
mit6.828笔记 - lab4 Part A:多处理器支持和协同多任务处理
到目前为止,lab3是我们的内核能够按顺序完成env_create创建的进程。但是还不能做到多进程同时执行。lab4中我们将实现多进程的调度和进程间通信。
为了不迷失方向,我们来看一下与 lab4 合并后 kern/init.c : i386_init() 有什么变化:
void
i386_init(void)
{
// Initialize the console.
// Can't call cprintf until after we do this!
cons_init();
cprintf("6828 decimal is %o octal!\n", 6828);
// Lab 2 memory management initialization functions
mem_init();
// Lab 3 user environment initialization functions
env_init();
trap_init();
// Lab 4 multiprocessor initialization functions
mp_init();
lapic_init();
// Lab 4 multitasking initialization functions
pic_init();
// Acquire the big kernel lock before waking up APs
// Your code here:
// Starting non-boot CPUs
boot_aps();
#if defined(TEST)
// Don't touch -- used by grading script!
ENV_CREATE(TEST, ENV_TYPE_USER);
#else
// Touch all you want.
ENV_CREATE(user_primes, ENV_TYPE_USER);
#endif // TEST*
// Schedule and run the first user environment!
sched_yield();
}
可以看到,在 trap_init 和 ENV_CREATE 之间,多了 mp_init、lapic_init、pic_init、boot_aps。
最后不在是 调用 env_run 而是调用 shed_yield(),这个函数看起来是用于调度多个进程的。
PartA:多处理器支持和协同多任务处理
首先,我们了解一些关于多进程的概念:
多处理器的基本知识
要实现多进程,首先要支持多处理器。JOS使用"symmetric multiprocessing"(SMP)模式,,这是一种多处理器模式,在这种模式下,所有的 CPU 都可以平等地访问内存和 I/O 总线等系统资源。
在 SMP 中所有 CPU 的功能都是相同的,但在启动过程中,它们可以分为两种类型:
bootstrap processor(BSP)负责初始化系统和启动操作系统;application processors(AP)只有在操作系统启动和运行后才由 BSP 激活。哪个处理器是 BSP 由硬件和 BIOS 决定。
在 SMP 系统中,每个 CPU 都有一个Local APIC(LAPIC)单元。
LAPIC 单元负责在整个系统中提供中断。
LAPIC 还为其连接的 CPU 提供唯一标识符。
多处理器支持
关于lapic的代码,lab4已经在kern/lapic.c中提供好了,不需要我们自己写这么底层的代码。我们只需要知道:
cpunum()可以获取cpu编号,其原理是读取 lapic id。lapic_startap()可以唤醒其他ap,其原理是向目标AP发送 STARTUP 中断信号。lapic_init可以初始化ap,对lapic内置的定时器进行编程,使其每过一段时间产生时钟中断,这是后面实现轮转调度的基础。
CPU 以 MMIO 的方式访问 LAPIC ,MMIO 的物理地址位于 0xFE00_0000,距离4GB还有32MB
注意哦,这是物理地址,如果我们通过目前虚拟地址空间布局的顶部物理映射区来访问的话,那就是这个样子:
kernbase + 0xFE00_0000 = 0xF000_0000+0xFE00_0000
显然,这是个无法访问的虚拟地址,为了访问这个区域,JOS的虚拟空间布局设置了专门的 MMIO 区域,而 exercise1 的工作就是完成这部分的映射。
Exercise 1
练习 1. 在 kern/pmap.c 中实现 mmio_map_region。要了解其用法,请查看 kern/lapic.c 中 lapic_init 的开头。
// 在 MMIO 区域保留大小字节,并将 [pa,pa+size) 映射到该位置。
// 返回保留区域的基数。size 不一定是 PGSIZE 的倍数。
//
void *
mmio_map_region(physaddr_t pa, size_t size)
{
// 下一区域的起始位置。 最初,这是 MMIO 区域的起点。
// 因为它是静态的,所以在调用 mmio_map_region 时它的值会被保留
//(就像 boot_alloc 中的 nextfree 一样)。
static uintptr_t base = MMIOBASE;
// 从 base 开始预留大小字节的虚拟内存,
// 并将物理页 [pa,pa+size) 映射到虚拟地址 [base,base+size) 上。
// 由于这是设备内存,而不是普通的 DRAM,因此必须告诉 CPU,缓存访问该内存是不安全的。
// 幸运的是,页表提供了用于此目的的位,只需在创建映射时,
// 在 PTE_W 之外再加上 PTE_PCD|PTE_PWT(禁用缓存和写透)即可
//(如果您对这方面的更多细节感兴趣,请参阅 IA32 第 3A 卷第 10.5 节)。
//
// 务必将大小取整为 PGSIZE 的倍数,并处理该预留值是否会溢出 MMIOLIM(如果发生这种情况,只需panic即可)。
//
// Hint: The staff solution uses boot_map_region.
//
// Your code here:
// panic("mmio_map_region not implemented");
size = ROUNDUP(pa+size, PGSIZE);
pa = ROUNDDOWN(pa, PGSIZE);
size -= pa;
if (base+size >= MMIOLIM) panic("not enough memory");
boot_map_region(kern_pgdir, base, size, pa, PTE_PCD|PTE_PWT|PTE_W);
base += size;
return (void*) (base - size);
}
这个函数在 lapic_init 的开头被调用。
应用处理器引导程序
在启动 AP 之前,BSP 应首先收集有关多处理器系统的信息,如 CPU 总数、其 APIC ID 和 LAPIC 单元的 MMIO 地址。
kern/mpconfig.c 中的 mp_init() 函数通过读取 BIOS 内存区域中的 MP 配置表来获取这些信息。
kern/mpconfig.c 的所有代码都是最终都是服务于这个 mp_init(),他的输出就是完成了 kern/mpconfig.c 开头的几个变量的赋值:
// Initialized in mpconfig.c
extern struct CpuInfo cpus[NCPU];
extern int ncpu; // Total number of CPUs in the system
extern struct CpuInfo *bootcpu; // The boot-strap processor (BSP)
extern physaddr_t lapicaddr; // Physical MMIO address of the local APIC
kern/init.c:boot_aps() 负责启动所有AP。那么怎么启动呢?
