
《阿里云天池大赛赛题解析》——工业蒸汽量预测
赛事链接:https://tianchi.aliyun.com/competition/entrance/231693/information
代码下载:https://github.com/luxuantao/alibaba_tianchi_book
请自己阅读赛题描述和下载代码
1.数据探索
1.1数据说明
在数据探索阶段,我们大致可以了解到训练集占总体大概0.6,测试集占总体大概0.4;
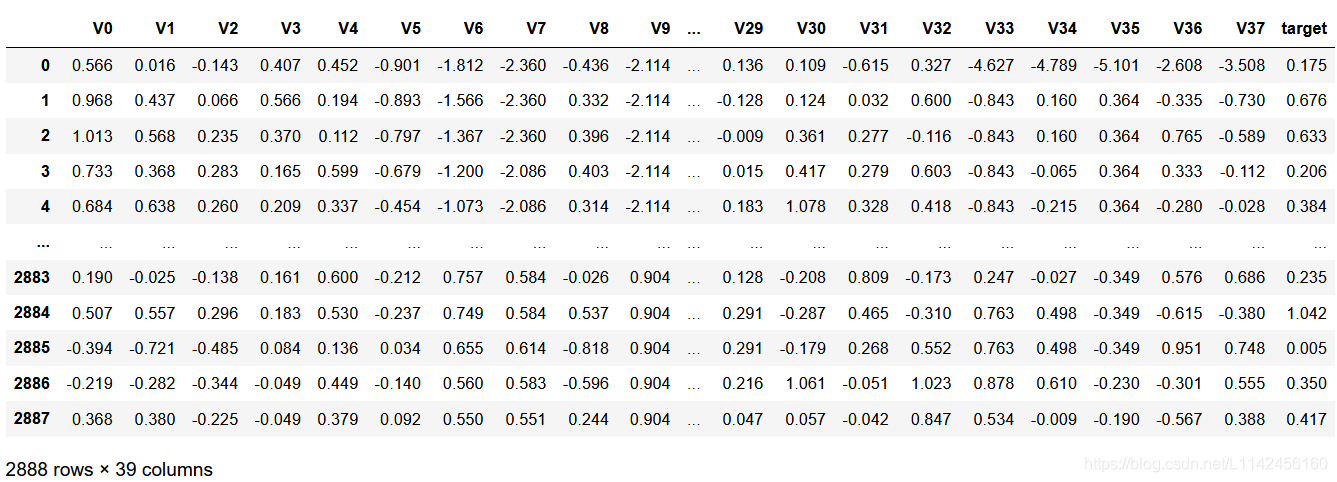
此训练集数据共有2888个样本,数据中有V0-V37共计38个特征变量,变量类型都为数值类型,所有数据特征没有缺失值数据。可以理解为V0~V37是影响锅炉燃烧效率的因素也就是x1,x2,x3......x37,target是在某一时间及给定的因素下锅炉产生的蒸汽量也就是y; 数据字段由于采用了脱敏处理,删除了特征数据的具体含义;target字段为标签变量。训练数据具体如下图:
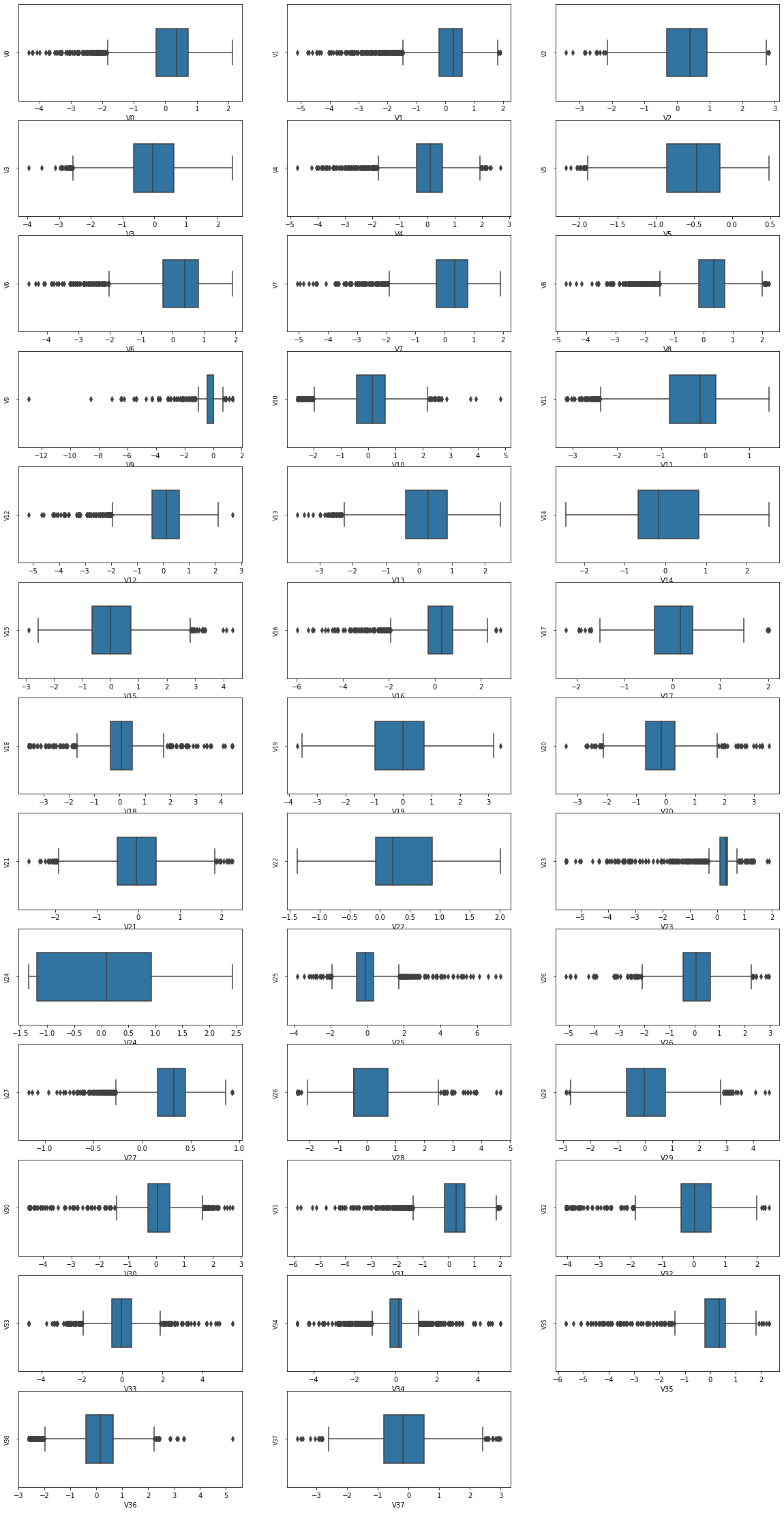
