


Opencv Q&A_6
2022/03/12-2022/03/13
基于YOLO3的物体识别
代码

import cv2 as cv import numpy as np whT = 320 confidence_thres = 0.5 NMS_thres = 0.2 ## 模型配置文件和权重文件路径 modelConfig = 'D:\work\\automation\Skill\Python\pythonWORK\cv\yolo3\yolov3.cfg' modelWeight = 'D:\work\\automation\Skill\Python\pythonWORK\cv\yolo3\yolov3.weights' with open('D:\work\\automation\Skill\Python\pythonWORK\cv\yolo3\coco.names') as f: className = f.read() className = list(className.split('\n')) cap = cv.VideoCapture(0) net = cv.dnn.readNetFromDarknet(modelConfig,modelWeight) #使用darknet框架读取模型 net.setPreferableBackend(cv.dnn.DNN_BACKEND_OPENCV) #设置计算后台 net.setPreferableTarget(cv.dnn.DNN_TARGET_CPU) #设置目标设备(用什么计算) def findObject(outputs_,img): hT,wT,CT = img.shape #图片格式(h,w,3) bbox = [] classIds = [] confidence = [] for output in outputs_: #遍历每个预测 for line in output: #遍历每一层 classId = np.argmax(line[5:]) #获得最大confidenct的序号 if line[5:][classId] > confidence_thres: #前五位数值不参与判断 w, h = int(line[2] * wT), int(line[3] * hT) # 第三四位数值为宽高值(百分比) x, y = int(line[0] * wT - w / 2), int(line[1] * hT - h / 2) # 第一二位数值为中心点的坐标(百分比) bbox.append([x,y,w,h]) classIds.append(classId) confidence.append(float(line[5:][classId])) indice = cv.dnn.NMSBoxes(bbox,confidence,confidence_thres,NMS_thres) for i in indice: ## NMS找出的识别索引 i = i[0] box = bbox[i] classId = classIds[i] confid = confidence[i] cv.rectangle(img,(box[0],box[1]),(box[0]+box[2],box[1]+box[3]),(0,255,0),2) cv.putText(img,className[classId],(box[0],box[1]-10),cv.FONT_HERSHEY_SIMPLEX,1,(0,255,0),2) cv.putText(img, str(round(confid*100,2)) +'%', (box[0] + 150, box[1] - 10), cv.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2) while True: flag,frame = cap.read() blob = cv.dnn.blobFromImage(frame,1/255,(whT,whT),[0,0,0],1,crop=None) net.setInput(blob) layerNames = net.getLayerNames() #获得每个层的名称 outputNames = [layerNames[i[0]-1] for i in net.getUnconnectedOutLayers()] #getUnconnectedOutLayers():获得非连接层(即预测输出层) outputs = net.forward(outputNames) #前向传播三个预测值输出 findObject(outputs,frame) cv.imshow('img',frame) cv.waitKey(1)
运行效果

遇到的问题
Q1:图片的shape
A1:高度,宽度,3个颜色通道
Q2:几个dnn函数解释
A2:
1. cv.dnn.readNetFromDarknet():使用darknet框架读取模型:输入参数为(模型配置文件,模型权重文件)
2. setPreferableBackend():设置计算后台,一般用cv.dnn.DNN_BACKEND_OPENCV
3. setPreferableTarget():设置计算目标设备
4. cv2.dnn.blobFromImage():对图片进行预处理,返回一个作为神经网络输入的数组。输入参数为(图片,缩放比例,输出尺寸大小,各颜色通道减去的均值,交换RB通道...)
5. getLayerNames():获得每个层的层名
6. getUnconnectedOutLayers():获得非连接层的层号
7. forward():前向传播并返回预测输出(本模型有三个预测输出)
Q3:forward()预测输出数据结构
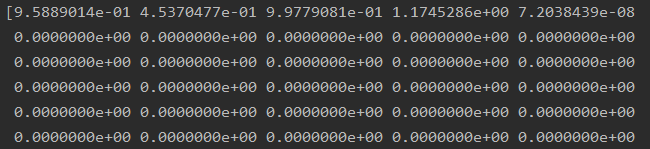
A3:如图所示三个输出,为列数相同的二维数组结构。不同输出不同的层数,每层包含了依次1-5个数值为:中心坐标x,y,宽高w,h,识别总置信度confidence。从第6位数值开始对应coco.names数据集的各个置信度。
(注意:如第二个图所示,每个数值为原数值/100,需先转换为百分比格式)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通