回一下,我们最初的cpu(BSP)是怎么启动的,是bootloader按照boot/boot.S启动的。
那么AP也类似,不过,他的代码是kern/mpentry.S。
那么BSP要做的事情就是,将kern/mpentry.S代码拷贝到AP(实模式状态)能够寻址到的内存位置。
与bootloader,我们可以控制 AP 开始执行代码的位置;这里,我们将入口代码复制到 0x7000 (MPENTRY_PADDR)(但理论上,任何未使用的、页面对齐的、低于 640KB 的物理地址都可以。)
控制其他AP的入口地址的方法,就是对他们调用 lapic_startap ,该函数负责唤醒这些AP,并指定entry位置,具体不做深究了。专注主线。
lapic_startap会发送IPC:startup来启动其他AP
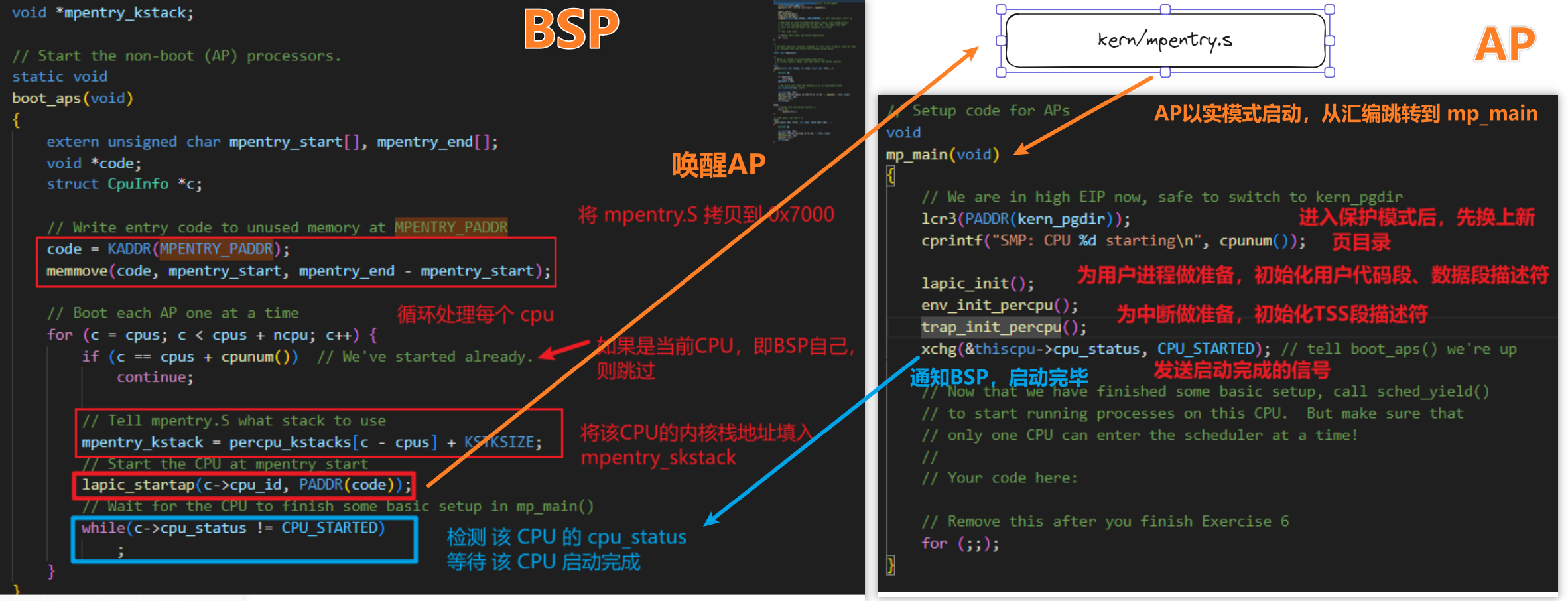
注意BSP 唤醒 AP 的那句, lapic_startap 的第二个参数,制定了AP的首个执行地址,即 0x7000
从 lab1 BSP的启动到目前为止的情况如下:
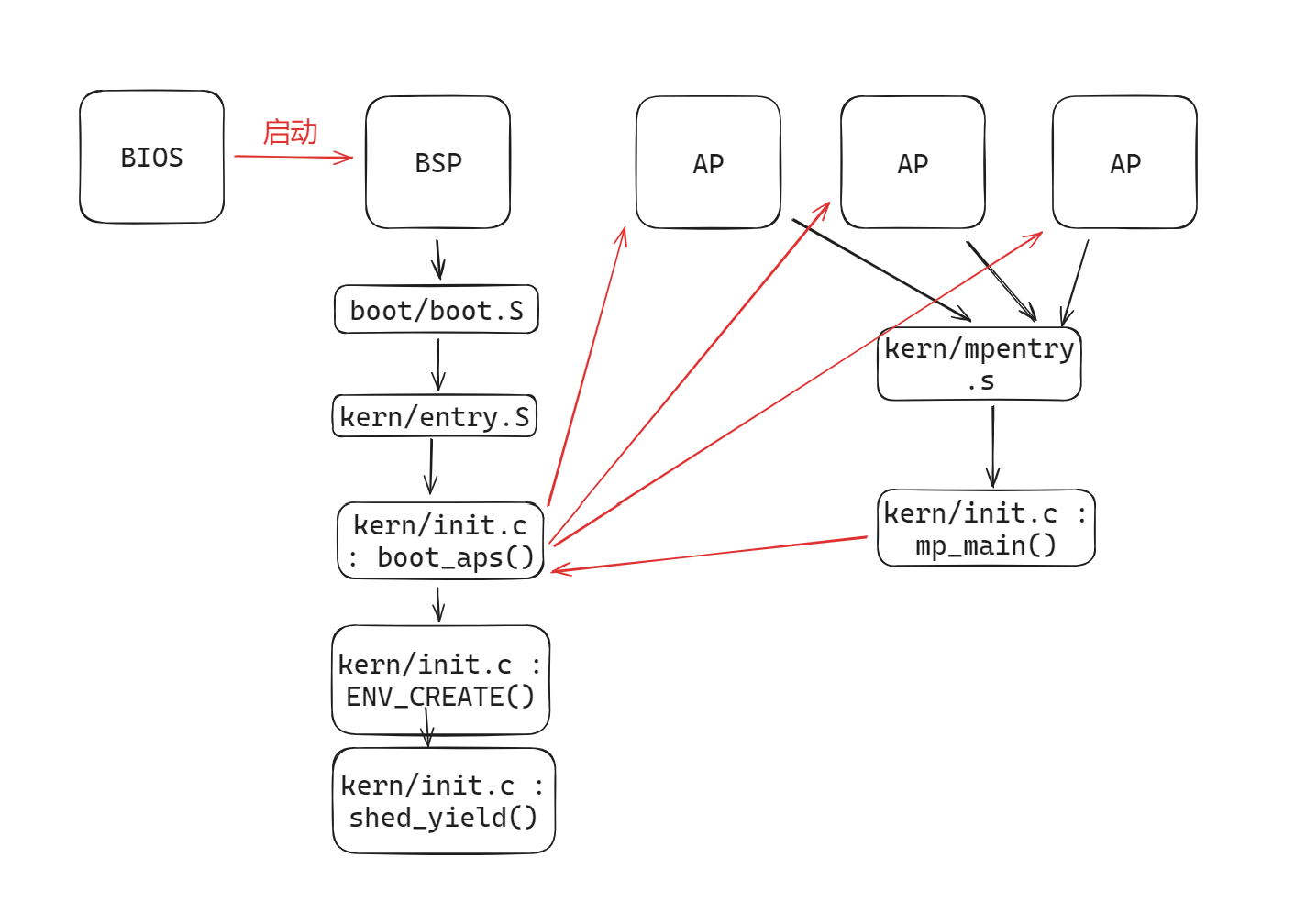
Exercise 2
- 阅读
kern/init.c中的boot_aps()和mp_main(),以及kern/mpentry.S中的汇编代码,确保你理解了 AP 引导过程中的控制流传输。 - 修改
kern/pmap.c中page_init()的实现,避免将位于MPENTRY_PADDR的页面添加到空闲列表中,这样我们就可以在该物理地址上安全地复制和运行 AP 引导代码。
代码应能通过更新后的 check_page_free_list() 测试(但可能无法通过更新后的 check_kern_pgdir() 测试,我们将尽快修复)。
void
page_init(void)
{
// LAB 4:
// Change your code to mark the physical page at MPENTRY_PADDR
// as in use
// The example code here marks all physical pages as free.
// However this is not truly the case. What memory is free?
// 1) Mark physical page 0 as in use.
// This way we preserve the real-mode IDT and BIOS structures
// in case we ever need them. (Currently we don't, but...)
// 2) The rest of base memory, [PGSIZE, npages_basemem * PGSIZE)
// is free.
// 3) Then comes the IO hole [IOPHYSMEM, EXTPHYSMEM), which must
// never be allocated.
// 4) Then extended memory [EXTPHYSMEM, ...).
// Some of it is in use, some is free. Where is the kernel
// in physical memory? Which pages are already in use for
// page tables and other data structures?
//
// Change the code to reflect this.
// NB: DO NOT actually touch the physical memory corresponding to
// free pages!
size_t i;
size_t io_hole_start_page = (size_t)IOPHYSMEM / PGSIZE;
size_t kernel_end_page = PADDR(boot_alloc(0)) / PGSIZE;
for (i = 0; i < npages; i++) {
// pages[i].pp_ref = 0;
// pages[i].pp_link = page_free_list;
// page_free_list = &pages[i];
if (i == 0) {
pages[i].pp_ref = 1;
pages[i].pp_link = NULL;
} else if (i >= io_hole_start_page && i < kernel_end_page) {
pages[i].pp_ref = 1;
pages[i].pp_link = NULL;
}else if(i == MPENTRY_PADDR / PGSIZE){
//为mpentry预留1页内存
pages[i].pp_ref = 1;
pages[i].pp_link = NULL;
} else {
pages[i].pp_ref = 0;
pages[i].pp_link = page_free_list;
page_free_list = &pages[i];
}
}
}
我们来看看手册中的问题:
尝试比较一下
kern/mpentry.S与boot/boot.S
思考这样一个问题:
kern/mpentry.S与内核中的其他内容一样,都是编译并链接到KERNBASE上运行的,那么宏MPBOOTPHYS的作用是什么?