1.2箱型图
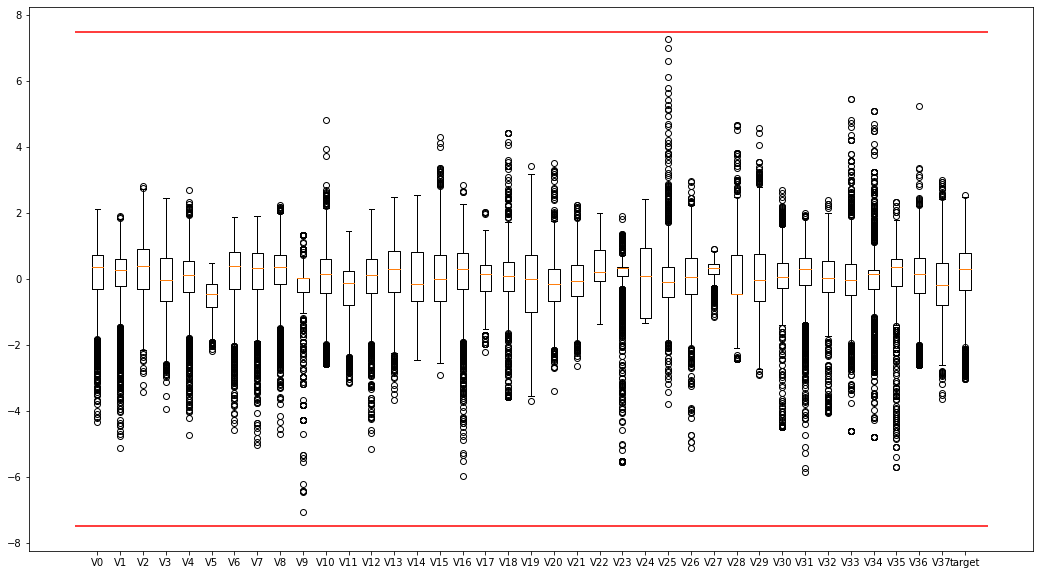
我们通过箱型图是为了可以直接明了的识别图中的异常值,超过上下边缘的都是异常值。在这里只让我们直观的感受到异常值即可,不做过多操作。
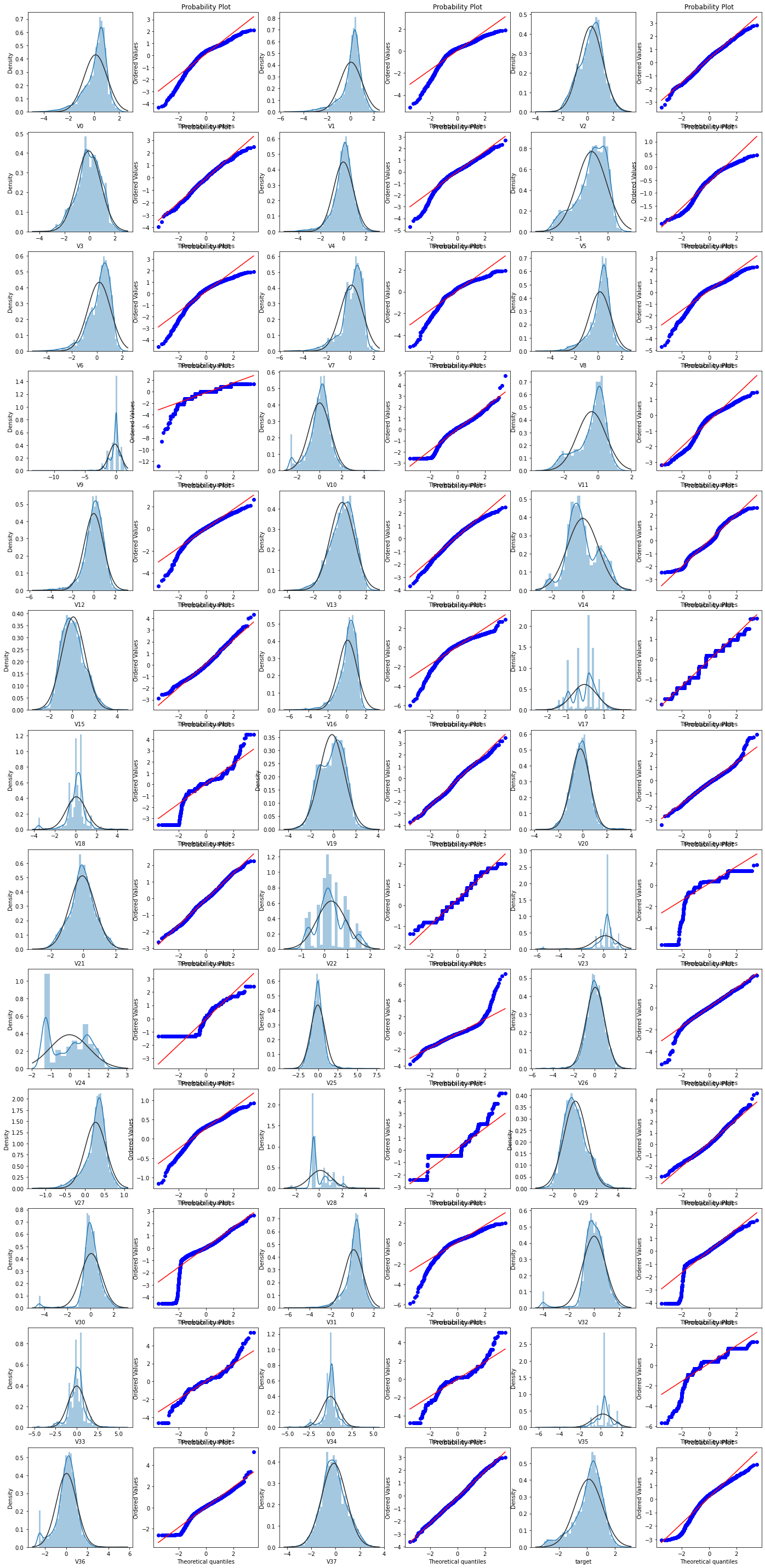
1.3查看数据分布图
首先我们查看特征变量‘V0’的数据分布直方图,并绘制Q-Q图查看数据是否近似于正态分布。
在这里会有小伙伴产生疑惑,‘V0’的数据分布直方图是什么,Q-Q图是什么,为什么要看是否正态分布,别着急我这就告诉你。
-
数据分布直方图
绘制分布直方图是为了查看其在训练集中的统计分布。
stats.norm是正态分布,也就是高斯分布,这里画出一个直方图,用来拟合标准正态分布。控制拟合的参数分布图形,能够直观地评估它(这里是正态分布)与观察数据的对应关系。
简而言之,就是我们将特征变量画出一个直方图,然后用来拟合标准正态分布,这样就可以直观的查看特征变量与正态分布之间的对应关系。
-
Q-Q图
