节点的命令,将会合并所有的信息的总和并返回
安装
#git命令
git clone https://github.com/artix75/redis-cluster-proxy
#手动下载zip解压
unzip redis-cluster-proxy-unstable.zip
#------------------------------------------------
# 安装gcc9.1
yum -y install centos-release-scl
yum -y install devtoolset-9-gcc devtoolset-9-gcc-c++ devtoolset-9-binutils
# 开启gcc9.1
scl enable devtoolset-9 bash
# 查看版本
gcc -v
#scl命令启用只是临时的,新开的会话默认还是原gcc版本。
#如果要长期使用gcc 9.1的话执行下面的命令即可:
echo -e "\nsource /opt/rh/devtoolset-9/enable" >>/etc/profile
# -----------------------------------------------
#进入目录并编译
cd redis-cluster-proxy-unstable
make
#如果编译出错之后再编译可以先执行命令删除之前的编译文件,看到有Done说明编译成功
make distclean
# -----------------------------------------------
#安装Redis集群代理,可指定安装目录
make install PREFIX=/opt/app/redis-cluster-proxy
使用
配置启动
# 从源码中复制配置文件
cp ../redis-cluster-proxy-unstable/proxy.conf /opt/app/redis-cluster-proxy/
# -----------------------------------------------
# 修改配置文件vim /opt/app/redis-cluster-proxy/proxy.conf
#配置Redis集群,三主三从
cluster 127.0.0.1:6381 #主1
cluster 127.0.0.1:6382 #主2
cluster 127.0.0.1:6383 #主3
cluster 127.0.0.1:6391 #从1
cluster 127.0.0.1:6392 #从2
cluster 127.0.0.1:6393 #从3
#默认端口
port 7777
#线程数
threads 8
#后台运行
daemonize yes
#日志文件
logfile "/opt/app/redis-cluster-proxy/redis-cluster-proxy.log"
#允许跨slot查询
enable-cross-slot yes
#最大客户端连接数
max-clients 10000
#ACL用户密码(也可以在启动服务时指定)
auth-user myuser #ACL用户
