



Sharding-Jdbc
基于Sharding-Jdbc实现读写分离
基于Sharding-Jdbc实现分表分库
Sharding-Jdbc源码分析
数据库集群自动增长id,Sharding-Jdbc 雪花算法
Sharding-Jdbc介绍
Sharding-Jdbc在3.0后改名为Shardingsphere它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
Sharding-Sphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。它通过关注不变,进而抓住事物本质。关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
应用场景:
数据库读写分离
数据库分表分库
相关资料:
Sharding-Jdbc官方网址: http://shardingsphere.io/index_zh.html
改名新闻: https://www.oschina.net/news/95889/sharding-jdbc-change-to-sphere
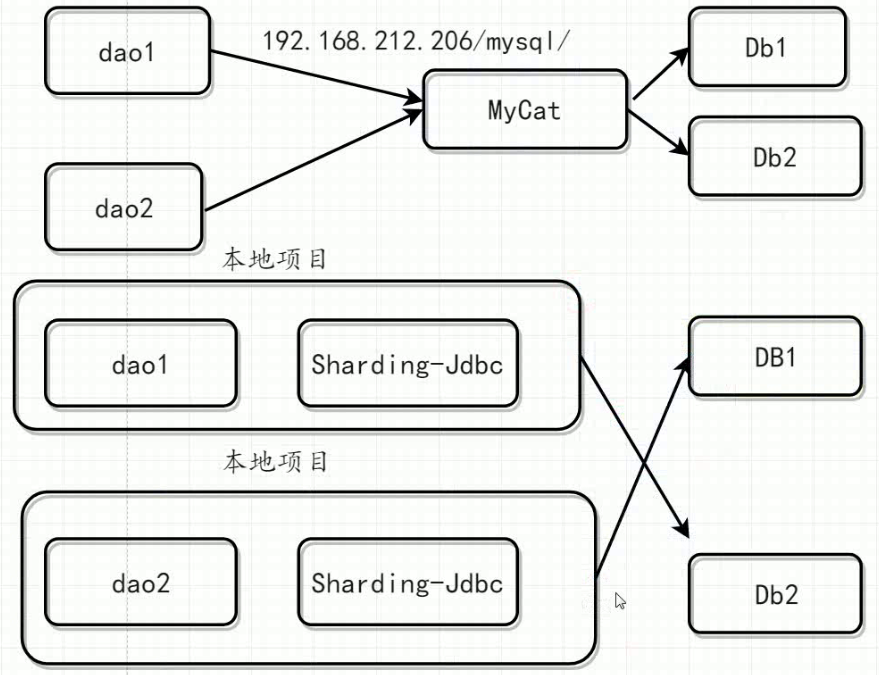
Sharding-Jdbc与MyCat区别
MyCat是一个基于第三方应用中间件数据库代理框架,客户端所有的jdbc请求都必须要先交给MyCat,再有MyCat转发到具体的真实服务器中。
Sharding-Jdbc是一个Jar形式,在本地应用层重写Jdbc原生的方法,实现数据库分片形式。
MyCat属于服务器端数据库中间件,而Sharding-Jdbc是一个本地数据库中间件框架。
从设计理念上看确实有一定的相似性。主要流程都是SQL 解析 -> SQL 路由 -> SQL 改写 -> SQL 执行 -> 结果归并。但架构设计上是不同的。Mycat 是基于 Proxy,它复写了 MySQL 协议,将 Mycat Server 伪装成一个 MySQL 数据库,而 Sharding-JDBC 是基于 JDBC 的扩展,是以 jar 包的形式提供轻量级服务的。
这也就是之前在微服务中学习的SpringCloud Ribbon与Nginx区别。
如图所示:
MyCat属于服务器端的
Sharding-Jdbc属于本底的
类似于Nginx和Rabbon
Sharding-Jdbc实现读写分离
Sharding-Jdbc实现读写分离原理,非常容易。只需要在项目中集成主和从的数据源,Sharding-Jdbc自动根据DML和DQL 语句类型连接主或者从数据源。
注意: Sharding-Jdbc只是实现连接主或者从数据源,不会实现主从复制功能,需要自己配置数据库自带主从复制方式。
查看MasterSlaveDataSource即可查看该类getDataSource方法获取当前数据源名称
DML:数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE 子句组成的查询块: SELECT <字段名表> FROM <表或视图名> WHERE <查询条件>
DQL:数据操纵语言DML主要有三种形式: 1) 插入:INSERT 2) 更新:UPDATE 3) 删除:DELETE

需要在配置文件配置读写分离jdbc连接全部交给 全部交给Sharding-Jdbc
主数据库和从数据库 主的数据库与从的数据库采用二进制文件实现数据同步
Sharding-Jdbc 会自动判断sql语句类型 (DML或者DQL),如果是DML语句的话 会获取主的jdbc连接配置进行发送请求,如果是DQL语句的话,
它没有实现主从同步,只是单纯实现DML语句或者SQL语句