使用Q-Q图可以分析不同数据集是否为同一分布,并且可以用Q-Q图来验证数据集是否符合正态分布。
我们这组数据中一串数目的每个点都是该数据的某分位点,把这些点的(称为样本分位数点)和相应的理论上的分位数配对做出散点图,如果该数据服从正态分布,那么该图看上去应该像一条直线,否则就不服从正态分布。
那么为什么要看特征变量是否服从正态分布呢?正态分布十分重要,尤其是在数据科学和机器学习领域,它几乎无处不在。我们这里不做多解释,只需要知道一句话:大自然中发现的变量,大多近似服从正态分布。因此在机器学习中我们对待特征变量也要看是否符合正态分布,如果不符合则说明这个特征变量是不合格的。
下面我们来查看训练集的特征变量与测试集中相对应的特征变量的直方图。(我们上面查看的是训练集中特征变量与其拟合的正态分布的直方图)。
查看所有特征变量下,训练集数据和测试集数据的分布情况,分析并寻找出数据分布不一致的特征变量。
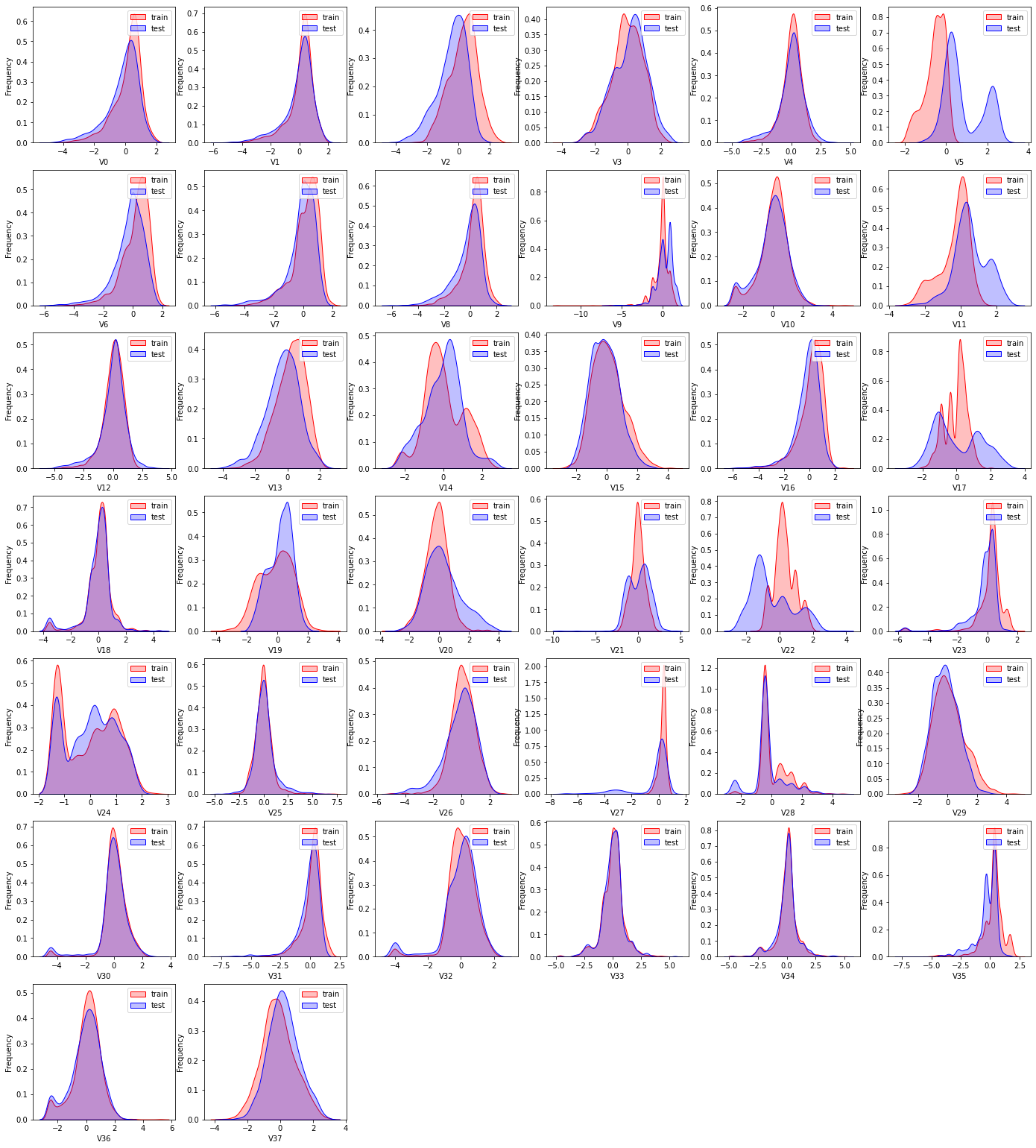
