
Deep learning:四十三(用Hessian Free方法训练Deep Network)
目前,深度网络(Deep Nets)权值训练的主流方法还是梯度下降法(结合BP算法),当然在此之前可以用无监督的方法(比如说RBM,Autoencoder)来预训练参数的权值,而梯度下降法应用在深度网络中的一个缺点是权值的迭代变化值会很小,很容易收敛到的局部最优点;另一个缺点是梯度下降法不能很好的处理有病态的曲率(比如Rosenbrock函数)的误差函数。而本文中所介绍的Hessian Free方法(以下简称HF)可以不用预训练网络的权值,效果也还不错,且其适用范围更广(可以用于RNN等网络的学习),同时克服了上面梯度下降法的那2个缺点。HF的主要思想类似于牛顿迭代法,只是并没有显示的去计算误差曲面函数某点的Hessian矩阵H,而是通过某种技巧直接算出H和任意向量v的乘积Hv(该矩阵-向量的乘积形式在后面的优化过程中需要用到),因此叫做”Hessian Free”。本文主要是读完Martens的论文Deep learning via Hessian-free optimization记下的一些笔记(具体内容请参考论文部分)。
Hessian Free方法其实在多年前就已经被使用,但为什么Martens论文又重提这个方法呢?其实它们的不同在于H矩阵”free”的方式不同,因为隐式计算H的方法可以有很多种,而算法的名字都可以叫做HF,因此不能简单的认为Martens文章中在Deep Learning中的HF方法就是很久以前存在的方法了(如果真是如此,Deep Learning在N年前就火了!),只能说明它们的思想类似。将HF思想应用于DL网络时,需要用到各种技巧,而数学优化本身就是各种技巧、近似的组合。Matrens主要使用2个大思想+5个小技巧(论文给出的大概是5个,但是其code里面还有不少技巧论文中没有提到)来完成DL网络的训练。
idea 1:利用某种方法计算Hv的值(v任意),比如说常见的对误差导函数用有限差分法来高精度近似计算Hv(见下面公式),这比以前只是用一个对角矩阵近似Hessian矩阵保留下来的信息要多很多。通过计算隐式计算Hv,可以避免直接求H的逆,一是因为H太大,二是H的逆有可能根本不存在。
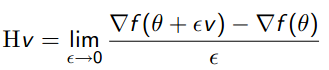
idea 2:用下面二次项公式来近似得到θ值附近的函数值。且最佳搜索方向p由CG迭代法(该算法简单介绍见前面博文:机器学习&数据挖掘笔记_12(对Conjugate Gradient 优化的简单理解))求得。
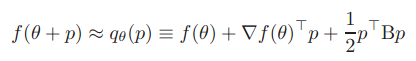
技巧1:计算Hv时并不是直接用有限差分法,而是利用Pearlmutter的R-operator方法(没看懂,但是该方法优点有很多)。
技巧2:用Gauss-Newton矩阵G来代替Hessian矩阵H,所以最终隐式计算的是Gv.
技巧3:作者给出了用CG算法(有预条件的CG,即先对参数θ进行了一次线性坐标变换)求解θ搜索方向p时的迭代终止条件,即:
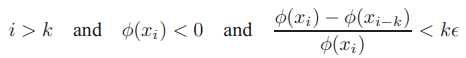
技巧4:在进行处理大数据学习时,用CG算法进行线性搜索时并没有用到所有样本,而是采用的mini-batch,因为从一些mini-batch样本已经可以获得关于曲面的一些有效曲率信息。
技巧5:用启发式的方法(Levenburg-Marquardt)求得系统的阻尼系数λ,该系数在预条件的CG算法中有用到,预条件矩阵M的计算公式为:
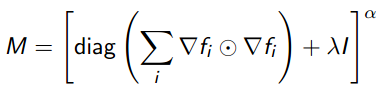
上面的7点需要详细阅读Martens的paper,且结合其paper对应的code来读(code见他的个人主页http://www.cs.toronto.edu/~jmartens/research.html).
下面来简单看看HF的流程图:
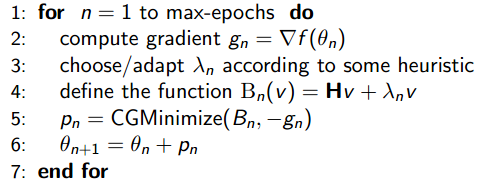
流程图说明的是:定义好系统的目标函数,见本博客中的第2个公式,接着定义一个最大权值更新次数max-epochs,每次循环时首先用BP算法求出目标函数的梯度值,接着用启发式的方法取得λ值,然后预条件CG方法来优化参数搜索方向p(此过程需要用到Hv形式的求解函数),最后更新参数进入下一轮。
关于code部分,简单说以下几点:
运行该程序,迭代到170次,共用了差不多20个小时,程序的输出如下:
maxiters = 250; miniters = 1 CG steps used: 250, total is: 28170 ch magnitude : 7.7864 Chose iters : 152 rho = 0.50606 Number of reductions : 0, chosen rate: 1 New lambda: 0.0001043 epoch: 169, Log likelihood: -54.7121, error rate: 0.25552 TEST Log likelihood: -87.9114, error rate: 3.5457 Error rate difference (test - train): 3.2901
code完成的是CURVES数据库的分类,用的是Autoencoder网络,网络的层次结构为:[784 400 200 100 50 25 6 25 50 100 200 400 784]。
conjgrad_1(): 完成的是预条件的CG优化算法,函数求出了CG所迭代的步数以及优化的结果(搜索方向)。
computeGV(): 完成的是矩阵Gv的计算,结合了R操作和Gauss-Newton方法。
computeLL(): 计算样本输出值的log似然以及误差(不同激发函数的输出节点其误差公式各异)。
nnet_train_2():该函数当然是核心函数了,直接用来训练一个DL网络,里面当少不了要调用conjgrad_1(),computeGV(),computeLL(),另外关于误差曲面函数导数的求法也是用的经典BP算法。
参考资料:
Martens, J. (2010). Deep learning via Hessian-free optimization. Proceedings of the 27th International Conference on Machine Learning (ICML-10).
机器学习&数据挖掘笔记_12(对Conjugate Gradient 优化的简单理解)
http://www.cs.toronto.edu/~jmartens/research.html
http://pillowlab.wordpress.com/2013/06/11/lab-meeting-6102013-hessian-free-optimization/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号