机器学习笔记(1) -- 决策树
csv的内容为:
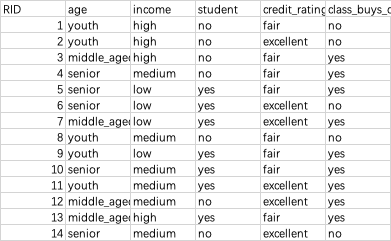
运行的代码为:
from sklearn.feature_extraction import DictVectorizer import csv from sklearn import tree,preprocessing from six import StringIO allElectronicsData = open(r'/Users/zhangsanfeng/Documents/jupyterNotebook/AllElectronics.csv') reader = csv.reader(allElectronicsData) headers = next(reader) # 获取表头 print(headers) featureList = [] labelList = [] for row in reader: labelList.append(row[len(row)-1]) # 取该行最后一个值 rowDict = {} for i in range(1,len(row)-1): # 从第二个值开始轮询该行,到倒数第二个值结束 rowDict[headers[i]] = row[i] # 用headers里面的值和该行的值组装成一个键值对 featureList.append(rowDict) # 将键值对拼接到列表里面 print(featureList) print(labelList) vec = DictVectorizer() dummyX = vec.fit_transform(featureList).toarray() # 将键值对中的值转换为坐标值 print("dummyX: " + str(dummyX)) # 打印转换后的结果 print(vec.get_feature_names()) # 打印每一项标识的含义 print("labelList: " + str(labelList)) # labelList尚未转换 lb = preprocessing.LabelBinarizer() dummyY = lb.fit_transform(labelList) # 转换labelList print("dummyY: " + str(dummyY)) # 使用决策树进行分类 clf = tree.DecisionTreeClassifier(criterion='entropy') clf = clf.fit(dummyX, dummyY) print("clf: " + str(clf)) # 可视化模型,将结果写入到文件 with open("/Users/zhangsanfeng/Documents/jupyterNotebook/allElectronicInformationGainOri.dot", 'w') as f: f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f) oneRowX = dummyX[0, :] print("oneRowX: " + str(oneRowX)) newRowX = oneRowX newRowX[0] = 1 newRowX[2] = 0 newRowX = newRowX.reshape(1, -1) # 这里需要将1维数组转换为2维数组,不然后面会报错 print("newRowX: " + str(newRowX)) predictedY = clf.predict(newRowX) # 验证测试结果 print("predictedY: " + str(predictedY))
输出结果为:
['RID', 'age', 'income', 'student', 'credit_rating', 'class_buys_computer']
[{'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'youth', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'medium', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}]
['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
dummyX: [[0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes']
labelList: ['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
dummyY: [[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
clf: DecisionTreeClassifier(criterion='entropy')
oneRowX: [0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
newRowX: [[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]]
predictedY: [1]
posted on 2022-12-01 17:06 torotoise512 阅读(44) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号