注意这里,测试集中没有target,sns.kdeplot为核密度估计,核密度估计是概率论上用来估计未知的密度函数,属于非参数检验,通过核密度估计图可以比较直观的看出样本数据本身的分布特征。比如咱们这里的test就没有target也就是y值,因此使用核密度估计来估计未知的y值。
训练集数据与测试集数据分布不一致,会导致模型泛化能力差。
1.4线性回归关系
这里我们来查看所有特征变量与'target'变量的线性回归关系
下面我们来通过画热力图来查看特征变量的相关性,这里注意我们查看的不只是特征变量与target之间的相关性,还包括特征变量之间的相关性。如图:
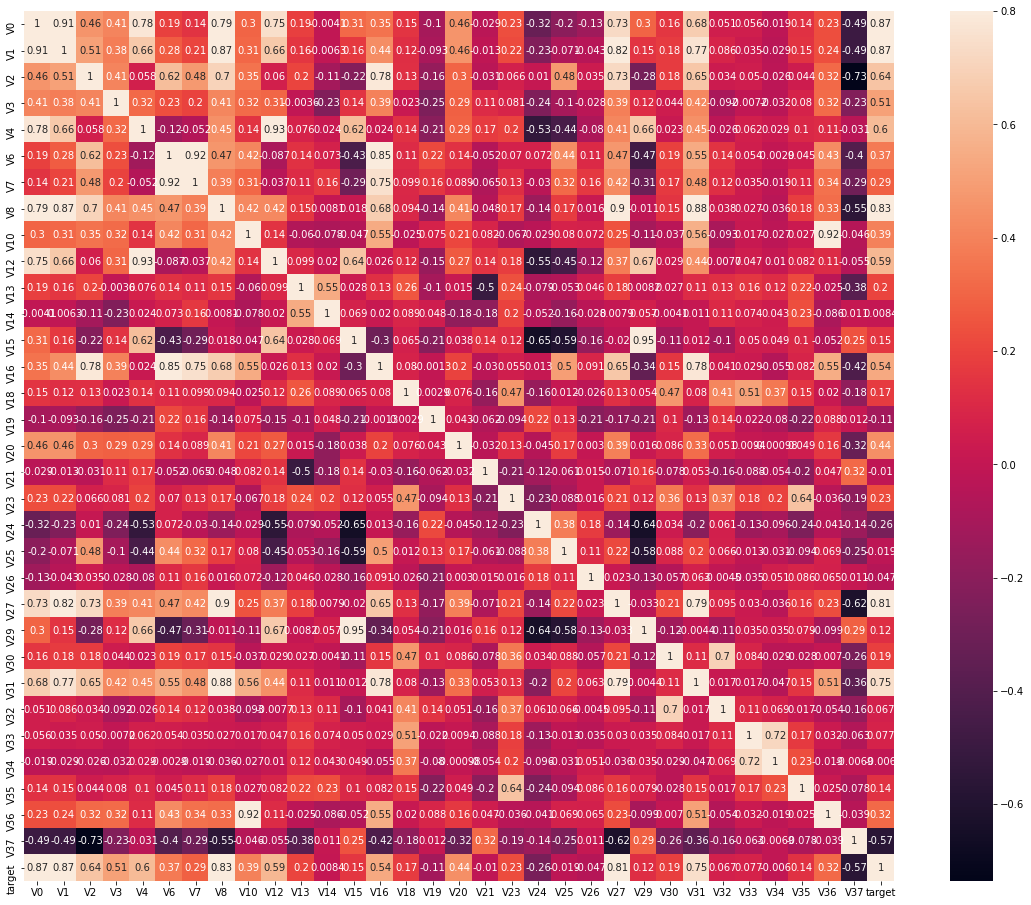
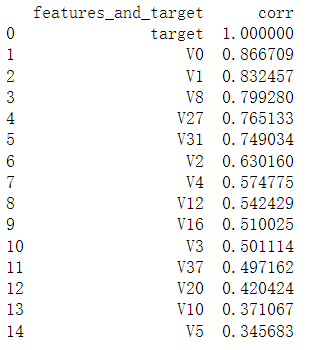
下面查找出特征变量和target变量相关系数大于0.5的特征变量,当然相关系数越大,就认为这些特征变量对target变量的线性影响越大。
这里我们先寻找出k个与target变量最相关的特征变量,然后再找出与target变量的相关系数大于0.5的特征变量。(这里我不明白为什么不直接找相关系数大于0.5的特征变量,而是先设置一个k值范围?)