为什么在kern/mpentry.S中需要宏MPBOOTPHYS而在boot/boot.S中不需要?
如果在kern/mpentry.S中省略它,会出现什么问题?
我们知道 BSP 启动的时候是以物理地址,0x0000_7C00为起点执行的,然后通过 kernel.ld 将 entry.S 编译出的代码链接到这个地址。
但是想想,0x0000_7C00 这个地址和 0x0000_7000 好像有点重合,如果将 mpentry_start (mpentry.S 中 入口点的标号) 链接到这的话,肯定是冲突的。
在vscode 中全局搜索 mpentry_start ,果然没有在链接脚本出现
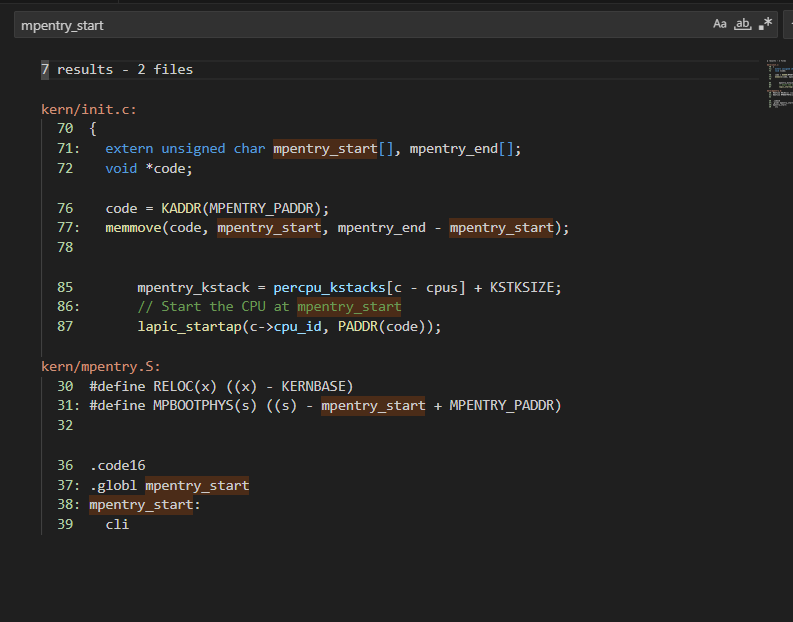
如果没有猜错,他大概位于内核的代码段,某个很高的虚拟地址上面,通过objdump -t 看看 mpentry_start 这个符号:

果然如此啊,这就意味着 mpentry.S 被编译链接后,其中的变量和标号都是虚拟地址,而且还很高。但是AP需要的是物理地址,所以需要
#define MPBOOTPHYS(s) ((s) - mpentry_start + MPENTRY_PADDR)
这么一个宏,用来将虚拟地址转化为物理地址。当然这都是为了编写代码方便,也可以通过链接脚本将 mpentry.S连接到某个不冲突的物理地址的low memory 区域。
然后在 lapic_startup 的时候指定 AP 从这个地址启动。
各 CPU 状态和初始化
通过之前对 boot_aps和mp_main()的学习,我们发现 AP 其实和 BSP 区别不大,只不过AP醒来的时候,内存布局都已经让BSP处理好了。但是,每个AP都需要自己的内存栈、为了在中断、权限转移时保存环境,需要自己的TSS记录自己的内存栈位置,这需要我们修改一些代码。
这就是接下来练习3、练习4要做的事情,不过在那之前,先来了解下 JOS 是如何记录CPU信息的:
JOS在 kern/cpu.h 中定义了 struct CpuInfo,用于抽象每个CPU。
struct CpuInfo {
uint8_t cpu_id; // Local APIC ID; index into cpus[] below
volatile unsigned cpu_status; // The status of the CPU
struct Env *cpu_env; // The currently-running environment.
struct Taskstate cpu_ts; // Used by x86 to find stack for interrupt
};
CPU的重要属性有:
- 内核栈,可以在 lib/memlayout.h 中看到各个CPU内核栈的分布
- TSS和TSS描述符,用于记录各个CPU的内核栈位置
- 环境指针,用于记录当前运行的环境
- 寄存器
Exercise 3
练习 3. 修改 mem_init_mp()(在 kern/pmap.c 中),
映射从 KSTACKTOP 开始的每个 CPU 堆栈,如 inc/memlayout.h 所示。
每个堆栈的大小是 KSTKSIZE 字节加上未映射的保护页 KSTKGAP 字节。
代码应通过 check_kern_pgdir() 中的新检查。
static void
mem_init_mp(void)
{
// Map per-CPU stacks starting at KSTACKTOP, for up to 'NCPU' CPUs.
//
// For CPU i, use the physical memory that 'percpu_kstacks[i]' refers
// to as its kernel stack. CPU i's kernel stack grows down from virtual
// address kstacktop_i = KSTACKTOP - i * (KSTKSIZE + KSTKGAP), and is
// divided into two pieces, just like the single stack you set up in
// mem_init:
// * [kstacktop_i - KSTKSIZE, kstacktop_i)
// -- backed by physical memory
// * [kstacktop_i - (KSTKSIZE + KSTKGAP), kstacktop_i - KSTKSIZE)
// -- not backed; so if the kernel overflows its stack,
// it will fault rather than overwrite another CPU's stack.
// Known as a "guard page".
// Permissions: kernel RW, user NONE
//
// LAB 4: Your code here:
for(int i = 0; i<NCPU;++i){
boot_map_region(kern_pgdir,
KSTACKTOP-(KSTKSIZE+KSTKGAP)*i - KSTKSIZE,
KSTKSIZE,
PADDR(percpu_kstacks[i]),
PTE_W);
}
}
注意,这个 percpu_kstacks 是在 mpconfig.c 中定义的:
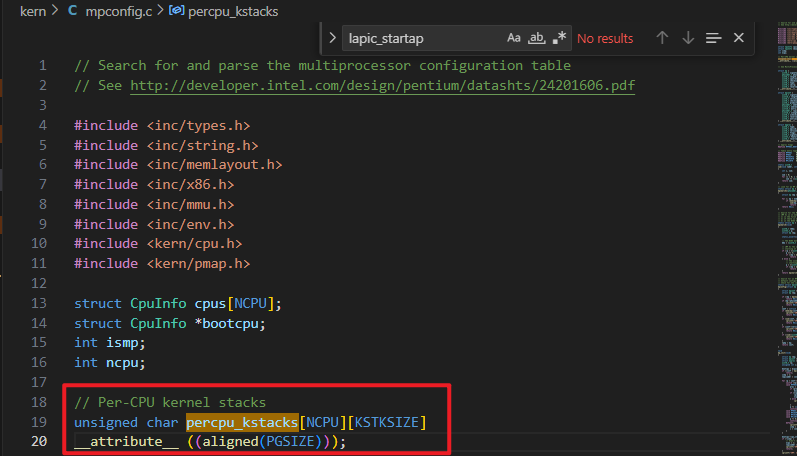
由于是个为初始化的全局变量,应该是位于kernel的 .bss 段

确实如此。
Exercise 4
练习 4. trap_init_percpu() (kern/trap.c) 中的代码初始化了 BSP 的 TSS 和 TSS 描述符。
它在实验 3 中正常工作,但在其他 CPU 上运行时却不正确。
修改代码,使其能在所有 CPU 上运行。(注意:新代码不应再使用全局 ts 变量)
void
trap_init_percpu(void)
{
// The example code here sets up the Task State Segment (TSS) and
// the TSS descriptor for CPU 0. But it is incorrect if we are
// running on other CPUs because each CPU has its own kernel stack.
