
ARIMA时间序列模型,确定合适的 p 和 q 值
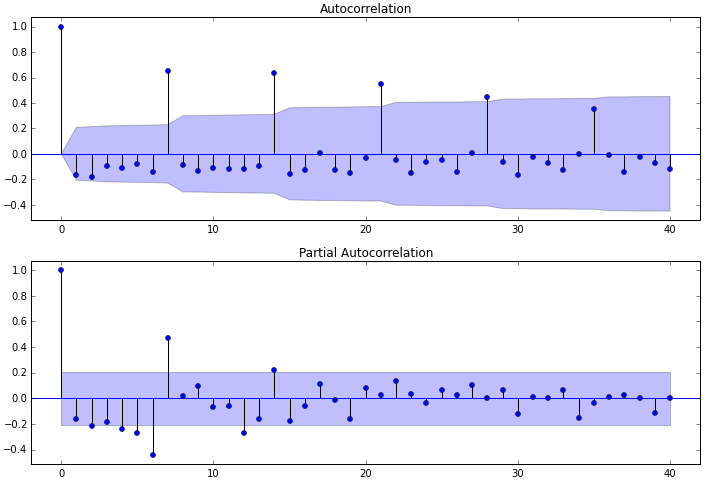
图3 自相关图、偏相关图
通过观察图3中的acf图和pacf图,可以得到:
-
自相关图显示滞后有三个阶超出了置信边界(第一条线代表起始点,不在滞后范围内);
-
偏相关图显示在滞后1至7阶(lags 1,2,…,7)时的偏自相关系数超出了置信边界,从lag 7之后偏自相关系数值缩小至0
则有以下模型可以供选择:
-
ARMA(0,1)模型:即自相关图在滞后1阶之后缩小为0,且偏自相关缩小至0,则是一个阶数q=1的移动平均模型;
-
ARMA(7,0)模型:即偏自相关图在滞后7阶之后缩小为0,且自相关缩小至0,则是一个阶层p=7的自回归模型;
-
ARMA(7,1)模型:即使得自相关和偏自相关都缩小至零。则是一个混合模型。
-
…其他供选择的模型。
补充:(1) 分析得到的自相关图和偏自相关图,确定用AR(p)模型还是MA(q)模型亦或是ARMA(p,q)模型依据为
表1 ARMA模型定阶的基本原则
(2) 若都拖尾,得到ARMA(p,q)模型,自相关图有几个在两倍标准差之外就能确定p,偏自相关图突出两倍标准差的确定q。
2.模型选择/参数选择
对于上述可供选择的模型,通常采用AIC或者SBC来判断得到的p和q参数值的好坏。我们知道:增加自由参数的数目提高了拟合的优良性,AIC鼓励数据拟合的优良性但是尽量避免出现过度拟合(Overfitting)的情况。所以优先考虑的模型应是AIC值最小的那一个。赤池信息准则的方法是寻找可以最好地解释数据但包含最少自由参数的模型。不仅仅包括AIC准则,目前选择模型常用如下准则:
AIC=-2 ln(L) + 2 k 中文名字:赤池信息量 akaike information criterion
BIC=-2 ln(L) + ln(n)*k 中文名字:贝叶斯信息量 bayesian information criterion
HQ=-2 ln(L) + ln(ln(n))*k hannan-quinn criterion
SBC=-2*ln(模型中的极大似然函数值)+ln(n)(模型中的未知参数的个数)
SBC是对AIC的修正,并且这四个指标越小则表示模型参数越好。构造这些统计量所遵循的统计思想是一致的,就是在考虑拟合残差的同时,依自变量个数施加“惩罚”。但要注意的是,这些准则不能说明某一个模型的精确度,也即是说,对于三个模型A,B,C,我们能够判断出C模型是最好的,但不能保证C模型能够很好地刻画数据,因为有可能三个模型都是糟糕的。
在本文中ARMA(7,0)的aic,bic,hqic均最小,因此是最佳模型。
本文作者:torrentgz
本文链接:https://www.cnblogs.com/torrentgz/p/16640718.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步