结果如图
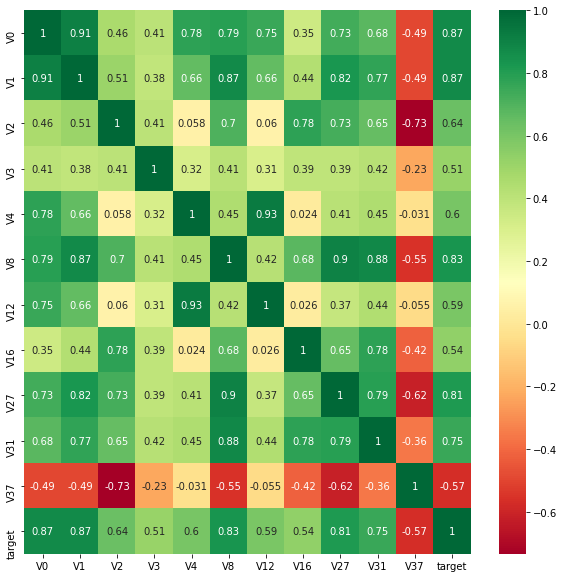
那些相关系数小于0.5的,则认为这些特征与最终的预测target值不相关,删除这些特征变量。
1.5Box-Cox变换
在第3小节的数据直方图中,我们看到了特征向量与其标准正态分布的直方图,有几个特征向量实在是太不符合正态分布了,影响我们的后续操作,因此在进行统计分析时,需要将数据转换使其符合正态分布。
Box-Cox变换是统计建模中常用的一种数据转换方法。在连续的影响变量不满足正态分布时,可以使用Box-Cox变换,这一变换可以使线性回归模型在满足线性、正态性、独立性以及方差齐性的同时,又不丢失信息。
-
第一步:归一化处理
这里我们是将训练集和测试集统一进行了归一化处理,因为合并归一化必须要保证数据的一致性,所以我们将训练集中的target扔掉了先,然后和测试集就保持一致啦。 -
第二步:进行Box-Cox变换
这里我们变换完成后,再画一次Q-Q图(基于正态分布),可以惊喜的看见那几个不符合正态分布的特征变量开始符合正态分布啦!