// Fix the code so that it works for all CPUs.
//
// Hints:
// - The macro "thiscpu" always refers to the current CPU's
// struct CpuInfo;
// - The ID of the current CPU is given by cpunum() or
// thiscpu->cpu_id;
// - Use "thiscpu->cpu_ts" as the TSS for the current CPU,
// rather than the global "ts" variable;
// - Use gdt[(GD_TSS0 >> 3) + i] for CPU i's TSS descriptor;
// - You mapped the per-CPU kernel stacks in mem_init_mp()
// - Initialize cpu_ts.ts_iomb to prevent unauthorized environments
// from doing IO (0 is not the correct value!)
//
// ltr sets a 'busy' flag in the TSS selector, so if you
// accidentally load the same TSS on more than one CPU, you'll
// get a triple fault. If you set up an individual CPU's TSS
// wrong, you may not get a fault until you try to return from
// user space on that CPU.
//
// LAB 4: Your code here:
// Setup a TSS so that we get the right stack
// when we trap to the kernel.
int cpu_num = cpunum();
//在TSS中记录内核栈位置
thiscpu->cpu_ts.ts_esp0 = KSTACKTOP - cpu_num * (KSTKSIZE + KSTKGAP);
thiscpu->cpu_ts.ts_ss0 = GD_KD;
thiscpu->cpu_ts.ts_iomb = sizeof(struct Taskstate);
// Initialize the TSS slot of the gdt.
// 为每个CPU设置一个 TSS 段;
gdt[(GD_TSS0 >> 3) + cpu_num] = SEG16(STS_T32A, (uint32_t) (&thiscpu->cpu_ts),
sizeof(struct Taskstate) - 1, 0);
gdt[(GD_TSS0 >> 3) + cpu_num].sd_s = 0;
// Load the TSS selector (like other segment selectors, the
// bottom three bits are special; we leave them 0)
ltr(GD_TSS0+ (cpu_num << 3));
// Load the IDT
lidt(&idt_pd);
}
trap_init_percpu 会被各个AP执行,他们自己初始化自己的TSS描述符。在 mp_main 中被调用
锁
到现在为止,所有的CPU都启动完毕了,BSP顺着 i386_init 在完成 boot_aps 后差不多该 ENV_CREATE 了,各个 AP 也该顺着 mp_main 进入 shed_yield ,由进程调度分配用户进程执行了。
想一想,多个CPU同时执行,如果不做任何措施,肯定在读写数据时产生冲突。
如果各个CPU都在用户态还好,因为用户态下只能读写虚拟地址空间中的用户区域,而且各个进程的虚拟地址空间通过页表隔离,实际上操作的是不同的物理页。
但是内核态就不一样了,所有虚拟地址空间的内核区域的映射相同的,如果有多个cpu同时在进入内核势必产生冲突。
我们必须要处理竞争条件。最简单粗暴的办法就是使用"big kernel lock","big kernel lock"是一个全局锁,进程从用户态进入内核后获取该锁,退出内核释放该锁。这样就能保证只有一个CPU在执行内核代码,但缺点也很明显就是一个CPU在执行内核代码时,另一个CPU如果也想进入内核,就会处于等待的状态。
kern/spinlock.h 声明了大内核锁,即 kernel_lock,长这个样子
// Mutual exclusion lock.
struct spinlock {
unsigned locked; // Is the lock held?
#ifdef DEBUG_SPINLOCK
// For debugging:
char *name; // Name of lock.
struct CpuInfo *cpu; // The CPU holding the lock.
uintptr_t pcs[10]; // The call stack (an array of program counters)
// that locked the lock.
#endif
};
好家伙,本质上就是一个整形,它还提供了 lock_kernel() 和 unlock_kernel(),这是获取和释放锁的快捷方式。你应该在四个位置应用内核大锁:
- 在
i386_init()中,在 BSP 唤醒其他 CPU 之前获取锁。 - 在
mp_main()中,初始化 AP 后获取锁,然后调用 sched_yield()开始在该 AP 上运行环境。 - 在
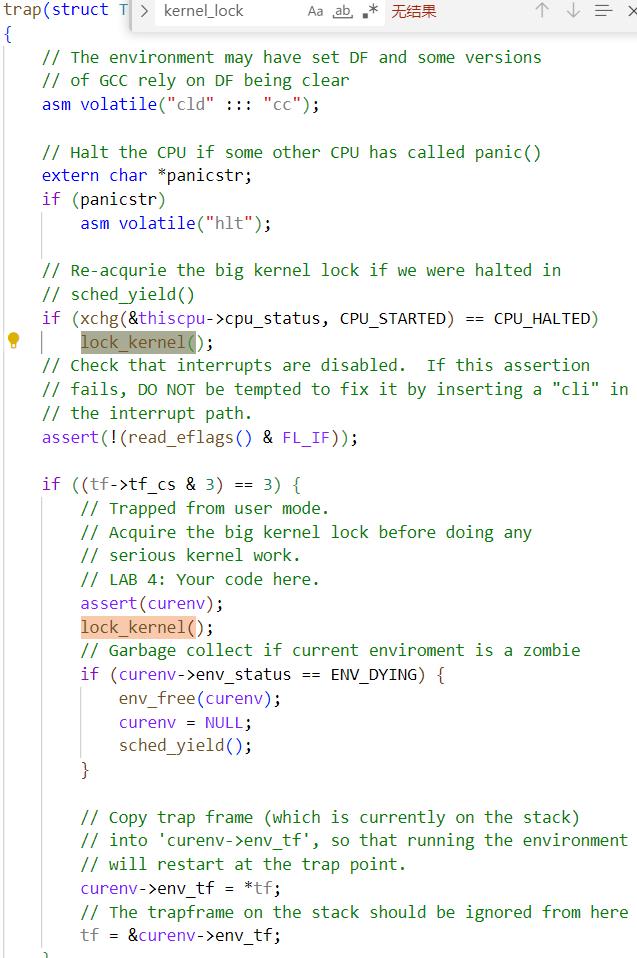
trap()中,从用户模式捕获陷阱时获取锁。要确定陷阱是在用户模式还是内核模式下发生,请检查 tf_cs 的低位。 - 在
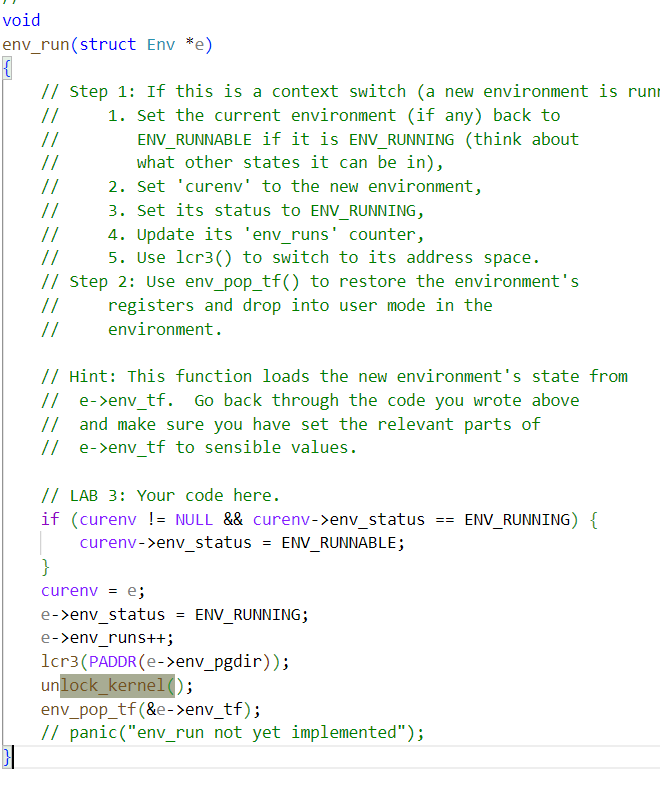
env_run()中,在切换到用户模式前释放锁。不要过早或过晚释放锁,否则会出现竞赛或死锁。
Exercise 5
练习 5. 在适当的位置调用 lock_kernel() 和 unlock_kernel(),应用上述的大内核锁。
i386_init()
// Lab 4 multitasking initialization functions
pic_init();
// Acquire the big kernel lock before waking up APs
// Your code here:
lock_kernel(); //在唤醒其他AP之前,需要获取大内核锁
// Starting non-boot CPUs
boot_aps();
mp_main()
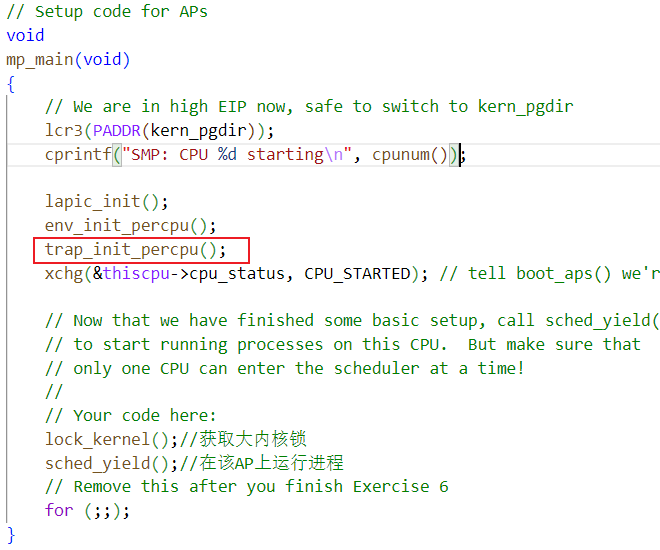
// Setup code for APs
void
mp_main(void)
{
// We are in high EIP now, safe to switch to kern_pgdir
lcr3(PADDR(kern_pgdir));
cprintf("SMP: CPU %d starting\n", cpunum());
lapic_init();
env_init_percpu();
trap_init_percpu();
xchg(&thiscpu->cpu_status, CPU_STARTED); // tell boot_aps() we're up
// Now that we have finished some basic setup, call sched_yield()
// to start running processes on this CPU. But make sure that
// only one CPU can enter the scheduler at a time!
