


神经网络梯度爆炸/消失以及改善方式(吴恩达)
神经网络的传播(前向)过程如图,如果ω>1(即使是稍微大一点点),只要层数足够多最后会造成ω呈指数上升,这就是梯度爆炸;同理,当ω<1(即使是稍微小一点点),ω会快速缩小逼近0,这就是梯度消失
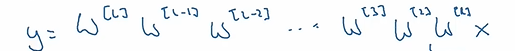
目前能稍微解决的方法是对ω进行合理地初始化
对于若干层数且每层的神经元数量不尽相同的情况下,比较好的取向是神经元数量多的ω大小尽可能小,而神经元数量少的ω尽可能大,即神经元数量与ω成反比关系:ω∝k/√n,其中k为常数,n为神经元数
实际使用中,k的取值需要考虑激活函数。如ReLU函数k取2,tanh函数k取1
根据之前 随机初始化参数的必要性 https://www.cnblogs.com/toriyung/p/16406891.html
可得到ω的初始化值:
ω = np.random()*np.sqrt(1/n)*k


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通