2.特征工程
2.1异常值处理
我们在 1.2箱型图 中使用过箱型图来查看异常值,因此这里就不做过多赘述,这里我们将异常值进行删除处理。
2.2最大最小值归一化
这里对数据进行归一化处理,以便于后续操作。
2.3查看训练集数据和测试集数据分布情况
我们在 1.3查看数据分布图 中查看过测试集与训练集特征变量的直方图分布,因此这里也不做过多赘述。这里直接将这些分布差异较大的特征变量删除了去,因为分布差异较大会影响模型的泛化能力。
下图为分布差异较大的几个特征变量:

值得一提的是,在`1.3查看数据分布图`中我们使用了Box-Cox变换,将不符合正态分布的特征变量变得符合了正态分布,因此这里可不可以使用Box-Cox变换,将同一特征变量的训练集与测试集也相拟合?这样就可以保留这些分布差异较大的特征变量。
2.4特征相关性
我们在 1.4线性回归关系 中探讨了特征相关性,因此这里也不做过多赘述。
2.5特征降维
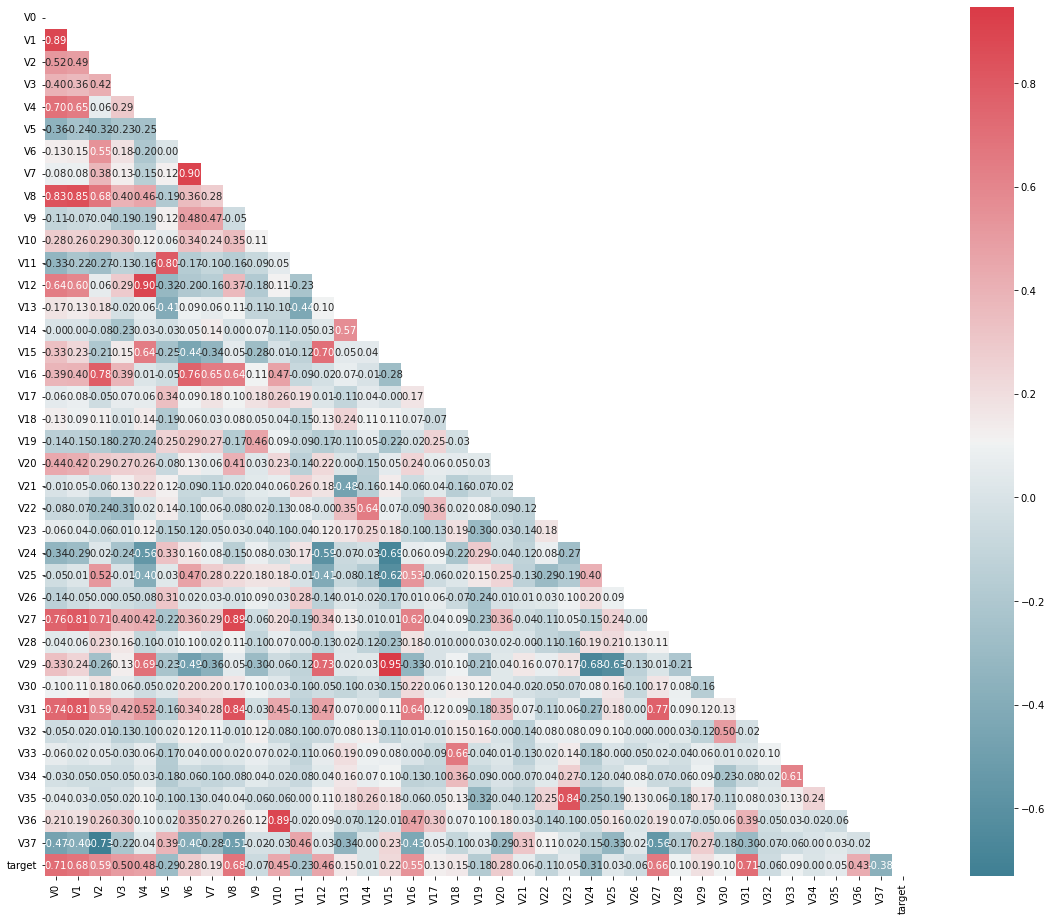
2.5.1特征相关性初筛
这里我们算出来所有的特征变量和target对target的相关性系数,并且筛选出大于0.1的特征变量。如图:
2.5.2多重共线性分析
多重共线性分析的原则是特征组之间的相关性系数较大,即每个特征变量与其他特征变量之间的相关性系数较大,故可能存在较大的共线性影响,这会导致模型估计不准确。因此,我们后续要使用PCA对数据进行处理,去除多重共线性。
首先我们需要先计算VIF,也就是多重共线性方差膨胀因子。
然后就可以开始使用PCA对数据进行降维处。
3.模型训练
在前面的特征处理结束后,我们就进入到了模型训练阶段。
3.1 回归模型的训练和预测
回归模型训练和预测的步骤:
(1)导入需要的工具库
(2)对数据预处理,包括导入数据集,处理数据等操作,集体为缺失值处理、连续特征归一化、类别特征转换等。
(3)训练模型。选择合适的机器学习模型,利用训练集对模型进行训练,达到最佳拟合效果。
(4)预测结果。将待预测的数据集输入到训练好的模型中,得到预测结果。
3.2线性回归模型
概念:最简单的回归模型,假定因变量Y和自变量X呈线性相关,则可以采用线性模型找出自变量X和因变量Y的关系,以便预测新的自变量X的值,这就是线性回归模型。