//
// Your code here:
lock_kernel();//获取大内核锁
sched_yield();//在该AP上运行进程
// Remove this after you finish Exercise 6
for (;;);
}
trap()
env_run
循环调度 Round-Robin Scheduling
lab3的时候,我们在 kern/init.c -> i386_init()中通过 env_create 创建进程后,使用 env_run 运行一个进程,进程结束后,操作系统也就退出了。
这距离一个操作系统还是远远不够的,为了能够让操作系统运行多个进程,我们需要实现进程调度,给所用用户进程分配时间片,当某个进程得到时间片时,就可以运行;从CPU视角来看,则是有多个CPU以轮转的方式在多个进程之间交替运行。
这个功能由 kern/sched.c 的 sched_yield() 实现。它以循环方式依次搜索 envs[] 数组,从之前运行的环境之后开始(如果之前没有运行的环境,则从数组的开头开始),选择找到的第一个状态为 ENV_RUNNABLE(参见 inc/env.h)的环境,并调用 env_run() 跳转到该环境。
sched_yield() 决不能同时在两个 CPU 上运行同一个环境。struct env 的 status 字段来判断,这个进程是否正在某个CPU上进行
它可以判断出某个环境当前正在某个 CPU(可能是当前 CPU)上运行,因为该环境的状态将是 ENV_RUNNING。
sched_yield 需要注册成系统调用,用户环境可以调用 sched_yield 将控制交还给CPU,让CPU进行调度。
Exercise 6
练习 6. 如上所述,在
sched_yield()中实现循环调度。不要忘记修改
syscall()以调度sys_yield()。确保在
mp_main中调用sched_yield()。修改
kern/init.c来创建三个(或更多!)进程,这些进程都运行user/yield.c运行
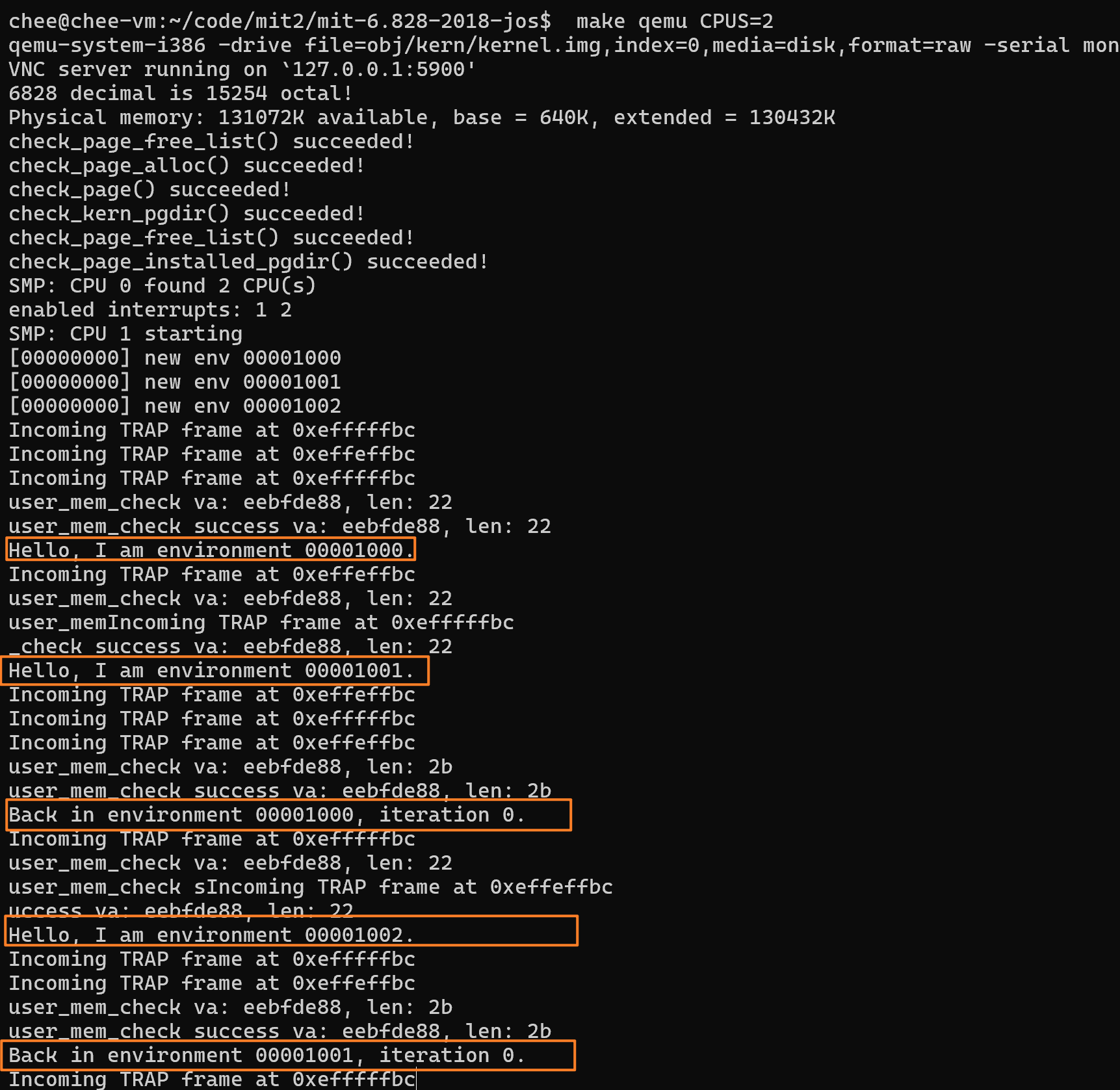
make qemu。你应该会看到环境在彼此间来回切换五次后终止,如下图所示。也使用多个 CPUS 进行测试:
make qemu CPUS=2....
你好,我是环境 00001000。
你好,我是环境 00001001。
你好,我是环境 00001002。
回到环境 00001000,迭代 0。
回到环境 00001001,迭代 0。
回到环境 00001002,迭代 0。
回到环境 00001000,迭代 1。
返回环境 00001001,迭代 1。
回到环境 00001002,迭代 1。
...