auth mypassw #ACL密码
#连接池
connections-pool-size 10
connections-pool-min-size 10
connections-pool-spawn-every 50
connections-pool-spawn-rate 50
# -----------------------------------------------
#创建日志文件
touch /opt/app/redis-cluster-proxy/redis-cluster-proxy.log
#启动Redis集群代理服务
/opt/app/redis-cluster-proxy/bin/redis-cluster-proxy -c /opt/app/redis-cluster-proxy/proxy.conf
#连接Redis集群代理客户端
/opt/app/redis6/bin/redis-cli -p 7777
集群代理模式下不支持cluseter命令
跨节点slot操作
在集群代理模式下,可以跨slot甚至跨节点操作key,而在集群模式下链接客户端是做不到的。以下演示了如果在集群代理中使用mset和mget跨slot跨node设置或查询key,对于用户来说仿佛是在使用一个单实例的Redis
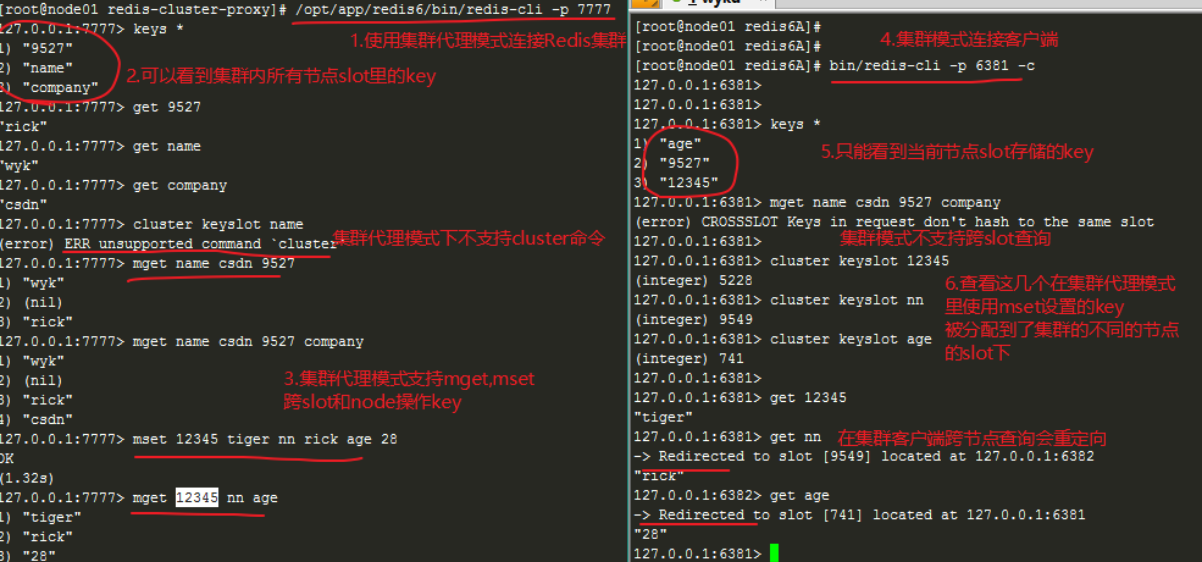
故障转移
手动将6381主节点宕机,6391从节点升级为主节点,集群恢复正常,但6381节点还没启动,此时集群代理无法使用,需要启动6381节点之后集群代理才能恢复使用
IO多线程
开启
# vim redis.conf
#开启IO多线程
io-threads-do-reads yes
#配置线程数量,如果设为1就是主线程模式。
io-threads 4
# 官方建议:至少4核的机器才开启IO多线程,并且除非真的遇到了性能瓶颈,否则不建议开启此配置 ,且配置的线程数少于机器总线程数,如果有4核建议开启2,3个线程,如果有8核建议开6线程。 线程并不是越多越好,多于8个线程意义不大。
源码流程
IO多线程只是在网络数据的读写上是多线程
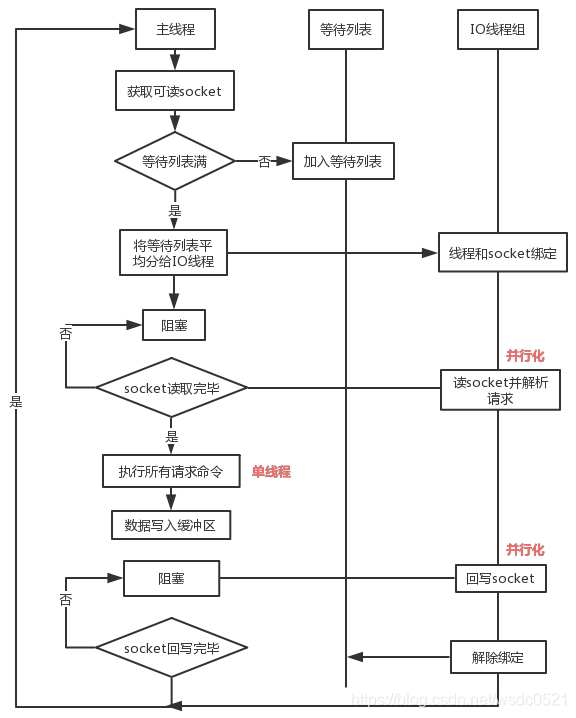
流程:
- 主线程获取 socket 放入等待列表
- 将 socket 分配给各个 IO 线程(并不会等列表满)
- 主线程阻塞等待 IO 线程读取 socket 完毕
- 主线程以单线程执行命令 (如果命令没有接收完毕,会等 IO 下次继续)
- 主线程阻塞等待 IO 线程将数据回写 socket 完毕(一次没写完,会等下次再写)
- 解除绑定,清空等待队列
注意:
- IO 线程要么同时在读 socket,要么同时在写,不会同时读或写;
- IO 线程只负责读写 socket 解析命令,不负责执行命令,由主线程串行执行命令;
- IO 线程数可配置,默认为 1;
- 上面的过程是完全无锁的,因为在 IO 线程处理的时主线程会等待全部的 IO 线程完成,所以不会出现 data race 的场景。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号