- 特征工程后,需要对数据集进行切分,我们将其切分为数据训练数据80%,验证数据20%。
然后直接从sklearn中导入LinearRegression()就可以进行线性回归模型了。
3.3K近邻回归
概念:K近邻算法不仅可以用于分类,还可以用于回归。通过找出某个样本的k个最近邻居,将这些邻居的某个(些)属性的平均值赋给该样本,就可以得到该样本对应属性的值。
这里推荐一个小视频,看完就懂:什么是KNN(K近邻算法)?
直接从sklearn中导入KNeighborsRegressor()就可以进行K近邻算法进行预测了。
3.4决策树回归
概念:决策树回归可以理解为根据一定准则,将一个空间划分为若干个子空间,然后利用子空间内所有点的信息表示这个子空间的值。对于测试数据,我们只需要按照特征将其归到某个子空间,便可得到对应子空间的输出值。如下图:
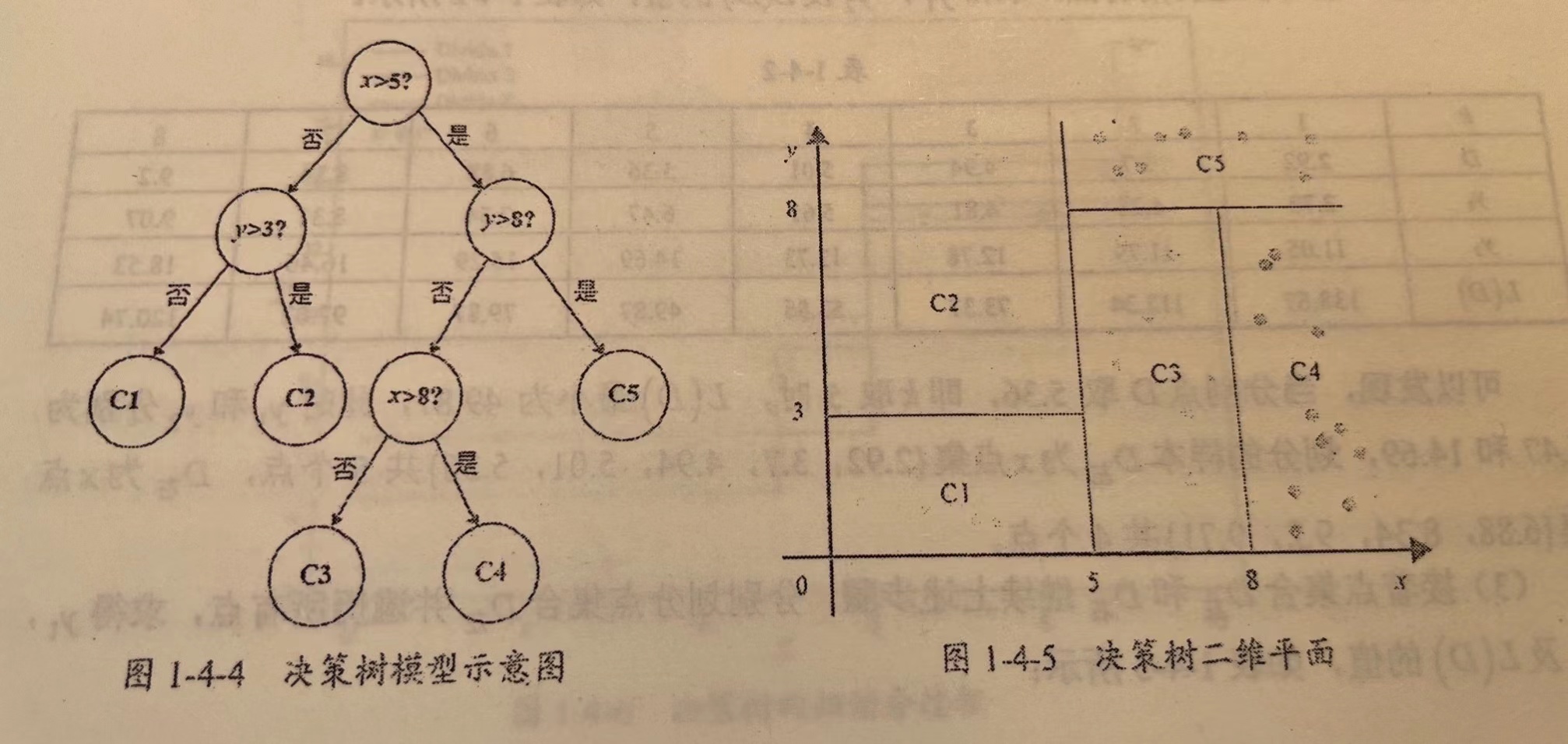
那么我们如何预测呢?我们可以利用这些划分区域的均值或者中位数代表这个区域的预测值,一旦有样本按划分规则落入某一个区域,就直接利用该区域的均值或者中位数代表其预测值。
直接从sklearn中导入DecisionTreeRegressor()就可以进行策树算法回归预测了。
3.5集成学习
这里见我的随记《集成学习》
3.5.1随机森林
直接从sklearn中导入RandomForestRegressor()就可以进行随机森林算法预测了。
3.5.2GBDT
这里见我的随记《集成学习——GBDT(手推公式)》
直接从sklearn中导入GradientBoostingRegressor(),就可以进行GBDT算法预测了。
4.模型验证
4.1拟合问题
关于拟合问题,很简单理解,这里建议可以去其他博客进行了解,简而言之,欠拟合就是模型训练的还不够,而过拟合就是模型训练的太过了。
如果过拟合的话,则需要在模型中加入正则化。
4.2交叉验证
这里先小小的进行一下科普,简单阐述一下训练集以及测试集;
-
训练集:用于训练模型的训练参数
-