收益程序退出后,系统中将没有可运行的环境,调度程序应调用 JOS 内核监控器。如果上述任何情况没有发生,请在继续之前修改代码
void
sched_yield(void)
{
struct Env *idle;
// 实施简单的循环调度。
//
// 在 “envs ”中循环搜索 ENV_RUNNABLE 环境,从 CPU 最后运行的环境之后开始。
// 切换到找到的第一个此类环境。
//
// 如果没有可运行的环境,但该 CPU 先前运行的环境仍为 ENV_RUNNING,则可以选择该环境。
//
// 切勿选择当前正在其他 CPU 上运行的环境(env_status == ENV_RUNNING)。
// 如果没有可运行的环境,则直接跳转到下面的代码,停止 CPU 运行。
// LAB 4: Your code here.
int begin = 0;
if(curenv)//从当前的env的下一个env开始尝试
{
begin = ENVX(curenv->env_id) + 1;
}
for(int i = 0 ; i < NENV; ++i)//遍历整个 envs 数组寻找 ENV_RUNNABLE 的环境
{
int index = (begin + i) % NENV;
if(envs[index].env_status == ENV_RUNNABLE)
{ //如果有可运行的进程,就运行,陷入内核栈
env_run(&envs[index]);//env_run仍然是回归用户态的唯一出口
}
}
if(curenv && curenv->env_status == ENV_RUNNING)//如果之前的环境还没运行结束,即ENV_RUNNING,则继续执行之前的env
{
env_run(curenv);
}
//实在不行就 drop through to the halt
// sched_halt never returns
sched_halt();
}
在 kern/syscall.c : syscall 中补充对 sys_yield 的调用
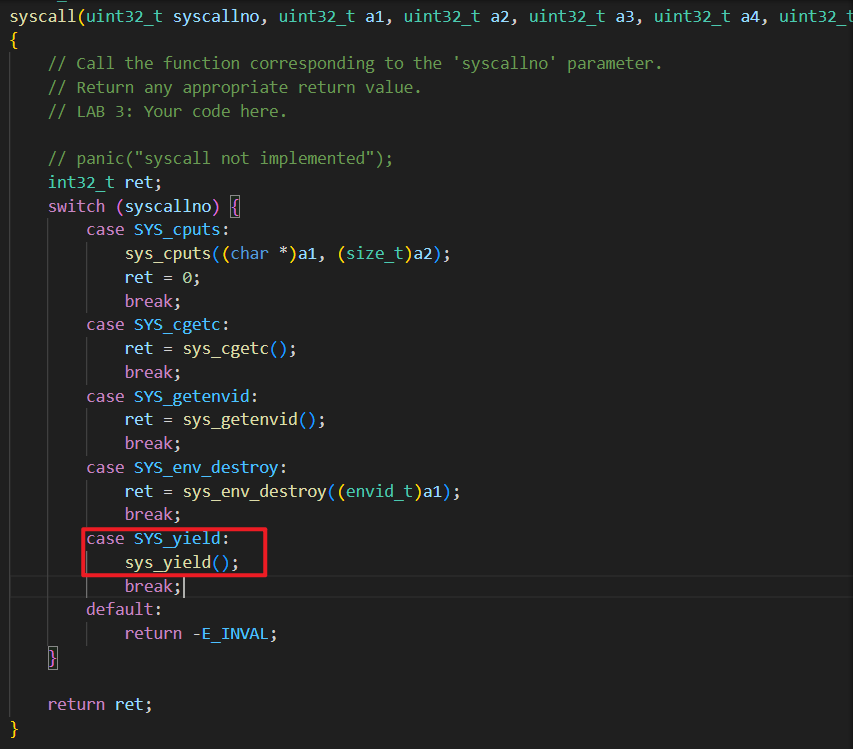
修改 mp_main, 在 初始化完毕后调用 sys_yield
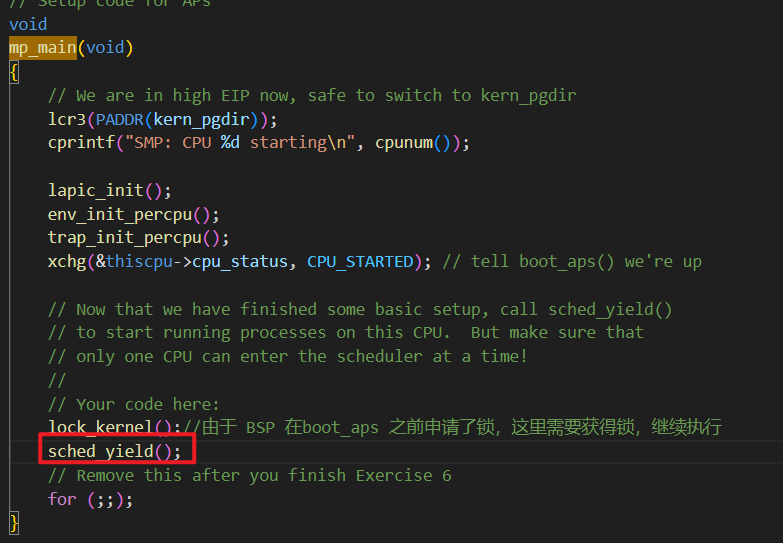
为了测试效果,修改 kern/init.c : i386_init , 创建多个用户进程 user/yield.c
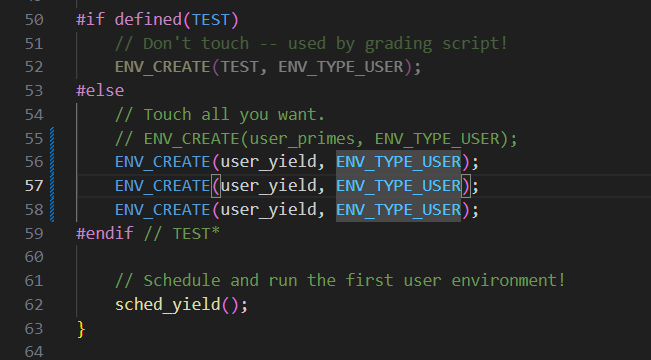
make qemu CPUS = 2 测试效果
创建环境的系统调用
到现在为止,内核现在可以让多个CPU在多个进程间切换。
但是,内核中究竟运行哪些进程还是硬编码在 i386_init 中。
为了能够让用户进程创建进程,我们要实现 fork。
关于 fork
Unix 提供fork()系统调用作为创建进程的基本方法。Unixfork()复制调用进程(父进程)的整个地址空间,创建一个新进程(子进程)。从用户空间观察到的两个进程之间的唯一区别是它们的进程 ID 和父进程 ID(由getpid和getppid返回)。在父进程中,fork()返回的是子进程的进程 ID,而在子进程中,fork()返回的是 0。默认情况下,每个进程都有自己的私有地址空间,两个进程对内存的修改对对方都不可见。
除了其他创建环境的方式外,JOS 还可以在用户空间完全使用类似 Unix 的fork()功能。
在这之前需要准备一些基础设施,即一些与fork相关的系统调用:
sys_exofork:
该系统调用创建的新环境几乎是一片空白:其地址空间的用户部分没有任何映射,也无法运行。在调用 sys_exofork 时,新环境的寄存器状态与父环境相同。
在父环境中,sys_exofork 将返回新创建环境的 envid_t(如果环境分配失败,则返回负错误代码)。
但在子环境中,它将返回 0(由于子环境一开始就被标记为不可运行,因此在父环境通过使用 .... 将子环境标记为可运行后,sys_exofork 才会在子环境中实际返回)。
sys_env_set_status:
将指定环境的状态设置为 ENV_RUNNABLE 或 ENV_NOT_RUNNABLE。
当新环境的地址空间和寄存器状态完全初始化后,该系统调用通常用于标记该环境已准备好运行。
sys_page_alloc:
分配物理内存页,并将其映射到给定环境地址空间中的给定虚拟地址上。
sys_page_map:
将一个页面映射(而不是页面内容!)从一个环境的地址空间复制到另一个环境的地址空间,同时保留内存共享安排,使新旧映射都指向同一个物理内存页面。
sys_page_unmap:
解除映射到给定环境中给定虚拟地址的页面。
对于上述所有接受环境 ID 的系统调用,JOS 内核支持 0 表示 "当前环境 "的约定。这一约定由 kern/env.c 中的 envid2env() 实现。
Exerceise 7
练习 7. 在 `kern/syscall.c` 中实现上述系统调用,并确保 `syscall()` 调用它们。
您将需要使用 `kern/pmap.c` 和 `kern/env.c` 中的各种函数,尤其是 `envid2env()`。
目前,无论何时调用 `envid2env()`,都要在 `checkperm` 参数中传递 1。
一定要检查任何无效的系统调用参数,在这种情况下返回 `-E_INVAL`。
使用 `user/dumbfork` 测试你的 JOS 内核,确保它能正常工作后再继续。
sys_exofork
// Allocate a new environment.
