模型压缩-轻量化Bert模型
bert之类的预训练模型在NLP各项任务上取得的效果是显著的,但是因为bert的模型参数多,推断速度慢等原因,导致bert在工业界上的应用很难普及,针对预训练模型做模型压缩是促进其在工业界应用的关键,今天介绍几篇轻量化bert模型—DistillBert, ALBERT。
一. DistillBert
论文: DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
方法
DistillBert是在bert的基础上用知识蒸馏技术训练出来的小型化bert,具体做法如下:
- 给定原始的bert-base作为teacher网络。
- 在bert-base的基础上将网络层数减半(也就是从原来的12层减少到6层)。
- 利用teacher的软标签和teacher的隐层参数来训练student网络。
损失函数
训练时的损失函数定义为三种损失函数的线性和,三种损失函数分别为:
- \(Lce\)。这是teacher网络softmax层输出的概率分布和student网络softmax层输出的概率分布的交叉熵(注:MLM任务的输出)。
- \(Lmlm\)。这是student网络softmax层输出的概率分布和真实的one-hot标签的交叉熵
- \(Lcos\)。这是student网络隐层输出和teacher网络隐层输出的余弦相似度值,
在上面我们说student的网络层数只有6层,teacher网络的层数有12层,因此个人认为这里在计算该损失的时候是用student的第1层对应teacher的第2层,student的第2层对应teacher的第4层,以此类推.
Student模型初始化
作者对student的初始化也做了些工作,作者用teacher的参数来初始化student的网络参数,
做法和上面类似,用teacher的第2层初始化student的第1层,teacher的第4层初始化student的第2层。
补充
- 作者也解释了为什么减小网络的层数,而不减小隐层大小,作者认为在现代线性代数框架中,在张量计算中,降低最后一维(也就是隐层大小)的维度对计算效率提升不大,反倒是减小层数,也提升计算效率。
- 另外作者在这里移除了句子向量和\(pooler\)层,在这里也没有看到\(NSP\)任务的损失函数,因此个人认为作者也去除了NSP任务(主要是很多人证明该任务并没有什么效果)。
整体上来说虽然方法简单,但是效果还是很不错的,模型大小减小了40%(66M),推断速度提升了60%,但性能只降低了约3%。
二. ALBERT
论文:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Github: https://github.com/brightmart/albert_zh
方法
ALBERT主要做了三点改变:Factorized embedding parameterization ,Cross-layer parameter sharing ,Inter-sentence coherence loss 。
Factorized embedding parameterization
- 在bert中采用的是embedding层的嵌入词向量大小E等于隐层大小H,但作者认为embedding层只是做了词嵌入,在这一层词与词之间是相互独立的,词嵌入后得到的向量包含的信息也仅仅只有当前词的信息,因此向量长度不需要那么大(我们常用的word2vec向量长度一般不超过300),但是隐层因为会和其他词计算self-attention,因此隐层词对应的向量是包含了上下文信息的,此时含有的信息是非常丰富的,用小的向量容易丢失信息,需要将隐层大小设大一点。
- 针对这样的分析,作者认为像bert中embedding层和隐层大小设置为相等是不合理的(bert-base中,E=H=768)。而且在embedding层,有一个大的词嵌入矩阵V x E。在这里V为vocab size(通常比较大,bert中就是20000多),因此当E很大时,这里的参数就非常多,又基于上面的分析,E可以不用设这么大,
- 因此作者在这里做了一个矩阵分解,将矩阵\(V × H(E)\)分解为两个小的矩阵\(V × E,\ E × H\)。在这里将E设置为一个远小于H的值,然后再经过一个矩阵\(E × H\)将词向量维度映射到H。
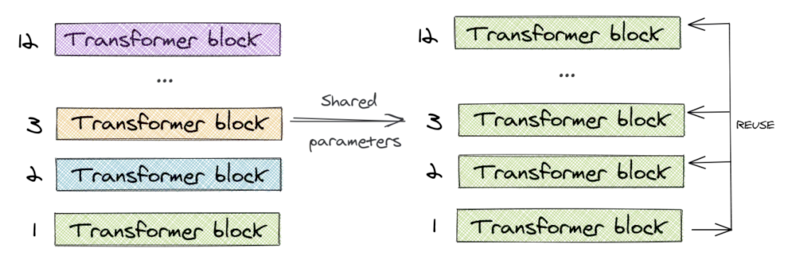
Cross-layer parameter sharing-跨层参数共享
ALBERT只学习第一个块的参数,并在剩下的 11 个层中重用该块,而不是为 12 个层中每个层都学习不同的参数。
可以只共享 feed-forward 层的参数,只共享注意力参数,也可以共享整个块的参数。论文对整个块的参数进行了共享
句子顺序预测(SOP)
Bert 的 NSP(Next Sentence Prediction) 被发现不可靠,本文作者猜测任务难度相比 MLM 来说太小,其实它可以看作一个任务做了主题预测和连贯性预测,但主题预测很容易,而且和 MLM 有重叠。NSP二分类:
- 从训练语料库中取出两个连续的段落作为正样本
- 从不同的文档中随机创建一对段落作为负样本
ROBERTA和XLNET等论文都阐明了NSP无效,且发现它对下游任务影响不可靠,甚至取消NSP之后多个任务的性能都提高了。
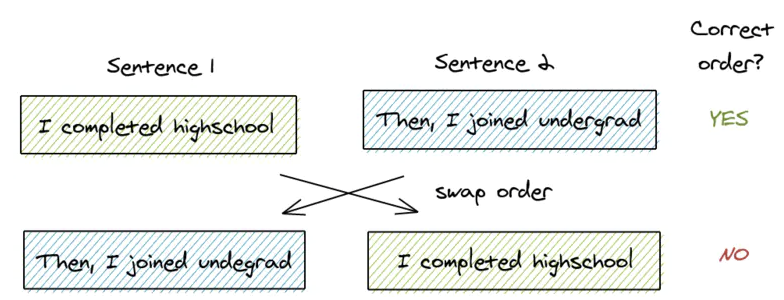
因此本文提出了 SOP(Sentence-order Prediction),聚焦在句子连贯的建模上,具体做法是:Positive 和 Bert 一样,来自同一个文档的两个连续片段;Negative 用的还是这两个片段,只不过交换了一下顺序。
- 从同一个文档中取两个连续的段落作为一个正样本
- 交换这两个段落的顺序,并使用它作为一个负样本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号