测试集:用来检测已知训练好的最终模型的泛化性能,但不能用于模型参数的调整。
由此可见,测试集主要目的是检测模型的泛化性能,并不能对模型的参数进行调整,那么我们如何来通过一遍遍的训练,使模型的参数得以改进呢,这里就需要验证集的出现了。
模型参数分为训练参数和超参数,其中训练参数是通过不断的训练来不断完善,而超参数则是人为制订的。
- 验证集:用于检验模型的性能(这一点和测试集相同),但还可以根据检验的结果反过来调整模型的参数,特别是超参数(这一点和测试集不同)。
当数据少的时候我们就可以将数据直接分成训练集,验证集和测试集,但是当数据量少的时候我们就需要进行交叉验证了,那么何为交叉验证?
- 交叉验证:其实就是将训练集拆成训练集+验证集,但是拆的方法多种多样,如K折交叉验证、留一交叉验证、留P交叉验证等等。一般情况下我们都是用训练集进行交叉验证,当然一切特殊情况下我们也可以将全部数据进行交叉验证。
4.3网络搜索
- 网络搜索:一种调参手段,所有候选参数中遍历所有参数,选出最合适的,好比我给出了α=[1,4,9,15],网络搜索遍历所有情况,最后得出α=15时模型最好。
这里我们会发现两种调节超参数的方法,一种是网络搜索,另一种就是交叉验证,两者都可以对模型的超参数进行改进,那么二者有何区别呢?
网络搜索的候选参数要人为的给出,交叉验证则是自己训练来不断地微调超参数。因此可以理解为网络搜索给了一个大概的方向,而交叉验证则是在其基础上进行不断地微调。
因此可以将网络搜索和交叉验证进行结合,在以后的实操中可以使用这个方法,相信会节约不少时间。
交叉验证经常与网格搜索进行结合,作为参数评价的一种方法,这种方法叫做grid search with cross validation。sklearn因此设计了一个这样的类GridSearchCV
4.4学习曲线与验证曲线
-
学习曲线:在训练集大小不同的时候才会遇到,判断模型的方差和偏差是否过高,以及增大训练集可否减小过拟合。
-
验证曲线:是根据超参数的改变而画的,观察模型是否过拟合。
验证曲线可以看拟合程度,如果过拟合了则需要再模型中加入正则化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号