// Returns envid of new environment, or < 0 on error. Errors are:
// -E_NO_FREE_ENV if no free environment is available.
// -E_NO_MEM on memory exhaustion.
static envid_t
sys_exofork(void)
{
// 使用 kern/env.c 中的 env_alloc() 创建新环境。
// 除了将状态设置为 ENV_NOT_RUNNABLE,
// 以及从当前环境复制寄存器集之外,
// 它应该保持 env_alloc 创建时的状态,
// 但 sys_exofork 似乎会返回 0。
// LAB 4: Your code here.
// panic("sys_exofork not implemented");
struct Env *e;
int iret = env_alloc(&e, curenv->env_id); //创建新环境
if(iret<0) return iret; //返回错误
e->env_status = ENV_NOT_RUNNABLE; //设置状态
e->env_tf = curenv->env_tf; //寄存器值和父环境保持一致
e->env_tf.tf_regs.reg_eax = 0; //通过eax设置子环境的返回值
return e->env_id; //返回syscall,syscall也会通过eax返回父环境
}
sys_env_set_status
// 将 envid 的 env_status 设置为 status,
// 即 ENV_RUNNABLE 或 ENV_NOT_RUNNABLE。
//
// Returns 0 on success, < 0 on error. Errors are:
// -E_BAD_ENV if environment envid doesn't currently exist,
// or the caller doesn't have permission to change envid.
// -E_INVAL if status is not a valid status for an environment.
static int
sys_env_set_status(envid_t envid, int status)
{
// 提示:使用 kern/env.c 中的 “envid2env ”函数
// 将 envid 转换为 struct Env。
// 应将 envid2env 的第三个参数设置为 1,
// 它将检查当前环境是否有权限设置 envid 的状态。
// LAB 4: Your code here.
// panic("sys_env_set_status not implemented");
if(status != ENV_RUNNABLE && status != ENV_NOT_RUNNABLE){
return -E_INVAL;
}
struct Env *e;
if(envid2env(envid, &e, true) < 0){
return -E_BAD_ENV;
}
e->env_status = status;
return 0;
}
sys_page_alloc
// 分配一页内存,并将其映射到权限为
// 'perm' 位于'envid'的地址空间。
// 该页的内容设置为 0。
// 如果在'va'处已经映射了一个页面,该页面将作为副作用被取消映射。
//
// perm -- PTE_U | PTE_P 必须设置,PTE_AVAIL | PTE_W 可以设置,也可以不设置、
// 但不能设置其他位。 参见 inc/mmu.h 中的 PTE_SYSCALL。
//
// 成功时返回 0,错误时返回 <0。 错误是
// -E_BAD_ENV 如果环境 envid 当前不存在,或者调用者没有权限更改 envid。
// -E_INVAL 如果 va >= UTOP,或者 va 不是页面对齐的。
// -E_INVAL 如果 perm 不合适(见上文)。
// -E_NO_MEM 如果没有内存分配新页面,或分配任何必要的页表。
static int
sys_page_alloc(envid_t envid, void *va, int perm)
{
// 提示:该函数是 kern/pmap.c 中 page_alloc() 和 page_insert() 的包装器。
// 你编写的大部分新代码应该是检查参数是否正确。
// 如果 page_insert() 失败,请记住释放你分配的页
// 分配的页面!
// LAB 4: Your code here.
// panic("sys_page_alloc not implemented");
struct Env * e;
if(envid2env(envid, &e, 1)<0) //获取环境
{
return -E_BAD_ENV;
}
if((physaddr_t)(va)>=UTOP || PGOFF(va)) //检查va合规性
return -E_INVAL;
if((perm &PTE_U) == 0||(perm & PTE_P) == 0 || (perm & ~PTE_SYSCALL) == 1) //检查Perm合规性
{
return -E_INVAL;
}
struct PageInfo * pi = page_alloc(ALLOC_ZERO); //申请内存页
if(pi == NULL) return -E_INVAL; //检查是否还有内存页可供分配
if(page_insert(e->env_pgdir, pi, va, perm)<0) //插入页表,如果va已有页则覆盖(page_insert保障)
{
page_free(pi); //如果失败要释放已经申请的page
return -E_NO_MEM;
}
return 0;
}
sys_page_map
// 将 srcenvid 地址空间中位于'srcva'的内存页
// 映射到 dstenvid 地址空间中位于'dstva'的内存页,
// 并授予权限'perm'。
// Perm 与 sys_page_alloc 中的限制相同,
// 只是它也不能对只读页面授予写访问权限。
//
// 成功时返回 0,错误时返回 <0。 错误包括
// -E_BAD_ENV 如果 srcenvid 和/或 dstenvid 当前不存在,或者调用者没有权限更改其中一个。
// -E_INVAL 表示 srcva >= UTOP 或 srcva 未进行页面对齐,或 dstva >= UTOP 或 dstva 未进行页面对齐。
// -E_INVAL 表示 srcva 没有映射到 srcenvid 的地址空间。
// -E_INVAL 如果 perm 不合适(参见 sys_page_alloc)。
// -E_INVAL 如果(perm & PTE_W),但 srcva 在 srcenvid 的地址空间中是只读的。
// -E_NO_MEM 如果没有内存来分配任何必要的页表。
static int
sys_page_map(envid_t srcenvid, void *srcva,
envid_t dstenvid, void *dstva, int perm)
{
// 提示:该函数是 kern/pmap.c 中 page_lookup() 和
// page_insert() 的封装。
// 同样,您编写的大部分新代码应该是检查
// 参数的正确性。
// 使用 page_lookup() 的第三个参数来
// 检查页面的当前权限。
// LAB 4: Your code here.
// panic("sys_page_map not implemented");
struct Env * src_env;
if(envid2env(srcenvid, &src_env, 1)<0) //获取环境
return -E_BAD_ENV;
struct Env * dst_env;
if(envid2env(dstenvid, &dst_env, 1)<0) //获取环境
return -E_BAD_ENV;
//检查va合规性
if((physaddr_t)(srcva)>=UTOP || PGOFF(srcva)||(physaddr_t)(dstva)>=UTOP || PGOFF(dstva))
return -E_INVAL;
//检查Perm合规性
if((perm &PTE_U) == 0||(perm & PTE_P) == 0 || (perm & ~PTE_SYSCALL) == 1)
return -E_INVAL;
pte_t *pte;
struct PageInfo * pp = page_lookup(src_env->env_pgdir, srcva, &pte);
if(!pp) return -E_INVAL;
//如果srcva 在 srcenvid 只读,但是perm要求写,则返回错误
if((*pte&PTE_W) == 0 && (perm & PTE_W) == 1)
return -E_INVAL;
if(page_insert(dst_env->env_pgdir, pp, dstva, perm)<0)
return -E_INVAL;
return 0;
}
sys_page_unmap
// 在 “envid ”的地址空间中,解映射位于 “va ”的内存页。
// 如果没有映射到内存页,函数将自动成功。
//
// 成功时返回 0,错误时返回 <0。 错误是
// -E_BAD_ENV 如果环境 envid 当前不存在,或者调用者没有权限更改 envid。
// -E_INVAL 如果 va >= UTOP,或者 va 不是页面对齐的。
static int
sys_page_unmap(envid_t envid, void *va)
{
// Hint: This function is a wrapper around page_remove().
