[转贴】如何将HTML标记去除,保留有用的文本
Text.Css里定义了一个用于文本处理的类,它只有一个静态方法TruncateText(string FullText,int numberofCharacters)
源代码如下:
 public static string TruncateText(string fullText, int numberOfCharacters)
public static string TruncateText(string fullText, int numberOfCharacters) {
{
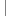 string text; if (fullText.Length > numberOfCharacters)
string text; if (fullText.Length > numberOfCharacters) {
{ int spacePos = fullText.IndexOf(" ", numberOfCharacters); if (spacePos > -1) { text = fullText.Substring(0, spacePos) + "
int spacePos = fullText.IndexOf(" ", numberOfCharacters); if (spacePos > -1) { text = fullText.Substring(0, spacePos) + " ";
"; } else { text = fullText; } } else { text = fullText; } Regex regexStripHTML = new Regex("<[^>]+>",RegexOptions.IgnoreCase|RegexOptions.Compiled); text = regexStripHTML.Replace(text, " "); return text;
} else { text = fullText; } } else { text = fullText; } Regex regexStripHTML = new Regex("<[^>]+>",RegexOptions.IgnoreCase|RegexOptions.Compiled); text = regexStripHTML.Replace(text, " "); return text; }
}1.先判断长度是否大于要保留的字符个数,不大于,则执行第三步
2.如果要处理的字符串长度大于要保留的字符数,从要保留的字符数索引位置开始,查找下一个空格位,然后取出从第一个字符到这个空格位的字符
3.使用正则表达式将字符串中的HTML标记剔除掉
这里有两个小小的技巧:
第一个 int spacepost=fulltext.indexOf(" ",numberOfCharacters)
这 就取出了从某位置往后的第一个空格,这样做的目的是为了断词,例如,要取得25个字符,但是从第23个字符开始出现了一个单词"programe",现在 的问题是,如果你硬取前25个,则会拆掉programe这个词,这里的方法很灵活,把位置延缓到单词的结尾,这样就取得完整些
第二个就是正则表达式"<[^>]+>"这个表达式代表了所有标记,中间的^>意思是除了>以外的所有字符,而且后面的+就限制了<>间必定有一个字符,经过正则表达式的替换,就把取出的字符串中的HTML标记再次剔除了
上面的方法是不错,但是,我觉得不够完美,对于一般性的非段落带格式的HTML文本,他可以处理的很好,因为HTML标记不见了,等于是去除带格式文本的格式,但是,如果是一段带有文本以外标记(如IMG,Button)的字符串,那取出的结果就不尽人意了
这种场景用的非常多,相信许多开发新闻系统的朋友都遇到过,因为我们需要生成新闻的摘要内容
不过,我所建议的方法是,对于摘要性质的内容,最灵活也是最具有扩展性的方法是增加一个摘要栏目和字段,让采编人员可以自由的来录入摘要内容,这样的好处是两方面:一是,摘要内容更准确,二是摘要内容的字数更容易控制,更灵活)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号