// LAB 4: Your code here.
// panic("sys_page_unmap not implemented");
struct Env * e ;
if(envid2env(envid, &e, 1)<0)
return -E_BAD_ENV;
if((physaddr_t)(va)>=UTOP || PGOFF(va)) //检查va合规性
return -E_INVAL;
page_remove(e->env_pgdir, va);
return 0;
}
补充syscall
完事之后一定记得在 kern/syscall.c : syscall 里补充上这几个 syscall:
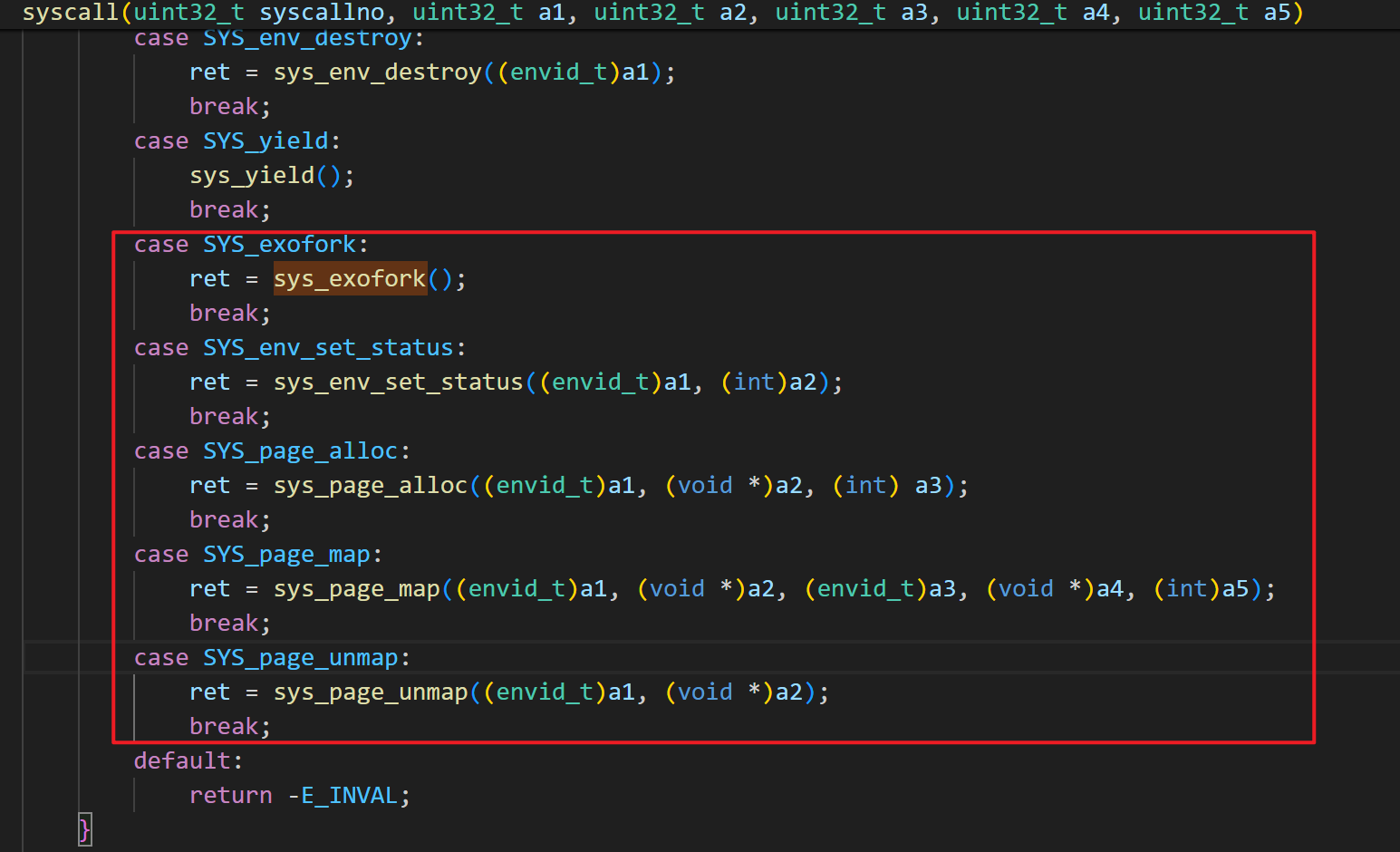
否则在 make run-dumbfork 就会在用户进程进行syscall的时候失败:
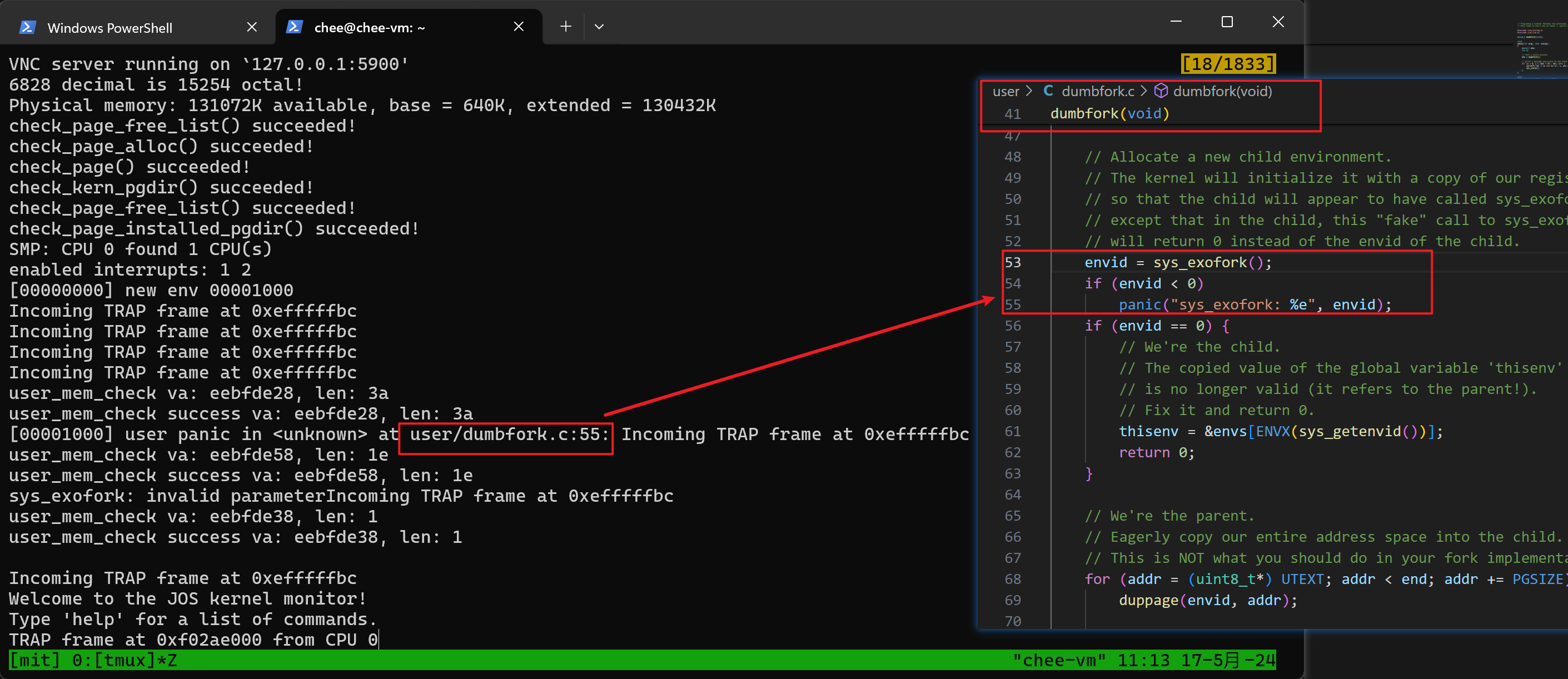
修改好之后就正常了


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律